概要
- 与えられたモデルにおけるBiasとVarianceの解釈について学びます。
- BiasとVarianceの違いは何か
- 機械学習のワークフローを使ってBiasとVarianceのトレードオフを実現する方法
はじめに
天気について説明します。 少し湿度が高いと雨が降り、風が強いと雨が降らない、暑いと雨が降らない、氷点下だと雨が降らない。 この場合、どのように予測モデルを学習させ、天気の予測に誤りがないようにするのでしょうか。 学習アルゴリズムはたくさんあると言われるかもしれません。 それらは多くの点で区別されますが、私たちが期待するものとモデルが予測するものには大きな違いがあります。 それが、バイアスと分散のトレードオフの概念です。
通常、バイアスと分散のトレードオフは、緻密な数学的公式によって教えられます。 しかし、この記事では、できるだけ簡単にバイアスと分散を説明しようとしました!
私の焦点は、問題ステートメントを理解し、バイアスと分散の誤差が最小となる最適なモデルを選択するプロセスを通して、あなたを回転させることです。 このデータセットは、ネイティブ・インディアンのPima Heritageの成人女性患者の診断測定値で構成されています。 このデータセットでは、我々は、”Outcome” 変数 – 患者が糖尿病であるかどうかを示す – に注目します。
この問題やデータサイエンスの概念に興味があり、実践的に学びたい場合は、コース「データサイエンス入門」
目次
- 機械学習モデルの評価
- 問題文と主要ステップ
- バイアスとは何か
- バイアスとは何か
- バイアスとは何か
- 機械学習モデルを評価する
- 問題文と主要ステップ
バイアスとは何か
- バイアスとは何か
機械学習モデルを評価する
- バイアスとは何か
機械学習モデルを評価する
- 問題文と主要ステップ3058
- 分散とは
- Bias-Variance Tradeoff
Evaluating your Machine Learning Model
機械学習モデルの主要目的は、与えられたデータから学び、学習プロセス中に観察されるパターンに基づいて予測を生成することである。 しかし、私たちのタスクはそこで終わりではありません。 私たちは、モデルが生成する結果の種類に基づいて、継続的にモデルを改善する必要があります。 また、精度、平均二乗誤差(MSE)、F1スコアなどの指標を用いてモデルの性能を定量化し、これらの指標を改善するよう努めます。
教師付き機械学習モデルは、予測値 (Y) が実際の値にできるだけ近くなるように、入力変数 (X) に対して自分自身を訓練することを目的としています。 この実際の値と予測値の差が誤差となり、モデルを評価するのに使われる。 教師あり機械学習アルゴリズムの誤差は3つの部分からなる:
- バイアス誤差
- 分散誤差
- ノイズ
ノイズは除去できない誤差であるが、他の2つはすなわち。
以下のセクションでは、バイアス誤差、分散誤差、および最適なモデル選択を支援するバイアス-分散トレードオフをカバーします。
問題ステートメントと主要ステップ
先に説明したように、Pima Indians Diabetes データセットを取り上げて、その分類問題を作成しました。 まず、データセットを測定し、我々が扱っているのがどのようなデータであるかを観察することから始めましょう。
さて、データをデータフレームにロードし、いくつかの行を観察して、データへの洞察を得ることにします。 それを分離して、ターゲット変数’y’に代入しましょう。 データフレームの残りの部分は入力変数Xのセットになります。
さて、予測変数をスケールして、トレーニングデータとテストデータを分離してみましょう。
結果は2値で分類されるので、最も単純なK-最近傍分類器(Knn)を使って、患者が糖尿病かどうかを分類します。
しかし、どのようにして「k」の値を決めるのですか?
- 多分、学習データで非常に良い結果を得るために、k = 1とすべきでしょうか? 3058>
- k = 100 のような高い値を使用して、多数の最近接点を考慮し、遠い点も考慮できるようにするのはどうでしょうか。
ここで、kの値をいくつか取り、それらの値すべてについて学習データにモデルを当てはめてみましょう。
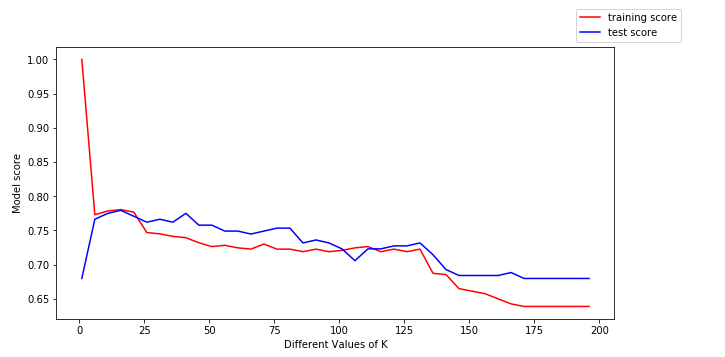
ここからさらに洞察を得るために、学習データ(赤)とテストデータ(青)をプロットしてみましょう。
あるkの値に対するスコアを計算するために、
上のプロットから以下の結論が得られる:
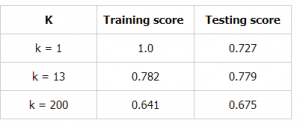
- kの値が小さい場合、トレーニングスコアは高く、テストスコアは低い
- kの値が増加するとテストスコアが増加し始めトレーニングスコアは減少している。
- しかし、あるkの値では、トレーニングスコアとテストスコアの両方が互いに近くなる。
ここで、BiasとVarianceが出てくる。 さらに説明すると、モデルは提供されたデータで学習するときに特定の仮定をします。
私たちのモデルでは、多数の最近傍を使用する場合、モデルはいくつかのパラメーターがまったく重要でないと判断することができます。 例えば、糖尿病かどうかは血糖値と血圧で決まると考えることができるのです。 このモデルは、他のパラメータが結果に影響しないことを非常に強く仮定します。
数学的に、入力変数をX、ターゲット変数をYとするとき、関数fを用いて2つの関係をマッピングする。 モデルf'(x)の目的は、できるだけf(x)に近い値を予測することである。 ここで、モデルのバイアスは:
Bias = E
上で説明したように、モデルが一般化を行うとき、すなわちバイアス誤差が大きいときは、バリエーションをあまり考慮しない非常に単純なモデルになってしまう。
分散とは
バイアスとは逆に、分散とはモデルがデータの揺らぎ、つまりノイズも考慮することです。 では、モデルが高い分散を持つとどうなるかというと、
モデルはやはり分散を学習すべきものと見なします。 つまり、モデルは学習データから学習しすぎて、新しい(テスト)データに直面したときに、それに基づいて正確に予測することができなくなる。
数学的には、モデルの分散誤差は次のようになる:
Variance-E^2
高分散の場合、モデルは学習データから学習しすぎているので、これはオーバーフィッティングと呼ばれる。
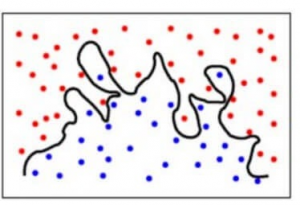
我々のデータの文脈では、ごく少数の最近傍を使う場合、すべての特徴について、妊娠回数が3回以上、グルコース値が78以上、拡張期血圧が98以下、皮膚の厚さが23mm以下…であれば、この患者は糖尿病だと判断する…というようなことです。 それ以外の、上記の条件に当てはまらない患者さんは、すべて糖尿病ではありません。 これはトレーニングセットの中のある特定の患者には当てはまるかもしれませんが、これらのパラメータが異常値であったり、間違って記録されていたりしたらどうでしょうか? 明らかに、このようなモデルは非常にコストがかかることがわかります!
さらに、患者が糖尿病であるかどうかの予測は、提供するトレーニング データの種類によって大きく異なるため、このモデルは分散誤差が大きくなります。 つまり、グルコース レベルを 75 に変更するだけでも、モデルは患者が糖尿病ではないと予測することになります。
より簡単に言うと、二次方程式で十分だったはずなのに、モデルは結果と入力特徴の間に非常に複雑な関係を予測するのです。 これは、分散誤差が大きい場合/オーバーフィッティングがある場合の分類モデルがどのように見えるかを示しています。
要約すると、このようになります。
- バイアス誤差が大きいモデルはデータに適合せず、非常に単純な仮定をしている
- 分散誤差が大きいモデルはデータに適合しすぎ、データから過剰に学習している
- 良いモデルとはバイアスおよび分散誤差がともに均衡している状態
バイアス-分散トレードオフ
以上の概念と先ほどの Knn モデルとはどう関係すれば良いのだろうか。 それを調べてみましょう!
我々のモデルでは、例えば k = 1 の場合、問題のデータポイントに最も近い点が考慮されます。 ここで、予測はその特定のデータポイントに対して正確かもしれないので、バイアス誤差は少なくなります。
しかし、1つの最も近い点だけが考慮され、これは他の可能な点を考慮していないので、分散誤差は高くなります。 これはどのようなシナリオに対応するのでしょうか。
一方、k の値が高い場合、問題のデータポイントに近い多くのポイントが考慮されます。 この場合、データポイントに近い多くの点が考慮されるため、バイアス誤差が大きくなり、学習セットから詳細を学習できないためアンダーフィットになる。
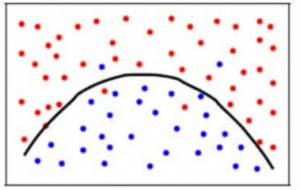
バイアス誤差と分散誤差のバランスをとるために、モデルがノイズから学習する(データに対してオーバーフィットする)ことも、データに対して大げさに仮定する(データに対してアンダーフィットする)こともないようなkの値が必要である。 より単純化すると、バランスのとれたモデルは次のようになります:
いくつかのポイントは間違って分類されますが、モデルは一般的にデータポイントのほとんどを正確にフィットさせます。 バイアス誤差と分散誤差のバランスがバイアス-分散トレードオフです。
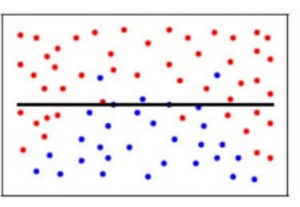
次の雄牛の目の図がトレードオフをよりよく説明しています。
バイアスが低く、分散が高いモデルは、一般的に中心付近にあるが、互いにかなり離れている点を予測します。 高バイアス、低分散のモデルは、雄牛の目からかなり離れているが、分散が低いので、予測される点は互いに近い。
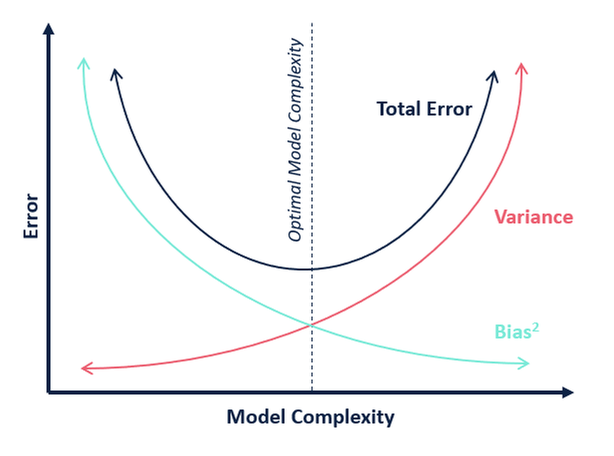
モデルの複雑さという点では、次の図を使って、モデルの最適な複雑さを決定することができる。
では、kの最適値は何だと思いますか。
以上の説明から、
- テストスコアが最も高く、
- テストスコアと学習スコアが共に近い
場合のkは最適値だと結論付けることができるのです。
これをさらに証明するために、kの値を変えて表にしてみましょう。
結論
まとめると、今回の記事では、バイアス誤差と分散誤差がともに小さいモデルが理想的であることを学びました。 しかし、学習データのモデル スコアがテスト データのモデル スコアにできるだけ近いモデルを常に目指すべきです。
そこで、オーバーフィッティングにつながる複雑すぎないモデル (高分散、低バイアス) とアンダーフィッティングにつながるシンプルすぎるモデル (高バイアス、低分散) を選ぶ方法を理解しました。 この記事で、そのコンセプトがよく理解できたと思います。