Le proteine ancorate a GPI sono l’eccezione. Nella biologia cellulare introduttiva, ci hanno insegnato che c’erano cinque tipi di proteine di membrana, chiamate come segue: Tipo I, Tipo II, Tipo III, Tipo IV e GPI-anchored. Perché abbiamo questa strana classe di proteine fuse ad una catena di zuccheri e grassi? Cosa fanno? Possiamo ottenere qualche intuizione sulla mia proteina di interesse – PrP – imparando di più su questa classe di proteine di cui fa parte?
Sonia, io e il nostro compagno di squadra Andrew e abbiamo letto qualcosa su questo argomento e sto scrivendo questo post sul blog per condividere parte di ciò che abbiamo imparato.
lettura
Abbiamo iniziato leggendo alcune recensioni. Queste riguardavano soprattutto la struttura e la biogenesi dell’ancora GPI stessa, di cui si sa un’incredibile quantità.
Questa ancora, il cui nome completo è glicosilfosfatidilinositolo, non è un monolite: è una descrizione generale di una molecola i cui dettagli possono variare. In generale, a partire dall’ω (ultimo residuo post-traslazionale) della proteina, si ha etanolamina, poi un fosfato, poi alcuni zuccheri, poi un fosfolipide. La spina dorsale dello zucchero è conservata, ma le catene laterali che si diramano da essa possono variare, e anche il gruppo di testa del fosfolipide e gli acidi grassi possono variare. L’ancora GPI di PrP è stata caratterizzata in , ma anche allora non è un monolite – hanno identificato almeno sei diverse strutture che differiscono nella composizione della catena laterale dello zucchero.
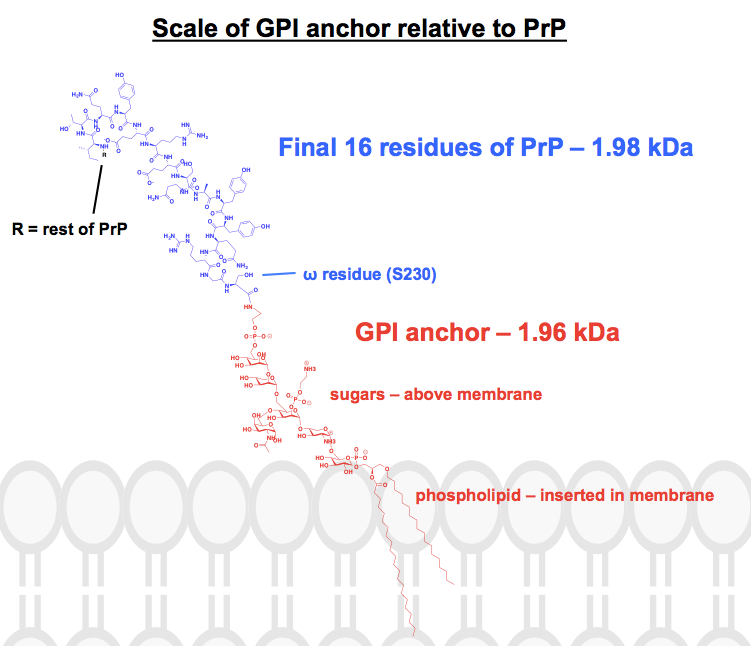
Ogni struttura chimica che ho trovato di ancore GPI ha almeno alcune parti abbreviate o riassunte, e la proteina è di solito solo mostrata come immagine. Volevo farmi un’idea di come sono in realtà queste ancore dal punto di vista chimico, nel contesto delle loro proteine collegate, così ho deciso di disegnare una struttura completa in ChemDraw. Lavorando dalla Figura 1 di – la cosa più vicina a una struttura scheletrica completa che ho potuto trovare – ho aggiunto i dettagli di una delle ancore GPI di PrP dal pannello superiore della Figura 6. Il peso molecolare è arrivato a 1.958 Da, così per il contesto ho disegnato i 16 residui finali di HuPrP23-230, che pesano in modo comparabile, a 1.979 Da. Questo è circa l’8% della sequenza di PrP modificata post-traslazione. Non sono certo di aver azzeccato tutti i legami, ma ecco cosa mi è venuto in mente:
In molti casi, un gene ha isoforme multiple, con un prodotto di splicing che dà origine a una proteina ancorata a GPI mentre altri danno origine a forme secrete o transmembrana. Gli esempi includono NCAM1, che ha tre isoforme principali, una delle quali è ancorata a GPI e le altre due sono transmembrana, e ACHE (che codifica l’acetilcolinesterasi), la cui forma ancorata a GPI si trova apparentemente solo sui globuli rossi (NCBI Genes). La storia più affascinante è quella del gene murino Ly6a che, grazie a un polimorfismo genetico, è ancorato a GPI in alcuni ceppi di topi e non in altri. Solo nella sua forma ancorata a GPI, agisce come recettore per il vettore virale AAV PHP.eB. (Questo vettore raggiunge un assorbimento incredibilmente efficiente nei neuroni del cervello per la terapia genica, ma purtroppo, è un gene del topo solo – noi umani non abbiamo nemmeno Ly6a).
Si sa molto su come le ancore GPI vengono sintetizzate e attaccate alle proteine, con >20 proteine coinvolte nel percorso, la maggior parte delle quali inizia con il prefisso “PIG” e sono codificate da geni come PIGA, PIGK, e così via – vedi Figura 2 per un diagramma. La maggior parte della biosintesi avviene con l’ancora inserita nella membrana nell’ER ma non attaccata ad alcuna proteina. Infatti, i primi passi avvengono sul foglietto citosolico della membrana, e solo più tardi l’ancora si sposta sul lato lumenale (all’interno dell’ER). Il passo finale è quando la transamidasi GPI, un complesso composto da almeno cinque proteine, taglia il segnale GPI dal terminale C della proteina e attacca l’ancora GPI al cosiddetto residuo ω della proteina (l’ultimo residuo nella sequenza modificata post-traslazionalmente). C’è poi un’ulteriore maturazione dell’ancora GPI mentre la proteina migra fuori dall’ER verso la superficie cellulare.
Esistono una serie di inibitori di piccole molecole della biosintesi di GPI nei funghi, alcuni dei quali hanno cercato di sviluppare come farmaci antifungini, ma per quanto ho potuto dire, l’unico inibitore noto della biosintesi di GPI nelle cellule dei mammiferi è la mannosamina, un analogo del mannosio che è chimicamente incompatibile con l’incorporazione in GPI.
Ho cercato e ricercato un logo di sequenza di quale motivo di sequenza di aminoacidi riconosce la transamidasi GPI, ma non ne ho trovato nessuno. Apparentemente il motivo di sequenza è abbastanza sciolto, e apparentemente i segnali GPI non sono nemmeno omologhi, il che significa che non si sono evoluti da una sequenza ancestrale comune, ma piuttosto si sono evoluti in modo convergente, nella misura in cui c’è persino una convergenza. La migliore descrizione che sono riuscito a trovare è che (leggendo da N a C-terminale fino alla fine della proteina) avete bisogno di 1) circa 11 residui di un linker non strutturato, 2) alcuni residui con piccole catene laterali tra cui un residuo ω che può essere sia S, N, D, G, A, o C, 3) un distanziatore di 5-10 aminoacidi polari, e infine 4) 15-20 aminoacidi idrofobici. PrP segue vagamente questo motivo. Secondo le strutture pubblicate, l’alfa-elica 3 termina al residuo Q223, che lascia il ‘linker non strutturato’ come solo AYYQR (un po’ più corto degli 11 residui prescritti). La regione della ‘piccola catena laterale’ sarebbe GS|SM (con il tubo che denota il sito di taglio della transamidasi), la regione polare sarebbe VLFSSPP, e il terminale C idrofobico come VILLISFLIFLIVG.
Alcune delle proteine nella biosintesi di GPI e nella via di attacco sono molto importanti, e sono state descritte una serie di gravi malattie e sindromi da carenza di ancoraggio di GPI, dovute a mutazioni missense bialleliche loss-of-function o apparentemente ipomorfe in geni come PIGO, PIGV, PIGW, PGAP2 e PGAP3 .
Sonia ha trovato un eccellente documento di qualche anno fa dove hanno fatto uno screening di mutagenesi in cellule umane aploidi per identificare i geni necessari per la biogenesi di due proteine ancorate a GPI: PrP e CD59 . Hanno usato ripetuti FACS ordinamento delle cellule in base alla superficie cellulare PrP e CD59 al fine di identificare le cellule con livelli di superficie drammaticamente ridotti di queste proteine, e poi ha fatto il sequenziamento per vedere quale gene knockout sono stati arricchiti in quelle cellule rispetto alla popolazione dei genitori. Come ci si aspetterebbe, la maggior parte dei geni PIG è venuta fuori per entrambe le proteine (Figura 4), ma non tutti i colpi si sono sovrapposti, il che è un po’ sorprendente, soprattutto perché a livello di RNA, almeno, PrP e CD59 sono due delle proteine con i profili di espressione più simili tra i tessuti (vedi mappa di calore in fondo a questo post). Un gruppo di enzimi coinvolti nella modifica della catena laterale dell’ancora GPI è risultato solo per CD59, suggerendo che CD59, ma non PrP, ha bisogno di queste catene laterali complesse per maturare e raggiungere la superficie cellulare. Nel frattempo, Sec62 e Sec63 si sono rivelati solo per PrP – queste sono proteine in qualche modo coinvolte nella traslocazione co-traslazionale nell’ER, ma apparentemente, sono necessarie per PrP ma non per CD59 né per CD55 o CD109, altre due proteine di controllo che hanno esaminato. Questo è un nuovo affascinante capitolo nella risposta alla mia domanda, “c’è qualcosa di speciale nell’espressione della PrP?”, dove stavo cercando qualcosa di unico sulla biogenesi della PrP che potrebbe essere potenzialmente bersaglio di una piccola molecola. Naturalmente, solo perché queste proteine non erano importanti per altre tre proteine di controllo in non significa che non sono importanti – uno studio ha trovato che Sec62 era necessario per la secrezione di molte piccole proteine, e il gene SEC62 è totalmente impoverito per le varianti di perdita di funzione nella popolazione umana, abbastanza per suggerire aploinsufficienza. SEC63 sembra meno vincolato, anche se questo potrebbe solo significare che agisce in modo recessivo.
Nessuno dei precedenti risponde alla domanda sul perché le proteine ancorate a GPI esistono. Il mio vecchio corso di biologia cellulare ha omesso un dettaglio: c’è in realtà una sesta classe di proteine di membrana, chiamate proteine ancorate alla coda (TA), che hanno solo un terminale C idrofobico che si attacca alla membrana ma non sporge dall’altro lato. Perché tutte queste proteine ancorate a GPI non potrebbero essere solo proteine TA? Perché le cellule hanno evoluto un percorso così complicato per sintetizzare un’ancora zucchero-grasso, e perché l’hanno fatto così presto – le ancore GPI sono presenti in tutti gli eucarioti, compresi molti patogeni unicellulari che infettano gli esseri umani.
La maggior parte delle recensioni non ha dedicato molto tempo a questa domanda, probabilmente perché è la cosa più difficile a cui rispondere. Le stesse proteine ancorate a GPI, nella misura in cui le loro funzioni native sono note, hanno un’enorme gamma di funzioni – ci sono enzimi (come AChE), molecole di adesione cellulare (come NCAM1), proteine che regolano il complemento nel sistema immunitario (CD59), e così via. C’è apparentemente almeno una proteina ancorata a GPI coinvolta nel mantenimento della mielina nei nervi periferici. Ma cosa possono fare esattamente le proteine ancorate a GPI che altre proteine non possono fare? Una recensione cita alcune idee che sono state proposte. Una è che le proteine ancorate a GPI sono brave a dimerizzare transitoriamente. Alcuni studi hanno esplorato l’idea che l’omodimerizzazione giochi un qualche ruolo nella biologia dei prioni, anche se la rilevanza dei sistemi modello utilizzati alla situazione in vivo non è ancora chiara. Un’altra idea è che, poiché le proteine ancorate a GPI possono essere liberate dalla superficie cellulare, per esempio dall’enzima di conversione dell’angiotensina (ACE), la loro localizzazione può essere regolata in qualche modo dinamico. Anche qui, sappiamo che la PrP può essere liberata, apparentemente dall’enzima ADAM10 , anche se non è ancora chiaro il suo ruolo nella funzione nativa della PrP. Una terza idea, e forse quella di cui ho sentito parlare di più, è che le proteine ancorate a GPI si riuniscano selettivamente in “zattere lipidiche”. Questa è forse la spiegazione più allettante, perché si potrebbero immaginare tutti i tipi di effetti a catena, dove l’aumentata concentrazione locale effettiva di queste proteine permette più interazioni, e così via. Ma una recensione ha sottolineato che un avvertimento è che le zattere lipidiche sono ancora più un’idea astratta che una cosa concreta – mentre sono funzionalmente definite dall’insolubilità del detergente e la maggior parte delle persone le descrive come ricche di sfingomielina e colesterolo, non c’è una definizione universalmente accettata di ciò che è e non è una zattera lipidica, e l’evidenza empirica suggerisce che possono essere molto più piccole e più transitorie di quanto la maggior parte delle persone pensi.
Con questa lettura in mano, ho deciso di ottenere una lista di queste proteine e fare qualche analisi su di esse per vedere se potevo avere un senso migliore di come sono.
analisi
Uniprot ha una lista di 173 proteine umane ancorate a GPI. Queste corrispondono a 140 simboli genici, che sono scesi a 135 dopo aver eseguito questo script per aggiornare i simboli dei geni codificanti le proteine attualmente approvati dall’HGNC. La lista finale di 135 simboli genici è qui.
Uniprot non offre alcuna informazione su come sono state generate le loro annotazioni, anche se ci deve essere un grado significativo di cura manuale. Per il confronto, Andrew ha anche scovato una serie di documenti ordinati che hanno usato PI-PLD o PI-PLC, due enzimi che scindono gli ancoraggi GPI, per isolare empiricamente le proteine ancorate a GPI dalle cellule. Combinando le liste di questi articoli e la mappatura con i simboli dei geni attuali, abbiamo ottenuto 107 geni. Abbiamo controllato diversi di questi a caso. Tra questi c’erano proteine ben note ancorate a GPI come il glicano-1 (GPC1) e la molecola di adesione delle cellule neurali (NCAM1), entrambi i quali sono segnalati per avere interazioni con PrP. Ma erano presenti anche diversi geni per i quali nessun ancoraggio GPI sembrava essere noto in letteratura, come VDAC3, alcuni dei quali possono essere semplicemente proteine molto abbondanti o falsi positivi per altri motivi. Nel frattempo, ci sono ovvie fonti di falsi negativi: geni che semplicemente non erano espressi nella linea cellulare studiata, o non erano abbastanza abbondanti da essere rilevati dallo spettrometro di massa, e i paraloghi di PrP SPRN e PRND non erano nelle liste. Nel complesso, 51 geni erano in entrambe le liste, un arricchimento altamente significativo (OR = 217, P < 1 × 10-84), che aiuta a rassicurarmi che le annotazioni di Uniprot sono coerenti con i dati empirici. Ma per ulteriori analisi abbiamo deciso di andare con la lista Uniprot come sembra più sensibile e specifico.
Arricchito con questa lista, ho voluto vedere come le proteine GPI-anchored stack up. La PrP è una proteina a esone singolo, breve (208 aminoacidi nella sua forma matura), non essenziale e ampiamente espressa. Queste caratteristiche sono tipiche o atipiche per una proteina ancorata a GPI?
Si è scoperto che le proteine ancorate a GPI sono tutte sulla mappa, così variabili su ogni dimensione che ho guardato come qualsiasi altra serie di proteine.
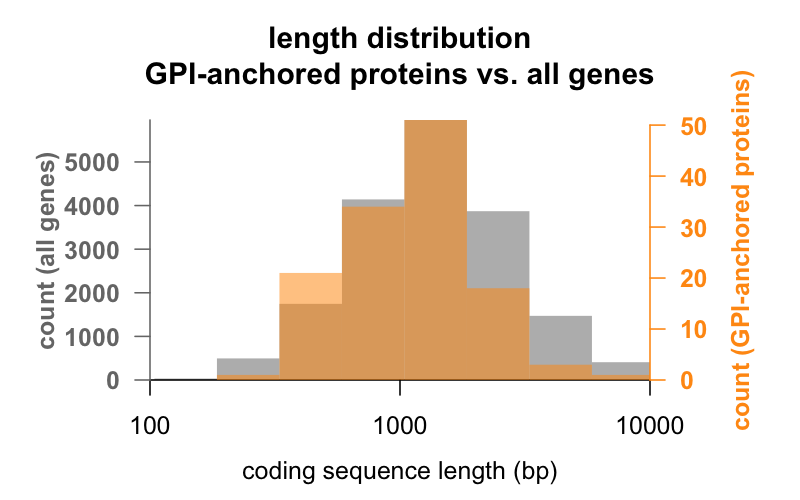
Primo, la lunghezza. Qui sotto sono sovrapposti gli istogrammi della lunghezza della sequenza codificante in paia di basi per tutti i geni, rispetto ai geni che codificano le proteine GPI-anchored. La distribuzione GPI-anchored è appena spostata a sinistra. Il gene medio della proteina GPI-anchored ha 1.301 bp di sequenza codificante, mentre il gene medio ne ha 1.729, ma questa differenza di mezzi è piccola rispetto alla variazione all’interno di ogni gruppo. PrP, con soli 762 bp di sequenza codificante, è decisamente sul lato piccolo, anche se non è affatto un outlier in nessuno dei due gruppi – CD52, con solo 186 paia di basi di sequenza e apparentemente solo 12 aminoacidi nella sua forma matura, è la più piccola proteina ancorata a GPI.
Che dire del numero di esoni? Le proteine ancorate a GPI hanno in media un numero leggermente inferiore di esoni, rispetto a tutti i geni (media 7,8 contro 10,1), coerentemente con la leggera differenza di distribuzione della lunghezza notata sopra, ma la maggior parte sono multi-esone. Anche qui, PrP è sul lato piccolo: ci sono solo sei proteine GPI-anchored che hanno solo 1 esone codificante, e tre di loro sono PrP e i suoi due paraloghi, Sho e Dpl. (Gli altri tre geni sono GAS1, SPACA4 e il favoloso OMG).
Poi ho guardato al vincolo di perdita di funzione. Il vincolo è una misura di quanto sia forte la selezione naturale a cui è sottoposto un gene, basata su quanto sia impoverito per, diciamo, il nonsense, il frameshift e la variazione del sito di splice nella popolazione generale rispetto all’aspettativa basata sui tassi di mutazione. Questa metrica non è molto interpretabile per i geni brevi, sia per ragioni statistiche (il numero di mutazioni attese è basso per i geni brevi, quindi è difficile quantificare l’impoverimento) sia per ragioni biologiche (i geni a singolo esone non sono soggetti al decadimento mediato dal nonsenso, quindi è più difficile sapere se le varianti che troncano le proteine sono davvero “loss-of-function” o no). Ma poiché la maggior parte delle proteine ancorate a GPI non sono così corte come PrP, ho pensato che valesse la pena dare un’occhiata. Il risultato: in media, le proteine ancorate a GPI sono solo leggermente meno vincolate, il che significa che hanno più della loro quantità prevista di variazione di perdita di funzione, rispetto al gene medio. Il gene medio ha il 47% della sua variazione di perdita di funzione, e le proteine ancorate a GPI hanno il 56%. Ma come per tutto qui, c’è un’ampia distribuzione in entrambi i campi. Per le proteine ancorate a GPI, si ha l’ACHE assolutamente vincolato (17 LoF previsti e nessuno osservato) a un’estremità e, all’altra estremità, diversi geni che sembrano non essere sotto selezione contro la perdita di funzione a tutti – CNTN6, CD109, TREH, e MSLN sono alcuni esempi. PRNP cade in quest’ultimo campo una volta che si escludono i residui ≥145 dove le varianti che troncano la proteina causano un guadagno di funzione.
Infine, mi sono chiesto dove sono espresse le proteine ancorate a GPI. PRNP è più alto nel cervello, ma è espresso ovunque. È tipico? Ho scaricato il file di riepilogo completo GTEx v7 “gene mediano tpm” (15 gennaio 2016), dove ogni riga è un gene e ogni colonna è un tessuto e le cellule sono RPKMs – RNA-seq legge per kilobase di esone per milione di letture mappate. Lavorare con questo set di dati ha richiesto un po’ di affinamento. Ho sentito che alcuni bioinformatici considerano <1 RPKM come “non espresso”, ma la matrice di espressione è scarsa – la maggior parte dei geni non sono altamente espressi nella maggior parte dei tessuti – quindi il rumore sotto 1 RPKM può dominare se si tracciano solo gli RPKM grezzi. Nel frattempo, l’espressione genica è qualcosa che devi pensare su una scala logaritmica, poiché i geni in un tessuto possono variare da <1 RPKM a >10.000 RPKM, quindi se consideri tutto su una scala lineare, allora le poche combinazioni gene/tessuto davvero altamente espresse possono anche dominare, facendo sembrare la matrice ancora più spartana di quanto non sia. Ho quindi preso il log10 della matrice e troncato la distribuzione a , quindi, la scala viola che ho usato corre 1 – 10 – 100 – 1.000 – 10.000 RPKM. Poi ho fatto un subset alle proteine GPI-anchored di Uniprot. Per visualizzare questo, ho fatto una heatmap per la prima volta nella mia vita. Ho visto spesso queste in documenti e di solito non mi parlano, ma qui il mio obiettivo era solo quello di avere un senso del modello di espressione, e dopo aver giocato un po’, questo è stato quello che mi ha dato la maggior comprensione. Il principio di una heatmap è che le righe e le colonne sono raggruppate in modo che cose simili vadano insieme. Così, per esempio, tutte le colonne del tessuto cerebrale sono allineate consecutivamente in una zona sull’asse x, e tutti i geni altamente espressi nel cervello sono allineati consecutivamente in una zona sull’asse y, così che la loro intersezione forma un denso rettangolo viola che può essere interpretato come “esiste un cluster di geni che sono principalmente espressi nel cervello”.
I lettori interessati possono visualizzare il PDF in scala reale della heatmap, ma per renderlo più immediatamente accessibile, ecco una versione annotata a mano che chiama i cluster di interesse:

La risposta, quindi, è no – la maggior parte delle proteine ancorate a GPI non hanno lo stesso modello di espressione di PRNP. PRNP è una delle poche proteine più altamente e ampiamente espresse, e si trova vicino alla cima di questa heatmap, insieme a CD59, LY6E, GPC1 e BST2. La maggior parte delle proteine ancorate a GPI hanno un’espressione più bassa o più limitata al tessuto, con alcune espresse quasi unicamente nel cervello e altre quasi unicamente non espresse nel cervello, e altri gruppi più piccoli appartenenti principalmente a tessuti specifici come i testicoli, come il paralog PRND di PrP, il cui knockout causa sterilità maschile.
conclusioni
Le proteine ancorate a GPI possono essere di qualsiasi dimensione, espresse in qualsiasi tessuto e apparentemente hanno qualsiasi funzione, nella misura in cui le loro funzioni sono note. Molte proteine ancorate a GPI hanno funzioni native molto chiare, ma queste funzioni sono diverse e non è chiaro perché richiedano l’ancoraggio GPI, soprattutto perché molte di queste proteine esistono anche in isoforme non ancorate a GPI. Nel frattempo, per altre proteine ancorate a GPI, compresa la PrP, sappiamo poco sulla funzione nativa per cominciare, quindi è difficile anche solo ipotizzare perché la funzione nativa richieda l’ancoraggio a GPI. Nessuna delle analisi che ho fatto o delle recensioni che ho letto è stata in grado di trarre un principio unificante sul perché esiste questo meccanismo di ancoraggio o su cosa fa sì che queste proteine lo richiedano. Ci sono diverse ipotesi sul perché le proteine ancorate a GPI sono uniche, compresi i rafts lipidici, gli omodimeri e lo shedding. Tutte queste ipotesi possono avere un po’ d’acqua. Ma alla fine della giornata, la risposta sembra improbabile essere un momento eureka, ma piuttosto, come gran parte della biologia, un mix prosaico di cose diverse.
Il codice R e i file di dati grezzi per le analisi in questo post sono qui.