Da: Derek Colley | Aggiornato: 2014-01-29 | Commenti (5) | Correlati: Altre >funzioni – Sistema
Problema
Si sta cercando di recuperare un campione casuale da un set di risultati di una query SQL Server. Forse state cercando un campione rappresentativo di dati da un grande database di clienti; forse state cercando alcune medie, o un’idea del tipo di dati che avete in mano. SELECT TOP N non è sempre l’ideale, poiché i dati anomali appaiono spesso all’inizio e alla fine dei set di dati, specialmente se ordinati alfabeticamente o per qualche valore scalare. Allo stesso modo potreste aver usato TABLESAMPLE, ma ha dei limiti soprattutto con insiemi di dati piccoli o distorti. Forse il vostro capo vi ha chiesto una selezione casuale di 100 nomi di clienti e località; oppure state partecipando a una verifica e avete bisogno di recuperare un campione casuale di dati per l’analisi. Come realizzereste questo compito? Controllate questo suggerimento per saperne di più.
Soluzione
Questo suggerimento vi mostrerà come usare TABLESAMPLE in T-SQL per recuperare campioni di dati pseudo-casuali, e parlerà delle caratteristiche interne di TABLESAMPLE e di dove non è appropriato. Vi mostrerà anche un metodo alternativo – un metodo matematico che usa NEWID() accoppiato con CHECKSUM e un operatore bitwise, notato da Microsoft nell’articolo TABLESAMPLE TechNet. Parleremo un po’ del campionamento statistico in generale (le differenze tra casuale, sistematico e stratificato) con degli esempi, e daremo un’occhiata a come vengono campionate le statistiche SQL come esempio, e le opzioni che possiamo usare per sovrascrivere questo campionamento. Dopo aver letto questo suggerimento, dovreste avere un apprezzamento dei benefici del campionamento rispetto all’uso di metodi come TOP N e sapere come applicare almeno un metodo per ottenere questo in SQL Server.
Impostazione
Per questo suggerimento, userò un set di dati contenente una colonna INT di identità (per stabilire il grado di casualità nella selezione delle righe) e altre colonne riempite con dati pseudocasuali di diversi tipi di dati, per simulare (vagamente) i dati reali in una tabella. Potete usare il codice T-SQL qui sotto per impostarlo. Dovrebbe richiedere solo un paio di minuti per essere eseguito ed è testato su SQL Server 2012 Developer Edition.
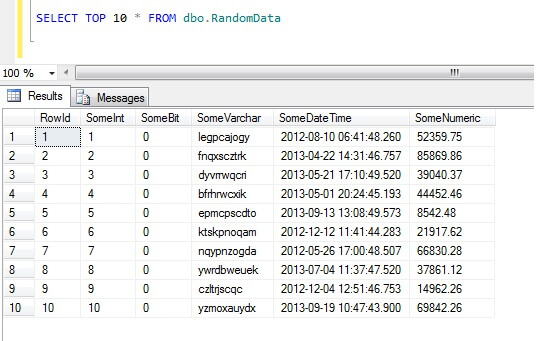
Selezionando le prime 10 righe di dati si ottiene questo risultato (solo per darvi un’idea della forma dei dati).Per inciso, questo è un pezzo di codice generale che ho creato per generare dati casuali ogni volta che ne avevo bisogno – sentitevi liberi di prenderlo e aumentarlo/sfruttare a vostro piacimento!
Come non campionare i dati in SQL Server
Ora abbiamo i nostri campioni di dati, pensiamo ai modi peggiori per ottenere un campione. Nel database di AdventureWorks, esiste una tabella chiamata Person.Address. Prendiamo un campione prendendo i primi 10 risultati, in nessun ordine particolare:
SELECT TOP 10 * FROM Person.Address
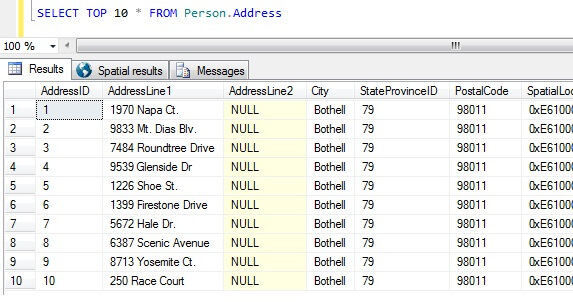
Andando solo da questo campione, possiamo vedere che tutte le persone restituite vivono a Bothell, e condividono il codice postale 98011. Questo perché i risultati sono stati specificati per essere restituiti senza un ordine particolare, ma di fatto sono stati restituiti in ordine della colonna AddressID. Si noti che questo NON è un comportamento garantito per i dati heap in particolare – si veda questa citazione da BOL:
“Di solito i dati sono inizialmente memorizzati nell’ordine in cui le righe sono inserite nella tabella, ma il motore di database può spostare i dati nell’heap per memorizzare le righe in modo efficiente; quindi l’ordine dei dati non può essere previsto. Per garantire l’ordine delle righe restituite da un heap, è necessario utilizzare la clausola ORDER BY.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Prendendo questo set di risultati, una persona non informata sulla natura della tabella potrebbe concludere che tutti i loro clienti vivono a Bothell.
Tipi di campionamento dei dati in SQL Server
Quanto sopra è chiaramente falso, quindi abbiamo bisogno di un modo migliore di campionamento. Che ne dite di prendere un campione a intervalli regolari in tutta la tabella?
Questo dovrebbe restituire 47 righe:
Fin qui, tutto bene. Abbiamo preso una riga a intervalli regolari in tutto il nostro set di dati e restituito uno spaccato statistico – o no? Non necessariamente. Non dimenticate che l’ordine non è garantito. Potremmo trarre una o due conclusioni su questi dati. Aggreghiamo i dati per illustrarli. Eseguite nuovamente lo snippet di codice qui sopra, ma cambiate il blocco SELECT finale come segue:
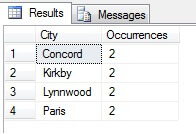
Nel mio esempio potete vedere che da un conteggio totale di più di 19.000 righe nella tabella Person.Address, ho campionato circa 1/4% delle righe e quindi posso concludere che (nel mio esempio), Concord, Kirkby, Lynnwood e Paris hanno il maggior numero di residenti e inoltre sono ugualmente popolati. Accurato? Sciocchezze, naturalmente:
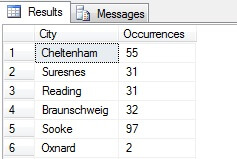
Come potete vedere, nessuno dei miei quattro era effettivamente tra i primi quattro posti dove vivere, come giudicato da questa tabella. Non solo i dati del campione erano troppo piccoli, ma ho aggregato questo minuscolo campione e ho cercato di raggiungere una conclusione da esso. Questo significa che il mio set di risultati è statisticamente insignificante – in realtà, dimostrare la significatività statistica è uno dei maggiori oneri di prova quando si presentano riassunti statistici (o dovrebbe esserlo) e una delle principali cadute di molte infografiche popolari e dei datagrammi guidati dal marketing.
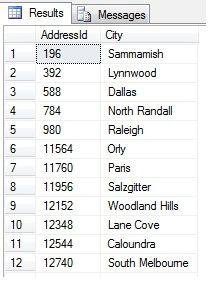
Quindi, il campionamento in questo modo (chiamato campionamento sistematico) è efficace, ma solo per una popolazione statisticamente significativa. Ci sono fattori come la periodicità e la proporzione che possono rovinare un campione – vediamo la proporzione in azione prendendo un campione di 10 città dalla tabella Person.Address, usando il seguente codice, che ottiene una lista distinta di città dalla tabella Person.Address, poi seleziona 10 città da quella lista usando un campionamento sistematico:
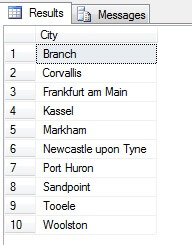
Sembra un buon campione, giusto? Ora contrapponiamolo a un campione di città NON-distinte elencate in ordine crescente, cioè ogni nesima città, dove n è il numero totale di righe diviso per 10. Questa misura tiene conto della popolazione del campione:
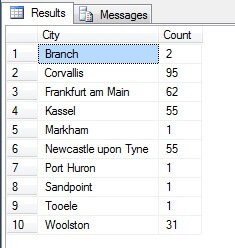
I dati restituiti sono completamente diversi – non per caso, ma per presentazione di un campione rappresentativo. Si noti che questa lista, sulla quale ho incluso i conteggi di ogni città nella tabella di origine per delineare quanto la popolazione giochi un ruolo nella selezione dei dati, include le prime quattro città più popolate del campione, che (se si considera una lista ordinata non distinta) è la rappresentazione più giusta. Non è necessariamente la migliore rappresentazione per le tue esigenze, quindi fai attenzione quando scegli il tuo metodo di campionamento statistico.
Altri metodi di campionamento
Campionamento a cluster – questo è il caso in cui la popolazione da campionare è divisa in cluster, o sottoinsiemi, poi ognuno di questi sottoinsiemi è determinato in modo casuale per essere incluso o meno nell’insieme dei risultati di uscita. Se incluso, ogni membro di quel sottoinsieme viene restituito nell’insieme dei risultati. Vedi TABLESAMPLE qui sotto per un esempio di questo.
Campionamento sproporzionato – questo è come il campionamento stratificato, dove i membri dei sottogruppi sono selezionati per rappresentare l’intero gruppo, ma invece di essere in proporzione, ci può essere un numero diverso di membri di ogni gruppo selezionati per equalizzare la rappresentazione di ogni gruppo. Cioè, date le città in Person.Address nell’esempio della sezione precedente, il primo set di risultati era sproporzionato perché non teneva conto della popolazione, ma il secondo set di risultati era proporzionato perché rappresentava il numero di voci di città nella tabella Person.Address. Questo tipo di campionamento è infatti utile se una particolare categoria è sottorappresentata nell’insieme di dati, e la proporzione non è importante (per esempio, 100 clienti casuali da 100 città casuali stratificate per città – le città nel sottoinsieme avrebbero bisogno di una normalizzazione – si potrebbe usare un campionamento sproporzionato).
SQL Server Random Data with TABLESAMPLE
QL Server è dotato di un metodo di campionamento dei dati. Vediamolo in azione. Usate il seguente codice per restituire circa 100 righe (se restituisce 0 righe, rieseguite – ve lo spiegherò tra un momento) di dati da dbo.RandomData che abbiamo definito prima.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
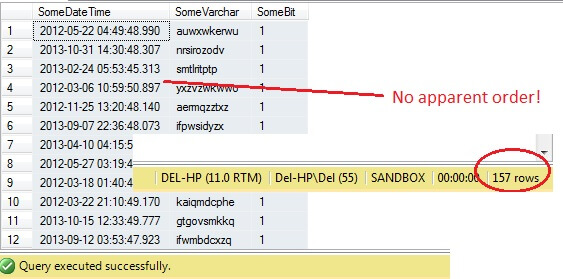
Fin qui tutto bene, giusto? Aspetta – non possiamo vedere la colonna Id. Includiamo questo e rieseguiamo:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
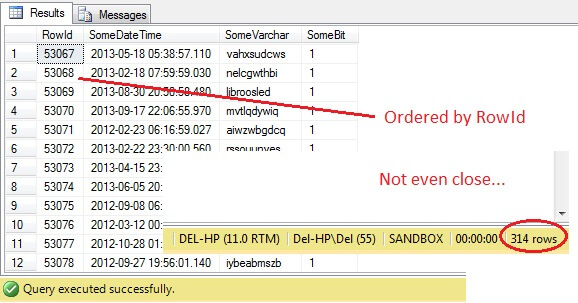
Oh caro – TABLESAMPLE ha selezionato una fetta di dati, ma non è casuale – il RowId mostra una fetta chiaramente delineata con un valore minimo e uno massimo. Inoltre, non ha nemmeno restituito esattamente 100 righe. Cosa sta succedendo?
TABLESAMPLE usa il modificatore implicito SYSTEM. Questo modificatore, attivo di default e una specifica ANSI-SQL, cioè non opzionale, prenderà ogni pagina di 8KB su cui risiede la tabella e deciderà se includere o meno tutte le righe di quella pagina che sono in quella tabella nel campione prodotto, in base alla percentuale o alle N ROWS passate. Quindi, una tabella che risiede su molte pagine, cioè ha grandi righe di dati, dovrebbe restituire un campione più randomizzato poiché ci saranno più pagine nel campione. Non funziona per un esempio come il nostro, dove i dati sono scalari e piccoli e risiedono su poche pagine – se un qualsiasi numero di pagine non riesce a fare il taglio, questo può alterare significativamente il campione in uscita. Questo è il difetto di TABLESAMPLE – non funziona bene per dati ‘piccoli’ e non tiene conto della distribuzione dei dati sulle pagine. Quindi la disposizione dei dati sulle pagine è in definitiva responsabile del campione restituito da questo metodo.
Questo vi suona familiare? Si tratta essenzialmente di un campionamento a grappolo, in cui tutti i membri (righe) nei gruppi selezionati (cluster) sono rappresentati nel set di risultati.
Proviamolo su una grande tabella per sottolineare il punto della non scalabilità inversa. Per prima cosa identifichiamo la tabella più grande nel database di AdventureWorks. Useremo un rapporto standard per questo – usando SSMS, clicchiamo con il tasto destro sul database AdventureWorks2012, andiamo su Reports -> Standard Reports -> Disk Usage by Top Tables. Ordina per Dati (KB) cliccando sull’intestazione della colonna (potresti volerlo fare due volte per un ordine decrescente). Vedrai il rapporto qui sotto.
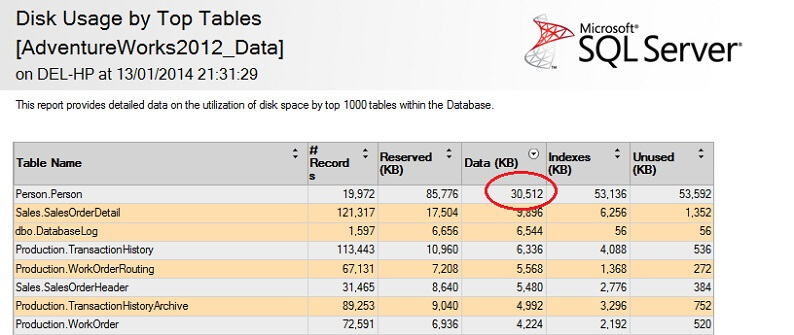
Ho cerchiato la cifra interessante – la tabella Person. Person consuma 30.5MB di dati ed è la tabella più grande (per dati, non per numero di record). Proviamo invece a prendere un campione da questa tabella:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
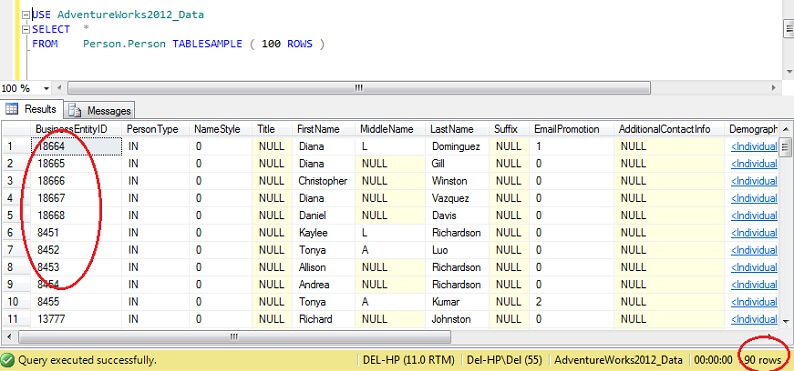
Si può vedere che siamo molto più vicini a 100 righe, ma, cosa fondamentale, non sembra esserci molto clustering sulla chiave primaria (anche se ce n’è un po’, dato che ci sono più di 1 riga per pagina).
Di conseguenza, TABLESAMPLE è buono per i grandi dati, e diventa catastroficamente peggiore quanto più piccolo è il set di dati. Questo non va bene per noi quando campioniamo da dati stratificati o dati clusterizzati, dove prendiamo molti campioni da piccoli gruppi o sottoinsiemi di dati per poi aggregarli. Vediamo allora un metodo alternativo.
Dati casuali di SQL Server con ORDER BY NEWID()
Ecco una citazione da BOL su come ottenere un campione veramente casuale:
“Se volete veramente un campione casuale di singole righe, modificate la vostra query per filtrare le righe in modo casuale, invece di usare TABLESAMPLE. Per esempio, la seguente query usa la funzione NEWID per restituire circa l’uno per cento delle righe della tabella Sales.SalesOrderDetail:
Come funziona? Dividiamo la clausola WHERE e la spieghiamo.
La funzione CHECKSUM sta calcolando una somma di controllo sulle voci della lista. È discutibile se SalesOrderID sia addirittura necessario, dato che NEWID() è una funzione che restituisce un nuovo GUID casuale, quindi moltiplicando una cifra casuale per una costante si dovrebbe ottenere una cifra casuale in ogni caso.Infatti, escludere SalesOrderID sembra non fare alcuna differenza. Se sei un appassionato di statistica e puoi giustificare l’inclusione di questo, per favore usa la sezione commenti qui sotto e fammi sapere perché mi sbaglio!
La funzione CHECKSUM restituisce un VARBINARY. Eseguendo un’operazione bitwise AND con 0x7fffffff, che è l’equivalente di (111111111111…) in binario, si ottiene un valore decimale che è effettivamente una rappresentazione di una stringa casuale di 0 e 1. Dividendo per il coefficiente 0x7fffff si normalizza efficacemente questa cifra decimale in una cifra tra 0 e 1. Quindi, per decidere se ogni riga merita di essere inclusa nell’insieme dei risultati finali, si usa una soglia di 1/x (in questo caso, 0,01) dove x è la percentuale dei dati da recuperare come campione.
Fate attenzione al fatto che questo metodo è una forma di campionamento casuale piuttosto che sistematico, quindi è probabile che otteniate dati da tutte le parti dei vostri dati sorgente, ma la chiave qui è che *potreste non farlo*. La natura del campionamento casuale significa che ogni campione che raccogliete può essere distorto verso un segmento dei vostri dati, quindi per beneficiare della regressione alla media (tendenza verso un risultato casuale, in questo caso) assicuratevi di prendere più campioni e selezionate da un sottoinsieme di questi, se i vostri risultati sembrano distorti. In alternativa, prendete campioni da sottoinsiemi dei vostri dati, poi aggregateli – questo è un altro tipo di campionamento, chiamato campionamento stratificato.
Come vengono campionate le statistiche di SQL Server?
In SQL Server, l’aggiornamento automatico delle statistiche di colonna o definite dall’utente avviene ogni volta che una soglia impostata di righe di tabella viene modificata per una data tabella. Per il 2012, questa soglia è calcolata a SQRT(1000 * TR) dove TR è il numero di righe della tabella. Prima del 2005, il lavoro di aggiornamento automatico delle statistiche si attiva per ogni (500 righe + 20% di cambiamento) di righe della tabella. Una volta avviato il processo di aggiornamento automatico, il campionamento *riduce il numero di righe campionate quanto più grande diventa la tabella*, in altre parole c’è una relazione simile alla proporzione inversa tra la percentuale di campionamento della tabella e la dimensione della tabella, ma segue un algoritmo proprietario.
Interessante, questo sembra essere il contrario dell’opzione TABLESAMPLE (N PERCENT), dove le righe campionate sono in proporzione normale al numero di righe nella tabella. Possiamo disabilitare le statistiche automatiche (fate attenzione) e aggiornare le statistiche manualmente – questo si ottiene usando NORECOMPUTE sull’istruzione UPDATE STATISTICS. Con UPDATE STATISTICS possiamo sovrascrivere alcune delle opzioni – per esempio, possiamo scegliere di campionare N righe, o N per cento (simile a TABLESAMPLE), eseguire una FULLSCAN, o semplicemente RESAMPLE usando l’ultimo tasso conosciuto.
Passi successivi
Per ulteriori letture, Joseph Sack è un MVP Microsoft noto per il suo lavoro nell’analisi statistica di SQL Server – vedi sotto per alcuni link al suo lavoro, insieme ad alcuni riferimenti al lavoro utilizzato per questo articolo e ad alcuni suggerimenti correlati da MSSQLTips.com. Grazie per aver letto!
Ultimo aggiornamento: 2014-01-29


Chi è l’autore
 Derek Colley è un DBA e uno sviluppatore BI con sede nel Regno Unito e con più di un decennio di esperienza di lavoro con SQL Server, Oracle e MySQL.
Derek Colley è un DBA e uno sviluppatore BI con sede nel Regno Unito e con più di un decennio di esperienza di lavoro con SQL Server, Oracle e MySQL.Vedi tutti i miei consigli
- Altri consigli per sviluppatori di database…