Last Updated on August 18, 2020
データセットには欠損値があり、これは多くの機械学習アルゴリズムに問題を引き起こすことがあります。
そのため、予測タスクをモデル化する前に入力データ内の各列について欠損値を識別し置き換えることは良い練習になります。
データインピュテーションの一般的なアプローチは、各列の統計値(平均値など)を計算し、その列のすべての欠損値をその統計値で置き換えることです。 統計値は学習データセットを使用して簡単に計算でき、しばしば良いパフォーマンスにつながるため、人気のあるアプローチです。
このチュートリアルでは、機械学習における欠損データに対する統計的インピュテーション戦略の使用方法を発見します。
このチュートリアルを完了すると、次のことがわかるようになります:
- Missing values must be marked with NaN values and can be replaced with statistical measure to calculate the column of values.
- 欠損値を含むCSV値を読み込み、欠損値をNaN値でマークし、各列の欠損値の数と割合を報告する方法
- モデルの評価時、および新しいデータで予測を行うために最終的なモデルを適合する際のデータ準備方法として統計で欠損値をインピュートする方法。
ステップバイステップのチュートリアルとすべての例のPythonソースコードファイルを含む私の新しい本「Data Preparation for Machine Learning」であなたのプロジェクトを始めましょう!
- 更新日:2020年6月。

Statistical Imputation for Missing Values in Machine Learning
Photo by Bernal Saborio, some rights reserved.を更新しました。
チュートリアルの概要
このチュートリアルは、3つのパートに分かれています。
- Statistical Imputation
- Horse Colic Dataset
- Statistical Imputation With SimpleImputer
- SimpleImputer Data Transform
- SimpleImputer and Model Evaluation
- 異なるインプットされた統計値を比較する
- 予測を行う際のSimpleImputer変換
(英語
統計的インプット
データセットには欠損値がある場合があります。
これらは、その行の1つまたは複数の値または列が存在しないデータの行です。 値は完全に欠落している場合もあれば、クエスチョンマーク “?” などの特殊な文字または値でマークされている場合もあります。
これらの値はさまざまな方法で表現することができます。 何もない、空の文字列、明示的な文字列 NULL または undefined または N/A または NaN、そして数字 0 などとして表示されるのを見たことがあります。
– Page 10, Bad Data Handbook, 2012.
値がない理由はさまざまですが、問題領域に特有のものが多く、破損した測定やデータの使用不可などの理由が含まれる場合があります。
測定機器の故障、データ収集中の実験デザインの変更、類似しているが同一ではない複数のデータセットの照合など、多くの理由で発生する可能性があります。
– Page 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
ほとんどの機械学習アルゴリズムは数値入力値を必要とし、データセットの各行と列に対して値が存在することが必要です。 そのため、欠損値は機械学習アルゴリズムにとって問題を引き起こす可能性があります。
そのため、データセット内の欠損値を特定し、数値で置き換えることが一般的となっています。 これはデータインピュテーション、または欠損データインピュテーションと呼ばれます。
データインピュテーションへのシンプルで一般的なアプローチは、統計的手法を使用して、存在するこれらの値から列の値を推定し、次に列内のすべての欠損値を計算された統計値に置き換えることを含んでいます。
統計は計算が速いので単純であり、しばしば非常に効果的であると判明するので人気があります。
- 列平均値。
欠損値代入の統計的手法に慣れたところで、欠損値のあるデータセットを見てみましょう。
データ準備を始めたいですか?
今すぐ7日間の無料Eメール クラッシュコース(サンプルコード付き)に参加しましょう。
Click to sign-up and also get the free PDF Ebook version of the course.
Download Your FREE Mini-Course
Horse Colic Dataset
The horse colic dataset described the medical characteristics of horses with colic and whether they lived or dead.
There is 300 rows and 26 input variables with one output variable.これは、300行の26入力変数と1出力変数のデータセットで、馬の病気と死亡のデータセットです。 これは2値分類の予測タスクで、馬が生きていたら1を、馬が死んだら2を予測する。
このデータセットで予測するために選択できるフィールドがたくさんある。
このデータセットには、多くの列で多数の欠損値があり、各欠損値はクエスチョンマーク文字(”?”)でマークされています。
以下は、データセットからマークされた欠損値を持つ行の例です。
123452,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,21,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,22,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,11,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1…データセットについての詳細はこちら:
- Horse Colic Dataset
- Horse Colic Dataset Description
動作例で自動的にデータセットをダウンロードしますので、必要ございません。
Python を使って読み込んだデータセットで NaN (not a number) 値で欠損値をマークすることはベストプラクティスです。
Pandas 関数の read_csv() を使ってデータセットを読み込み、「na_values」を指定して ‘?’の値を欠損として、NaN値でマークします。
1234・・・・・・・。# load dataseturl = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’dataframe = read_csv(url, header=None, na_values=’?’)ロードしたら、ロードしたデータを見て「?”の値はNaNとしてマークされます。
123…です。# 最初の数行を要約するprint(dataframe.head())次に、各列を列挙し、その列に値がない行の数を報告することができます。
1234567…# 各列の欠損値のある行数をまとめるfor i in range(dataframe.shape):# 欠損値のある行数を数えるn_miss = dataframe].isnull().sum()perc = n_miss / dataframe.shape * 100print(‘> %d, 欠落している。 %d (%.1f%%%)’ % (i, n_miss, perc)).これを結びつけて、データセットをロードしてサマライズする完全な例を以下に示します。
12345678910111213# summarize horse colic datasetfrom pandas import read_csv# load dataseturl = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url.Layer.Layer), header=None, na_values=’?’)# 最初の数行を要約するprint(dataframe.head())# 各列の欠損値のある行数をまとめるfor i in range(dataframe.shape):# 欠損値のある行数を数えるn_miss = dataframe].isnull().sum()perc = n_miss / dataframe.shape * 100print(‘> %d, 欠損値: %d (%.1f%%)’ % (i, n_miss, perc))例を実行すると、まずデータセットをロードし、最初の5行を要約します。
「?」文字でマークされていた欠損値がNaN値で置換されていることが確認できます。
次に、データセット内のすべての列のリストと欠損値の数と割合を見ることができます。
いくつかの列(例えば、列インデックス1および2)には欠損値がなく、他の列(例えば、列インデックス15および21)には多くの欠損値または過半数さえあることが分かります。
12345678910111213141516171819202122232425262728> 0, Missing: 1 (0.3%)> 1, Missing: 0 (0.0%)> 2, 不足している。 0 (0.0%)> 3, 不足している。 60 (20.0%)> 4, 不足している。 24 (8.0%)> 5、欠落している。 58 (19.3%)> 6、行方不明。 56 (18.7%)> 7、欠番。 69 (23.0%)> 8、行方不明。 47 (15.7%)> 9、行方不明。 32 (10.7%)> 10、行方不明。 55 (18.3%)> 11、行方不明。 44 (14.7%)> 12、行方不明。 56 (18.7%)> 13, 行方不明: 104名(34.7%)> 14名, 行方不明: 106 (35.3%)> 15, 行方不明: 247 (82.3%)> 16、行方不明。 102 (34.0%)> 17, 行方不明: 118名(39.3%)> 18名、行方不明。 29 (9.7%)> 19, 行方不明: 33 (11.0%)> 20、行方不明。 165 (55.0%)> 21, 行方不明: 198 (66.0%)> 22, 不在: 1 (0.3%)> 23, 不在(Missing): 0 (0.0%)> 24、欠番。 0 (0.0%)> 25, 不足している。 0 (0.0%)> 26, 不足している。 0 (0.0%)> 27, 不足している。 0 (0.0%)欠損値を持つ馬疝痛のデータセットに慣れたところで、統計的インピュテーションの使い方を見ていきましょう。
SimpleImputerによる統計的インピュテーション
scikit-learn 機械学習ライブラリでは、統計的インピュテーションをサポートするクラス SimpleImputer が提供されています。
このセクションでは、SimpleImputer クラスを効果的に使用する方法を探ります。
SimpleImputer Data Transform
SimpleImputerは、各列に対して計算する統計の種類に基づいて最初に設定されるデータ変換で、例.g. mean.
123…等。# define imputerimputer = SimpleImputer(strategy=’mean’)そしてインピュータはデータセットにフィットして各列の統計量を算出する。
123…# fit on the datasetimputer.fit(X)fit imputerは、データセットに適用して、各列のすべての欠損値を統計値で置換したデータセットの複製を作成します。
123…# transform the datasetXtrans = imputer.transform(X)horse colic datasetでその使い方を示し、変換前後のデータセットの欠損値の総数をまとめてその効果を確認できる
Complete exampleは次の通りである。
123456789101112131415161718192021# statistical imputation(統計的インピュテーション transform for horse colic datasetfrom numpy import isnanfrom pandas import read_csvfrom sklearn.Datasetfrom numpy import isnanfrom pandas import read_csv# load dataseturl = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’dataframe = read_csv(url, header=None, na_values=’?’)# split into input and output elementsdata = dataframe.valuesix = ) if i != 23] ←クリックすると拡大されます。X, y = data, data# print total missingprint(‘Missing: %d’ % sum(isnan(X).flatten()))# define imputerimputer = SimpleImputer(strategy=’mean’)# fit on the datasetimputer.fit(X)# transform the datasetXtrans = imputer.transform(X)# print total missingprint(‘Missing: %d’ % sum(isnan(Xtrans).Xtrans).Xtrans)# print(‘Missing: %d’ % sum(isnan(Xtrans).Xtrans).flatten())例を実行すると、まずデータセットをロードし、データセット内の欠損値の総数が1,605と報告されます。
変換が設定、フィット、実行されて、結果の新しいデータセットに欠損値がなく、期待通りに実行されたことが確認されました。
各欠測値はその列の平均値に置き換えられました。
12欠測あり。 1605Missing: 0SimpleImputer and Model Evaluation
k-fold cross-validation を使用してデータセット上で機械学習モデルを評価することは良い習慣である。
統計的欠損データインピュテーションを正しく適用し、データの漏洩を避けるためには、各列で計算された統計量をトレーニングデータセットのみで計算し、データセットの各フォールドのトレーニングセットとテストセットに適用することが必要である。
チューニングパラメータ値を選択するため、またはパフォーマンスを推定するためにリサンプリングを使用している場合、インピュテーションはリサンプリング内に組み込まれるべきである。
– Page 42, Applied Predictive Modeling, 2013.
これは、最初のステップが統計インピュテーション、次に次のステップがモデルであるモデリングパイプラインを作ることで達成することができます。 これは、Pipelineクラスを使用して実現できます。
たとえば、以下のPipelineは、「平均」戦略を持つSimpleImputerを使用し、次にランダムフォレストモデルを使用しています。
12345…# define modeling pipelinemodel = RandomForestClassifier()imputer = SimpleImputer(strategy=’mean’)pipeline = Pipeline(steps=)mean-> の評価もできるようになりました。馬の疝痛のデータセットに対して、インプットされたデータセットとランダムフォレストモデリングのパイプラインを、10回クロスバリデーションを繰り返し行う。
完全な例を以下に示す。
12345678910111213141516171819202122232425# mean imputation と random を評価する。 forest for horse colic datasetfrom numpy import meanfrom numpy import stdfrom pandas import read_csvfrom sklearn.NET Framework 2.0from numpy import stdfrom pandas import read_csvfrom sklearn.NET Framework 2.0ensemble import RandomForestClassifierfrom sklearn.impute import SimpleImputerfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.import_security(インポート)(英語)for Sklearn.Model_Selection import RandomForestClassifier# load dataseturl = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’dataframe = read_csv(url, header=None, na_values=’?’)# input要素とoutput要素に分割data = dataframe.valuesix = ) if i != 23]. ←クリックすると詳細がご覧いただけます。X, y = data, data# define modeling pipelinemodel = RandomForestClassifier()imputer = SimpleImputer(strategy=’mean’)pipeline = Pipeline(steps=)# define model evaluationcv = RepeatedStratifiedKFold(n_splits=10.Cv = RandomClassifier) # model evaluation# defined model evaluation # define model evaluation# evaluate modelscores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)print(‘Mean Accuracy. “平均値”、”平均値 “は “精度 “を意味する。 %.3f (%.3f)’ % (mean(scores), std(scores))例を実行すると、クロスバリデーション手順の各フォールドにデータインピュテーションが正しく適用されます。
注意:アルゴリズムまたは評価手順の確率的性質、または数値精度の違いによって、結果が異なる場合があります。 パイプラインは、10 倍のクロスバリデーションの 3 回の繰り返しを使用して評価され、データセットでの平均分類精度は約 86 と報告されました。3%であり、これは良いスコアである。
1Mean Accuracy: 0.863 (0.3) (1)平均精度:0.5%(1.5%) (2)平均精度:0.5%(2.5%) (3)平均精度:0.5%(1.5%) (4.5%)054)Comparing Different Imputed Statistics
「平均」統計戦略を使うことがこのデータセットにとって良いまたは最良だとなぜわかるのか?
答えは、わからない、そしてそれは任意に選ばれたということです。
私たちは、平均、中央値、最頻値(最も頻繁に)、および一定(0)の戦略を比較しながら、各統計戦略をテストし、このデータセットに最適なものを発見する実験を設計することができます。 各アプローチの平均精度を比較することができます。
完全な例を以下に記載します。
1234567891011121314151617181920212223242526272829303132#を比較する。 馬の疝痛データセットに対する統計的インピュテーション戦略from numpy import meanfrom numpy import stdfrom pandas import read_csvfrom sklearn.Inc.ensemble import RandomForestClassifierfrom sklearn.impute import SimpleImputerfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.pipeline import Pipelinefrom matplotlib import pyplot# load dataseturl = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’dataframe = read_csv(url, header=None, na_values=’?’)# input要素とoutput要素に分割data = dataframe.valuesix = ) if i != 23].X, y = data, data# evaluate each strategy on datasetresults = list()strategies =for s in strategies.X, y = data, data# for strategies.y = data, y = data:# モデリングパイプラインの作成pipeline = Pipeline(steps=)# モデルの評価cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)# results storeresults.append(scores)print(‘>%s %.3f (%.3f)’ % (s, mean(scores), std(scores)))# plot model performance for comparisonpyplot.boxplot(results, labels=strategies, showmeans=True)pyplot.show()例の実行により、反復クロスバリデーションによる馬colicデータの各統計置換戦略を評価することができました。
注意:アルゴリズムや評価手順の確率的性質、または数値精度の違いにより、結果が異なる場合があります。 この例を数回実行し、平均結果を比較することを検討してください。
各戦略の平均精度が途中で報告されます。 その結果、一定値、例えば0を使用すると、約88.1%という最高のパフォーマンスが得られることが示唆され、これは傑出した結果である。
1234>平均 0. “0 “を使用。860 (0.054)>median 0.862 (0. 0.054)065)>most_frequent 0.872 (0.052)>constant 0.881 (0.047)実行終了時に結果のボックスとウィスカープロットが各セットに対して作成されて、結果の分布が比較できるようになります。
定数戦略の精度スコアの分布が、他の戦略よりも優れていることがよくわかります。
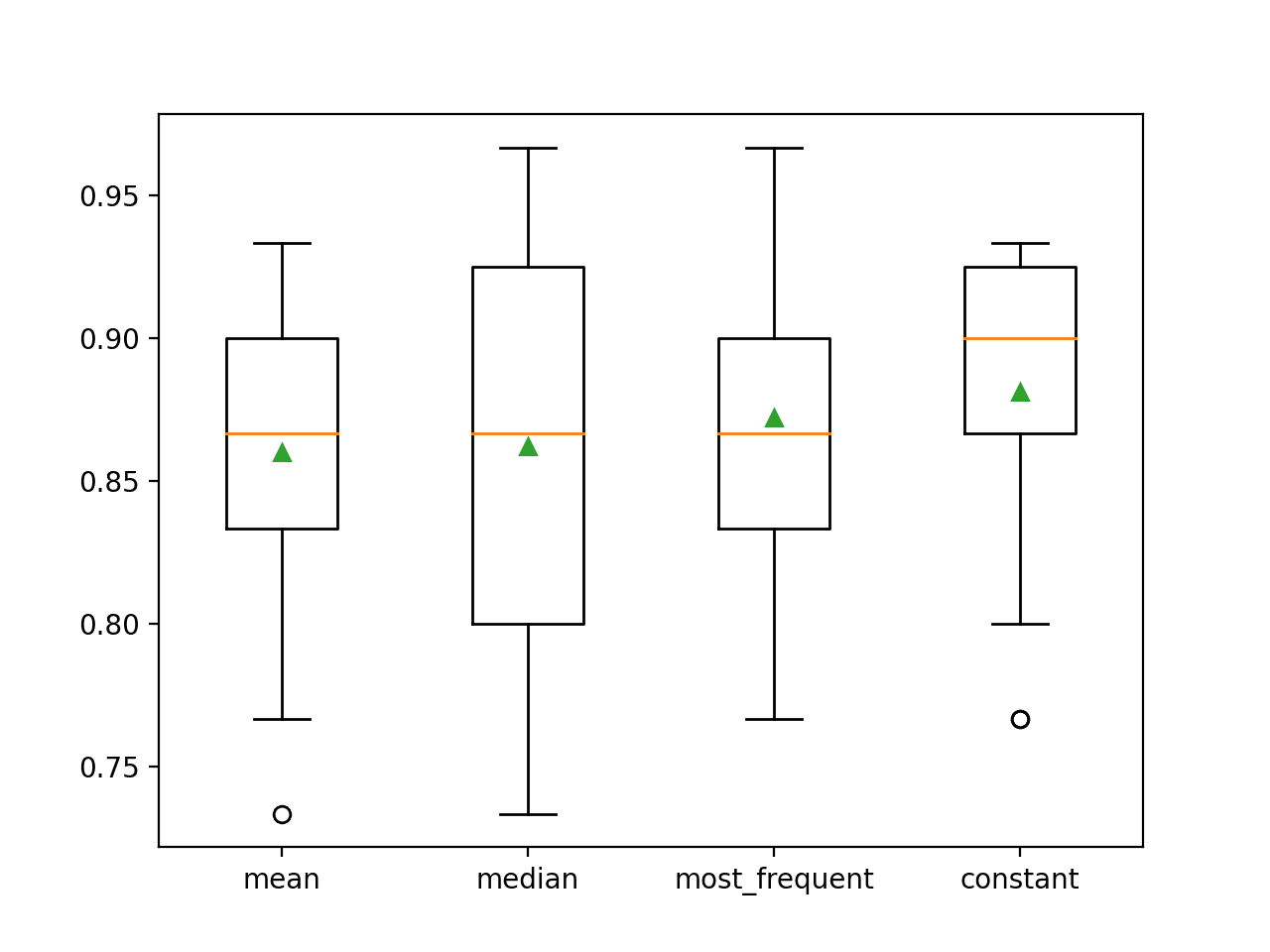
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
constant imputation strategy と random forest algorithm で最終モデリングパイプラインを作って、新しいデータに対して予測したい場合もありますね。
これは、パイプラインを定義し、利用可能なすべてのデータでそれをフィットさせ、次に新しいデータを引数として渡すpredict()関数を呼び出すことで実現できる。
重要なのは、新しいデータの行は、NaN 値を使用して任意の欠損値をマークする必要があることです。
123…# define new datarow =完全な例を以下に列挙します。
1234567891011121314151617181920212223# constant imputation(定数インピュテーション ホースコリックデータセットの戦略と予測from numpy import nanfrom pandas import read_csvfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.impute import SimpleImputerfrom sklearn.pipeline import Pipeline# load dataseturl = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’dataframe = read_csv(url, header=None, na_values=’?’)# split into input and output elementsdata = dataframe.valuesix = ) if i != 23]X, y = data, data# create modeling pipelinepipeline = Pipeline(steps=)# fit the modelpipeline.X, y = model, data# fit the model, y = model, data# fit the model, y = data, data# modeling pipeline.fit(X, y)
# define new datarow =# make a predictionyhat = pipeline.Fit(X)・Y(y)・Y(X)・Y(X)・Y(Y)predict()# summarize predictionprint(‘Predicted Class: %d’ % yhat)例を実行すると、すべての利用可能データでモデリングパイプラインを適合させることができます。
データの新しい行は、NaNでマークされた欠損値で定義され、分類予測が行われます。
1予測したクラスです。 2Further Reading
このセクションでは、さらに深く知りたい場合に、このトピックに関するより多くのリソースを提供します。
関連チュートリアル
- 標準の分類および回帰機械学習データセットの結果
- How to Handle Missing Data with Python
書籍
- Bad Data Handbook, 2012.
- Data Mining.DataMining.DataMining、2012、
DataMining.DataMining.DataMining、2012、
DataMining.DataMining.DataMining、2012、
- Applied Predictive Modeling, 2013.
APIs
- Imputation of missing values, scikit-learn Documentation.
- sklearn.impute.SimpleImputer APIの紹介です。
データセット
- Horse Colic Dataset Description
概要
このチュートリアルでは、機械学習における欠損データへの統計的インプットストラクションの使用方法を発見しました。
具体的には、次のことを学びました:
- 欠損値を NaN 値でマークする必要があり、値の列を計算するために統計的尺度で置き換えることができます。
- 欠損値を持つ CSV 値をロードし、欠損値を NaN 値でマークし、各列の欠損値の数と割合を報告する方法です。
- モデルの評価時や、新しいデータで予測を行うための最終的なモデルのフィッティング時に、データ準備の方法として統計学で欠損値をインピュートする方法
何か質問はありませんか?
下のコメントで質問していただければ、できる限りお答えします。最新のデータ準備のハンドルを握ろう!

Prepare Your Machine Learning Data in Minutes
…(英語)。
Data Preparation for Machine Learningこのチュートリアルでは、
Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction, and moreに関する完全な動作コードとともに自習することができます。…最新のデータ準備技術を
あなたの機械学習プロジェクトに導入する中身を見る
Tweet 共有する