A sémakezelés alapjainak megértése kulcsfontosságú egy hatékony PostgreSQL adatbázis felépítéséhez és karbantartásához. Ebben a cikkben a Postgres-sémák kezelésének hagyományos módját és egy újabb, hatékonyabb, vizuálisan, egyetlen sor kód megírása nélkül megvalósítható módszert fogunk megvizsgálni.
Mi az a PostgreSQL séma?
Először, hogy megalapozzuk a cikket, tisztázzunk néhány fogalmat. A Postgresben a sémát névtérnek is nevezik. A névtérhez társítható egy családnév. Az adatbázis egyes objektumainak (táblák, nézetek, oszlopok stb.) azonosítására és megkülönböztetésére szolgál. Egy sémában nem szabad két azonos nevű táblát létrehozni, de két különböző sémában igen. Például lehet két táblánk, mindkettőnek a neve table1, amelyek jelen vannak a public és a postgres sémákban.
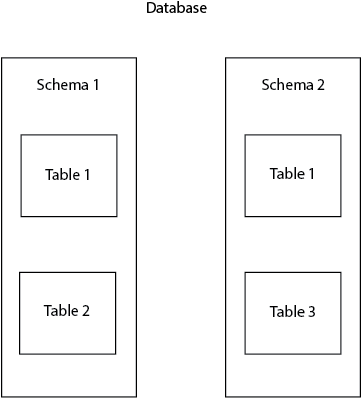
Miért használunk sémákat?
A sémák nagyon hasznosak az adatbázis-objektumok logikai csoportokba rendezésére és a névütközések elkerülésére. Emellett a sémákat gyakran használják arra is, hogy a különböző felhasználók úgy dolgozhassanak az adatbázissal, hogy ne zavarják egymást. Gyakori példa erre, amikor minden egyes adatbázis-felhasználó a saját sémáján dolgozik, anélkül, hogy zavarja a többi felhasználót és elkerülje a konfliktusokat.
A PostgreSQL sémák kezelésének klasszikus módja
Az alábbi lekérdezéseket a PostgreSQL héjon belülről hajtjuk végre.
Séma létrehozása
A PostgreSQL új adatbázisának létrehozásakor az alapértelmezett séma nyilvános. Új sémát a következő lekérdezés végrehajtásával hozhatunk létre:
CREATE SCHEMA schema_1;
Előtte néhány táblázat hozzáadása, Elmagyarázok két fontos fogalmat: A minősített és a minősítetlen neveket.
-
A minősített név a sémanév és a táblanév egy ponttal elválasztva. Ez adja meg azt a sémát, amelyben a táblánkat létre akarjuk hozni:
.
xxxxxxxxxx
CREATE TABLE schema_name.table_name (...);
-
A minősítetlen név csak a táblázat nevéből áll. Ez létrehozza a táblát a kiválasztott adatbázisban, amely alapértelmezés szerint nyilvános. Ez a search_path-on keresztül megváltoztatható, de ezt később részletezzük. Egy példa a minősítetlen elnevezésre a következő:
.
xxxxxxxxxx
CREATE TABLE table_name (...);
A táblázatok oszlopai a fenti lekérdezésekből a zárójelen belül kerülnek meghatározásra (…).
Egy új tábla létrehozásához az új sémánkban a következő parancsot hajtjuk végre:
.
xxxxxxxxxx
CREATE TABLE schema_1.persons (name text, age int);
A séma elhagyásához, két lehetőségünk van. Ha a séma üres (nem tartalmaz egyetlen táblát, nézetet vagy egyéb objektumot sem), akkor elvégezhetjük:
.
xxxxxxxxxx
DROP SCHEMA schema_1;
Ha a séma adatbázis objektumokat tartalmaz, beillesztjük a kaszkádparancsot:
xxxxxxxxxx
DROP SCHEMA schema_1 CASCADE;
A PostgreSQL-ben lehetőség van egy másik felhasználó tulajdonában lévő séma létrehozására is:
xxxxxxxxxx
CREATE SCHEMA schema_name AUTHORIZATION username;
Keresési útvonal
Kvalifikálatlan nevű parancs végrehajtásakor, Postgres egy keresési útvonalat követ annak meghatározásához, hogy milyen sémákat használjon. Alapértelmezés szerint a keresési útvonal a nyilvános sémára van beállítva. Ennek megtekintéséhez hajtsa végre a következőt:
.
xxxxxxxxxx
SHOW search_path;
Ha semmi sem változott az adatbázisában, ennek a lekérdezésnek a következő eredményt kell hoznia:
xxxxxxxxxx
search_path
--------------
"$user",public
A search_path módosítható, így a rendszer automatikusan más sémát választ, ha nem minősített nevet használ. A keresési útvonal első sémáját nevezzük aktuális sémának. Például a schema_1-et fogom beállítani aktuális sémának:
.
xxxxxxxxxx
SET search_path TO schema_1,public;
A következő lekérdezés egy táblázat létrehozásához egy nem minősített nevet használ. Ez automatikusan létrehozza azt a schema_1-ben:
xxxxxxxxxx
CREATE TABLE address (city text, street text, number int);
Az új út:
Létezik egy egyszerűbb mód a sémakezelési feladatok elvégzésére anélkül, hogy egyetlen sor kódot is írnunk kellene. A DbSchema használatával a fenti összes lekérdezést egy intuitív grafikus felhasználói felületről néhány kattintással végrehajthatja. Az adatbázishoz való csatlakozás mindössze néhány másodpercet vesz igénybe. Kezdettől fogva kiválaszthatja, hogy milyen sémán dolgozzon.
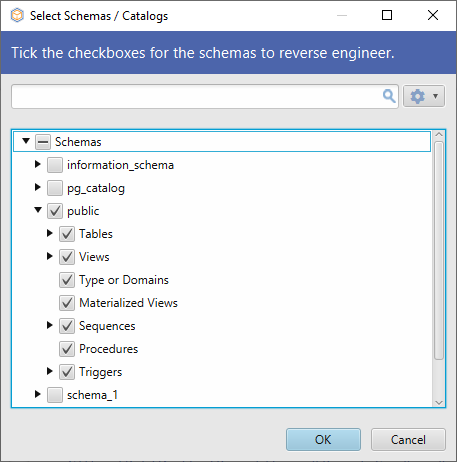
A kiválasztott sémát vagy sémákat a DbSchema visszafejti és megjeleníti az elrendezésben.
Új séma létrehozásához kattintson a jobb gombbal a bal oldali menüben a séma mappára, és válassza a Séma létrehozása parancsot.
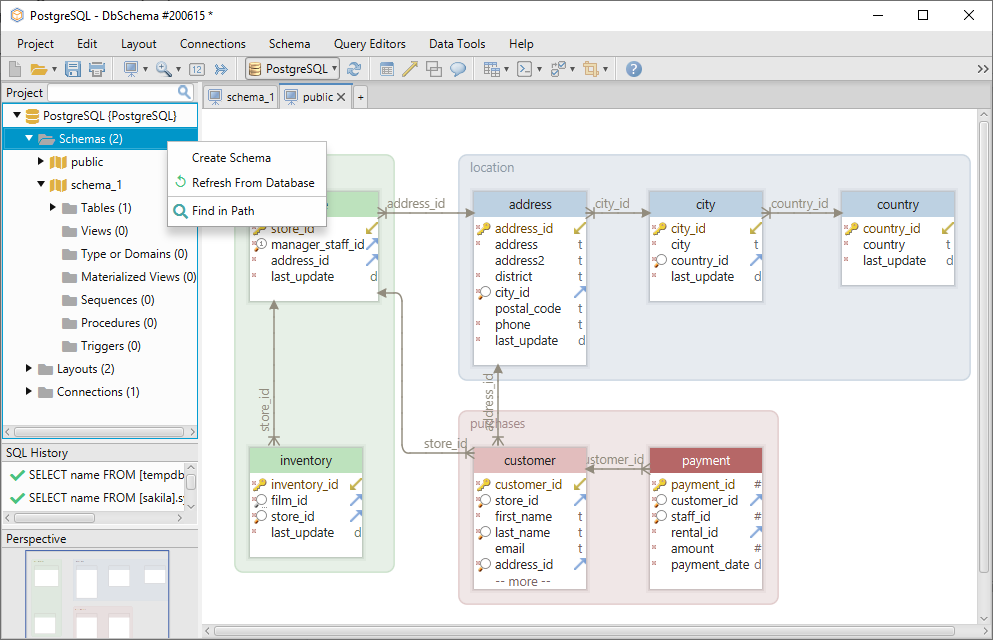
Új tábla létrehozásához a sémában kattintson a jobb gombbal az elrendezésen, és válassza a Táblázat létrehozása parancsot.
A séma a bal oldali menüben a nevére jobb egérgombbal kattintva ejthető el.
Az adatbázisból egy másik séma hozzáadásához válassza a Frissítés az adatbázisból parancsot.
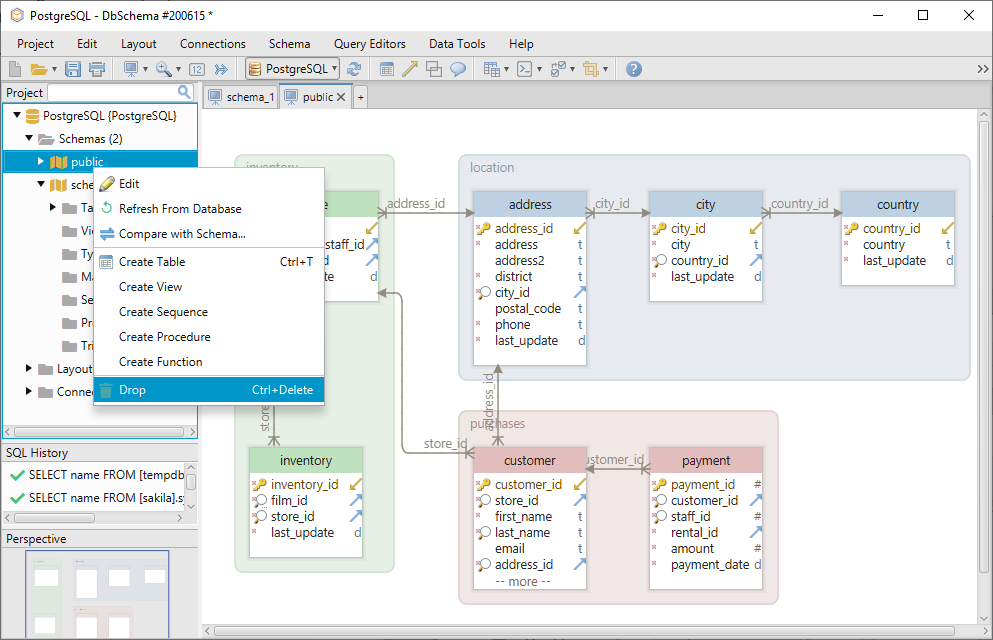
A DbSchema használatával nem lesz szükség a show_path szintaxis használatára, mivel a táblákat közvetlenül az elrendezésben hozhatja létre. Az elrendezés egy rajzlaphoz hasonlítható, amelyen hozzáadhatja a táblákat és szerkesztheti őket. Minden elrendezéshez egy séma tartozik, így ha a schema_1 elrendezésen vagy, akkor a táblák automatikusan ott lesznek létrehozva.
Munka offline
A DbSchema egy helyi projektfájlban tárolja a séma helyi képét. Ez azt jelenti, hogy a projektfájl adatbázis-kapcsolat nélkül (offline) megnyitható. Offline állapotban a fent bemutatott összes műveletet és még többet is elvégezhet, de adatok nélkül. Az adatbázishoz való újbóli kapcsolódás után összehasonlíthatja a projektfájlt az adatbázissal, és kiválaszthatja, hogy mely műveleteket kívánja megtartani vagy elhagyni.
Ugyanez elvégezhető ugyanazon projektfájl két különböző verziója között is. Ha például egy csapatban dolgozik, előfordulhat, hogy több séma van (termelési, tesztelési, fejlesztési), mindegyikhez saját projektfájl tartozik. Ha a fejlesztésben megjelenik egy változás, és azt a másik két sémán keresztül szeretné végrehajtani, akkor egyszerűen összehasonlíthatja és szinkronizálhatja a két projektfájlt.
Következtetés
A fent felsorolt fogalmak megértése segít a PostgreSQL-sémák egyszerű kezelésében. Egy vizuális tervező, például a DbSchema használata még inkább megkönnyíti a munkáját, mivel mindent vizuálisan végezhet el, anélkül, hogy egyetlen sor kódot kellene írnia.