La crittografia dei dati a riposo è un must per qualsiasi azienda moderna di Internet. Molte aziende, tuttavia, non criptano i loro dischi, perché temono la potenziale penalizzazione delle prestazioni causata dall’overhead della crittografia.
Crittografare i dati a riposo è vitale per Cloudflare con più di 200 data center in tutto il mondo. In questo post, esamineremo le prestazioni della crittografia del disco su Linux e spiegheremo come l’abbiamo resa almeno due volte più veloce per noi stessi e per i nostri clienti!
Crittografia dei dati a riposo
Quando si tratta di crittografare i dati a riposo ci sono diversi modi in cui può essere implementata su un moderno sistema operativo (OS). Le tecniche disponibili sono strettamente accoppiate con un tipico stack di archiviazione del sistema operativo. Una versione semplificata dello stack di memorizzazione e delle soluzioni di crittografia può essere trovata nel diagramma sottostante:
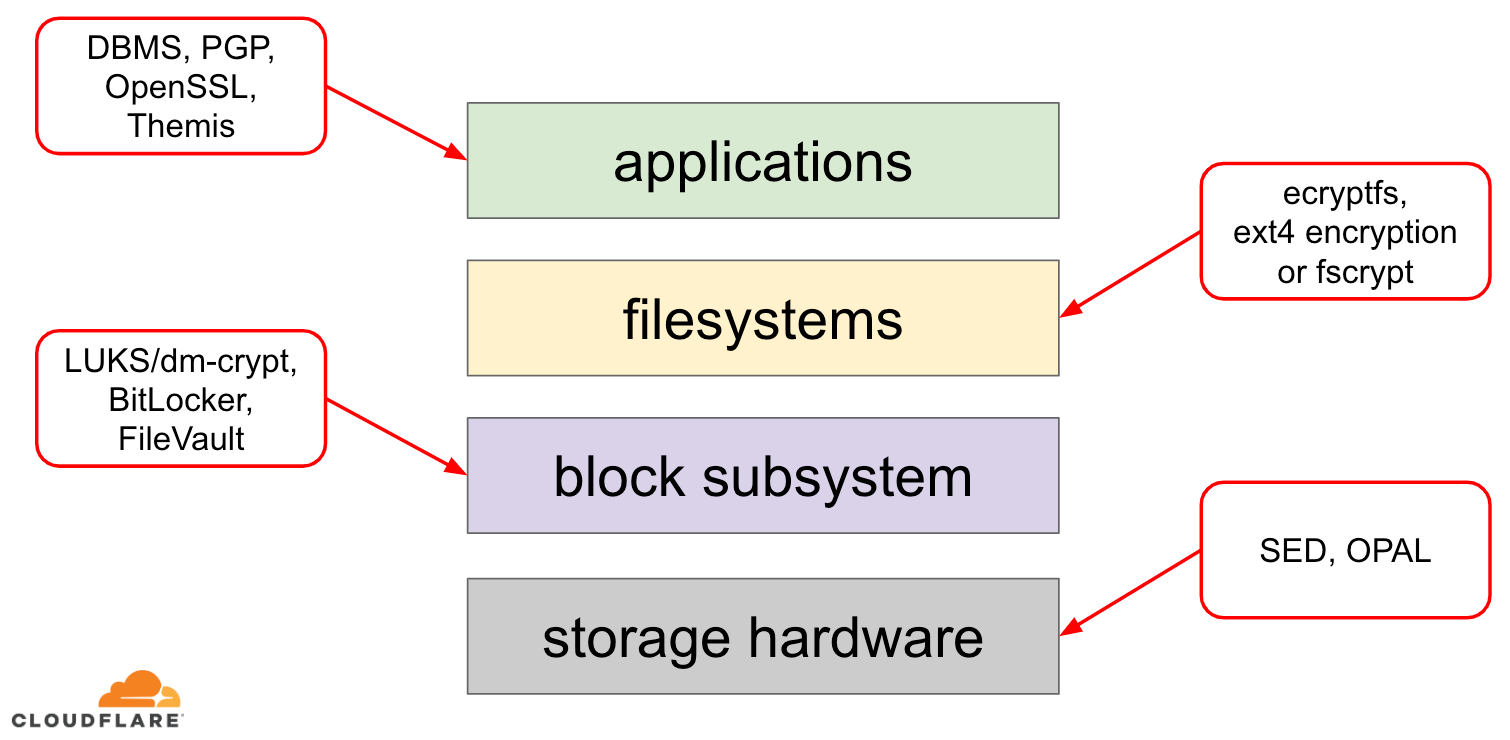
In cima allo stack ci sono le applicazioni, che leggono e scrivono dati in file (o flussi). Il file system nel kernel del sistema operativo tiene traccia di quali blocchi del dispositivo a blocchi sottostante appartengono a quali file e traduce queste letture e scritture di file in letture e scritture di blocchi, tuttavia le specifiche hardware del dispositivo di archiviazione sottostante sono astratte dal filesystem. Infine, il sottosistema a blocchi passa effettivamente le letture e le scritture dei blocchi all’hardware sottostante usando appropriati driver di dispositivo.
Il concetto di stack di archiviazione è in realtà simile al ben noto modello OSI di rete, dove ogni livello ha una visione più di alto livello delle informazioni e i dettagli di implementazione dei livelli inferiori sono astratti dai livelli superiori. E, similmente al modello OSI, si può applicare la crittografia a diversi livelli (si pensi a TLS contro IPsec o una VPN).
Per i dati a riposo possiamo applicare la crittografia sia a livello di blocco (sia nell’hardware che nel software) o a livello di file (direttamente nelle applicazioni o nel filesystem).
Crittografia a blocchi contro quella a file
In genere, più in alto nello stack applichiamo la crittografia, più flessibilità abbiamo. Con la crittografia a livello di applicazione, i manutentori dell’applicazione possono applicare qualsiasi codice di crittografia che desiderano a qualsiasi dato particolare di cui hanno bisogno. Lo svantaggio di questo approccio è che devono effettivamente implementarlo da soli e la crittografia in generale non è molto amichevole per gli sviluppatori: uno deve conoscere i pro e i contro di uno specifico algoritmo crittografico, generare correttamente chiavi, nonces, IVs ecc. Inoltre, la crittografia a livello di applicazione non sfrutta la cache a livello di OS e la cache delle pagine di Linux in particolare: ogni volta che l’applicazione ha bisogno di usare i dati, deve o decifrarli di nuovo, sprecando cicli di CPU, o implementare la propria “cache” decifrata, il che introduce più complessità nel codice.
La crittografia a livello di file system rende la crittografia dei dati trasparente alle applicazioni, perché il file system stesso crittografa i dati prima di passarli al sottosistema a blocchi, quindi i file sono crittografati indipendentemente dal fatto che l’applicazione abbia o meno un supporto crittografico. Inoltre, i file system possono essere configurati per criptare solo una particolare directory o avere chiavi diverse per file diversi. Questa flessibilità, tuttavia, viene al costo di una configurazione più complessa. La crittografia del file system è anche considerata meno sicura della crittografia dei dispositivi a blocchi, poiché solo il contenuto dei file è crittografato. I file hanno anche dei metadati associati, come la dimensione del file, il numero di file, la disposizione dell’albero delle directory ecc. che sono ancora visibili ad un potenziale avversario.
La crittografia a livello di blocco (spesso indicata come crittografia del disco o crittografia dell’intero disco) rende anche la crittografia dei dati trasparente alle applicazioni e persino a interi file system. A differenza della crittografia a livello di file system, crittografa tutti i dati sul disco, compresi i metadati dei file e anche lo spazio libero. Tuttavia è meno flessibile – si può criptare solo l’intero disco con una singola chiave, quindi non c’è una configurazione per directory, per file o per utente. Dal punto di vista crittografico, non tutti gli algoritmi crittografici possono essere usati perché il livello dei blocchi non ha più una visione di alto livello dei dati, quindi ha bisogno di processare ogni blocco indipendentemente. La maggior parte degli algoritmi comuni richiedono una sorta di concatenazione dei blocchi per essere sicuri, quindi non sono applicabili alla crittografia del disco. Invece, modi speciali sono stati sviluppati solo per questo specifico caso d’uso.
Quindi quale livello scegliere? Come sempre, dipende… La crittografia a livello di applicazione e di file system è di solito la scelta preferita per i sistemi client a causa della flessibilità. Per esempio, ogni utente su un desktop multiutente potrebbe voler crittografare la propria home directory con una chiave che possiede e lasciare alcune directory condivise non crittografate. Al contrario, sui sistemi server, gestiti da società SaaS/PaaS/IaaS (tra cui Cloudflare) la scelta preferita è la semplicità di configurazione e la sicurezza – con la crittografia completa del disco abilitata qualsiasi dato da qualsiasi applicazione viene automaticamente crittografato senza eccezioni o sovrascritture. Crediamo che tutti i dati debbano essere protetti senza dividerli in “importanti” e “non importanti”, quindi la flessibilità selettiva che i livelli superiori forniscono non è necessaria.
Crittografia del disco hardware o software
Quando si crittografano i dati a livello di blocco è possibile farlo direttamente nell’hardware di archiviazione, se l’hardware lo supporta. Facendo così di solito si ottengono migliori prestazioni di lettura/scrittura e si consumano meno risorse dall’host. Tuttavia, poiché la maggior parte del firmware dell’hardware è proprietario, non riceve molta attenzione e revisione dalla comunità della sicurezza. In passato questo ha portato a difetti in alcune implementazioni della crittografia hardware del disco, che rendono inutile l’intero modello di sicurezza. Microsoft, per esempio, ha iniziato a preferire la crittografia del disco basata sul software da allora.
Non volevamo mettere i nostri dati e quelli dei nostri clienti al rischio di usare soluzioni potenzialmente insicure e crediamo fortemente nell’open-source. Ecco perché ci affidiamo solo alla crittografia software del disco nel kernel Linux, che è aperto ed è stato verificato da molti professionisti della sicurezza in tutto il mondo.
Prestazioni della crittografia del disco Linux
Il nostro obiettivo non è solo quello di risparmiare i costi di banda per i nostri clienti, ma di fornire contenuti agli utenti Internet il più velocemente possibile.
A un certo punto abbiamo notato che i nostri dischi non erano così veloci come avremmo voluto. Alcuni profili e un rapido test A/B hanno indicato la crittografia del disco di Linux. Poiché non criptare i dati (anche se si suppone che siano una cache pubblica di Internet) non è un’opzione sostenibile, abbiamo deciso di dare un’occhiata più da vicino alle prestazioni della crittografia del disco di Linux.
Device mapper e dm-crypt
Linux implementa la crittografia trasparente del disco tramite un modulo dm-crypt e dm-crypt stesso è parte del framework del kernel device mapper. In poche parole, il device mapper permette di pre/post-processare le richieste di IO mentre viaggiano tra il file system e il dispositivo a blocchi sottostante.
dm-crypt in particolare cripta le richieste di IO “write” prima di inviarle più in basso nello stack al dispositivo a blocchi attuale e decripta le richieste di IO “read” prima di inviarle al driver del file system. Semplice e facile! O lo è?
Impostazione benchmarking
Per la cronaca, i numeri in questo post sono stati ottenuti eseguendo i comandi specificati su un server Cloudflare G9 inattivo fuori produzione. Tuttavia, la configurazione dovrebbe essere facilmente riproducibile su qualsiasi portatile moderno x86.
Generalmente, il benchmarking di qualsiasi cosa intorno a uno stack di storage è difficile a causa del rumore introdotto dall’hardware di storage stesso. Non tutti i dischi sono creati uguali, quindi per lo scopo di questo post useremo i dischi più veloci disponibili là fuori – cioè nessun disco.
Invece Linux ha un’opzione per emulare un disco direttamente nella RAM. Dal momento che la RAM è molto più veloce di qualsiasi memoria persistente, dovrebbe introdurre poche distorsioni nei nostri risultati.
Il seguente comando crea un ramdisk da 4GB:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Ora possiamo impostare un’istanza dm-crypt su di esso, abilitando così la crittografia del disco. Per prima cosa, dobbiamo generare la chiave di crittografia del disco, “formattare” il disco e specificare una password per sbloccare la chiave appena generata.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Chi ha familiarità con LUKS/dm-crypt potrebbe aver notato che qui abbiamo usato un’intestazione staccata LUKS. Normalmente, LUKS memorizza la chiave di cifratura del disco criptata con password sullo stesso disco dei dati, ma poiché vogliamo confrontare le prestazioni di lettura/scrittura tra dispositivi criptati e non criptati, potremmo accidentalmente sovrascrivere la chiave criptata durante il nostro benchmarking in seguito. Mantenere la chiave criptata in un file separato evita questo problema per gli scopi di questo post.
Ora, possiamo effettivamente “sbloccare” il dispositivo criptato per i nostri test:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0A questo punto possiamo ora confrontare le prestazioni del ramdisk criptato e non criptato: se leggiamo/scriviamo dati su /dev/ram0, questi saranno memorizzati in chiaro. Allo stesso modo, se leggiamo/scriviamo dati su /dev/mapper/encrypted-ram0, saranno decriptati/crittografati lungo il percorso da dm-crypt e memorizzati in testo cifrato.
E’ da notare che non stiamo creando alcun file system sopra i nostri dispositivi a blocchi per evitare di falsare i risultati con un overhead del file system.
Misurare il throughput
Quando si tratta di test/benchmarking dello storage Flexible I/O tester è la solita soluzione. Simuliamo un semplice carico sequenziale di lettura/scrittura con una dimensione di blocco di 4K sul ramdisk senza crittografia:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Il comando di cui sopra viene eseguito per molto tempo, quindi lo fermiamo dopo un po’. Come possiamo vedere dalle statistiche, siamo in grado di leggere e scrivere approssimativamente con lo stesso throughput intorno a 1126 MB/s. Ripetiamo il test con il ramdisk criptato:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, questo è un calo! Ora otteniamo solo ~147 MB/s, che è più di 7 volte più lento! E questo su una macchina totalmente inattiva!
Forse la crittografia è solo lenta
La prima cosa che abbiamo considerato è assicurarci di usare la crittografia più veloce. cryptsetup ci permette di confrontare tutte le implementazioni di crittografia disponibili sul sistema per selezionare la migliore:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/ASembra che aes-xts con una chiave di crittografia a 256 bit sia la più veloce. Ma quale stiamo effettivamente usando per il nostro ramdisk criptato?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Noi usiamo aes-xts con una chiave di crittografia dei dati a 256 bit (contate tutti gli zeri opportunamente mascherati dallo strumento dmsetup – se volete vedere i byte effettivi, aggiungete l’opzione --showkeys al comando di cui sopra). I numeri però non si sommano: cryptsetup benchmark ci dice sopra di non fare affidamento sui risultati, poiché “I test sono approssimativi usando solo la memoria (nessun IO di memorizzazione)”, ma questo è esattamente il modo in cui abbiamo impostato il nostro esperimento usando il ramdisk. In un caso un po’ peggiore (supponendo che stiamo leggendo tutti i dati e poi criptandoli/decriptandoli sequenzialmente senza parallelismo) facendo un calcolo a ritroso dovremmo ottenere circa (1126 * 1823) / (1126 + 1823) =~696 MB/s, che è ancora abbastanza lontano dal reale 147 * 2 = 294 MB/s (totale per letture e scritture).
dm-crypt performance flags
Leggendo la pagina man di cryptsetup abbiamo notato che ha due opzioni con prefisso --perf-, che probabilmente sono legate alla regolazione delle prestazioni. La prima è --perf-same_cpu_crypt con una descrizione piuttosto criptica:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Abilitiamo quindi l’opzione
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Nota: secondo l’ultima pagina man esiste anche un comando cryptsetup refresh, che può essere usato per abilitare queste opzioni dal vivo senza dover “chiudere” e “riaprire” il dispositivo criptato. Il nostro cryptsetup però non lo supportava ancora.
Verificare se l’opzione è stata realmente abilitata:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptSì, ora possiamo vedere same_cpu_crypt nell’output, che è quello che volevamo. Rieseguiamo il benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, ora è ~136 MB/s che è leggermente peggio di prima, quindi non va bene. Che dire della seconda opzione --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Forse, siamo in una “qualche situazione” qui, quindi proviamola:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusE ora il benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, che è un po’ meglio, ma ancora non buono…
Chiedendo alla comunità
Disperati abbiamo deciso di cercare il supporto di Internet e abbiamo postato le nostre scoperte nella mailing list dm-crypt, ma la risposta che abbiamo ottenuto non è stata molto incoraggiante:
Se i numeri vi disturbano, allora è per mancanza di comprensione da parte vostra. Probabilmente non sapete che la crittografia è un’operazione pesante…
Abbiamo deciso di fare una ricerca scientifica su questo argomento digitando “la crittografia è costosa” in Google Search e uno dei primi risultati, che effettivamente contiene misure significative, è… il nostro stesso post sul costo della crittografia, ma nel contesto di TLS! È una lettura affascinante da sola, ma il succo è: la crittografia moderna su hardware moderno è molto economica anche su scala Cloudflare (facendo milioni di richieste HTTP crittografate al secondo). Infatti, è così economico che Cloudflare è stato il primo fornitore ad offrire SSL/TLS gratis per tutti.
Scavando nel codice sorgente
Quando abbiamo provato ad usare le opzioni personalizzate dm-crypt descritte sopra eravamo curiosi di sapere perché esistono in primo luogo e cos’è questo “offloading”. Originariamente ci aspettavamo che dm-crypt fosse un semplice “proxy”, che semplicemente cripta/decripta i dati mentre fluiscono attraverso lo stack. Si scopre che dm-crypt fa molto di più che criptare i buffer di memoria e un diagramma (semplificato) del percorso IO è presentato qui sotto:

Quando il file system emette una richiesta di scrittura, dm-crypt non la processa immediatamente – invece la mette in un workqueue chiamato “kcryptd”. In poche parole, un workqueue del kernel programma semplicemente un lavoro (la crittografia in questo caso) da eseguire in un momento successivo, quando è più conveniente. Quando “il momento” arriva, dm-crypt invia la richiesta a Linux Crypto API per l’effettiva crittografia. Tuttavia, la moderna Linux Crypto API è anche asincrona, quindi a seconda della particolare implementazione che il tuo sistema userà, molto probabilmente non sarà processata immediatamente, ma accodata di nuovo per un “momento successivo”. Quando Linux Crypto API farà finalmente la crittografia, dm-crypt potrebbe cercare di ordinare le richieste di scrittura in sospeso mettendo ogni richiesta in un albero rosso-nero. Poi un thread separato del kernel, di nuovo in “qualche tempo dopo”, prende effettivamente tutte le richieste di IO nell’albero e le invia giù per lo stack.
Ora per le richieste di lettura: questa volta abbiamo bisogno di ottenere prima i dati criptati dall’hardware, ma dm-crypt non chiede semplicemente il driver per i dati, ma mette in coda la richiesta in un workqueue diverso chiamato “kcryptd_io”. Ad un certo punto più tardi, quando abbiamo effettivamente i dati criptati, li programmiamo per la decrittazione usando l’ormai familiare workqueue “kcryptd”. “kcryptd” invierà la richiesta a Linux Crypto API, che può decifrare i dati anche in modo asincrono.
Ad essere onesti la richiesta non attraversa sempre tutte queste code, ma la parte importante qui è che le richieste di scrittura possono essere accodate fino a 4 volte in dm-crypt e quelle di lettura fino a 3 volte. A questo punto ci stavamo chiedendo se tutto questo accodamento extra può causare qualche problema di prestazioni. Per esempio, c’è una bella presentazione di Google sulla relazione tra code e latenza di coda. Un risultato chiave della presentazione è:
Una quantità significativa di latenza di coda è dovuta agli effetti di accodamento
Perciò, perché ci sono tutte queste code e possiamo rimuoverle?
Archeologia di Git
Nessuno scrive codice più complesso solo per divertimento, specialmente per il kernel del SO. Quindi tutte queste code devono essere state messe lì per una ragione. Fortunatamente, il sorgente del kernel Linux è gestito da git, quindi possiamo provare a ripercorrere i cambiamenti e le decisioni intorno ad essi.
Il workqueue “kcryptd” era nel sorgente fin dall’inizio della storia disponibile con il seguente commento:
Necessario perché sarebbe molto poco saggio fare la decrittazione in un contesto di interrupt, quindi il bios di ritorno dalle richieste di lettura viene accodato qui.
Così era solo per le letture, ma anche allora – perché ci interessa se è un contesto di interrupt o no, se Linux Crypto API probabilmente userà comunque un thread/queue dedicato per la crittografia? Beh, nel 2005 la Crypto API non era asincrona, quindi questo aveva perfettamente senso.
Nel 2006 dm-cryptha iniziato ad usare il workqueue “kcryptd” non solo per la crittografia, ma per presentare le richieste IO:
Questa patch è progettata per aiutare dm-crypt a rispettare i nuovi vincoli imposti dalla seguente patch in -mm: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Sembra che l’obiettivo qui non fosse quello di aggiungere più concorrenza, ma piuttosto di ridurre l’uso dello stack del kernel, il che ha ancora senso dato che il kernel ha uno stack comune a tutto il codice, quindi è una risorsa abbastanza limitata. Vale la pena notare, tuttavia, che lo stack del kernel Linux è stato ampliato nel 2014 per le piattaforme x86, quindi questo potrebbe non essere più un problema.
Una prima versione del workqueue “kcryptd_io” è stata aggiunta nel 2007 con l’intento di evitare:
la stanchezza causata da molte richieste in attesa di allocazione di memoria…
L’elaborazione delle richieste stava creando un collo di bottiglia su un singolo workqueue, quindi la soluzione era di aggiungerne un altro. Ha senso.
Non siamo certo i primi a sperimentare un degrado delle prestazioni a causa dell’accodamento esteso: nel 2011 è stata introdotta una modifica per invertire in modo condizionale parte dell’accodamento per le richieste di lettura:
Se c’è abbastanza memoria, il codice può inviare direttamente bio invece di accodare questa operazione in un thread separato.
Purtroppo, a quel tempo i messaggi di commit del kernel Linux non erano così verbosi come oggi, quindi non ci sono dati sulle prestazioni disponibili.
Nel 2015 dm-crypt ha iniziato a smistare le scritture in un thread separato “dmcrypt_write” prima di inviarle giù per lo stack:
Su una macchina multiprocessore, le richieste di crittografia finiscono in un ordine diverso da quello in cui sono state presentate. Di conseguenza, le richieste di scrittura verrebbero inviate in un ordine diverso e ciò potrebbe causare una grave degradazione delle prestazioni.
Ha senso, poiché l’accesso sequenziale al disco era molto più veloce di quello casuale e dm-crypt stava rompendo lo schema. Ma questo si applica principalmente ai dischi rotanti, che erano ancora dominanti nel 2015. Potrebbe non essere così importante con i moderni SSD veloci (compresi gli SSD NVME).
Un’altra parte del messaggio di commit vale la pena menzionare:
…in particolare consente agli scheduler IO come CFQ di ordinare più efficacemente…
Cita i benefici delle prestazioni per lo scheduler IO CFQ, ma gli scheduler Linux sono migliorati da allora al punto che lo scheduler CFQ è stato rimosso dal kernel nel 2018.
Lo stesso patchset sostituisce la lista di ordinamento con un albero rosso-nero:
In teoria l’ordinamento dovrebbe essere eseguito dallo scheduler del disco sottostante, tuttavia, in pratica lo scheduler del disco accetta e ordina solo un numero finito di richieste. Per permettere l’ordinamento di tutte le richieste, dm-crypt ha bisogno di implementare il proprio ordinamento.
L’overhead associato all’ordinamento basato su rbtree è considerato trascurabile, quindi non è usato condizionatamente.
Tutto ciò ha senso, ma sarebbe bello avere dei dati di supporto.
Interessante, nello stesso patchset vediamo l’introduzione della nostra familiare opzione “submit_from_crypt_cpus”:
Ci sono alcune situazioni in cui l’offloading della scrittura del bios dai thread di crittografia ad un singolo thread degrada significativamente le prestazioni
In generale, possiamo vedere che ogni cambiamento era ragionevole e necessario, tuttavia le cose sono cambiate da allora:
- l’hardware è diventato più veloce e più intelligente
- L’allocazione delle risorse di Linux è stata rivisitata
- i sottosistemi Linux accoppiati sono stati riarchitettati
e molte delle scelte di progettazione di cui sopra potrebbero non essere applicabili al moderno Linux.
Il “clean-up”
Sulla base della ricerca di cui sopra abbiamo deciso di provare a rimuovere tutte le code extra e il comportamento asincrono e tornare dm-cryptal suo scopo originale: semplicemente criptare/decriptare le richieste IO mentre passano. Ma per il bene della stabilità e di un ulteriore benchmarking abbiamo finito per non rimuovere il codice attuale, ma piuttosto per aggiungere un’altra opzione dm-crypt, che bypassa tutte le code/threads, se abilitata. Il flag ci permette di passare dall’attuale al nuovo comportamento in fase di runtime sotto pieno carico di produzione, in modo da poter facilmente ripristinare le nostre modifiche se dovessimo vedere degli effetti collaterali. La patch risultante può essere trovata sul repository Linux di Cloudflare GitHub.
Synchronous Linux Crypto API
Dal diagramma sopra ricordiamo che non tutto il queueing è implementato in dm-crypt. Le moderne Linux Crypto API possono anche essere asincrone e per il bene di questo esperimento vogliamo eliminare le code anche lì. Ma cosa significa “può essere”? Il sistema operativo può contenere diverse implementazioni dello stesso algoritmo (per esempio, AES-NI con accelerazione hardware su piattaforme x86 e implementazioni AES generiche in codice C). Per default il sistema sceglie il “migliore” in base alla priorità dell’algoritmo configurato. dm-crypt permette di sovrascrivere questo comportamento e richiedere una particolare implementazione del cifrario usando il prefisso capi:. Tuttavia, c’è un problema. Controlliamo effettivamente le implementazioni AES-XTS disponibili (questo è il nostro cifrario per la cifratura del disco, ricordate?) sul nostro sistema:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64Vogliamo selezionare esplicitamente un cifrario sincrono dalla lista di cui sopra per evitare effetti di coda nei thread, ma gli unici due supportati sono xts(ecb(aes-generic)) (l’implementazione C generica) e __xts-aes-aesni (l’implementazione x86 con accelerazione hardware). Vogliamo sicuramente quest’ultima perché è molto più veloce (stiamo puntando alle prestazioni qui), ma è sospettosamente segnata come interna (vedi internal: yes). Se controlliamo il codice sorgente:
Marcare un cifrario come implementazione di servizio utilizzabile solo da un altro cifrario e mai da un normale utente della crypto API del kernel
Quindi questo cifrario è pensato per essere usato solo da altro codice wrapper nella Crypto API e non fuori di essa. In pratica questo significa che il chiamante della Crypto API ha bisogno di specificare esplicitamente questo flag, quando richiede una particolare implementazione del cifrario, ma dm-crypt non lo fa, perché per progettazione non fa parte della Linux Crypto API, piuttosto un utente “esterno”. Abbiamo già patchato il modulo dm-crypt, quindi potremmo anche solo aggiungere il relativo flag. Tuttavia, c’è un altro problema con AES-NI in particolare: x86 FPU. “In virgola mobile” direte voi? Perché abbiamo bisogno della matematica in virgola mobile per fare una crittografia simmetrica che dovrebbe riguardare solo spostamenti di bit e operazioni XOR? Non abbiamo bisogno della matematica, ma le istruzioni AES-NI usano alcuni dei registri della CPU, che sono dedicati alla FPU. Sfortunatamente il kernel Linux non conserva sempre questi registri in un contesto di interrupt per ragioni di performance (salvare/ripristinare la FPU è costoso). Ma dm-crypt può eseguire codice in un contesto di interrupt, quindi rischiamo di corrompere qualche altro dato di processo e torniamo all’affermazione “sarebbe molto poco saggio fare la decrittazione in un contesto di interrupt” nel codice originale.
La nostra soluzione per affrontare quanto sopra è stata quella di creare un altro modulo API Crypto un po’ “intelligente”. Questo modulo è sincrono e non esegue la propria crittografia, ma è solo un “router” di richieste di crittografia:
- se possiamo usare la FPU (e quindi AES-NI) nel contesto di esecuzione corrente, inoltriamo semplicemente la richiesta di crittografia alla più veloce implementazione “interna”
__xts-aes-aesni(e la possiamo usare qui, perché ora siamo parte della Crypto API) - altrimenti, inoltriamo la richiesta di crittografia alla più lenta e generica implementazione
xts(ecb(aes-generic))basata su C
Utilizzando il tutto
Passiamo attraverso il processo di utilizzo di tutto questo insieme. Il primo passo è prendere le patch e ricompilare il kernel (o semplicemente compilare dm-crypt e i nostri moduli xtsproxy).
Poi, riavviamo il nostro carico di lavoro IO in un terminale separato, così possiamo assicurarci di poter riconfigurare il kernel a runtime sotto carico:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Nel terminale principale assicuriamoci che il nostro nuovo modulo Crypto API sia caricato e disponibile:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Riconfiguriamo il disco criptato per usare il nostro modulo appena caricato e abilitiamo il nostro flag dm-crypt patchato (dobbiamo usare lo strumento di basso livello dmsetup perché cryptsetup ovviamente non è a conoscenza delle nostre modifiche):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Abbiamo appena “caricato” la nuova configurazione, ma perché abbia effetto, dobbiamo sospendere/riprendere il dispositivo criptato:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0E ora osserviamo il risultato. Possiamo tornare all’altro terminale che esegue il lavoro fio e guardare l’output, ma per rendere le cose più piacevoli, ecco un’istantanea del throughput di lettura/scrittura osservato in Grafana:
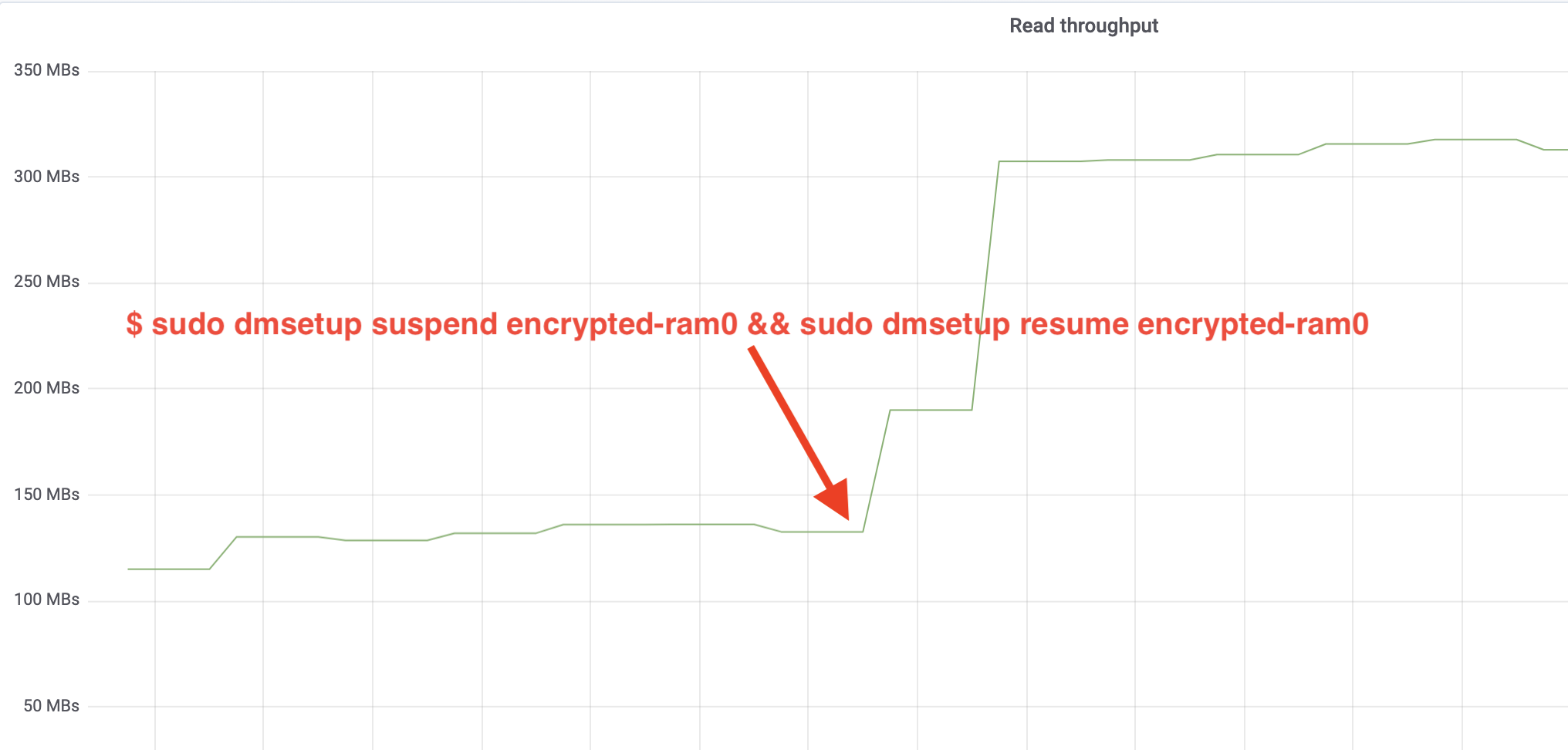
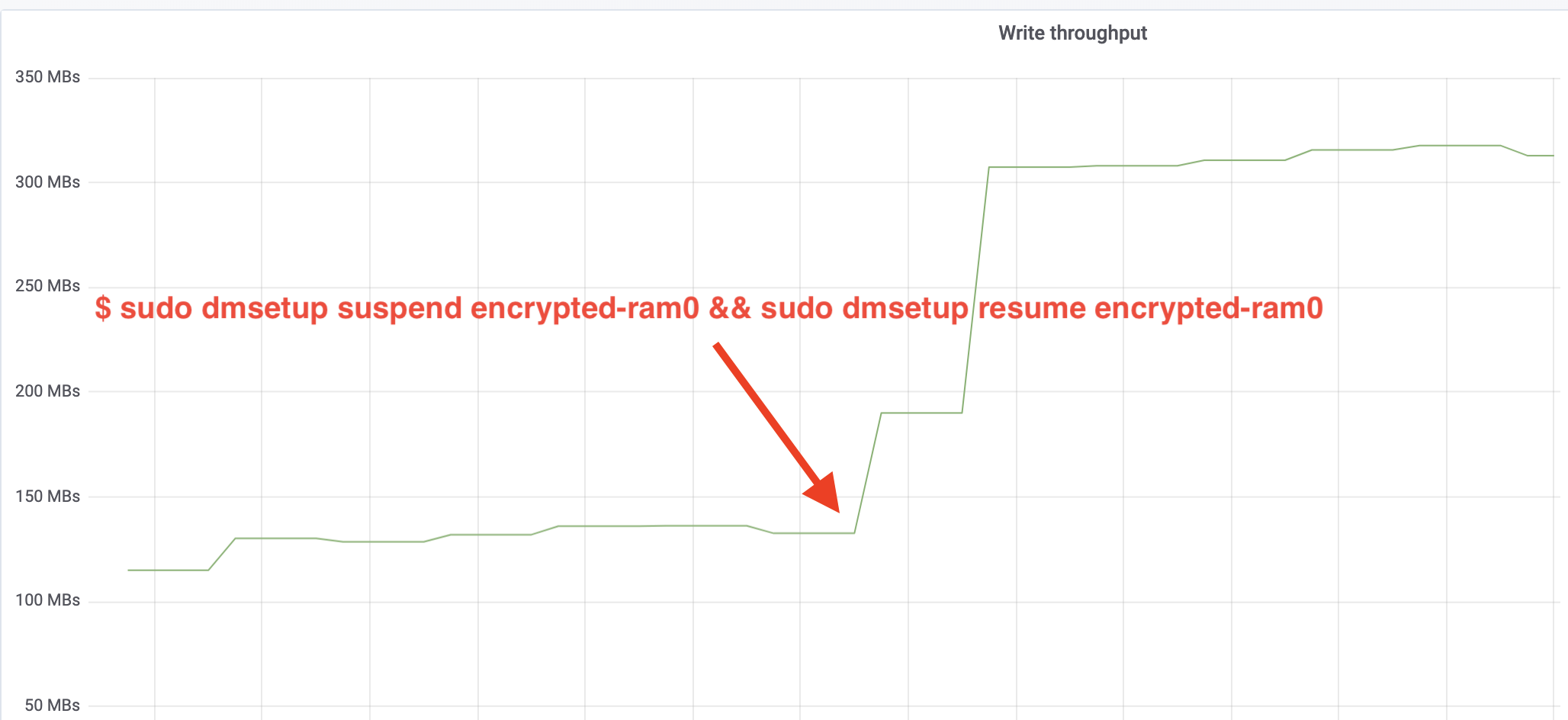
Wow, abbiamo più che raddoppiato il throughput! Con un throughput totale di ~640 MB/s ora siamo molto più vicini al ~696 MB/s previsto dall’articolo precedente. E la latenza IO? (La statistica await dallo strumento di reporting iostat):
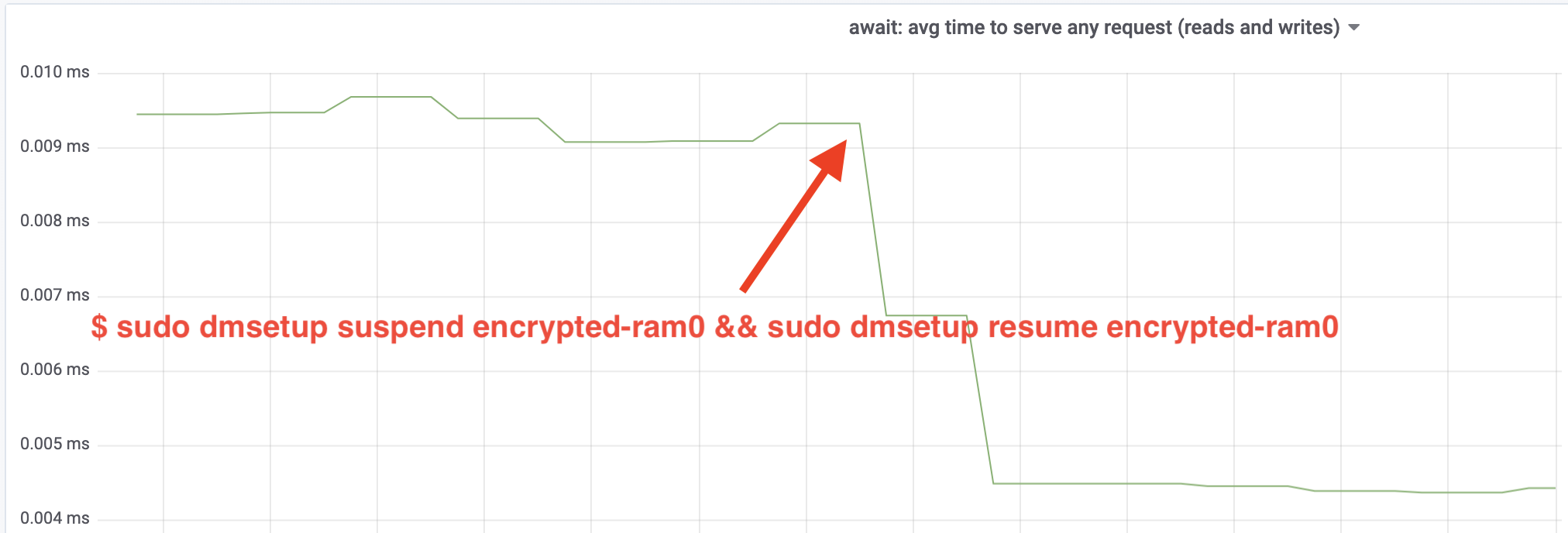
Anche la latenza è stata dimezzata!
Alla produzione
Finora abbiamo usato una configurazione sintetica con alcune parti dello stack di produzione completo mancanti, come file system, hardware reale e, soprattutto, il carico di lavoro di produzione. Per assicurarci che non stiamo ottimizzando cose immaginarie, ecco un’istantanea dell’impatto di produzione che queste modifiche portano alla parte di caching del nostro stack:

Questo grafico rappresenta un confronto a tre vie dei tempi di risposta nel caso peggiore (99° percentile) per un hit della cache in uno dei nostri server. La linea verde proviene da un server con dischi non criptati, che useremo come linea di base. La linea rossa proviene da un server con dischi criptati con l’implementazione predefinita della crittografia del disco di Linux e la linea blu proviene da un server con dischi criptati e le nostre ottimizzazioni abilitate. Come possiamo vedere l’implementazione predefinita della crittografia del disco di Linux ha un impatto significativo sulla nostra latenza della cache negli scenari peggiori, mentre l’implementazione con patch è indistinguibile dal non usare affatto la crittografia. In altre parole, l’implementazione migliorata della crittografia non ha alcun impatto sulla nostra velocità di risposta della cache, quindi in pratica la otteniamo gratis! È una vittoria!
Abbiamo appena iniziato
Questo post mostra come una revisione dell’architettura può raddoppiare le prestazioni di un sistema. Inoltre abbiamo riconfermato che la crittografia moderna non è costosa e di solito non ci sono scuse per non proteggere i propri dati.
Presenteremo questo lavoro per l’inclusione nell’albero principale dei sorgenti del kernel, ma molto probabilmente non nella sua forma attuale. Anche se i risultati sembrano incoraggianti, dobbiamo ricordare che Linux è un sistema operativo altamente portabile: gira su potenti server così come su piccoli dispositivi IoT con risorse limitate e anche su molte altre architetture di CPU. La versione attuale delle patch ottimizza solo la crittografia del disco per un particolare carico di lavoro su una particolare architettura, ma Linux ha bisogno di una soluzione che funzioni senza problemi ovunque.
Detto questo, se pensate che il vostro caso sia simile e volete approfittare dei miglioramenti delle prestazioni ora, potete prendere le patch e sperare di fornire un feedback. Il flag di runtime rende facile attivare la funzionalità al volo e un semplice test A/B può essere eseguito per vedere se beneficia di qualche caso o configurazione particolare. Queste patch sono state eseguite nella nostra vasta rete di oltre 200 data center su cinque generazioni di hardware, quindi possono essere ragionevolmente considerate stabili. Godetevi sia le prestazioni che la sicurezza di Cloudflare per tutti!

Aggiornamento (11 ottobre 2020)
La patch principale di questo blog (in una forma leggermente aggiornata) è stata incorporata nel kernel Linux mainline ed è disponibile dalla versione 5.9 in poi. La differenza principale è che la versione mainline espone due flag invece di uno, che forniscono la possibilità di bypassare le code di lavoro dm-crypt per letture e scritture in modo indipendente. Per i dettagli, vedere la documentazione ufficiale di dm-crypt.