Introduzione
Se stai analizzando i tuoi dati usando la regressione multipla e una qualsiasi delle tue variabili indipendenti è stata misurata su una scala nominale o ordinale, devi sapere come creare variabili dummy e interpretare i loro risultati. Questo perché le variabili indipendenti nominali e ordinali, più ampiamente note come variabili indipendenti categoriali, non possono essere inserite direttamente in un’analisi di regressione multipla. Invece, devono essere convertite in variabili dummy. L’eccezione è rappresentata dalle variabili indipendenti ordinali che sono inserite in una regressione multipla come variabili indipendenti continue, che non hanno bisogno di essere convertite in variabili dummy. Pertanto, in questa guida vi mostreremo come creare variabili dummy quando avete variabili indipendenti categoriche.
Prima di tutto, vi presentiamo l’esempio che usiamo per mostrare come creare variabili dummy in SPSS Statistics, prima di spiegare come impostare i vostri dati nelle finestre Vista Variabile e Vista Dati di SPSS Statistics in modo da poter creare variabili dummy. Se non avete familiarità con l’uso delle variabili dummy, vi consigliamo di leggere alcuni dei principi di base delle variabili dummy e della codifica dummy, tra cui (a) il numero di variabili dummy da creare nella vostra analisi; e (b) come creare variabili dummy e codifica dummy. Nella sezione Procedura che segue, esponiamo la semplice procedura in 3 passi Create Dummy Variables in SPSS Statistics che può essere usata per creare le variabili dummy. Infine, spieghiamo l’output di SPSS Statistics dopo l’esecuzione della procedura Create Dummy Variables, compreso il modo in cui le vostre variabili dummy saranno ora impostate nelle finestre Variable View e Data View di SPSS Statistics.
Nota: Se trovate che le procedure di questa guida non coprono il tipo di variabili dummy che volete creare, contattateci. Potremmo essere in grado di aggiungere un’altra guida al sito per aiutarvi.
SPSS Statistics
Esempio usato in questa guida
In questa guida useremo l’esempio di 10 triatleti ai quali è stato chiesto di selezionare il loro sport preferito tra i tre sport che praticano quando fanno un triathlon: nuoto, ciclismo e corsa. Le loro risposte sono state registrate nella variabile indipendente nominale, favourite_sport, che ha tre categorie: “nuoto”, “ciclismo” e “corsa”. Questa variabile indipendente nominale, favourite_sport, doveva essere inclusa in un’analisi di regressione multipla che aveva anche una serie di variabili indipendenti continue. Poiché questa variabile indipendente era categorica (cioè, le variabili nominali e le variabili ordinali possono essere ampiamente classificate come variabili categoriche), è stato necessario creare delle variabili dummy prima di poterla inserire nell’analisi di regressione multipla.
Importante: Si noti che favourite_sport è una variabile nominale, ma è anche possibile creare variabili dummy per una variabile ordinale. Inoltre, il processo di creazione delle variabili dummy è lo stesso indipendentemente dal fatto che abbiate una variabile ordinale o nominale, con l’eccezione di un piccolo cambiamento che dovete fare quando impostate i vostri dati, che è spiegato di seguito.
Nota 1: Le “categorie” di una variabile indipendente categorica sono anche chiamate “gruppi” o “livelli”, ma il termine “livelli” è solitamente riservato alle categorie che hanno un ordine (ad esempio, la variabile indipendente ordinale, “fitness level”, potrebbe avere tre livelli: “basso”, “moderato” e “alto”). Tuttavia, questi tre termini – “categorie”, “gruppi” e “livelli” – possono essere usati in modo intercambiabile. In questa guida, ci riferiremo a loro come categorie, ma potreste riferirvi a loro come gruppi o livelli se preferite.
Nota 2: Il termine “fattori” è talvolta usato al posto di “variabili indipendenti categoriche” (cioè, variabili indipendenti che sono “ordinali” o “nominali”). Tuttavia, questi due termini – “variabili indipendenti categoriche” e “fattori” – possono essere usati in modo intercambiabile. In questa guida, ci riferiremo a loro come variabili indipendenti categoriche e vedrete anche SPSS Statistics riferirsi a loro come variabili indipendenti piuttosto che come fattori nella sua procedura di regressione multipla. Tuttavia, puoi riferirti a loro come fattori se preferisci.
SPSS Statistics
Impostare i tuoi dati in SPSS Statistics
Quando crei variabili dummy, inizierai con una singola variabile indipendente categorica (ad esempio, sport_favorito). Per impostare questa variabile indipendente categorica, SPSS Statistics ha una Vista Variabile dove si definisce il tipo di variabile che si sta analizzando e una Vista Dati dove si inseriscono i dati per questa variabile. In questa sezione, vi mostreremo innanzitutto come impostare una variabile indipendente categorica nella finestra Vista delle variabili di SPSS Statistics, prima di mostrarvi come inserire i vostri dati nella finestra Vista dei dati. Lo facciamo usando la nostra variabile indipendente categorica, favourite_sport, che ha tre categorie: “nuoto”, “ciclismo” e “corsa”.
La Vista Variabile in SPSS Statistics
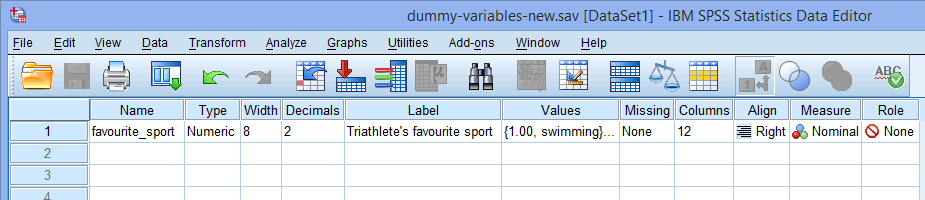
Per una singola variabile indipendente categorica (es, per una singola variabile indipendente categorica (ad esempio, lo sport preferito), la vostra finestra di visualizzazione delle variabili avrà l’aspetto seguente:
Nota: Potete accedere alla finestra di visualizzazione delle variabili in SPSS Statistics cliccando sulla scheda ![]() nell’angolo in basso a sinistra del software SPSS Statistics.
nell’angolo in basso a sinistra del software SPSS Statistics.
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Il nome della vostra variabile categorica indipendente deve essere inserito nella cella sotto la colonna ![]() (es, “favourite_sport” nella riga
(es, “favourite_sport” nella riga ![]() per rappresentare la nostra variabile categorica indipendente, favorite_sport. Ci sono alcuni caratteri “illegali” che non possono essere inseriti nella cella
per rappresentare la nostra variabile categorica indipendente, favorite_sport. Ci sono alcuni caratteri “illegali” che non possono essere inseriti nella cella ![]() . Pertanto, se ricevete un messaggio di errore e volete che aggiungiamo una guida di SPSS Statistics per spiegare quali sono questi caratteri illegali, contattateci.
. Pertanto, se ricevete un messaggio di errore e volete che aggiungiamo una guida di SPSS Statistics per spiegare quali sono questi caratteri illegali, contattateci.
Nota: Per la vostra chiarezza, potete anche fornire un’etichetta per le vostre variabili nella colonna ![]() . Per esempio, l’etichetta che abbiamo inserito per “sport_favorito” è “Sport preferito del triatleta”.
. Per esempio, l’etichetta che abbiamo inserito per “sport_favorito” è “Sport preferito del triatleta”.
La cella sotto la colonna ![]() dovrebbe contenere le informazioni sulle categorie della vostra variabile indipendente categorica (per esempio, “nuoto”, “ciclismo” e “corsa” per sport_favorito. Per inserire queste informazioni, cliccate nella cella sotto la colonna
dovrebbe contenere le informazioni sulle categorie della vostra variabile indipendente categorica (per esempio, “nuoto”, “ciclismo” e “corsa” per sport_favorito. Per inserire queste informazioni, cliccate nella cella sotto la colonna ![]() della vostra variabile indipendente. Il pulsante
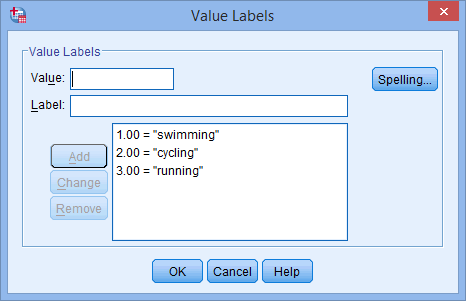
della vostra variabile indipendente. Il pulsante ![]() apparirà nella cella. Cliccate su questo pulsante e apparirà la finestra di dialogo delle etichette dei valori. Ora dovete dare a ogni categoria della vostra variabile indipendente un “valore”, che inserite nella casella Value: (per esempio, “1”), e un'”etichetta”, che inserite nella casella Label: (per esempio, “swimming”). Cliccando il pulsante
apparirà nella cella. Cliccate su questo pulsante e apparirà la finestra di dialogo delle etichette dei valori. Ora dovete dare a ogni categoria della vostra variabile indipendente un “valore”, che inserite nella casella Value: (per esempio, “1”), e un'”etichetta”, che inserite nella casella Label: (per esempio, “swimming”). Cliccando il pulsante ![]() la codifica apparirà nella casella principale (per esempio, “1.00=”nuoto” per favourite_sport). La configurazione per la nostra variabile indipendente categorica è mostrata nella finestra di dialogo Etichette valore qui sotto:
la codifica apparirà nella casella principale (per esempio, “1.00=”nuoto” per favourite_sport). La configurazione per la nostra variabile indipendente categorica è mostrata nella finestra di dialogo Etichette valore qui sotto:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
La cella sotto la colonna ![]() dovrebbe mostrare
dovrebbe mostrare ![]() se avete una variabile indipendente nominale (es, favorite_sport, come nel nostro esempio) o
se avete una variabile indipendente nominale (es, favorite_sport, come nel nostro esempio) o ![]() se avete una variabile indipendente ordinale (ad esempio, immaginate una variabile ordinale come “Body Mass Index” (BMI), BMI), che ha quattro livelli: “Sottopeso”, “Sano/Normale”, “Sovrappeso” e “Obeso”). Infine, la cella sotto la colonna
se avete una variabile indipendente ordinale (ad esempio, immaginate una variabile ordinale come “Body Mass Index” (BMI), BMI), che ha quattro livelli: “Sottopeso”, “Sano/Normale”, “Sovrappeso” e “Obeso”). Infine, la cella sotto la colonna ![]() dovrebbe mostrare
dovrebbe mostrare ![]() .
.
Nota: Suggeriamo di cambiare la cella sotto la colonna ![]() da
da ![]() a
a ![]() , ma non è necessario fare questo cambiamento. Ti suggeriamo di farlo perché ci sono alcune analisi in SPSS Statistics in cui l’impostazione
, ma non è necessario fare questo cambiamento. Ti suggeriamo di farlo perché ci sono alcune analisi in SPSS Statistics in cui l’impostazione ![]() fa sì che le tue variabili vengano trasferite automaticamente in alcuni campi delle finestre di dialogo che stai usando. Poiché potreste non voler trasferire queste variabili, vi suggeriamo di cambiare l’impostazione
fa sì che le tue variabili vengano trasferite automaticamente in alcuni campi delle finestre di dialogo che stai usando. Poiché potreste non voler trasferire queste variabili, vi suggeriamo di cambiare l’impostazione ![]() in
in ![]() in modo che ciò non avvenga automaticamente.
in modo che ciò non avvenga automaticamente.
Ora avete inserito con successo tutte le informazioni che SPSS Statistics ha bisogno di sapere sulla vostra variabile categorica indipendente nella finestra Vista delle variabili. Nella prossima sezione, vi mostreremo come inserire i vostri dati nella finestra Data View.
The Data View in SPSS Statistics
In base alla configurazione del file per la vostra variabile categorica indipendente nella finestra Variable View di cui sopra, la finestra Data View apparirà come segue:
Nota: Potete accedere alla finestra Data View in SPSS Statistics cliccando sulla scheda ![]() in basso a sinistra del software SPSS Statistics.
in basso a sinistra del software SPSS Statistics.
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
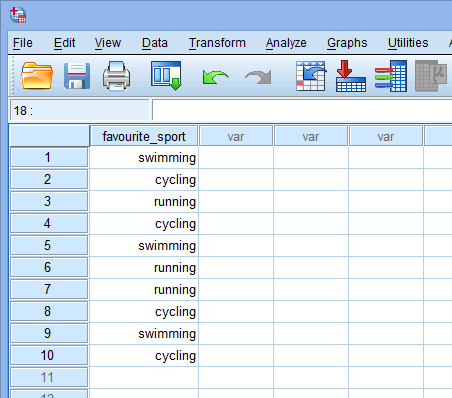
La tua variabile categorica indipendente sarà visualizzata nella prima colonna, poiché questo è l’ordine in cui abbiamo inserito la variabile nella finestra Visualizzazione variabili. Nel nostro esempio, le risposte dei 10 triatleti sono presentate sotto la colonna ![]() . Ora, dovete semplicemente inserire i vostri dati nelle celle sotto questa prima colonna. Ricorda che ogni riga rappresenta un caso (ad esempio, un caso potrebbe essere un singolo partecipante). Pertanto, nella riga
. Ora, dovete semplicemente inserire i vostri dati nelle celle sotto questa prima colonna. Ricorda che ogni riga rappresenta un caso (ad esempio, un caso potrebbe essere un singolo partecipante). Pertanto, nella riga ![]() del nostro esempio, il primo caso rappresenta un triatleta il cui sport preferito è il “nuoto”. Poiché queste celle saranno inizialmente vuote, è necessario cliccare nelle celle per inserire i dati. Noterete che quando cliccherete nelle celle sotto la colonna
del nostro esempio, il primo caso rappresenta un triatleta il cui sport preferito è il “nuoto”. Poiché queste celle saranno inizialmente vuote, è necessario cliccare nelle celle per inserire i dati. Noterete che quando cliccherete nelle celle sotto la colonna ![]() , SPSS Statistics vi darà un’opzione a discesa con le vostre categorie già popolate.
, SPSS Statistics vi darà un’opzione a discesa con le vostre categorie già popolate.
Ora che avete impostato i vostri dati nelle finestre Vista variabili e Vista dati di SPSS Statistics, vi consigliamo di leggere la prossima sezione: Capire le variabili dummy e la codifica dummy, dove spieghiamo i principi di base delle variabili dummy e della codifica dummy. Tuttavia, se avete già familiarità con i fondamenti delle variabili dummy e della codifica dummy, potete saltare questa sezione e andare direttamente alla sezione Procedura, dove esponiamo la procedura Create Dummy Variables in SPSS Statistics che viene utilizzata per creare variabili dummy.
SPSS Statistics
Comprendere le variabili dummy e la codifica dummy
Come abbiamo detto nell’introduzione, se stai analizzando i tuoi dati usando la regressione multipla e una qualsiasi delle tue variabili indipendenti è stata misurata su una scala nominale o ordinale, devi sapere come creare variabili dummy e interpretare i loro risultati. Questo perché le variabili indipendenti categoriche (cioè le variabili indipendenti nominali e ordinali) non possono essere inserite direttamente in una regressione multipla. Invece, hanno bisogno di essere convertite in variabili dummy. L’eccezione è rappresentata dalle variabili indipendenti ordinali che sono inserite in una regressione multipla come variabili indipendenti continue, che non hanno bisogno di essere convertite in variabili dummy. Nelle sezioni seguenti, spieghiamo: (a) il numero di variabili dummy da creare; e (b) come creare le variabili dummy e la codifica dummy.
Il numero di variabili dummy da creare
Il numero di variabili dummy da creare dipenderà da quante categorie ha la vostra variabile indipendente categoriale. Come regola generale, creerete una variabile dummy in meno rispetto al numero di categorie nella vostra variabile categorica indipendente. Per esempio, se avete una variabile categorica indipendente con tre categorie (per esempio, favorite_sport, con le seguenti tre categorie: “nuoto”, “ciclismo” e “corsa”), creerete due variabili dummy e selezionerete una categoria che funga da categoria di riferimento (ad esempio, “nuoto” e “ciclismo” diventano variabili dummy e “corsa” diventa la categoria di riferimento). Spieghiamo meglio le categorie di riferimento dopo la seguente tabella, che fornisce alcuni esempi di variabili indipendenti categoriali e il numero di variabili dummy che devono essere create:
| Nome della variabile categorica indipendente | Tipo di variabile | Numero di categorie | Numero di variabili dummy | ||||
|---|---|---|---|---|---|---|---|
| 1 | Gender | Nominale | Due (Maschi & Femmine) |
Uno=Maschi “Femmine” è la categoria di riferimento |
|||
| 2 | Height | Ordinal | Two (Under 180cm & 180cm e oltre) |
One=Under 180cm “180cm e oltre” è la categoria di riferimento |
|||
| 3 | Ethnicity | Nominal | Three (African American, Caucasico & Ispanico) |
Due=Africano americano & Caucasico “Ispanico” è la categoria di riferimento |
|||
| 4 | Livello attività fisica | Ordinale | Tre (Basso, Moderato & Alto) |
Due=Basso & Moderato “Alto” è la categoria di riferimento |
|||
| 5 | Professione | Nominale | Quattro (Chirurgo, Medico, Infermiere & Terapista) |
Tre=Chirurgo, Medico & Infermiere “Terapista” è la categoria di riferimento |
|||
| 6 | Livello di accordo | Ordinale | Quattro (Molto d’accordo, D’accordo, Disagree, Strongly disagree) |
Tre=Fortemente d’accordo, Agree & Disagree “Strongly disagree” è la categoria di riferimento |
|||
| 7 | Area tematica | Nominale | Cinque (Studi di business, Psicologia, Scienze biologiche, Ingegneria & Diritto) |
Quattro=Studi commerciali, Psicologia, Scienze biologiche & Ingegneria “Diritto” è la categoria di riferimento |
|||
| 8 | Età | Ordinale | Cinque (Under 18, 19-30, 31-40, 41-50, 51-60) |
Quattro=Under 18, 19-30, 31-40 & 41-50 “51-60” è la categoria di riferimento |
|||
| Tabella: Esempi di variabili indipendenti categoriche e le loro rispettive variabili dummy | |||||||
Come mostrato nella tabella sopra, avete solo bisogno di creare una variabile dummy in meno rispetto al numero di categorie nella vostra variabile indipendente categorica. Questo perché avete solo bisogno di (e dovreste) trasferire questo numero di variabili dummy in una regressione multipla quando avete una variabile indipendente categorica. Tuttavia, ci sono buone ragioni per creare una variabile dummy per ogni categoria della variabile indipendente categoriale: (a) è più flessibile e (b) permette di fare confronti multipli (vedi la nota sotto). In altre parole, se la vostra variabile categorica indipendente ha tre categorie, dovreste creare tre variabili dummy, non solo due.
Fortunatamente, la procedura Create Dummy Variables in SPSS Statistics versione 22 e superiore crea automaticamente una variabile dummy per ogni categoria della vostra variabile categorica indipendente. Tuttavia, questo non è il caso della procedura Recode into Different Variables in SPSS Statistics versione 21 o precedente. Pertanto, in circostanze normali, avrete creato la seguente configurazione in SPSS Statistics, a seconda che abbiate la versione 21 o precedente o la versione 22 e superiore:
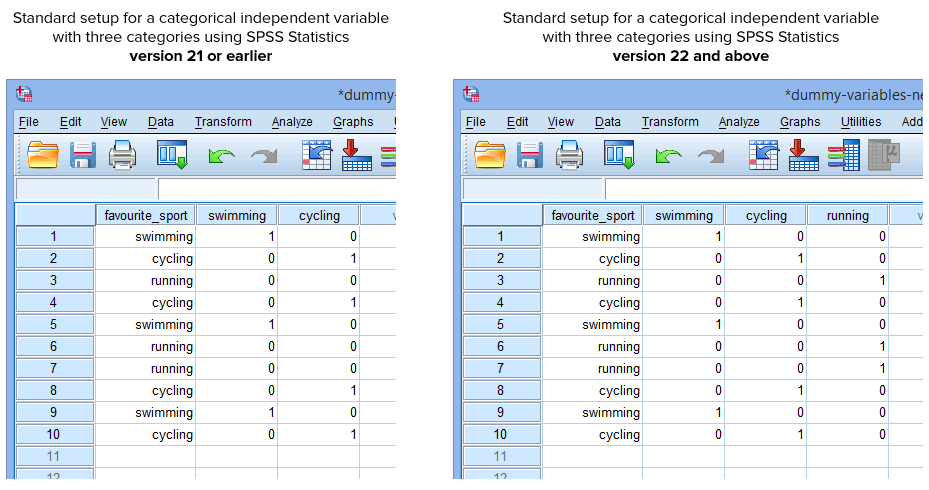
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota: Come detto sopra, creare una variabile dummy per ogni categoria della variabile indipendente categorica è vantaggioso per due motivi: (a) è più flessibile e (b) permette di fare confronti multipli. Accenniamo brevemente a questi vantaggi di seguito:
È più flessibile:
Quando avete creato una variabile dummy per ogni categoria della vostra variabile indipendente categoriale, potete considerare qualsiasi categoria come categoria di riferimento. Nel nostro esempio, abbiamo considerato la categoria “corsa” come categoria di riferimento, il che significa che avremmo trasferito “nuoto” e “ciclismo” nell’equazione di regressione multipla. Tuttavia, se in seguito cambiassimo idea sulla nostra scelta della categoria di riferimento, dovremmo eseguire nuovamente la procedura della variabile dummy (a meno che non abbiate SPSS Statistics versione 22 o superiore). Per esempio, supponiamo di voler considerare la categoria “ciclismo” come categoria di riferimento. Potremmo ora trasferire le variabili dummy “nuoto” e “corsa” nell’equazione di regressione multipla perché abbiamo anche la variabile dummy “corsa”.
Permette di fare confronti multipli:
Il coefficiente di una variabile dummy rappresenta la differenza tra la categoria che la variabile dummy rappresenta e la categoria di riferimento. Per esempio, con “corsa” come categoria di riferimento, il coefficiente della variabile dummy “nuoto” rappresenta la differenza nella variabile dipendente tra le categorie “nuoto” e “corsa”. Usando questo metodo, non tutte le combinazioni di categorie saranno possibili. Questo problema può essere risolto utilizzando diverse categorie di riferimento. Questo è possibile se tutte le categorie della variabile categorica hanno una variabile dummy.
Come creare variabili dummy e codifica dummy
Ci sono due passi per impostare con successo le variabili dummy in una regressione multipla: (1) creare variabili dummy che rappresentano le categorie della vostra variabile indipendente categorica; e (2) inserire valori in queste variabili dummy – conosciute come codifica dummy – per rappresentare le categorie della variabile indipendente categorica. Spieghiamo questo processo di seguito usando l’esempio che abbiamo esposto sopra.
Spiegazione: Le variabili dummy sono semplicemente nuove variabili che fungono da “segnaposto” per un particolare schema di codifica. Non contengono alcun dato, di per sé. Invece, i dati/valori devono essere aggiunti a queste variabili dummy in modo che possano adempiere al loro scopo di rappresentare le categorie della vostra variabile indipendente categorica. Ci sono molti tipi diversi di schemi di codifica che dettano i valori che vengono inseriti nelle variabili dummy, ma noi usiamo uno schema di codifica molto comune chiamato codifica dummy o, in alternativa, codifica degli indicatori (N.B., non confondetevi perché le variabili dummy e la codifica dummy non sono la stessa cosa). La codifica dummy funziona usando ogni variabile dummy per identificare una categoria specifica di una variabile indipendente categorica con l’eccezione di una categoria di riferimento, che spieghiamo di seguito.
Iniziamo a considerare il nostro esempio di variabile indipendente categorica, sport_favorito, che ha tre categorie: “nuoto”, “ciclismo” e “corsa”. Poiché ci sono tre categorie, ci devono essere due variabili dummy che rappresentano due delle categorie, e una categoria di riferimento che rappresenta la terza categoria.
Nota: Ricordate dalla discussione precedente che una regressione multipla richiede di trasferire una variabile dummy in meno rispetto al numero di categorie nella vostra variabile indipendente categoriale (cioè, due nel nostro esempio). Tuttavia, è possibile creare una variabile dummy per ogni categoria della variabile indipendente categoriale ai fini di una maggiore flessibilità e la capacità di fare confronti multipli. Ciononostante, nella discussione che segue sottolineiamo solo ciò che è richiesto per una regressione multipla; cioè, la creazione di una variabile dummy in meno rispetto al numero di categorie nella vostra variabile indipendente categoriale con la categoria che non è direttamente rappresentata che diventa la “categoria di riferimento”.
Per esempio, lasciamo che la variabile dummy #1 rappresenti la categoria “nuoto” e la variabile dummy #2 la categoria “ciclismo”. Questo lascia nessuna variabile dummy per la categoria “corsa”. Questa categoria “mancante” è la categoria di riferimento e non è necessaria. Inoltre, è interamente una vostra decisione quale categoria volete usare come categoria di riferimento. Avremmo potuto benissimo scegliere la categoria “nuoto” come categoria di riferimento piuttosto che la categoria “corsa”. L’unico motivo per cui non l’abbiamo fatto è che, per impostazione predefinita, SPSS Statistics utilizza come categoria di riferimento l’ultima categoria che avete codificato nella Vista Variabile per la vostra variabile categorica indipendente (vedere la nota sotto).
Nota: Come spiegato nella sezione Impostazione dei dati in precedenza e come mostrato sotto nella finestra di dialogo Etichette dei valori, la terza e ultima categoria della nostra variabile categorica indipendente era “corsa” (cioè, 3=”corsa”).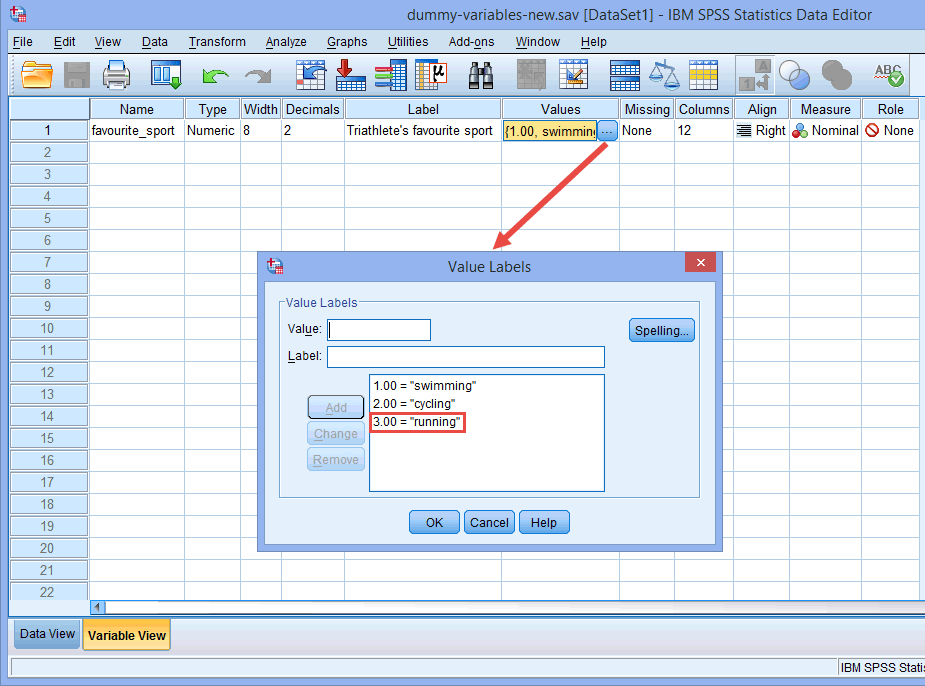
Non c’era alcuna ragione teorica o statistica per rendere la categoria “corsa” la terza e ultima categoria, che la rendeva la categoria di riferimento in SPSS Statistics per impostazione predefinita. L’abbiamo semplicemente fatto in questo modo perché quando i triatleti partecipano a un triathlon, fanno prima il nuoto, poi intraprendono un ciclo, prima di correre finalmente verso il traguardo. Pertanto, sembrava logico codificare la nostra variabile indipendente categorica in questo modo. Tuttavia, avremmo potuto codificarla come 1=ciclismo, 2=corsa e 3=nuoto; non avrebbe fatto alcuna differenza se non per il fatto che, come terza e ultima categoria, “nuoto” sarebbe diventata la nostra categoria di riferimento di default in SPSS Statistics.
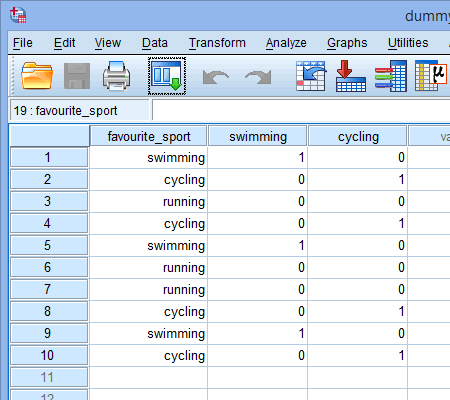
Quando si creano variabili dummy si dovrebbe dare loro un nome significativo. Poiché ciascuna delle nostre variabili dummy rappresenta una categoria della nostra variabile indipendente categorica, è consuetudine riferirsi a ciascuna variabile dummy con il nome della categoria che rappresenta. Pertanto, abbiamo chiamato la variabile dummy #1 “nuoto” in quanto rappresenta la categoria del nuoto. Allo stesso modo, abbiamo chiamato la variabile dummy #2 “ciclismo” in quanto rappresenta la categoria del ciclismo. Creando queste due variabili dummy, avremo due nuove colonne nel nostro set di dati in SPSS Statistics, come mostrato di seguito:
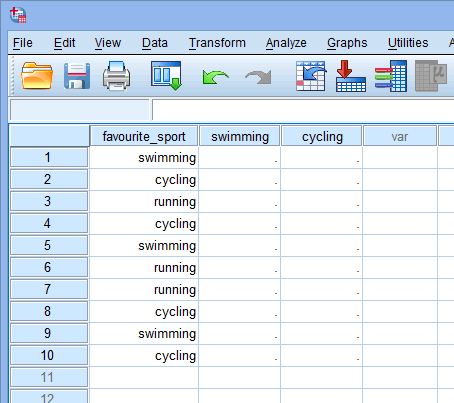
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Ora che abbiamo creato due variabili dummy e dato loro nomi appropriati, abbiamo bisogno di inserire valori in queste variabili in modo che ogni variabile dummy rappresenti davvero la sua categoria della variabile indipendente categoriale. Con la codifica dummy questo è molto semplice. Si inserisce un “1” per rappresentare qualsiasi caso (ad esempio, un partecipante nel vostro set di dati) che ha la categoria e si inserisce uno “0” (zero) se non hanno la categoria. Per prima cosa, considerate la variabile dummy “nuoto”, come mostrato di seguito:
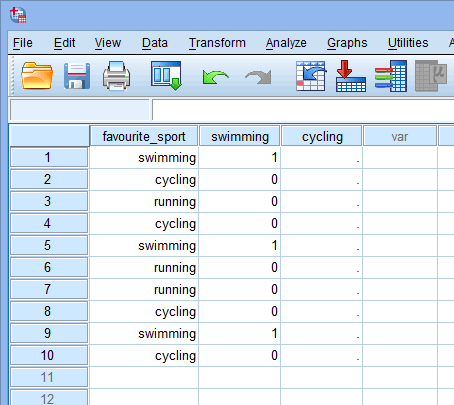
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Se uno dei triatleti ha dichiarato che il “nuoto” è il suo sport “preferito”, dovremmo inserire un “1” nella cella sotto la colonna della variabile dummy del nuoto (![]() ) per quel triatleta che ha dichiarato che il nuoto è il suo sport “preferito”. In alternativa, se uno dei triatleti ha dichiarato che il “ciclismo” o la “corsa” era il suo sport “preferito”, inseriremo uno “0” nella cella sotto la colonna della variabile dummy del nuoto (
) per quel triatleta che ha dichiarato che il nuoto è il suo sport “preferito”. In alternativa, se uno dei triatleti ha dichiarato che il “ciclismo” o la “corsa” era il suo sport “preferito”, inseriremo uno “0” nella cella sotto la colonna della variabile dummy del nuoto (![]() ) per quel triatleta che ha dichiarato che il nuoto era “non” il suo sport preferito (cioè, questo significa che il “ciclismo” o la “corsa” erano lo sport preferito di quel triatleta). Questo è evidenziato di seguito per tutti i 10 triatleti:
) per quel triatleta che ha dichiarato che il nuoto era “non” il suo sport preferito (cioè, questo significa che il “ciclismo” o la “corsa” erano lo sport preferito di quel triatleta). Questo è evidenziato di seguito per tutti i 10 triatleti:
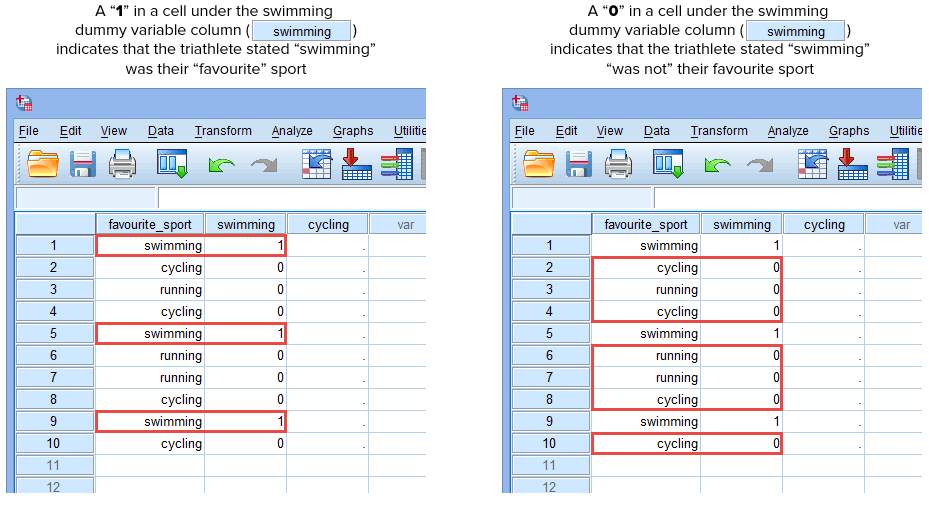
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Ripetiamo questo processo per l’altra variabile dummy, “ciclismo”, come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Se uno dei triatleti ha dichiarato che il “ciclismo” è il suo sport “preferito”, dovremmo inserire un “1” nella cella sotto la colonna della variabile dummy del ciclismo (![]() ) per quel triatleta che ha dichiarato che il ciclismo è il suo sport “preferito”. In alternativa, se uno dei triatleti ha dichiarato che il “nuoto” o la “corsa” era il suo sport “preferito”, inseriremo uno “0” nella cella sotto la colonna della variabile dummy del ciclismo (
) per quel triatleta che ha dichiarato che il ciclismo è il suo sport “preferito”. In alternativa, se uno dei triatleti ha dichiarato che il “nuoto” o la “corsa” era il suo sport “preferito”, inseriremo uno “0” nella cella sotto la colonna della variabile dummy del ciclismo (![]() ) per quel triatleta che ha dichiarato che il ciclismo era “non” il suo sport preferito (cioè, questo significa che il “nuoto” o la “corsa” erano gli sport preferiti di quel triatleta). Questo è evidenziato di seguito per tutti i 10 triatleti:
) per quel triatleta che ha dichiarato che il ciclismo era “non” il suo sport preferito (cioè, questo significa che il “nuoto” o la “corsa” erano gli sport preferiti di quel triatleta). Questo è evidenziato di seguito per tutti i 10 triatleti:
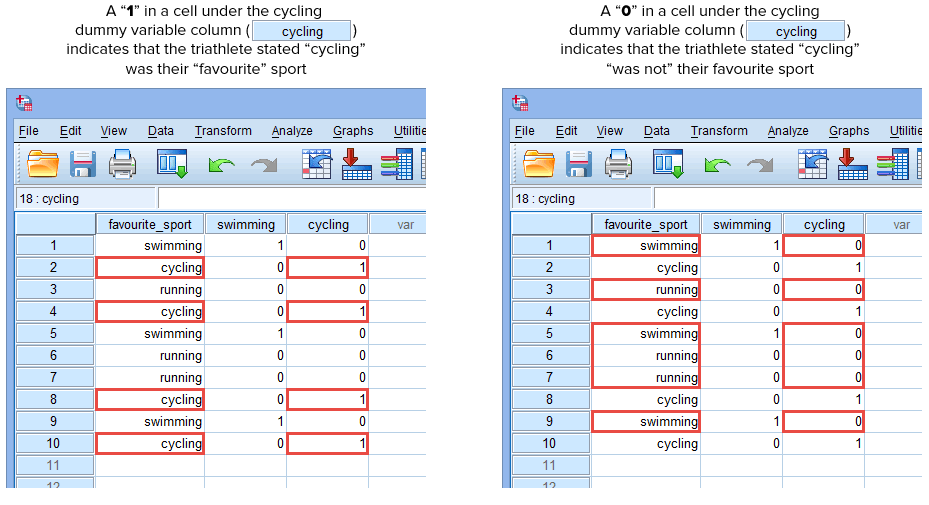
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Inserendo “1” e “0” nelle vostre variabili dummy in questo modo, avrete creato un set di variabili dummy che potete inserire in un’analisi di regressione multipla. Nella sezione della procedura che segue, vi mostriamo come creare queste variabili dummy usando la procedura Create Dummy Variables.
SPSS Statistics
Procedura in SPSS Statistics per creare variabili dummy
Ci sono due procedure in SPSS Statistics per creare variabili dummy: la procedura Create Dummy Variables e la procedura Recode into Different Variables. In questa guida, vi mostriamo come usare la procedura Create Dummy Variables, che è una semplice procedura in 3 passi. Tuttavia, è disponibile solo se avete SPSS Statistics versione 22 o successiva, mentre la versione 26 (e la versione in abbonamento di SPSS Statistics) è l’ultima versione di SPSS Statistics. Se non sei sicuro di quale versione di SPSS Statistics stai utilizzando, consulta la nostra guida: Identificare la tua versione di SPSS Statistics. Se si dispone di SPSS Statistics versione 21 o precedente o se si è interessati a effettuare confronti multipli quando si esegue l’analisi di regressione multipla, consultare la nota seguente:
Nota: Se si dispone di SPSS Statistics versione 21 o precedente, non è possibile utilizzare la procedura Create Dummy Variables. Pertanto, la procedura Recode into Different Variables vi permette almeno di creare variabili dummy in SPSS Statistics. Sebbene sia possibile utilizzare anche la procedura Recode into Different Variables per creare delle variabili dummy se avete SPSS Statistics versione 22 o successiva, in questa guida abbiamo esposto la procedura Create Dummy Variables perché è dedicata alla creazione di variabili dummy ed è molto più semplice e veloce da utilizzare. Per esempio, richiede solo 3 passi per creare variabili dummy per l’esempio usato in questa guida rispetto ai 28 passi per lo stesso esempio usando la procedura Recode into Different Variables.
Quindi, se avete SPSS Statistics versione 21 o precedente, la nostra guida migliorata su Creare variabili dummy nella sezione membri su Laerd Statistics include una pagina dedicata a mostrare come eseguire questa procedura di 28 passi Recode into Different Variables. Potete accedere a questa guida migliorata abbonandovi a Laerd Statistics. In alternativa, è possibile utilizzare semplicemente la procedura Create Dummy Variables di seguito.
Per creare le variabili dummy quando si dispone di SPSS Statistics versione 22 o successiva, seguire la procedura in 3 passi Create Dummy Variables di seguito:
- Cliccare Transform > Create Dummy Variables sul menu principale, come mostrato di seguito:

Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Vi verrà presentata la finestra di dialogo Create Dummy Variables, come mostrato di seguito:
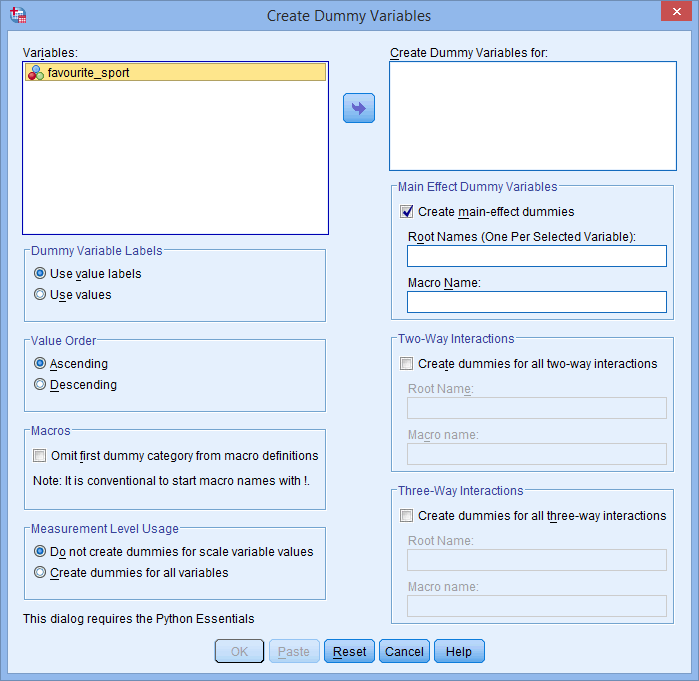
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Trasferite la variabile indipendente categorica, favourite_sport, nella casella Create Dummy Variables for: selezionandola (cliccando su di essa) e poi cliccando sul pulsante
 . Inoltre, inserite un nome “radice” che possa rappresentare tutte le nuove variabili dummy nella casella Root Names (One Per Selected Variable): nell’area -Main Effect Dummy Variables-. Abbiamo inserito il nome radice “fs” come abbreviazione per la nostra variabile categorica indipendente, “favourite_sport”, come mostrato di seguito:
. Inoltre, inserite un nome “radice” che possa rappresentare tutte le nuove variabili dummy nella casella Root Names (One Per Selected Variable): nell’area -Main Effect Dummy Variables-. Abbiamo inserito il nome radice “fs” come abbreviazione per la nostra variabile categorica indipendente, “favourite_sport”, come mostrato di seguito:
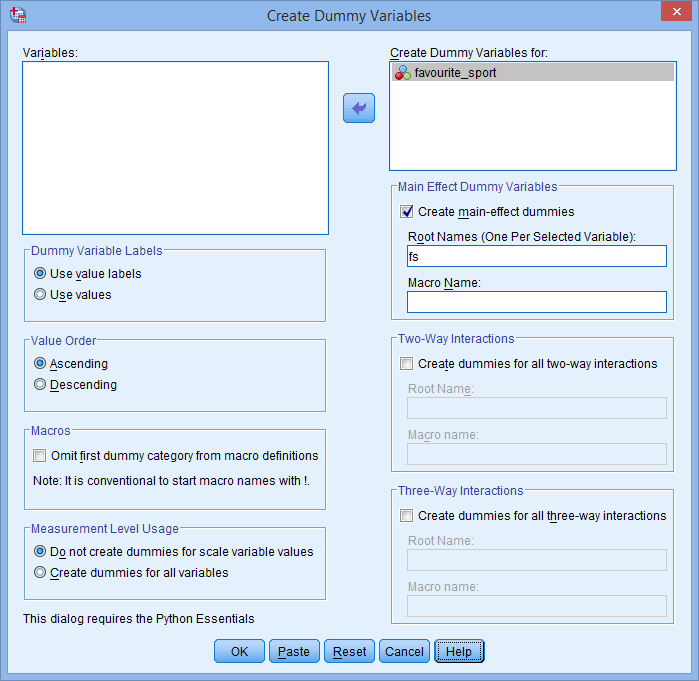
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota: SPSS Statistics aggiungerà un numero sequenziale (cioè, 1, 2, 3, 4, ecc.) alla fine del nome radice scelto per rappresentare la variabile categorica indipendente. Un numero sequenziale sarà creato per ciascuna delle variabili fittizie che volete creare (per esempio, se avete due variabili fittizie, un 1 e un 2 saranno aggiunti alla fine del nome della radice, ma se avete sei variabili fittizie, un 1, 2, 3, 4, 5 e 6 saranno aggiunti alla fine del nome della radice). Questo è mostrato per il nostro esempio nella finestra Vista delle variabili qui sotto:
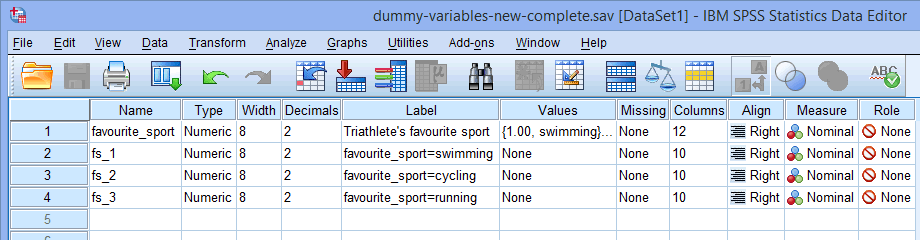
Siccome la nostra variabile indipendente categorica, favourite_sport, ha tre categorie (cioè, nuoto, ciclismo e corsa), la procedura Crea Variabili Dummy crea tre variabili dummy (cioè, una per il nuoto, una per il ciclismo e una per la corsa). Queste tre variabili fittizie sono evidenziate nella colonna qui sopra: “fs_1” (per il nuoto), “fs_2” (per il ciclismo) e “fs_3” (per la corsa). Potete rinominarle in seguito in modo che abbiano più senso. Stiamo solo evidenziando questo in modo che sappiate come funziona la casella Root Names (One Per Selected Variable): sopra.
qui sopra: “fs_1” (per il nuoto), “fs_2” (per il ciclismo) e “fs_3” (per la corsa). Potete rinominarle in seguito in modo che abbiano più senso. Stiamo solo evidenziando questo in modo che sappiate come funziona la casella Root Names (One Per Selected Variable): sopra.
Inoltre, il nome della radice che inserite nella casella Root Names (One Per Selected Variable): non può essere lo stesso del nome della vostra variabile categorica indipendente, come mostrato sotto (cioè, dove abbiamo inserito il nome della radice, “favourite_sport”, per illustrare come non potremmo chiamare il nostro nome della radice):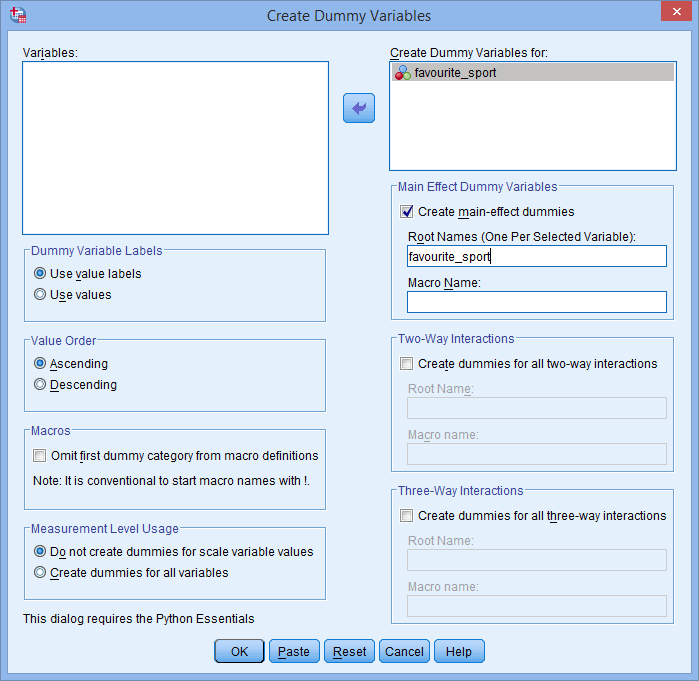
Se il nome della radice che inserite è lo stesso del nome della vostra variabile categorica indipendente, come mostrato sopra, quando cliccate sul pulsante , riceverete il seguente avviso:
, riceverete il seguente avviso:
- Cliccate sul pulsante .
Dopo aver eseguito la procedura in 3 passi Create Dummy Variable, avrete creato delle variabili dummy per la vostra variabile indipendente categorica. Nella prossima sezione, evidenziate l’output che viene creato nella Vista Variabili e nella Vista Dati di SPSS Statistics dopo l’esecuzione della procedura Create Dummy Variables.
SPSS Statistics
Output e impostazione dei dati in SPSS Statistics dopo la creazione delle variabili dummy
Dopo aver creato le vostre variabili dummy, SPSS Statistics produce la seguente tabella di creazione delle variabili nel suo IBM SPSS Statistics Viewer:
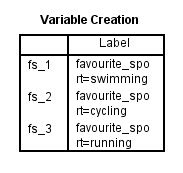
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
La tabella di creazione delle variabili conferma che avete creato con successo le variabili fittizie. Ci dovrebbero essere tante righe quante sono le nuove variabili fittizie. Poiché abbiamo creato tre variabili fittizie, ci sono tre righe nella tabella, “fs_1”, “fs_2” e “fs_3”, che riflettono il nome principale e la numerazione sequenziale inseriti nel passo 2 della procedura Create Dummy Variables nella sezione precedente. Per ognuna di queste variabili dummy, viene fornita un’etichetta nella tabella per rendere chiaro quale categoria della variabile indipendente categorica ogni variabile dummy rappresenta. Per esempio, l’etichetta, “favourite_sport=nuoto”, è fornita per “fs_1”, indicando che “fs_1” è la variabile dummy per la categoria “nuoto” della variabile categorica indipendente, favorite_sport.
Poi, vai alla finestra Variable View di SPSS Statistics cliccando sulla scheda ![]() . Le tre variabili dummy saranno state aggiunte, come mostrato di seguito (cioè le variabili dummy, “fs_1”, “fs_2” e “fs_3”, nella colonna
. Le tre variabili dummy saranno state aggiunte, come mostrato di seguito (cioè le variabili dummy, “fs_1”, “fs_2” e “fs_3”, nella colonna ![]() ):
):
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota: Potete cambiare i nomi delle variabili dummy nella colonna ![]() per rendere più chiaro cosa sono. Per esempio, abbiamo cambiato “fs_1” in “nuoto”, “fs_2” in “ciclismo” e “fs_3” in “corsa”, come mostrato di seguito:
per rendere più chiaro cosa sono. Per esempio, abbiamo cambiato “fs_1” in “nuoto”, “fs_2” in “ciclismo” e “fs_3” in “corsa”, come mostrato di seguito:
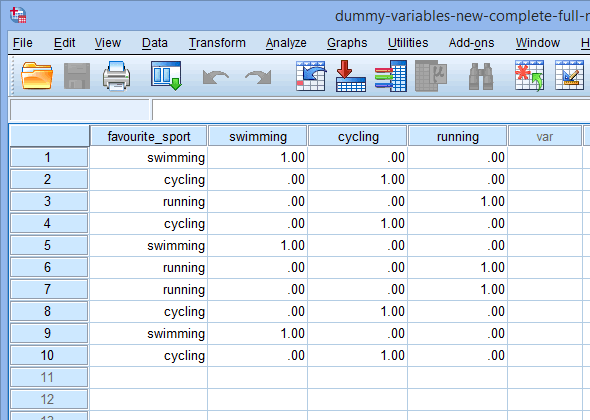
Infine, vai alla finestra Data View di SPSS Statistics cliccando sulla scheda ![]() . La codifica dei dummy è mostrata sotto ciascuna delle variabili dummy che sono state create. Per esempio, nelle righe sotto la colonna “fs_1”, la categoria “nuoto” è codificata come “1.00”, mentre le categorie “ciclismo” e “corsa” sono codificate come “.00”, come mostrato sotto. Se non siete sicuri del perché queste variabili dummy sono codificate in questo modo, consultate la sezione: Capire le variabili dummy e la codifica dummy.
. La codifica dei dummy è mostrata sotto ciascuna delle variabili dummy che sono state create. Per esempio, nelle righe sotto la colonna “fs_1”, la categoria “nuoto” è codificata come “1.00”, mentre le categorie “ciclismo” e “corsa” sono codificate come “.00”, come mostrato sotto. Se non siete sicuri del perché queste variabili dummy sono codificate in questo modo, consultate la sezione: Capire le variabili dummy e la codifica dummy.
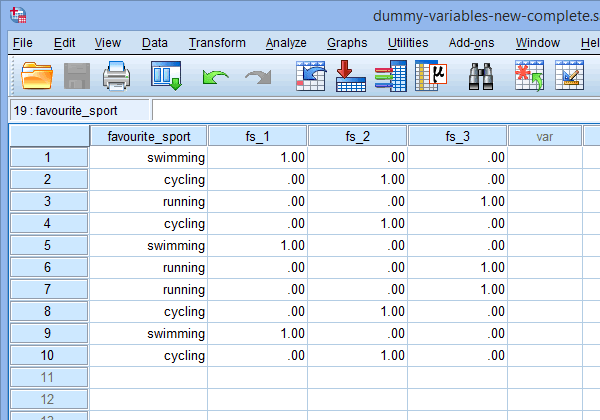
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota 1: A causa delle impostazioni predefinite di SPSS Statistics, le vostre variabili dummy saranno codificate “1.00” o “.00” invece di “1” o “0”, rispettivamente. Sono identici. Tuttavia, vedrete spesso la codifica delle variabili dummy scritta in termini di 1 e 0 piuttosto che includere i decimali.
Nota 2: Se avete cambiato i nomi delle variabili dummy nella colonna ![]() della finestra Vista variabili sopra, questi saranno stati cambiati anche nelle colonne della finestra Vista dati, come mostrato di seguito (ad esempio, l’intestazione della colonna
della finestra Vista variabili sopra, questi saranno stati cambiati anche nelle colonne della finestra Vista dati, come mostrato di seguito (ad esempio, l’intestazione della colonna ![]() è ora intitolata
è ora intitolata ![]() ):
):