
Se vuoi imparare di più in Python, segui il corso gratuito di DataCamp Intro to Python for Data Science.
Tutti voi avete visto dei dataset. A volte sono piccoli, ma spesso, a volte, sono di dimensioni tremendamente grandi. Diventa molto impegnativo elaborare i set di dati che sono molto grandi, almeno abbastanza significativi da causare un collo di bottiglia nell’elaborazione.
Quindi, cosa rende questi set di dati così grandi? Beh, sono le caratteristiche. Maggiore è il numero di caratteristiche, più grandi saranno i set di dati. Beh, non sempre. Troverete set di dati in cui il numero di caratteristiche è molto elevato, ma non contengono così tante istanze. Ma questo non è il punto della discussione qui. Quindi, ci si potrebbe chiedere, con un computer commodity in mano, come elaborare questo tipo di dataset senza menare il can per l’aia.
Spesso, in un dataset ad alta dimensione, rimangono alcune caratteristiche del tutto irrilevanti, insignificanti e poco importanti. Si è visto che il contributo di questi tipi di caratteristiche è spesso inferiore alla modellazione predittiva rispetto alle caratteristiche critiche. Possono anche avere un contributo nullo. Queste caratteristiche causano una serie di problemi che a loro volta impediscono il processo di modellazione predittiva efficiente –
- Inutile allocazione di risorse per queste caratteristiche.
- Queste caratteristiche agiscono come un rumore per cui il modello di apprendimento automatico può eseguire terribilmente male.
- Il modello automatico richiede più tempo per essere addestrato.
Quindi, qual è la soluzione qui? La soluzione più economica è Feature Selection.
Feature Selection è il processo di selezione delle caratteristiche più significative da un dato set di dati. In molti casi, la selezione delle caratteristiche può anche migliorare le prestazioni di un modello di apprendimento automatico.
Sembra interessante, vero?
Hai avuto un’introduzione informale alla selezione delle caratteristiche e alla sua importanza nel mondo della scienza dei dati e dell’apprendimento automatico. In questo post coprirai:
- Introduzione alla feature selection e comprensione della sua importanza
- Differenza tra feature selection e riduzione della dimensionalità
- Diversi tipi di metodi di feature selection
- Implementazione di diversi metodi di feature selection con scikit-learn
Introduzione alla selezione delle caratteristiche
La selezione delle caratteristiche è anche conosciuta come selezione delle variabili o degli attributi.
Essenzialmente, è il processo di selezione delle più importanti/rilevanti.
Comprendere l’importanza della selezione delle caratteristiche
L’importanza della selezione delle caratteristiche può essere meglio riconosciuta quando si ha a che fare con un set di dati che contiene un gran numero di caratteristiche. Questo tipo di set di dati è spesso indicato come un set di dati ad alta dimensionalità. Ora, con questa alta dimensionalità, arrivano un sacco di problemi come – questa alta dimensionalità aumenterà significativamente il tempo di addestramento del vostro modello di apprendimento automatico, può rendere il vostro modello molto complicato che a sua volta può portare a Overfitting.
Spesso in un set di caratteristiche ad alta dimensionalità, rimangono diverse caratteristiche che sono ridondanti, cioè queste caratteristiche non sono altro che estensioni delle altre caratteristiche essenziali. Queste caratteristiche ridondanti non contribuiscono efficacemente alla formazione del modello. Quindi, chiaramente, c’è la necessità di estrarre le caratteristiche più importanti e più rilevanti per un set di dati al fine di ottenere le prestazioni di modellazione predittiva più efficaci.
“L’obiettivo della selezione delle variabili è triplice: migliorare le prestazioni di predizione dei predittori, fornire predittori più veloci e convenienti, e fornire una migliore comprensione del processo sottostante che ha generato i dati.”
Introduzione alla selezione delle variabili e delle caratteristiche
Ora cerchiamo di capire la differenza tra riduzione della dimensionalità e selezione delle caratteristiche.
A volte, la selezione delle caratteristiche viene confusa con la riduzione della dimensionalità. Ma sono diversi. La selezione delle caratteristiche è diversa dalla riduzione della dimensionalità. Entrambi i metodi tendono a ridurre il numero di attributi nel set di dati, ma un metodo di riduzione della dimensionalità lo fa creando nuove combinazioni di attributi (a volte noto come trasformazione delle caratteristiche), mentre i metodi di selezione delle caratteristiche includono ed escludono gli attributi presenti nei dati senza modificarli.
Alcuni esempi di metodi di riduzione della dimensionalità sono la Principal Component Analysis, la Singular Value Decomposition, la Linear Discriminant Analysis, ecc.
Lasciate che vi riassuma l’importanza della selezione delle caratteristiche:
- Permette all’algoritmo di apprendimento automatico di allenarsi più velocemente.
- Riduce la complessità di un modello e lo rende più facile da interpretare.
- Migliora la precisione di un modello se viene scelto il giusto sottoinsieme.
- Riduce l’overfitting.
Nella prossima sezione, studierai i diversi tipi di metodi generali di selezione delle caratteristiche – metodi filtro, metodi wrapper e metodi embedded.
Metodi filtro
L’immagine seguente descrive meglio i metodi di selezione delle caratteristiche basati sul filtro:

Fonte immagine: Analytics Vidhya
Il metodo del filtro si basa sull’unicità generale dei dati da valutare e sceglie un sottoinsieme di caratteristiche, senza includere alcun algoritmo di estrazione. Il metodo del filtro usa il criterio esatto di valutazione che include distanza, informazione, dipendenza e coerenza. Il metodo del filtro usa i criteri principali della tecnica di classificazione e usa il metodo di ordinamento di rango per la selezione delle variabili. La ragione per usare il metodo di classificazione è la semplicità, produrre caratteristiche eccellenti e rilevanti. Il metodo di classificazione filtrerà le caratteristiche irrilevanti prima dell’inizio del processo di classificazione.
I metodi di filtro sono generalmente utilizzati come una fase di pre-elaborazione dei dati. La selezione delle caratteristiche è indipendente da qualsiasi algoritmo di apprendimento automatico. Le caratteristiche vengono classificate sulla base di punteggi statistici che tendono a determinare la correlazione delle caratteristiche con la variabile di risultato. La correlazione è un termine fortemente contestuale, e varia da lavoro a lavoro. Potete fare riferimento alla seguente tabella per definire i coefficienti di correlazione per diversi tipi di dati (in questo caso continui e categorici).

Fonte immagine: Analytics Vidhya
Alcuni esempi di alcuni metodi di filtro includono il test del Chi-quadrato, il guadagno di informazioni e i punteggi dei coefficienti di correlazione.
Prossimo, vedrete i metodi Wrapper.
Metodi wrapper
Come i metodi di filtro, lasciate che vi dia lo stesso tipo di info-grafica che vi aiuterà a capire meglio i metodi wrapper:
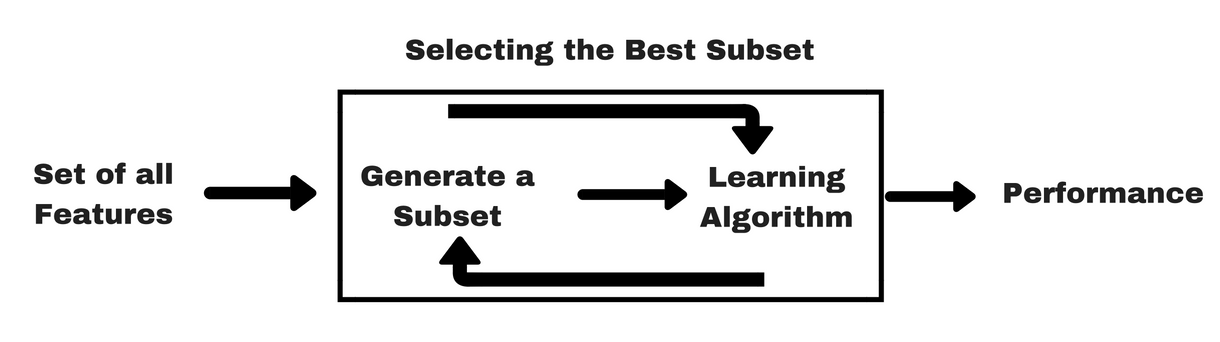
Fonte immagine: Analytics Vidhya
Come potete vedere nell’immagine qui sopra, un metodo wrapper ha bisogno di un algoritmo di apprendimento automatico e usa le sue prestazioni come criterio di valutazione. Questo metodo cerca una caratteristica che è più adatta all’algoritmo di apprendimento automatico e mira a migliorare le prestazioni di estrazione. Per valutare le caratteristiche, l’accuratezza predittiva usata per i compiti di classificazione e la bontà del cluster è valutata usando il clustering.
Alcuni esempi tipici di metodi wrapper sono la selezione avanzata delle caratteristiche, l’eliminazione delle caratteristiche all’indietro, l’eliminazione ricorsiva delle caratteristiche, ecc.
- Selezione avanzata: La procedura inizia con un insieme vuoto di caratteristiche. La migliore delle caratteristiche originali è determinata e aggiunta all’insieme ridotto. Ad ogni iterazione successiva, il migliore degli attributi originali rimanenti viene aggiunto all’insieme.
- Eliminazione a ritroso: La procedura inizia con l’insieme completo di attributi. Ad ogni passo, rimuove il peggiore attributo rimasto nell’insieme.
- Combinazione di selezione in avanti ed eliminazione all’indietro: I metodi di selezione in avanti e di eliminazione all’indietro possono essere combinati in modo che, ad ogni passo, la procedura selezioni l’attributo migliore e rimuova il peggiore tra gli attributi rimanenti.
- Eliminazione ricorsiva delle caratteristiche: L’eliminazione ricorsiva delle caratteristiche esegue una ricerca avida per trovare il sottoinsieme di caratteristiche più performante. Crea iterativamente i modelli e determina la caratteristica migliore o peggiore ad ogni iterazione. Costruisce i modelli successivi con le caratteristiche rimaste fino a quando tutte le caratteristiche sono esplorate. Poi classifica le caratteristiche in base all’ordine della loro eliminazione. Nel caso peggiore, se un set di dati contiene un numero N di caratteristiche RFE farà una ricerca avida per 2N combinazioni di caratteristiche.
Basta così!
Ora studiamo i metodi incorporati.
Metodi incorporati
I metodi incorporati sono iterativi nel senso che si prendono cura di ogni iterazione del processo di formazione del modello ed estraggono attentamente quelle caratteristiche che contribuiscono maggiormente alla formazione per una particolare iterazione. I metodi di regolarizzazione sono i metodi incorporati più comunemente usati che penalizzano una caratteristica data una soglia di coefficiente.
Questo è il motivo per cui i metodi di regolarizzazione sono anche chiamati metodi di penalizzazione che introducono vincoli aggiuntivi nell’ottimizzazione di un algoritmo predittivo (come un algoritmo di regressione) che distorcono il modello verso una minore complessità (meno coefficienti).
Esempi di algoritmi di regolarizzazione sono il LASSO, Elastic Net, Ridge Regression, ecc.
Differenza tra metodi filtro e wrapper
Bene, a volte può confondere la distinzione tra metodi filtro e wrapper in termini di funzionalità. Diamo un’occhiata a quali punti differiscono l’uno dall’altro.
- I metodi filtro non incorporano un modello di apprendimento automatico per determinare se una caratteristica è buona o cattiva, mentre i metodi wrapper utilizzano un modello di apprendimento automatico e addestrano la caratteristica per decidere se è essenziale o meno.
- I metodi filtro sono molto più veloci rispetto ai metodi wrapper poiché non implicano l’addestramento dei modelli. D’altra parte, i metodi wrapper sono computazionalmente costosi, e nel caso di insiemi di dati massicci, i metodi wrapper non sono il metodo di selezione delle caratteristiche più efficace da considerare.
- I metodi filtro possono fallire nel trovare il miglior sottoinsieme di caratteristiche in situazioni in cui non ci sono abbastanza dati per modellare la correlazione statistica delle caratteristiche, ma i metodi wrapper possono sempre fornire il miglior sottoinsieme di caratteristiche grazie alla loro natura esaustiva.
- Utilizzare le caratteristiche dai metodi wrapper nel vostro modello finale di apprendimento automatico può portare all’overfitting in quanto i metodi wrapper addestrano già i modelli di apprendimento automatico con le caratteristiche e ciò influisce sul vero potere di apprendimento. Ma le caratteristiche dai metodi filtro non porteranno all’overfitting nella maggior parte dei casi
Finora avete studiato l’importanza della selezione delle caratteristiche, capito la sua differenza con la riduzione della dimensionalità. Hai anche coperto vari tipi di metodi di selezione delle caratteristiche. Fin qui, tutto bene!
Ora, vediamo alcune trappole in cui si può incorrere durante la selezione delle caratteristiche:
Considerazioni importanti
Avrai già capito il valore della selezione delle caratteristiche in una pipeline di apprendimento automatico e il tipo di servizi che fornisce se integrata. Ma è molto importante capire esattamente dove dovreste integrare la selezione delle caratteristiche nella vostra pipeline di apprendimento automatico.
In parole povere, dovreste includere la fase di selezione delle caratteristiche prima di fornire i dati al modello per l’addestramento, specialmente quando state usando metodi di stima della precisione come la convalida incrociata. Questo assicura che la selezione delle caratteristiche venga eseguita sulla piega dei dati subito prima che il modello venga addestrato. Ma se si esegue la selezione delle caratteristiche prima per preparare i dati, poi si esegue la selezione del modello e l’addestramento sulle caratteristiche selezionate, allora sarebbe un errore.
Se si esegue la selezione delle caratteristiche su tutti i dati e poi la convalida incrociata, allora i dati di test in ogni piega della procedura di convalida incrociata sono stati utilizzati anche per scegliere le caratteristiche, e questo tende a distorcere le prestazioni del vostro modello di apprendimento automatico.
Basta con le teorie! Passiamo subito a un po’ di codifica.
Un caso di studio in Python
Per questo caso di studio, userete il dataset Pima Indians Diabetes. La descrizione del set di dati può essere trovata qui.
Il set di dati corrisponde a compiti di classificazione su cui è necessario prevedere se una persona ha il diabete sulla base di 8 caratteristiche.
Ci sono un totale di 768 osservazioni nel set di dati. Il tuo primo compito è quello di caricare il dataset in modo da poter procedere. Ma prima di questo importiamo le dipendenze necessarie, di cui avrete bisogno. Puoi importare le altre man mano che vai avanti.
import pandas as pdimport numpy as npOra che le dipendenze sono importate, carichiamo il dataset degli indiani Pima in un oggetto Dataframe con l’aiuto della libreria Pandas.
data = pd.read_csv("diabetes.csv")Il dataset è caricato con successo nell’oggetto Dataframe. Ora, diamo un’occhiata ai dati.
data.head()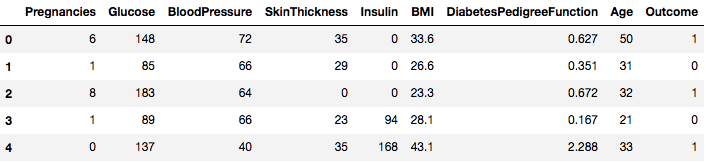
Così potete vedere 8 diverse caratteristiche etichettate nei risultati di 1 e 0 dove 1 sta per l’osservazione ha il diabete, e 0 denota l’osservazione non ha il diabete. Il set di dati è noto per avere valori mancanti. In particolare, ci sono osservazioni mancanti per alcune colonne che sono contrassegnate da un valore zero. Si può dedurre questo dalla definizione di quelle colonne, ed è poco pratico avere un valore zero non valido per quelle misure, ad es, zero per l’indice di massa corporea o la pressione sanguigna non è valido.
Ma per questo tutorial, si utilizzerà direttamente la versione preelaborata del dataset.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Hai caricato i dati in un oggetto DataFrame chiamato dataframe ora.
Convertiamo l’oggetto DataFrame in un array NumPy per ottenere un calcolo più veloce. Inoltre, separiamo i dati in variabili separate in modo che le caratteristiche e le etichette siano separate.
array = dataframe.valuesX = arrayY = arrayMeraviglioso! Hai preparato i tuoi dati.
Prima di tutto, implementerai un test statistico Chi-quadrato per caratteristiche non negative per selezionare 4 delle migliori caratteristiche dal set di dati. Avete già visto che il test Chi-quadrato appartiene alla classe dei metodi di filtraggio. Se qualcuno è curioso di conoscere gli interni del Chi-Squared, questo video fa un ottimo lavoro.
La libreria scikit-learn fornisce la classe SelectKBest che può essere utilizzata con una suite di diversi test statistici per selezionare un numero specifico di caratteristiche, in questo caso, è il Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Hai importato le librerie per eseguire gli esperimenti. Ora, vediamo in azione.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretazione:
Puoi vedere i punteggi per ogni attributo e i 4 attributi scelti (quelli con i punteggi più alti): plas, test, massa ed età. Questi punteggi vi aiuteranno ulteriormente a determinare le migliori caratteristiche per l’addestramento del vostro modello.
P.S.: La prima riga indica i nomi delle caratteristiche. Per la pre-elaborazione del set di dati, i nomi sono stati codificati numericamente.
Poi, implementerete Recursive Feature Elimination che è un tipo di metodo di selezione delle caratteristiche wrapper.
La Recursive Feature Elimination (o RFE) funziona rimuovendo ricorsivamente gli attributi e costruendo un modello su quegli attributi che rimangono.
Utilizza l’accuratezza del modello per identificare quali attributi (e combinazioni di attributi) contribuiscono maggiormente a prevedere l’attributo di destinazione.
Puoi saperne di più sulla classe RFE nella documentazione di scikit-learn.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionUtilizzerai RFE con il classificatore Logistic Regression per selezionare le prime 3 caratteristiche. La scelta dell’algoritmo non ha molta importanza, purché sia abile e coerente.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Si può vedere che RFE ha scelto le prime 3 caratteristiche come preg, mass, e pedi.
Queste sono segnate come True nell’array di supporto e segnate con una scelta “1” nell’array di classificazione. Questo, a sua volta, indica la forza di queste caratteristiche.
Prossimamente userete la regressione Ridge che è fondamentalmente una tecnica di regolarizzazione e anche una tecnica di selezione delle caratteristiche incorporata.
Questo articolo vi dà una spiegazione eccellente sulla regressione Ridge. Assicuratevi di controllarlo.
# First things firstfrom sklearn.linear_model import RidgeProssimo, userete la regressione Ridge per determinare il coefficiente R2.
Inoltre, controllate la documentazione ufficiale di scikit-learn sulla regressione Ridge.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Per capire meglio i risultati della regressione Ridge, implementerete una piccola funzione helper che vi aiuterà a stampare i risultati in modo migliore in modo da poterli interpretare facilmente.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Poi, passerete i termini dei coefficienti del modello Ridge a questa piccola funzione e vedrete cosa succede.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Si possono individuare tutti i termini dei coefficienti aggiunti alle variabili caratteristiche. Vi aiuterà di nuovo a scegliere le caratteristiche più essenziali. Sotto ci sono alcuni punti che dovreste tenere a mente mentre applicate la regressione Ridge:
- È anche conosciuta come L2-Regularization.
- Per le caratteristiche correlate, significa che tendono ad avere coefficienti simili.
- Le caratteristiche con coefficienti negativi non contribuiscono molto. Ma in uno scenario più complesso dove avete a che fare con molte caratteristiche, allora questo punteggio vi aiuterà sicuramente nel processo decisionale finale di selezione delle caratteristiche.
Bene, questo conclude la sezione del caso studio. I metodi che avete implementato nella sezione precedente vi aiuteranno a capire le caratteristiche di un particolare set di dati in modo completo. Permettetemi di darvi alcuni punti critici su queste tecniche:
- La selezione delle caratteristiche è essenzialmente una parte della pre-elaborazione dei dati che è considerata la parte più dispendiosa in termini di tempo di qualsiasi pipeline di apprendimento automatico.
- Queste tecniche vi aiuteranno ad avvicinarvi in un modo più sistematico e favorevole all’apprendimento automatico. Sarete in grado di interpretare le caratteristiche in modo più accurato.
Per finire!
In questo post, avete coperto uno degli argomenti statistici più studiati e ben ricercati, cioè la selezione delle caratteristiche. Hai anche familiarizzato con le sue diverse varianti e le hai usate per vedere quali caratteristiche in un set di dati sono importanti.
Puoi portare avanti questo tutorial fondendo una misura di correlazione nel metodo wrapper e vedere come si comporta. Nel corso dell’azione, potreste finire per creare il vostro meccanismo di selezione delle caratteristiche. Questo è il modo in cui si stabiliscono le basi per la vostra piccola ricerca. I ricercatori stanno anche usando vari principi di soft computing per eseguire la selezione. Questo è di per sé un intero campo di studio e ricerca. Inoltre, dovresti provare gli algoritmi di selezione delle caratteristiche esistenti su vari set di dati e trarre le tue conclusioni.
Perché questi metodi tradizionali di selezione delle caratteristiche sono ancora validi?
Sì, questa domanda è ovvia. Perché ci sono architetture di reti neurali (per esempio le CNN) che sono abbastanza capaci di estrarre le caratteristiche più significative dai dati, ma anche questo ha un limite. Usare una CNN per un normale set di dati tabulari che non ha proprietà specifiche (le proprietà che un’immagine tipica possiede come le proprietà di transizione, i bordi, le proprietà posizionali, i contorni, etc.) non è la decisione più saggia da prendere. Inoltre, quando si hanno dati limitati e risorse limitate, addestrare una CNN su normali set di dati tabulari potrebbe trasformarsi in un completo spreco. Quindi, in situazioni come questa, i metodi che hai studiato ti torneranno sicuramente utili.
Queste sono alcune risorse se vuoi approfondire l’argomento:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection: Workshop sulle prospettive statistiche e di ottimizzazione
- Selezione delle caratteristiche: Problem statement and uses
- Using genetic algorithms for feature selection in Data Analytics
Di seguito i riferimenti che sono stati utilizzati per scrivere questo tutorial.
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- Un’introduzione alla selezione delle caratteristiche
- Articolo di Analytics Vidhya sulla selezione delle caratteristiche
- Modello gerarchico e misto – Corso DataCamp
- Selezione delle caratteristiche per l’apprendimento automatico in Python
- Rilevazione degli outlier nei dati di flusso con metodi di MachineLearning e selezione delle caratteristiche
- S. Visalakshi e V. Radha, “Una revisione della letteratura delle tecniche di selezione delle caratteristiche e delle applicazioni: Review of feature selection in data mining,” 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.