Ultimo aggiornamento del 18 agosto 2020
I dataset possono avere valori mancanti, e questo può causare problemi a molti algoritmi di apprendimento automatico.
Come tale, è buona pratica identificare e sostituire i valori mancanti per ogni colonna nei dati di input prima di modellare il compito di predizione. Questo è chiamato imputazione dei dati mancanti, o imputazione in breve.
Un approccio popolare per l’imputazione dei dati è quello di calcolare un valore statistico per ogni colonna (come una media) e sostituire tutti i valori mancanti per quella colonna con la statistica. E’ un approccio popolare perché la statistica è facile da calcolare usando il set di dati di addestramento e perché spesso risulta in buone prestazioni.
In questo tutorial, scoprirai come usare strategie di imputazione statistica per i dati mancanti nel machine learning.
Dopo aver completato questo tutorial, saprai:
- I valori mancanti devono essere contrassegnati con valori NaN e possono essere sostituiti con misure statistiche per calcolare la colonna di valori.
- Come caricare un valore CSV con valori mancanti e marcare i valori mancanti con valori NaN e riportare il numero e la percentuale di valori mancanti per ogni colonna.
- Come imputare i valori mancanti con le statistiche come metodo di preparazione dei dati quando si valutano i modelli e quando si adatta un modello finale per fare previsioni su nuovi dati.
Inizia il tuo progetto con il mio nuovo libro Data Preparation for Machine Learning, che include tutorial passo-passo e i file del codice sorgente Python per tutti gli esempi.
Iniziamo.
- Aggiornato a giugno/2020: Cambiata la colonna usata per la predizione negli esempi.

Imputazione statistica dei valori mancanti nell’apprendimento automatico
Foto di Bernal Saborio, alcuni diritti riservati.
Panoramica del tutorial
Questo tutorial è diviso in tre parti; esse sono:
- Imputazione statistica
- Imputazione statistica con SimpleImputer
- Trasformazione dei dati con SimpleImputer
- SimpleImputer e valutazione del modello
- Confronto di diverse statistiche imputate
- Trasformazione semplice dell’elaboratore quando si fa una previsione
Imputazione statistica
Un dataset può avere valori mancanti.
Sono righe di dati in cui uno o più valori o colonne in quella riga non sono presenti. I valori possono mancare completamente o possono essere marcati con un carattere o un valore speciale, come un punto interrogativo “?”.
Questi valori possono essere espressi in molti modi. Li ho visti apparire come niente, una stringa vuota, la stringa esplicita NULL o non definita o N/A o NaN, e il numero 0, tra gli altri. Non importa come appaiono nel vostro set di dati, sapere cosa aspettarsi e controllare che i dati corrispondano a tale aspettativa ridurrà i problemi quando inizierete a usare i dati.
– Page 10, Bad Data Handbook, 2012.
I valori potrebbero mancare per molte ragioni, spesso specifiche del dominio del problema, e potrebbero includere ragioni come misure corrotte o indisponibilità dei dati.
Possono verificarsi per una serie di motivi, come il malfunzionamento delle apparecchiature di misurazione, i cambiamenti nel progetto sperimentale durante la raccolta dei dati e la collazione di diversi set di dati simili ma non identici.
– Pagina 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
La maggior parte degli algoritmi di apprendimento automatico richiede valori di input numerici, e che un valore sia presente per ogni riga e colonna in un set di dati. Come tale, i valori mancanti possono causare problemi per gli algoritmi di apprendimento automatico.
Come tale, è comune identificare i valori mancanti in un set di dati e sostituirli con un valore numerico. Questo è chiamato imputazione dei dati, o imputazione dei dati mancanti.
Un approccio semplice e popolare all’imputazione dei dati comporta l’utilizzo di metodi statistici per stimare un valore per una colonna da quei valori che sono presenti, quindi sostituire tutti i valori mancanti nella colonna con la statistica calcolata.
È semplice perché le statistiche sono veloci da calcolare ed è popolare perché spesso si dimostra molto efficace.
Le statistiche comuni calcolate includono:
- Il valore medio della colonna.
- Il valore mediano della colonna.
- Il valore della modalità della colonna.
- Un valore costante.
Ora che abbiamo familiarità con i metodi statistici per l’imputazione dei valori mancanti, diamo un’occhiata a un set di dati con valori mancanti.
Vuoi iniziare con la preparazione dei dati?
Prendi subito il mio corso crash gratuito di 7 giorni via email (con codice di esempio).
Clicca per iscriverti e ottieni anche una versione gratuita del corso in PDF Ebook.
Scarica il tuo mini-corso GRATUITO
Horse Colic Dataset
Il dataset horse colic descrive le caratteristiche mediche dei cavalli con coliche e se sono vivi o morti.
Ci sono 300 righe e 26 variabili di input con una variabile di output. Si tratta di un compito di predizione di classificazione binaria che consiste nel predire 1 se il cavallo è sopravvissuto e 2 se il cavallo è morto.
Ci sono molti campi che potremmo selezionare per predire in questo dataset. In questo caso, prevederemo se il problema era chirurgico o meno (indice di colonna 23), rendendolo un problema di classificazione binaria.
Il dataset ha numerosi valori mancanti per molte delle colonne in cui ogni valore mancante è contrassegnato da un carattere punto interrogativo (“?”).
Di seguito un esempio di righe del dataset con valori mancanti contrassegnati.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Puoi saperne di più sul dataset qui:
- Horse Colic Dataset
- Horse Colic Dataset Description
Non è necessario scaricare il dataset perché lo scaricheremo automaticamente negli esempi lavorati.
Marcare i valori mancanti con un valore NaN (non un numero) in un dataset caricato usando Python è una buona pratica.
Possiamo caricare il dataset usando la funzione read_csv() Pandas e specificare “na_values” per caricare valori di ‘?’ come mancanti, contrassegnati da un valore NaN.
|
1
2
3
4
|
…
# caricare dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=Nessuno, na_values=’?’)
|
Una volta caricati, possiamo esaminare i dati caricati per confermare che i valori “?” sono contrassegnati come NaN.
|
1
2
3
|
…
# riassumiamo le prime righe
print(dataframe.head())
|
Possiamo quindi enumerare ogni colonna e riportare il numero di righe con valori mancanti per la colonna.
|
1
2
3
4
5
6
7
|
…
# riassume il numero di righe con valori mancanti per ogni colonna
per i in range(dataframe.shape):
# conta il numero di righe con valori mancanti
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Mancante: %d (%.1f%%)’ % (i, n_miss, perc))
|
Collegando il tutto, l’esempio completo di caricamento e riassunto del dataset è elencato qui sotto.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# riassume il dataset delle coliche di cavallo
from pandas import read_csv
# carica il dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# riassume le prime righe
print(dataframe.head())
# riassumere il numero di righe con valori mancanti per ogni colonna
for i in range(dataframe.shape):
# conta il numero di righe con valori mancanti
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Missing: %d (%.1f%%)’ % (i, n_miss, perc))
|
L’esecuzione dell’esempio carica prima il set di dati e riassume le prime cinque righe.
Si può vedere che i valori mancanti che erano contrassegnati da un carattere “?” sono stati sostituiti con valori NaN.
Poi possiamo vedere la lista di tutte le colonne del dataset e il numero e la percentuale di valori mancanti.
Possiamo vedere che alcune colonne (per esempio gli indici di colonna 1 e 2) non hanno valori mancanti e altre colonne (per esempio gli indici di colonna 15 e 21) hanno molti o addirittura la maggioranza di valori mancanti.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Missing: 1 (0,3%)
> 1, Mancante: 0 (0,0%)
> 2, Mancante: 0 (0,0%)
> 3, Mancante: 60 (20,0%)
> 4, Mancante: 24 (8,0%)
> 5, Mancante: 58 (19,3%)
> 6, Mancante: 56 (18,7%)
> 7, Mancante: 69 (23,0%)
> 8, Mancante: 47 (15,7%)
> 9, Mancante: 32 (10,7%)
> 10, Mancante: 55 (18.3%)
> 11, Mancante: 44 (14.7%)
> 12, Mancante: 56 (18.7%)
> 13, Mancante: 104 (34.7%)
> 14, Mancante: 106 (35,3%)
> 15, Mancante: 247 (82.3%)
> 16, Mancante: 102 (34.0%)
> 17, Mancante: 118 (39,3%)
> 18, Mancante: 29 (9,7%)
> 19, Mancante: 33 (11,0%)
> 20, Mancante: 165 (55,0%)
> 21, Mancante: 198 (66,0%)
> 22, Mancante: 1 (0,3%)
> 23, Mancante: 0 (0,0%)
> 24, Mancante: 0 (0,0%)
> 25, Mancante: 0 (0,0%)
> 26, Mancante: 0 (0,0%)
> 27, Mancante: 0 (0,0%)
|
Ora che abbiamo familiarità con il dataset delle coliche di cavallo che ha valori mancanti, vediamo come possiamo usare l’imputazione statistica.
Statistical Imputation With SimpleImputer
La libreria di apprendimento automatico scikit-learn fornisce la classe SimpleImputer che supporta l’imputazione statistica.
In questa sezione, esploreremo come utilizzare efficacemente la classe SimpleImputer.
Trasformazione dei dati SimpleImputer
Il SimpleImputer è una trasformazione dei dati che viene prima configurata in base al tipo di statistica da calcolare per ogni colonna, ad es.ad es. media.
|
1
2
3
|
…
# define imputer
imputer = SimpleImputer(strategy=’mean’)
|
Poi l’imputer viene adattato su un set di dati per calcolare la statistica per ogni colonna.
|
1
2
3
|
…
# fit sul dataset
imputer.fit(X)
|
Il fit imputer viene quindi applicato a un dataset per creare una copia del dataset con tutti i valori mancanti per ogni colonna sostituiti con un valore statistico.
|
1
2
3
|
…
# trasforma il dataset
Xtrans = imputer.transform(X)
|
Possiamo dimostrare il suo utilizzo sul dataset delle coliche dei cavalli e confermare che funziona riassumendo il numero totale di valori mancanti nel dataset prima e dopo la trasformazione.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# imputazione statistica trasformazione per il set di dati sulle coliche dei cavalli
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split in input e output elements
data = dataframe.values
ix = ) if i != 23]
X, y = dati, dati
# stampa il totale mancante
print(‘Missing: %d’ % sum(isnan(X).flatten())
# definire imputer
imputer = SimpleImputer(strategy=’mean’)
# fit sul dataset
imputer.fit(X)
# trasforma il dataset
Xtrans = imputer.transform(X)
# stampa il totale mancante
print(‘Missing: %d’ % sum(isnan(Xtrans).flatten()))
|
L’esecuzione dell’esempio carica prima il dataset e riporta il numero totale di valori mancanti nel dataset come 1.605.
La trasformazione viene configurata, adattata ed eseguita e il nuovo dataset risultante non ha valori mancanti, confermando che è stata eseguita come ci aspettavamo.
Ogni valore mancante è stato sostituito con il valore medio della sua colonna.
|
1
2
|
Missing: 1605
Mancante: 0
|
Semplice valutazione del modello e del computer
E’ una buona pratica valutare i modelli di apprendimento automatico su un set di dati usando k-fold cross-validation.
Per applicare correttamente l’imputazione statistica dei dati mancanti ed evitare la perdita di dati, è necessario che le statistiche calcolate per ogni colonna siano calcolate solo sul dataset di addestramento, quindi applicate ai set di training e test per ogni piega del dataset.
Se stiamo usando il ricampionamento per selezionare i valori dei parametri di tuning o per stimare le prestazioni, l’imputazione dovrebbe essere incorporata all’interno del ricampionamento.
– Page 42, Applied Predictive Modeling, 2013.
Questo può essere ottenuto creando una pipeline di modellazione dove il primo passo è l’imputazione statistica, poi il secondo passo è il modello. Questo può essere ottenuto utilizzando la classe Pipeline.
Per esempio, la Pipeline qui sotto utilizza un SimpleImputer con una strategia ‘media’, seguita da un modello random forest.
|
1
2
3
4
5
|
…
# definire la pipeline di modellazione
modello = RandomForestClassifier()
imputer = SimpleImputer(strategia=’media’)
pipeline = Pipeline(passi=)
|
Possiamo valutare il set di dati imputati in media e il modello di foresta casualeimputati e la pipeline di modellazione della foresta casuale per il set di dati sulle coliche dei cavalli con una ripetuta convalida incrociata di 10 volte.
L’esempio completo è elencato di seguito.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# valutare imputazione media e foresta casuale per il set di dati sulle coliche dei cavalli
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split in input e output elements
data = dataframe.values
ix = ) if i != 23]
X, y = dati, dati
# definire pipeline di modellazione
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# definire valutazione modello
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# valutare il modello
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(‘Mean Accuracy: %.3f (%.3f)’ % (mean(scores), std(scores))
|
L’esecuzione dell’esempio applica correttamente l’imputazione dei dati ad ogni piega della procedura di convalida incrociata.
Nota: I vostri risultati possono variare data la natura stocastica dell’algoritmo o della procedura di valutazione, o differenze nella precisione numerica. Considerate di eseguire l’esempio più volte e confrontate il risultato medio.
La pipeline viene valutata utilizzando tre ripetizioni della convalida incrociata di 10 volte e riporta la precisione media di classificazione sul set di dati come circa l’86.3 per cento, che è un buon punteggio.
|
1
|
Mean Accuracy: 0.863 (0.054)
|
Confronto di diverse statistiche imputate
Come facciamo a sapere che usare una strategia statistica ‘media’ è buona o migliore per questo set di dati?
La risposta è che non lo sappiamo e che è stata scelta arbitrariamente.
Possiamo progettare un esperimento per testare ogni strategia statistica e scoprire quale funziona meglio per questo set di dati, confrontando le strategie media, mediana, modalità (più frequente) e costante (0). L’accuratezza media di ogni approccio può quindi essere confrontata.
L’esempio completo è elencato di seguito.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# confrontare strategie di imputazione statistica per il set di dati sulle coliche di cavallo
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# diviso in elementi di input e output
dati = dataframe.values
ix = ) if i != 23]
X, y = dati, dati
# valutare ogni strategia sul dataset
risultati = lista()
strategie =
per s in strategie:
# crea la pipeline di modellazione
pipeline = Pipeline(steps=)
# valuta il modello
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# store results
results.append(scores)
print(‘>%s %.3f (%.3f)’ % (s, mean(scores), std(scores))
# tracciare le prestazioni del modello per il confronto
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
L’esecuzione dell’esempio valuta ogni strategia di imputazione statistica sul set di dati sulle coliche dei cavalli usando una validazione incrociata ripetuta.
Nota: I vostri risultati possono variare a causa della natura stocastica dell’algoritmo o della procedura di valutazione, o delle differenze nella precisione numerica. Considera di eseguire l’esempio alcune volte e confronta il risultato medio.
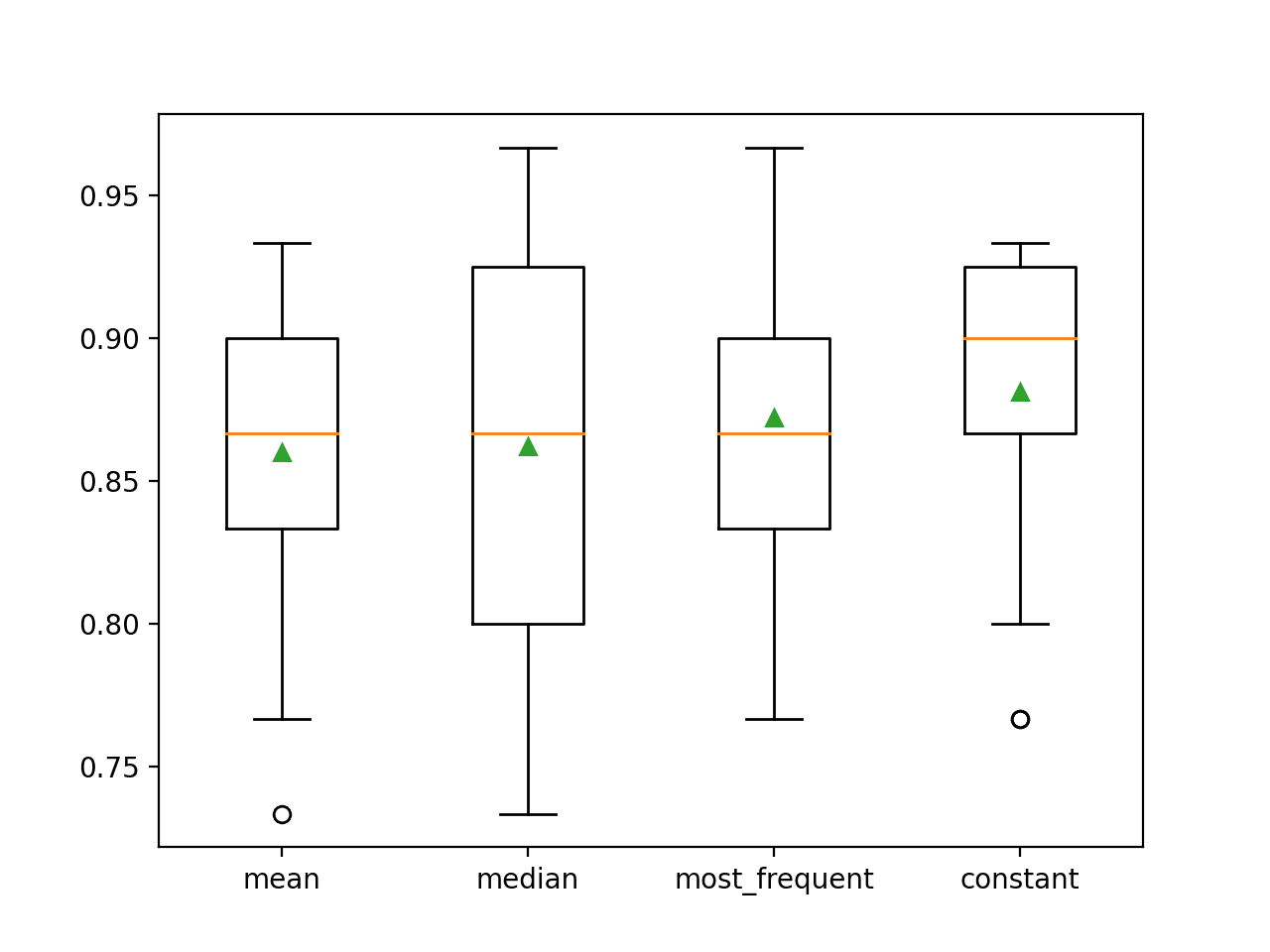
L’accuratezza media di ogni strategia è riportata lungo il percorso. I risultati suggeriscono che utilizzando un valore costante, ad esempio 0, si ottiene la migliore prestazione di circa l’88,1%, che è un risultato eccezionale.
|
1
2
3
4
|
>media 0.860 (0.054)
>media 0.862 (0.065)
>most_frequent 0.872 (0.052)
>constant 0.881 (0.047)
|
Alla fine della corsa, viene creato un box and whisker plot per ogni set di risultati, permettendo di confrontare la distribuzione dei risultati.
Si vede chiaramente che la distribuzione dei punteggi di precisione per la strategia costante è migliore delle altre strategie.
Potremmo creare una pipeline di modellazione finale con la strategia di imputazione costante e l’algoritmo random forest, quindi fare una previsione per i nuovi dati.
Questo può essere ottenuto definendo la pipeline e adattandola a tutti i dati disponibili, poi chiamando la funzione predict() passando i nuovi dati come argomento.
Importante, la riga dei nuovi dati deve marcare qualsiasi valore mancante usando il valore NaN.
|
1
2
3
|
…
# definire nuovi dati
riga =
|
L’esempio completo è elencato sotto.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# imputazione costante strategia e predizione per il set di dati sulle colichette
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# diviso in elementi di input e output
dati = dataframe.values
ix = ) if i != 23]
X, y = dati, dati
# crea la pipeline di modellazione
pipeline = Pipeline(steps=)
# adatta il modello
pipeline.fit(X, y)
# definisce nuovi dati
row =
# fa una predizione
yhat = pipeline.predict()
# riassume la predizione
print(‘Classe predetta: %d’ % yhat)
|
L’esempio si adatta alla pipeline di modellazione su tutti i dati disponibili.
Viene definita una nuova riga di dati con i valori mancanti contrassegnati da NaN e viene fatta una previsione di classificazione.
|
1
|
Classe prevista: 2
|
Altre letture
Questa sezione fornisce altre risorse sull’argomento se vuoi approfondire.
Tutorial correlati
- Risultati per dataset standard di classificazione e regressione per l’apprendimento automatico
- Come gestire i dati mancanti con Python
Libri
- Manuale dei dati cattivi, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
APIs
- Imputazione dei valori mancanti, scikit-learn Documentation.
- sklearn.impute.SimpleImputer API.
Dataset
- Horse Colic Dataset
- Horse Colic Dataset Descrizione
Summary
In questo tutorial, hai scoperto come usare strategie di imputazione statistica per i dati mancanti nel machine learning.
In particolare, hai imparato:
- I valori mancanti devono essere marcati con valori NaN e possono essere sostituiti con misure statistiche per calcolare la colonna di valori.
- Come caricare un valore CSV con valori mancanti e marcare i valori mancanti con valori NaN e riportare il numero e la percentuale di valori mancanti per ogni colonna.
- Come imputare i valori mancanti con le statistiche come metodo di preparazione dei dati quando si valutano i modelli e quando si adatta un modello finale per fare previsioni su nuovi dati.
Hai qualche domanda?
Fai le tue domande nei commenti qui sotto e farò del mio meglio per risponderti.
Get a Handle on Modern Data Preparation!

Prepara i tuoi dati di Machine Learning in pochi minuti
…con poche righe di codice python
Scopri come nel mio nuovo Ebook:
Preparazione dei dati per l’apprendimento automatico
Fornisce tutorial autodidattici con codice funzionante completo su:
Selezione delle caratteristiche, RFE, pulizia dei dati, trasformazione dei dati, scalatura, riduzione della dimensionalità, e molto altro…
Porta le moderne tecniche di preparazione dei dati ai
tuoi progetti di apprendimento automatico
Vedi cosa c’è dentro