
Prima di iniziare questo viaggio per cercare di imparare l’informatica, c’erano certi termini e frasi che mi facevano venir voglia di scappare nella direzione opposta.
Ma invece di scappare, fingevo di conoscerli, annuendo nelle conversazioni, fingendo di sapere a cosa qualcuno si stesse riferendo anche se la verità era che non ne avevo idea e avevo smesso completamente di ascoltare quando avevo sentito quel Super Scary Computer Science Term™. Nel corso di questa serie, sono riuscito a coprire un sacco di terreno e molti di questi termini sono effettivamente diventati molto meno spaventosi!
C’è uno grande, però, che ho evitato per un po’. Fino ad ora, ogni volta che ho sentito questo termine, mi sono sentito paralizzato. È venuto fuori in conversazioni casuali in incontri e a volte in conferenze. Ogni volta, penso alle macchine che girano e ai computer che sputano fuori stringhe di codice che sono indecifrabili, tranne per il fatto che tutti gli altri intorno a me possono effettivamente decifrarli, quindi in realtà sono solo io che non so cosa sta succedendo (whoops come è successo?!).
Forse non sono l’unico che si è sentito così. Ma suppongo che dovrei dirvi cos’è questo termine, giusto? Beh, preparatevi, perché mi sto riferendo al sempre sfuggente e apparentemente confuso albero della sintassi astratta, o AST in breve. Dopo molti anni di intimidazione, sono entusiasta di poter finalmente smettere di avere paura di questo termine e di capire veramente di cosa diavolo si tratta.
È ora di affrontare a testa alta la radice dell’albero della sintassi astratta – e migliorare il nostro gioco di parsing!
Ogni buona ricerca inizia con una solida base, e la nostra missione di demistificare questa struttura dovrebbe iniziare esattamente allo stesso modo: con una definizione, ovviamente!
Un albero di sintassi astratto (di solito chiamato semplicemente AST) non è altro che una versione semplificata e condensata di un albero di analisi. Nel contesto della progettazione di compilatori, il termine “AST” è usato in modo intercambiabile con albero di sintassi.

Pensiamo spesso agli alberi di sintassi (e a come sono costruiti) in confronto ai loro omologhi parse tree, che ci sono già abbastanza familiari. Sappiamo che gli alberi di parse sono strutture di dati ad albero che contengono la struttura grammaticale del nostro codice; in altre parole, contengono tutte le informazioni sintattiche che appaiono in una “frase” del codice, e derivano direttamente dalla grammatica del linguaggio di programmazione stesso.
Un albero di sintassi astratto, d’altra parte, ignora una quantità significativa delle informazioni sintattiche che un albero di parse altrimenti conterrebbe.
Al contrario, un AST contiene solo le informazioni relative all’analisi del testo sorgente, e salta qualsiasi altro contenuto extra che viene usato durante l’analisi del testo.
Questa distinzione inizia ad avere molto più senso se ci concentriamo sull'”astrattezza” di un AST.
Ricordiamo che un albero di parse è una versione illustrata e pittorica della struttura grammaticale di una frase. In altre parole, possiamo dire che un albero di parse rappresenta esattamente l’aspetto di un’espressione, una frase o un testo. È fondamentalmente una traduzione diretta del testo stesso; prendiamo la frase e trasformiamo ogni piccolo pezzo di essa – dalla punteggiatura alle espressioni ai token – in una struttura dati ad albero. Rivela la sintassi concreta di un testo, che è il motivo per cui viene anche chiamato albero di sintassi concreta, o CST. Usiamo il termine concreto per descrivere questa struttura perché è una copia grammaticale del nostro codice, token per token, in formato albero.
Ma cosa rende qualcosa concreto rispetto a qualcosa di astratto? Beh, un albero sintattico astratto non ci mostra esattamente l’aspetto di un’espressione, come fa un albero di parsing.

Piuttosto, un albero sintattico astratto ci mostra i pezzi “importanti” – le cose che ci interessano veramente, che danno significato alla nostra “frase” di codice. Gli alberi della sintassi ci mostrano i pezzi significativi di un’espressione, o la sintassi astratta del nostro testo sorgente. Quindi, in confronto agli alberi di sintassi concreti, queste strutture sono rappresentazioni astratte del nostro codice (e in qualche modo, meno esatte), che è esattamente il modo in cui hanno ottenuto il loro nome.
Ora che abbiamo capito la distinzione tra queste due strutture di dati e i diversi modi in cui possono rappresentare il nostro codice, vale la pena fare una domanda: dove si inserisce un albero di sintassi astratto nel compilatore? Per prima cosa, ricordiamoci tutto quello che sappiamo sul processo di compilazione come lo conosciamo finora.

Diciamo di avere un testo sorgente super breve e dolce, che assomiglia a questo: 5 + (1 x 12).
Ricordiamo che la prima cosa che accade nel processo di compilazione è la scansione del testo, un lavoro eseguito dallo scanner, che ha come risultato la scomposizione del testo nelle sue parti più piccole possibili, che sono chiamate lessemi. Questa parte sarà indipendente dalla lingua, e ci ritroveremo con la versione spogliata del nostro testo sorgente.
Poi, questi stessi lessemi vengono passati al lexer/tokenizer, che trasforma queste piccole rappresentazioni del nostro testo sorgente in token, che saranno specifici della nostra lingua. I nostri token avranno un aspetto simile a questo: . Lo sforzo congiunto dello scanner e del tokenizer costituisce l’analisi lessicale della compilazione.
Poi, una volta che il nostro input è stato tokenizzato, i suoi token risultanti sono passati al nostro parser, che poi prende il testo sorgente e ne costruisce un albero di parsing. L’illustrazione qui sotto esemplifica come appare il nostro codice tokenizzato, in formato albero di parsa.
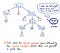
Il lavoro di trasformare i token in un albero di parsa è chiamato anche parsing, ed è noto come fase di analisi della sintassi. La fase di analisi della sintassi dipende direttamente dalla fase di analisi lessicale; quindi l’analisi lessicale deve sempre venire prima nel processo di compilazione, perché il parser del nostro compilatore può fare il suo lavoro solo dopo che il tokenizer ha fatto il suo lavoro!
Possiamo pensare alle parti del compilatore come a dei buoni amici, che dipendono l’uno dall’altro per assicurarsi che il nostro codice sia correttamente trasformato da un testo o da un file in un albero di parsing.
Ma torniamo alla nostra domanda originale: dove si inserisce l’albero sintattico astratto in questo gruppo di amici? Bene, per rispondere a questa domanda, aiuta a capire la necessità di un AST in primo luogo.
Condensare un albero in un altro
Ok, così ora abbiamo due alberi da tenere dritti nella nostra testa. Avevamo già un albero di parse, e ora c’è un’altra struttura di dati da imparare! E apparentemente, questa struttura dati AST è solo un albero di parsing semplificato. Quindi, perché ne abbiamo bisogno? Qual è il suo scopo?
Bene, diamo un’occhiata al nostro albero di parse, che ne dite?
Sappiamo già che gli alberi di parse rappresentano il nostro programma nelle sue parti più distinte; infatti, questo è il motivo per cui lo scanner e il tokenizer hanno il compito così importante di scomporre la nostra espressione nelle sue parti più piccole!
Cosa significa rappresentare effettivamente un programma nelle sue parti più distinte?
Come si è scoperto, a volte tutte le parti distinte di un programma in realtà non ci sono sempre molto utili.
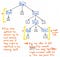
Diamo un’occhiata all’illustrazione mostrata qui, che rappresenta la nostra espressione originale, 5 + (1 x 12), in formato parse tree. Se osserviamo da vicino questo albero con occhio critico, vedremo che ci sono alcuni casi in cui un nodo ha esattamente un figlio, che sono anche chiamati nodi a successore singolo, poiché hanno solo un nodo figlio che deriva da loro (o un “successore”).
Nel caso del nostro esempio di albero di parsing, i nodi monosuccessore hanno un nodo padre di un Expression, o Exp, che hanno un singolo successore di qualche valore, come 5, 1, o 12. Tuttavia, i nodi padre Exp qui non stanno effettivamente aggiungendo qualcosa di valore per noi, vero? Possiamo vedere che contengono nodi figli di token/terminali, ma non ci interessa molto il nodo padre “espressione”; tutto quello che vogliamo sapere è qual è l’espressione?
Il nodo padre non ci dà alcuna informazione aggiuntiva una volta che abbiamo analizzato il nostro albero. Invece, quello che ci interessa veramente è il singolo nodo figlio, singolo successore. Infatti, questo è il nodo che ci dà l’informazione importante, la parte che è significativa per noi: il numero e il valore stesso! Considerando il fatto che questi nodi padre sono piuttosto inutili per noi, diventa ovvio che questo albero di parse è una specie di verbosità.
Tutti questi nodi figlio singolo sono piuttosto superflui per noi, e non ci aiutano affatto. Quindi, sbarazziamocene!
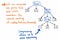
Se comprimiamo i nodi a successore singolo nel nostro albero di parse, ci ritroveremo con una versione più compressa della stessa esatta struttura. Guardando l’illustrazione qui sopra, vedremo che stiamo ancora mantenendo la stessa esatta nidificazione di prima, e i nostri nodi/token/terminali appaiono ancora nel posto corretto all’interno dell’albero. Ma siamo riusciti a snellirlo un po’.
E possiamo tagliare anche altre parti del nostro albero. Per esempio, se guardiamo il nostro albero di parsing nella sua forma attuale, vedremo che c’è una struttura a specchio al suo interno. La sotto-espressione di (1 x 12) è annidata all’interno delle parentesi (), che sono token a pieno titolo.
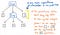
Tuttavia, queste parentesi non ci aiutano molto una volta che abbiamo il nostro albero. Sappiamo già che 1 e 12 sono argomenti che verranno passati all’operazione di moltiplicazione x, quindi le parentesi non ci dicono molto a questo punto. Infatti, potremmo comprimere ulteriormente il nostro albero di parse e liberarci di questi nodi foglia superflui.
Una volta che abbiamo compresso e semplificato il nostro albero di parse e ci siamo liberati della “polvere” sintattica estranea, ci ritroviamo con una struttura che sembra visibilmente diversa a questo punto. Quella struttura è, infatti, il nostro nuovo e tanto atteso amico: l’albero della sintassi astratta.

L’immagine sopra illustra esattamente la stessa espressione del nostro albero di parse: 5 + (1 x 12). La differenza è che ha astratto l’espressione dalla sintassi concreta. Non vediamo più le parentesi () in questo albero, perché non sono necessarie. Allo stesso modo, non vediamo non-terminali come Exp, poiché abbiamo già capito qual è l'”espressione”, e siamo in grado di estrarre il valore che ci interessa veramente – per esempio, il numero 5.
Questo è esattamente il fattore che distingue un AST da un CST. Sappiamo che un albero sintattico astratto ignora una quantità significativa di informazioni sintattiche che un albero di parsing contiene, e salta il “contenuto extra” che viene usato nel parsing. Ma ora possiamo vedere esattamente come questo accade!

Ora che abbiamo condensato un nostro albero di parse, saremo molto più bravi a cogliere alcuni dei pattern che distinguono un AST da un CST.
Ci sono alcuni modi in cui un albero sintattico astratto differisce visivamente da un albero di parse:
- Un AST non conterrà mai dettagli sintattici, come virgole, parentesi e punti e virgola (a seconda, naturalmente, della lingua).
- Un AST avrà versioni collassate di ciò che altrimenti apparirebbe come nodi a successore singolo; non conterrà mai “catene” di nodi con un solo figlio.
- Infine, qualsiasi token operatore (come
+,-,x, e/) diventerà nodi interni (genitori) nell’albero, piuttosto che le foglie che terminano in un albero di analisi.
Visualmente, un AST apparirà sempre più compatto di un albero di analisi, poiché è, per definizione, una versione compressa di un albero di analisi, con meno dettagli sintattici.
Sarebbe logico, quindi, che se un AST è una versione compattata di un albero di parse, possiamo davvero creare un albero di sintassi astratto solo se abbiamo le cose per costruire un albero di parse per cominciare!
Questo è, infatti, come l’albero di sintassi astratto si inserisce nel più ampio processo di compilazione. Un AST ha una connessione diretta con gli alberi di parsing che abbiamo già imparato a conoscere, mentre allo stesso tempo si basa sul lexer per fare il suo lavoro prima che un AST possa mai essere creato.

L’albero sintattico astratto viene creato come risultato finale della fase di analisi sintattica. Il parser, che è davanti e al centro come il “personaggio” principale durante l’analisi della sintassi, può o non può sempre generare un parse tree, o CST. A seconda del compilatore stesso, e di come è stato progettato, il parser può passare direttamente alla costruzione di un albero della sintassi, o AST. Ma il parser genererà sempre un AST come suo output, non importa se crea un albero di parsing nel mezzo, o quanti passaggi potrebbe aver bisogno di fare per farlo.
Anatomia di un AST
Ora che sappiamo che l’albero sintattico astratto è importante (ma non necessariamente intimidatorio!), possiamo iniziare a sezionarlo un po’ di più. Un aspetto interessante di come l’AST è costruito ha a che fare con i nodi di questo albero.
L’immagine sottostante esemplifica l’anatomia di un singolo nodo all’interno di un albero di sintassi astratta.
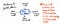
Noi noteremo che questo nodo è simile ad altri che abbiamo visto prima in quanto contiene alcuni dati (un token e il suo value). Tuttavia, contiene anche alcuni puntatori molto specifici. Ogni nodo in un AST contiene riferimenti al suo prossimo nodo fratello, così come al suo primo nodo figlio.
Per esempio, la nostra semplice espressione di 5 + (1 x 12) potrebbe essere costruita in un’illustrazione visualizzata di un AST, come quella sotto.

Possiamo immaginare che la lettura, l’attraversamento, o “l’interpretazione” di questo AST possa iniziare dai livelli più bassi dell’albero, risalendo fino a costruire un valore o un ritorno result alla fine.
Può anche aiutare vedere una versione codificata dell’output di un parser per aiutare a completare le nostre visualizzazioni. Possiamo appoggiarci a vari strumenti e usare parser preesistenti per vedere un rapido esempio di come potrebbe apparire la nostra espressione quando viene eseguita attraverso un parser. Qui sotto c’è un esempio del nostro testo sorgente, 5 + (1 * 12), eseguito attraverso Esprima, un parser ECMAScript, e il suo albero di sintassi astratta risultante, seguito da una lista dei suoi token distinti.
In questo formato, possiamo vedere l’annidamento dell’albero se guardiamo gli oggetti annidati. Noteremo che i valori che contengono 1 e 12 sono rispettivamente i figli left e right di un’operazione madre, *. Vedremo anche che l’operazione di moltiplicazione (*) costituisce il sottoalbero destro dell’intera espressione stessa, che è il motivo per cui è annidata all’interno del più grande oggetto BinaryExpression, sotto la chiave "right". Allo stesso modo, il valore di 5 è il singolo "left" figlio dell’oggetto più grande BinaryExpression.

L’aspetto più intrigante dell’albero sintattico astratto è, tuttavia, il fatto che anche se sono così compatti e puliti, non sono sempre una struttura dati facile da provare a costruire. Infatti, costruire un AST può essere piuttosto complesso, a seconda della lingua con cui il parser ha a che fare!
La maggior parte dei parser di solito costruisce un albero di parsing (CST) e poi lo converte in un formato AST, perché questo a volte può essere più facile – anche se significa più passi, e in generale, più passaggi attraverso il testo sorgente. Costruire un CST è in realtà abbastanza facile una volta che il parser conosce la grammatica della lingua che sta cercando di analizzare. Non ha bisogno di fare alcun lavoro complicato per capire se un token è “significativo” o meno; invece, prende esattamente ciò che vede, nell’ordine specifico in cui lo vede, e lo sputa fuori in un albero.
D’altra parte, ci sono alcuni parser che cercheranno di fare tutto questo come un processo a passo singolo, saltando direttamente alla costruzione di un albero sintattico astratto.
Costruire direttamente un AST può essere difficile, poiché il parser deve non solo trovare i token e rappresentarli correttamente, ma anche decidere quali token sono importanti per noi e quali no.
Nella progettazione dei compilatori, l’AST finisce per essere super importante per più di una ragione. Sì, può essere difficile da costruire (e probabilmente facile da rovinare), ma è anche l’ultimo e definitivo risultato delle fasi di analisi lessicale e sintattica combinate! Le fasi di analisi lessicale e sintattica sono spesso chiamate insieme la fase di analisi, o il front-end del compilatore.

Si può pensare all’albero sintattico astratto come al “progetto finale” del front-end del compilatore. È la parte più importante, perché è l’ultima cosa che il front-end deve mostrare a se stesso. Il termine tecnico per questo si chiama rappresentazione del codice intermedio o IR, perché diventa la struttura dati che viene utilizzata in ultima analisi dal compilatore per rappresentare un testo sorgente.
Un albero di sintassi astratto è la forma più comune di IR, ma anche, a volte la più incompresa. Ma ora che lo capiamo un po’ meglio, possiamo iniziare a cambiare la nostra percezione di questa struttura spaventosa! Speriamo che ora sia un po’ meno intimidatoria per noi.
Risorse
Ci sono un sacco di risorse là fuori sugli AST, in una varietà di lingue. Sapere da dove iniziare può essere difficile, specialmente se stai cercando di imparare di più. Qui di seguito ci sono alcune risorse per principianti che approfondiscono molto di più i dettagli senza essere troppo invadenti. Happy asbtracting!
- L’AST contro l’albero di parse, Professor Charles N. Fischer
- Qual è la differenza tra alberi di parse e alberi di sintassi astratti? StackOverflow
- Alberi di sintassi astratti vs. concreti, Eli Bendersky
- Alberi di sintassi astratti, Professor Stephen A. Edwards
- Alberi di sintassi astratti & Parsing top-down, Professor Konstantinos (Kostis) Sagonas
- Analisi lessicale e sintattica dei linguaggi di programmazione, Chris Northwood
- AST Explorer, Felix Kling