Las proteínas ancladas a GPI son el hombre extraño. En la introducción a la Biología Celular, nos enseñaron que había cinco tipos de proteínas de membrana, denominadas de la siguiente manera: Tipo I, Tipo II, Tipo III, Tipo IV y ancladas a GPI. ¿Por qué tenemos esta extraña clase de proteínas fusionadas a una cadena de azúcar y grasa? ¿Qué hacen? ¿Podemos obtener alguna información sobre mi proteína de interés – la PrP – aprendiendo más sobre esta clase de proteínas de la que es miembro?
Sonia y yo y nuestro compañero de equipo Andrew y hemos estado leyendo algo sobre este tema y estoy escribiendo esta entrada del blog para compartir algo de lo que hemos aprendido.
lectura
Comenzamos leyendo algunas revisiones . Estas cubrían sobre todo la estructura y la biogénesis del anclaje GPI en sí, sobre el que se sabe una barbaridad.
Este anclaje, cuyo nombre completo es glucosilfosfatidilinositol, no es un monolito: es una descripción general de una molécula cuyos detalles pueden variar. En general, a partir del residuo ω (último residuo postraduccional) de la proteína, se tiene una etanolamina, luego un fosfato, luego algunos azúcares, luego un fosfolípido. El núcleo del azúcar se conserva, pero las cadenas laterales que se ramifican a partir de él pueden variar, y el grupo principal del fosfolípido y los ácidos grasos también pueden variar. El anclaje GPI de la PrP se caracterizó en , pero incluso entonces no es un monolito – identificaron al menos seis estructuras diferentes que difieren en la composición de la cadena lateral de azúcar.
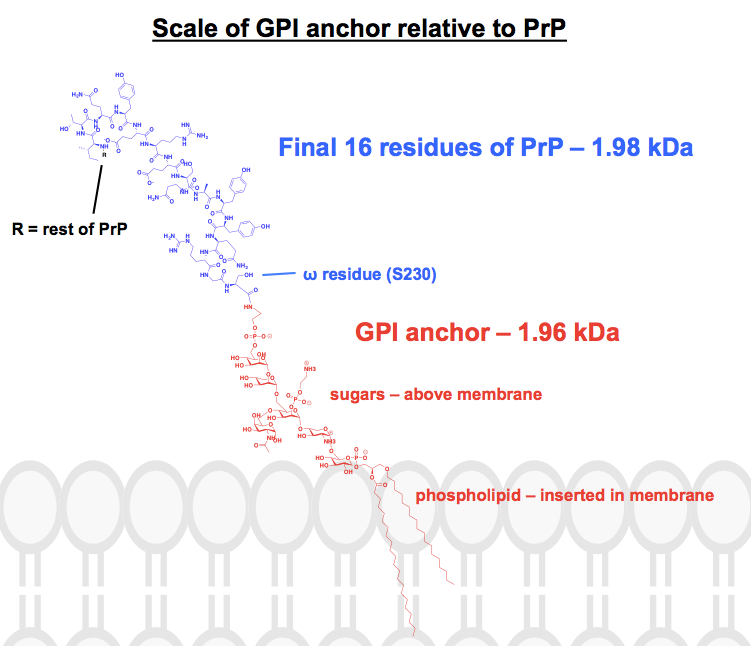
Todas las estructuras químicas que he encontrado de los anclajes GPI tienen al menos algunas partes abreviadas o resumidas, y la proteína suele mostrarse simplemente como una imagen. Quería tener una idea de cómo son estos anclajes desde el punto de vista químico, en el contexto de las proteínas a las que están unidos, así que me propuse dibujar una estructura completa en ChemDraw. A partir de la Figura 1 -lo más parecido a una estructura esquelética completa que pude encontrar- añadí los detalles de uno de los anclajes GPI de la PrP del panel superior de la Figura 6. El peso molecular era de 1.958 Da, así que para contextualizarlo dibujé los últimos 16 residuos de la HuPrP23-230, que pesan comparativamente 1.979 Da. Esto es aproximadamente el 8% de la secuencia modificada postraduccionalmente de la PrP. No estoy seguro de haber acertado con todos los enlaces, pero esto es lo que se me ocurrió:
En muchos casos, un gen tiene múltiples isoformas, con un producto de empalme que da lugar a una proteína anclada a la GPI mientras que otros dan lugar a formas secretadas o transmembrana. Algunos ejemplos son NCAM1, que tiene tres isoformas principales, una de las cuales está anclada a la GPI y las otras dos son transmembrana, y ACHE (que codifica la acetilcolinesterasa), cuya forma anclada a la GPI se encuentra aparentemente sólo en los glóbulos rojos (NCBI Genes). La historia más fascinante es la del gen Ly6a del ratón que, gracias a un polimorfismo genético, está anclado a la GPI en algunas cepas de ratón y no en otras. Sólo en su forma anclada a la GPI, actúa como receptor del vector viral AAV PHP.eB . (Este vector logra una captación asombrosamente eficiente en las neuronas del cerebro para la terapia génica , pero lamentablemente, es un gen de ratón solamente – nosotros los humanos ni siquiera tenemos Ly6a).
Se sabe mucho sobre cómo se sintetizan los anclajes GPI y se unen a las proteínas , con >20 proteínas implicadas en la vía, la mayoría de las cuales comienzan con el prefijo «PIG» y están codificadas por genes como PIGA, PIGK, etc. – véase la Figura 2 para un diagrama. La mayor parte de la biosíntesis tiene lugar con el anclaje insertado en la membrana en el RE pero sin estar unido a ninguna proteína. De hecho, los primeros pasos tienen lugar en el prospecto citosólico de la membrana, y sólo después el ancla se vuelca hacia el lado lumenal (dentro del RE). El último paso es cuando la transamidasa GPI, un complejo formado por al menos cinco proteínas, escinde la señal GPI del extremo C de la proteína y une el anclaje GPI al llamado residuo ω de la proteína (el último residuo de la secuencia modificada postraduccionalmente). A continuación, se produce una mayor maduración del anclaje GPI a medida que la proteína migra fuera del RE hacia la superficie celular.
Existen varios inhibidores de moléculas pequeñas de la biosíntesis de GPI en los hongos, algunos de los cuales se han intentado desarrollar como fármacos antifúngicos, pero, por lo que he podido comprobar, el único inhibidor conocido de la biosíntesis de GPI en las células de mamíferos es la mannosamina, un análogo de la manosa que es químicamente incompatible con la incorporación a la GPI.
Busqué y busqué un logotipo de secuencia de qué motivo de secuencia de aminoácidos reconoce la GPI transamidasa, pero no encontré ninguno. Aparentemente el motivo de la secuencia es bastante flojo , y aparentemente las señales de GPI ni siquiera son homólogas , lo que significa que no evolucionaron a partir de una secuencia ancestral común, sino que evolucionaron de forma convergente, en la medida en que hay incluso alguna convergencia. La mejor descripción que he podido encontrar es que (leyendo de N a C-terminal hasta el final de la proteína) se necesitan 1) unos 11 residuos de un enlazador no estructurado, 2) unos pocos residuos con pequeñas cadenas laterales incluyendo un residuo ω que puede ser S, N, D, G, A, o C, 3) un espaciador de 5-10 aminoácidos polares, y finalmente 4) 15-20 aminoácidos hidrofóbicos . La PrP sigue vagamente este motivo. Según las estructuras publicadas, la hélice alfa 3 termina en el residuo Q223, lo que deja el «enlazador no estructurado» como sólo AYYQR (algo más corto que los 11 residuos prescritos). La región de la ‘cadena lateral pequeña’ sería GS|SM (con el tubo denotando el sitio de corte de la transamidasa), la región polar sería VLFSSPP, y el extremo C hidrofóbico como VILLISFLIFLIVG.
Algunas de las proteínas de la vía de biosíntesis y fijación de GPI son muy importantes, y se han descrito varias enfermedades graves y síndromes de deficiencia de anclaje de GPI, debido a mutaciones biállicas de pérdida de función o aparentemente hipomórficas de sentido erróneo en genes como PIGO, PIGV, PIGW, PGAP2 y PGAP3 .
Sonia encontró un excelente artículo de hace unos años en el que hicieron un cribado de mutagénesis en células humanas haploides para identificar los genes necesarios para la biogénesis de dos proteínas ancladas a la GPI: PrP y CD59 . Utilizaron repetidas clasificaciones FACS de células basadas en la superficie celular de la PrP y la CD59 con el fin de identificar las células con niveles de superficie drásticamente reducidos de estas proteínas, y luego hicieron la secuenciación para ver qué mutaciones genéticas estaban enriquecidas en esas células frente a la población madre. Como era de esperar, la mayoría de los genes PIG aparecieron para ambas proteínas (Figura 4), pero no todos los resultados se superpusieron, lo que es un poco sorprendente, sobre todo porque a nivel de ARN, al menos, la PrP y la CD59 son dos de las proteínas con los perfiles de expresión más similares en todos los tejidos (véase el mapa de calor al final de este post). Un grupo de enzimas implicadas en la modificación de la cadena lateral del ancla GPI sólo apareció para CD59, lo que sugiere que CD59, pero no PrP, necesita estas complejas cadenas laterales para madurar y alcanzar la superficie celular. Por su parte, Sec62 y Sec63 sólo aparecieron para la PrP: se trata de proteínas implicadas de alguna manera en la translocación cotraduccional al RE, pero aparentemente son necesarias para la PrP pero no para la CD59 ni para la CD55 o la CD109, otras dos proteínas de control que examinaron. Este es un nuevo y fascinante capítulo en la respuesta a mi pregunta, «¿hay algo especial en la expresión de la PrP?», en la que buscaba algo único sobre la biogénesis de la PrP que pudiera ser potencialmente atacable con una pequeña molécula. Por supuesto, el hecho de que estas proteínas no fueran importantes para otras tres proteínas de control en no significa que no sean importantes – un estudio encontró que Sec62 era necesario para la secreción de muchas proteínas pequeñas , y el gen SEC62 está totalmente agotado por variantes de pérdida de función en la población humana, lo suficiente como para sugerir la haploinsuficiencia. SEC63 parece menos restringido, aunque eso podría significar simplemente que actúa de forma recesiva.
Nada de lo anterior responde a la pregunta de por qué existen las proteínas ancladas a la GPI. Por cierto, mi antigua clase de biología celular omitió un detalle: en realidad hay una sexta clase de proteínas de membrana, llamadas proteínas ancladas a la cola (TA), que sólo tienen un extremo C hidrofóbico que se adhiere a la membrana pero no sobresale por el otro lado. ¿Por qué todas estas proteínas ancladas a la GPI no podrían ser simplemente proteínas TA? ¿Por qué las células evolucionaron una vía tan complicada para sintetizar un anclaje de azúcar y grasa en su lugar, y por qué lo hicieron tan temprano en el juego – los anclajes GPI están presentes en todos los eucariotas, incluso en muchos patógenos unicelulares que infectan a los seres humanos.
La mayoría de las revisiones no dedicaron mucho tiempo a esta pregunta, probablemente porque es lo más difícil de responder. Las propias proteínas ancladas a la GPI, en la medida en que se conocen sus funciones nativas, tienen una enorme variedad de funciones: hay enzimas (como la AChE), moléculas de adhesión celular (como la NCAM1), proteínas que regulan el complemento en el sistema inmunitario (CD59), etc. . Al parecer, hay al menos una proteína anclada a GPI que participa en el mantenimiento de la mielina en los nervios periféricos. Pero, ¿qué pueden hacer exactamente las proteínas ancladas a la GPI que no puedan hacer otras proteínas? Una revisión cita algunas ideas que se han propuesto. Una de ellas es que las proteínas ancladas a GPI son buenas para dimerizar transitoriamente. Algunos estudios han explorado la idea de que la homodimerización desempeña algún papel en la biología de los priones, aunque la relevancia de los sistemas modelo utilizados allí para la situación in vivo aún no está clara. Otra idea es que, dado que las proteínas ancladas a la GPI pueden desprenderse de la superficie celular, por ejemplo mediante la enzima convertidora de angiotensina (ECA), su localización puede estar regulada de alguna manera dinámica. En este caso también sabemos que la PrP puede desprenderse, aparentemente por la enzima ADAM10 , aunque todavía no está claro su papel en la función nativa de la PrP. Una tercera idea, y quizás la que más he escuchado, es que las proteínas ancladas a la GPI se congregan selectivamente en «balsas lipídicas». Esta es quizás la explicación más atractiva, porque se podría imaginar todo tipo de efectos en cadena, donde el aumento de la concentración local efectiva de estas proteínas permite más interacciones, y así sucesivamente. Pero una revisión señaló que una advertencia es que las balsas de lípidos son todavía más una idea abstracta que una cosa concreta – mientras que se definen funcionalmente por la insolubilidad del detergente y la mayoría de la gente los describe como ricos en esfingomielina y colesterol, no hay ninguna definición universalmente aceptada de lo que es y no es una balsa de lípidos, y la evidencia empírica sugiere que pueden ser mucho más pequeños y más transitorios que la mayoría de la gente piensa.
Con esa lectura en la mano, me propuse conseguir una lista de estas proteínas y hacer algunos análisis sobre ellas para ver si podía tener una mejor idea de cómo son.
análisis
Uniprot tiene una lista de 173 proteínas humanas ancladas a GPI. Estos mapeados a 140 símbolos de genes, que se redujo a 135 después de ejecutar esta secuencia de comandos para actualizar a los símbolos de genes de codificación de proteínas actualmente aprobados por HGNC. La lista final de 135 símbolos genéticos está aquí.
Uniprot no ofrece ninguna información sobre cómo se generaron sus anotaciones, aunque debe haber un grado significativo de curación manual. A modo de comparación, Andrew también desenterró una serie de trabajos que utilizaban PI-PLD o PI-PLC, dos enzimas que escinden los anclajes GPI, para aislar empíricamente las proteínas ancladas a GPI de las células. Combinando las listas de estos artículos y mapeando con los símbolos genéticos actuales se obtuvieron 107 genes. Comprobamos varios de ellos al azar. Entre ellos había proteínas ancladas a la GPI bien conocidas, como el glicano-1 (GPC1) y la molécula de adhesión celular neural (NCAM1), de las que se ha informado que tienen interacciones con la PrP. Pero también estaban presentes varios genes para los que no parecía conocerse ningún anclaje GPI en la literatura, como VDAC3, algunos de los cuales pueden ser simplemente proteínas muy abundantes o falsos positivos por otras razones. Mientras tanto, hay fuentes obvias de falsos negativos: genes que simplemente no se expresaban en la línea celular estudiada, o que no eran lo suficientemente abundantes como para ser recogidos por el espectro de masas, y los paralogos de la PrP, SPRN y PRND, no estaban en las listas. En general, 51 genes estaban en ambas listas, un enriquecimiento altamente significativo (OR = 217, P < 1 × 10-84), lo que me ayuda a asegurar que las anotaciones de Uniprot son consistentes con los datos empíricos. Pero para los análisis posteriores decidimos ir con la lista de Uniprot, ya que parece más sensible y específica.
Armado con esta lista, quería ver cómo las proteínas ancladas a la GPI se apilan. La PrP es una proteína de un solo exón, corta (208 aminoácidos en su forma madura), no esencial y de amplia expresión. ¿Son estas características típicas o atípicas para una proteína anclada a la GPI?
Resulta que las proteínas ancladas a la GPI están por todo el mapa, son tan variables en cada dimensión que miré como cualquier otro conjunto de proteínas.
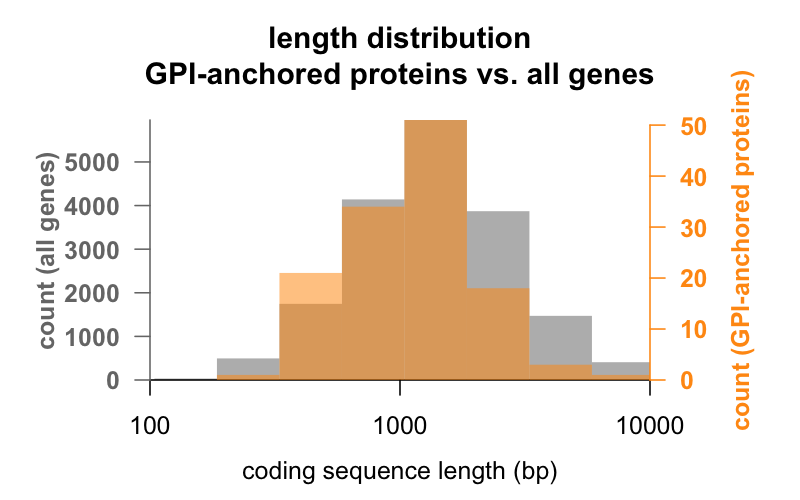
Primero, la longitud. A continuación se superponen los histogramas de la longitud de la secuencia de codificación en pares de bases para todos los genes, frente a los genes que codifican proteínas ancladas a GPI. La distribución anclada a la GPI está apenas desplazada a la izquierda. El gen medio de la proteína anclada a la GPI tiene 1.301 pb de secuencia codificante, mientras que el gen medio tiene 1.729, pero esta diferencia de medias es pequeña comparada con la variación dentro de cada grupo. La PrP, con sólo 762 pb de secuencia codificante, está definitivamente en el lado pequeño, aunque de ninguna manera es un valor atípico en ninguno de los grupos – CD52, con sólo 186 pares de bases de secuencia y aparentemente sólo 12 aminoácidos en su forma madura, es la proteína anclada a la GPI más pequeña.
¿Qué hay del número de exones? Las proteínas ancladas a la GPI tienen una media de exones ligeramente inferior a la de todos los genes (media de 7,8 frente a 10,1), en consonancia con la ligera diferencia de distribución de la longitud señalada anteriormente, pero la mayoría son multiexones. Aquí, también, la PrP está en el lado pequeño: sólo hay seis proteínas ancladas a la GPI que tienen sólo un exón de codificación, y tres de ellas son la PrP y sus dos paralogos, Sho y Dpl. (Los otros tres genes son GAS1, SPACA4, y el fabulosamente llamado OMG).
Luego miré la restricción de pérdida de función. La restricción es una medida de la fuerza de la selección natural a la que está sometido un gen, basada en la disminución de, por ejemplo, las variaciones sin sentido, los cambios de marco y los sitios de empalme en la población general, en comparación con las expectativas basadas en las tasas de mutación. Esta métrica no es muy interpretable para los genes cortos, tanto por razones estadísticas (el número de mutaciones esperadas es bajo para los genes cortos, por lo que es difícil cuantificar el agotamiento) como por razones biológicas (los genes de un solo exón no están sujetos a la decadencia mediada por el sinsentido, por lo que es más difícil saber si las variantes que truncan la proteína son realmente «pérdida de función» o no). Pero como la mayoría de las proteínas ancladas a la GPI no son tan cortas como la PrP, pensé que merecía la pena echar un vistazo. El resultado: por término medio, las proteínas ancladas a la GPI están ligeramente menos limitadas, lo que significa que tienen más de su cantidad esperada de variación de pérdida de función, que el gen medio. El gen medio tiene el 47% de su variación de pérdida de función, y las proteínas ancladas a la GPI tienen el 56%. Pero como en todo esto, hay una amplia distribución en ambos campos. En el caso de las proteínas ancladas a la GPI, tenemos el absolutamente restringido ACHE (17 LoFs esperados y ninguno observado) en un extremo y, en el otro extremo, varios genes que parecen no estar bajo selección contra la pérdida de función en absoluto – CNTN6, CD109, TREH, y MSLN son algunos ejemplos. PRNP cae en el último campo una vez que se excluyen los residuos ≥145 donde las variantes de truncamiento de la proteína causan una ganancia de función.
Por último, me pregunté dónde se expresan las proteínas ancladas a la GPI. PRNP es más alto en el cerebro, pero se expresa en todas partes. ¿Es esto típico? Descargué el archivo de resumen completo de GTEx v7 «gene median tpm» (15 de enero de 2016), donde cada fila es un gen y cada columna es un tejido y las celdas son RPKMs – lecturas de RNA-seq por kilobase de exón por millón de lecturas mapeadas. Trabajar con este conjunto de datos requirió algunos ajustes. He oído que algunos bioinformáticos consideran que <1 RPKM es «no expresado», pero la matriz de expresión es escasa -la mayoría de los genes no se expresan mucho en la mayoría de los tejidos-, por lo que el ruido por debajo de 1 RPKM puede dominar si sólo se representan los RPKM en bruto. Mientras tanto, la expresión de los genes es algo que hay que pensar en una escala logarítmica, ya que los genes en un tejido pueden variar de <1 RPKM a >10.000 RPKM, por lo que si se considera todo en una escala lineal, entonces las pocas combinaciones de genes/tejidos muy expresados también pueden dominar, haciendo que la matriz parezca aún más escasa de lo que es. Por lo tanto, tomé el logaritmo 10 de la matriz y trunqué la distribución en , por lo que la escala púrpura que utilicé corre 1 – 10 – 100 – 1.000 – 10.000 RPKM. Luego hice un subconjunto de las proteínas ancladas a la GPI de Uniprot. Para visualizar esto, hice un mapa de calor por primera vez en mi vida. A menudo he visto estos en los documentos y por lo general no me hablan, pero aquí mi objetivo era sólo para tener una idea del patrón de expresión, y después de jugar un poco, esto fue lo que me dio la mayor comprensión. El principio de un mapa de calor es que las filas y las columnas se agrupan para que las cosas similares vayan juntas. Así, por ejemplo, todas las columnas del tejido cerebral están alineadas consecutivamente en un parche en el eje x, y todos los genes altamente expresados en el cerebro están alineados consecutivamente en un parche en el eje y, de modo que su intersección forma un denso rectángulo púrpura que puede interpretarse como «existe un grupo de genes que se expresan principalmente en el cerebro».
Los lectores interesados pueden ver el PDF de arte vectorial a escala completa del mapa de calor, pero para hacerlo más inmediatamente accesible, aquí hay una versión anotada a mano que señala los grupos de interés:

La respuesta, entonces, es no – la mayoría de las proteínas ancladas a la GPI no tienen el mismo patrón de expresión que la PRNP. La PRNP es una de las que se expresan más ampliamente y en mayor medida, y aparece cerca de la parte superior de este mapa de calor, junto con la CD59, la LY6E, la GPC1 y la BST2. La mayoría de las proteínas ancladas a la GPI tienen una expresión menor o más restringida a los tejidos, con algunas que se expresan casi exclusivamente en el cerebro y otras que no se expresan casi exclusivamente en el cerebro, y otros grupos más pequeños que pertenecen principalmente a tejidos específicos como los testículos, como el paralogismo de la PrP, la PRND, cuyo knockout causa esterilidad masculina.
conclusiones
Las proteínas ancladas a GPI pueden tener casi cualquier tamaño, expresarse en casi cualquier tejido y, aparentemente, tener casi cualquier función, en la medida en que se conocen sus funciones. Muchas proteínas ancladas a GPI tienen funciones nativas muy claras, pero estas funciones son diversas y no está claro por qué requieren el anclaje a GPI, especialmente porque muchas de estas proteínas existen también en isoformas no ancladas a GPI. Mientras tanto, en el caso de otras proteínas ancladas a GPI, incluida la PrP, sabemos muy poco sobre la función nativa para empezar, por lo que es difícil incluso especular por qué la función nativa requiere el anclaje a GPI. Ninguno de los análisis que realicé o las revisiones que leí fueron capaces de extraer un principio unificador de por qué existe este mecanismo de anclaje o qué hace que estas proteínas lo requieran. Hay una serie de hipótesis sobre el motivo por el que las proteínas ancladas a GPI son únicas, como las balsas lipídicas, los homodímeros y el desprendimiento. Todas estas hipótesis pueden ser válidas. Pero al final, la respuesta parece poco probable que sea un momento eureka, sino más bien, como gran parte de la biología, una prosaica mezcla de cosas diferentes.
El código R y los archivos de datos en bruto para los análisis de este post están aquí.