Ci sono molti grandi vantaggi che vengono offerti dalla virtualizzazione dell’infrastruttura e dall’esecuzione di risorse virtuali per servire i carichi di lavoro business-critical. Nel caso di VMware vSphere, fornisce molte caratteristiche e capacità notevoli che forniscono alta disponibilità nell’ambiente così come la pianificazione automatica del carico di lavoro per garantire l’uso più efficiente di hardware e risorse nel vostro ambiente vSphere.
In questo post, parleremo di due delle caratteristiche fondamentali di vSphere a livello di cluster nell’impresa – vSphere HA e DRS. È molto probabile che abbiate visto entrambi i riferimenti all’esecuzione di vSphere in azienda.
Che cosa sono vSphere HA e DRS? Cosa fanno?
Come si può beneficiare dell’esecuzione di entrambi nel proprio ambiente vSphere?
Diamo un’occhiata a un’introduzione di base a HA e DRS in VMware vSphere e vediamo come si confrontano e i vantaggi del loro utilizzo.
VMware vSphere Cluster
Uno degli ovvi vantaggi e delle migliori pratiche quando si utilizza VMware vSphere per eseguire carichi di lavoro business-critical è quello di eseguire un vSphere Cluster.
Cos’è un vSphere Cluster?
Un vSphere cluster è una configurazione di più di un server VMware ESXi aggregati insieme come un pool di risorse che contribuiscono al vSphere cluster. Risorse come la CPU, la memoria e, nel caso dello storage definito dal software come vSAN, lo storage, sono fornite da ogni host ESXi.
Perché è importante eseguire i carichi di lavoro business-critical su un cluster vSphere?
Quando si pensa ai vantaggi forniti dall’esecuzione di un hypervisor, esso permette a più di un server di funzionare su un singolo set di hardware fisico. Virtualizzare i carichi di lavoro in questo modo fornisce molti vantaggi di efficienza in ordini di grandezza rispetto all’esecuzione di un singolo server su un singolo set di hardware fisico.
Tuttavia, questo può anche diventare il tallone d’Achille di una soluzione virtualizzata, poiché l’impatto di un guasto hardware può interessare molti più servizi e applicazioni business-critical. Si può immaginare che se si ha un solo host VMware ESXi che esegue molte VM, l’impatto di perdere quel singolo host ESXi sarebbe immenso.
È qui che l’esecuzione di più host VMware ESXi in un vSphere Cluster brilla davvero.
Tuttavia, ci si può chiedere: in che modo la semplice esecuzione di più host in un cluster migliora l’alta disponibilità? Come fa un host nel vSphere Cluster a “sapere” se un altro host è fallito? C’è un meccanismo speciale che viene utilizzato per gestire l’alta disponibilità dei carichi di lavoro in esecuzione su un vSphere Cluster? Sì, c’è. Vediamo.
Cos’è la HA in VMware?
VMware si è resa conto della necessità di avere un meccanismo per poter fornire protezione contro un host ESXi fallito nel vSphere Cluster. Con questa necessità, è nato VMware High-Availability (HA).
VMware vSphere HA offre i seguenti vantaggi:
VMware vSphere HA è conveniente e permette il riavvio automatico delle VM e degli host vSphere quando c’è un’interruzione del server o un guasto del sistema operativo rilevato nell’ambiente vSphere
Monitorizza tutti gli host VMware vSphere &Le VM nel cluster vSphere
Fornisce alta disponibilità alla maggior parte delle applicazioni in esecuzione nelle macchine virtuali indipendentemente dal sistema operativo e dalle applicazioni.
La bellezza della soluzione vSphere HA di VMware, implementata tramite il cluster VMware, è la semplicità con cui può essere configurata. Con pochi clic attraverso un’interfaccia guidata, l’alta disponibilità può essere configurata. Come si confronta con le tecnologie di “clustering” tradizionali?
Confronto tra Windows Server Failover Clustering
Windows Server Failover Clustering (WSFC) è diventata la tecnologia di clustering a cui molti pensano quando hanno in mente una tecnologia di clustering. Il problema visto con WSFC è che richiede un sacco di competenze specialistiche per eseguire correttamente i servizi WSFC, soprattutto quando si tratta di aggiornamenti, patch e compiti operativi generali.
Confrontando vSphere HA con WSFC, l’overhead operativo è minimo in confronto a WSFC. C’è poca possibilità che HA possa essere configurato in modo errato, poiché è abilitato o meno su un cluster. Con WSFC, ci sono molte considerazioni che devono essere fatte quando si configura WSFC per evitare sia errori di configurazione che di implementazione. Pensate a quanto segue:
- Il Failover clustering richiede applicazioni che supportino il clustering (SQL, ecc.)
- Il Failover clustering richiede che il quorum sia configurato correttamente
- Non è supportato da molti sistemi operativi e applicazioni legacy
- Richiede complessità dei nomi di rete del cluster, risorse e networking
Windows Server Failover Clustering è pubblicizzato per fornire quasi zero downtime a livello di applicazione. Tuttavia, quando si aggiungono le competenze necessarie per una soluzione HA correttamente funzionante, insieme alla corretta implementazione di WSFC, i rischi possono iniziare a superare i benefici dell’uso di WSFC per l’alta disponibilità di applicazioni e servizi. Questo è particolarmente vero quando per la maggior parte delle organizzazioni che potrebbero non avere veramente bisogno di una soluzione “zero downtime”. Inoltre, la vostra applicazione deve essere progettata per trarre vantaggio da WSFC e lavorare correttamente con la tecnologia WSFC.
Mentre vSphere HA richiede un riavvio delle macchine virtuali su un host sano quando si verifica un failover, non richiede l’installazione di software aggiuntivo all’interno delle macchine virtuali guest, nessuna configurazione complessa di tecnologie di clustering aggiuntive e le applicazioni o i sistemi operativi non devono essere progettati per funzionare con una particolare tecnologia di clustering.
I sistemi operativi e le applicazioni legacy hanno generalmente capacità limitate quando si tratta di tecnologie supportate per fornire alta disponibilità. Quindi, potrebbero letteralmente non esserci opzioni native per fornire funzionalità di failover in caso di guasti hardware.
Il meccanismo di alta disponibilità di vSphere HA funziona ed è semplice da implementare, configurare e gestire. Inoltre, si tratta di una tecnologia ben testata in migliaia di ambienti di clienti VMware, quindi ha una storia stabile e lunga di implementazioni di successo.
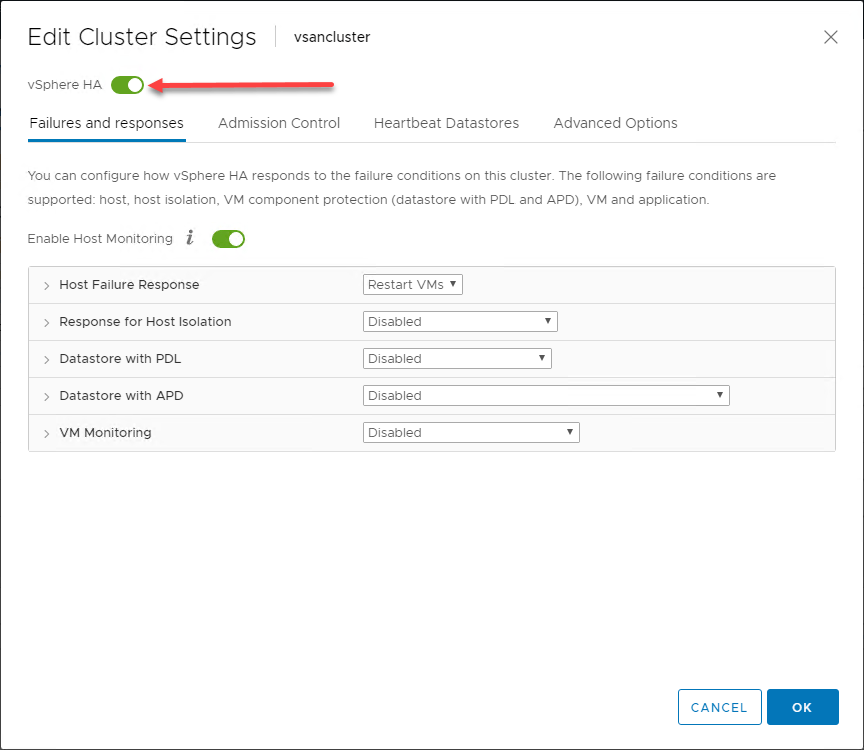
Panoramica generale del comportamento di vSphere HA
Utilizzando i vantaggi forniti agli host ESXi in un vSphere Cluster, nella sua forma più elementare, vSphere HA implementa un meccanismo di monitoraggio tra gli host nel vSphere Cluster. Il meccanismo di monitoraggio fornisce un modo per determinare se un host nel vSphere Cluster è fallito.
Nell’infografica sottostante, un vSphere Cluster a due nodi ha subito un guasto di uno degli host ESXi nel vSphere Cluster. Il vSphere Cluster ha vSphere HA abilitato a livello di cluster.
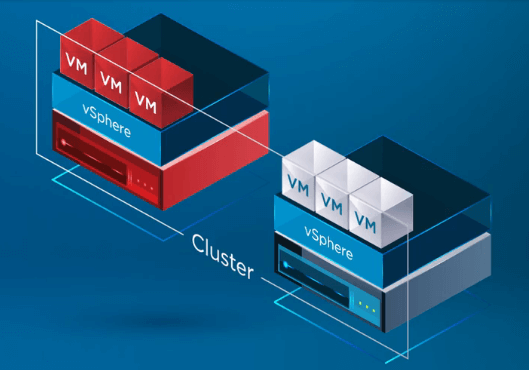
Dopo che vSphere HA riconosce che un host nel vSphere Cluster è guasto, il processo HA sposta la registrazione delle VM dall’host guasto a un host sano.
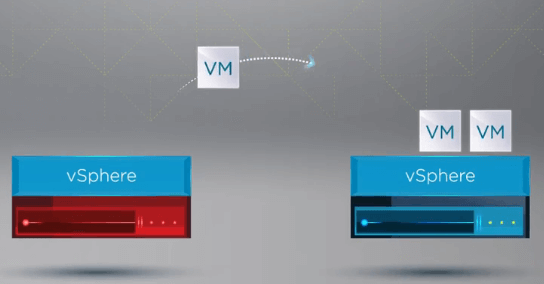
Dopo che le VM sono state registrate su un host sano, vSphere HA riavvia tutte le VM dell’host fallito su un host ESXi sano nel cluster dove le VM sono state registrate nuovamente. L’unico tempo di inattività sostenuto è il riavvio delle VM su un host sano nel cluster vSphere.
VSphere HA Technical Overview
Prequisiti per vSphere HA
Ti potresti chiedere quali prerequisiti di base siano necessari per far funzionare vSphere HA. Hai semplicemente bisogno di un cluster VMware per abilitare HA? A differenza del Failover Clustering di Windows Server, ci sono solo pochi requisiti che devono essere presenti perché la HA funzioni.
Requisiti:
- Almeno due host ESXi
- Almeno 4 GB di memoria configurati su ogni host
- vCenter Server
- vSphere Standard License
- Stoccaggio condiviso per le VM
- Gateway pingabile o un altro nodo di rete affidabile
Se noti, non c’è nessun componente quorum richiesto, nessuna complessa denominazione di rete coinvolta, e nessun’altra risorsa speciale del cluster che deve essere presente.
Leggi di più: Come configurare un cluster vSphere High Availability
VMware vSphere HA Master vs Subordinate Hosts
Quando abiliti vSphere HA su un cluster, un particolare host nel vSphere Cluster è designato come master di vSphere HA. I restanti host ESXi nel vSphere Cluster sono configurati come subordinati nella configurazione di vSphere HA.
Quale ruolo svolge l’host ESXi vSphere HA designato come master? Il nodo master di vSphere HA:
- Monitorizza lo stato degli host subordinati slave – Se l’host subordinato fallisce o è irraggiungibile, l’host master identifica quali VM devono essere riavviate
- Monitorizza lo stato di alimentazione di tutte le VM che sono protette. Se una VM si guasta, il nodo master vSphere HA si assicura che la VM venga riavviata. Il master vSphere HA decide dove avviene il riavvio della VM (quale host ESXi).
- Tiene traccia di tutti gli host del cluster e delle VM che sono protette da vSphere HA
- È designato come mediatore tra il vSphere Cluster e vCenter Server. Il master HA riporta la salute del cluster a vCenter e fornisce l’interfaccia di gestione del cluster per vCenter Server
- Può eseguire da solo le VM e monitorare lo stato delle VM
- Conserva le VM protette nei datastore del cluster
vSphere HA Subordinate Hosts:
- Esegue le macchine virtuali localmente
- Monitorizza gli stati di runtime delle VM nel cluster vSphere
- Riporta gli aggiornamenti di stato al master vSphere HA
Elezione dell’host master e fallimento del master
Come viene selezionato l’host master vSphere HA? Quando vSphere HA è abilitato per un cluster, tutti gli host attivi (nessuna modalità di manutenzione, ecc.) partecipano all’elezione dell’host master. Se l’host master eletto fallisce, ha luogo una nuova elezione in cui viene eletto un nuovo host master HA per ricoprire quel ruolo.
Tipi di guasto del cluster vSphere HA diVMware
In un cluster vSphere HA abilitato, ci sono tre tipi di guasti che possono verificarsi per innescare un evento di failover vSphere HA. Questi tipi di fallimento dell’host sono:
- Failure – Un fallimento è intuitivamente quello che si pensa. Un host ha smesso di funzionare in qualche forma o modo a causa dell’hardware o di altri problemi.
- Isolamento – L’isolamento di un host avviene generalmente a causa di un evento di rete che isola un particolare host dagli altri host nel cluster vSphere HA.
- Partizione – Un evento di partizione è caratterizzato da un host subordinato che perde la connettività di rete all’host master del cluster vSphere HA.
Heartbeating, Failure Detection, and Failure Actions
Come fa il nodo master a determinare se c’è un fallimento di un particolare host?
Ci sono diversi meccanismi che il nodo master usa per determinare se un host è fallito:
- Il nodo master scambia heartbeat di rete con gli altri host nel cluster ogni secondo.
- Dopo che l’heartbeat di rete è fallito, l’host master controlla la verifica della liveness dell’host.
- La verifica della liveness dell’host determina se l’host subordinato sta scambiando heartbeat con uno dei datastore. Quindi invia ping ICMP ai suoi indirizzi IP di gestione
- Se la comunicazione diretta con l’agente HA di un host subordinato dall’host master non è possibile e i ping ICMP all’indirizzo di gestione falliscono, l’host viene considerato fallito e le VM vengono riavviate su un host diverso.
- Se si trova che l’host subordinato sta scambiando heartbeat con il datastore, l’host master assume che l’host sia in una partizione di rete o sia isolato dalla rete. In questo caso, il master monitora semplicemente l’host e le VM
- L’isolamento della rete è l’evento in cui un host subordinato è in esecuzione, ma non può più essere visto dalla prospettiva dell’agente di gestione HA sulla rete di gestione. Se un host smette di vedere questo traffico, tenta di fare un ping agli indirizzi di isolamento del cluster. Se questo ping fallisce, l’host dichiara di essere isolato dalla rete
- In questo caso, il nodo master controlla le VM che sono in esecuzione sull’host isolato. Se le VM si spengono sull’host isolato, il nodo master riavvia le VM su un altro host
Datastore Heartbeating
Come detto sopra, una delle metriche utilizzate per determinare il rilevamento dei guasti è il datastore heartbeating. Che cos’è esattamente? VMware vCenter seleziona un set preferito di datastore per l’heartbeating. Poi, vSphere HA crea una directory alla radice di ogni datastore che viene utilizzata sia per l’heartbeating del datastore che per mantenere l’elenco delle VM protette. Questa directory si chiama .vSphere-HA.
C’è una nota importante da ricordare riguardo ai datastore vSAN. Un datastore vSAN non può essere utilizzato per l’heartbeating del datastore. Se avete solo un datastore vSAN disponibile, non possono essere utilizzati datastore heartbeat.
- VM e Application Monitoring
Un’altra caratteristica estremamente potente di vSphere HA è la capacità di monitorare le singole macchine virtuali tramite VMware Tools e riavviare qualsiasi macchina virtuale che non risponde agli heartbeat di VMware Tools. Il monitoraggio delle applicazioni può riavviare una VM se gli heartbeat di un’applicazione in esecuzione non vengono ricevuti.
- VM Monitoring – Con VM Monitoring, il servizio VM Monitoring usa VMware Tools per determinare se ogni VM è in esecuzione controllando sia gli heartbeat che gli I/O del disco generati da VMware Tools. Nel caso in cui questi controlli falliscano, il servizio VM Monitoring determina che molto probabilmente il sistema operativo guest è fallito e la VM viene riavviata. Il controllo aggiuntivo di I/O del disco aiuta ad evitare qualsiasi reset inutile della VM se le VM o le applicazioni stanno ancora funzionando correttamente.
Application Monitoring – La funzione di monitoraggio delle applicazioni è abilitata ottenendo l’SDK appropriato da un fornitore di software di terze parti che permette di impostare heartbeat personalizzati per le applicazioni da monitorare dal processo vSphere HA. Proprio come il processo di monitoraggio delle VM, se gli heartbeat delle applicazioni smettono di essere ricevuti, la VM viene resettata.
Entrambe queste funzioni di monitoraggio possono essere ulteriormente configurate con la sensibilità di monitoraggio e anche con i reset massimi per VM per evitare di resettare ripetutamente le VM per errori software o falsi positivi.
VMware vSphere HA è un ottimo modo per garantire che il tuo vSphere Cluster fornisca un’alta disponibilità molto resiliente per proteggere contro i guasti generali degli host ESXi nel tuo vSphere Cluster.
E per garantire un uso efficiente delle risorse nel tuo vSphere Cluster? Diamo un’occhiata alla prossima disposizione del vSphere Cluster per garantire un uso efficiente delle risorse e della capacità del vSphere Cluster.
Cos’è DRS in VMware?
VMware Distributed Resource Scheduler (DRS) è una funzione molto potente quando si eseguono i vSphere Cluster. Fornisce la pianificazione e il bilanciamento del carico in un cluster vSphere. VMware DRS è la funzione presente nei cluster vSphere che assicura che le macchine virtuali in esecuzione nell’ambiente vSphere ricevano le risorse necessarie per funzionare in modo efficace ed efficiente.
Le VM sono generalmente soggette a DRS fin dalla loro prima accensione in un cluster abilitato a DRS, DRS colloca le VM sul miglior host configurato per fornire le risorse necessarie alla VM non appena vengono accese. Inoltre, DRS si sforza di mantenere i cluster vSphere bilanciati dal punto di vista dell’utilizzo delle risorse.
Anche se un vSphere Cluster è bilanciato in un certo momento, le VM possono essere spostate o cambiare in modo tale che uno squilibrio delle risorse del cluster possa insinuarsi nuovamente nell’ambiente. Quando i cluster diventano sbilanciati, può essere dannoso per le prestazioni complessive delle macchine virtuali in esecuzione in un cluster vSphere.
Di default, DRS viene eseguito automaticamente su un cluster vSphere ogni cinque minuti per determinare l’equilibrio di un cluster vSphere e vedere se è necessario apportare modifiche per un uso più efficace delle risorse.
Requisiti di VMware DRS
Per trarre vantaggio da VMware DRS, ci sono diversi requisiti che devono essere soddisfatti per garantire l’utilizzo della funzionalità Distributed Resource Scheduler. Questi includono:
- Un cluster di host ESXi
- vCenter Server
- Licenza Enterprise Plus
- vMotion è richiesto per il bilanciamento automatico del carico
Leggi tutto: Come configurare un vSphere DRS Cluster
VMware DRS Actions
Quando VMware DRS viene eseguito su un vSphere Cluster ogni cinque minuti, determina se ci sono squilibri nel cluster. In caso affermativo, verrà eseguita una vMotion per spostare le VM designate da un host ESXi a un altro.
Come fa esattamente DRS a determinare se le macchine virtuali sono più adatte su un host ESXi o un altro?
DRS esegue un algoritmo speciale per determinare l’host ESXi giusto che dovrebbe ospitare una particolare VM. Quando una VM viene accesa, questo algoritmo prende in considerazione la distribuzione delle risorse in tutto il cluster vSphere dopo aver assicurato che non ci sono violazioni dei vincoli se una particolare VM viene messa su un particolare host ESXi.
Inoltre, la domanda della VM stessa viene presa in considerazione in modo che la VM non sia mai affamata di risorse quando viene accesa. Cosa è incluso nella domanda della VM? La domanda di una VM include la quantità di risorse necessarie per funzionare.
- Per la domanda della CPU, questa è calcolata in base alla quantità di CPU che la VM sta attualmente consumando
- Per la memoria, la domanda è calcolata in base alla formula: Domanda di memoria della VM = Funzione (memoria attiva usata, scambiata, condivisa) + 25% (memoria consumata inattiva). Questo dimostra che il bilanciamento della memoria DRS si basa principalmente sull’utilizzo della memoria attiva di una VM, considerando una piccola quantità di memoria consumata inattiva come cuscinetto per qualsiasi aumento del carico di lavoro.
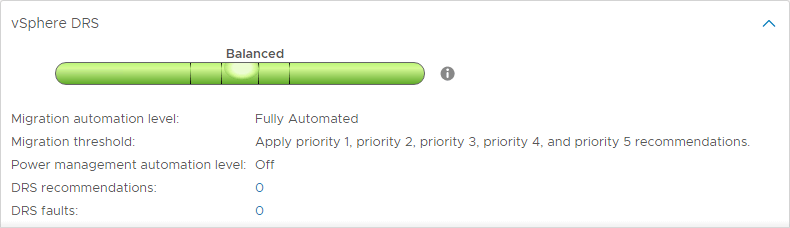
Livelli di automazione DRS
Una delle caratteristiche interessanti di DRS sono i livelli di automazione DRS. Mentre DRS continua a scansionare il cluster vSphere e a fornire raccomandazioni ogni 5 minuti, è possibile determinare se DRS è in grado di attuare le sue raccomandazioni automaticamente o se suggerisce solo le modifiche che dovrebbero essere fatte. DRS ha tre livelli di automazione DRS. Questi includono:
- Completamente automatizzato – Nell’approccio completamente automatizzato, DRS applica automaticamente le raccomandazioni per il posizionamento iniziale e il bilanciamento del carico
- Parzialmente automatizzato – Con l’automazione parziale, DRS applica le raccomandazioni solo per il posizionamento iniziale delle VM
- Manuale – Nella modalità manuale, devi applicare le raccomandazioni sia per il posizionamento iniziale che per il bilanciamento del carico
Soglie di migrazione DRS
DRS include un’altra impostazione molto utile per controllare la quantità di squilibrio che sarà tollerata prima che vengano fatte raccomandazioni DRS. Ci sono cinque soglie di migrazione DRS per controllare la quantità di squilibrio tollerata.
L’intervallo va da 1 (più conservativo) a 5 (più aggressivo).
Con impostazioni più aggressive, DRS tollera meno squilibri in un cluster. Più è conservativo, più DRS tollera lo squilibrio.

VMware DRS VM/Host Rules
C’è una funzione estremamente utile quando si usa VMware DRS per controllare il posizionamento delle VM nei cluster abilitati a DRS vSphere. Le regole VM/Host permettono di eseguire specifiche VM su specifici host ESXi. Si può pensare a questo come a regole di affinità in un certo senso.
Le regole VM/Host ti permettono di:
- Tenere le macchine virtuali insieme
- Separare le macchine virtuali
- Legare le macchine virtuali a specifici host
- Legare le macchine virtuali alle macchine virtuali
Di seguito è mostrato un esempio di creazione di una regola VM/Host per macchine virtuali e host ESXi.
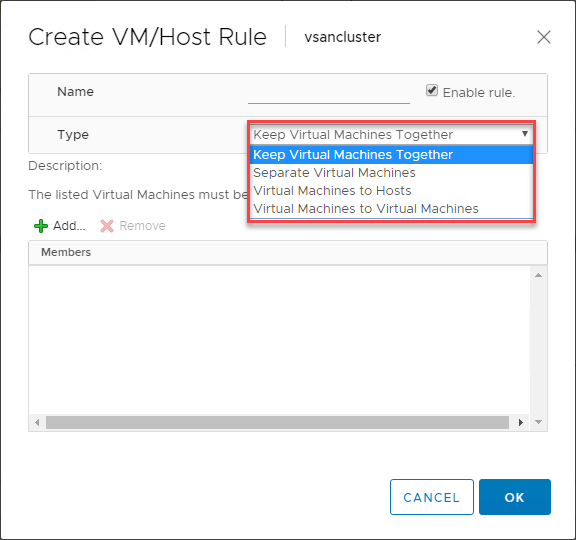
Che tipo di caso d’uso esiste per queste regole VM/Host? Uno dei casi d’uso classici che esistono è con i controller di dominio. In generale, se state eseguendo tutti i vostri controller di dominio in un ambiente virtualizzato come un cluster vSphere, volete assicurarvi di avere le vostre macchine virtuali di controller di dominio separate le une dalle altre all’interno del cluster. In questo modo, se un host ESXi va giù insieme a uno dei tuoi controller di dominio, hai ancora un controller di dominio che è soggetto a una regola Separate Virtual Machines che lo tiene lontano dallo stesso host di un altro DC.
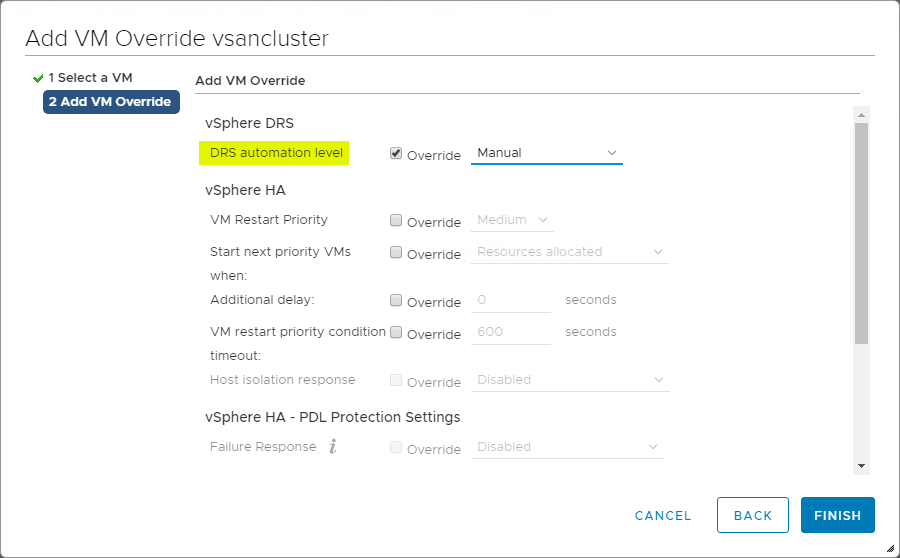
VM Overrides for DRS
Il vSphere Cluster fornisce grande granularità per le operazioni che riguardano le singole VM all’interno del vSphere Cluster. Puoi creare VM Overrides per sovrascrivere le impostazioni globali impostate a livello di cluster per HA e DRS per definire impostazioni più specifiche per ogni singola VM.
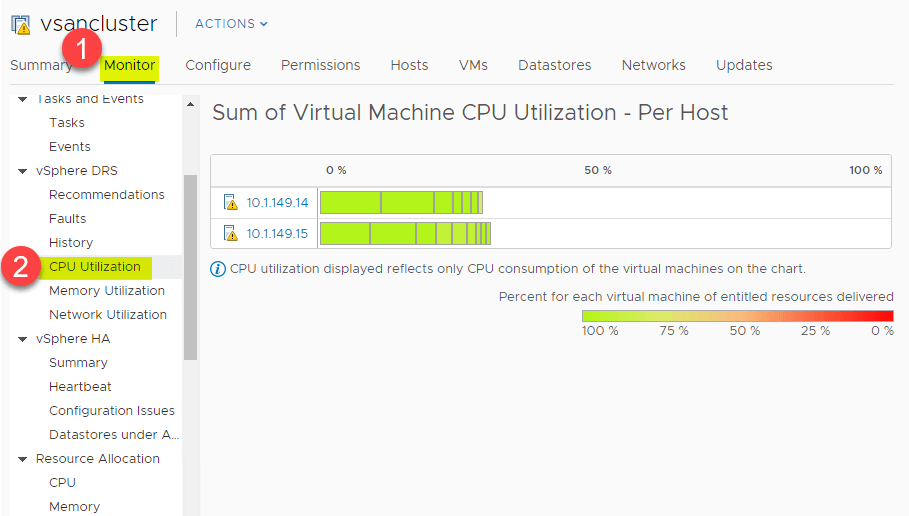
Sommario utilizzo CPU e memoria
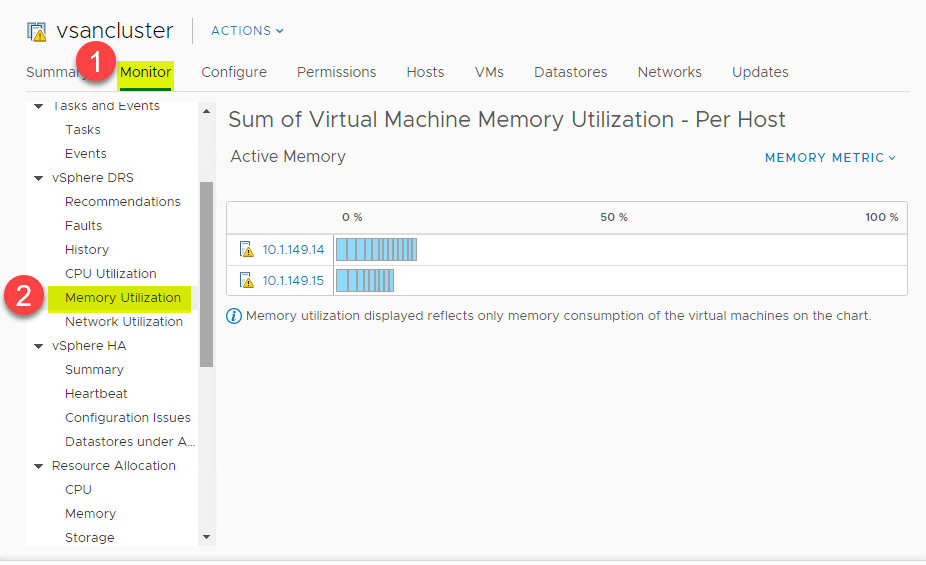
DRS fornisce una grande visione di alto livello del sommario utilizzo CPU delle risorse CPU degli host ESXi nel vSphere Cluster. Vai a > Impostazioni > Monitor > vSphere DRS > Utilizzo della CPU.
La stessa panoramica di alto livello può essere vista anche per il consumo di memoria. Vai a > Impostazioni > Monitor > vSphere DRS > Utilizzo della memoria
Il meglio dei due mondi
Vamware vSphere HA e VMware DRS sono tecnologie concorrenti?
No, non lo sono. Infatti, si consiglia vivamente di utilizzare sia vSphere HA che VMware DRS insieme per combinare il failover automatico con le caratteristiche e le funzionalità di bilanciamento del carico. Questo si traduce in un ambiente vSphere molto più resiliente e bilanciato.
Se si verifica il fallimento di un host ESXi, vSphere HA riavvierà le VM sui restanti host sani in un cluster vSphere. Quindi, la prima priorità, ovviamente, è la disponibilità delle risorse della macchina virtuale. VMware DRS verrà quindi eseguito e determinerà se esiste uno squilibrio tra gli host ESXi che eseguono i carichi di lavoro e farà raccomandazioni per risolvere eventuali squilibri nel cluster in base alla soglia di migrazione configurata. In base al livello di automazione, queste raccomandazioni saranno attuate automaticamente o solo raccomandate se non completamente automatizzate.
Pensieri finali su VMware vSphere HA e DRS
Eseguire sia VMware vSphere HA che DRS è altamente consigliato in un cluster vSphere di produzione. L’utilizzo di entrambe le tecnologie aiuta a rendere i vostri carichi di lavoro altamente disponibili e garantisce che abbiano continuamente le risorse necessarie in base alle richieste di CPU/memoria della VM.
Capire come funzionano entrambi i meccanismi vi aiuta come amministratore di vSphere a sfruttare entrambe le tecnologie nel miglior modo possibile e in accordo con le migliori pratiche. Tra i vantaggi che entrambe le tecnologie portano al tavolo, ogni caratteristica è estremamente facile da abilitare e configurare. Con pochi semplici clic nelle proprietà dei vostri cluster vSphere, potete iniziare rapidamente a beneficiare di queste caratteristiche disponibili a livello di cluster.
Segui i nostri feed di Twitter e Facebook per nuove release, aggiornamenti, post interessanti e altro ancora.
.