Overview
- Learn to interpret Bias and Variance in a given model.
- Mi a különbség a torzítás és a variancia között?
- Hogyan érhetjük el a torzítás és a variancia kompromisszumát a gépi tanulás munkafolyamatával
Bevezetés
Beszéljünk az időjárásról. Csak akkor esik az eső, ha kicsit párás, és nem esik, ha szeles, meleg vagy fagyos az idő. Ebben az esetben hogyan képeznénk ki egy előrejelző modellt, és hogyan biztosítanánk, hogy ne legyen hiba az időjárás előrejelzésében? Mondhatod, hogy sok tanulási algoritmus közül lehet választani. Sok tekintetben különböznek egymástól, de nagy különbség van abban, hogy mit várunk és mit jósol a modell. Ez a Bias and Variance Tradeoff fogalma.
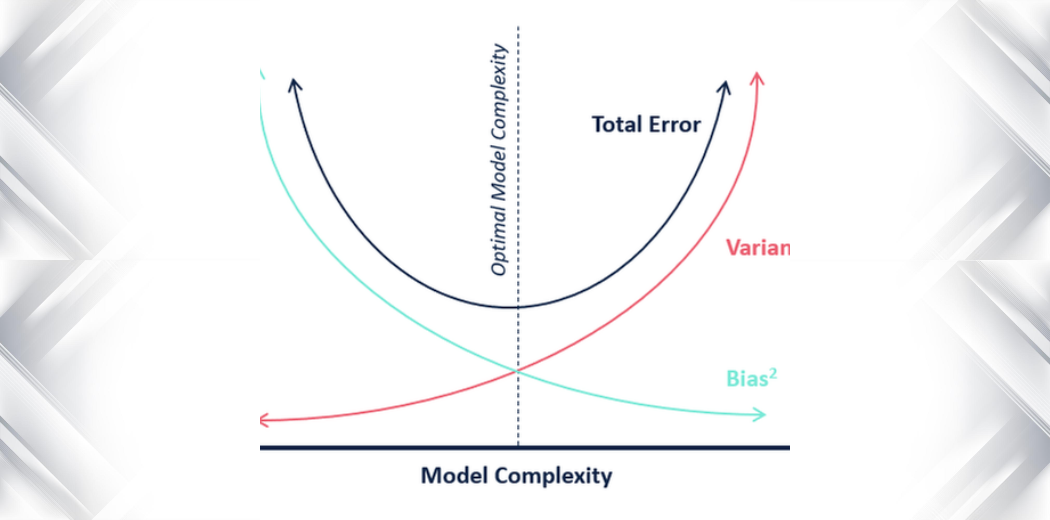
A Bias and Variance Tradeoffot általában sűrű matematikai képleteken keresztül tanítják. Ebben a cikkben azonban megpróbáltam a lehető legegyszerűbben elmagyarázni a Bias and Variance-t!
Az lesz a célom, hogy végigpörgessem Önt a problémafelvetés megértésének folyamatán, és biztosítsam, hogy a legjobb modellt válassza, ahol a Bias and Variance hibák minimálisak.
Ezért a népszerű Pima Indians Diabetes adatkészletet vettem elő. Az adatkészlet a Pima indián őslakos indián örökséghez tartozó felnőtt női betegek diagnosztikai méréseiből áll. Ennél az adatkészletnél az “Outcome” változóra fogunk összpontosítani – amely azt jelzi, hogy a betegnek van-e cukorbetegsége vagy sem. Nyilvánvaló, hogy ez egy bináris osztályozási probléma, és mi most rögtön belevetjük magunkat, és megtanuljuk, hogyan kell hozzáfogni.
Ha érdekli ez és az adattudományi fogalmak, és szeretne gyakorlatban tanulni, nézze meg a tanfolyamunkat – Bevezetés az adattudományba
Tartalomjegyzék
- Egy gépi tanulási modell értékelése
- Problémafelvetés és elsődleges lépések
- Mi az elfogultság?
- Mi a variancia?
- Bias-Variance Tradeoff
A gépi tanulási modell értékelése
A gépi tanulási modell elsődleges célja, hogy az adott adatokból tanuljon, és a tanulási folyamat során megfigyelt mintázat alapján jóslatokat készítsen. Feladatunk azonban ezzel nem ér véget. Folyamatosan javítanunk kell a modelleket, annak alapján, hogy milyen eredményeket produkálnak. A modell teljesítményét olyan mérőszámok segítségével is számszerűsítjük, mint a pontosság, a hiba négyzetének átlaga (MSE), az F1-pontszám stb. és megpróbáljuk ezeket a mérőszámokat javítani. Ez gyakran nehézségekbe ütközhet, amikor meg kell őriznünk a modell rugalmasságát anélkül, hogy kompromisszumot kötnénk a modell helyességével kapcsolatban.
A felügyelt gépi tanulási modell célja, hogy úgy képezze magát a bemeneti változókra(X), hogy a megjósolt értékek(Y) a lehető legközelebb legyenek a tényleges értékekhez. A tényleges értékek és az előre jelzett értékek közötti különbség a hiba, és ez szolgál a modell értékelésére. Bármely felügyelt gépi tanulási algoritmus hibája 3 részből áll:
- Bias error
- Variance error
- A zaj
Míg a zaj az irreducibilis hiba, amit nem tudunk kiküszöbölni, a másik kettő i.azaz a torzítás és a variancia redukálható hibák, amelyeket megpróbálhatunk a lehető legjobban minimalizálni.
A következő szakaszokban a torzítás hibájával, a variancia hibájával és a torzítás-variáció kompromisszummal foglalkozunk, amelyek segítenek nekünk a legjobb modell kiválasztásában. És ami izgalmas, hogy egy példaadatkészlet segítségével foglalkozunk majd néhány technikával e hibák kezelésére.
Problémafelvetés és elsődleges lépések
Amint korábban kifejtettük, felvettük a Pima indiánok diabétesz adathalmazát, és egy osztályozási problémát alakítottunk ki rajta. Kezdjük az adathalmaz felmérésével, és figyeljük meg, hogy milyen adatokkal van dolgunk. Ezt a szükséges könyvtárak importálásával fogjuk megtenni:
Most töltsük be az adatokat egy adatkeretbe, és figyeljünk meg néhány sort, hogy betekintést nyerjünk az adatokba.
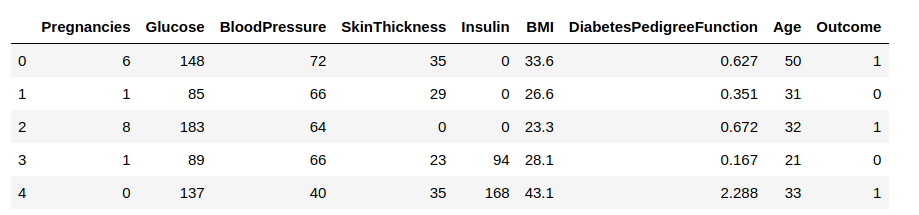
Meg kell jósolnunk az ‘Outcome’ oszlopot. Válasszuk szét, és rendeljük hozzá egy ‘y’ célváltozóhoz. Az adatkeret többi része az X bemeneti változók halmaza lesz.
Most skálázzuk ki az előrejelző változókat, majd válasszuk szét a képzési és a tesztelési adatokat.
Mivel az eredményeket bináris formában osztályozzuk, a legegyszerűbb K-közelibb szomszéd osztályozót(Knn) fogjuk használni annak osztályozására, hogy a beteg cukorbeteg-e vagy sem.
Hogyan döntsük el azonban a ‘k’ értékét?
- Meglehet, hogy k = 1-t kellene használnunk, hogy nagyon jó eredményeket kapjunk a képzési adatainkon? Ez működhet, de nem tudjuk garantálni, hogy a modell ugyanolyan jól fog teljesíteni a tesztelési adatainkon, mivel túlságosan specifikus lehet
- Hogyan lenne, ha egy nagy k értéket használnánk, mondjuk k = 100-at, hogy a legközelebbi pontok nagy számát figyelembe tudjuk venni, hogy a távoli pontokat is figyelembe vegyük? Ez a fajta modell azonban túl általános lesz, és nem lehetünk biztosak abban, hogy az összes lehetséges hozzájáruló jellemzőt helyesen vette figyelembe.
Vegyünk néhány lehetséges k értéket, és illesszük a modellt a képzési adatokra az összes ilyen értékre. Kiszámítjuk a képzési pontszámot és a tesztelési pontszámot is mindezen értékekre.
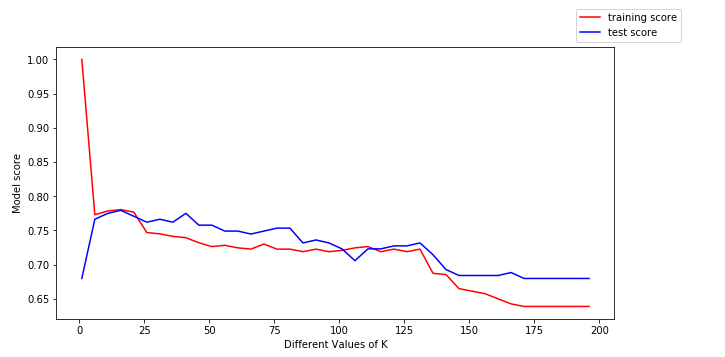
Azért, hogy további betekintést nyerjünk ebből, ábrázoljuk a képzési adatokat(piros színnel) és a tesztelési adatokat(kék színnel).
Hogy kiszámítsuk a pontszámokat egy adott k értékre,
![]()
A fenti ábrából a következő következtetéseket vonhatjuk le:
- A k alacsony értékei esetén a képzési pontszám magas, míg a tesztelési pontszám alacsony
- Amint a k értéke nő, a tesztelési pontszám nőni, a képzési pontszám pedig csökkenni kezd.
- Egy bizonyos k értéknél azonban mind a képzési pontszám, mind a tesztelési pontszám közel van egymáshoz.
Ez az a pont, ahol a torzítás és a szórás a képbe kerül.
Mi a torzítás?
A legegyszerűbben fogalmazva, a torzítás a különbség a jósolt érték és a várható érték között. További magyarázatként elmondható, hogy a modell bizonyos feltételezéseket tesz, amikor a megadott adatokon edz. Amikor bevezetjük a tesztelési/validálási adatokhoz, ezek a feltételezések nem mindig helytállóak.
A mi modellünkben, ha nagyszámú legközelebbi szomszédot használunk, a modell teljesen eldöntheti, hogy egyes paraméterek egyáltalán nem fontosak. Például csak azt veheti úgy, hogy a Glusoce-szint és a Vérnyomás dönti el, hogy a betegnek cukorbetegsége van-e. Ez a modell nagyon erős feltételezéseket tenne arról, hogy a többi paraméter nem befolyásolja az eredményt. Úgy is elképzelhetjük, hogy a modell egy egyszerű összefüggést jósol, amikor az adatpontok egyértelműen összetettebb összefüggésre utalnak:
Matematikailag legyen a bemeneti változó X és egy célváltozó Y. A kettő közötti összefüggést egy f függvény segítségével képezzük le.
Ezért,
Y = f(X) + e
Itt “e” a hiba, amely normális eloszlású. Az f'(x) modellünk célja, hogy az f(x)-hez minél közelebbi értékeket jósoljon. Itt a modell torzítása:
Bias = E
Amint fentebb kifejtettem, amikor a modell általánosításokat végez, azaz amikor nagy a torzítási hiba, akkor egy nagyon leegyszerűsített modellt eredményez, amely nem veszi jól figyelembe a változásokat. Mivel nem tanulja meg jól a képzési adatokat, ezt nevezzük alulilleszkedésnek.
Mi az a variancia?
A torzítással ellentétben a variancia az, amikor a modell figyelembe veszi az adatokban lévő ingadozásokat, azaz a zajt is. Mi történik tehát, ha a modellünknek nagy a varianciája?
A modell továbbra is úgy tekinti a varianciát, mint olyasvalamit, amiből tanulhat. Vagyis a modell túl sokat tanul a képzési adatokból, olyannyira, hogy amikor új (tesztelési) adatokkal szembesül, nem képes azok alapján pontosan jósolni.
Matematikailag a modell varianciahibája:
Variancia-E^2
Mivel magas variancia esetén a modell túl sokat tanul a képzési adatokból, ezt nevezzük túlillesztésnek.
A mi adatainkkal összefüggésben, ha nagyon kevés legközelebbi szomszédot használunk, ez olyan, mintha azt mondanánk, hogy ha a terhességek száma több mint 3, a glükózszint több mint 78, a diasztolés vérnyomás kevesebb mint 98, a bőrvastagság kevesebb mint 23 mm és így tovább minden egyes jellemzőre….. úgy dönt, hogy a beteg cukorbeteg. Az összes többi beteg, aki nem felel meg a fenti kritériumoknak, nem cukorbeteg. Bár ez igaz lehet a képzési halmaz egy adott betegére, mi van akkor, ha ezek a paraméterek a kiugró értékek, vagy akár helytelenül lettek rögzítve? Nyilvánvaló, hogy egy ilyen modell nagyon költségesnek bizonyulhat!
Ez a modell ráadásul nagy szóráshibával rendelkezne, mivel az arra vonatkozó előrejelzések, hogy a beteg cukorbeteg vagy nem cukorbeteg, nagymértékben eltérnek attól, hogy milyen képzési adatokat szolgáltatunk neki. Így még a Glükózszint 75-re történő módosítása is azt eredményezné, hogy a modell azt jósolná, hogy a beteg nem cukorbeteg.
Egyszerűsítve, a modell nagyon összetett összefüggéseket jósol a kimenetel és a bemeneti jellemzők között, amikor egy kvadratikus egyenlet is elegendő lett volna. Így nézne ki egy osztályozási modell, ha nagy szóráshiba van/ha túlillesztés van:
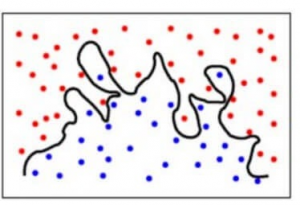
Összefoglalva,
- A magas torzítási hibával rendelkező modell alulilleszkedik az adatokhoz és nagyon leegyszerűsítő feltételezéseket tesz róluk
- A magas szóráshibával rendelkező modell túlilleszkedik az adatokhoz és túl sokat tanul belőlük
- A jó modell az, ahol mind a torzítási, mind a szóráshiba kiegyensúlyozott
Bias-Variance Tradeoff
Hogyan kapcsoljuk a fenti fogalmakat a korábbi Knn modellünkhöz? Derítsük ki!
Modellünkben, mondjuk, k = 1 esetén, a kérdéses adatponthoz legközelebbi pontot vesszük figyelembe. Itt az előrejelzés pontos lehet erre az adott adatpontra, így a torzítási hiba kisebb lesz.
A szóráshiba azonban nagy lesz, mivel csak az egy legközelebbi pontot vesszük figyelembe, és ez nem veszi figyelembe a többi lehetséges pontot. Ön szerint ez milyen forgatókönyvnek felel meg? Igen, jól gondolja, ez azt jelenti, hogy a modellünk túlilleszkedik.
Másrészt a k nagyobb értékei esetén sokkal több, a kérdéses adatponthoz közelebbi pontot veszünk figyelembe. Ez nagyobb torzítási hibát és alulilleszkedést eredményezne, mivel sok, az adatponthoz közelebbi pontot vesz figyelembe, és így nem tudja megtanulni a sajátosságokat a képzési halmazból. A tesztkészlet esetében azonban alacsonyabb varianciahibát tudunk figyelembe venni, amely ismeretlen értékeket tartalmaz.
Az előfeszítési hiba és a varianciahiba közötti egyensúly eléréséhez olyan k értékre van szükségünk, hogy a modell ne tanuljon a zajból (overfit az adatokon), és ne tegyen elsöprő feltételezéseket az adatokról (underfit az adatokon). Az egyszerűség kedvéért egy kiegyensúlyozott modell így nézne ki:
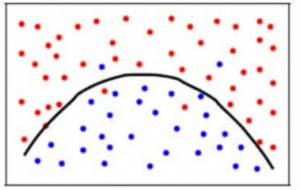
Noha néhány pontot helytelenül osztályozunk, a modell általában pontosan illeszkedik az adatpontok többségéhez. A torzítási hiba és a szóráshiba közötti egyensúly a torzítás-változás tradeoff.
A következő bull-szem diagram jobban kifejezi a tradeoffot:
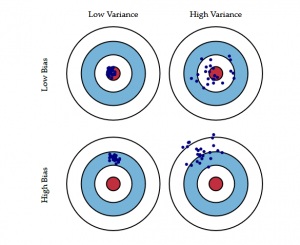
A középpont, azaz a bull-szem az a modelleredmény, amelyet el akarunk érni, és amely tökéletesen helyesen jósolja meg az összes értéket. Ahogy távolodunk a telitalponttól, a modellünk egyre több hibás előrejelzést kezd adni.
Az alacsony torzítású és nagy szórású modell olyan pontokat jósol, amelyek általában a középpont körül vannak, de egymástól elég messze. Egy magas torzítású és alacsony varianciájú modell elég messze van a telitalpon, de mivel a variancia alacsony, az előrejelzett pontok közelebb vannak egymáshoz.
A modell bonyolultságát tekintve a következő diagram segítségével dönthetünk a modellünk optimális bonyolultságáról.
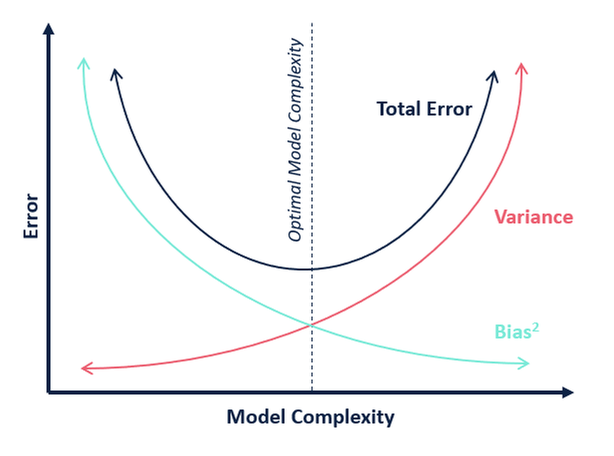
Szerinted mi a k optimális értéke?
A fenti magyarázatból arra következtethetünk, hogy az a k, amelynél
- a tesztelési pontszám a legmagasabb, és
- mind a tesztelési, mind a képzési pontszám közel van egymáshoz
az a k optimális értéke. Tehát hiába kötünk kompromisszumot egy alacsonyabb képzési pontszámmal, mégis magas pontszámot kapunk a tesztelési adatokra, ami sokkal fontosabb – a tesztelési adatok végül is ismeretlen adatok.
Készítsünk egy táblázatot a k különböző értékeire, hogy ezt tovább bizonyítsuk:
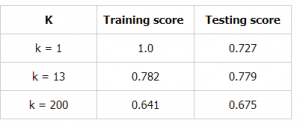
Következtetés
Ezzel a cikkel összefoglalva megtudtuk, hogy az ideális modell az lenne, ahol mind a torzítási hiba, mind a szóráshiba alacsony. Ugyanakkor mindig olyan modellre kell törekednünk, ahol a képzési adatokra kapott modellpontszám a lehető legközelebb van a tesztelési adatokra kapott modellpontszámhoz.
Ezzel kitaláltuk, hogyan válasszunk olyan modellt, amely nem túl bonyolult (magas variancia és alacsony torzítás), ami túlillesztéshez vezetne, és nem túl egyszerű (magas torzítás és alacsony variancia), ami alulillesztéshez vezetne.
A torzítás és a variancia fontos szerepet játszik annak eldöntésében, hogy melyik előrejelző modellt használjuk. Remélem, ez a cikk jól elmagyarázta a fogalmat.