
Antes de empezar este viaje de intentar aprender ciencias de la computación, había ciertos términos y frases que me hacían querer correr en otra dirección.
Pero en lugar de correr, fingía conocerlos, asintiendo en las conversaciones, fingiendo que sabía a qué se refería alguien aunque la verdad era que no tenía ni idea y había dejado de escuchar por completo cuando oía That Super Scary Computer Science Term™. A lo largo de esta serie, me las he arreglado para cubrir un montón de terreno y muchos de esos términos se han convertido en mucho menos aterrador!
Hay uno grande, sin embargo, que he estado evitando por un tiempo. Hasta ahora, cada vez que había escuchado este término, me sentía paralizado. Ha surgido en conversaciones casuales en reuniones y a veces en charlas de conferencias. Cada vez, pienso en máquinas girando y ordenadores escupiendo cadenas de código que son indescifrables, excepto que todos los demás a mi alrededor pueden descifrarlas, así que en realidad soy yo quien no sabe lo que está pasando (¡vaya, cómo ha ocurrido esto!).
Quizás no soy el único que se ha sentido así. Pero, supongo que debería contaros qué es realmente este término, ¿no? Pues prepárate, porque me refiero al siempre esquivo y aparentemente confuso árbol de sintaxis abstracta, o AST para abreviar. ¡Después de muchos años de estar intimidado, estoy emocionado por dejar de tener miedo de este término y entender realmente lo que es.
Es hora de enfrentarse a la raíz del árbol de sintaxis abstracta de frente – y subir de nivel nuestro juego de análisis sintáctico!
Toda buena búsqueda comienza con una base sólida, y nuestra misión de desmitificar esta estructura debería comenzar exactamente de la misma manera: ¡con una definición, por supuesto!
Un árbol de sintaxis abstracto (normalmente denominado simplemente AST) no es más que una versión simplificada y condensada de un árbol de análisis sintáctico. En el contexto del diseño de compiladores, el término «AST» se utiliza indistintamente con el árbol de sintaxis.

A menudo pensamos en los árboles de sintaxis (y cómo se construyen) en comparación con sus homólogos de árboles de parseo, con los que ya estamos bastante familiarizados. Sabemos que los árboles de análisis son estructuras de datos en forma de árbol que contienen la estructura gramatical de nuestro código; en otras palabras, contienen toda la información sintáctica que aparece en una «sentencia» de código, y se deriva directamente de la gramática del propio lenguaje de programación.
Un árbol de sintaxis abstracto, por otro lado, ignora una cantidad significativa de la información sintáctica que un árbol de análisis contendría.
Por el contrario, un AST sólo contiene la información relacionada con el análisis del texto fuente, y omite cualquier otro contenido extra que se utiliza mientras se analiza el texto.
Esta distinción empieza a tener mucho más sentido si nos centramos en la «abstracción» de un AST.
Recordemos que un árbol de análisis sintáctico es una versión ilustrada y pictórica de la estructura gramatical de una frase. En otras palabras, podemos decir que un árbol de análisis sintáctico representa exactamente el aspecto de una expresión, frase o texto. Es básicamente una traducción directa del propio texto; tomamos la frase y convertimos cada pedacito de ella -desde la puntuación hasta las expresiones y los tokens- en una estructura de datos en forma de árbol. Revela la sintaxis concreta de un texto, por lo que también se denomina árbol sintáctico concreto, o CST. Usamos el término concreto para describir esta estructura porque es una copia gramatical de nuestro código, token por token, en formato de árbol.
¿Pero qué hace que algo sea concreto frente a lo abstracto? Bueno, un árbol sintáctico abstracto no nos muestra exactamente cómo es una expresión, de la forma en que lo hace un árbol de análisis.

Más bien, un árbol de sintaxis abstracto nos muestra las partes «importantes» – las cosas que realmente nos importan, que dan significado a nuestra «sentencia» de código en sí. Los árboles sintácticos nos muestran las piezas significativas de una expresión, o la sintaxis abstracta de nuestro texto fuente. Por lo tanto, en comparación con los árboles de sintaxis concretos, estas estructuras son representaciones abstractas de nuestro código (y en cierto modo, menos exactas), que es exactamente como obtuvieron su nombre.
Ahora que entendemos la distinción entre estas dos estructuras de datos y las diferentes formas en que pueden representar nuestro código, vale la pena hacer la pregunta: ¿dónde encaja un árbol de sintaxis abstracto en el compilador? En primer lugar, recordemos todo lo que sabemos sobre el proceso de compilación tal y como lo conocemos hasta ahora.

Digamos que tenemos un texto fuente súper corto y dulce, que tiene este aspecto: 5 + (1 x 12).
Recordaremos que lo primero que ocurre en el proceso de compilación es el escaneo del texto, un trabajo realizado por el escáner, que tiene como resultado la división del texto en sus partes más pequeñas posibles, que se llaman lexemas. Esta parte será agnóstica al idioma, y terminaremos con la versión despojada de nuestro texto fuente.
A continuación, estos mismos lexemas se pasan al lexer/tokenizador, que convierte esas pequeñas representaciones de nuestro texto fuente en tokens, que serán específicos de nuestro idioma. Nuestros tokens serán algo así: . El esfuerzo conjunto del escáner y el tokenizador conforman el análisis léxico de la compilación.
Entonces, una vez que nuestra entrada ha sido tokenizada, sus tokens resultantes se pasan a nuestro analizador sintáctico, que entonces toma el texto fuente y construye un árbol de análisis sintáctico a partir de él. La siguiente ilustración ejemplifica el aspecto de nuestro código tokenizado, en formato de árbol de análisis sintáctico.
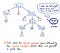
El trabajo de convertir los tokens en un árbol de análisis sintáctico también se llama análisis sintáctico, y se conoce como fase de análisis sintáctico. La fase de análisis sintáctico depende directamente de la fase de análisis léxico; por lo tanto, el análisis léxico debe venir siempre primero en el proceso de compilación, ¡porque el analizador sintáctico de nuestro compilador sólo puede hacer su trabajo una vez que el tokenizador hace su trabajo!
Podemos pensar en las partes del compilador como buenos amigos, que dependen unos de otros para asegurarse de que nuestro código se transforma correctamente de un texto o archivo en un árbol de análisis sintáctico.
Pero volvamos a nuestra pregunta original: ¿dónde encaja el árbol sintáctico abstracto en este grupo de amigos? Bueno, con el fin de responder a esa pregunta, ayuda a entender la necesidad de un AST en el primer lugar.
Condensación de un árbol en otro
Okay, así que ahora tenemos dos árboles para mantener recta en nuestras cabezas. Ya teníamos un árbol de análisis, ¡y cómo hay otra estructura de datos que aprender! Y aparentemente, esta estructura de datos AST es sólo un árbol de análisis simplificado. Entonces, ¿por qué la necesitamos? ¿Qué sentido tiene?
Bueno, echemos un vistazo a nuestro árbol de análisis sintáctico, ¿vale?
Ya sabemos que los árboles de análisis sintácticos representan nuestro programa en sus partes más distintas; de hecho, ¡ésta es la razón por la que el escáner y el tokenizador tienen un trabajo tan importante de descomponer nuestra expresión en sus partes más pequeñas!
¿Qué significa realmente representar un programa por sus partes más distintas?
Como resulta, a veces todas las partes distintas de un programa en realidad no son tan útiles para nosotros todo el tiempo.
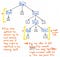
Echemos un vistazo a la ilustración que se muestra aquí, que representa nuestra expresión original, 5 + (1 x 12), en formato de árbol de parse. Si observamos detenidamente este árbol con ojo crítico, veremos que hay algunos casos en los que un nodo tiene exactamente un hijo, que también se denominan nodos de sucesor único, ya que sólo tienen un nodo hijo derivado de ellos (o un «sucesor»).
En el caso de nuestro ejemplo de árbol de análisis, los nodos de sucesor único tienen un nodo padre de un Expression, o Exp, que tienen un único sucesor de algún valor, como 5, 1, o 12. Sin embargo, los nodos padre Exp aquí no están añadiendo nada de valor para nosotros, ¿verdad? Podemos ver que contienen nodos hijos de tokens/terminales, pero realmente no nos interesa el nodo padre «expresión»; todo lo que queremos saber es ¿cuál es la expresión?
El nodo padre no nos da ninguna información adicional una vez que hemos analizado nuestro árbol. En cambio, lo que realmente nos interesa es el nodo hijo y sucesor. De hecho, ese es el nodo que nos da la información importante, la parte que es significativa para nosotros: ¡el número y el valor en sí! Teniendo en cuenta el hecho de que estos nodos padres son un poco innecesarios para nosotros, es obvio que este árbol de análisis es una especie de verborrea.
Todos estos nodos sucesores únicos son bastante superfluos para nosotros, y no nos ayudan en absoluto. Así que, ¡deshagámonos de ellos!
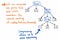
Si comprimimos los nodos sucesores únicos de nuestro árbol de análisis sintáctico, terminaremos con una versión más comprimida de la misma estructura exacta. Si observamos la ilustración anterior, veremos que seguimos manteniendo exactamente el mismo anidamiento que antes, y nuestros nodos/tokens/terminales siguen apareciendo en el lugar correcto dentro del árbol. Pero, hemos logrado reducirlo un poco.
Y también podemos recortar algo más de nuestro árbol. Por ejemplo, si miramos nuestro árbol de análisis sintáctico tal y como está en este momento, veremos que hay una estructura de espejo dentro de él. La sub-expresión de (1 x 12) está anidada dentro de los paréntesis (), que son tokens por derecho propio.
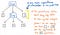
Sin embargo, estos paréntesis no nos ayudan realmente una vez que tenemos nuestro árbol. Ya sabemos que 1 y 12 son argumentos que se pasarán a la operación de multiplicación x, así que los paréntesis no nos dicen mucho en este punto. De hecho, podríamos comprimir nuestro árbol de análisis sintáctico aún más y deshacernos de estos nodos hoja superfluos.
Una vez que comprimimos y simplificamos nuestro árbol de análisis sintáctico y nos deshacemos del «polvo» sintáctico superfluo, acabamos con una estructura que parece visiblemente diferente en este punto. Esa estructura es, de hecho, nuestro nuevo y esperado amigo: el árbol sintáctico abstracto.

La imagen de arriba ilustra exactamente la misma expresión que nuestro árbol de análisis: 5 + (1 x 12). La diferencia es que se ha abstraído la expresión de la sintaxis concreta. No vemos más paréntesis () en este árbol, porque no son necesarios. Del mismo modo, no vemos los no-terminales como Exp, ya que hemos averiguado lo que es la «expresión», y somos capaces de sacar el valor que realmente nos importa – por ejemplo, el número 5.
Este es exactamente el factor distintivo entre un AST y un CST. Sabemos que un árbol sintáctico abstracto ignora una cantidad significativa de la información sintáctica que contiene un árbol de análisis, y omite el «contenido extra» que se utiliza en el análisis sintáctico. Pero ahora podemos ver exactamente cómo sucede eso!

Ahora que hemos condensado un árbol de análisis sintáctico propio, seremos mucho más capaces de captar algunos de los patrones que distinguen un AST de un CST.
Hay algunas formas en las que un árbol de sintaxis abstracta se diferenciará visualmente de un árbol de análisis sintáctico:
- Un AST nunca contendrá detalles sintácticos, como comas, paréntesis y punto y coma (dependiendo, por supuesto, del lenguaje).
- Un AST tendrá una versión colapsada de lo que de otro modo aparecería como nodos de un solo sucesor; nunca contendrá «cadenas» de nodos con un solo hijo.
- Finalmente, cualquier token operador (como
+,-,x, y/) se convertirá en nodos internos (padres) en el árbol, en lugar de las hojas que terminan en un árbol de parse.
Visualmente, un AST siempre parecerá más compacto que un árbol de parse, ya que es, por definición, una versión comprimida de un árbol de parse, con menos detalles sintácticos.
Es lógico, entonces, que si un AST es una versión compactada de un árbol de parseo, ¡sólo podemos crear realmente un árbol de sintaxis abstracto si tenemos las cosas para construir un árbol de parseo para empezar!
Así es, de hecho, como el árbol de sintaxis abstracto encaja en el proceso de compilación más amplio. Un AST tiene una conexión directa con los árboles de parseo que ya hemos aprendido, mientras que simultáneamente depende del lexer para hacer su trabajo antes de que un AST pueda ser creado.

El árbol sintáctico abstracto se crea como resultado final de la fase de análisis sintáctico. El analizador sintáctico, que está al frente y al centro como el «personaje» principal durante el análisis sintáctico, puede o no generar siempre un árbol de análisis sintáctico, o CST. Dependiendo del propio compilador, y de cómo haya sido diseñado, el analizador sintáctico puede pasar directamente a construir un árbol sintáctico, o AST. Pero el analizador sintáctico siempre generará un AST como su salida, sin importar si crea un árbol de análisis sintáctico en el medio, o cuántas pasadas pueda necesitar para hacerlo.
Anatomía de un AST
Ahora que sabemos que el árbol sintáctico abstracto es importante (¡pero no necesariamente intimidante!), podemos empezar a diseccionarlo un poco más. Un aspecto interesante sobre cómo se construye el AST tiene que ver con los nodos de este árbol.
La imagen siguiente ejemplifica la anatomía de un solo nodo dentro de un árbol de sintaxis abstracta.
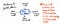
Notaremos que este nodo es similar a otros que hemos visto antes en el sentido de que contiene algunos datos (un token y su value). Sin embargo, también contiene algunos punteros muy específicos. Cada nodo de un AST contiene referencias a su siguiente nodo hermano, así como a su primer nodo hijo.
Por ejemplo, nuestra simple expresión de 5 + (1 x 12) podría construirse en una ilustración visualizada de un AST, como la siguiente.

Podemos imaginar que la lectura, el recorrido o la «interpretación» de este AST podría comenzar desde los niveles inferiores del árbol, trabajando hacia atrás para construir un valor o un retorno resultal final.
También puede ayudar ver una versión codificada de la salida de un analizador sintáctico para ayudar a complementar nuestras visualizaciones. Podemos apoyarnos en varias herramientas y utilizar analizadores preexistentes para ver un ejemplo rápido de cómo podría ser nuestra expresión cuando se ejecuta a través de un analizador. A continuación se muestra un ejemplo de nuestro texto fuente, 5 + (1 * 12), ejecutado a través de Esprima, un analizador sintáctico de ECMAScript, y su árbol de sintaxis abstracta resultante, seguido de una lista de sus distintos tokens.
En este formato, podemos ver el anidamiento del árbol si nos fijamos en los objetos anidados. Notaremos que los valores que contienen 1 y 12 son los left y right hijos, respectivamente, de una operación padre, *. También veremos que la operación de multiplicación (*) constituye el subárbol derecho de toda la expresión en sí, por lo que está anidada dentro del objeto mayor BinaryExpression, bajo la clave "right". Del mismo modo, el valor de 5 es el único "left" hijo del objeto mayor BinaryExpression.

El aspecto más intrigante del árbol de sintaxis abstracta es, sin embargo, el hecho de que aunque sean tan compactos y limpios, no siempre son una estructura de datos fácil de intentar construir. De hecho, construir un AST puede ser bastante complejo, dependiendo del lenguaje con el que el analizador sintáctico esté tratando.
La mayoría de los analizadores sintácticos suelen construir un árbol de análisis sintáctico (CST) y luego convertirlo a un formato AST, porque a veces puede ser más fácil – a pesar de que significa más pasos, y en general, más pasadas a través del texto fuente. Construir un CST es bastante fácil una vez que el analizador conoce la gramática del lenguaje que está tratando de analizar. No necesita hacer ningún trabajo complicado para averiguar si un token es «significativo» o no; en su lugar, sólo toma exactamente lo que ve, en el orden específico en que lo ve, y lo escupe todo en un árbol.
Por otro lado, hay algunos analizadores que tratarán de hacer todo esto como un proceso de un solo paso, saltando directamente a la construcción de un árbol sintáctico abstracto.
Construir un AST directamente puede ser complicado, ya que el analizador no sólo tiene que encontrar los tokens y representarlos correctamente, sino también decidir qué tokens nos importan, y cuáles no.
En el diseño del compilador, el AST termina siendo súper importante por más de una razón. Sí, puede ser complicado de construir (y probablemente fácil de estropear), pero además, ¡es el último y definitivo resultado de las fases de análisis léxico y sintáctico combinadas! Las fases de análisis léxico y sintáctico a menudo se llaman conjuntamente la fase de análisis, o el front-end del compilador.

Podemos pensar en el árbol sintáctico abstracto como el «proyecto final» del front-end del compilador. Es la parte más importante, porque es lo último que el front-end tiene que mostrar por sí mismo. El término técnico para esto se llama la representación de código intermedio o el IR, porque se convierte en la estructura de datos que se utiliza en última instancia por el compilador para representar un texto fuente.
Un árbol de sintaxis abstracto es la forma más común de IR, pero también, a veces el más incomprendido. Pero ahora que lo entendemos un poco mejor, ¡podemos empezar a cambiar nuestra percepción de esta temible estructura! Esperemos que ahora sea un poco menos intimidante para nosotros.
Recursos
Hay un montón de recursos por ahí sobre ASTs, en una variedad de lenguajes. Saber por dónde empezar puede ser complicado, especialmente si quieres aprender más. A continuación se presentan algunos recursos para principiantes que entran en mucho más detalle sin ser demasiado abrumadores. Feliz asbtracción!
- El AST vs el Parse Tree, Profesor Charles N. Fischer
- ¿Cuál es la diferencia entre los árboles de parse y los árboles de sintaxis abstracta? StackOverflow
- Árboles de sintaxis abstractos vs. concretos, Eli Bendersky
- Árboles de sintaxis abstractos, Profesor Stephen A. Edwards
- Árboles de sintaxis abstractos & Análisis sintáctico descendente, Profesor Konstantinos (Kostis) Sagonas
- Análisis léxico y sintáctico de lenguajes de programación, Chris Northwood
- Explorador de AST, Felix Kling