Az infrastruktúra virtualizálása és az üzleti szempontból kritikus munkaterhelések kiszolgálására szolgáló virtuális erőforrások futtatása számos nagy előnnyel jár. A VMware vSphere esetében számos figyelemre méltó funkciót és képességet biztosít, amelyek nagyfokú rendelkezésre állást biztosítanak a környezetben, valamint automatizált munkaterhelés-ütemezést, hogy a vSphere-környezetben a hardver és az erőforrások leghatékonyabb felhasználását biztosítsa.
Ebben a bejegyzésben a vSphere két alapvető, vállalati fürt szintű funkciójáról, a vSphere HA-ról és a DRS-ről lesz szó. Valószínűleg mindkettőre látott már hivatkozni a vSphere vállalati futtatásával együtt.
Mi a vSphere HA és a DRS? Mi a feladatuk?
Milyen előnyökkel jár, ha mindkettőt futtatja a vSphere-környezetében?
Vessünk egy pillantást a VMware vSphere HA és DRS alapvető bevezetésére, és nézzük meg, hogyan viszonyulnak egymáshoz, és milyen előnyökkel jár a használatuk.
VMware vSphere Clusters
A vSphere Cluster futtatása az egyik nyilvánvaló előny és legjobb gyakorlat, amikor a VMware vSphere-t üzleti szempontból kritikus munkaterhelések futtatására használjuk.
Mi a vSphere-klaszter?
A vSphere-klaszter egynél több VMware ESXi-kiszolgálóból álló konfiguráció, amely a vSphere-klaszterhez hozzájáruló erőforrások pooljaként van összevonva. Az egyes ESXi hosztok olyan erőforrásokkal járulnak hozzá, mint a CPU számítási kapacitás, a memória és a szoftveresen definiált tárolás, például a vSAN esetében a tárolás.
Miért fontos az üzleti szempontból kritikus munkaterhelések futtatása egy vSphere Cluster tetején?
Ha a hypervisor futtatása által nyújtott előnyökre gondol, akkor az lehetővé teszi, hogy egynél több kiszolgálót futtasson egyetlen fizikai hardveren. A munkaterhelések ilyen módon történő virtualizálása számos nagyságrendnyi hatékonysági előnyt biztosít ahhoz képest, mintha egyetlen kiszolgálót futtatnánk egyetlen fizikai hardveren.
Ez azonban a virtualizált megoldás Achilles-sarkává is válhat, mivel egy hardverhiba hatása sokkal több üzletileg kritikus szolgáltatást és alkalmazást érinthet. Elképzelhető, hogy ha csak egyetlen VMware ESXi hoszton fut sok VM, akkor ennek az egyetlen ESXi hosztnak a kiesése óriási hatással járna.
Ez az a pont, ahol több VMware ESXi hoszt vSphere Clusterben történő futtatása igazán ragyog.
Azt kérdezheti azonban, hogy hogyan növeli egyszerűen több hoszt futtatása egy fürtben a magas rendelkezésre állást? Honnan “tudja” a vSphere Clusterben lévő host, ha egy másik host meghibásodott? Van-e valamilyen speciális mechanizmus, amely gondoskodik a vSphere Clusterben futó munkaterhelések magas rendelkezésre állásának kezeléséről? Igen, van ilyen. Lássuk.
Mi a HA a VMware-ben?
A VMware felismerte, hogy szükség van egy olyan mechanizmusra, amely képes védelmet nyújtani a vSphere Clusterben lévő ESXi hostok meghibásodása ellen. Ezzel az igénnyel született meg a VMware High-Availability (HA).
A VMware vSphere HA a következő előnyöket nyújtja:
A VMware vSphere HA költséghatékony, és lehetővé teszi a VM-ek és a vSphere hosztok automatikus újraindítását, ha a vSphere-környezetben szerverkiesés vagy operációs rendszerhiba észlelhető
A vSphere-klaszterben lévő összes VMware vSphere host & VM felügyelete
Magas rendelkezésre állást biztosít a virtuális gépeken futó legtöbb alkalmazás számára, függetlenül az operációs rendszertől és az alkalmazásoktól.
A VMware vSphere HA megoldásának szépsége, amely a VMware Cluster segítségével valósul meg, az az egyszerűség, amellyel konfigurálható. Néhány kattintással, egy varázsló által vezérelt felületen keresztül konfigurálható a nagy rendelkezésre állás. Hogyan viszonyul ez a hagyományos “fürtözési” technológiákhoz?
Windows Server Failover Clustering összehasonlítás
A Windows Server Failover Clustering (WSFC) lett az a fürtözési technológia, amelyre a legtöbben gondolnak, amikor a fürtözési technológiára gondolnak. A WSFC-vel kapcsolatban látott probléma az, hogy a WSFC-szolgáltatások megfelelő futtatásához sok speciális szakértelemre van szükség, különösen a frissítések, a javítások és az általános üzemeltetési feladatok esetében.
A vSphere HA és a WSFC összehasonlításában az üzemeltetési többletköltségek minimálisak a WSFC-hez képest. Kevés esély van arra, hogy a HA-t rosszul konfigurálják, mivel vagy engedélyezve van egy fürtön, vagy nem. A WSFC esetében a WSFC konfigurálásakor számos megfontolásra van szükség a konfigurációs és végrehajtási hibák elkerülése érdekében. Gondoljon a következőkre:
- A Failover Clustering olyan alkalmazásokat igényel, amelyek támogatják a fürtözést (SQL stb.)
- A Failover Clustering megköveteli a quorum megfelelő konfigurálását
- Nem támogatja sok régi operációs rendszer és alkalmazás
- A fürt hálózati neveinek, erőforrásainak és hálózatának összetettségét igényli
A Windows Server Failover Clustering a reklámok szerint alkalmazásszinten közel nulla állásidőt biztosít. Ha azonban hozzáadjuk a megfelelően működő HA-megoldáshoz szükséges szakértelmet, valamint a WSFC megfelelő végrehajtását, a kockázatok kezdik felülmúlni az alkalmazások és szolgáltatások nagyfokú rendelkezésre állására szolgáló WSFC használatának előnyeit. Ez különösen igaz a legtöbb szervezet esetében, amelyeknek nem feltétlenül van szükségük valóban “zéró leállási idejű” megoldásra. Ráadásul az alkalmazást úgy kell megtervezni, hogy kihasználja a WSFC előnyeit, és megfelelően működjön a WSFC technológiával.
Míg a vSphere HA megköveteli a virtuális gépek újraindítását egy egészséges állomáson, amikor meghibásodás történik, nem igényel további szoftverek telepítését a vendég virtuális gépeken belül, nem igényel további fürtözési technológiák bonyolult konfigurációit, és az alkalmazásokat vagy operációs rendszereket nem kell úgy tervezni, hogy azok bizonyos fürtözési technológiával működjenek.
A hagyományos operációs rendszerek és alkalmazások általában korlátozott képességekkel rendelkeznek a nagy rendelkezésre állást biztosító támogatott technológiák tekintetében. Így szó szerint előfordulhat, hogy nincsenek natív lehetőségek a hardverhibák esetén a failover funkció biztosítására.
A vSphere HA nagy rendelkezésre állású mechanizmusa működik, és egyszerűen megvalósítható, konfigurálható és kezelhető. Ráadásul ez egy olyan technológia, amelyet több ezer VMware ügyfélkörnyezetben jól teszteltek, így stabil és hosszú múltra visszatekintő sikeres telepítésekkel rendelkezik.
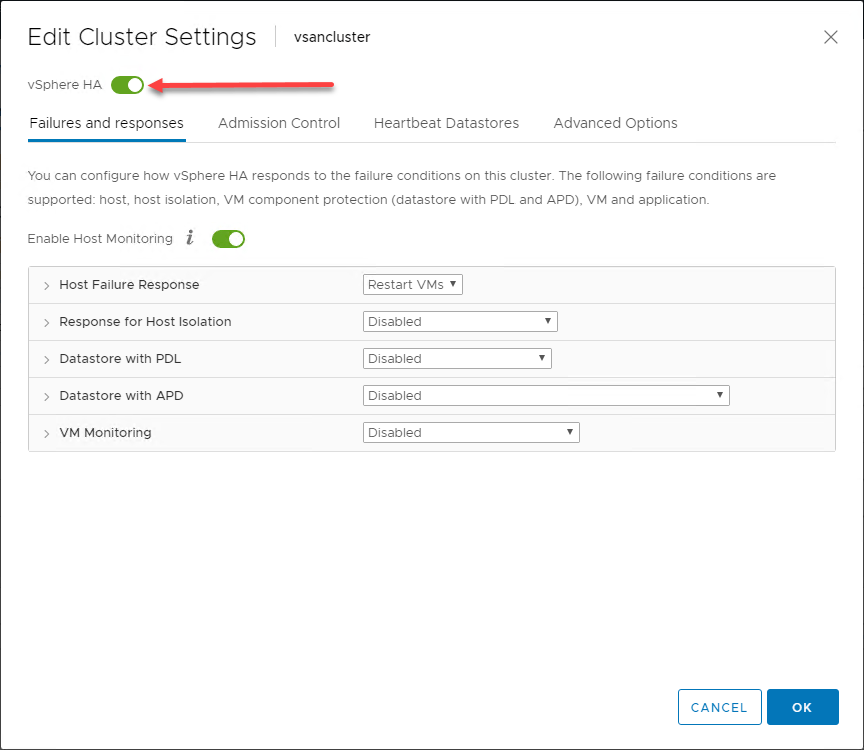
A vSphere HA viselkedésének általános áttekintése
A vSphere Clusterben lévő ESXi hosztok számára biztosított előnyök kihasználásával a vSphere HA a legegyszerűbb formájában egy felügyeleti mechanizmust valósít meg a vSphere Clusterben lévő hosztok között. A felügyeleti mechanizmus lehetővé teszi annak megállapítását, hogy a vSphere Cluster bármelyik hosztja meghibásodott-e.
A lenti infografikán egy két csomópontos vSphere Clusterben a vSphere Cluster egyik ESXi hosztjának meghibásodása történt. A vSphere Clusterben a vSphere HA fürt szinten engedélyezve van.
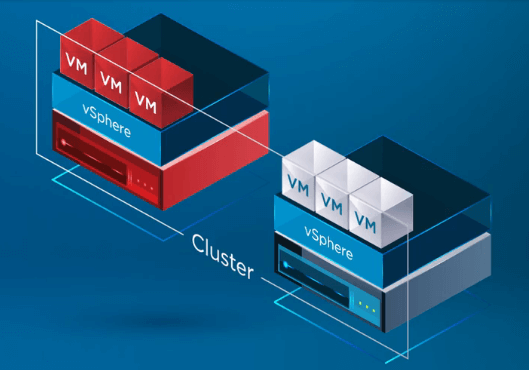
Miután a vSphere HA felismeri, hogy a vSphere Cluster egyik hostja meghibásodott, a HA-folyamat áthelyezi a VM-ek regisztrációját a meghibásodott hostról egy egészséges hostra.
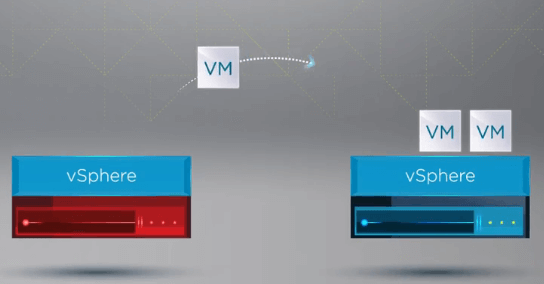
Azt követően, hogy a VM-ek regisztrálása egy egészséges hosztra történt, a vSphere HA újraindítja a meghibásodott host összes VM-jét egy egészséges ESXi hoston a fürtben, ahol a VM-ek újraregisztrálása történt. Az egyetlen kiesési idő a VM-ek újraindítása a vSphere fürt egy egészséges állomásán.
VSphere HA technikai áttekintés
A vSphere HA előfeltételei
Elképzelhető, hogy milyen alapfeltételekre lehet szükség a vSphere HA működéséhez. Egyszerűen csak egy VMware Clusterre van szükség a HA engedélyezéséhez? A Windows Server Failover Clusteringtől eltérően a HA működéséhez csak néhány követelménynek kell teljesülnie.
Követelmények:
- Mindössze két ESXi host
- Mindegyik hoston legalább 4 GB memória konfigurálva
- vCenter Server
- vSphere Standard License
- Megosztott tároló a VM-ek számára
- Pingelhető átjáró vagy más megbízható hálózati csomópont
Ha észreveszi, nincs szükség quorum komponensre, nincs szükség bonyolult hálózati elnevezésekre, és nincs más speciális fürt erőforrás, amelynek a helyén kellene lennie.
Bővebben: Hogyan kell konfigurálni egy vSphere High Availability fürtöt
VMware vSphere HA Master vs. alárendelt hosztok
A vSphere HA fürtön történő engedélyezésekor a vSphere fürtben egy adott hosztot jelöl ki a vSphere HA masterjeként. A vSphere Cluster többi ESXi hosztja alárendeltként van konfigurálva a vSphere HA konfigurációban.
Milyen szerepet játszik a mesterré kijelölt vSphere HA ESXi állomás? A vSphere HA master csomópont:
- Figyeli az alárendelt slave hostok állapotát – Ha az alárendelt host meghibásodik vagy elérhetetlen, a master host azonosítja, hogy mely VM-eket kell újraindítani
- Figyeli az összes védett VM energiaellátási állapotát. Ha egy VM meghibásodik, a master vSphere HA csomópont gondoskodik a VM újraindításáról. A vSphere HA master eldönti, hogy hol történik a VM újraindítása (melyik ESXi hoszton).
- Követi a vSphere HA által védett összes fürthostot és VM-et
- A vSphere Cluster és a vCenter Server közötti közvetítőnek van kijelölve. A HA master jelenti a fürt állapotát a vCenter számára, és kezelési felületet biztosít a fürthöz a vCenter Server számára
- Maga is futtathat VM-eket, és figyelemmel kísérheti a VM-ek állapotát
- A védett VM-eket a fürt adattárolóiban tárolja
vSphere HA alárendelt hosztok:
- Lokálisan futtatja a virtuális gépeket
- Figyeli a vSphere fürtben lévő VM-ek futásidejű állapotait
- Beszámol a vSphere HA főállomásnak az állapotfrissítésekről
Mesterállomás kiválasztása és a főállomás hibája
Hogyan történik a vSphere HA főállomás kiválasztása? Amikor a vSphere HA engedélyezve van egy fürtben, az összes aktív hoszt (nincs karbantartási mód stb.) részt vesz a master hoszt megválasztásában. Ha a megválasztott mesterállomás meghibásodik, új választás történik, ahol egy új HA-mesterállomás kerül kiválasztásra, amely betölti ezt a szerepet.
VMware vSphere HA fürt hibatípusai
Egy vSphere HA engedélyezett fürtben háromféle hiba történhet, amelyek vSphere HA failover eseményt váltanak ki. Ezek az állomáshibatípusok a következők:
- Hiba – A hiba intuitíve az, amire gondol. Egy állomás valamilyen formában vagy módon leállt hardveres vagy egyéb problémák miatt.
- Elszigetelés – Egy állomás elszigetelése általában egy olyan hálózati esemény miatt történik, amely elszigeteli az adott állomást a vSphere HA fürt többi állomásától.
- Szétválasztás – A szétválasztási eseményt az jellemzi, hogy egy alárendelt állomás elveszíti hálózati kapcsolatát a vSphere HA fürt master állomásával.
Heartbeating, Failure Detection, and Failure Actions
Hogyan állapítja meg a master csomópont, hogy egy adott állomás meghibásodott-e?
A fő csomópont több különböző mechanizmust használ annak megállapítására, hogy egy állomás meghibásodott-e:
- A fő csomópont másodpercenként hálózati szívveréseket cserél a fürt többi állomásával.
- A hálózati szívverés meghibásodása után a fő állomás ellenőrzi az állomás életképességének ellenőrzését.
- Az állomás életképességének ellenőrzése meghatározza, hogy az alárendelt állomás cserél-e szívveréseket valamelyik adattárolóval. Ezután ICMP pingeket küld a kezelési IP-címekre
- Ha az alárendelt állomás HA-ügynökével való közvetlen kommunikáció a főállomásról nem lehetséges, és a kezelési címre küldött ICMP pingek sikertelenek, az állomás hibásnak minősül, és a VM-ek egy másik állomáson indulnak újra.
- Ha kiderül, hogy az alárendelt állomás szívveréseket cserél az adattárolóval, a főállomás feltételezi, hogy az állomás hálózati partícióban van vagy hálózati elszigetelt. Ebben az esetben a master egyszerűen figyeli a hosztot és a VM-eket
- Hálózati izolációnak nevezzük azt az esetet, amikor az alárendelt hoszt fut, de a HA menedzsmentügynök szempontjából már nem látható a menedzsmenthálózaton. Ha egy állomás már nem látja ezt a forgalmat, megpróbálja pingelni a fürtelkülönítési címeket. Ha ez a pingelés sikertelen, az állomás kijelenti, hogy elszigetelődött a hálózattól
- Ez esetben a fő csomópont figyeli az elszigetelt állomáson futó VM-eket. Ha a VM-ek kikapcsolnak az elszigetelt állomáson, a master csomópont újraindítja a VM-eket egy másik állomáson
Datastore Heartbeating
Mint már említettük, az egyik metrika, amelyet a hiba észlelésére használunk, a datastore heartbeating. Mi is ez pontosan? A VMware vCenter kiválasztja az adattárolók egy preferált csoportját a heartbeatinghez. Ezután a vSphere HA létrehoz egy könyvtárat az egyes adattárolók gyökerénél, amelyet mind az adattárolók szívverésére, mind a védett VM-ek listájának vezetésére használ. Ennek a könyvtárnak a neve .vSphere-HA.
A vSAN adattárolókkal kapcsolatban van egy fontos megjegyzés. A vSAN adattároló nem használható adattároló szívverésre. Ha csak egy vSAN adattároló áll rendelkezésre, akkor nem használhatók heartbeat adattárolók.
- VM- és alkalmazásfigyelés
A vSphere HA másik rendkívül hatékony funkciója az egyes virtuális gépek VMware Tools-on keresztüli figyelése és az olyan virtuális gépek újraindítása, amelyek nem reagálnak a VMware Tools szívverésekre. Az Alkalmazásfelügyelet képes újraindítani egy VM-et, ha egy futó alkalmazás szívverései nem érkeznek meg.
- VM Monitoring – A VM Monitoring szolgáltatás a VMware Tools segítségével állapítja meg, hogy az egyes VM-ek futnak-e, a VMware Tools által generált szívverések és lemezes I/O ellenőrzése révén. Abban az esetben, ha ezek az ellenőrzések sikertelenek, a VM felügyeleti szolgáltatás megállapítja, hogy valószínűleg a vendég operációs rendszer hibásodott meg, és a VM újraindul. A kiegészítő lemez I/O ellenőrzés segít elkerülni a felesleges VM-újraindításokat, ha a VM-ek vagy az alkalmazások még mindig megfelelően működnek.
Alkalmazásfelügyelet – Az alkalmazásfelügyeleti funkciót a megfelelő SDK beszerzésével lehet aktiválni egy harmadik féltől származó szoftvergyártótól, amely lehetővé teszi a vSphere HA folyamat által felügyelendő alkalmazások egyéni szívveréseinek beállítását. A VM-felügyeleti folyamathoz hasonlóan, ha az alkalmazások szívveréseinek fogadása megszűnik, a VM alaphelyzetbe kerül.
Mindkét felügyeleti funkció tovább konfigurálható a felügyeleti érzékenységgel és a VM-enkénti maximális visszaállításokkal, hogy elkerülhető legyen a VM-ek ismételt visszaállítása szoftveres vagy hamis pozitív hibák miatt.
A VMware vSphere HA egy nagyszerű módja annak, hogy a vSphere fürtje nagyon rugalmas nagy rendelkezésre állást biztosítson a vSphere fürtjében lévő ESXi hosztok általános állomáshibái ellen.
Mi a helyzet az erőforrások hatékony felhasználásának biztosításával a vSphere fürtjében? Nézzük meg a következő vSphere Cluster rendelkezést, amely segít biztosítani a vSphere Cluster erőforrásainak és kapacitásának hatékony használatát.
Mi a DRS a VMware-ben?
A VMware Distributed Resource Scheduler (DRS) egy igazán hatékony funkció a vSphere Clusterek futtatása során. Ez biztosítja az ütemezést és a terheléselosztást a vSphere Clusterben. A VMware DRS a vSphere Clustersben található funkció, amely biztosítja, hogy a vSphere-környezetben futó virtuális gépek megkapják a hatékony és eredményes működéshez szükséges erőforrásokat.
A VM-ek általában már korán a DRS hatálya alá kerülnek, mivel a DRS-kompatibilis fürtben az első bekapcsolástól kezdve a DRS a VM-eket a legjobb hostra helyezi, amely úgy van konfigurálva, hogy a VM számára a szükséges erőforrásokat biztosítsa, amint bekapcsolják őket. Emellett a DRS arra törekszik, hogy a vSphere fürtök erőforrás-felhasználási szempontból kiegyensúlyozottak maradjanak.
Még ha egy vSphere fürt egy adott időpontban kiegyensúlyozott is, előfordulhat, hogy a VM-ek áthelyeződnek vagy úgy változnak, hogy a fürt erőforrásainak kiegyensúlyozatlansága visszakúszik a környezetbe. Ha a fürtök kiegyensúlyozatlanná válnak, az hátrányosan befolyásolhatja a vSphere Clusterben futó virtuális gépek általános teljesítményét.
Alapértelmezés szerint a DRS ötpercenként automatikusan lefut a vSphere fürtön, hogy meghatározza a vSphere fürt egyensúlyát, és megállapítsa, hogy szükséges-e bármilyen változtatás az erőforrások hatékonyabb kihasználása érdekében.
VMware DRS követelmények
A VMware DRS előnyeinek kihasználásához több követelménynek is meg kell felelni ahhoz, hogy az elosztott erőforrás ütemező funkciót ki lehessen használni. Ezek közé tartozik:
- Egy ESXi hosztokból álló fürt
- vCenter Server
- Enterprise Plus licenc
- vMotion szükséges az automatikus terheléselosztáshoz
Bővebben: A vSphere DRS fürt konfigurálása
VMware DRS műveletei
A VMware DRS ötpercenként futtat egy vSphere fürtön, és meghatározza, hogy vannak-e kiegyensúlyozatlanságok a fürtben. Ha igen, akkor vMotion műveletet hajt végre a kijelölt VM-ek egyik ESXi hosztról a másikra történő áthelyezésére.
Hogyan határozza meg pontosan a DRS, hogy a virtuális gépek jobban illenek-e az egyik vagy a másik ESXi hosztra?
A DRS egy speciális algoritmust futtat annak meghatározására, hogy melyik ESXi hoszt a megfelelő, ahol egy adott VM-nek helyet kell kapnia. A VM bekapcsolásakor ez az algoritmus figyelembe veszi az erőforrások eloszlását a vSphere Clusterben, miután biztosítja, hogy nem történik korlátozások megsértése, ha egy adott VM egy adott ESXi hostra kerül.
Emellett magának a VM-nek az igényét is figyelembe veszi, így a VM remélhetőleg soha nem fog erőforrás-hiányban szenvedni, amikor bekapcsolják. Mit tartalmaz a VM igénye? A VM igénye magában foglalja a futtatáshoz szükséges erőforrások mennyiségét.
- A CPU-igény esetében ez a VM által jelenleg elfogyasztott CPU mennyisége alapján kerül kiszámításra
- A memória esetében az igény a következő képlet alapján kerül kiszámításra: A VM memóriaigénye = Function(Active memory used, Swapped, Shared) + 25% (idle consumed memory). Ez azt mutatja, hogy a DRS memóriaegyensúlya elsősorban a VM aktív memóriahasználatán alapul, miközben figyelembe vesz egy kis mennyiséget az üresen fogyasztott memóriából a munkaterhelés esetleges növekedése miatt.
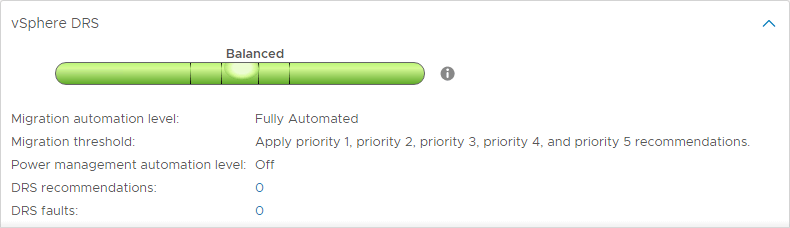
DRS automatizálási szintek
A DRS egyik érdekes jellemzője a DRS automatizálási szintek. Miközben a DRS továbbra is vizsgálja a vSphere Cluster-t és 5 percenként ajánlásokat tesz, meghatározhatja, hogy a DRS képes-e automatikusan végrehajtani az ajánlásait, vagy csak javaslatot tesz a végrehajtandó változtatásokra. A DRS-nek három DRS-automatizálási szintje van. Ezek a következők:
- Teljesen automatizált – A teljesen automatizált megközelítésben a DRS mind a kezdeti elhelyezési, mind a terheléselosztási ajánlásokat automatikusan alkalmazza
- Részlegesen automatizált – Részleges automatizálás esetén a DRS csak a VM-ek kezdeti elhelyezésére vonatkozó ajánlásokat alkalmazza
- Kézi – Kézi üzemmódban, mind a kezdeti elhelyezési, mind a terheléselosztási ajánlásokat alkalmaznia kell
DRS migrációs küszöbértékek
A DRS tartalmaz egy másik nagyon hasznos beállítást, amellyel szabályozható a DRS-ajánlások előtt tolerált kiegyensúlyozatlanság mértéke. Öt DRS migrációs küszöbérték áll rendelkezésre a tolerált kiegyensúlyozatlanság mértékének szabályozására.
A tartomány 1-től (legkonzervatívabb) 5-ig (legagresszívabb) terjed.
Agresszívabb beállítások esetén a DRS kevesebb kiegyensúlyozatlanságot tolerál a fürtben. Minél konzervatívabb, annál jobban tolerálja a DRS az egyensúlytalanságot.

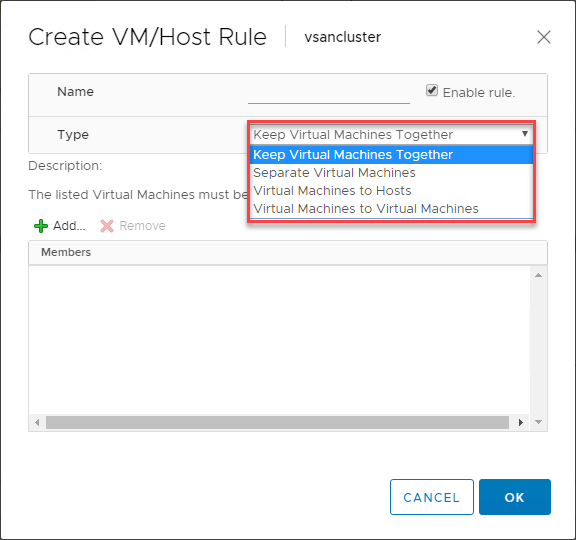
VMware DRS VM/Host szabályok
A VMware DRS használatakor egy rendkívül hasznos funkciót találunk a VM-ek vSphere DRS-képes fürtökben való elhelyezésének szabályozására. A VM/Host szabályok lehetővé teszik bizonyos VM-ek futtatását bizonyos ESXi hostokon. Ezt úgy is elképzelheti, mint affinitási szabályokat bizonyos értelemben.
A VM/Host szabályok lehetővé teszik:
- A virtuális gépek együtt tartását
- A virtuális gépek elkülönítését
- A virtuális gépek meghatározott hosztokhoz kötését
- A virtuális gépek virtuális gépekhez kötését
Az alábbiakban egy példa látható a virtuális gépek és ESXi hosztok VM/Host szabályának létrehozására.
Milyen típusú felhasználási eset létezik ezekre a VM/Host szabályokra? Az egyik létező klasszikus felhasználási eset a tartományvezérlőkkel kapcsolatos. Általánosságban elmondható, hogy ha az összes tartományvezérlőt virtualizált környezetben, például egy vSphere fürtben futtatja, akkor biztosítani szeretné, hogy a tartományvezérlő virtuális gépei elkülönüljenek egymástól a fürtön belül. Ily módon, ha egy ESXi állomás az egyik tartományvezérlőjével együtt leáll, még mindig van egy tartományvezérlője, amelyre vonatkozik a Separate Virtual Machines szabály, amely távol tartja egy másik DC-vel azonos állomáson.
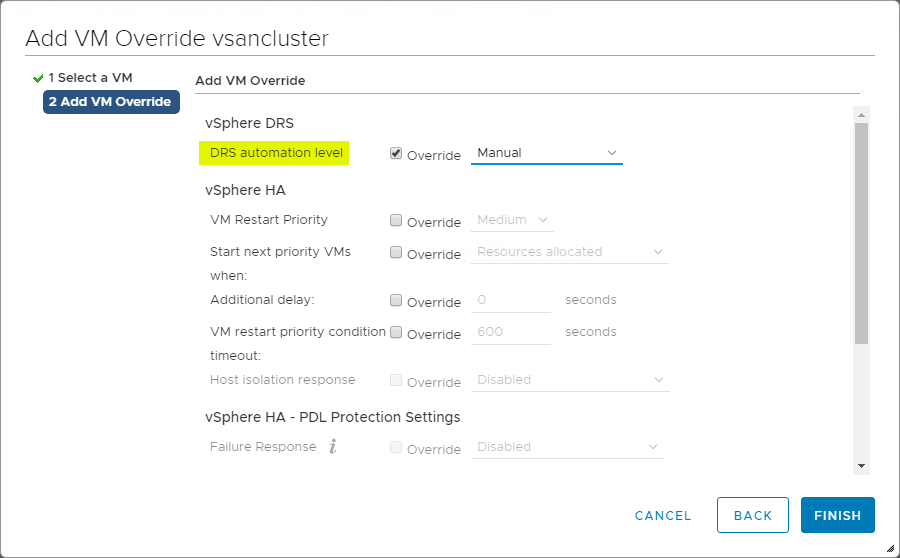
VM Overrides for DRS
A vSphere Cluster nagyfokú granularitást biztosít a vSphere Cluster-en belüli egyes VM-eket érintő műveletekhez. Létrehozhat VM-felülbírálásokat a HA és a DRS klaszterszinten beállított globális beállításainak felülírására, hogy specifikusabb beállításokat határozzon meg az egyes VM-ekre vonatkozóan.
CPU- és memóriahasználati összefoglaló
A DRS nagyszerű magas szintű áttekintést nyújt a vSphere Clusterben lévő ESXi hosztok CPU-erőforrásainak CPU-használati összefoglalójáról. Navigáljon a > Beállítások > Monitor > vSphere DRS > CPU-kihasználtság.
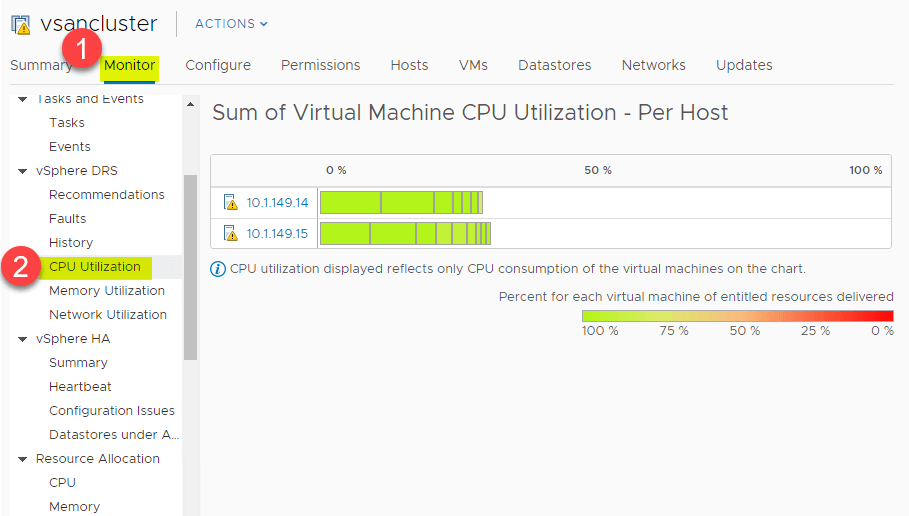
Ez a magas szintű áttekintés a memóriafogyasztásra is megtekinthető. Navigáljon a > Beállítások > Monitor > vSphere DRS > Memória kihasználtság
A két világ legjobbja
A VMware vSphere HA és a VMware DRS konkurens technológiák?
Nem, nem azok. Valójában erősen ajánlott a vSphere HA és a VMware DRS együttes használata, hogy az automatikus üzemzavar-átvételt a terheléselosztási funkciókkal és funkciókkal kombináljuk. Ez sokkal rugalmasabb és kiegyensúlyozottabb vSphere-környezetet eredményez.
Egy ESXi hoszt meghibásodása esetén a vSphere HA újraindítja a VM-eket a vSphere Clusterben megmaradt egészséges hosztokon. Az első számú prioritás tehát természetesen a virtuális gépek erőforrásainak rendelkezésre állása. A VMware DRS ezután lefut, és megállapítja, hogy a munkaterheket futtató ESXi hosztok között van-e egyensúlyhiány, és a konfigurált migrációs küszöbérték alapján ajánlásokat tesz a fürtön belüli egyensúlyhiány feloldására. Az automatizálási szint alapján ezeket az ajánlásokat vagy automatikusan végrehajtja, vagy csak ajánlást tesz, ha nem teljesen automatizált.
Végső gondolatok a VMware vSphere HA-ról és a DRS-ről
A VMware vSphere HA és a DRS futtatása egyaránt erősen ajánlott egy termelő vSphere fürtben. Mindkét technológia használata segít a munkaterhelések magas rendelkezésre állásában, és biztosítja, hogy a VM CPU/memória igényei alapján folyamatosan rendelkezzenek a szükséges erőforrásokkal.
A két mechanizmus működésének megismerése segít Önnek vSphere rendszergazdaként mindkét technológiát a lehető legjobban és a legjobb gyakorlatoknak megfelelően kihasználni. A két technológia előnyei közé tartozik, hogy mindegyik funkció rendkívül könnyen engedélyezhető és konfigurálható. A vSphere-klaszterek tulajdonságaiban néhány egyszerű kattintással gyorsan elkezdheti kihasználni ezeket az elérhető klaszterszintű funkciókat.
Kövesse Twitter és Facebook hírfolyamunkat az új kiadásokért, frissítésekért, tanulságos bejegyzésekért és még sok másért.