Reinforcement Learning(RL) è uno dei temi di ricerca più caldi nel campo della moderna Intelligenza Artificiale e la sua popolarità sta solo crescendo. Vediamo 5 cose utili da sapere per iniziare con l’RL.
L’apprendimento per rinforzo (RL) è un tipo di tecnica di apprendimento automatico che permette ad un agente di imparare in un ambiente interattivo per tentativi ed errori usando il feedback delle proprie azioni ed esperienze.
Anche se sia l’apprendimento supervisionato che quello di rinforzo usano la mappatura tra input e output, a differenza dell’apprendimento supervisionato dove il feedback fornito all’agente è un insieme corretto di azioni per eseguire un compito, l’apprendimento di rinforzo usa ricompense e punizioni come segnali per comportamenti positivi e negativi.
Rispetto all’apprendimento non supervisionato, l’apprendimento di rinforzo è diverso in termini di obiettivi. Mentre l’obiettivo nell’apprendimento non supervisionato è quello di trovare somiglianze e differenze tra i punti dati, nel caso dell’apprendimento di rinforzo l’obiettivo è quello di trovare un modello di azione adatto che massimizzi la ricompensa cumulativa totale dell’agente. La figura sottostante illustra il ciclo di feedback azione-ricompensa di un generico modello RL.

Come formulare un problema base di Reinforcement Learning?
Alcuni termini chiave che descrivono gli elementi di base di un problema di RL sono:
- Ambiente – Mondo fisico in cui l’agente opera
- Stato – Situazione attuale dell’agente
- Ricompensa – Feedback dall’ambiente
- Politica – Metodo per mappare lo stato dell’agente alle azioni
- Valore – Ricompensa futura che un agente riceverebbe compiendo un’azione in un particolare stato
Un problema RL può essere spiegato meglio attraverso dei giochi. Prendiamo il gioco di PacMan dove l’obiettivo dell’agente (PacMan) è quello di mangiare il cibo nella griglia evitando i fantasmi sulla sua strada. In questo caso, il mondo della griglia è l’ambiente interattivo per l’agente dove agisce. L’agente riceve una ricompensa per aver mangiato il cibo e una punizione se viene ucciso dal fantasma (perde il gioco). Gli stati sono la posizione dell’agente nel mondo della griglia e la ricompensa cumulativa totale è l’agente che vince il gioco.

Per costruire una politica ottimale, l’agente affronta il dilemma di esplorare nuovi stati mentre massimizza la sua ricompensa complessiva allo stesso tempo. Questo è chiamato Exploration vs Exploitation trade-off. Per bilanciare entrambi, la migliore strategia complessiva può comportare sacrifici a breve termine. Pertanto, l’agente dovrebbe raccogliere abbastanza informazioni per prendere la migliore decisione complessiva in futuro.
I processi decisionali di Markov (MDP) sono strutture matematiche per descrivere un ambiente in RL e quasi tutti i problemi RL possono essere formulati utilizzando MDP. Un MDP consiste in un insieme di stati finiti dell’ambiente S, un insieme di possibili azioni A(s) in ogni stato, una funzione di ricompensa con valore reale R(s) e un modello di transizione P(s’, s | a). Tuttavia, è più probabile che gli ambienti del mondo reale non abbiano alcuna conoscenza preliminare delle dinamiche ambientali. I metodi RL senza modello sono utili in questi casi.
Q-learning è un approccio senza modello comunemente usato che può essere usato per costruire un agente PacMan che gioca da solo. Ruota intorno alla nozione di aggiornamento dei valori Q che denota il valore dell’esecuzione dell’azione a nello stato s. La seguente regola di aggiornamento dei valori è il nucleo dell’algoritmo di Q-learning.

Ecco una dimostrazione video di un agente PacMan che usa il Deep Reinforcement Learning.
Q-learning e SARSA (State-Action-Reward-State-Action) sono due algoritmi di RL senza modello comunemente usati. Essi differiscono in termini di strategie di esplorazione, mentre le loro strategie di sfruttamento sono simili. Mentre Q-learning è un metodo off-policy in cui l’agente impara il valore basato sull’azione a* derivata da un’altra politica, SARSA è un metodo on-policy in cui impara il valore basato sulla sua attuale azione a derivata dalla sua attuale politica. Questi due metodi sono semplici da implementare ma mancano di generalità in quanto non hanno la capacità di stimare i valori per gli stati non visti.
Questo può essere superato da algoritmi più avanzati come i Deep Q-Networks(DQNs) che usano reti neurali per stimare i valori Q. Ma i DQN possono solo gestire spazi d’azione discreti e di bassa dimensione.
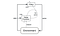
Deep Deterministic Policy Gradient(DDPG) è un algoritmo senza modello, off-policy, actor-critic che affronta questo problema imparando politiche in spazi d’azione continui di alta dimensione. La figura sottostante è una rappresentazione dell’architettura actor-critic.
Quali sono le applicazioni pratiche del Reinforcement Learning?
Poiché, l’RL richiede molti dati, quindi è più applicabile in domini in cui i dati simulati sono facilmente disponibili come il gioco, la robotica.
- L’RL è abbastanza usato nella costruzione di IA per giocare al computer. AlphaGo Zero è il primo programma per computer a sconfiggere un campione del mondo nell’antico gioco cinese del Go. Altri includono giochi ATARI, Backgammon, ecc
- Nella robotica e nell’automazione industriale, la RL è usata per permettere al robot di creare un efficiente sistema di controllo adattivo per se stesso che impara dalla propria esperienza e comportamento. Il lavoro di DeepMind sul Deep Reinforcement Learning per la manipolazione robotica con aggiornamenti asincroni della politica è un buon esempio dello stesso. Guardate questo interessante video dimostrativo.
Altre applicazioni di RL includono motori di riassunto del testo astrattivo, agenti di dialogo (testo, discorso) che possono imparare dalle interazioni dell’utente e migliorare con il tempo, l’apprendimento di politiche di trattamento ottimali nella sanità e agenti basati su RL per il trading azionario online.
Come posso iniziare con il Reinforcement Learning?
Per capire i concetti di base della RL, si può fare riferimento alle seguenti risorse.
- Reinforcement Learning-An Introduction, un libro del padre del Reinforcement Learning- Richard Sutton e del suo consigliere di dottorato Andrew Barto. Una bozza online del libro è disponibile qui.
- Il materiale didattico di David Silver, incluse le lezioni video, è un ottimo corso introduttivo sulla RL.
- Qui c’è un altro tutorial tecnico sulla RL di Pieter Abbeel e John Schulman (Open AI/ Berkeley AI Research Lab).
Per iniziare a costruire e testare agenti RL, le seguenti risorse possono essere utili.
- Questo blog su come addestrare un agente di Rete Neurale ATARI Pong con Policy Gradients dai pixel grezzi di Andrej Karpathy vi aiuterà ad avere il vostro primo agente di Deep Reinforcement Learning attivo e funzionante in sole 130 righe di codice Python.
- DeepMind Lab è una piattaforma open source simile a un gioco in 3D creata per la ricerca AI basata su agenti con ricchi ambienti simulati.
- Project Malmo è un’altra piattaforma di sperimentazione AI per supportare la ricerca fondamentale in AI.
- OpenAI gym è un toolkit per costruire e confrontare algoritmi di apprendimento per rinforzo.