By: Derek Colley | Frissítve: Derek Colley | Frissítve: Derek Colley Hozzászólások (5) | Kapcsolódó: 2014-01-29 | Hozzászólások (5) | Kapcsolódó: 2014-01-29 | Hozzászólások (5) | Kapcsolódó: 2014-01-29 | Hozzászólások (5) | Kapcsolódó: 2014-01-29 > További > függvények – Rendszer
Probléma
Egy SQL Server lekérdezés eredményhalmazából szeretne véletlenszerű mintát kinyerni. Talán egy nagy ügyféladatbázisból keres reprezentatív adatmintát; esetleg néhány átlagot, vagy elképzelést szeretne kapni arról, hogy milyen típusú adatokkal rendelkezik. A SELECT TOP N nem mindig ideális, mivel az adatkiugró értékek gyakran megjelennek az adathalmazok elején és végén, különösen akkor, ha ábécé vagy valamilyen skalárérték szerint vannak rendezve. Hasonlóképpen használhatta a TABLESAMPLE-t is, de ennek is vannak korlátai, különösen kis vagy ferde adathalmazok esetén. Lehet, hogy a főnöke 100 ügyfél nevének és helyének véletlenszerű kiválasztását kérte; vagy részt vesz egy könyvvizsgálatban, és az elemzéshez véletlenszerű adatmintára van szüksége. Hogyan oldaná meg ezt a feladatot? Nézze meg ezt a tippet, hogy többet tudjon meg.
Megoldás
Ez a tipp megmutatja, hogyan használhatja a TABLESAMPLE-t a T-SQL-ben álvéletlenszerű adatminták lekérdezésére, és átbeszéli a TABLESAMPLE belső tulajdonságait, valamint azt, hogy hol nem megfelelő. Bemutat egy alternatív módszert is – egy matematikai módszert, amely a NEWID()-t használja a CHECKSUMmal és egy bitenkénti operátorral párosítva, amelyet a Microsoft a TABLESAMPLE TechNet cikkben jegyzett meg. Beszélünk egy kicsit a statisztikai mintavételről általában (a véletlenszerű, a szisztematikus és a rétegzett mintavétel közötti különbségekről) példákkal, és példaként megnézzük, hogyan történik az SQL statisztikák mintavétele, és milyen opciókkal tudjuk felülbírálni ezt a mintavételt. A tipp elolvasása után tisztában kell lennie a mintavételezés előnyeivel az olyan módszerek használatával szemben, mint a TOP N, és tudnia kell, hogyan alkalmazza legalább az egyik módszert ennek elérésére az SQL Serverben.
Elkészítés
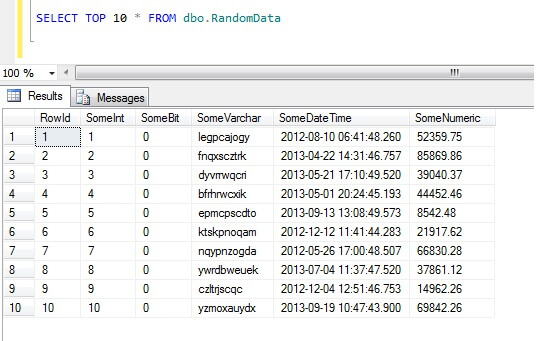
Ezért a tippért egy olyan adathalmazt fogok használni, amely egy identikus INT oszlopot (a sorok kiválasztásakor a véletlenszerűség mértékének megállapításához) és más, különböző adattípusú álvéletlen adatokat tartalmazó oszlopokat tartalmaz, hogy (homályosan) szimulálja a valós adatokat egy táblázatban. Ennek beállításához használhatja az alábbi T-SQL kódot. A futtatás mindössze néhány percet vesz igénybe, és az SQL Server 2012 Developer Edition rendszeren teszteltük.
A felső 10 adatsor kiválasztása ezt az eredményt adja (csak hogy képet kapjunk az adatok alakjáról).Mellékesen megjegyezném, hogy ez egy általános kódrészlet, amelyet azért hoztam létre, hogy véletlenszerű adatokat generáljak, amikor csak szükségem van rá – nyugodtan vegye át, és bővítse/fosztogassa kedvére!
How Not To Sample Data in SQL Server
Most már megvan az adatmintánk, gondoljuk át, hogy mi a legrosszabb módja a mintavételnek. Az AdventureWorks adatbázisban létezik egy Person.Address nevű tábla. Vegyünk mintát úgy, hogy a top 10 találatot vesszük, különösebb sorrend nélkül:
SELECT TOP 10 * FROM Person.Address
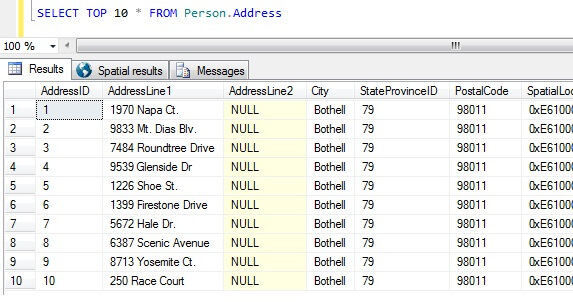
Elég ebből a mintából kiindulva láthatjuk, hogy az összes visszaküldött személy Bothellben él, és közös az irányítószámuk 98011. Ez azért van így, mert az eredmények nem meghatározott sorrendben, hanem az AddressID oszlop szerinti sorrendben kerültek visszaadásra. Megjegyzendő, hogy ez NEM garantált viselkedés a halomadatok esetében – lásd ezt az idézetet a BOL-ból:
“Általában az adatokat kezdetben abban a sorrendben tárolják, amelyben a sorokat beszúrják a táblázatba, de az adatbázis-motor a sorok hatékony tárolása érdekében mozgathatja az adatokat a halomban; így az adatok sorrendjét nem lehet megjósolni. A halomból visszaadott sorok sorrendjének garantálásához az ORDER BY záradékot kell használni.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Ezt az eredményhalmazt véve egy, a tábla természetéről nem tájékozott személy arra a következtetésre juthat, hogy az összes ügyfél Bothellben él.
Az adatmintavételezés típusai az SQL Serverben
A fentiek egyértelműen hamisak, ezért szükségünk van egy jobb mintavételi módra. Mi lenne, ha a táblázatban rendszeres időközönként vennénk mintát?
Ezzel 47 sort kellene visszaadnunk:
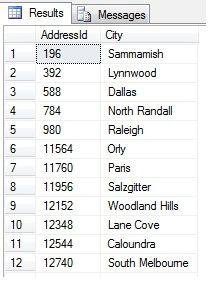
Ez eddig jó. Az adathalmazunkban rendszeres időközönként vettünk egy-egy sort, és egy statisztikai keresztmetszetet adtunk vissza – vagy mégis? Nem feltétlenül. Ne feledjük, a sorrend nem garantált. Egy-két következtetést levonhatunk ebből az adatból. A szemléltetés érdekében összesítsük őket. Futtassuk le újra a fenti kódrészletet, de az utolsó SELECT blokkot módosítsuk így:
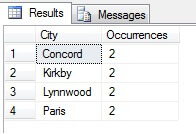
A példámban láthatjuk, hogy a Person.Address tábla több mint 19 000 sorának összlétszámából a sorok mintegy 1/4%-ából vettem mintát, és ezért arra következtethetek, hogy (példámban) Concord, Kirkby, Lynnwood és Paris rendelkezik a legtöbb lakossal, ráadásul egyformán népes. Pontos? Természetesen képtelenség:
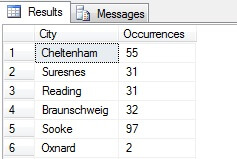
Amint láthatja, az én négy városom közül egyik sem volt a négy legkedveltebb lakóhely között a táblázat alapján. Nemcsak a mintaadatok voltak túl kicsik, de ezt a pici mintát összesítettem, és megpróbáltam következtetést levonni belőle. Ez azt jelenti, hogy az eredményhalmazom statisztikailag nem szignifikáns -a statisztikai szignifikancia bizonyítása a statisztikai összefoglalók bemutatásakor az egyik fő bizonyítási teher (vagy annak kellene lennie), és sok népszerű infografika és marketingvezérelt adatsor egyik fő buktatója.
Az ilyen módon történő mintavétel (az úgynevezett szisztematikus mintavétel) tehát hatékony, de csak statisztikailag szignifikáns populáció esetén. Vannak olyan tényezők, mint a periodicitás és az arányosság, amelyek tönkretehetik a mintát – nézzük meg az arányosságot a gyakorlatban, ha 10 városból veszünk mintát a Person.Address táblából, a következő kód segítségével, amely a Person.Address táblából egy különálló városlistát kap, majd ebből a listából szisztematikus mintavételezéssel kiválaszt 10 várost:
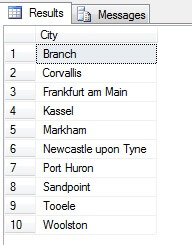
Jó mintának tűnik, igaz? Most pedig állítsuk szembe egy olyan mintával, amely a NEM megkülönböztetett, növekvő sorrendben felsorolt városokat tartalmazza, azaz minden n-edik várost, ahol n a sorok teljes száma osztva 10-zel. Ez a mérték figyelembe veszi a mintanépességet:
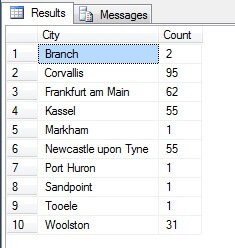
A visszakapott adatok teljesen mások – nem véletlenül, hanem egy reprezentatív minta bemutatásával. Megjegyzendő, hogy ez a lista, amelyen a forrástáblázatban az egyes városok számadatait tüntettem fel, hogy felvázoljam, mennyire játszik szerepet a népesség az adatok kiválasztásában, a minta négy legnépesebb városát tartalmazza, ami (ha egy rendezett, nem megkülönböztető listát tekintünk) a legigazságosabb reprezentációt jelenti. Nem feltétlenül ez a legjobb reprezentáció az Ön igényeihez, ezért legyen óvatos a statisztikai mintavételi módszer kiválasztásakor.
Más mintavételi módszerek
Klaszteres mintavétel – itt a mintavételezendő populációt klaszterekre vagy részhalmazokra osztják, majd ezen részhalmazok mindegyikét véletlenszerűen határozzák meg, hogy szerepeljen vagy ne szerepeljen a kimeneti eredményhalmazban. Ha szerepel, akkor az adott részhalmaz minden tagja visszakerül az eredményhalmazba. Erre egy példát lásd alább a Táblamintában.
Diszproporcionális mintavétel – ez olyan, mint a rétegzett mintavétel, ahol az alcsoportok tagjait úgy választják ki, hogy a teljes csoportot reprezentálják, de az arányosság helyett az egyes csoportokból különböző számú tagot választhatnak ki, hogy kiegyenlítsék az egyes csoportok képviseletét. Vagyis a fenti szakaszbeli példában a Person.Address táblázatban szereplő városokat tekintve az első eredményhalmaz aránytalan volt, mivel nem vette figyelembe a népességet, de a második eredményhalmaz arányos volt, mivel a Person.Address táblázatban szereplő városi bejegyzések számát reprezentálta. Ez a fajta mintavételezés valójában akkor hasznos, ha egy adott kategória alulreprezentált az adathalmazban, és az arány nem fontos (például 100 véletlenszerű ügyfél 100 véletlenszerű városból, városok szerint rétegezve – a részhalmazban lévő városokat normalizálni kellene – aránytalan mintavételt lehetne használni).
SQL Server véletlenszerű adatok TABLAKMINTÁKkal
A SQL Server segítőkészen rendelkezik egy módszerrel az adatok mintavételezésére. Nézzük meg a gyakorlatban. A következő kóddal adjunk vissza körülbelül 100 sort (ha 0 sort ad vissza, futtassuk újra – mindjárt elmagyarázom) a korábban definiált dbo.RandomData adataiból.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
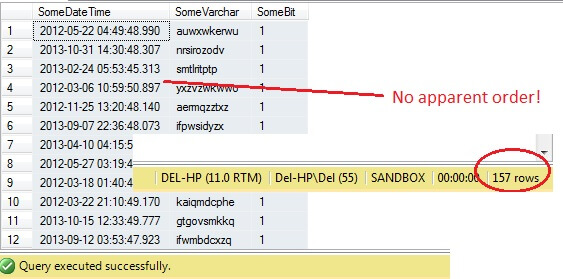
Szóval eddig minden rendben, igaz? Várjunk csak – nem látjuk az Id oszlopot. Vegyük be ezt, és futtassuk le újra:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
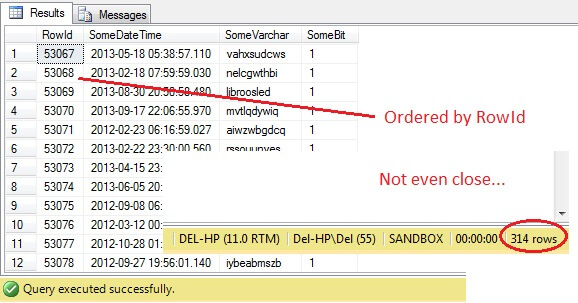
Ó, jaj – a TABLESAMPLE kiválasztott egy szeletet az adatokból, de ez nem véletlenszerű – a RowId egy jól körülhatárolt szeletet mutat, egy minimum és egy maximum értékkel. Ráadásul nem is pontosan 100 sort adott vissza. Mi folyik itt?
ATABLESAMPLE a hallgatólagos SYSTEM módosítót használja. Ez az alapértelmezés szerint bekapcsolt és ANSI-SQL specifikáció, azaz nem opcionális módosító minden egyes 8 KB-os oldalt, amelyen a táblázat található, és eldönti, hogy az átadott százalék vagy N ROWS alapján az összes olyan sort, amely azon az oldalon található, és amely a táblázatban van, bevonja-e az előállított mintába vagy sem. Ezért egy olyan táblázat, amely sok oldalon található, azaz nagyszámú adatsorral rendelkezik, véletlenszerűbb mintát fog visszaadni, mivel több oldal lesz a mintában. A miénkhez hasonló példánál, ahol az adatok skalárisak és kicsik, és csak néhány oldalon találhatóak, ez nem működik – ha néhány oldal nem kerül be a vágásba, ez jelentősen torzíthatja a kimeneti mintát. Ez a TABLESAMPLE hátránya – nem működik jól “kis” adatok esetén, és nem veszi figyelembe az adatok eloszlását az oldalakon. Tehát az adatok elrendezése az oldalakon végső soron az e módszer által visszaadott mintáért felelős.
Ez ismerősen hangzik? Lényegében klaszteres mintavételről van szó, ahol a kiválasztott csoportok (klaszterek) minden tagja (sora) reprezentálva van az eredményhalmazban.
Teszteljük le egy nagy táblán, hogy hangsúlyozzuk a fordított nem skálázhatóságot. Először is azonosítsuk az AdventureWorks adatbázis legnagyobb tábláját. Ehhez egy szabványos jelentést fogunk használni – az SSMS segítségével kattintsunk jobb gombbal az AdventureWorks2012 adatbázisra, majd lépjünk a Jelentések -> Szabványos jelentések -> Lemezhasználat a legfőbb táblák szerint menüpontra. Rendezzük az adatok(KB) szerint az oszlopfejlécre kattintva (a csökkenő sorrend érdekében ezt kétszer is megtehetjük). Az alábbi jelentést fogja látni.
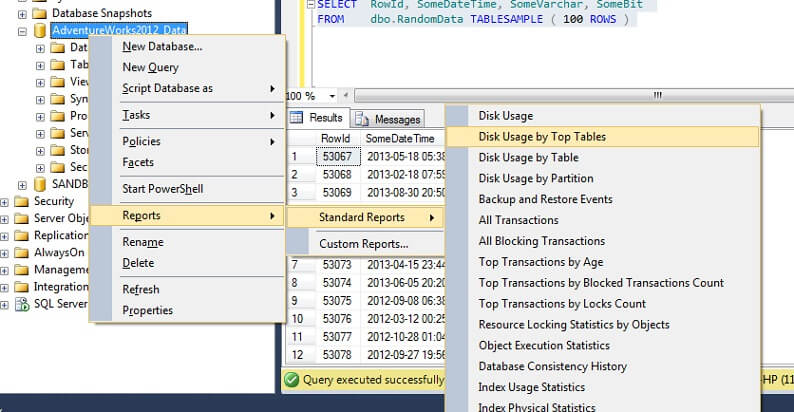
Az érdekes számot bekarikáztam – a Személy. Person tábla 30,5 MB adatot fogyaszt, és ez a legnagyobb (az adatok, nem a rekordok száma alapján) tábla. Próbáljunk meg tehát ehelyett egy mintát venni ebből a táblából:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
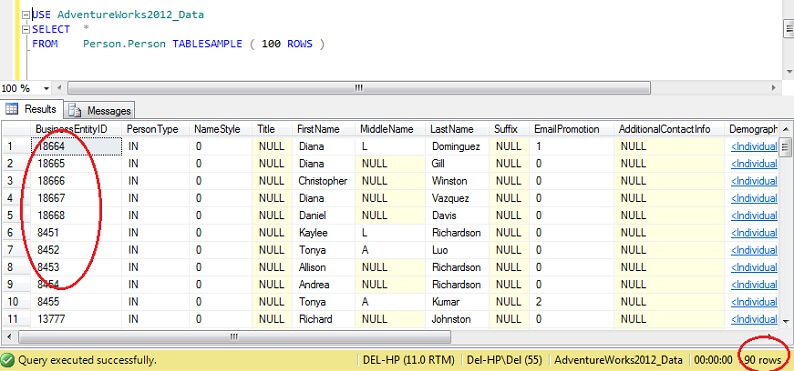
Láthatjuk, hogy sokkal közelebb vagyunk a 100 sorhoz, de ami döntő fontosságú, hogy úgy tűnik, nem nagyon van klaszteresedés az elsődleges kulcson (bár van, mivel laponként több mint 1 sor van).
Következésképpen a TABLESAMPLE jó nagy adatokhoz, és katasztrofálisan rosszabb lesz, minél kisebb az adathalmaz. Ez nem jó nekünk, amikor rétegzett adatokból vagy klaszterezett adatokból veszünk mintát, ahol sok mintát veszünk kis csoportokból vagy részadatokból, majd ezeket aggregáljuk. Akkor nézzünk meg egy alternatív módszert.
Véletlenszerű SQL Server adatok ORDER BY NEWID()
Itt egy idézet a BOL-tól a valóban véletlenszerű mintavételről:
“Ha valóban véletlenszerű mintát akarunk az egyes sorokból, akkor a TABLESAMPLE használata helyett módosítsuk a lekérdezést úgy, hogy véletlenszerűen szűrjük ki a sorokat. A következő lekérdezés például a NEWID függvényt használja a Sales.SalesOrderDetail tábla sorainak körülbelül egy százalékát adja vissza:
Hogyan működik ez? Bontsuk szét a WHERE záradékot, és magyarázzuk el.
A CHECKSUM függvény ellenőrző összeget számol a lista elemei felett. Azon lehet vitatkozni, hogy a SalesOrderID egyáltalán szükséges-e, mivel a NEWID() egy olyan függvény, amely egy új véletlen GUID-t ad vissza, így egy véletlen szám konstanssal való szorzása mindenképpen véletlenszerűt kell, hogy eredményezzen.Sőt, úgy tűnik, a SalesOrderID kizárása nem jelent különbséget. Ha lelkes statisztikus vagy, és meg tudod indokolni ennek felvételét, kérlek, használd az alábbi megjegyzés rovatot, és tudasd velem, miért tévedek!
A CHECKSUM függvény egy VARBINARY-t ad vissza. A bitenkénti ÉS művelet végrehajtása a 0x7fffffffff-fel, ami binárisan a (11111111111…) egyenértékű, egy decimális értéket ad, amely gyakorlatilag egy 0-ból és 1-ből álló véletlenszerű karakterlánc reprezentációja. A 0x7fffffffffff együtthatóval való osztás ezt a decimális számot gyakorlatilag 0 és 1 közötti értékre normalizálja. Ezután annak eldöntésére, hogy az egyes sorok érdemesek-e a végső eredményhalmazba való felvételre, 1/x küszöbértéket használunk (ebben az esetben 0,01), ahol x az adatok mintaként kinyerendő százalékát jelenti.
Vigyázzunk, hogy ez a módszer inkább egyfajta véletlen mintavétel, mint szisztematikus mintavétel, így valószínűleg a forrásadatok minden részéből kapunk adatokat, de a kulcs itt az, hogy *lehet* nem. A véletlenszerű mintavétel jellege azt jelenti, hogy bármelyik begyűjtött minta torzíthat az adatok egy szegmense felé, így az átlagra való regresszió (ebben az esetben a véletlenszerű eredmény felé mutató tendencia) előnyeinek kihasználása érdekében biztosítsa, hogy több mintát vegyen, és ezek egy részhalmazából válasszon, ha az eredményei torznak tűnnek. Vagy vegyen mintát az adatok részhalmazaiból, majd ezeket összesítse – ez a mintavétel egy másik típusa, az úgynevezett rétegzett mintavétel.
Hogyan történik az SQL Server statisztikáinak mintavétele?
Az SQL Serverben az oszlopok vagy a felhasználó által meghatározott statisztikák automatikus frissítésére akkor kerül sor, ha egy adott táblázatban a táblázat sorainak egy meghatározott küszöbértéke megváltozik. A 2012-es év esetében ez a küszöbérték SQRT(1000 * TR), ahol TR a táblázat sorainak száma a táblázatban. 2005 előtt a statisztikák automatikus frissítési feladata a táblázat sorainak minden (500 sor + 20%-os változása) után elindul. Amint az automatikus frissítési folyamat elindul, a mintavételezés *csökkenti a mintavételezett sorok számát, minél nagyobb lesz a tábla*, más szóval van egy fordított arányhoz hasonló kapcsolat a tábla mintavételi százalékos aránya és a tábla mérete között, de egy saját algoritmust követ.
Érdekes, hogy ez ellentétesnek tűnik a Táblaminta (N PERCENT) opcióval, ahol a mintavételezett sorok száma normál arányban van a tábla sorainak számával. Kikapcsolhatjuk az automatikus statisztikát (ezzel óvatosan járjunk el), és manuálisan frissíthetjük a statisztikákat – ezt az UPDATE STATISTICS utasításon a NORECOMPUTE használatával érhetjük el. Az UPDATE STATISTICS utasítással felülbírálhatunk néhány opciót – például választhatjuk, hogy N sort vagy N százalékot szeretnénk mintavételezni (hasonlóan a TABLESAMPLE utasításhoz), FULLSCAN-t végezhetünk, vagy egyszerűen RESAMPLE-t végezhetünk az utolsó ismert arányt használva.
Következő lépések
További olvasnivaló: Joseph Sack a Microsoft MVP-je, aki az SQL Server statisztikai elemzésével kapcsolatos munkájáról ismert – alább talál néhány hivatkozást a munkájára, valamint néhány hivatkozást a cikkhez felhasznált munkákra és az MSSQLTips.com néhány kapcsolódó tippjére. Köszönjük, hogy elolvasta!
Most Updated: 2014-01-29


A szerzőről
 Derek Colley brit DBA és BI fejlesztő több mint egy évtizedes SQL Server, Oracle és MySQL tapasztalattal rendelkezik.
Derek Colley brit DBA és BI fejlesztő több mint egy évtizedes SQL Server, Oracle és MySQL tapasztalattal rendelkezik.Minden tippem megtekintése
- Még több adatbázis-fejlesztői tipp…