Bevezetés
Ha többszörös regresszióval elemzi adatait, és bármelyik független változót nominális vagy ordinális skálán mérte, tudnia kell, hogyan hozzon létre dummy-változókat és hogyan értelmezze azok eredményeit. Ennek oka, hogy a nominális és ordinális független változókat, tágabb értelemben kategorikus független változókat nem lehet közvetlenül beírni a többszörös regresszióelemzésbe. Ehelyett dummy-változókká kell alakítani őket. Kivételt képeznek az ordinális független változók, amelyek folyamatos független változóként kerülnek be a többszörös regresszióba, és amelyeket nem kell dummy-változókká alakítani. Ezért ebben az útmutatóban megmutatjuk, hogyan hozhatunk létre dummy változókat, ha kategorikus független változókkal rendelkezünk.
Először bemutatjuk a példát, amelyen keresztül bemutatjuk, hogyan hozhatunk létre dummy változókat az SPSS Statisticsban, majd elmagyarázzuk, hogyan állíthatjuk be adatainkat az SPSS Statistics Variable View és Data View ablakaiban, hogy létrehozhassunk dummy változókat. Ha nem ismeri a dummy változók használatát, javasoljuk, hogy ezután olvassa el a dummy változók és a dummy kódolás néhány alapelvét, többek között: (a) az elemzésben létrehozandó dummy változók számát; és b) a dummy változók és a dummy kódolás létrehozásának módját. Az ezt követő Eljárás részben ismertetjük az SPSS Statistics-ban található egyszerű, 3 lépésből álló Dummy-változók létrehozása eljárást, amelyet a dummy-változók létrehozására használhatunk. Végül ismertetjük az SPSS Statistics kimenetét a Create Dummy Variables eljárás futtatása után, beleértve azt is, hogy a dummy változók mostantól hogyan lesznek beállítva az SPSS Statistics Variable View és Data View ablakaiban.
Megjegyzés: Ha úgy találja, hogy az ebben az útmutatóban szereplő eljárások nem fedik le az Ön által létrehozni kívánt dummy változók típusát, kérjük, lépjen kapcsolatba velünk. Lehet, hogy egy másik útmutatóval tudunk segíteni az oldalon.
SPSS Statistics
Az útmutatóban használt példa
Az útmutatóban 10 triatlonista példáját fogjuk használni, akiket arra kértünk, hogy válasszák ki kedvenc sportágukat a három sportág közül, amelyet triatlonozás közben végeznek: úszás, kerékpározás és futás. Válaszaikat a favourite_sport nevű nominális független változóban rögzítettük, amelynek három kategóriája van: “úszás”, “kerékpározás” és “futás”. Ezt a nominális független változót, a kedvenc_sportágat, be kellett vonni egy többszörös regressziós elemzésbe, amely számos folytonos független változót is tartalmazott. Mivel ez a független változó kategorikus volt (azaz a nominális változók és az ordinális változók nagyjából kategorikus változóknak minősíthetők), dummy változókat kellett létrehozni, mielőtt a többszörös regressziós elemzésbe be lehetett volna vinni.
Fontos: Vegyük észre, hogy a kedvenc_sport egy nominális változó, de egy ordinális változóhoz dummy változókat is létrehozhatunk. Továbbá a dummy változók létrehozásának folyamata ugyanaz, függetlenül attól, hogy ordinális vagy nominális változóról van szó, kivéve egy apró változtatást, amelyet az adatok beállításakor kell elvégeznie, és amelyet alább ismertetünk.
1. megjegyzés: A kategorikus független változó “kategóriáit” “csoportoknak” vagy “szinteknek” is nevezik, de a “szintek” kifejezést általában olyan kategóriákra tartjuk fenn, amelyeknek van egy sorrendje (pl. az ordinális független változónak, a “fittségi szint”-nek három szintje lehet: “alacsony”, “közepes” és “magas”). Ez a három kifejezés – “kategóriák”, “csoportok” és “szintek” – azonban felcserélhető egymással. Ebben az útmutatóban kategóriákként fogunk rájuk hivatkozni, de ha úgy tetszik, csoportokként vagy szintekként is hivatkozhat rájuk.
2. megjegyzés: A “kategorikus független változók” (azaz az “ordinális” vagy “nominális” független változók) helyett néha a “tényezők” kifejezést használják. Ez a két kifejezés – “kategorikus független változók” és “faktorok” – azonban felcserélhető egymással. Ebben az útmutatóban kategorikus független változóként fogunk rájuk hivatkozni, és az SPSS Statistics többszörös regressziós eljárásában is független változóként fog rájuk hivatkozni a faktorok helyett. Azonban hivatkozhat rájuk faktorokként is, ha szeretné.
SPSS Statistics
Az adatok beállítása az SPSS Statisticsban
A dummy változók létrehozásakor egyetlen kategorikus független változóval kezdünk (pl. kedvenc_sport). Ennek a kategorikus független változónak a beállításához az SPSS Statistics rendelkezik egy Változó nézettel, ahol meghatározhatja az elemzett változó típusait, és egy Adat nézettel, ahol megadhatja az adatokat ehhez a változóhoz. Ebben a szakaszban először azt mutatjuk be, hogyan állíthat be egy kategorikus független változót az SPSS Statistics Variable View (Változó nézet) ablakában, majd azt, hogyan adhatja meg adatait az Data View (Adatok nézete) ablakban. Ezt kategorikus független változónk, a favourite_sport segítségével tesszük, amelynek három kategóriája van: “úszás”, “kerékpározás” és “futás”.
A Variable View in SPSS Statistics
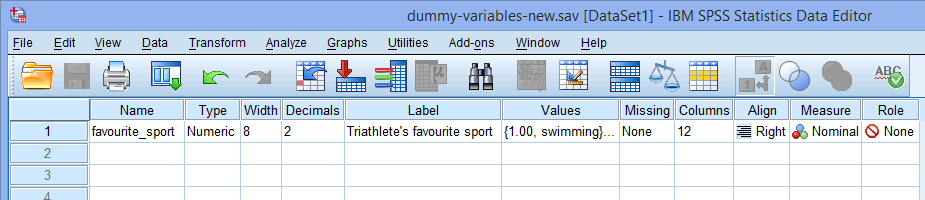
Egyetlen kategorikus független változóhoz (pl.:, kedvenc_sport), a Variable View ablak az alábbiak szerint fog kinézni:
Megjegyzés: A Variable Viewablakot az SPSS Statistics programban az SPSS Statistics szoftver bal alsó sarkában található ![]() fülre kattintva érheti el.
fülre kattintva érheti el.
Ez az SPSS Statistics, IBM Corporation írásos engedélyével jelent meg.
A kategorikus független változó nevét a ![]() oszlop alatti cellába kell beírni (pl, “kedvenc_sport” a
oszlop alatti cellába kell beírni (pl, “kedvenc_sport” a ![]() sorban a mi kategorikus független változónk, a kedvenc_sport jelölésére. Vannak bizonyos “tiltott” karakterek, amelyeket nem lehet beírni a
sorban a mi kategorikus független változónk, a kedvenc_sport jelölésére. Vannak bizonyos “tiltott” karakterek, amelyeket nem lehet beírni a ![]() cellába. Ezért, ha hibaüzenetet kap, és szeretné, ha hozzáadnánk egy SPSS Statistics útmutatót, amely elmagyarázza, hogy mik ezek az illegális karakterek, kérjük, vegye fel velünk a kapcsolatot.
cellába. Ezért, ha hibaüzenetet kap, és szeretné, ha hozzáadnánk egy SPSS Statistics útmutatót, amely elmagyarázza, hogy mik ezek az illegális karakterek, kérjük, vegye fel velünk a kapcsolatot.
Megjegyzés: A saját egyértelműsége érdekében a ![]() oszlopban is megadhatja a változók címkéjét. Például a “favourite_sport” címkét a következőképpen adtuk meg: “Triatlonista kedvenc sportja”.
oszlopban is megadhatja a változók címkéjét. Például a “favourite_sport” címkét a következőképpen adtuk meg: “Triatlonista kedvenc sportja”.
A ![]() oszlop alatti cellának tartalmaznia kell a kategorikus független változója kategóriáira vonatkozó információkat (pl. “úszás”, “kerékpározás” és “futás” a favourite_sport esetében. Ezen információk megadásához kattintson a
oszlop alatti cellának tartalmaznia kell a kategorikus független változója kategóriáira vonatkozó információkat (pl. “úszás”, “kerékpározás” és “futás” a favourite_sport esetében. Ezen információk megadásához kattintson a ![]() oszlop alatti cellába a független változójához. A
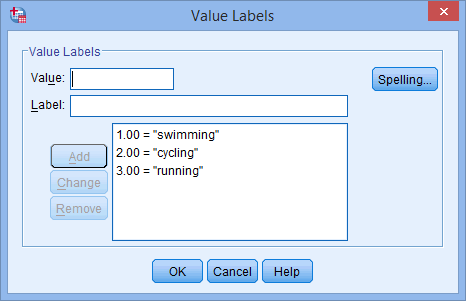
oszlop alatti cellába a független változójához. A ![]() gomb fog megjelenni a cellában. Kattintson erre a gombra, és megjelenik az Értékcímkék párbeszédpanel. Most a független változó minden egyes kategóriájának “értéket” kell adnia, amelyet az Érték: mezőbe ír be (pl. “1”), valamint egy “címkét”, amelyet a Címke: mezőbe ír be (pl. “úszás”). A
gomb fog megjelenni a cellában. Kattintson erre a gombra, és megjelenik az Értékcímkék párbeszédpanel. Most a független változó minden egyes kategóriájának “értéket” kell adnia, amelyet az Érték: mezőbe ír be (pl. “1”), valamint egy “címkét”, amelyet a Címke: mezőbe ír be (pl. “úszás”). A ![]() gombra kattintva a kódolás megjelenik a fődobozban (pl. “1.00=”úszás” a kedvenc_sportág esetében). A kategorikus független változónk beállítása az alábbi Value Labels párbeszédpanelben látható:
gombra kattintva a kódolás megjelenik a fődobozban (pl. “1.00=”úszás” a kedvenc_sportág esetében). A kategorikus független változónk beállítása az alábbi Value Labels párbeszédpanelben látható:
Published with written permission from SPSS Statistics, IBM Corporation.
A ![]() oszlop alatti cellában
oszlop alatti cellában ![]() -nek kell szerepelnie, ha nominális független változót használunk (pl., kedvenc_sport, mint példánkban), vagy
-nek kell szerepelnie, ha nominális független változót használunk (pl., kedvenc_sport, mint példánkban), vagy ![]() , ha ordinális független változója van (pl. képzeljünk el egy ordinális változót, mint a “Body Mass Index” (BMI), BMI), amelynek négy szintje van: “Alulsúlyos”, “Egészséges/normális testsúlyú”, “Túlsúlyos” és “Elhízott”). Végül a
, ha ordinális független változója van (pl. képzeljünk el egy ordinális változót, mint a “Body Mass Index” (BMI), BMI), amelynek négy szintje van: “Alulsúlyos”, “Egészséges/normális testsúlyú”, “Túlsúlyos” és “Elhízott”). Végül a ![]() oszlop alatti cellában
oszlop alatti cellában ![]() .
.
Megjegyzés: Javasoljuk, hogy a ![]() oszlop alatti cellát változtassa meg
oszlop alatti cellát változtassa meg ![]() -ről
-ről ![]() -re, de ezt a változtatást nem kell elvégeznie. Azért javasoljuk, mert vannak olyan elemzések az SPSS Statistics-ban, ahol a
-re, de ezt a változtatást nem kell elvégeznie. Azért javasoljuk, mert vannak olyan elemzések az SPSS Statistics-ban, ahol a ![]() beállítás azt eredményezi, hogy a változók automatikusan átkerülnek az Ön által használt párbeszédpanelek bizonyos mezőibe. Mivel nem biztos, hogy szeretné ezeket a változókat átvinni, javasoljuk, hogy a
beállítás azt eredményezi, hogy a változók automatikusan átkerülnek az Ön által használt párbeszédpanelek bizonyos mezőibe. Mivel nem biztos, hogy szeretné ezeket a változókat átvinni, javasoljuk, hogy a ![]() beállítást módosítsa
beállítást módosítsa ![]() -re, hogy ez ne történjen meg automatikusan.
-re, hogy ez ne történjen meg automatikusan.
Most sikeresen beírt minden olyan információt a Variable View ablakba, amit az SPSS Statisticsnak tudnia kell a kategorikus független változójáról. A következő részben megmutatjuk, hogyan adja be az adatait az Adatnézet ablakba.
Az adatnézet az SPSS Statisticsban
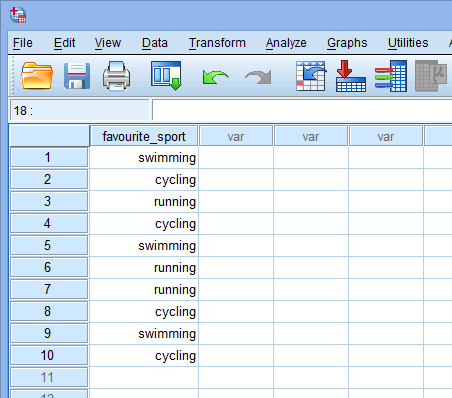
A fenti Variable View ablakban a kategorikus független változójának fájlbeállítása alapján az Adatnézet ablak a következőképpen néz ki:
Megjegyzés: Az SPSS Statistics szoftver bal alsó sarkában található ![]() fülre kattintva érheti el az Adatnézet ablakot.
fülre kattintva érheti el az Adatnézet ablakot.
Az SPSS Statistics, IBM Corporation írásos engedélyével jelent meg.
A kategorikus független változó az első oszlopban fog megjelenni, mivel ebben a sorrendben adtuk meg a változót a Variable View ablakban. Példánkban a 10 triatlonista válaszai a ![]() oszlop alatt jelennek meg. Most egyszerűen csak be kell írnia az adatait az ezen első oszlop alatti cellákba. Ne feledje, hogy minden sor egy-egy esetet képvisel (pl. egy eset lehet egyetlen résztvevő). Ezért példánk
oszlop alatt jelennek meg. Most egyszerűen csak be kell írnia az adatait az ezen első oszlop alatti cellákba. Ne feledje, hogy minden sor egy-egy esetet képvisel (pl. egy eset lehet egyetlen résztvevő). Ezért példánk ![]() sorában az első eset egy olyan triatlonistát jelent, akinek a kedvenc sportága az “úszás”. Mivel ezek a cellák kezdetben üresek lesznek, az adatok megadásához be kell kattintania a cellákba. Észre fogja venni, hogy amikor a
sorában az első eset egy olyan triatlonistát jelent, akinek a kedvenc sportága az “úszás”. Mivel ezek a cellák kezdetben üresek lesznek, az adatok megadásához be kell kattintania a cellákba. Észre fogja venni, hogy amikor a ![]() oszlop alatti cellákba kattint, az SPSS Statistics egy legördülő opciót ad, amelyben a kategóriák már ki vannak töltve.
oszlop alatti cellákba kattint, az SPSS Statistics egy legördülő opciót ad, amelyben a kategóriák már ki vannak töltve.
Most, hogy beállította az adatait az SPSS Statistics Variable View és Data View ablakaiban, javasoljuk a következő szakasz elolvasását: Dummy-változók és dummy-kódolás megértése, ahol elmagyarázzuk a dummy-változók és a dummy-kódolás alapelveit. Ha azonban már ismeri a dummy-változók és a dummy-kódolás alapjait, akkor ezt a szakaszt átugorhatja, és egyenesen az Eljárás szakaszra léphet, ahol bemutatjuk a dummy-változók létrehozására szolgáló Create Dummy Variables eljárást az SPSS Statistics-ban.
SPSS Statistics
A dummy-változók és a dummy-kódolás megértése
Amint azt a Bevezetésben említettük, ha adatait többszörös regresszióval elemzi, és bármelyik független változóját nominális vagy ordinális skálán mérte, tudnia kell, hogyan hozzon létre dummy-változókat és hogyan értelmezze azok eredményeit. Ennek oka, hogy a kategorikus független változókat (azaz a nominális és ordinális független változókat) nem lehet közvetlenül beírni a többszörös regresszióba. Ehelyett dummy-változókká kell alakítani őket. Kivételt képeznek az ordinális független változók, amelyek folyamatos független változóként kerülnek be a többszörös regresszióba, és amelyeket nem kell dummy-változókká alakítani. Az alábbi szakaszokban elmagyarázzuk: (a) a létrehozandó dummy változók számát; és (b) a dummy változók létrehozásának és a dummy kódolásnak a módját.
A létrehozandó dummy változók száma
A létrehozandó dummy változók száma attól függ, hogy a kategorikus független változónak hány kategóriája van. Általános szabály, hogy eggyel kevesebb dummy változót hoz létre, mint ahány kategória van a kategorikus független változóban. Például, ha van egy kategorikus független változója három kategóriával (pl. kedvenc_sport, a következő három kategóriával: “úszás”, “kerékpározás” és “futás”), akkor két dummy változót hoz létre, és kiválaszt egy kategóriát referenciakategóriaként (pl. az “úszás” és a “kerékpározás” dummy változók lesznek, és a “futás” lesz a referenciakategória). A referenciakategóriákról bővebben a következő táblázat után magyarázunk, amely néhány példát mutat be a kategorikus független változókra és a létrehozandó dummy változók számára:
| A kategorikus független változó neve | Változó típusa | Kategóriák száma | Kategóriák száma | Kategóriák száma. dummy változók | |||
|---|---|---|---|---|---|---|---|
| 1 | Gender | Nominal | Two (Males & Females) |
One=Males “Females” a referencia kategória |
|||
| 2 | magasság | Ordinal | Two (Under 180cm & 180cm and above) |
One=Under 180cm “180cm és felette” a referencia kategória |
|||
| 3 | Ethnicity | Nominal | Three (African American, Kaukázusi & spanyolajkú) |
Kettő=Afrikai amerikai & Kaukázusi “Spanyolajkú” a referencia kategória |
|||
| 4 | Fizikai aktivitás szintje | Ordinális | Három (Alacsony, Mérsékelt & Magas) |
Kettő=alacsony & Mérsékelt A “Magas” a referencia kategória |
|||
| 5 | Foglalkozás | Nominális | Négy (Sebész, Orvos, ápoló & Terapeuta) |
Három=Sebész, orvos & ápoló “Terapeuta” a referencia kategória |
|||
| 6 | Az egyetértés szintje | Ordinális | Négy (Teljes mértékben egyetért, Egyetért, Nem értek egyet, Egyáltalán nem értek egyet) |
Három=Teljesen egyetért, Egyetértek & Nem értek egyet “Egyáltalán nem értek egyet” a referencia kategória |
|||
| 7 | Tárgykör | Nominális | Öt (Üzleti tanulmányok, Pszichológia, Biológiai tudományok, Mérnöki tudományok & Jog) |
Négyes=Üzleti tanulmányok, Pszichológia, Biológiai tudományok & Mérnöki tudományok A “Jog” a referencia kategória |
|||
| 8 | Kor | Soros | Ötös (18 év alatt, 19-30, 31-40, 41-50, 51-60) |
Négy=18 év alatti, 19-30, 31-40 & 41-50 “51-60” a referencia kategória |
|||
| táblázat: Példák kategorikus független változókra és a hozzájuk tartozó dummy változókra | |||||||
Amint a fenti táblázatban látható, csak eggyel kevesebb dummy változót kell létrehozni, mint ahány kategória van a kategorikus független változóban. Ennek az az oka, hogy csak akkor kell (és érdemes) ennyi dummy változót átvinnie a többszörös regresszióba, ha kategorikus független változóval rendelkezik. Vannak azonban jó okok arra, hogy a kategorikus független változó minden kategóriájához hozzon létre egy dummy változót: (a) rugalmasabb, és (b) lehetővé teszi többszörös összehasonlítások elvégzését (lásd az alábbi megjegyzést). Más szóval, ha a kategorikus független változónak három kategóriája van, akkor három dummy változót kell létrehozni, nem csak kettőt.
Szerencsére az SPSS Statistics 22-es és magasabb verziójában a Create Dummy Variables eljárás automatikusan létrehoz egy dummy változót a kategorikus független változó minden kategóriájához. Ez azonban nem érvényes az SPSS Statistics 21-es vagy korábbi verziójában a Recode into Different Variables (Újrakódolás különböző változókba) eljárásra. Ezért normál körülmények között az SPSS Statistics programban a következő beállításokat hozta létre, attól függően, hogy a 21-es vagy korábbi, illetve a 22-es vagy magasabb verzióval rendelkezik-e:
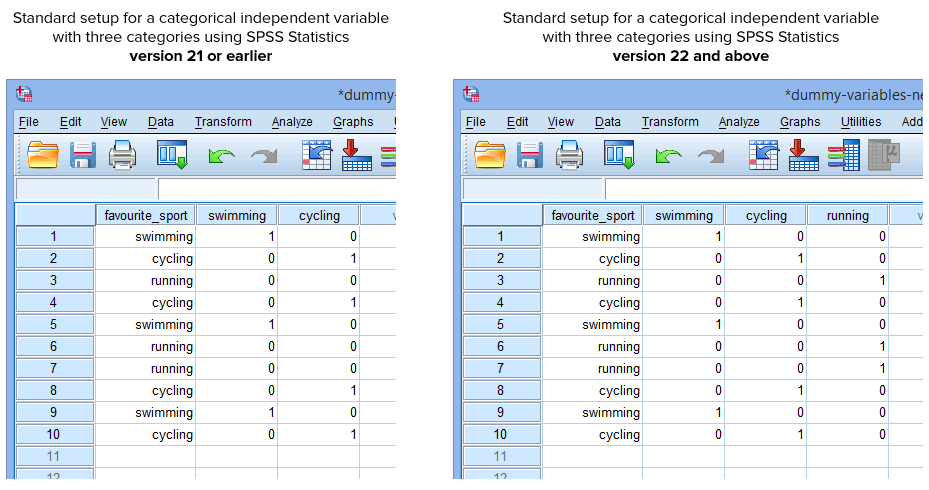
Published with written permission from SPSS Statistics, IBM Corporation.
Megjegyzés: Mint már említettük, a kategorikus független változó minden kategóriájához egy dummy változó létrehozása két okból is előnyös: (a) rugalmasabb, és (b) lehetővé teszi többszörös összehasonlítások elvégzését. Az alábbiakban röviden kitérünk ezekre az előnyökre:
Flexibilisebb:
Ha a kategorikus független változó minden kategóriájához létrehozott egy dummy változót, akkor bármelyik kategóriát tekintheti referencia-kategóriának. Példánkban a “futás” kategóriát tekintettük referenciakategóriának, ami azt jelenti, hogy az “úszást” és a “kerékpározást” is átvettük volna a többszörös regressziós egyenletbe. Ha azonban később meggondolnánk magunkat a referenciakategória kiválasztásával kapcsolatban, akkor újra le kellene futtatnunk a dummy változó eljárást (kivéve, ha az SPSS Statistics 22-es vagy magasabb verziójával rendelkezik). Tegyük fel például, hogy most a “kerékpározás” kategóriát szeretnénk referencia-kategóriának tekinteni. Most átvihetnénk az “úszás” és a “futás” dummy változókat a többszörös regressziós egyenletbe, mivel a “futás” dummy változó is megvan.
Ez lehetővé teszi többszörös összehasonlítások elvégzését:
A dummy változó együtthatója az adott dummy változó által reprezentált kategória és a referencia kategória közötti különbséget jelenti. Például, ha a “futás” a referencia-kategória, az “úszás” dummy változó együtthatója a függő változóban az “úszás” és a “futás” kategóriák közötti különbséget jelenti. Ezzel a módszerrel a kategóriák nem minden kombinációja lehetséges. Ez a probléma megoldható különböző referencia-kategóriák használatával. Ez akkor lehetséges, ha a kategorikus változó minden kategóriája rendelkezik dummy változóval.
Hogyan hozzunk létre dummy változókat és dummy kódolást
A dummy változók sikeres beállításának két lépése van egy többszörös regresszióban: (1) hozzon létre olyan dummy-változókat, amelyek a kategorikus független változó kategóriáit képviselik; és (2) adjon értékeket ezekbe a dummy-változókba – úgynevezett dummy-kódolás – a kategorikus független változó kategóriáinak képviseletére. Ezt a folyamatot az alábbiakban a fenti példánkon keresztül magyarázzuk el.
Magyarázat: A dummy változók egyszerűen olyan új változók, amelyek egy adott kódolási séma “helyőrzőiként” működnek. Önmagukban nem tartalmaznak semmilyen adatot. Ehelyett adatokat/értékeket kell hozzáadni ezekhez a dummy változókhoz, hogy betölthessék azt a céljukat, hogy a kategorikus független változó kategóriáit reprezentálják. Számos különböző típusú kódolási séma létezik, amely meghatározza a dummy-változókba beírt értékeket, de mi egy nagyon gyakori kódolási sémát használunk, amelyet dummy-kódolásnak vagy alternatívaként indikátor-kódolásnak nevezünk (N.B., ne keverjük össze, mert a dummy-változók és a dummy-kódolás nem ugyanaz a dolog). A dummy-kódolás úgy működik, hogy minden dummy-változót egy kategorikus független változó egy adott kategóriájának azonosítására használunk, kivéve a referencia-kategóriát, amelyet alább ismertetünk.
Kezdjük a példánkban szereplő kategorikus független változóval, a kedvenc_sporttal, amelynek három kategóriája van: “úszás”, “kerékpározás” és “futás”. Mivel három kategória van, két dummy változóra van szükség, amelyek két kategóriát képviselnek, és egy referenciakategóriára, amely a harmadik kategóriát képviseli.
Megjegyzés: Emlékezzünk a fenti megbeszélésből, hogy a többszörös regresszióhoz eggyel kevesebb dummy változót kell átadni, mint ahány kategória van a kategorikus független változóban (azaz példánkban kettő). A nagyobb rugalmasság és a többszörös összehasonlítás lehetősége érdekében azonban létrehozhat egy dummy változót a kategorikus független változó minden kategóriájához. Ennek ellenére az alábbi vitában csak azt emeljük ki, ami a többszörös regresszióhoz szükséges; vagyis eggyel kevesebb dummy változó létrehozását, mint ahány kategória van a kategorikus független változóban, és a közvetlenül nem reprezentált kategória lesz a “referencia-kategória”.
Elképzelhető például, hogy az 1. dummy változó az “úszás” kategóriát, a 2. dummy változó pedig a “kerékpározás” kategóriát képviseli. Így nem marad dummy változó a “futás” kategóriára. Ez a “hiányzó” kategória a referencia kategória, és nincs rá szükség. Továbbá, kizárólag az Ön döntésén múlik, hogy melyik kategóriát kívánja referenciakategóriaként használni. Ugyanilyen könnyen választhattuk volna referenciakategóriának az “úszás” kategóriát a “futás” kategória helyett. Az egyetlen ok, amiért nem tettük, hogy az SPSS Statistics alapértelmezés szerint azt az utolsó kategóriát használja referenciakategóriaként, amelyet a Variable View-ban a kategorikus független változóhoz kódolt (lásd az alábbi megjegyzést).
Megjegyzés: Amint azt korábban az Adatbeállítás című részben kifejtettük, és amint az alább az Értékcímkék párbeszédpanelen látható, a mi kategorikus független változónk harmadik és utolsó kategóriája a “futás” volt (azaz, 3=”running”).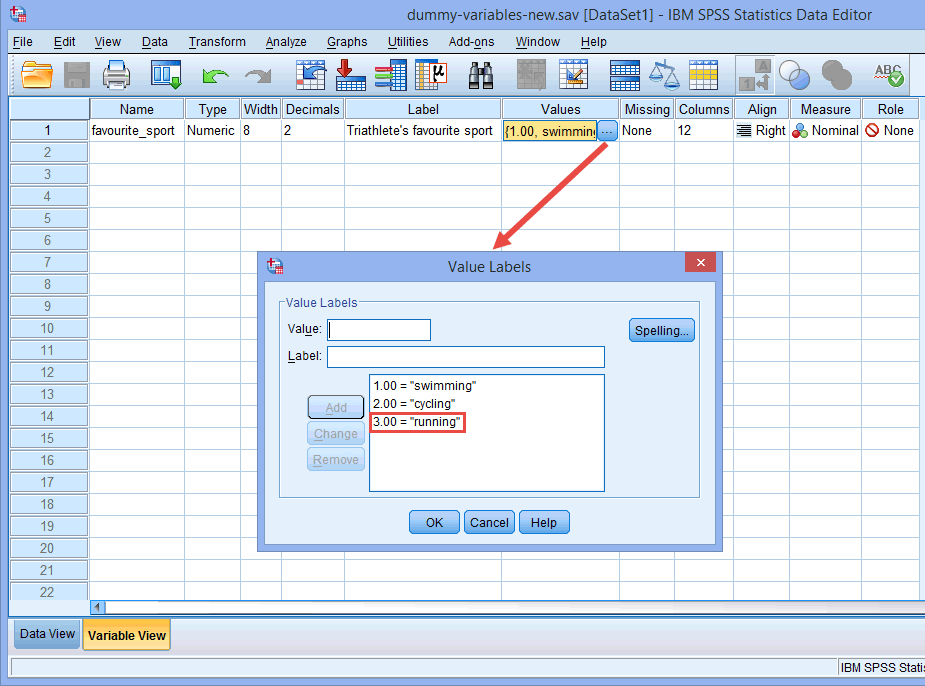
Nem volt elméleti vagy statisztikai okunk arra, hogy a “running” kategóriát tegyük a harmadik és utolsó kategóriává, így az SPSS Statisticsban alapértelmezés szerint ez lett a referencia-kategória. Egyszerűen azért tettük így, mert amikor a triatlonisták részt vesznek egy triatlonversenyen, először úsznak, majd vállalják a kerékpározást, mielőtt végül befutnak a célba. Ezért logikusnak tűnt, hogy kategorikus független változóinkat így kódoljuk. Azonban kódolhattuk volna úgy is, hogy 1=kerékpározás, 2=futás és 3=úszás; ez nem jelentett volna különbséget, kivéve azt a tényt, hogy harmadik és utolsó kategóriaként az SPSS Statisticsban alapértelmezés szerint az “úszás” lett volna a referencia-kategóriánk.
Amikor dummy változókat hozunk létre, értelmes nevet kell adni nekik. Mivel minden egyes dummy-változónk a kategorikus független változónk egy-egy kategóriáját képviseli, az egyes dummy-változókra az általuk képviselt kategória nevével szokás hivatkozni. Ezért az 1-es számú dummy változót “úszás”-nak neveztük el, mivel az úszás kategóriát képviseli. Hasonlóképpen, a 2. dummy változót “kerékpározás”-nak neveztük el, mivel a kerékpározás kategóriáját képviseli. E két dummy változó létrehozásával két új oszlopot kapunk az SPSS Statistics programban az adathalmazunkban, ahogy az alábbiakban látható:
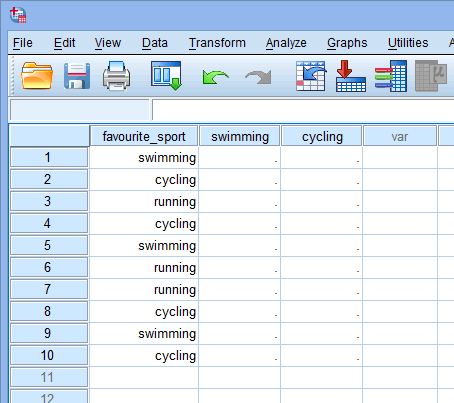
Published with written permission from SPSS Statistics, IBM Corporation.
Most, hogy létrehoztunk két dummy változót és megfelelő neveket adtunk nekik, értékeket kell beírnunk ezekbe a változókba, hogy mindegyik dummy változó valóban a kategorikus független változó kategóriáját képviselje. A dummy kódolással ez nagyon egyszerű. Az “1” értéket kell beírni minden olyan eset (pl. egy résztvevő az adathalmazban) jelölésére, amely rendelkezik a kategóriával, és a “0” (nulla) értéket kell beírni, ha nem rendelkezik a kategóriával. Vegyük először az “úszás” dummy változót az alábbiak szerint:
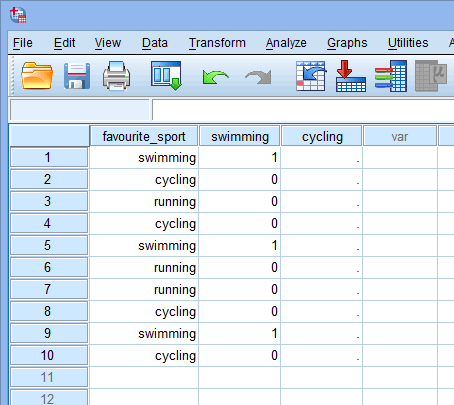
Ez az SPSS Statistics, IBM Corporation írásos engedélyével jelent meg.
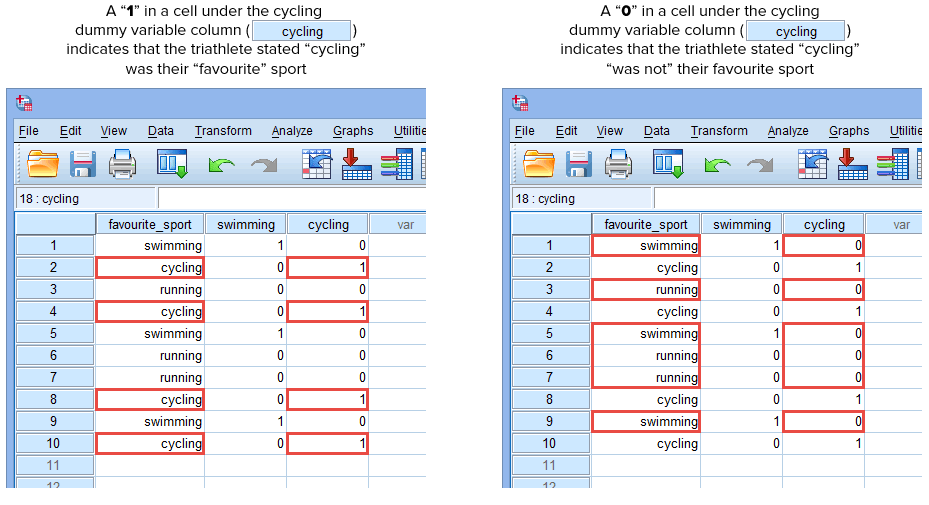
Ha az egyik triatlonista azt állította, hogy az “úszás” a “kedvenc” sportja, akkor az úszás dummy változó oszlop alatti cellába (![]() ) “1-et” írunk be arra a triatlonistára, aki azt állította, hogy az úszás a “kedvenc” sportja. Alternatívaként, ha valamelyik triatlonista azt állította, hogy a “kerékpározás” vagy a “futás” a “kedvenc” sportja, akkor az úszás dummy változó oszlop alatti cellába (
) “1-et” írunk be arra a triatlonistára, aki azt állította, hogy az úszás a “kedvenc” sportja. Alternatívaként, ha valamelyik triatlonista azt állította, hogy a “kerékpározás” vagy a “futás” a “kedvenc” sportja, akkor az úszás dummy változó oszlop alatti cellába (![]() ) “0”-t írunk annak a triatlonistának, aki azt állította, hogy az úszás “nem” a kedvenc sportja (azaz ez azt jelenti, hogy vagy a “kerékpározás” vagy a “futás” a triatlonista kedvenc sportja). Ezt az alábbiakban mind a 10 triatlonista esetében kiemeljük:
) “0”-t írunk annak a triatlonistának, aki azt állította, hogy az úszás “nem” a kedvenc sportja (azaz ez azt jelenti, hogy vagy a “kerékpározás” vagy a “futás” a triatlonista kedvenc sportja). Ezt az alábbiakban mind a 10 triatlonista esetében kiemeljük:
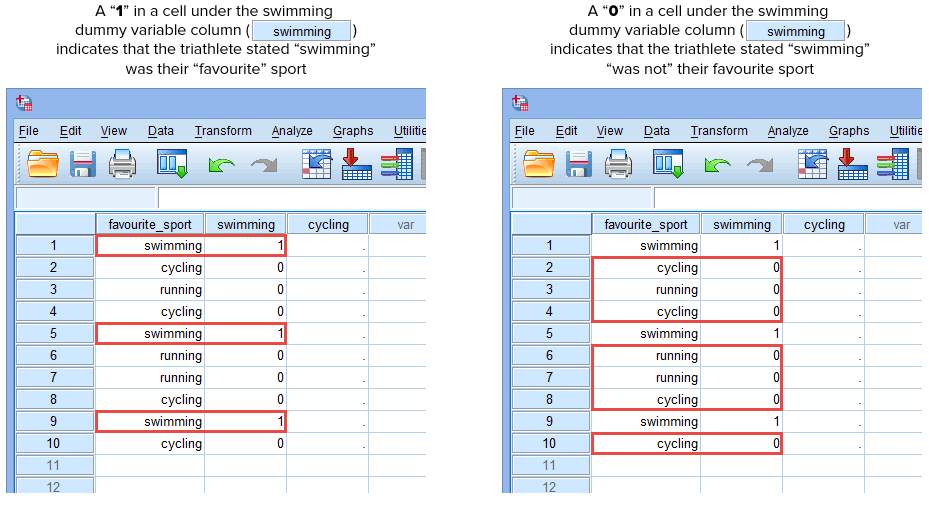
Ez az SPSS Statistics, IBM Corporation írásos engedélyével jelent meg.
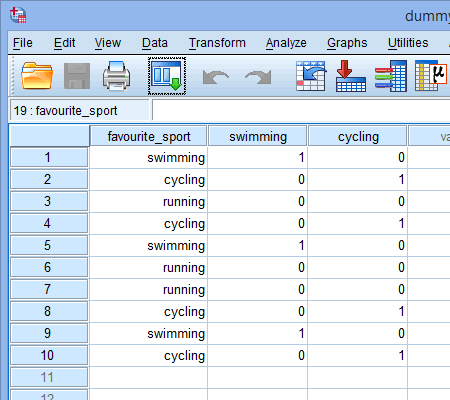
Ezt a folyamatot megismételjük a másik dummy változó, a “kerékpározás” esetében, az alábbiak szerint:
Ez az SPSS Statistics, IBM Corporation írásos engedélyével jelent meg.
Ha valamelyik triatlonista azt állította, hogy a “kerékpározás” a “kedvenc” sportja, akkor a kerékpározás dummy változó oszlop alatti cellába (![]() ) “1-et” írunk be arra a triatlonistára, aki azt állította, hogy a kerékpározás a “kedvenc” sportja. Alternatívaként, ha valamelyik triatlonista azt állította, hogy az “úszás” vagy a “futás” a “kedvenc” sportja, akkor a kerékpározás dummy változó oszlop alatti cellába (
) “1-et” írunk be arra a triatlonistára, aki azt állította, hogy a kerékpározás a “kedvenc” sportja. Alternatívaként, ha valamelyik triatlonista azt állította, hogy az “úszás” vagy a “futás” a “kedvenc” sportja, akkor a kerékpározás dummy változó oszlop alatti cellába (![]() ) “0”-t írunk annak a triatlonistának, aki azt állította, hogy a kerékpározás “nem” a kedvenc sportja (azaz ez azt jelenti, hogy az “úszás” vagy a “futás” a triatlonista kedvenc sportja). Ezt az alábbiakban mind a 10 triatlonista esetében kiemeljük:
) “0”-t írunk annak a triatlonistának, aki azt állította, hogy a kerékpározás “nem” a kedvenc sportja (azaz ez azt jelenti, hogy az “úszás” vagy a “futás” a triatlonista kedvenc sportja). Ezt az alábbiakban mind a 10 triatlonista esetében kiemeljük:
Ez az SPSS Statistics, IBM Corporation írásos engedélyével jelent meg.
Azzal, hogy ilyen módon “1”-eket és “0”-kat ír be a dummy-változókba, létrehozta a dummy-változók egy csoportját, amelyet beírhat a többszörös regressziós elemzésbe. A következő Eljárások részben megmutatjuk, hogyan hozhatja létre ezeket a dummy változókat a Create Dummy Variables eljárás segítségével.
SPSS Statistics
Procedure in SPSS Statistics to create dummy variables
Az SPSS Statistics-ban két eljárás létezik a dummy változók létrehozására: a Create Dummy Variables eljárás és a Recode into Different Variables eljárás. Ebben az útmutatóban a Dummy-változók létrehozása eljárást mutatjuk be, amely egy egyszerű, 3 lépésből álló eljárás. Ez az eljárás azonban csak akkor érhető el, ha az SPSS Statistics 22-es vagy újabb verziójával rendelkezik, a 26-os verzió (és az SPSS Statistics előfizetéses verziója) az SPSS Statistics legújabb verziója. Ha nem biztos abban, hogy az SPSS Statistics melyik verzióját használja, tekintse meg útmutatónkat: Az SPSS Statistics verziójának azonosítása. Ha az SPSS Statistics 21-es vagy korábbi verziójával rendelkezik, vagy többszörös összehasonlításokat szeretne végezni a többszörös regresszióelemzés elvégzése során, kérjük, olvassa el az alábbi megjegyzést:
Megjegyzés: Ha az SPSS Statistics 21-es vagy korábbi verziójával rendelkezik, nem tudja használni a Dummy-változók létrehozása eljárást. Ezért a Recode into Different Variables eljárás legalább lehetővé teszi a dummy változók létrehozását az SPSS Statisticsban. Bár a Recode into Different Variables eljárást is használhatja a dummy változók létrehozására, ha az SPSS Statistics 22-es vagy újabb verziójával rendelkezik, ebben az útmutatóban a Create Dummy Variables eljárást mutatjuk be, mivel ez az eljárás kifejezetten a dummy változók létrehozására szolgál, és sokkal egyszerűbb és gyorsabb a használata. Például az ebben az útmutatóban használt példa esetében mindössze 3 lépést igényel a dummy változók létrehozásához, szemben az ugyanezen példa esetében a Recode into Different Variables eljárással végzett 28 lépéssel.
Ezért, ha az SPSS Statistics 21-es vagy korábbi verziójával rendelkezik, a dummy változók létrehozása című bővített útmutatónkban a Laerd Statistics tagok részben található egy olyan oldal, amely bemutatja, hogyan kell ezt a 28 lépéses Recode into Different Variables eljárást végrehajtani. Ezt a továbbfejlesztett útmutatót a Laerd Statistics előfizetésével érheti el. Alternatív megoldásként egyszerűen használhatja az alábbi Dummy-változók létrehozása eljárást.
A dummy-változók létrehozásához, ha az SPSS Statistics 22-es vagy újabb verziójával rendelkezik, kövesse az alábbi 3 lépésből álló Dummy-változók létrehozása eljárást:
- Kattintson a főmenüben a Transform > Create Dummy Variables menüpontra az alábbiakban látható módon:

Az SPSS Statistics, IBM Corporation írásos engedélyével jelent meg.
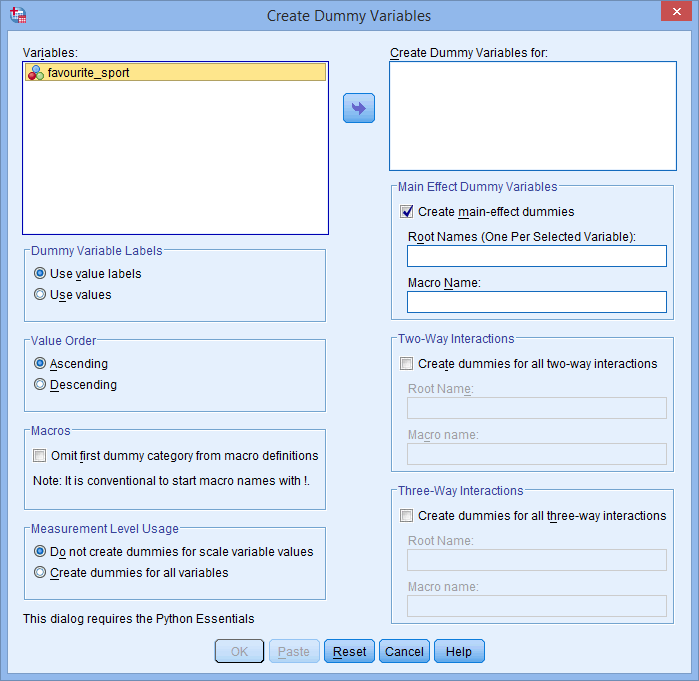
Az alábbiakban látható módon megjelenik a Create Dummy Variables párbeszédpanel:
Published with written permission from SPSS Statistics, IBM Corporation.
- A kategorikus független változót, a favourite_sportot, a Create Dummy Variables for: mezőbe helyezze át, kiválasztva (rákattintva), majd a
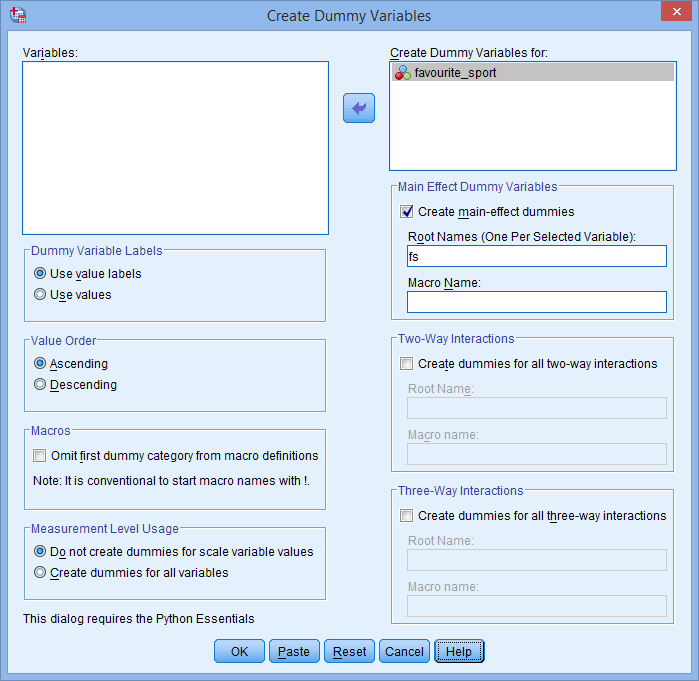
 gombra kattintva. Adjon meg továbbá egy “gyökér” nevet, amely az összes új dummy változót képviselheti a Root Names (One Per Selected Variable): mezőbe a -Main Effect Dummy Variables- területen. Mi az “fs” gyökérnevet adtuk meg a kategorikus független változónk, a “kedvenc_sport” rövidítéseként, az alábbiak szerint:
gombra kattintva. Adjon meg továbbá egy “gyökér” nevet, amely az összes új dummy változót képviselheti a Root Names (One Per Selected Variable): mezőbe a -Main Effect Dummy Variables- területen. Mi az “fs” gyökérnevet adtuk meg a kategorikus független változónk, a “kedvenc_sport” rövidítéseként, az alábbiak szerint:
Published with written permission from SPSS Statistics, IBM Corporation.
Megjegyzés: Az SPSS Statistics egy sorszámot (pl. 1, 2, 3, 4, stb.) ad a kategorikus független változó jelölésére választott gyökérnév végére. Minden egyes létrehozni kívánt dummy változóhoz egy sorszámot hoz létre (pl. ha két dummy változója van, a gyökérnév végére egy 1 és 2 kerül, de ha hat dummy változója van, a gyökérnév végére egy 1, 2, 3, 4, 5 és 6 kerül). Ez a mi példánk esetében az alábbi Variable View ablakban látható:
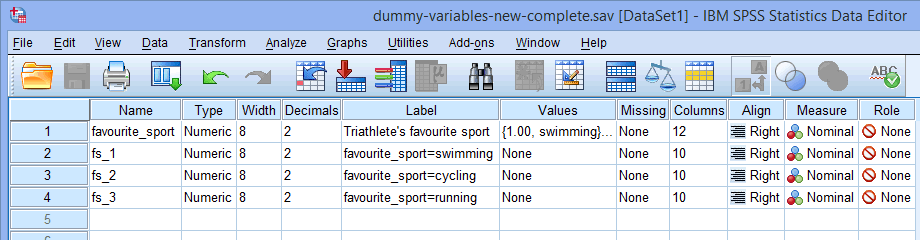
Mivel kategorikus független változónknak, a favourite_sportnak három kategóriája volt (azaz úszás, kerékpározás és futás), a Create Dummy Variables eljárás három dummy változót hoz létre (azaz egyet az úszásra, egyet a kerékpározásra és egyet a futásra). Ez a három dummy változó a fenti oszlopban van kiemelve: “fs_1” (úszás), “fs_2” (kerékpározás) és “fs_3” (futás). Ezeket később átnevezheti, hogy több értelme legyen. Ezt csak azért emeljük ki, hogy tudja, hogyan működik a fenti Root Names (One Per Selected Variable): mező.
oszlopban van kiemelve: “fs_1” (úszás), “fs_2” (kerékpározás) és “fs_3” (futás). Ezeket később átnevezheti, hogy több értelme legyen. Ezt csak azért emeljük ki, hogy tudja, hogyan működik a fenti Root Names (One Per Selected Variable): mező.
Ezeken kívül a Root Names (One Per Selected Variable): mezőbe beírt gyökérnév nem lehet azonos a kategorikus független változó nevével, ahogy az alább látható (pl, ahol a “kedvenc_sport” gyökérnevet adtuk meg, annak illusztrálására, hogy mit nem nevezhetünk gyökérnévnek):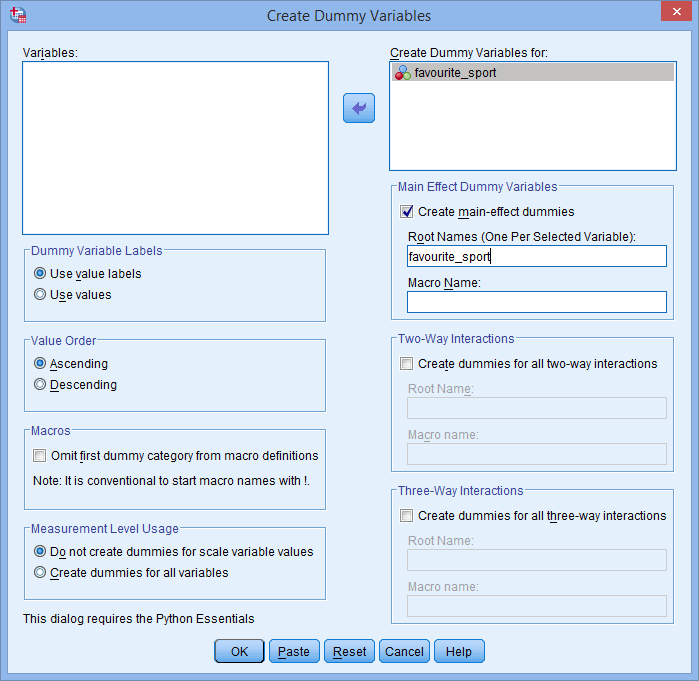
Ha az Ön által megadott gyökérnév megegyezik a kategorikus független változó nevével, a fentiek szerint, amikor a gombra kattint, a következő figyelmeztetést kapja:
gombra kattint, a következő figyelmeztetést kapja:
- Kattintson a gombra.
A fenti 3 lépéses Dummy-változó létrehozása eljárás elvégzése után létrehozta a kategorikus független változóhoz tartozó dummy-változókat. A következő szakaszban emelje ki azt a kimenetet, amely az SPSS Statistics változó nézetében és adatnézetében jön létre ennek a Create Dummy Variables eljárásnak a lefuttatása után.
SPSS Statistics
Kimenet és adatbeállítás az SPSS Statistics-ban a dummy változók létrehozása után
A dummy változók létrehozása után az SPSS Statistics a következő Variable Creation táblázatot állítja elő az IBM SPSS Statistics Viewerében:
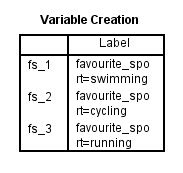
Published with written permission from SPSS Statistics, IBM Corporation.
A változó létrehozása táblázat megerősíti, hogy sikeresen létrehozta a dummy változókat. Annyi sornak kell lennie, ahány új dummy változó van. Mivel három dummy változót hoztunk létre, a táblázatban három sor van: “fs_1”, “fs_2” és “fs_3”, amelyek az előző szakaszban a Dummy változók létrehozása eljárás 2. lépésében megadott gyökérnevet és sorszámozást tükrözik. Mindegyik dummy változóhoz egy címke tartozik a táblázatban, amely egyértelművé teszi, hogy az egyes dummy változók a kategorikus független változó melyik kategóriáját képviselik. Például az “fs_1” esetében a “favourite_sport=úszás” címke szerepel, ami azt jelzi, hogy az “fs_1” a kategorikus független változó, a favourite_sport “úszás” kategóriájának dummy változója.
Ezután a ![]() fülre kattintva lépjen az SPSS Statistics Variable View ablakába. A három dummy változót az alábbiak szerint adtuk hozzá (azaz a
fülre kattintva lépjen az SPSS Statistics Variable View ablakába. A három dummy változót az alábbiak szerint adtuk hozzá (azaz a ![]() oszlopban a “fs_1”, “fs_2” és “fs_3” dummy változókat):
oszlopban a “fs_1”, “fs_2” és “fs_3” dummy változókat):
Published with written permission from SPSS Statistics, IBM Corporation.
Megjegyzés: A ![]() oszlopban a dummy változók nevét megváltoztathatja, hogy egyértelműbb legyen, miről van szó. Például az “fs_1”-t “úszás”-ra, az “fs_2”-t “kerékpározás”-ra és az “fs_3”-t “futás”-ra változtattuk az alábbiak szerint:
oszlopban a dummy változók nevét megváltoztathatja, hogy egyértelműbb legyen, miről van szó. Például az “fs_1”-t “úszás”-ra, az “fs_2”-t “kerékpározás”-ra és az “fs_3”-t “futás”-ra változtattuk az alábbiak szerint:
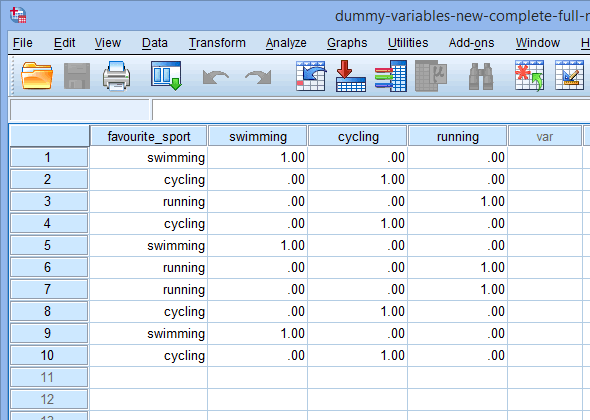
Végül az ![]() fülre kattintva lépjen az SPSS Statistics adatnézet ablakába. Az egyes létrehozott dummy változók alatt megjelenik a dummy kódolás. Például az “fs_1” oszlop alatti sorokban az “úszás” kategória “1,00”-ként van kódolva, míg a “kerékpározás” és a “futás” kategóriák “,00”-ként vannak kódolva, ahogy az alábbiakban látható. Ha nem biztos benne, hogy ezek a dummy változók miért vannak ilyen módon dummy kódolva, lásd a szakaszt:
fülre kattintva lépjen az SPSS Statistics adatnézet ablakába. Az egyes létrehozott dummy változók alatt megjelenik a dummy kódolás. Például az “fs_1” oszlop alatti sorokban az “úszás” kategória “1,00”-ként van kódolva, míg a “kerékpározás” és a “futás” kategóriák “,00”-ként vannak kódolva, ahogy az alábbiakban látható. Ha nem biztos benne, hogy ezek a dummy változók miért vannak ilyen módon dummy kódolva, lásd a szakaszt:
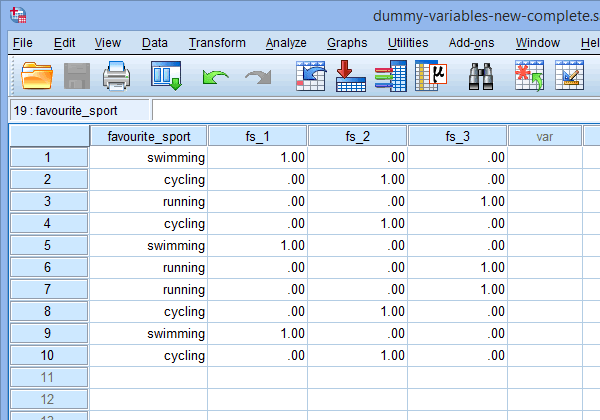
Published with written permission from SPSS Statistics, IBM Corporation.
Megjegyzés 1: Az SPSS Statistics alapértelmezett beállításai miatt az Ön dummy változói “1” vagy “0” helyett “1.00” vagy “.00” kódolásúak lesznek. Ezek megegyeznek. Azonban gyakran látni fogja, hogy a dummy-változók kódolása 1-es és 0-s értékekkel van leírva ahelyett, hogy tizedesjegyeket tartalmazna.
2. megjegyzés: Ha a fenti Variable View ablak ![]() oszlopában megváltoztatta a dummy-változók nevét, akkor ezek az adatnézet ablak oszlopaiban is megváltoznak, ahogy az alábbiakban látható (pl. a
oszlopában megváltoztatta a dummy-változók nevét, akkor ezek az adatnézet ablak oszlopaiban is megváltoznak, ahogy az alábbiakban látható (pl. a ![]() oszlopcím most
oszlopcím most ![]() ):
):
.