
Mielőtt elindultam volna ezen az úton, hogy megpróbáljam megtanulni az informatikát, voltak bizonyos kifejezések és kifejezések, amelyek miatt legszívesebben elfutottam volna a másik irányba.
De ahelyett, hogy elfutottam volna, úgy tettem, mintha tudnám, mire utal valaki, holott az igazság az volt, hogy fogalmam sem volt, és valójában teljesen abbahagytam a figyelést, amikor meghallottam azt a szuper ijesztő informatikai kifejezést™. A sorozat során sikerült sok mindent lefednem, és sok ilyen kifejezés valójában sokkal kevésbé lett ijesztő!
Van azonban egy nagy, amit egy ideje kerülök. Eddig, valahányszor hallottam ezt a kifejezést, megbénultam. Alkalmi beszélgetésekben, találkozókon és néha konferencia előadásokon is felmerült. Minden egyes alkalommal arra gondoltam, hogy a gépek pörögnek és a számítógépek megfejthetetlen kódsorokat köpködnek ki, kivéve, hogy körülöttem mindenki más valójában meg tudja fejteni őket, így valójában csak én vagyok az, aki nem tudja, mi történik (hoppá, hogy történt ez?!).
Talán nem én vagyok az egyetlen, aki így érezte. De azt hiszem, el kéne mondanom, hogy mi is ez a kifejezés valójában, nem? Nos, készüljetek fel, mert az örökké megfoghatatlan és látszólag zavaros absztrakt szintaxisfára, vagy röviden AST-re utalok. Sok évnyi megfélemlítés után izgatottan várom, hogy végre ne féljek ettől a kifejezéstől, és valóban megértsem, mi a fene ez.
Eljött az ideje, hogy szemtől szembe nézzünk az absztrakt szintaxisfa gyökerével – és szintre emeljük elemző játékunkat!
Minden jó küldetés szilárd alapokkal kezdődik, és a mi küldetésünket, hogy demisztifikáljuk ezt a struktúrát, pontosan ugyanígy kell kezdenünk: természetesen egy definícióval!
Az absztrakt szintaxisfa (általában csak AST-nek nevezik) valójában nem más, mint a parse tree egyszerűsített, sűrített változata. A fordítótervezés kontextusában az “AST” kifejezést felváltva használják a szintaxisfával.

A szintaxisfákról (és azok felépítéséről) gyakran a parse tree megfelelőikhez képest gondolkodunk, amelyeket már elég jól ismerünk. Tudjuk, hogy a tagolófák olyan fa adatszerkezetek, amelyek tartalmazzák a kódunk nyelvtani szerkezetét; más szóval tartalmazzák az összes olyan szintaktikai információt, amely egy kód “mondatában” megjelenik, és közvetlenül magából a programozási nyelv nyelvtanából származik.
Az absztrakt szintaxisfa ezzel szemben figyelmen kívül hagyja a szintaktikai információk jelentős részét, amelyeket egy tagolófa egyébként tartalmazna.
Ezzel szemben egy AST csak a forrásszöveg elemzésével kapcsolatos információkat tartalmazza, és kihagy minden egyéb, a szöveg elemzése során használt extra tartalmat.
Ez a megkülönböztetés sokkal több értelmet kezd nyerni, ha az AST “absztraktságára” összpontosítunk.
Emlékezzünk arra, hogy a parse tree egy mondat nyelvtani szerkezetének illusztrált, képi változata. Más szóval, azt mondhatjuk, hogy a parse tree pontosan azt ábrázolja, ahogyan egy kifejezés, mondat vagy szöveg kinéz. Ez lényegében magának a szövegnek a közvetlen fordítása; fogjuk a mondatot, és annak minden apró darabját – az írásjelektől kezdve a kifejezéseken át a tokenekig – egy fa adatszerkezetté alakítjuk. Feltárja a szöveg konkrét szintaxisát, ezért konkrét szintaxisfának vagy CST-nek is nevezik. Azért használjuk a konkrét kifejezést ennek a struktúrának a leírására, mert ez a kódunk nyelvtani másolata, tokenről tokenre, fa formátumban.
De mitől lesz valami konkrét az absztrakttal szemben? Nos, egy absztrakt szintaktikai fa nem mutatja meg nekünk pontosan, hogyan néz ki egy kifejezés, ahogyan azt egy parse tree teszi.

Ehelyett egy absztrakt szintaxisfa inkább a “fontos” részeket mutatja meg nekünk – azokat a dolgokat, amelyek valóban érdekelnek minket, amelyek értelmet adnak magának a kódunk “mondatának”. A szintaxisfák egy kifejezés jelentős darabjait, illetve forrásszövegünk absztrahált szintaxisát mutatják meg nekünk. Ezért a konkrét szintaxisfákhoz képest ezek a struktúrák a kódunk absztrakt (és bizonyos szempontból kevésbé pontos) reprezentációi, és pontosan ezért kapták a nevüket.
Most, hogy megértettük a különbséget e két adatstruktúra között és a különböző módokat, ahogyan a kódunkat reprezentálhatják, érdemes feltenni a kérdést: hol illeszkedik egy absztrakt szintaxisfa a fordítóprogramba? Először is emlékeztessük magunkat mindarra, amit eddig a fordítási folyamatról tudtunk.

Tegyük fel, hogy van egy szuper rövid és édes forrásszövegünk, ami így néz ki: 5 + (1 x 12).
Emlékszünk rá, hogy a fordítási folyamat során először a szöveg beolvasása történik, ezt a munkát a beolvasó végzi, aminek eredményeképpen a szöveget a lehető legkisebb részekre, úgynevezett lexémákra bontjuk. Ez a rész nyelvfüggetlen lesz, és a végén a forrásszövegünk lecsupaszított változatát kapjuk.
A következő lépésben éppen ezeket a lexémákat adjuk át a lexálónak/tokenizálónak, amely a forrásszövegünk ezen apró reprezentációit tokenekké alakítja, amelyek a nyelvünkre jellemzőek lesznek. A tokenjeink valahogy így fognak kinézni: . A szkenner és a tokenizáló közös munkája alkotja a fordítás lexikai elemzését.
Aztán, miután a bemenetünket tokenizáltuk, az így kapott tokeneket továbbítjuk az elemzőnknek, amely fogadja a forrásszöveget, és felépít belőle egy elemzőfát. Az alábbi ábra szemlélteti, hogyan néz ki a tokenizált kódunk parse tree formátumban.
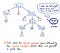
A tokenek parse tree-vé alakításának munkáját parsingnak is nevezik, és szintaxiselemzési fázisnak nevezik. A szintaxiselemzési fázis közvetlenül függ a lexikai elemzési fázistól; ezért a fordítási folyamatban mindig a lexikai elemzésnek kell az első helyen állnia, mert fordítóprogramunk elemzője csak akkor tudja elvégezni a munkáját, ha a tokenizáló elvégezte a munkáját!
A fordítóprogram részeire úgy is gondolhatunk, mint jó barátokra, akik mindannyian egymásra vannak utalva, hogy a kódunk egy szövegből vagy fájlból helyesen alakuljon át parse-fává.
De vissza az eredeti kérdésünkhöz: hol illeszkedik az absztrakt szintaxisfa ebbe a baráti körbe? Nos, ahhoz, hogy erre a kérdésre választ kapjunk, segít megérteni, hogy egyáltalán miért van szükség egy AST-re.
Egy fa kondenzálása egy másikba
Oké, tehát most már két fát kell rendben tartanunk a fejünkben. Már volt egy elemzőfánk, és hogy van még egy adatszerkezet, amit meg kell tanulnunk! És úgy tűnik, hogy ez az AST adatszerkezet csak egy egyszerűsített tagolófa. Szóval, miért van rá szükségünk? Mi értelme van egyáltalán?
Nézzük csak meg a parse-fánkat, jó?
Már tudjuk, hogy a parse-fák a programunkat a legkülönbözőbb részeiben reprezentálják; valójában ezért volt a szkennernek és a tokenizátornak olyan fontos feladata, hogy a kifejezésünket a legkisebb részeire bontja!
Mit jelent az, hogy valójában a programot a legkülönbözőbb részeiben reprezentáljuk?
Mint kiderült, néha egy program összes megkülönböztethető része valójában nem mindig olyan hasznos számunkra.
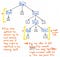
Vessünk egy pillantást az itt látható ábrára, amely az eredeti 5 + (1 x 12) kifejezésünket ábrázolja parse tree fa formátumban. Ha kritikus szemmel alaposan szemügyre vesszük ezt a fát, látni fogjuk, hogy van néhány olyan példa, ahol egy csomópontnak pontosan egy gyermeke van, amelyeket egyutódos csomópontoknak is neveznek, mivel csak egy gyermekcsomópont származik belőlük (vagy egy “utód”).
A tagolófa példánk esetében az egyutódos csomópontok szülő csomópontja egy Expression vagy Exp, amelyeknek egyetlen utódja van valamilyen értékkel, például 5, 1 vagy 12. Azonban a Exp szülő csomópontok itt valójában semmi értéket nem adnak hozzá számunkra, ugye? Láthatjuk, hogy token/terminális gyermekcsomópontokat tartalmaznak, de minket nem igazán érdekel a “kifejezés” szülői csomópont; valójában csak arra vagyunk kíváncsiak, hogy mi a kifejezés?
A szülői csomópont egyáltalán nem ad nekünk semmilyen további információt, miután elemeztük a fánkat. Ehelyett, amivel igazán foglalkozunk, az az egyetlen gyermek, egyetlen utód csomópont. Sőt, ez az a csomópont, amely a fontos információt, a számunkra lényeges részt adja: magát a számot és az értéket! Ha figyelembe vesszük, hogy ezek a szülő csomópontok számunkra eléggé feleslegesek, akkor nyilvánvalóvá válik, hogy ez a tagolófa egyfajta szószátyár.
Az összes ilyen single-successor csomópont eléggé felesleges számunkra, és egyáltalán nem segít nekünk. Szabaduljunk meg tőlük!
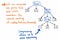
Ha a parse tree-ben lévő single-successor csomópontokat tömörítjük, akkor ugyanannak a pontos szerkezetnek egy tömörebb változatát kapjuk. Ha megnézzük a fenti ábrát, láthatjuk, hogy továbbra is pontosan ugyanazt a beágyazottságot tartjuk fenn, mint korábban, és a csomópontjaink/jegyeink/terminálisaink továbbra is a megfelelő helyen jelennek meg a fán belül. De sikerült egy kicsit karcsúsítanunk.
És a fánkból is le tudunk vágni még néhányat. Például, ha megnézzük a tagolófánkat a jelenlegi állapotában, láthatjuk, hogy van benne egy tükörszerkezet. A (1 x 12) részkifejezés () zárójelekbe van beágyazva, amelyek önmagukban is tokenek.
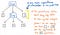
Ezek a zárójelek azonban nem igazán segítenek nekünk, ha már megvan a fánk. Már tudjuk, hogy 1 és 12 olyan argumentumok, amelyeket átadunk a x szorzás műveletnek, így a zárójelek ezen a ponton nem mondanak túl sokat. Valójában még tovább tömöríthetnénk a tagolófánkat, és megszabadulhatnánk ezektől a felesleges levélcsomópontoktól.
Mihelyt tömörítjük és egyszerűsítjük a tagolófánkat, és megszabadulunk a felesleges szintaktikai “portól”, olyan szerkezetet kapunk, amely ezen a ponton láthatóan másképp néz ki. Ez a struktúra valójában az új és várva várt barátunk: az absztrakt szintaktikai fa.

A fenti kép pontosan ugyanazt a kifejezést szemlélteti, mint a mi szintaktikai fánk: 5 + (1 x 12). A különbség az, hogy elvonatkoztatta a kifejezést a konkrét szintaxistól. Ebben a fában már nem látjuk a () zárójeleket, mert nincs rájuk szükség. Hasonlóképpen nem látunk olyan nem-terminálisokat, mint Exp, mivel már kitaláltuk, hogy mi a “kifejezés”, és képesek vagyunk kihúzni a számunkra valóban fontos értéket – például a számot 5.
Pontosan ez a megkülönböztető tényező egy AST és egy CST között. Tudjuk, hogy egy absztrakt szintaktikai fa figyelmen kívül hagyja a szintaktikai információ jelentős részét, amit egy elemzőfa tartalmaz, és kihagyja a “többlettartalmat”, amit a bontás során használunk. De most már pontosan láthatjuk, hogyan történik ez!

Most, hogy tömörítettünk egy saját szintagmafát, sokkal jobban felismerhetünk néhány mintát, amelyek megkülönböztetik az AST-t a CST-től.
Van néhány dolog, amiben egy absztrakt szintaktikai fa vizuálisan különbözik egy parse-fától:
- Egy AST soha nem tartalmaz szintaktikai részleteket, például vesszőket, zárójeleket és pontosvesszőket (természetesen a nyelvtől függően).
- Egy AST-ben összecsukott változata van az egyébként egyetlen utódnak tűnő csomópontoknak; soha nem tartalmaz olyan csomópontok “láncát”, amelyeknek egyetlen gyermeke van.
- Végül az operátorjelek (mint például
+,-,xés/) a fa belső (szülő) csomópontjaivá válnak, nem pedig a levelekké, amelyek egy tagolófában végződnek.
Vizuálisan egy AST mindig kompaktabbnak tűnik, mint egy tagolófa, mivel definíció szerint a tagolófa tömörített változata, kevesebb szintaktikai részletességgel.
Ez azt jelentené tehát, hogy ha egy AST egy tagolófa tömörített változata, akkor csak akkor tudunk igazán absztrakt szintaktikai fát létrehozni, ha kezdetben rendelkezünk a tagolófa felépítéséhez szükséges dolgokkal!
Az absztrakt szintaktikai fa valóban így illeszkedik a nagyobb fordítási folyamatba. Az AST közvetlen kapcsolatban áll a parse fákkal, amelyekről már tanultunk, miközben egyúttal a lexerre támaszkodik, hogy elvégezze a munkáját, mielőtt az AST egyáltalán létrejöhetne.

Az absztrakt szintaxisfa a szintaxiselemzési fázis végeredményeként jön létre. Az elemző, amely a szintaxiselemzés során fő “szereplőként” kerül előtérbe, vagy nem mindig generál egy elemzési fát, vagy CST-t. Magától a fordítótól és annak tervezési módjától függően az elemző közvetlenül rátérhet a szintaxisfa vagy AST létrehozására. De az elemző kimenetként mindig egy AST-t fog generálni, függetlenül attól, hogy közben létrehoz-e egy parse-fát, vagy hogy hány átfutást kell ehhez elvégeznie.
Az AST anatómiája
Most, hogy tudjuk, hogy az absztrakt szintaxisfa fontos (de nem feltétlenül félelmetes!), elkezdhetjük egy kicsit jobban boncolgatni. Az AST felépítésének egy érdekes aspektusa ennek a fának a csomópontjaival kapcsolatos.
Az alábbi kép egy absztrakt szintaxisfán belüli egyetlen csomópont anatómiáját szemlélteti.
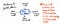
Láthatjuk, hogy ez a csomópont abban hasonlít az eddig látottakhoz, hogy tartalmaz néhány adatot (egy token és annak value). Azonban tartalmaz néhány nagyon speciális mutatót is. Egy AST minden csomópontja tartalmaz hivatkozásokat a következő testvércsomópontjára, valamint az első gyermekcsomópontjára.
A mi egyszerű 5 + (1 x 12) kifejezésünkből például felépíthető egy AST vizualizált ábrázolása, mint az alábbi.

Elképzelhetjük, hogy ennek az AST-nek az olvasása, bejárása vagy “értelmezése” a fa legalsó szintjeitől indulhat, visszafelé haladva, hogy a végére egy értéket vagy egy visszatérést result építsen fel.
A vizualizációnk kiegészítéseként az is segíthet, ha egy elemző kimenetének kódolt változatát látjuk. Különböző eszközökre támaszkodhatunk, és használhatunk már létező elemzőket, hogy lássunk egy gyors példát arra, hogyan nézhet ki a kifejezésünk, amikor lefut egy elemzőn keresztül. Az alábbiakban a forrásszövegünk 5 + (1 * 12) példáját futtatjuk végig az Esprima, egy ECMAScript elemzőn, és az eredményül kapott absztrakt szintaxisfát, majd a benne található különböző tokenek listáját.
Ebben a formátumban láthatjuk a fa egymásba ágyazottságát, ha megnézzük a beágyazott objektumokat. Észrevehetjük, hogy a 1 és 12 értékeket tartalmazó értékek egy * nevű szülőművelet left, illetve right gyermekei. Azt is látni fogjuk, hogy a szorzási művelet (*) magának az egész kifejezésnek a jobb oldali részfáját alkotja, ezért van beágyazva a nagyobb BinaryExpression objektumba, a "right" kulcs alatt. Hasonlóképpen, a 5 értéke a nagyobb BinaryExpression objektum egyetlen "left" gyermeke.

Az absztrakt szintaxisfák legérdekesebb aspektusa azonban az, hogy bár olyan kompaktak és tiszták, mégsem mindig egyszerű adatszerkezetet próbálnak létrehozni. Valójában egy AST felépítése elég bonyolult lehet, attól függően, hogy milyen nyelvvel foglalkozik az elemző!
A legtöbb elemző rendszerint vagy felépít egy szintagmafát (CST), majd átalakítja azt AST formátumba, mert ez néha egyszerűbb lehet – annak ellenére, hogy ez több lépést jelent, és általában véve több átjárást a forrásszövegen. A CST felépítése valójában elég egyszerű, ha az elemző ismeri a nyelv nyelvtanát, amelyet elemezni próbál. Nem kell bonyolult munkát végeznie, hogy kitalálja, hogy egy token “jelentős”-e vagy sem; ehelyett csak pontosan azt veszi, amit lát, abban a meghatározott sorrendben, ahogyan látja, és mindezt egy fává alakítja.
Másrészt vannak olyan elemzők, amelyek mindezt egylépéses folyamatként próbálják elvégezni, és rögtön egy absztrakt szintaktikai fa megalkotására ugranak.
Az AST közvetlen felépítése trükkös lehet, mivel az elemzőnek nem csak a tokeneket kell megtalálnia és helyesen ábrázolnia, hanem azt is el kell döntenie, hogy mely tokenek számítanak nekünk, és melyek nem.
A fordítótervezésben az AST végül több okból is szuper fontos. Igen, trükkös lehet a felépítése (és valószínűleg könnyű elrontani), de emellett ez a lexikai és a szintaktikai elemzési fázisok utolsó és végső eredménye együttesen! A lexikai és a szintaktikai elemzési fázist gyakran nevezik együttesen elemzési fázisnak, vagy a fordítóprogram front-endjének.

Az absztrakt szintaxisfára úgy is gondolhatunk, mint a fordítóprogram front-endjének “végső projektjére”. Ez a legfontosabb része, mert ez az utolsó dolog, amit a front-endnek magának kell megmutatnia. A szakkifejezés erre az úgynevezett köztes kódreprezentáció vagy IR, mert ez lesz az az adatszerkezet, amelyet a fordító végül a forrásszöveg reprezentálására használ.
Az absztrakt szintaxisfa az IR leggyakoribb formája, de néha a leginkább félreértett is. De most, hogy egy kicsit jobban megértettük, elkezdhetjük megváltoztatni a megítélésünket erről az ijesztő struktúráról! Remélhetőleg most már egy kicsit kevésbé félelmetes számunkra.
Források
Egy csomó forrás létezik az AST-ekről, a legkülönbözőbb nyelveken. Tudni, hogy hol kezdjük, trükkös lehet, különösen, ha többet szeretnénk tanulni. Az alábbiakban bemutatunk néhány kezdőbarát forrást, amelyek sokkal több részletbe merülnek el anélkül, hogy túlságosan elnagyoltak lennének. Boldog asbtracting!
- The AST vs the Parse Tree, Professor Charles N. Fischer
- What’s the difference between parse trees and abstract syntax trees?, StackOverflow
- Abstract vs. Concrete Syntax Trees, Eli Bendersky
- Abstract Syntax Trees, Professor Stephen A. Edwards
- Abstract Syntax Trees & Top-Down Parsing, Professor Konstantinos (Kostis) Sagonas
- Lexical and Syntax Analysis of Programming Languages, Chris Northwood
- AST Explorer, Felix Kling