A nyugalmi adatok titkosítása minden modern internetes vállalat számára elengedhetetlen. Sok vállalat azonban nem titkosítja a lemezeit, mert félnek a titkosítási többletköltségek okozta potenciális teljesítménycsökkenéstől.
A nyugalmi adatok titkosítása létfontosságú a Cloudflare számára, amelynek világszerte több mint 200 adatközpontja van. Ebben a bejegyzésben megvizsgáljuk a lemezek titkosításának teljesítményét Linuxon, és elmagyarázzuk, hogyan tettük azt legalább kétszer gyorsabbá magunk és ügyfeleink számára!
A nyugalmi adatok titkosítása
A nyugalmi adatok titkosítása többféleképpen is megvalósítható egy modern operációs rendszeren (OS). A rendelkezésre álló technikák szorosan kapcsolódnak egy tipikus operációs rendszer tárolási vereméhez. A tárolási verem és a titkosítási megoldások egyszerűsített változata az alábbi ábrán látható:
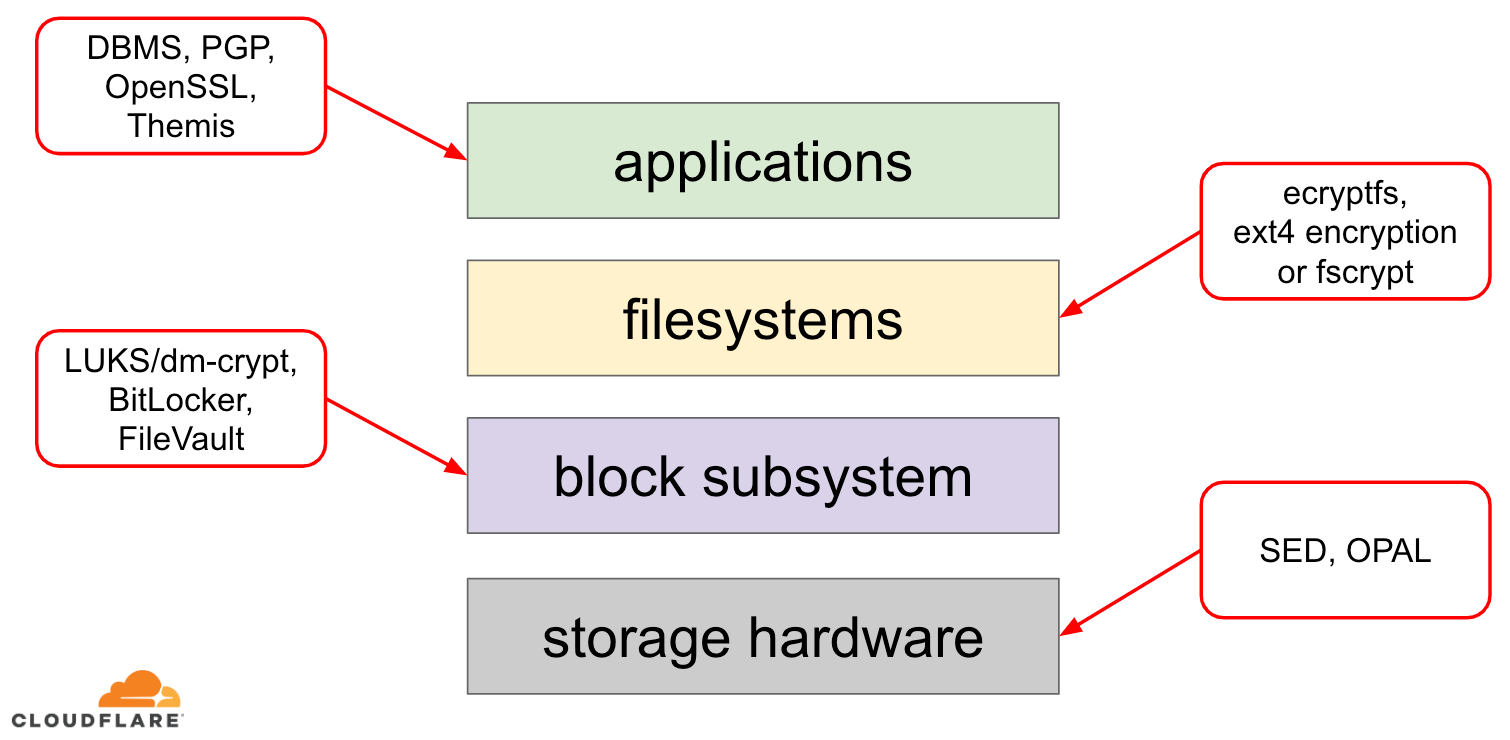
A verem tetején helyezkednek el az alkalmazások, amelyek fájlokban (vagy streamekben) olvasnak és írnak adatokat. Az operációs rendszer kernelében lévő fájlrendszer nyomon követi, hogy a mögöttes blokkeszköz mely blokkjai melyik fájlhoz tartoznak, és ezeket a fájlolvasásokat és -írásokat blokkolvasásokra és -írásokra fordítja, azonban a mögöttes tárolóeszköz hardveres sajátosságai elvonatkoztatva vannak a fájlrendszertől. Végül a blokk alrendszer a megfelelő eszközmeghajtók segítségével ténylegesen továbbítja a blokkolvasásokat és -írásokat a mögöttes hardverhez.
A tárolási verem koncepciója valójában hasonlít a jól ismert hálózati OSI-modellhez, ahol az egyes rétegek magasabban látják az információkat, és az alsóbb rétegek végrehajtási részletei el vannak vonva a felsőbb rétegektől. És az OSI-modellhez hasonlóan a titkosítást különböző rétegeken is alkalmazhatjuk (gondoljunk csak a TLS vs. IPsec vagy egy VPN-re).
A nyugvó adatok esetében a titkosítást vagy a blokkszinteken (hardverben vagy szoftverben) vagy a fájlszinteken (közvetlenül az alkalmazásokban vagy a fájlrendszerben) alkalmazhatjuk.
Blokk- vs. fájltitkosítás
Általában minél magasabb szinten alkalmazzuk a titkosítást a veremben, annál nagyobb a rugalmasságunk. Az alkalmazásszintű titkosítással az alkalmazás karbantartói bármilyen titkosítási kódot alkalmazhatnak tetszőleges adatokra, amire szükségük van. Ennek a megközelítésnek az a hátránya, hogy valójában nekik maguknak kell megvalósítaniuk, és a titkosítás általában nem túl fejlesztőbarát: ismerni kell egy adott kriptográfiai algoritmus minden csínját-bínját, megfelelően kell generálni a kulcsokat, nonce-eket, IV-eket stb. Ráadásul az alkalmazásszintű titkosítás nem használja ki az operációs rendszer szintű gyorsítótárat és különösen a Linux oldal gyorsítótárát: minden alkalommal, amikor az alkalmazásnak szüksége van az adatok használatára, vagy újra kell dekódolnia azokat, ami CPU-ciklusokat pazarol, vagy saját dekódolt “gyorsítótárat” kell létrehoznia, ami még bonyolultabbá teszi a kódot.
A fájlrendszer szintű titkosítás átláthatóvá teszi az adatok titkosítását az alkalmazások számára, mivel a fájlrendszer maga titkosítja az adatokat, mielőtt továbbítja azokat a blokk alrendszerhez, így a fájlok titkosítva vannak, függetlenül attól, hogy az alkalmazás rendelkezik-e titkosítási támogatással vagy sem. Emellett a fájlrendszerek úgy is konfigurálhatók, hogy csak egy adott könyvtárat titkosítanak, vagy különböző kulcsokat használnak a különböző fájlokhoz. Ez a rugalmasság azonban a bonyolultabb konfiguráció árán érhető el. A fájlrendszerek titkosítása kevésbé biztonságosnak tekinthető, mint a blokkeszközök titkosítása, mivel csak a fájlok tartalma van titkosítva. A fájlokhoz kapcsolódó metaadatok is tartoznak, mint például a fájlméret, a fájlok száma, a könyvtárfa elrendezése stb., amelyek egy potenciális támadó számára továbbra is láthatóak.
A blokkrétegben történő titkosítás (gyakran nevezik lemeztitkosításnak vagy teljes lemeztitkosításnak) az adatok titkosítását az alkalmazások, sőt egész fájlrendszerek számára is átláthatóvá teszi. A fájlrendszer-szintű titkosítással ellentétben a lemezen lévő összes adatot titkosítja, beleértve a fájl metaadatokat és még a szabad helyet is. Ez azonban kevésbé rugalmas – a teljes lemezt csak egyetlen kulccsal lehet titkosítani, így nincs könyvtárankénti, fájlonkénti vagy felhasználónkénti konfiguráció. A kriptográfia szempontjából nem minden kriptográfiai algoritmus használható, mivel a blokkréteg már nem rendelkezik magas szintű áttekintéssel az adatokról, így minden egyes blokkot önállóan kell feldolgoznia. A legtöbb elterjedt algoritmusnak valamilyen blokkláncolásra van szüksége ahhoz, hogy biztonságos legyen, ezért nem alkalmazható lemezes titkosításra. Ehelyett speciális módokat fejlesztettek ki csak erre a speciális felhasználási esetre.
Hát melyik réteget válasszuk? Mint mindig, ez attól függ… Az alkalmazás- és fájlrendszer-szintű titkosítás általában az ügyfélrendszerek esetében a rugalmasság miatt az előnyben részesített választás. Például egy többfelhasználós asztali gépen minden felhasználó titkosíthatja a saját kulcsával a saját könyvtárát, és néhány megosztott könyvtárat nem titkosíthat. Ezzel szemben a SaaS/PaaS/IaaS cégek (köztük a Cloudflare) által kezelt szerverrendszerek esetében a konfiguráció egyszerűsége és biztonsága az előnyben részesített választás – a teljes lemeztitkosítás engedélyezésével bármely alkalmazásból származó bármely adat automatikusan titkosítva lesz, kivételek vagy felülbírálatok nélkül. Úgy gondoljuk, hogy minden adatot védeni kell anélkül, hogy “fontos” vs. “nem fontos” vödrökbe sorolnánk, így nincs szükség a felsőbb rétegek által biztosított szelektív rugalmasságra.
Hardveres vs. szoftveres lemeztitkosítás
Az adatok blokkrétegben történő titkosítása esetén lehetséges, hogy közvetlenül a tároló hardverben végezzük el, ha a hardver támogatja. Ez általában jobb írási/olvasási teljesítményt biztosít, és kevesebb erőforrást igényel az állomáson. Mivel azonban a legtöbb hardveres firmware szabadalmaztatott, ez nem kap annyi figyelmet és felülvizsgálatot a biztonsági közösség részéről. A múltban ez a hardveres lemeztitkosítás egyes megvalósításaiban olyan hibákhoz vezetett, amelyek az egész biztonsági modellt használhatatlanná tették. A Microsoft például azóta a szoftveralapú lemeztitkosítást kezdte előnyben részesíteni.
Nem akartuk kitenni adatainkat és ügyfeleink adatait annak a kockázatnak, hogy potenciálisan nem biztonságos megoldásokat használjunk, és erősen hiszünk a nyílt forráskódú megoldásokban. Ezért támaszkodunk kizárólag a Linux kernelben lévő szoftveres lemeztitkosításra, amely nyílt és a világ számos biztonsági szakembere által auditált.
Linux lemeztitkosítás teljesítménye
A célunk nem csak az, hogy sávszélességi költségeket takarítsunk meg ügyfeleink számára, hanem az is, hogy a lehető leggyorsabban juttassuk el a tartalmat az internetezőkhöz.
Egyszer észrevettük, hogy a lemezeink nem olyan gyorsak, mint amilyennek szerettük volna. Némi profilalkotás, valamint egy gyors A/B teszt a Linux lemez titkosítására utalt. Mivel az adatok titkosításának mellőzése (még akkor is, ha az elvileg nyilvános internetes gyorsítótár) nem fenntartható megoldás, úgy döntöttünk, hogy közelebbről megvizsgáljuk a Linux lemez titkosításának teljesítményét.
Device mapper és dm-crypt
A Linux egy dm-crypt modulon keresztül valósítja meg az átlátható lemez titkosítást, és dm-crypt maga a device mapper kernel keretrendszer része. Dióhéjban az eszközleképező lehetővé teszi az IO-kérelmek előzetes/utólagos feldolgozását, miközben azok a fájlrendszer és a mögöttes blokkeszköz között utaznak.
dm-crypt különösen az “írási” IO-kérelmeket titkosítja, mielőtt továbbküldi őket a veremben lefelé a tényleges blokkeszközhöz, és az “olvasási” IO-kérelmeket dekódolja, mielőtt felküldi őket a fájlrendszer-illesztőprogramhoz. Egyszerű és könnyű! Vagy nem?
Benchmarking setup
Az ebben a bejegyzésben szereplő számokat a megadott parancsok futtatásával kaptuk egy üres Cloudflare G9 szerveren, a termelésen kívül. A beállítás azonban könnyen reprodukálható bármelyik modern x86-os laptopon.
Általában nehéz bármit is benchmarkolni egy tároló stack körül, mert maga a tároló hardver által okozott zaj miatt. Nem minden lemez egyforma, ezért ennek a posztnak a céljaira a leggyorsabb lemezeket fogjuk használni – azaz nem használunk lemezeket.
Ehelyett a Linuxnak van egy olyan lehetősége, hogy közvetlenül a RAM-ban emuláljon egy lemezt. Mivel a RAM sokkal gyorsabb, mint bármilyen tartós tároló, ez kevés torzítást hozhat az eredményeinkbe.
A következő parancs létrehoz egy 4 GB-os ramdisket:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Ezután létrehozhatunk rajta egy dm-crypt példányt, így lehetővé téve a lemez titkosítását. Először is létre kell hoznunk a lemez titkosítási kulcsát, “formáznunk” kell a lemezt, és meg kell adnunk egy jelszót az újonnan generált kulcs feloldásához.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Aki ismeri a LUKS/dm-crypt-t, észrevehette, hogy itt egy LUKS leválasztott fejlécet használtunk. Normális esetben a LUKS a jelszóval titkosított lemez titkosítási kulcsát ugyanazon a lemezen tárolja, mint az adatokat, de mivel mi a titkosított és a titkosítatlan eszközök közötti írási/olvasási teljesítményt akarjuk összehasonlítani, előfordulhat, hogy később véletlenül felülírjuk a titkosított kulcsot a benchmarking során. Ha a titkosított kulcsot külön fájlban tartjuk, akkor ezt a problémát e bejegyzés céljaira elkerüljük.
Most már ténylegesen “feloldhatjuk” a titkosított eszközt a teszteléshez:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0Ezzel a ponttal már össze tudjuk hasonlítani a titkosított és a titkosítatlan ramdisk teljesítményét: ha a /dev/ram0-re írunk/olvasunk adatokat, akkor azok nyílt szövegben lesznek tárolva. Hasonlóképpen, ha /dev/mapper/encrypted-ram0-ra írunk/olvasunk adatot, akkor azt útközben dm-crypt-val dekódoljuk/titkosítjuk, és rejtjelezett szövegben tároljuk.
Megjegyzendő, hogy nem hozunk létre semmilyen fájlrendszert a blokkos eszközeink tetején, hogy elkerüljük az eredmények torzítását a fájlrendszer többletköltségével.
Az átviteli sebesség mérése
A tárolók tesztelése/benchmarkolása esetén a Flexible I/O tester a szokásos megoldás. Szimuláljunk egyszerű szekvenciális olvasási/írási terhelést 4K blokkmérettel a ramdiskre titkosítás nélkül:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%A fenti parancs sokáig fog futni, ezért egy idő után egyszerűen leállítjuk. Ahogy a statisztikákból láthatjuk, nagyjából azonos átviteli sebességgel tudunk olvasni és írni 1126 MB/s körül. Ismételjük meg a tesztet a titkosított ramdiskkel:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecHú, ez aztán a csökkenés! Már csak ~147 MB/s-t kapunk, ami több mint 7-szer lassabb! És ez egy teljesen üres gépen van!
Meglehet, a kripto csak lassú
Az első dolog, amit figyelembe vettünk, hogy biztosítsuk, hogy a leggyorsabb kriptót használjuk. A cryptsetup lehetővé teszi számunkra, hogy összehasonlítsuk a rendszerben elérhető összes kripto implementációt, hogy kiválaszthassuk a legjobbat:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/A Úgy tűnik, hogy itt a aes-xts 256 bites adattitkosítási kulccsal a leggyorsabb. De melyiket használjuk valójában a titkosított ramdiskünkhöz?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Tényleg a aes-xts-t használjuk 256 bites adattitkosítási kulccsal (számoljuk meg a dmsetup eszközzel kényelmesen maszkolt összes nullát – ha látni akarjuk a tényleges bájtokat, adjuk hozzá a --showkeys opciót a fenti parancshoz). A számok azonban nem adódnak össze: A cryptsetup benchmark fentebb azt mondja, hogy ne hagyatkozzunk az eredményekre, mivel “A tesztek közelítőleg csak a memóriát használják (nincs tárolási IO)”, de mi pontosan így állítottuk be a kísérletünket a ramdisk használatával. Egy kissé rosszabb esetben (feltételezve, hogy az összes adatot beolvassuk, majd titkosítjuk/dekódoljuk szekvenciálisan, párhuzamosság nélkül) a borítékon alapuló számításokat végezve (1126 * 1823) / (1126 + 1823) =~696 MB/s körül kellene kapnunk, ami még mindig elég messze van a tényleges 147 * 2 = 294 MB/s-től (az olvasások és írások összege).
dm-crypt performance flags
A cryptsetup man oldalát olvasva észrevettük, hogy két opciót is tartalmaz --perf- előtaggal, amelyek valószínűleg a teljesítményhangolással kapcsolatosak. Az első a --perf-same_cpu_crypt, meglehetősen rejtélyes leírással:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Az opciót tehát engedélyezzük
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Megjegyezzük: a legutóbbi man page szerint van egy cryptsetup refresh parancs is, amellyel ezeket az opciókat élesben is engedélyezhetjük anélkül, hogy a titkosított eszközt “be kellene zárni” és “újra meg kellene nyitni”. A mi cryptsetup-unk azonban ezt még nem támogatta.
Az ellenőrzés, hogy valóban engedélyezve lett-e az opció:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptIgen, most már same_cpu_crypt látható a kimeneten, amit szerettünk volna. Futtassuk le újra a benchmarkot:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, most ~136 MB/s, ami valamivel rosszabb, mint korábban, tehát nem jó. Mi a helyzet a második lehetőséggel --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Meglehet, itt a “valamilyen helyzetben” vagyunk, próbáljuk ki:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusÉs most a benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, ami egy kicsit jobb, de még mindig nem jó…
Kérdeztük a közösséget
Kétségbeesve úgy döntöttünk, hogy segítséget kérünk az interneten, és a dm-crypt levelezési listán tettük közzé eredményeinket, de a válasz, amit kaptunk, nem volt túl biztató:
Ha a számok zavarnak, akkor ez a te oldaladon a megértés hiányából fakad. Valószínűleg nem vagy tisztában azzal, hogy a titkosítás egy nehézkes művelet…
Úgy döntöttünk, hogy tudományos kutatást végzünk a témában, beírtuk a Google keresőbe, hogy “drága-e a titkosítás”, és az egyik legelső találat, ami valóban értelmes méréseket tartalmaz, az… a saját bejegyzésünk a titkosítás költségeiről, de a TLS kontextusában! Ez önmagában is lenyűgöző olvasmány, de a lényeg a következő: a modern titkosítás modern hardveren nagyon olcsó, még Cloudflare léptékben is (több millió titkosított HTTP-kérés másodpercenként). Valójában annyira olcsó, hogy a Cloudflare volt az első szolgáltató, amely mindenki számára ingyenes SSL/TLS-t kínált.
A forráskódba való beleásás
A fent leírt egyéni dm-crypt opciók használatának próbálkozásakor kíváncsiak voltunk, hogy miért léteznek egyáltalán, és mi ez a “tehermentesítés”. Eredetileg arra számítottunk, hogy a dm-crypt egy egyszerű “proxy” lesz, amely csak titkosítja/dekódolja az adatokat, ahogy azok átfutnak a vermen. Kiderült, hogy a dm-crypt többre képes, mint a memóriapufferek titkosítása, és az alábbiakban egy (egyszerűsített) IO áthaladási útvonal diagramot mutatunk be:

Amikor a fájlrendszer írási kérést ad ki, a dm-crypt nem dolgozza fel azt azonnal – ehelyett egy “kcryptd” nevű munkasorba teszi. Dióhéjban, egy kernel workqueue csak beütemez valamilyen munkát (ebben az esetben a titkosítást) egy későbbi időpontra, amikor az kényelmesebb. Amikor “eljön az idő”, dm-crypt elküldi a kérést a Linux Crypto API-nak a tényleges titkosításhoz. A modern Linux Crypto API azonban aszinkron is, így attól függően, hogy milyen konkrét implementációt használ a rendszered, valószínűleg nem azonnal kerül feldolgozásra, hanem újra sorba kerül “későbbi időpontra”. Amikor a Linux Crypto API végül elvégzi a titkosítást, a dm-crypt megpróbálhatja rendezni a függőben lévő írási kéréseket úgy, hogy minden egyes kérést egy piros-fekete fába helyez. Ezután egy külön kernel szál ismét “valamikor később” ténylegesen átveszi a fában lévő összes IO kérést, és leküldi őket a veremben.
Most az olvasási kérések: ezúttal először a titkosított adatokat kell megkapnunk a hardvertől, de a dm-crypt nem egyszerűen elkéri a meghajtótól az adatokat, hanem a kérést egy másik, “kcryptd_io” nevű workqueue-ba sorolja. Egy későbbi időpontban, amikor már valóban megvan a titkosított adat, a már ismert “kcryptd” workqueue segítségével ütemezzük be a dekódolást. A “kcryptd” elküldi a kérést a Linux Crypto API-nak, amely aszinkron módon is visszafejtheti az adatokat.
Az igazság kedvéért a kérés nem mindig halad át ezeken a sorokon, de itt az a fontos, hogy az írási kérések akár 4-szer is beállhatnak a dm-crypt sorba, az olvasási kérések pedig akár 3-szor is. Ezen a ponton azon tűnődtünk, hogy ez a sok extra sorban állás okozhat-e teljesítményproblémákat. Van például egy szép bemutató a Google-től a sorbaállítás és a tail latency közötti kapcsolatról. A prezentáció egyik legfontosabb tanulsága:
A tail latency jelentős része a sorban állás hatásainak köszönhető
Szóval, miért vannak ezek a sorban állások, és el tudjuk-e távolítani őket?
Git archeológia
Senki sem ír bonyolultabb kódot csak úgy szórakozásból, különösen nem az operációs rendszer kerneléhez. Tehát ezek a várólisták biztos okkal kerültek oda. Szerencsére a Linux kernel forrását a git kezeli, így megpróbálhatjuk visszakövetni a változtatásokat és az azokat körülvevő döntéseket.
A “kcryptd” workqueue a forrásban volt a rendelkezésre álló történet kezdete óta a következő megjegyzéssel:
Szükséges, mert nagyon nem lenne bölcs dolog megszakítási kontextusban dekódolást végezni, ezért az olvasási kérésekből visszatérő bios ide kerül sorba.
Szóval csak olvasásra, de még akkor is – miért érdekel minket, hogy megszakítási kontextusban van-e vagy sem, ha a Linux Crypto API valószínűleg úgyis egy dedikált szálat/várólistát fog használni a titkosításra? Nos, 2005-ben a Crypto API nem volt aszinkron, így ennek tökéletes értelme volt.
2006-ban dm-crypt elkezdte használni a “kcryptd” workqueue-t nem csak titkosításra, hanem IO kérések benyújtására is:
Ez a javítás célja, hogy a dm-crypt megfeleljen a következő patch által a -mm-ben előírt új korlátozásoknak: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Úgy tűnik, hogy a cél itt nem a több párhuzamosság hozzáadása volt, hanem a kernel veremhasználatának csökkentése, aminek ismét van értelme, mivel a kernel az összes kódban közös veremmel rendelkezik, így ez egy meglehetősen korlátozott erőforrás. Érdemes azonban megjegyezni, hogy a Linux kernel verem 2014-ben bővült az x86-os platformok számára, így ez talán már nem jelent problémát.
A “kcryptd_io” workqueue első verzióját 2007-ben adták hozzá azzal a szándékkal, hogy elkerüljék:
a memória kiosztására váró sok kérés okozta éhezést…
A kérések feldolgozása itt egyetlen workqueue-n szűk keresztmetszetet okozott, ezért a megoldás egy másik workqueue hozzáadása volt. Van értelme.
Egyértelműen nem mi vagyunk az elsők, akik teljesítménycsökkenést tapasztalnak a kiterjedt sorbaállítás miatt: 2011-ben bevezettek egy változtatást, amely feltételesen visszaállította az olvasási kérések sorbaállításának egy részét:
Ha van elég memória, a kód közvetlenül elküldheti a bio-t ahelyett, hogy ezt a műveletet egy külön szálban sorba állítaná.
Szerencsére akkoriban a Linux kernel commit üzenetei nem voltak olyan bőbeszédűek, mint manapság, így nem állnak rendelkezésre teljesítményadatok.
2015-ben a dm-crypt elkezdte az írásokat egy külön “dmcrypt_write” szálban rendezni, mielőtt leküldi őket a veremben:
Multiprocesszoros gépen a titkosítási kérések más sorrendben fejeződnek be, mint ahogyan elküldték őket. Következésképpen az írási kérések is más sorrendben lennének elküldve, és ez komoly teljesítménycsökkenést okozhat.
Ez valóban értelmes, mivel a szekvenciális lemezelérés régebben sokkal gyorsabb volt, mint a véletlenszerű, és dm-crypt megtörte ezt a mintát. De ez leginkább a pörgős lemezekre vonatkozik, amelyek 2015-ben még dominánsak voltak. A modern gyors SSD-knél (beleértve az NVME SSD-ket is) talán már nem annyira fontos.
A commit üzenet egy másik részét is érdemes megemlíteni:
…különösen lehetővé teszi az IO ütemezők, mint a CFQ, hatékonyabb rendezést…
Ez a CFQ IO ütemező teljesítményelőnyeit említi, de a Linux ütemezők azóta annyit fejlődtek, hogy a CFQ ütemezőt 2018-ban eltávolították a kernelből.
Ez a patchkészlet a rendezési listát egy piros-fekete fával helyettesíti:
A rendezést elméletileg a mögöttes lemezütemezőnek kellene elvégeznie, azonban a gyakorlatban a lemezütemező csak véges számú kérést fogad el és rendezi. Ahhoz, hogy az összes kérés rendezését lehetővé tegye, a dm-cryptnek saját rendezést kell implementálnia.
Az rbtree-alapú rendezéssel járó többletköltséget elhanyagolhatónak tartják, ezért feltételesen nem használják.
Az egésznek van értelme, de jó lenne, ha lenne néhány háttéradat.
Érdekes, hogy ugyanebben a patchkészletben látjuk az általunk ismert “submit_from_crypt_cpus” opció bevezetését:
Vannak olyan helyzetek, amikor a titkosítási szálakról az írási bioszok egyetlen szálra való áthelyezése jelentősen rontja a teljesítményt
Összességében láthatjuk, hogy minden változtatás ésszerű és szükséges volt, azonban a dolgok azóta megváltoztak:
- a hardver gyorsabb és okosabb lett
- a Linux erőforrás-elosztását felülvizsgálták
- a Linux alrendszerek összekapcsolt rendszereit újraarchitektúrázták
És a fenti tervezési döntések közül sok nem feltétlenül alkalmazható a modern Linuxra.
A “tisztítás”
A fenti kutatás alapján úgy döntöttünk, hogy megpróbáljuk eltávolítani az összes extra sorbanállást és aszinkron viselkedést, és visszatérünk dm-crypt az eredeti céljához: egyszerűen titkosítani/dekódolni az IO kéréseket, ahogy áthaladnak. De a stabilitás és a további benchmarking érdekében végül nem távolítottuk el a tényleges kódot, hanem inkább egy újabb dm-crypt opciót adtunk hozzá, amely az összes várólistát/szálat megkerüli, ha engedélyezve van. A flag lehetővé teszi számunkra, hogy teljes termelési terhelés alatt, futásidőben váltsunk a jelenlegi és az új viselkedés között, így könnyen vissza tudjuk állítani a változtatásainkat, ha bármilyen mellékhatást észlelünk. Az így kapott javítás megtalálható a Cloudflare GitHub Linux repositoryban.
Synchronous Linux Crypto API
A fenti diagramból emlékszünk arra, hogy nem minden sorbanállás van implementálva a dm-crypt-ban. A modern Linux Crypto API is lehet aszinkron, és a kísérlet kedvéért ott is ki akarjuk iktatni a sorban állást. Mit jelent azonban az, hogy “lehet”? Az operációs rendszerben ugyanannak az algoritmusnak különböző implementációi lehetnek (például hardveresen gyorsított AES-NI x86-os platformokon és általános C-kódos AES implementációk). Alapértelmezés szerint a rendszer a konfigurált algoritmusprioritás alapján a “legjobbat” választja. A dm-crypt lehetővé teszi ennek a viselkedésnek a felülbírálását, és a capi: előtag használatával egy adott titkosítási implementáció kérését. Van azonban egy probléma. Nézzük meg ténylegesen a rendszerünkön elérhető AES-XTS (ez a mi lemezes titkosításunk, emlékszünk?) implementációkat:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64A fenti listából kifejezetten szinkron titkosítást szeretnénk választani, hogy elkerüljük a szálak sorbanállási hatásait, de az egyetlen támogatott a xts(ecb(aes-generic)) (az általános C implementáció) és a __xts-aes-aesni (az x86 hardveresen gyorsított implementáció). Mindenképpen az utóbbit szeretnénk, mivel sokkal gyorsabb (itt a teljesítményre törekszünk), de gyanúsan belsőnek van jelölve (lásd internal: yes). Ha megnézzük a forráskódot:
Mark a cipher as a service implementation only used by another cipher and never by a normal user of the kernel crypto API
So this cipher is meant to be used only by other wrapper code in the Crypto API and not outside it. A gyakorlatban ez azt jelenti, hogy a Crypto API hívójának kifejezetten meg kell adnia ezt a flaget, amikor egy adott rejtjel implementációt kér, de dm-crypt ezt nem teszi meg, mert eleve nem a Linux Crypto API része, inkább egy “külső” felhasználóé. A dm-crypt modult már javítjuk, így akár egyszerűen hozzá is adhatjuk a megfelelő flaget. Van azonban egy másik probléma is, különösen az AES-NI-vel kapcsolatban: x86 FPU. Azt mondod “lebegőpontos”? Miért van szükségünk lebegőpontos matematikára a szimmetrikus titkosításhoz, aminek csak biteltolásokról és XOR műveletekről kellene szólnia? Nincs szükségünk matematikára, de az AES-NI utasítások a CPU néhány regiszterét használják, amelyek az FPU számára vannak dedikálva. Sajnos a Linux kernel a teljesítmény miatt nem mindig őrzi meg ezeket a regisztereket megszakítási kontextusban (az FPU mentése/visszaállítása drága). De dm-crypt előfordulhat, hogy megszakítási kontextusban hajtunk végre kódot, így azt kockáztatjuk, hogy megrongálunk néhány más folyamat adatait, és visszatérünk az eredeti kódban szereplő “nagyon nem lenne bölcs dolog megszakítási kontextusban végezni a dekódolást” kijelentéshez.
A megoldásunk a fentiek kezelésére egy másik, kissé “okos” Crypto API modul létrehozása volt. Ez a modul szinkron, és nem tekeri a saját kriptográfiáját, hanem csak a titkosítási kérések “útválasztója”:
- ha az aktuális végrehajtási kontextusban tudjuk használni az FPU-t (és így az AES-NI-t), akkor csak továbbítjuk a titkosítási kérést a gyorsabb, “belső”
__xts-aes-aesniimplementációhoz (és itt tudjuk használni, mert most már a Crypto API része vagyunk) - máskülönben csak továbbítjuk a titkosítási kérést a lassabb, általános C-alapú
xts(ecb(aes-generic))implementációnak
Az egészet használva
Menjünk végig az egész használatán együtt. Az első lépés a javítások megszerzése és a kernel újrafordítása (vagy csak a dm-crypt és a mi xtsproxy moduljaink lefordítása).
Következő lépésként indítsuk újra az IO munkaterhelésünket egy külön terminálban, hogy meggyőződhessünk róla, hogy terhelés alatt, futásidőben újra tudjuk konfigurálni a kernelt:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...A fő terminálban győződjünk meg róla, hogy az új Crypto API modulunk betöltődött és elérhető:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Konfiguráljuk újra a titkosított lemezt, hogy használja az újonnan betöltött modulunkat, és engedélyezzük a javított dm-crypt flagünket (ehhez alacsony szintű dmsetup eszközt kell használnunk, mivel a cryptsetup nyilvánvalóan nem tud a módosításainkról):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Az imént “betöltöttük” az új konfigurációt, de ahhoz, hogy az érvénybe lépjen, fel kell függesztenünk/újrakapcsolnunk a titkosított eszközt:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0És most figyeljük az eredményt. Visszamehetünk a másik terminálra, ahol a fio feladat fut, és megnézhetjük a kimenetet, de hogy szebb legyen, íme egy pillanatkép a Grafana-ban megfigyelt olvasási/írási átviteli sebességről:
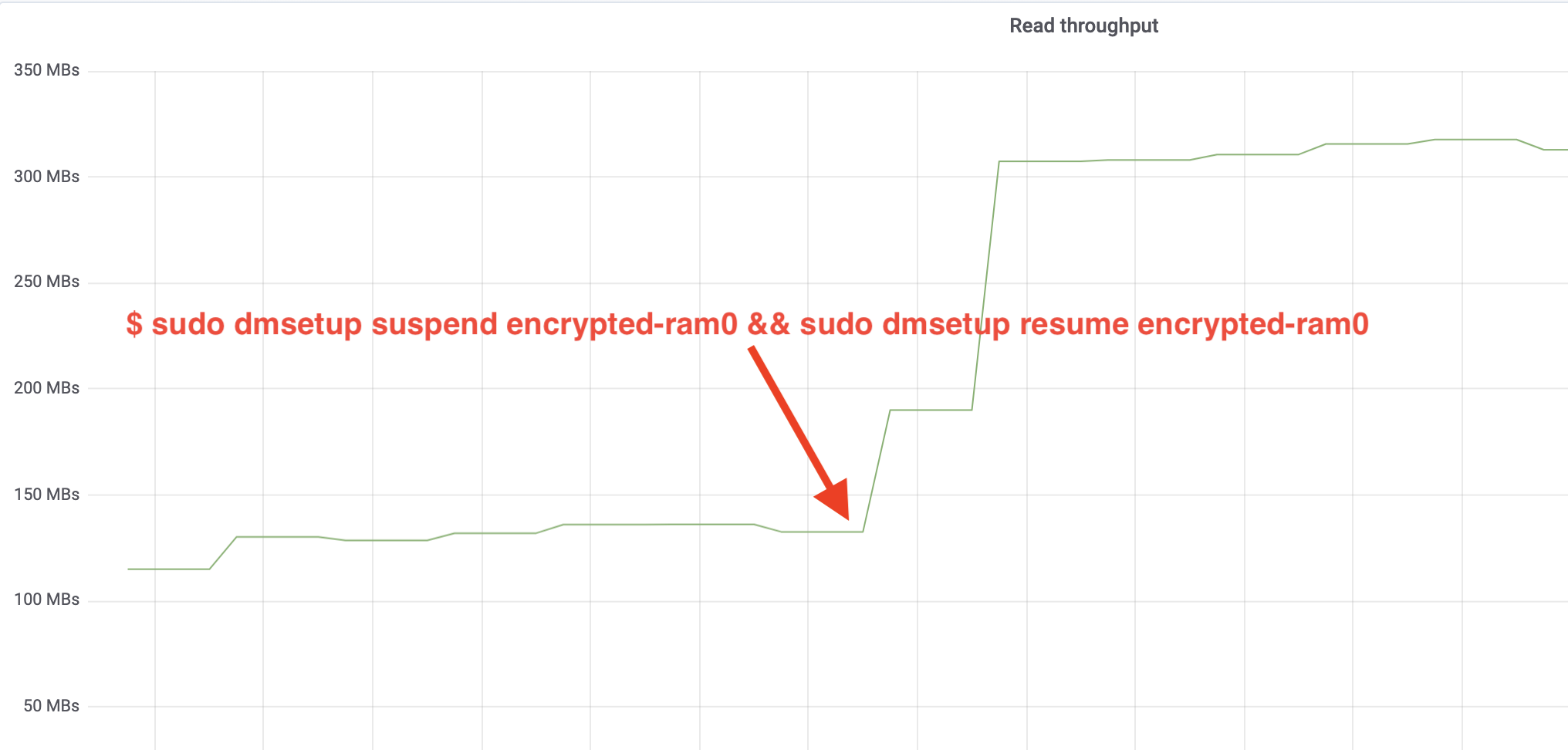
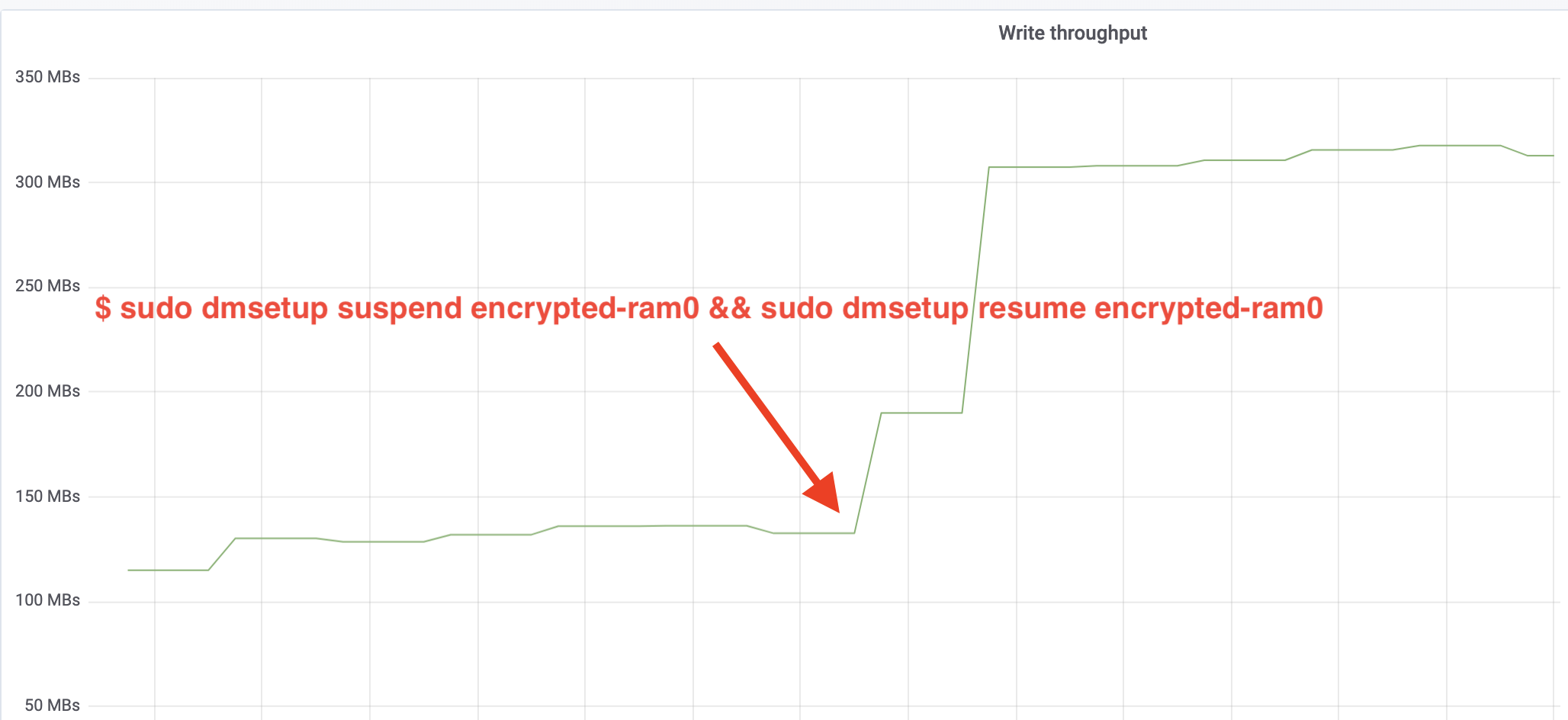
Hű, több mint megdupláztuk az átviteli sebességet! A teljes ~640 MB/s áteresztőképességgel már sokkal közelebb vagyunk a fentebb várt ~696 MB/s értékhez. Mi a helyzet az IO késleltetéssel? (Az iostat jelentési eszköz await statisztikája):
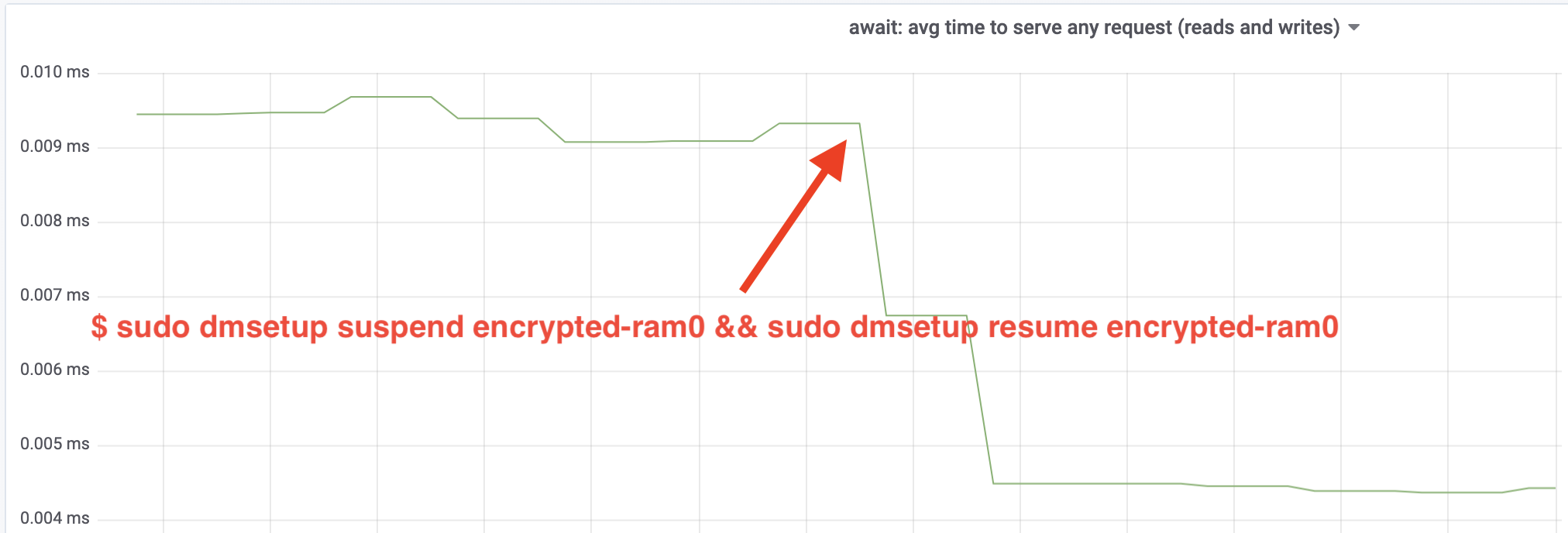
A késleltetés is a felére csökkent!
A termeléshez
Edig egy szintetikus beállítást használtunk, amelyből hiányzott a teljes termelési stack néhány része, például a fájlrendszerek, a valódi hardver és ami a legfontosabb, a termelési munkaterhelés. Hogy biztosak lehessünk abban, hogy nem képzeletbeli dolgokat optimalizálunk, íme egy pillanatkép arról, hogy ezek a változtatások milyen termelési hatást gyakorolnak a stackünk gyorsítótárazási részére:

Ez a grafikon az egyik szerverünk gyorsítótárának legrosszabb esetre vonatkozó válaszidejének (99. percentilis) hármas összehasonlítását mutatja be. A zöld vonal egy titkosítatlan lemezekkel rendelkező szerverről származik, amelyet alapértékként fogunk használni. A piros vonal egy titkosított lemezekkel rendelkező szerverről származik, az alapértelmezett Linux lemez titkosítási implementációval, a kék vonal pedig egy titkosított lemezekkel rendelkező és a mi optimalizációinkat engedélyező szerverről. Amint láthatjuk, az alapértelmezett Linux lemezek titkosításának megvalósítása a legrosszabb esetben jelentős hatással van a gyorsítótár késleltetésére, míg a javított megvalósítás megkülönböztethetetlen attól, mintha egyáltalán nem használnánk titkosítást. Más szóval a továbbfejlesztett titkosítási implementációnak egyáltalán nincs hatása a gyorsítótár válaszsebességére, tehát gyakorlatilag ingyen kapjuk! Ez egy győzelem!
Még csak most kezdtük
Ez a bejegyzés megmutatja, hogy egy architektúra felülvizsgálata hogyan duplázhatja meg egy rendszer teljesítményét. Emellett újra megerősítettük, hogy a modern kriptográfia nem drága, és általában nincs kifogás arra, hogy ne védd meg az adataidat.
Ezt a munkát be fogjuk nyújtani a fő kernel forrásfájába való felvételre, de valószínűleg nem a jelenlegi formájában. Bár az eredmények biztatónak tűnnek, nem szabad elfelejtenünk, hogy a Linux egy rendkívül hordozható operációs rendszer: nagy teljesítményű szervereken éppúgy fut, mint kis erőforrás-korlátozott IoT-eszközökön és számos más CPU-architektúrán is. A foltok jelenlegi verziója csak a lemeztitkosítást optimalizálja egy adott munkaterhelésre egy adott architektúrán, de a Linuxnak olyan megoldásra van szüksége, amely mindenhol zökkenőmentesen fut.
Ezek alapján, ha úgy gondolod, hogy a te eseted hasonló, és már most szeretnéd kihasználni a teljesítményjavulást, akkor szerezd be a foltokat és remélhetőleg adj visszajelzést. A futásidejű flag megkönnyíti a funkcionalitás menet közbeni átkapcsolását, és egy egyszerű A/B tesztet is el lehet végezni, hogy lássuk, előnyös-e ez egy adott esetben vagy beállításban. Ezek a javítások több mint 200 adatközpontból álló széles hálózatunkban, öt generációs hardveren futnak, így ésszerűen stabilnak tekinthetők. Élvezze mind a teljesítményt, mind a Cloudflare biztonságát mindenki számára!

Frissítés (2020. október 11.)
A blogban található fő javítás (kissé frissített formában) beolvadt a fővonalbeli Linux kernelbe, és az 5.9-es verziótól kezdve elérhető. A fő különbség az, hogy a mainline verzió egy helyett két flaget tesz közzé, amelyek lehetővé teszik a dm-crypt munkasorok megkerülését olvasás és írás esetén egymástól függetlenül. A részletekért lásd a hivatalos dm-crypt dokumentációt.