Panoramica
- Impara a interpretare Bias e Varianza in un dato modello.
- Che differenza c’è tra Bias e Varianza?
- Come ottenere Bias e Varianza Tradeoff usando il flusso di lavoro del Machine Learning
Introduzione
Parliamo del tempo. Piove solo se è un po’ umido e non piove se c’è vento, caldo o gelo. In questo caso, come fareste ad addestrare un modello predittivo e garantire che non ci siano errori nella previsione del tempo? Si potrebbe dire che ci sono molti algoritmi di apprendimento tra cui scegliere. Sono distinti in molti modi, ma c’è una grande differenza in ciò che ci aspettiamo e ciò che il modello predice. Questo è il concetto di Bias e Variance Tradeoff.
Di solito, Bias e Variance Tradeoff viene insegnato attraverso dense formule matematiche. Ma in questo articolo, ho cercato di spiegare Bias e Varianza nel modo più semplice possibile!
Il mio obiettivo sarà quello di farvi girare attraverso il processo di comprensione del problema e di assicurarvi di scegliere il modello migliore dove gli errori di Bias e Varianza sono minimi.
Per questo, ho preso il popolare set di dati sul diabete degli indiani Pima. Il set di dati consiste in misurazioni diagnostiche di pazienti adulti di sesso femminile di origine indiana Pima. Per questo dataset, ci concentreremo sulla variabile “Outcome” – che indica se il paziente ha il diabete o no. Evidentemente, questo è un problema di classificazione binaria e stiamo per tuffarci e imparare come procedere.
Se sei interessato a questo e ai concetti della scienza dei dati e vuoi imparare praticamente fai riferimento al nostro corso- Introduzione alla scienza dei dati
Tabella dei contenuti
- Valutazione di un modello di apprendimento automatico
- Dichiarazione del problema e passi principali
- Che cos’è la distorsione?
- Che cos’è la varianza?
- Bias-Variance Tradeoff
Valutazione del tuo modello di Machine Learning
Lo scopo principale del modello di Machine Learning è quello di imparare dai dati forniti e generare previsioni basate sul modello osservato durante il processo di apprendimento. Tuttavia, il nostro compito non finisce qui. Dobbiamo continuamente apportare miglioramenti ai modelli, in base al tipo di risultati che genera. Quantifichiamo anche le prestazioni del modello usando metriche come la precisione, l’errore quadratico medio (MSE), il punteggio F1, ecc. e cerchiamo di migliorare queste metriche. Questo può spesso diventare difficile quando dobbiamo mantenere la flessibilità del modello senza compromettere la sua correttezza.
Un modello di apprendimento automatico supervisionato mira ad addestrarsi sulle variabili di input (X) in modo tale che i valori predetti (Y) siano il più vicino possibile ai valori reali. Questa differenza tra i valori reali e i valori predetti è l’errore e viene utilizzato per valutare il modello. L’errore per qualsiasi algoritmo di apprendimento automatico supervisionato comprende 3 parti:
- Errore di bias
- Errore di varianza
- Il rumore
Mentre il rumore è l’errore irriducibile che non si può eliminare, gli altri due, cioè bias e varianza, sono un’eccezione.e. Bias e Varianza sono errori riducibili che possiamo tentare di minimizzare il più possibile.
Nelle sezioni seguenti, copriremo l’errore Bias, l’errore di Varianza, e il tradeoff Bias-Varianza che ci aiuterà nella migliore selezione del modello. E ciò che è eccitante è che copriremo alcune tecniche per affrontare questi errori utilizzando un set di dati di esempio.
Dichiarazione del problema e passi principali
Come spiegato in precedenza, abbiamo preso il set di dati sul diabete degli indiani Pima e abbiamo formato un problema di classificazione su di esso. Cominciamo a misurare il dataset e ad osservare il tipo di dati con cui abbiamo a che fare. Lo faremo importando le librerie necessarie:
Ora, caricheremo i dati in un frame di dati e osserveremo alcune righe per avere un’idea dei dati.
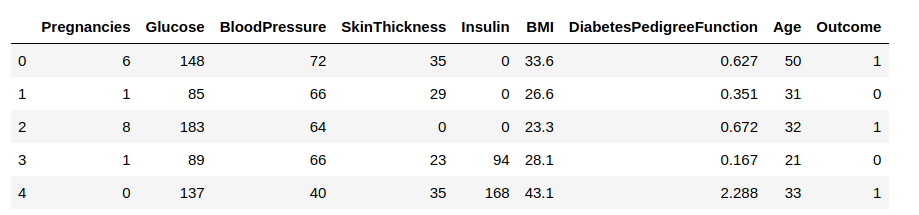
Dobbiamo prevedere la colonna ‘Outcome’. Separiamola e assegniamola a una variabile obiettivo ‘y’. Il resto del data frame sarà l’insieme delle variabili di input X.
Ora scaliamo le variabili predittive e poi separiamo i dati di training e quelli di test.
Siccome i risultati sono classificati in forma binaria, useremo il più semplice classificatore K-nearest neighbor (Knn) per classificare se il paziente ha il diabete o no.
Ma come decidiamo il valore di ‘k’?
- Forse dovremmo usare k = 1 in modo da ottenere ottimi risultati sui nostri dati di allenamento? Questo potrebbe funzionare, ma non possiamo garantire che il modello si comporti altrettanto bene sui nostri dati di test, poiché può diventare troppo specifico
- Che ne dite di usare un valore elevato di k, diciamo come k = 100, in modo da poter considerare un gran numero di punti più vicini per tenere conto anche dei punti lontani? Tuttavia, questo tipo di modello sarà troppo generico e non possiamo essere sicuri che abbia considerato tutte le possibili caratteristiche che contribuiscono correttamente.
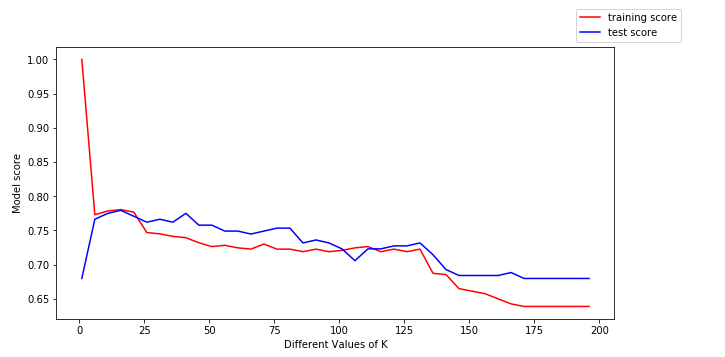
Prendiamo alcuni possibili valori di k e adattiamo il modello ai dati di allenamento per tutti questi valori. Calcoleremo anche il punteggio di addestramento e il punteggio di test per tutti questi valori.
Per ricavare maggiori informazioni da questo, tracciamo i dati di addestramento (in rosso) e i dati di test (in blu).
Per calcolare i punteggi per un particolare valore di k,
![]()
Possiamo trarre le seguenti conclusioni dal grafico di cui sopra:
- Per valori bassi di k, il punteggio di allenamento è alto, mentre il punteggio di test è basso
- Come il valore di k aumenta, il punteggio di test inizia ad aumentare e quello di allenamento a diminuire.
- Tuttavia, ad un certo valore di k, sia il punteggio di allenamento che quello di verifica sono vicini tra loro.
Ecco dove entrano in gioco Bias e Varianza.
Che cos’è il Bias?
In termini più semplici, il Bias è la differenza tra il valore previsto e quello atteso. Per spiegare meglio, il modello fa certe assunzioni quando si allena sui dati forniti. Quando viene introdotto nei dati di test/validazione, queste ipotesi possono non essere sempre corrette.
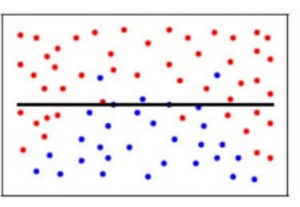
Nel nostro modello, se usiamo un gran numero di vicini più vicini, il modello può decidere totalmente che alcuni parametri non sono affatto importanti. Per esempio, può semplicemente considerare che il livello di Glusoce e la pressione sanguigna decidono se il paziente ha il diabete. Questo modello farebbe ipotesi molto forti sul fatto che gli altri parametri non influenzano il risultato. Si può anche pensare come un modello che predice una relazione semplice quando i datapoint indicano chiaramente una relazione più complessa:
Matematicamente, lasciamo che le variabili di input siano X e una variabile target Y. Mappiamo la relazione tra le due usando una funzione f.
Quindi,
Y = f(X) + e
Qui ‘e’ è l’errore che è normalmente distribuito. Lo scopo del nostro modello f'(x) è di prevedere valori il più possibile vicini a f(x). Qui, il Bias del modello è:
Bias = E
Come ho spiegato sopra, quando il modello fa le generalizzazioni cioè quando c’è un alto errore di bias, risulta un modello molto semplicistico che non considera molto bene le variazioni. Poiché non impara molto bene i dati di formazione, si chiama Underfitting.
Che cos’è la Varianza?
Al contrario del bias, la Varianza è quando il modello tiene conto anche delle fluttuazioni nei dati, cioè del rumore. Quindi, cosa succede quando il nostro modello ha una varianza elevata?
Il modello considererà ancora la varianza come qualcosa da cui imparare. Cioè, il modello impara troppo dai dati di addestramento, tanto che quando si trova di fronte a nuovi dati (test), non è in grado di prevedere accuratamente sulla base di essi.
Matematicamente, l’errore di varianza nel modello è:
Varianza-E^2
Siccome nel caso di alta varianza, il modello impara troppo dai dati di addestramento, si chiama overfitting.
Nel contesto dei nostri dati, se usiamo pochissimi vicini, è come dire che se il numero di gravidanze è più di 3, il livello di glucosio è più di 78, la pressione diastolica è meno di 98, lo spessore della pelle è meno di 23 mm e così via per ogni caratteristica….. decidere che il paziente ha il diabete. Tutti gli altri pazienti che non soddisfano i criteri di cui sopra non sono diabetici. Mentre questo può essere vero per un particolare paziente nel set di addestramento, cosa succede se questi parametri sono gli outlier o addirittura sono stati registrati in modo errato? Chiaramente, un tale modello potrebbe rivelarsi molto costoso!
Inoltre, questo modello avrebbe un alto errore di varianza perché le previsioni sul fatto che il paziente sia diabetico o meno variano notevolmente con il tipo di dati di allenamento che gli stiamo fornendo. Così, anche cambiando il livello di glucosio a 75, il modello predice che il paziente non ha il diabete.
Per semplificare, il modello predice relazioni molto complesse tra il risultato e le caratteristiche di input, quando sarebbe bastata un’equazione quadratica. Questo è l’aspetto di un modello di classificazione quando c’è un alto errore di varianza/quando c’è un overfitting:
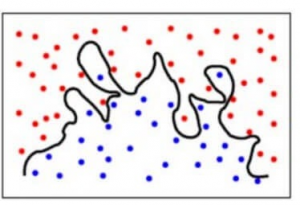
Per riassumere,
- Un modello con un alto errore di bias non si adatta ai dati e fa ipotesi molto semplicistiche
- Un modello con un alto errore di varianza si adatta troppo ai dati e impara troppo da essi
- Un buon modello è quello in cui entrambi gli errori di bias e varianza sono bilanciati
Bias-Variance Tradeoff
Come possiamo collegare questi concetti al nostro modello Knn di prima? Scopriamolo!
Nel nostro modello, diciamo, per, k = 1, sarà considerato il punto più vicino al punto dati in questione. In questo caso, la previsione potrebbe essere accurata per quel particolare punto di dati, quindi l’errore di polarizzazione sarà minore.
Tuttavia, l’errore di varianza sarà elevato, poiché viene considerato solo il punto più vicino e questo non tiene conto degli altri punti possibili. A quale scenario pensi che questo corrisponda? Sì, hai ragione, questo significa che il nostro modello è in overfitting.
D’altra parte, per valori più alti di k, molti più punti più vicini al punto dati in questione saranno considerati. Questo si tradurrebbe in un errore di polarizzazione più elevato e in un underfitting, poiché vengono considerati molti punti più vicini al punto dati e quindi non può imparare le specifiche dal set di allenamento. Tuttavia, possiamo tenere conto di un errore di varianza più basso per il set di test che ha valori sconosciuti.
Per ottenere un equilibrio tra l’errore di bias e l’errore di varianza, abbiamo bisogno di un valore di k tale che il modello non impari dal rumore (overfit sui dati) né faccia ipotesi radicali sui dati (underfit sui dati). Per semplificare, un modello bilanciato sarebbe come questo:
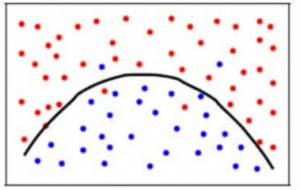
Anche se alcuni punti sono classificati in modo errato, il modello generalmente si adatta accuratamente alla maggior parte dei punti dei dati. L’equilibrio tra l’errore di bias e l’errore di varianza è il tradeoff bias-varianza.
Il seguente diagramma dell’occhio di bue spiega meglio il tradeoff:
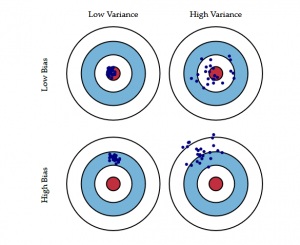
Il centro, cioè l’occhio di bue, è il risultato del modello che vogliamo ottenere che predice perfettamente tutti i valori in modo corretto. Man mano che ci allontaniamo dall’occhio di bue, il nostro modello comincia a fare previsioni sempre più sbagliate.
Un modello con basso bias e alta varianza predice punti che sono generalmente intorno al centro, ma piuttosto lontani tra loro. Un modello con alto bias e bassa varianza è abbastanza lontano dall’occhio di bue, ma poiché la varianza è bassa, i punti predetti sono più vicini tra loro.
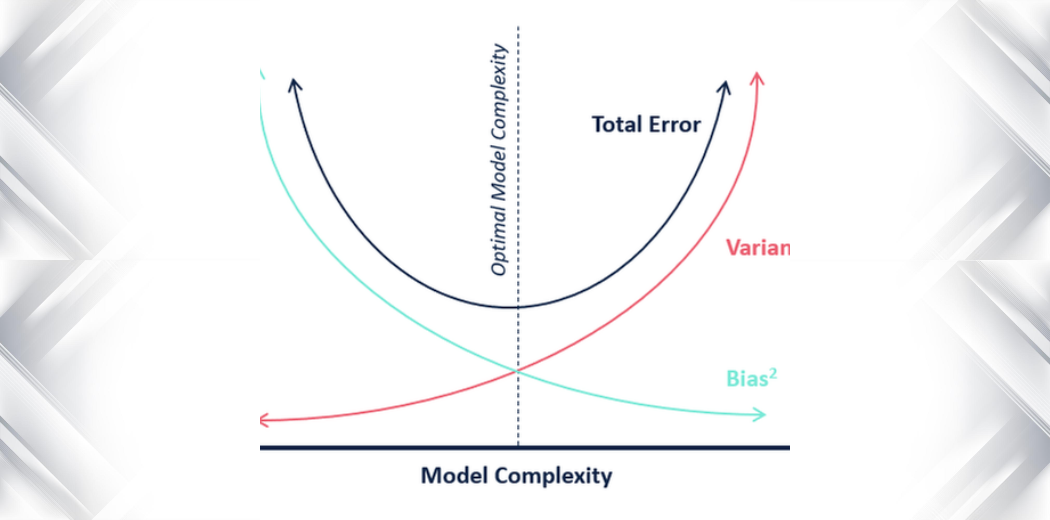
In termini di complessità del modello, possiamo usare il seguente diagramma per decidere la complessità ottimale del nostro modello.
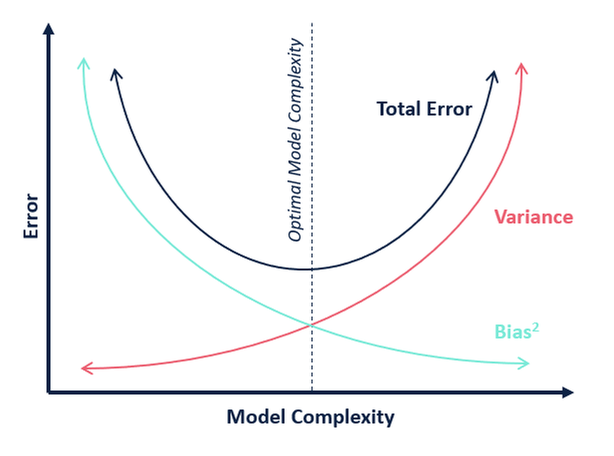
Quindi, quale pensi sia il valore ottimale di k?
Dalla spiegazione di cui sopra, possiamo concludere che il k per cui
- il punteggio di test è il più alto, e
- sia il punteggio di test che quello di allenamento sono vicini tra loro
è il valore ottimale di k. Quindi, anche se scendiamo a compromessi su un punteggio di addestramento più basso, otteniamo comunque un punteggio alto per i nostri dati di test, che è più cruciale – i dati di test sono dopo tutto dati sconosciuti.
Facciamo una tabella per diversi valori di k per dimostrare ulteriormente questo:
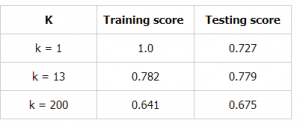
Conclusione
Per riassumere, in questo articolo, abbiamo imparato che un modello ideale sarebbe uno dove sia l’errore di bias che quello di varianza sono bassi. Tuttavia, dovremmo sempre mirare a un modello in cui il punteggio del modello per i dati di addestramento sia il più vicino possibile al punteggio del modello per i dati di test.
Ecco dove abbiamo capito come scegliere un modello che non sia troppo complesso (alta varianza e basso bias) che porterebbe all’overfitting e nemmeno troppo semplice (alto bias e bassa varianza) che porterebbe al underfitting.
Bias e varianza giocano un ruolo importante nel decidere quale modello predittivo usare. Spero che questo articolo abbia spiegato bene il concetto.