Última actualización el 18 de agosto de 2020
Los conjuntos de datos pueden tener valores perdidos, y esto puede causar problemas para muchos algoritmos de aprendizaje automático.
Como tal, es una buena práctica identificar y reemplazar los valores perdidos para cada columna en sus datos de entrada antes de modelar su tarea de predicción. Esto se llama imputación de datos perdidos, o imputación para abreviar.
Un enfoque popular para la imputación de datos es calcular un valor estadístico para cada columna (como una media) y reemplazar todos los valores perdidos para esa columna con la estadística. Es un enfoque popular porque la estadística es fácil de calcular utilizando el conjunto de datos de entrenamiento y porque a menudo resulta en un buen rendimiento.
En este tutorial, descubrirá cómo utilizar las estrategias de imputación estadística para los datos que faltan en el aprendizaje automático.
Después de completar este tutorial, sabrá:
- Los valores que faltan deben ser marcados con valores NaN y pueden ser reemplazados con medidas estadísticas para calcular la columna de valores.
- Cómo cargar un valor CSV con valores perdidos y marcar los valores perdidos con valores NaN e informar del número y el porcentaje de valores perdidos para cada columna.
- Cómo imputar los valores perdidos con estadísticas como método de preparación de datos al evaluar modelos y al ajustar un modelo final para hacer predicciones sobre nuevos datos.
Comienza tu proyecto con mi nuevo libro Data Preparation for Machine Learning, que incluye tutoriales paso a paso y los archivos de código fuente de Python para todos los ejemplos.
Comencemos.
- Actualizado Jun/2020: Cambiada la columna utilizada para la predicción en los ejemplos.

Imputación estadística de valores perdidos en aprendizaje automático
Foto de Bernal Saborio, algunos derechos reservados.
Resumen del tutorial
Este tutorial está dividido en tres partes; son:
- Imputación estadística
- Conjunto de datos de cólico equino
- Imputación estadística con SimpleImputer
- Transformación de datos con SimpleImputer
- Evaluación de SimpleImputer y del modelo
- Comparación de diferentes estadísticas imputadas
- Transformación de SimpleImputer al hacer una predicción
.
Imputación estadística
Un conjunto de datos puede tener valores perdidos.
Son filas de datos en las que uno o más valores o columnas de esa fila no están presentes. Los valores pueden faltar por completo o pueden estar marcados con un carácter o valor especial, como un signo de interrogación «?».
Estos valores pueden expresarse de muchas maneras. Los he visto aparecer como nada en absoluto, una cadena vacía, la cadena explícita NULL o indefinida o N/A o NaN, y el número 0, entre otros. Independientemente de cómo aparezcan en su conjunto de datos, saber qué esperar y comprobar que los datos coinciden con esa expectativa reducirá los problemas a medida que empiece a utilizar los datos.
– Página 10, Bad Data Handbook, 2012.
Los valores podrían faltar por muchas razones, a menudo específicas del dominio del problema, y podrían incluir razones tales como mediciones corruptas o falta de disponibilidad de datos.
Pueden ocurrir por una serie de razones, como el mal funcionamiento del equipo de medición, los cambios en el diseño experimental durante la recopilación de datos y el cotejo de varios conjuntos de datos similares pero no idénticos.
– Página 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
La mayoría de los algoritmos de aprendizaje automático requieren valores numéricos de entrada, y que haya un valor para cada fila y columna de un conjunto de datos. Como tal, los valores que faltan pueden causar problemas para los algoritmos de aprendizaje automático.
Como tal, es común identificar los valores que faltan en un conjunto de datos y reemplazarlos con un valor numérico. Esto se llama imputación de datos, o imputación de datos faltantes.
Un enfoque simple y popular para la imputación de datos implica el uso de métodos estadísticos para estimar un valor para una columna a partir de los valores que están presentes, y luego reemplazar todos los valores faltantes en la columna con la estadística calculada.
Es simple porque las estadísticas son rápidas de calcular y es popular porque a menudo resulta muy eficaz.
Las estadísticas comunes calculadas incluyen:
- El valor medio de la columna.
- El valor de la mediana de la columna.
- El valor de la moda de la columna.
- Un valor constante.
Ahora que estamos familiarizados con los métodos estadísticos para la imputación de valores perdidos, vamos a echar un vistazo a un conjunto de datos con valores perdidos.
¿Quieres empezar con la preparación de datos?
Toma mi curso intensivo gratuito de 7 días por correo electrónico ahora (con código de ejemplo).
Haga clic para inscribirse y obtener también una versión gratuita del curso en formato PDF.
Descargue su minicurso GRATUITO
Conjunto de datos sobre el cólico del caballo
El conjunto de datos sobre el cólico del caballo describe las características médicas de los caballos con cólicos y si viven o mueren.
Hay 300 filas y 26 variables de entrada con una variable de salida. Es una tarea de predicción de clasificación binaria que implica predecir 1 si el caballo vivió y 2 si el caballo murió.
Hay muchos campos que podríamos seleccionar para predecir en este conjunto de datos. En este caso, predeciremos si el problema fue quirúrgico o no (índice de columna 23), lo que lo convierte en un problema de clasificación binaria.
El conjunto de datos tiene numerosos valores perdidos para muchas de las columnas en las que cada valor perdido está marcado con un carácter de signo de interrogación («?»).
A continuación se ofrece un ejemplo de filas del conjunto de datos con valores perdidos marcados.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Puede obtener más información sobre el conjunto de datos aquí:
- Conjunto de datos del cólico del caballo
- Descripción del conjunto de datos del cólico del caballo
No es necesario descargar el conjunto de datos, ya que lo descargaremos automáticamente en los ejemplos trabajados.
Marcar los valores perdidos con un valor NaN (no un número) en un conjunto de datos cargado usando Python es una buena práctica.
Podemos cargar el conjunto de datos usando la función de Pandas read_csv() y especificar los «na_values» para cargar valores de ‘?’ como perdidos, marcados con un valor NaN.
|
1
2
3
4
|
…
# cargar conjunto de datos
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
|
Una vez cargados, podemos revisar los datos cargados para confirmar que los valores «?» están marcados como NaN.
|
1
2
3
|
…
# resumir las primeras filas
print(dataframe.head())
|
A continuación podemos enumerar cada columna e informar del número de filas con valores perdidos para la columna.
|
1
2
3
4
5
6
7
|
…
# resumir el número de filas con valores perdidos para cada columna
for i in range(dataframe.shape):
# contar el número de filas con valores perdidos
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Falta: %d (%.1f%%)’ % (i, n_miss, perc))
|
Enlazando todo esto, el ejemplo completo de carga y resumen del conjunto de datos aparece a continuación.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# resumir el conjunto de datos del cólico del caballo
from pandas import read_csv
# cargar el conjunto de datos
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# resumir las primeras filas
print(dataframe.head())
# resumir el número de filas con valores perdidos para cada columna
for i in range(dataframe.shape):
# contar el número de filas con valores perdidos
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Missing: %d (%.1f%%)’ % (i, n_miss, perc))
|
Al ejecutar el ejemplo se carga primero el conjunto de datos y se resumen las cinco primeras filas.
Podemos ver que los valores perdidos que estaban marcados con un carácter «?» han sido sustituidos por valores NaN.
A continuación, podemos ver la lista de todas las columnas del conjunto de datos y el número y el porcentaje de valores perdidos.
Podemos ver que algunas columnas (por ejemplo, los índices de las columnas 1 y 2) no tienen valores perdidos y otras columnas (por ejemplo, los índices de las columnas 15 y 21) tienen muchos o incluso la mayoría de los valores perdidos.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Missing: 1 (0,3%)
> 1, Falta: 0 (0.0%)
> 2, Falta: 0 (0,0%)
> 3, Falta: 60 (20,0%)
> 4, Falta: 24 (8,0%)
> 5, Falta: 58 (19,3%)
> 6, Falta: 56 (18,7%)
> 7, Falta: 69 (23,0%)
> 8, Falta: 47 (15,7%)
> 9, Falta: 32 (10,7%)
> 10, Falta: 55 (18,3%)
> 11, Falta: 44 (14,7%)
> 12, Falta: 56 (18,7%)
> 13, Falta: 104 (34,7%)
> 14, Falta: 106 (35,3%)
> 15, Desaparecidos: 247 (82,3%)
> 16, Falta: 102 (34,0%)
> 17, Desaparecidos: 118 (39,3%)
> 18, Desaparecidos: 29 (9,7%)
> 19, Desaparecidos: 33 (11,0%)
> 20, Falta: 165 (55,0%)
> 21, Falta: 198 (66,0%)
> 22, Falta: 1 (0,3%)
> 23, Falta: 0 (0,0%)
> 24, Falta: 0 (0,0%)
> 25, Falta: 0 (0.0%)
> 26, Falta: 0 (0.0%)
> 27, Falta: 0 (0,0%)
|
Ahora que estamos familiarizados con el conjunto de datos del cólico del caballo que tiene valores perdidos, vamos a ver cómo podemos utilizar la imputación estadística.
Imputación estadística con SimpleImputer
La biblioteca de aprendizaje automático de scikit-learn proporciona la clase SimpleImputer que soporta la imputación estadística.
En esta sección, exploraremos cómo utilizar eficazmente la clase SimpleImputer.
Transformación de datos SimpleImputer
El SimpleImputer es una transformación de datos que primero se configura en base al tipo de estadística a calcular para cada columna, e.g. media.
|
1
2
3
|
…
# define imputer
imputer = SimpleImputer(strategy=’mean’)
|
Entonces el imputer se ajusta a un conjunto de datos para calcular el estadístico de cada columna.
|
1
2
3
|
…
# ajuste en el conjunto de datos
imputer.fit(X)
|
El imputer de ajuste se aplica entonces a un conjunto de datos para crear una copia del conjunto de datos con todos los valores perdidos de cada columna sustituidos por un valor estadístico.
|
1
2
3
|
…
# transformar el conjunto de datos
Xtrans = imputer.transform(X)
|
Podemos demostrar su uso en el conjunto de datos del cólico del caballo y confirmar que funciona resumiendo el número total de valores perdidos en el conjunto de datos antes y después de la transformación.
El ejemplo completo aparece a continuación.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# imputación estadística transformar para el conjunto de datos del cólico del caballo
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# print total missing
print(‘Missing: %d’ % sum(isnan(X).flatten())
# definir imputación
imputación = SimpleImputer(strategy=’mean’)
# ajustar en el conjunto de datos
imputación.fit(X)
# transformar el conjunto de datos
Xtrans = imputer.transform(X)
# imprimir el total de faltantes
print(‘Faltan: %d’ % sum(isnan(Xtrans).flatten())
|
Al ejecutar el ejemplo se carga primero el conjunto de datos y se informa de que el número total de valores perdidos en el conjunto de datos es de 1.605.
La transformación se configura, se ajusta y se realiza y el nuevo conjunto de datos resultante no tiene valores perdidos, lo que confirma que se realizó como esperábamos.
Cada valor perdido fue reemplazado por el valor medio de su columna.
|
1
2
|
Falta: 1605
Falta: 0
|
Evaluación de modelos
Es una buena práctica evaluar los modelos de aprendizaje automático en un conjunto de datos utilizando la validación cruzada k-fold.
Para aplicar correctamente la imputación estadística de datos faltantes y evitar la fuga de datos, se requiere que las estadísticas calculadas para cada columna se calculen sólo en el conjunto de datos de entrenamiento, y luego se apliquen a los conjuntos de entrenamiento y prueba para cada pliegue del conjunto de datos.
Si estamos utilizando el remuestreo para seleccionar los valores de los parámetros de ajuste o para estimar el rendimiento, la imputación debe ser incorporada dentro del remuestreo.
– Página 42, Applied Predictive Modeling, 2013.
Esto se puede lograr mediante la creación de una tubería de modelado donde el primer paso es la imputación estadística, entonces el segundo paso es el modelo. Esto puede lograrse utilizando la clase Pipeline.
Por ejemplo, el Pipeline de abajo utiliza un SimpleImputer con una estrategia ‘media’, seguido de un modelo de bosque aleatorio.
|
1
2
3
4
5
|
…
# definir la tubería de modelado
modelo = RandomForestClassifier()
imputación = SimpleImputer(strategy=’mean’)
tubería = Pipeline(steps=)
|
Podemos evaluar la media-conjunto de datos imputados y la tubería de modelado de bosque aleatorio para el conjunto de datos de cólicos del caballo con validación cruzada repetida de 10 veces.
El ejemplo completo aparece a continuación.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# evaluar la imputación de medias y el bosque aleatorio forest para el conjunto de datos del cólico del caballo
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dividir en elementos de entrada y salida
data = dataframe.values
ix = ) if i != 23]
X, y = datos, data
# definir pipeline de modelado
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# definir evaluación del modelo
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluar el modelo
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(‘Mean Accuracy: %.3f (%.3f)’ % (mean(scores), std(scores))
|
La ejecución del ejemplo aplica correctamente la imputación de datos a cada pliegue del procedimiento de validación cruzada.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o del procedimiento de evaluación, o las diferencias en la precisión numérica. Considere la posibilidad de ejecutar el ejemplo varias veces y compare el resultado medio.
La tubería se evalúa utilizando tres repeticiones de validación cruzada de 10 veces y reporta la precisión de clasificación media en el conjunto de datos como alrededor del 86.3 por ciento, que es una buena puntuación.
|
1
|
Exactitud media: 0,863 (0.054)
|
Comparación de diferentes estadísticas imputadas
¿Cómo sabemos que el uso de una estrategia estadística «media» es bueno o mejor para este conjunto de datos?
La respuesta es que no lo sabemos y que se eligió arbitrariamente.
Podemos diseñar un experimento para probar cada estrategia estadística y descubrir cuál funciona mejor para este conjunto de datos, comparando las estrategias media, mediana, modo (más frecuente) y constante (0). A continuación, se puede comparar la precisión media de cada enfoque.
El ejemplo completo aparece a continuación.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# comparar estrategias de imputación estadística para el conjunto de datos del cólico del caballo
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dividir en elementos de entrada y salida
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# evaluar cada estrategia en el conjunto de datos
resultados = list()
estrategias =
para s en estrategias:
# crear la tubería de modelado
pipeline = Pipeline(steps=)
# evaluar el modelo
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# store results
results.append(scores)
print(‘>%s %.3f (%.3f)’ % (s, mean(scores), std(scores))
# trazar el rendimiento del modelo para su comparación
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
La ejecución del ejemplo evalúa cada estrategia de imputación estadística en el conjunto de datos del cólico del caballo utilizando una validación cruzada repetida.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o del procedimiento de evaluación, o las diferencias en la precisión numérica. Considere la posibilidad de ejecutar el ejemplo varias veces y compare el resultado medio.
Se informa de la precisión media de cada estrategia a lo largo del camino. Los resultados sugieren que el uso de un valor constante, por ejemplo, 0, resulta en el mejor rendimiento de alrededor de 88,1 por ciento, que es un resultado sobresaliente.
|
1
2
3
4
|
> media 0.860 (0,054)
>mediana 0,862 (0.065)
>más_frecuente 0,872 (0,052)
>constante 0,881 (0,047)
|
Al final de la ejecución, se crea un gráfico de cajas y bigotes para cada conjunto de resultados, lo que permite comparar la distribución de los resultados.
Podemos ver claramente que la distribución de las puntuaciones de precisión para la estrategia constante es mejor que las otras estrategias.
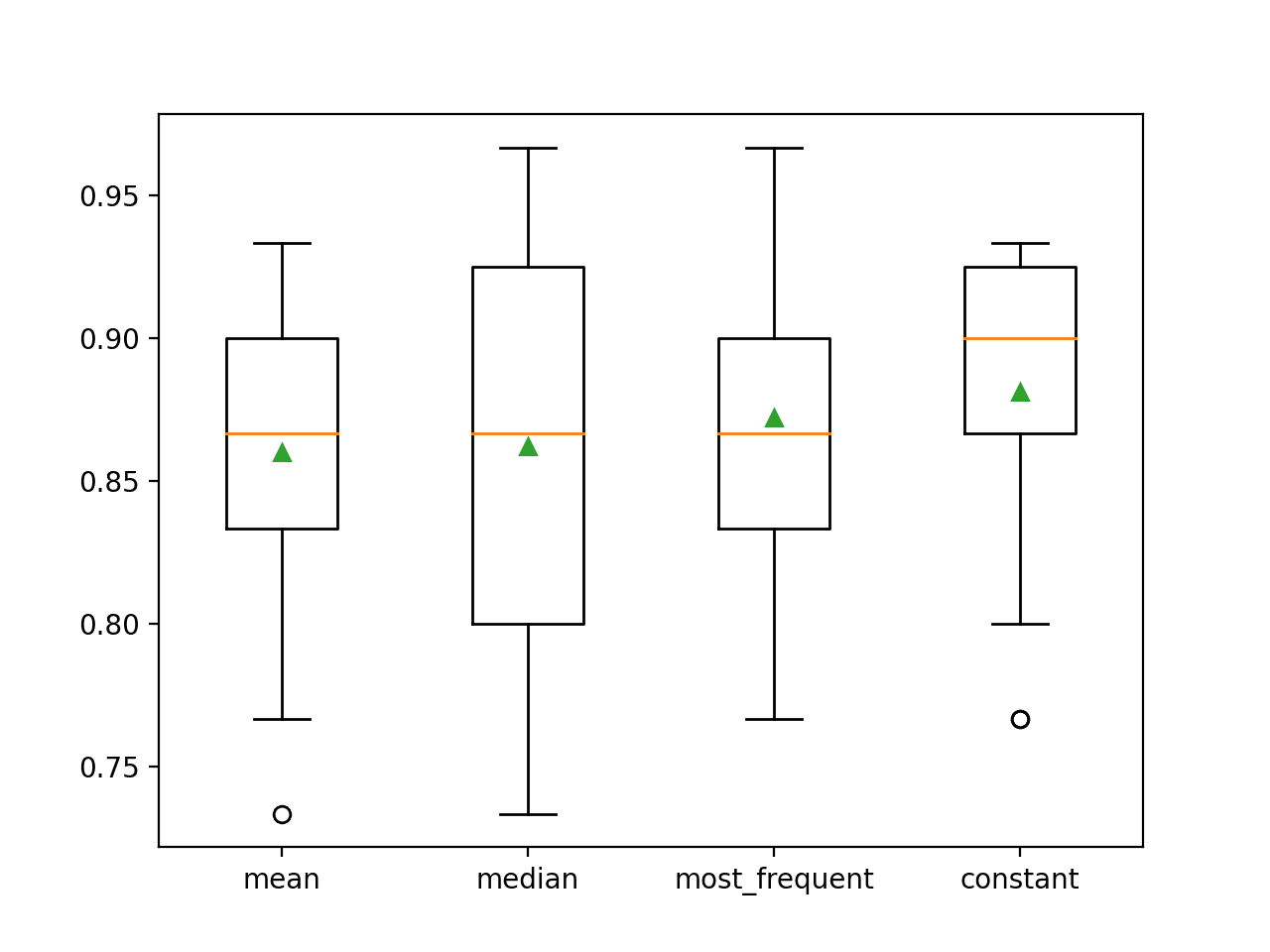
Ploteo de cajas y bigotes de las estrategias de imputación estadística aplicadas al conjunto de datos del cólico del caballo
Transformación simple del ordenador al hacer una predicción
Es posible que queramos crear una tubería de modelado final con la estrategia de imputación constante y el algoritmo de bosque aleatorio, y luego hacer una predicción para los nuevos datos.
Esto puede lograrse definiendo la tubería y ajustándola a todos los datos disponibles, y luego llamando a la función predict() pasando los nuevos datos como argumento.
Es importante que la fila de los nuevos datos marque los valores perdidos utilizando el valor NaN.
|
1
2
3
|
…
# definir nuevos datos
fila =
|
El ejemplo completo aparece a continuación.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# imputación constante estrategia y predicción para el conjunto de datos de cólicos de manguera
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# crear la tubería de modelado
pipeline = Pipeline(steps=)
# ajustar el modelo
pipeline.fit(X, y)
# definir nuevos datos
fila =
# hacer una predicción
yhat = pipeline.predict()
# resumir la predicción
print(‘Predicted Class: %d’ % yhat)
|
La ejecución del ejemplo se ajusta a la tubería de modelado en todos los datos disponibles.
Se define una nueva fila de datos con los valores perdidos marcados con NaNs y se realiza una predicción de clasificación.
|
1
|
Clase predicha: 2
|
Lectura adicional
Esta sección ofrece más recursos sobre el tema si se quiere profundizar.
Tutoriales relacionados
- Resultados para conjuntos de datos de aprendizaje automático de clasificación y regresión estándar
- Cómo manejar los datos perdidos con Python
Libros
- Manual de datos malos, 2012.
- Minería de datos: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
APIs
- Imputación de valores perdidos, Documentación de scikit-learn.
- API sklearn.impute.SimpleImputer.
Conjunto de datos
- Conjunto de datos del cólico del caballo
- Descripción del conjunto de datos del cólico del caballo
Resumen
En este tutorial, descubrió cómo utilizar estrategias de imputación estadística para datos perdidos en el aprendizaje automático.
Específicamente, usted aprendió:
- Los valores faltantes deben ser marcados con valores NaN y pueden ser reemplazados con medidas estadísticas para calcular la columna de valores.
- Cómo cargar un valor CSV con valores faltantes y marcar los valores faltantes con valores NaN e informar el número y porcentaje de valores faltantes para cada columna.
- Cómo imputar valores perdidos con estadísticas como método de preparación de datos al evaluar modelos y al ajustar un modelo final para hacer predicciones sobre nuevos datos.
¿Tiene alguna pregunta?
Haz tus preguntas en los comentarios de abajo y haré todo lo posible por responderlas.
¡Ponte al día con la preparación de datos moderna!

Prepara tus datos de aprendizaje automático en minutos
…con sólo unas pocas líneas de código python
Descubra cómo en mi nuevo Ebook:
Preparación de Datos para el Aprendizaje Automático
Proporciona tutoriales de autoestudio con código de trabajo completo sobre:
Selección de Características, RFE, Limpieza de Datos, Transformaciones de Datos, Escalado, Reducción de Dimensionalidad, y mucho más…
Traiga técnicas modernas de preparación de datos a
sus proyectos de aprendizaje automático
Vea lo que hay dentro