Postata il 27 agosto 2015
Reti neurali ricorrenti
Gli uomini non iniziano il loro pensiero da zero ogni secondo. Mentre leggete questo saggio, capite ogni parola sulla base della vostra comprensione delle parole precedenti. Non si butta via tutto e si ricomincia a pensare da zero. I vostri pensieri hanno persistenza.
Le reti neurali tradizionali non possono fare questo, e sembra una grande lacuna. Per esempio, immaginate di voler classificare che tipo di evento sta accadendo in ogni punto di un film. Non è chiaro come una rete neurale tradizionale potrebbe usare il suo ragionamento sugli eventi precedenti del film per informare quelli successivi.
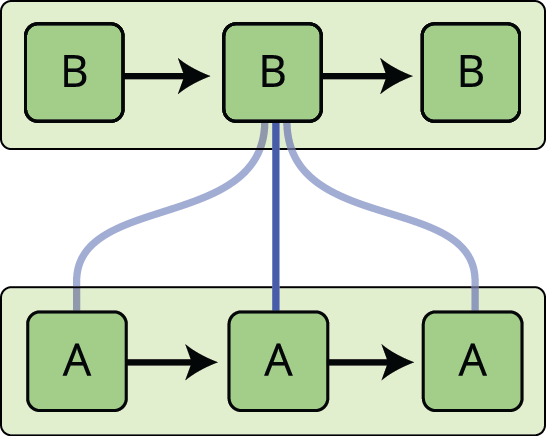
Le reti neurali ricorrenti affrontano questo problema. Sono reti con dei loop, che permettono alle informazioni di persistere.

Nel diagramma qui sopra, un pezzo di rete neurale, \(A\), guarda alcuni input \(x_t\) e produce un valore \(h_t\). Un ciclo permette alle informazioni di essere passate da un passo della rete al successivo.
Questi cicli fanno sembrare le reti neurali ricorrenti piuttosto misteriose. Tuttavia, se si pensa un po’ di più, si scopre che non sono poi così diverse da una normale rete neurale. Una rete neurale ricorrente può essere pensata come copie multiple della stessa rete, ognuna delle quali passa un messaggio ad un successore. Considerate cosa succede se srotoliamo il ciclo:

Questa natura a catena rivela che le reti neurali ricorrenti sono intimamente legate a sequenze e liste. Sono l’architettura naturale di rete neurale da utilizzare per tali dati.
E sono certamente utilizzate! Negli ultimi anni, ci sono stati incredibili successi nell’applicazione delle RNN a una varietà di problemi: riconoscimento vocale, modellazione del linguaggio, traduzione, didascalie di immagini… La lista continua. Lascerò la discussione delle incredibili imprese che si possono raggiungere con le RNN all’eccellente post di Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks. Ma sono davvero sorprendenti.
Essenziale per questi successi è l’uso di “LSTMs”, un tipo molto speciale di rete neurale ricorrente che funziona, per molti compiti, molto molto meglio della versione standard. Quasi tutti i risultati entusiasmanti basati sulle reti neurali ricorrenti sono ottenuti con esse. Sono queste LSTM che questo saggio esplorerà.
Il problema delle dipendenze a lungo termine
Una delle attrattive delle RNN è l’idea che possano essere in grado di collegare informazioni precedenti al compito presente, come l’uso di fotogrammi video precedenti potrebbe informare la comprensione del fotogramma presente. Se le RNN potessero fare questo, sarebbero estremamente utili. Ma possono farlo? Dipende.
A volte, abbiamo solo bisogno di guardare le informazioni recenti per eseguire il compito presente. Per esempio, consideriamo un modello linguistico che cerca di predire la prossima parola sulla base delle precedenti. Se stiamo cercando di predire l’ultima parola in “le nuvole sono in cielo”, non abbiamo bisogno di nessun altro contesto – è abbastanza ovvio che la prossima parola sarà cielo. In questi casi, dove il divario tra l’informazione rilevante e il luogo in cui è necessaria è piccolo, le RNN possono imparare a usare l’informazione passata.

Ma ci sono anche casi in cui abbiamo bisogno di più contesto. Consideriamo il tentativo di predire l’ultima parola nel testo “Sono cresciuto in Francia… parlo correntemente il francese”. Informazioni recenti suggeriscono che la prossima parola è probabilmente il nome di una lingua, ma se vogliamo restringere quale lingua, abbiamo bisogno del contesto della Francia, da più lontano. È del tutto possibile che il divario tra le informazioni rilevanti e il punto in cui sono necessarie diventi molto grande.
Purtroppo, quando questo divario cresce, le RNN diventano incapaci di imparare a collegare le informazioni.

In teoria, le RNN sono assolutamente in grado di gestire tali “dipendenze a lungo termine”. Un umano potrebbe scegliere attentamente i parametri per loro per risolvere problemi giocattolo di questa forma. Purtroppo, nella pratica, le RNN non sembrano essere in grado di impararle. Il problema è stato esplorato in profondità da Hochreiter (1991) e Bengio, et al. (1994), che hanno trovato alcune ragioni fondamentali per cui potrebbe essere difficile.
Grazie al cielo, le LSTM non hanno questo problema!
Reti LSTM
Le reti a memoria breve e lunga – di solito chiamate semplicemente “LSTM” – sono un tipo speciale di RNN, capaci di imparare dipendenze a lungo termine. Sono state introdotte da Hochreiter & Schmidhuber (1997), e sono state raffinate e rese popolari da molte persone nei lavori successivi.1 Lavorano tremendamente bene su una grande varietà di problemi, e sono ora ampiamente utilizzate.
Le LSTM sono esplicitamente progettate per evitare il problema della dipendenza a lungo termine. Ricordare le informazioni per lunghi periodi di tempo è praticamente il loro comportamento predefinito, non qualcosa che lottano per imparare!
Tutte le reti neurali ricorrenti hanno la forma di una catena di moduli ripetuti di rete neurale. Nelle RNN standard, questo modulo ripetente avrà una struttura molto semplice, come un singolo strato tanh.

Anche le LSTM hanno questa struttura a catena, ma il modulo ripetente ha una struttura diversa. Invece di avere un singolo strato della rete neurale, ce ne sono quattro, che interagiscono in un modo molto speciale.

Non preoccupatevi dei dettagli di ciò che succede. Più tardi, ci occuperemo del diagramma LSTM passo dopo passo. Per ora, cerchiamo solo di prendere confidenza con la notazione che useremo.

Nel diagramma qui sopra, ogni linea porta un intero vettore, dall’uscita di un nodo agli ingressi degli altri. I cerchi rosa rappresentano operazioni puntuali, come l’addizione di vettori, mentre le caselle gialle sono gli strati appresi della rete neurale. Le linee che si uniscono denotano la concatenazione, mentre una linea che si biforca denota che il suo contenuto viene copiato e le copie vanno in posizioni diverse.
L’idea centrale dietro le LSTM
La chiave delle LSTM è lo stato delle celle, la linea orizzontale che attraversa la parte superiore del diagramma.
Lo stato delle celle è come un nastro trasportatore. Corre dritto lungo l’intera catena, con solo alcune interazioni lineari minori. E’ molto facile che l’informazione scorra lungo di esso inalterata.

L’LSTM ha la capacità di rimuovere o aggiungere informazioni allo stato di cella, accuratamente regolato da strutture chiamate gates.
I gates sono un modo per far passare opzionalmente le informazioni. Sono composti da uno strato di rete neurale sigmoide e da un’operazione di moltiplicazione puntuale.

Lo strato sigmoide emette numeri tra zero e uno, descrivendo quanto di ogni componente dovrebbe essere lasciato passare. Un valore di zero significa “non far passare niente”, mentre un valore di uno significa “far passare tutto!”
Un LSTM ha tre di queste porte, per proteggere e controllare lo stato della cella.
Step-by-Step LSTM Walk Through
Il primo passo nel nostro LSTM è decidere quali informazioni dobbiamo buttare via dallo stato della cella. Questa decisione è presa da uno strato sigmoidale chiamato “forget gate layer”. Esso guarda \(h_{t-1}} e \(x_t\), e produce un numero tra \(0\) e \(1\) per ogni numero nello stato della cella \(C_{t-1}). Un \(1\) rappresenta “tenere completamente questo” mentre un \(0\) rappresenta “sbarazzarsi completamente di questo.”
Torniamo al nostro esempio di un modello linguistico che cerca di predire la prossima parola basandosi su tutte quelle precedenti. In un tale problema, lo stato della cella potrebbe includere il genere del soggetto presente, in modo da poter utilizzare i pronomi corretti. Quando vediamo un nuovo soggetto, vogliamo dimenticare il genere del vecchio soggetto.

Il passo successivo è decidere quali nuove informazioni memorizzare nello stato della cella. Questo ha due parti. Per prima cosa, uno strato sigmoidale chiamato “input gate layer” decide quali valori aggiornare. Poi, uno strato tanh crea un vettore di nuovi valori candidati, \(\tilde{C}_t\), che potrebbero essere aggiunti allo stato. Nel prossimo passo, combineremo questi due per creare un aggiornamento dello stato.
Nell’esempio del nostro modello linguistico, vorremmo aggiungere il sesso del nuovo soggetto allo stato della cella, per sostituire quello vecchio che stiamo dimenticando.

È ora il momento di aggiornare il vecchio stato della cella, \(C_{t-1}\), nel nuovo stato della cella \(C_t\). I passi precedenti hanno già deciso cosa fare, dobbiamo solo farlo davvero.
Moltiplichiamo il vecchio stato per \(f_t\), dimenticando le cose che abbiamo deciso di dimenticare prima. Poi aggiungiamo \(i_t*\tilde{C}_t\). Questi sono i nuovi valori candidati, scalati da quanto abbiamo deciso di aggiornare ogni valore di stato.
Nel caso del modello linguistico, questo è il punto in cui dovremmo effettivamente eliminare le informazioni sul sesso del vecchio soggetto e aggiungere le nuove informazioni, come abbiamo deciso nei passi precedenti.

Finalmente, dobbiamo decidere cosa produrremo in output. Questo output sarà basato sul nostro stato di cella, ma sarà una versione filtrata. Per prima cosa, eseguiamo uno strato sigmoidale che decide quali parti dello stato della cellula dobbiamo emettere. Poi, mettiamo lo stato della cella attraverso \(\tanh\) (per spingere i valori ad essere tra \(-1\) e \(1\)) e lo moltiplichiamo per l’output della porta sigmoide, in modo da emettere solo le parti che abbiamo deciso di emettere.
Per l’esempio del modello linguistico, poiché ha appena visto un soggetto, potrebbe voler emettere informazioni rilevanti per un verbo, nel caso sia quello che verrà dopo. Per esempio, potrebbe produrre se il soggetto è singolare o plurale, in modo da sapere in quale forma un verbo dovrebbe essere coniugato se è quello che segue.

Varianti della memoria a breve termine
Quello che ho descritto finora è una LSTM abbastanza normale. Ma non tutte le LSTM sono uguali alle precedenti. Infatti, sembra che quasi tutti gli articoli che coinvolgono le LSTM usino una versione leggermente diversa. Le differenze sono minori, ma vale la pena menzionarne alcune.
Una popolare variante LSTM, introdotta da Gers & Schmidhuber (2000), è l’aggiunta di “connessioni a spioncino”. Questo significa che lasciamo che i livelli dei gate guardino lo stato delle celle.

Il diagramma qui sopra aggiunge degli spioncini a tutti i gate, ma molti articoli daranno alcuni spioncini e non altri.
Un’altra variante è quella di usare gate di ingresso e di dimenticanza accoppiati. Invece di decidere separatamente cosa dimenticare e cosa aggiungere nuove informazioni, prendiamo queste decisioni insieme. Dimentichiamo solo quando stiamo per inserire qualcosa al suo posto. Inseriamo nuovi valori nello stato solo quando dimentichiamo qualcosa di più vecchio.

Una variazione leggermente più drammatica del LSTM è la Gated Recurrent Unit, o GRU, introdotta da Cho, et al. Essa combina i cancelli di dimenticanza e di ingresso in un unico “cancello di aggiornamento”. Unisce anche lo stato della cella e lo stato nascosto, e apporta alcune altre modifiche. Il modello risultante è più semplice dei modelli LSTM standard, e sta diventando sempre più popolare.

Queste sono solo alcune delle varianti LSTM più notevoli. Ce ne sono molte altre, come Depth Gated RNNs di Yao, et al. (2015). C’è anche qualche approccio completamente diverso per affrontare le dipendenze a lungo termine, come Clockwork RNNs di Koutnik, et al. (2014).
Quale di queste varianti è migliore? Le differenze sono importanti? Greff, et al. (2015) fanno un bel confronto delle varianti popolari, trovando che sono tutte più o meno uguali. Jozefowicz, et al. (2015) hanno testato più di diecimila architetture RNN, trovandone alcune che funzionano meglio degli LSTM su alcuni compiti.
Conclusione
Prima ho menzionato i notevoli risultati che le persone stanno ottenendo con le RNN. Essenzialmente tutti questi sono raggiunti usando gli LSTM. Funzionano davvero molto meglio per la maggior parte dei compiti!
Scritto come un insieme di equazioni, gli LSTM sembrano piuttosto intimidatori. Si spera che l’averli affrontati passo dopo passo in questo saggio li abbia resi un po’ più accessibili.
Le LSTM sono state un grande passo avanti in quello che possiamo realizzare con le RNN. È naturale chiedersi: c’è un altro grande passo? Un’opinione comune tra i ricercatori è: “Sì, c’è un prossimo passo ed è l’attenzione! L’idea è quella di lasciare che ogni passo di una RNN scelga le informazioni da guardare da una collezione più ampia di informazioni. Per esempio, se state usando una RNN per creare una didascalia che descriva un’immagine, potrebbe scegliere una parte dell’immagine da guardare per ogni parola che emette. Infatti, Xu, et al. (2015) fanno esattamente questo – potrebbe essere un punto di partenza divertente se si vuole esplorare l’attenzione! C’è stata una serie di risultati davvero eccitanti utilizzando l’attenzione, e sembra che molti altri siano dietro l’angolo…
L’attenzione non è l’unico filone eccitante nella ricerca RNN. Per esempio, Grid LSTMs di Kalchbrenner, et al. (2015) sembrano estremamente promettenti. Il lavoro che utilizza RNNs in modelli generativi – come Gregor, et al. (2015), Chung, et al. (2015), o Bayer & Osendorfer (2015) – sembra anche molto interessante. Gli ultimi anni sono stati un periodo eccitante per le reti neurali ricorrenti, e i prossimi promettono di esserlo ancora di più!
Riconoscimenti
Sono grato a diverse persone per avermi aiutato a capire meglio le LSTM, commentando le visualizzazioni e fornendo feedback su questo post.
Sono molto grato ai miei colleghi di Google per il loro utile feedback, specialmente Oriol Vinyals, Greg Corrado, Jon Shlens, Luke Vilnis e Ilya Sutskever. Sono anche grato a molti altri amici e colleghi per aver trovato il tempo di aiutarmi, compresi Dario Amodei e Jacob Steinhardt. Sono particolarmente grato a Kyunghyun Cho per la corrispondenza estremamente riflessiva sui miei diagrammi.
Prima di questo post, mi sono esercitato a spiegare le LSTM durante due serie di seminari che ho tenuto sulle reti neurali. Grazie a tutti quelli che hanno partecipato per la loro pazienza con me, e per il loro feedback.
-
Oltre agli autori originali, molte persone hanno contribuito al moderno LSTM. Una lista non esaustiva è: Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo e Alex Graves.
Altri post
Attenzione e reti neurali ricorrenti aumentate
Su Distill
Reti Conv
Una prospettiva modulare
Reti neurali, Manifolds, and Topology