Introduzione
La regressione di Poisson è usata per predire una variabile dipendente che consiste in “dati di conteggio” date una o più variabili indipendenti. La variabile che vogliamo predire è chiamata variabile dipendente (o a volte la variabile di risposta, risultato, obiettivo o criterio). Le variabili che stiamo usando per predire il valore della variabile dipendente sono chiamate variabili indipendenti (o a volte le variabili predittive, esplicative o regressori). Alcuni esempi in cui la regressione di Poisson potrebbe essere usata sono descritti di seguito:
- Esempio #1: Si potrebbe usare la regressione di Poisson per esaminare il numero di studenti sospesi dalle scuole di Washington negli Stati Uniti in base a predittori come il genere (ragazze e ragazzi), la razza (bianchi, neri, ispanici, asiatici/isole del Pacifico e indiani americani/nativi dell’Alaska), la lingua (l’inglese è la loro prima lingua, l’inglese non è la loro prima lingua) e lo stato di disabilità (disabili e non disabili). Qui, il “numero di sospensioni” è la variabile dipendente, mentre “genere”, “razza”, “lingua” e “stato di disabilità” sono tutte variabili indipendenti nominali.
- Esempio #2: Si potrebbe usare la regressione di Poisson per esaminare il numero di volte in cui le persone in Australia non pagano le rate della loro carta di credito in un periodo di cinque anni in base a predittori come lo stato di lavoro (occupato, disoccupato), lo stipendio annuale (in dollari australiani), l’età (in anni), il sesso (maschio e femmina) e i livelli di disoccupazione nel paese (% disoccupati). Qui, il “numero di mancati rimborsi con carta di credito” è la variabile dipendente, mentre “condizione lavorativa” e “sesso” sono variabili indipendenti nominali, e “stipendio annuale”, “età” e “livelli di disoccupazione nel paese” sono variabili indipendenti continue.
- Esempio #3: Potresti usare la regressione di Poisson per esaminare il numero di persone davanti a te nella coda al dipartimento di Accident & Emergency (A&E) di un ospedale in base a predittori come la modalità di arrivo al A&E (ambulanza o self check-in), la gravità della ferita valutata durante il triage (lieve, moderata, grave), l’ora del giorno e il giorno della settimana. Qui, il “numero di persone davanti a voi nella coda” è la variabile dipendente, mentre il “modo di arrivo” è una variabile indipendente nominale, la “gravità della ferita valutata” è una variabile indipendente ordinale, e “l’ora del giorno” e “il giorno della settimana” sono variabili indipendenti continue.
- Esempio #4: Si potrebbe usare la regressione di Poisson per esaminare il numero di studenti che ottengono un voto di prima classe in un programma MBA in base a predittori come i tipi di corsi opzionali che hanno scelto (principalmente numerici, principalmente qualitativi, un misto di numerici e qualitativi) e la loro GPA all’ingresso nel programma. Qui, “numero di studenti di prima classe” è la variabile dipendente, mentre “corsi opzionali” è una variabile indipendente nominale e “GPA” è una variabile indipendente continua.
Avendo effettuato una regressione di Poisson, sarai in grado di determinare quali delle tue variabili indipendenti (se ce ne sono) hanno un effetto statisticamente significativo sulla tua variabile dipendente. Per le variabili indipendenti categoriche, sarai in grado di determinare l’aumento o la diminuzione percentuale dei conteggi di un gruppo (ad esempio, le morti tra i “bambini” che vanno sulle montagne russe) rispetto a un altro (ad esempio, le morti tra gli “adulti” che vanno sulle montagne russe). Per le variabili indipendenti continue sarete in grado di interpretare come un aumento o una diminuzione di una singola unità di tale variabile sia associata a un aumento o a una diminuzione percentuale dei conteggi della vostra variabile dipendente (ad esempio, una diminuzione di 1.000 dollari di stipendio – la variabile indipendente – sulla variazione percentuale del numero di volte in cui le persone in Australia non pagano le rate della carta di credito – la variabile dipendente).
Questa guida “quick start” vi mostra come effettuare la regressione di Poisson utilizzando SPSS Statistics, oltre a interpretare e riportare i risultati di questo test. Tuttavia, prima di introdurti a questa procedura, devi capire le diverse ipotesi che i tuoi dati devono soddisfare affinché la regressione di Poisson ti dia un risultato valido. Discutiamo questi presupposti qui di seguito.
Nota: Attualmente non abbiamo una versione premium di questa guida nella parte in abbonamento del nostro sito web.
SPSS Statistics
Assunti
Quando scegliete di analizzare i vostri dati usando la regressione di Poisson, parte del processo consiste nel verificare che i dati che volete analizzare possano effettivamente essere analizzati usando la regressione di Poisson. Dovete fare questo perché è appropriato usare la regressione di Poisson solo se i vostri dati “passano” cinque ipotesi che sono richieste per la regressione di Poisson per darvi un risultato valido. In pratica, il controllo di queste cinque ipotesi richiederà la maggior parte del vostro tempo quando eseguite la regressione di Poisson. Tuttavia, è essenziale che lo facciate perché non è raro che i dati siano violati (cioè, non soddisfino) una o più di queste ipotesi. Tuttavia, anche quando i vostri dati non soddisfano alcune di queste ipotesi, c’è spesso una soluzione per superarle. Per prima cosa, diamo un’occhiata a queste cinque ipotesi:
- Ipotesi #1: La vostra variabile dipendente consiste in dati di conteggio. I dati di conteggio sono diversi dai dati misurati in altri noti tipi di regressione (ad esempio, la regressione lineare e la regressione multipla richiedono variabili dipendenti misurate su una scala “continua”, la regressione logistica binomiale richiede una variabile dipendente misurata su una scala “dicotomica”, la regressione ordinale richiede una variabile dipendente misurata su una scala “ordinale”, e la regressione logistica multinomiale richiede una variabile dipendente misurata su una scala “nominale”). Al contrario, le variabili di conteggio richiedono dati interi che devono essere uguali o superiori a zero. In termini semplici, pensate a un “intero” come a un numero “intero” (per esempio, 0, 1, 5, 8, 354, 888, 23400, ecc.). Inoltre, poiché i dati di conteggio devono essere “positivi” (cioè, consistono di valori interi “non negativi”), non possono consistere in valori “meno” (ad esempio, valori come -1, -5, -8, -354, -888 e -23400 non sarebbero considerati dati di conteggio). Inoltre, a volte si suggerisce di eseguire la regressione di Poisson solo quando il conteggio medio è un valore piccolo (ad esempio, meno di 10). Dove c’è un gran numero di conteggi, un diverso tipo di regressione potrebbe essere più appropriato (ad esempio, regressione multipla, regressione gamma, ecc.)
Esempi di variabili di conteggio includono il numero di voli in ritardo di più di tre ore negli aeroporti europei, il numero di studenti sospesi dalle scuole di Washington negli Stati Uniti, il numero di volte in cui le persone in Australia non pagano le rate della carta di credito in un periodo di cinque anni, il numero di persone che ti precedono nella coda al reparto di Accident & Emergency (A&E) di un ospedale, il numero di studenti che ricevono un voto di prima classe (in genere meno di 5) in un programma MBA, e il numero di persone morte in incidenti sulle montagne russe negli Stati Uniti. - Ipotesi #2: Avete una o più variabili indipendenti, che possono essere misurate su una scala continua, ordinale o nominale/dicotomica. Le variabili ordinali e nominali/dicotomiche possono essere ampiamente classificate come variabili categoriche.
Esempi di variabili continue includono il tempo di revisione (misurato in ore), l’intelligenza (misurata usando il punteggio del QI), il rendimento degli esami (misurato da 0 a 100) e il peso (misurato in kg). Esempi di variabili ordinali includono gli articoli Likert (per esempio, una scala a 7 punti da “fortemente d’accordo” a “fortemente in disaccordo”), tra gli altri modi di classificare le categorie (per esempio, una scala a 3 punti che spiega quanto un cliente ha apprezzato un prodotto, da “Non molto” a “Sì, molto”). Esempi di variabili nominali includono il genere (ad esempio, due gruppi – maschio e femmina – quindi noto anche come variabile dicotomica), l’etnia (ad esempio, tre gruppi: caucasico, afroamericano e ispanico) e la professione (ad esempio, cinque gruppi: chirurgo, medico, infermiere, dentista, terapista). Ricordate che le variabili ordinali e nominali/dicotomiche possono essere ampiamente classificate come variabili categoriche. Potete imparare di più sulle variabili nel nostro articolo: Tipi di variabili. - Assunzione #3: Dovresti avere l’indipendenza delle osservazioni. Questo significa che ogni osservazione è indipendente dalle altre osservazioni; cioè, un’osservazione non può fornire alcuna informazione su un’altra osservazione. Questo è un presupposto molto importante. Una mancanza di osservazioni indipendenti è per lo più un problema di progettazione dello studio. Un metodo per testare la possibilità di indipendenza delle osservazioni è quello di confrontare gli errori standard basati sul modello con gli errori robusti per determinare se ci sono grandi differenze.
- Assunzione #4: La distribuzione dei conteggi (condizionata al modello) segue una distribuzione di Poisson. Una conseguenza di ciò è che i conteggi osservati e quelli attesi dovrebbero essere uguali (in realtà, solo molto simili). Essenzialmente, questo significa che il modello predice bene i conteggi osservati. Questo può essere verificato in diversi modi, ma un metodo è quello di calcolare i conteggi attesi e tracciarli con quelli osservati per vedere se sono simili.
- Assunzione #5: La media e la varianza del modello sono identiche. Questa è una conseguenza dell’ipotesi #4: che ci sia una distribuzione di Poisson. Per una distribuzione di Poisson la varianza ha lo stesso valore della media. Se si soddisfa questa assunzione si ha equidispersione. Tuttavia, spesso questo non è il caso e i vostri dati sono sotto- o sovradispersi, con la sovradispersione che è il problema più comune. Ci sono una varietà di metodi che potete usare per valutare la sovradispersione. Un metodo è quello di valutare la statistica di dispersione di Pearson.
Puoi controllare le ipotesi #3, #4 e #5 usando SPSS Statistics. Le ipotesi #1 e #2 dovrebbero essere controllate per prime, prima di passare alle ipotesi #3, #4 e #5. Ricorda solo che se non esegui correttamente i test statistici su queste ipotesi, i risultati che ottieni quando esegui la regressione di Poisson potrebbero non essere validi.
Inoltre, se i tuoi dati violano l’ipotesi #5, che è estremamente comune quando si esegue la regressione di Poisson, devi prima controllare se hai “apparente dispersione di Poisson”. La sovradispersione apparente di Poisson si ha quando non avete specificato correttamente il modello in modo che i dati appaiano sovradispersi. Pertanto, se il vostro modello di Poisson inizialmente viola l’assunzione di equidispersione, dovreste prima fare una serie di aggiustamenti al vostro modello di Poisson per verificare che sia effettivamente disperso. Questo richiede che facciate sei controlli del vostro modello/dati: (a) Il vostro modello di Poisson include tutti i predittori importanti? (b) I vostri dati includono outlier? (c) La vostra regressione di Poisson include tutti i termini di interazione rilevanti? (d) Qualcuno dei vostri predittori deve essere trasformato? (e) Il vostro modello di Poisson richiede più dati e/o i vostri dati sono troppo scarsi?e (f) Avete valori mancanti che non sono mancanti a caso (MAR)?
Nella sezione, Procedura, illustriamo la procedura di SPSS Statistics per eseguire una regressione di Poisson assumendo che nessuna ipotesi sia stata violata. Per prima cosa, introduciamo l’esempio utilizzato in questa guida.
SPSS Statistics
Esempio &Impostazione in SPSS Statistics
Il direttore della ricerca di una piccola università vuole valutare se l’esperienza di un accademico e il tempo che ha a disposizione per fare ricerca influenzano il numero di pubblicazioni che produce. Pertanto, viene chiesto ad un campione casuale di 21 accademici dell’università di partecipare alla ricerca: 10 sono accademici esperti e 11 sono accademici recenti. Viene registrato il numero di ore che hanno dedicato alla ricerca negli ultimi 12 mesi e il numero di pubblicazioni peer-reviewed che hanno generato.
Per impostare questo disegno di studio in SPSS Statistics, abbiamo creato tre variabili: (1) no_of_publications, che è il numero di pubblicazioni che l’accademico ha pubblicato su riviste peer-reviewed negli ultimi 12 mesi; (2) experience_of_academic, che riflette se l’accademico è esperto (cioè, ha lavorato nel mondo accademico per 10 anni o più, ed è quindi classificato come “Experienced academic”) o è diventato recentemente un accademico (cioè, ha lavorato nel mondo accademico per meno di 3 anni, ma almeno un anno, ed è quindi classificato come “Accademico recente”); e (3) no_of_weekly_hours, che è il numero di ore che un accademico ha a disposizione ogni settimana per lavorare sulla ricerca.
SPSS Statistics
Procedura di test in SPSS Statistics
I 13 passi seguenti ti mostrano come analizzare i tuoi dati usando la regressione di Poisson in SPSS Statistics quando nessuna delle cinque ipotesi della sezione precedente, Ipotesi, è stata violata. Alla fine di questi 13 passi, ti mostriamo come interpretare i risultati della tua regressione di Poisson.
- Clicca su Analizza > Modelli Lineari Generalizzati > Modelli Lineari Generalizzati… nel menu principale, come mostrato di seguito:

Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Vi verrà presentata la finestra di dialogo Modelli Lineari Generalizzati di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Selezionare Poisson loglinear nell’area , come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota: Mentre è standard selezionare Poisson loglinear nell’area
per eseguire una regressione di Poisson, puoi anche scegliere di eseguire una regressione di Poisson personalizzata selezionando Custom nell’area e poi specificando il tipo di modello di Poisson che vuoi eseguire usando le opzioni Distribution:, Link function: e -Parameter-. - Seleziona la scheda . Ti verrà presentata la seguente finestra di dialogo:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Trasferite la vostra variabile dipendente, no_of_publications, nella casella Dependent variable: nell’area
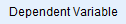 usando il pulsante , come mostrato di seguito:
usando il pulsante , come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Selezionate la scheda . Ti verrà presentata la seguente finestra di dialogo:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Trasferisci la variabile indipendente categorica, experience_of_academic, nella casella Factors: e la variabile indipendente continua, no_of_weekly_hours, nella casella Covariates:, usando i pulsanti , come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota 1: Se avete variabili indipendenti ordinali, dovete decidere se queste devono essere trattate come categoriche e inserite nel riquadro Fattori: o trattate come continue e inserite nel riquadro Covariate:. Non possono essere inserite in una regressione di Poisson come variabili ordinali.
Nota 2: Mentre è tipico inserire variabili indipendenti continue nel riquadro Covariate:, è possibile invece inserire variabili indipendenti ordinali. Tuttavia, se scegliete di farlo, la vostra variabile indipendente ordinale sarà trattata come continua.
Nota 3: Se cliccate sul pulsante
apparirà la seguente finestra di dialogo:
Nell’area -Ordine di categoria per i fattori- potete scegliere tra le opzioni Ascendente, Discendente e Usa ordine dati. Queste sono utili perché SPSS Statistics trasforma automaticamente le vostre variabili categoriche in variabili dummy. A meno che non abbiate familiarità con le variabili dummy, questo può rendere un po’ difficile interpretare l’output di una regressione di Poisson per ciascuno dei gruppi delle vostre variabili categoriche. Perciò, fare dei cambiamenti alle opzioni nell’area -Ordine di categoria per i fattori- può rendere più facile l’interpretazione dei tuoi risultati. - Seleziona la scheda . Ti verrà presentata la seguente finestra di dialogo:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Mantenete il valore predefinito di nell’area -Build Term(s)- e trasferite le variabili indipendenti categoriche e continue, experience_of_academic e no_of_weekly_hours, dal box Factors and Covariates: nel Model: box, utilizzando il pulsante , come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota 1: È nella finestra di dialogo
che si costruisce il modello di Poisson. In particolare, determinate quali effetti principali avete (l’opzione ) e se vi aspettate che ci siano interazioni tra le vostre variabili indipendenti (l’opzione ). Se sospettate di avere interazioni tra le vostre variabili indipendenti, includerle nel vostro modello è importante non solo per migliorare la previsione del vostro modello, ma anche per evitare problemi di sovradispersione, come evidenziato nella sezione Ipotesi prima.
Mentre forniamo un esempio per un modello molto semplice con un solo effetto principale (tra le variabili indipendenti categoriche e continue, experience_of_academic e no_of_weekly_hours), potete facilmente inserire modelli più complessi usando i tasti, , . e nell’area -Build Term(s)- a seconda del tipo di effetti principali e interazioni che avete nel vostro modello.Nota 2: Potete anche costruire termini annidati nel vostro modello aggiungendoli nella casella Term: nell’area -Build Nested Term-. Non abbiamo effetti annidati in questo modello, ma ci sono molti scenari in cui potresti avere termini annidati nel tuo modello.
- Seleziona la scheda . Ti verrà presentata la seguente finestra di dialogo:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Mantieni le opzioni predefinite selezionate.
Nota: Ci sono diverse opzioni che puoi selezionare nell’area -Stima dei parametri-, inclusa la possibilità di scegliere un diverso: (a) metodo dei parametri di scala (cioè,
o invece di nella casella -Metodo dei parametri di scala:), che potrebbe essere preso in considerazione per affrontare problemi di dispersione eccessiva; e (b) matrice di covarianza (cioè, Robust estimator invece di Model-based estimator nell’area -Matrice di covarianza-), che presenta un’altra opzione potenziale (tra le altre cose) per affrontare problemi di dispersione eccessiva.
Ci sono anche un certo numero di specifiche che puoi fare nell’area -Iterazioni- per affrontare problemi di non convergenza nel tuo modello di Poisson. - Seleziona la scheda . Vi verrà presentata la seguente finestra di dialogo:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
- Selezionate Includere le stime dei parametri esponenziali nell’area , come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Nota 1: Nell’area
, potete scegliere tra il rapporto Wald e il rapporto di verosimiglianza in base a fattori quali la dimensione del campione e le implicazioni che questo può avere per l’accuratezza del test di significatività statistica.
Nell’area, il test del moltiplicatore di Lagrange può anche essere utile per determinare se il modello di Poisson è appropriato per i tuoi dati (sebbene non possa essere eseguito usando la procedura di regressione Poisson).Nota 2: Puoi anche selezionare una vasta gamma di altre opzioni dalle schede
e . Queste includono opzioni che sono importanti quando si esaminano le differenze tra i gruppi delle vostre variabili categoriche e quando si verificano le ipotesi della regressione di Poisson, come discusso nella sezione Assunzioni in precedenza. - Clicca sul pulsante . Questo genererà l’output.
SPSS Statistics
Interpretare e riportare l’output dell’analisi di regressione di Poisson
SPSS Statistics genererà alcune tabelle di output per un’analisi di regressione di Poisson. In questa sezione, vi mostriamo le otto tabelle principali necessarie per comprendere i risultati della procedura di regressione di Poisson, supponendo che non sia stata violata nessuna ipotesi.
Informazioni sul modello e sulle variabili
La prima tabella nell’output è la tabella Informazioni sul modello (come mostrato sotto). Questa conferma che la variabile dipendente è il “Numero di pubblicazioni”, la distribuzione di probabilità è “Poisson” e la funzione di collegamento è il logaritmo naturale (cioè, “Log”). Se stai eseguendo una regressione di Poisson sui tuoi dati, il nome della variabile dipendente sarà diverso, ma la distribuzione di probabilità e la funzione di collegamento saranno le stesse.
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
La seconda tabella, Case Processing Summary, ti mostra quanti casi (es, soggetti) sono stati inclusi nella tua analisi (la riga “Inclusi”) e quanti non sono stati inclusi (la riga “Esclusi”), così come la percentuale di entrambi. Puoi pensare alla riga “Esclusi” come se indicasse i casi (ad esempio, i soggetti) che hanno uno o più valori mancanti. Come potete vedere qui sotto, c’erano 21 soggetti in questa analisi senza soggetti esclusi (cioè senza valori mancanti).
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
La tabella Informazioni sulle variabili categoriche evidenzia il numero e la percentuale di casi (per esempio, soggetti) in ogni gruppo di ogni variabile categorica indipendente nella vostra analisi. In questa analisi, c’è solo una variabile categorica indipendente (conosciuta anche come “fattore”), che era esperienza_di_accademica. Potete vedere che i gruppi sono abbastanza equilibrati nei numeri tra i due gruppi (cioè, 10 contro 11). Gruppi molto sbilanciati possono causare problemi con l’adattamento del modello, ma possiamo vedere che qui non ci sono problemi.
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
La tabella Informazioni sulle variabili continue può fornire un controllo rudimentale dei dati per eventuali problemi, ma è meno utile di altre statistiche descrittive che puoi eseguire separatamente prima di eseguire la regressione di Poisson. Il meglio che puoi ottenere da questa tabella è capire se ci potrebbe essere un eccesso di dispersione nella tua analisi (cioè, l’assunzione #5 della regressione di Poisson). Potete farlo considerando il rapporto tra la varianza (il quadrato della colonna “Deviazione standard”) e la media (la colonna “Media”) per la variabile dipendente. Potete vedere questi dati qui sotto:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
La media è 2,29 e la varianza è 2,81 (1,677582), che è un rapporto di 2,81 ÷ 2,29 = 1,23. Una distribuzione di Poisson assume un rapporto di 1 (cioè, la media e la varianza sono uguali). Pertanto, possiamo vedere che prima di aggiungere qualsiasi variabile esplicativa c’è una piccola quantità di sovradispersione. Tuttavia, abbiamo bisogno di verificare questa ipotesi quando tutte le variabili indipendenti sono state aggiunte alla regressione di Poisson. Questo è discusso nella prossima sezione.
Determinare quanto bene il modello si adatti
La tabella della bontà di adattamento fornisce molte misure che possono essere usate per valutare quanto bene il modello si adatti. Tuttavia, ci concentreremo sul valore nella colonna “Value/df” per la riga “Pearson Chi-Square”, che è 1,108 in questo esempio, come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Un valore di 1 indica equidispersione mentre valori maggiori di 1 indicano sovradispersione e valori inferiori a 1 indicano sottodispersione. Il tipo più comune di violazione dell’assunzione di equidispersione è la sovradispersione. Con una dimensione del campione così piccola in questo esempio, è improbabile che un valore di 1,108 sia una grave violazione di questo assunto.
La tabella del test Omnibus si inserisce da qualche parte tra questa sezione e la prossima. Si tratta di un test del rapporto di verosimiglianza per verificare se tutte le variabili indipendenti migliorano collettivamente il modello rispetto al modello di sola intercetta (cioè, senza l’aggiunta di variabili indipendenti). Avendo tutte le variabili indipendenti nel nostro modello di esempio, abbiamo un valore p di .006 (cioè, p = .006), che indica un modello complessivo statisticamente significativo, come mostrato sotto nella colonna “Sig.”:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Ora che sapete che l’aggiunta di tutte le variabili indipendenti genera un modello statisticamente significativo, vorrete sapere quali specifiche variabili indipendenti sono statisticamente significative. Questo è discusso nella prossima sezione.
Effetti del modello e significatività statistica delle variabili indipendenti
La tabella Tests of Model Effects (come mostrato sotto) mostra la significatività statistica di ciascuna delle variabili indipendenti nella colonna “Sig.”:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Di solito non c’è alcun interesse nell’intercetta del modello. Tuttavia, possiamo vedere che l’esperienza dell’accademico non era statisticamente significativa (p = .644), ma il numero di ore lavorate a settimana era statisticamente significativo (p = .030). Questa tabella è utile soprattutto per le variabili indipendenti categoriche perché è l’unica tabella che considera l’effetto complessivo di una variabile categorica, a differenza della tabella delle stime dei parametri, come mostrato di seguito:
Pubblicato con il permesso scritto di SPSS Statistics, IBM Corporation.
Questa tabella fornisce sia le stime dei coefficienti (la colonna “B”) della regressione di Poisson che i valori esponenziati dei coefficienti (la colonna “Exp(B)”). Di solito sono questi ultimi ad essere più informativi. Questi valori esponenziati possono essere interpretati in più di un modo e noi ve ne mostreremo uno in questa guida. Considerate, per esempio, il numero di ore lavorate settimanalmente (cioè la riga “no_of_weekly_hours”). Il valore esponenziato è 1,044. Questo significa che il numero di pubblicazioni (cioè il conteggio della variabile dipendente) sarà 1,044 volte maggiore per ogni ora extra lavorata a settimana. Un altro modo di dire questo è che c’è un aumento del 4,4% nel numero di pubblicazioni per ogni ora extra lavorata a settimana. Un’interpretazione simile può essere fatta per la variabile categorica.
Mettendo tutto insieme
Potresti scrivere i risultati del numero di ore lavorate a settimana come segue:
- Generale
È stata eseguita una regressione di Poisson per prevedere il numero di pubblicazioni che un accademico pubblica negli ultimi 12 mesi in base all’esperienza dell’accademico e al numero di ore che un accademico trascorre ogni settimana lavorando alla ricerca. Per ogni ora in più di lavoro settimanale sulla ricerca, sono state pubblicate 1,044 (95% CI, da 1,004 a 1,085) volte più pubblicazioni, un risultato statisticamente significativo, p = .030.