Por: Derek Colley | Actualizado: 2014-01-29 | Comentarios (5) | Relacionado: Más > Funciones – Sistema
Problema
Está buscando recuperar una muestra aleatoria de un conjunto de resultados de consulta de SQL Server. Quizás esté buscando una muestra representativa de datos de una gran base de datos de clientes; quizás esté buscando algunos promedios, o una idea del tipo de datos que tiene. SELECT TOP N no siempre es ideal, ya que los datos atípicos suelen aparecer al principio y al final de los conjuntos de datos, especialmente cuando están ordenados alfabéticamente o por algún valor escalar. También puede haber utilizado TABLESAMPLE, pero tiene limitaciones, especialmente con conjuntos de datos pequeños o sesgados. Quizás su jefe le ha pedido una selección aleatoria de 100 nombres de clientes y ubicaciones; o está participando en una auditoría y necesita recuperar una muestra aleatoria de datos para su análisis. ¿Cómo podría llevar a cabo esta tarea? Eche un vistazo a este consejo para aprender más.
Solución
Este consejo le mostrará cómo usar TABLESAMPLE en T-SQL para recuperar muestras de datos pseudo-aleatorios, y hablará sobre los aspectos internos de TABLESAMPLE y dónde no es apropiado. También le mostrará un método alternativo – un método matemático que utiliza NEWID() junto con CHECKSUM y un operador bitwise, señalado por Microsoft en el artículo TABLESAMPLE TechNet. Hablaremos un poco sobre el muestreo estadístico en general (las diferencias entre aleatorio, sistemático y estratificado) con ejemplos, y echaremos un vistazo a cómo se muestrean las estadísticas de SQL como ejemplo, y las opciones que podemos utilizar para anular este muestreo. Después de leer este consejo, debería tener una apreciación de los beneficios del muestreo sobre el uso de métodos como el TOP N y saber cómo aplicar al menos un método para lograrlo en SQL Server.
Configuración
Para este consejo, usaré un conjunto de datos que contiene una columna INT de identidad (para establecer el grado de aleatoriedad al seleccionar filas) y otras columnas llenas de datos pseudoaleatorios de diferentes tipos de datos, para simular (vagamente) datos reales en una tabla. Puede utilizar el código T-SQL que se muestra a continuación para configurarlo. Sólo debería tardar un par de minutos en ejecutarse y está probado en SQL Server 2012 Developer Edition.
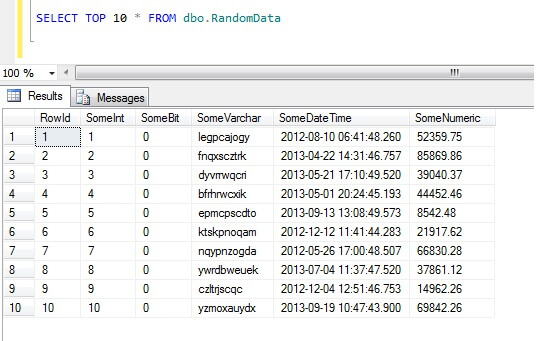
Seleccionando las 10 primeras filas de datos se obtiene este resultado (sólo para dar una idea de la forma de los datos).Como nota, este es un trozo de código general que he creado para generar datos aleatorios siempre que lo necesite – ¡siéntete libre de tomarlo y aumentarlo/destruirlo a tu gusto!
Cómo no muestrear datos en SQL Server
Ahora que tenemos nuestras muestras de datos, pensemos en las peores formas de obtener una muestra. En la base de datos AdventureWorks, existe una tabla llamada Persona.Dirección. Tomemos como muestra los 10 primeros resultados, sin ningún orden en particular:
SELECT TOP 10 * FROM Person.Address
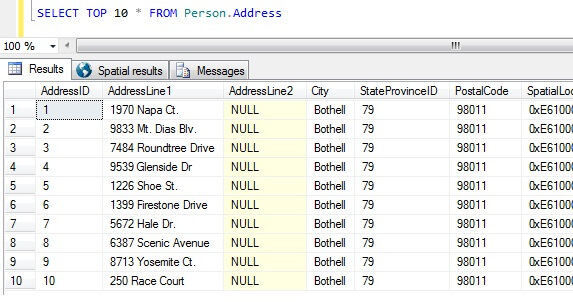
A partir de esta muestra solamente, podemos ver que todas las personas devueltas viven en Bothell, y comparten el código postal 98011. Esto se debe a que se especificó que los resultados se devolvieran sin ningún orden en particular, pero en realidad se devolvieron por orden de la columna AddressID. Tenga en cuenta que esto NO es un comportamiento garantizado para los datos del montón en particular – vea esta cita de BOL:
«Por lo general, los datos se almacenan inicialmente en el orden en que se insertan las filas en la tabla, pero el motor de la base de datos puede mover los datos en el montón para almacenar las filas de manera eficiente, por lo que el orden de los datos no se puede predecir. Para garantizar el orden de las filas devueltas desde un montón, debe utilizar la cláusula ORDER BY.»
http://technet.microsoft.com/en-us/library/hh213609.aspx
Tomando este conjunto de resultados, una persona desinformada sobre la naturaleza de la tabla podría concluir que todos sus clientes viven en Bothell.
Tipos de muestreo de datos en SQL Server
Lo anterior es claramente falso, por lo que necesitamos una forma mejor de muestreo. ¿Qué tal si tomamos una muestra a intervalos regulares en toda la tabla?
Esto debería devolver 47 filas:
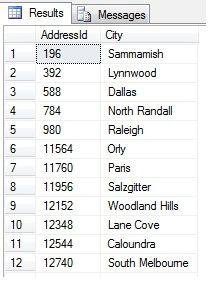
Hasta aquí, todo bien. Hemos tomado una fila a intervalos regulares a lo largo de nuestro conjunto de datos y hemos devuelto una sección transversal estadística, ¿o no? No necesariamente. No olvides que el orden no está garantizado. Podríamos sacar una o dos conclusiones sobre estos datos. Vamos a agregarlos para ilustrarlo. Vuelva a ejecutar el fragmento de código anterior, pero cambie el bloque SELECT final como sigue:
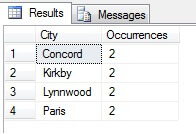
Puede ver en mi ejemplo que, de un recuento total de más de 19.000 filas en la tabla Person.Address, he muestreado alrededor de 1/4% de las filas y, por tanto, puedo concluir que (en mi ejemplo), Concord, Kirkby, Lynnwood y París tienen el mayor número de residentes y, además, están igualmente poblados. ¿Exactamente? Tonterías, por supuesto:
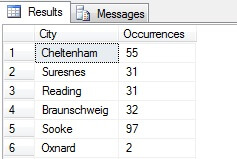
Como puedes ver, ninguno de mis cuatro estaba realmente entre los cuatro mejores lugares para vivir, según esta tabla. No sólo los datos de la muestra eran demasiado pequeños, sino que agregué esta pequeña muestra e intenté llegar a una conclusión a partir de ella. Esto significa que mi conjunto de resultados es estadísticamente insignificante -por cierto, demostrar la significación estadística es una de las principales cargas de la prueba cuando se presentan resúmenes estadísticos (o debería serlo) y una de las principales caídas de muchas infografías populares y datagramas dirigidos por el marketing.
Así que, el muestreo de esta manera (llamado muestreo sistemático) es eficaz, pero sólo para una población estadísticamente significativa. Hay factores como la periodicidad y la proporción que pueden arruinar una muestra – veamos la proporción en acción tomando una muestra de 10 ciudades de la tabla Person.Address, mediante el siguiente código, que obtiene una lista distinta de ciudades de la tabla Person.Address, y luego selecciona 10 ciudades de esa lista utilizando un muestreo sistemático:
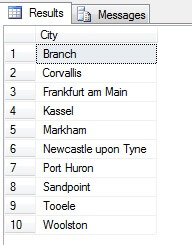
Parece una buena muestra, ¿verdad? Ahora contrastémosla con una muestra de ciudades NO distintas enumeradas en orden ascendente, es decir, cada enésima ciudad, donde n es el recuento total de filas dividido por 10. Esta medida tiene en cuenta la población de la muestra:
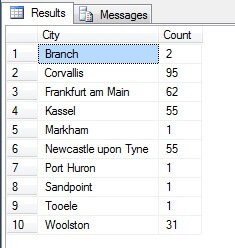
Los datos devueltos son completamente diferentes, no por azar, sino por la presentación de una muestra representativa. Obsérvese que esta lista, en la que he incluido los recuentos de cada ciudad en la tabla de origen para esbozar hasta qué punto la población interviene en la selección de los datos, incluye las cuatro ciudades más pobladas de la muestra, lo que (si se considera una lista ordenada no diferenciada) es la representación más justa. No es necesariamente la mejor representación para sus necesidades, así que tenga cuidado al elegir su método de muestreo estadístico.
Otros métodos de muestreo
Muestreo por conglomerados: en este caso, la población que se va a muestrear se divide en conglomerados, o subconjuntos, y luego se determina aleatoriamente que cada uno de estos subconjuntos se incluya o no en el conjunto de resultados de salida. Si se incluye, cada miembro de ese subconjunto se devuelve en el conjunto de resultados. Ver TABLESAMPLE más abajo para un ejemplo de esto.
Muestreo desproporcional – es como el muestreo estratificado, donde los miembros de los grupos de subconjuntos se seleccionan con el fin de representar a todo el grupo, pero en lugar de estar en proporción, puede haber diferentes números de miembros de cada grupo seleccionados para igualar la representación de cada grupo. Es decir, dadas las ciudades de Person.Address en el ejemplo de la sección anterior, el primer conjunto de resultados era desproporcionado, ya que no tenía en cuenta la población, pero el segundo conjunto de resultados era proporcional, ya que representaba el número de entradas de ciudades en la tabla Person.Address. Este tipo de muestreo es, de hecho, útil si una categoría particular está subrepresentada en el conjunto de datos, y la proporción no es importante (por ejemplo, 100 clientes aleatorios de 100 ciudades aleatorias estratificadas por ciudad – las ciudades en el subconjunto necesitarían normalización – se podría utilizar el muestreo desproporcionado).
Datos aleatorios de SQL Server con TABLESAMPLE
SQL Server viene con un método de muestreo de datos muy útil. Veámoslo en acción. Utilice el siguiente código para devolver aproximadamente 100 filas (si devuelve 0 filas, vuelva a ejecutar – lo explicaré en un momento) de los datos de dbo.RandomData que definimos anteriormente.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
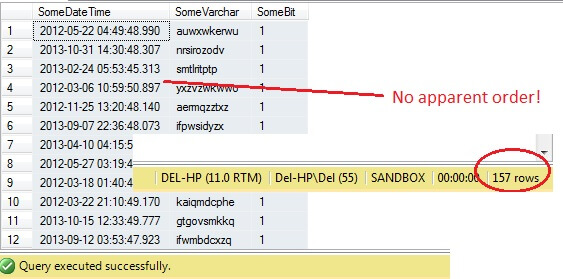
Hasta aquí, todo bien, ¿verdad? Espera – no podemos ver la columna Id. Incluyamos esto y volvamos a ejecutar:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
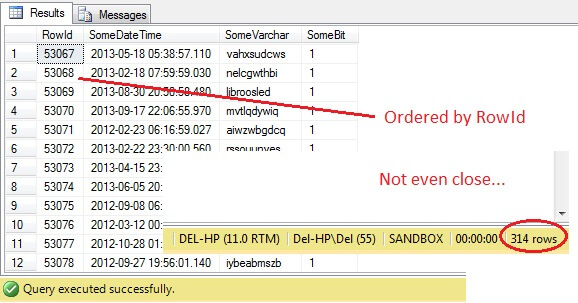
Oh, querido – TABLESAMPLE ha seleccionado una porción de datos, pero no es aleatoria – el RowId muestra una porción claramente delineada con un valor mínimo y uno máximo. Además, tampoco ha devuelto exactamente 100 filas. ¿Qué está pasando?
TABLESAMPLE utiliza el modificador implícito SYSTEM. Este modificador, activado por defecto y una especificación ANSI-SQL, es decir, no opcional, tomará cada página de 8KB en la que resida la tabla y decidirá si incluye o no todas las filas de esa página que estén en esa tabla en la muestra producida, basándose en el porcentaje o N FILAS pasadas. Por lo tanto, una tabla que reside en muchas páginas, es decir, que tiene grandes filas de datos, debería devolver una muestra más aleatoria, ya que habrá más páginas en la muestra. En cambio, en un ejemplo como el nuestro, en el que los datos son escalares y pequeños y residen en unas pocas páginas, no funciona, ya que si un número determinado de páginas no pasa el corte, la muestra resultante puede estar muy sesgada. Esta es la desventaja de TABLESAMPLE: no funciona bien con datos «pequeños» y no tiene en cuenta la distribución de los datos en las páginas. Así que la disposición de los datos en las páginas es la responsable en última instancia de la muestra devuelta por este método.
¿Le suena esto? Se trata esencialmente de un muestreo por conglomerados, en el que todos los miembros (filas) de los grupos (conglomerados) seleccionados están representados en el conjunto de resultados.
Pongamos a prueba este método en una tabla grande para enfatizar el punto de la no escalabilidad inversa. Primero identifiquemos la tabla más grande de la base de datos AdventureWorks. Usaremos un informe estándar para esto – usando SSMS, haga clic con el botón derecho en la base de datos AdventureWorks2012, vaya a Informes -> Informes estándar -> Uso de disco por tablas principales. Ordene por Datos(KB) haciendo clic en el encabezado de la columna (es posible que desee hacer esto dos veces para el orden descendente). Verá el informe siguiente.
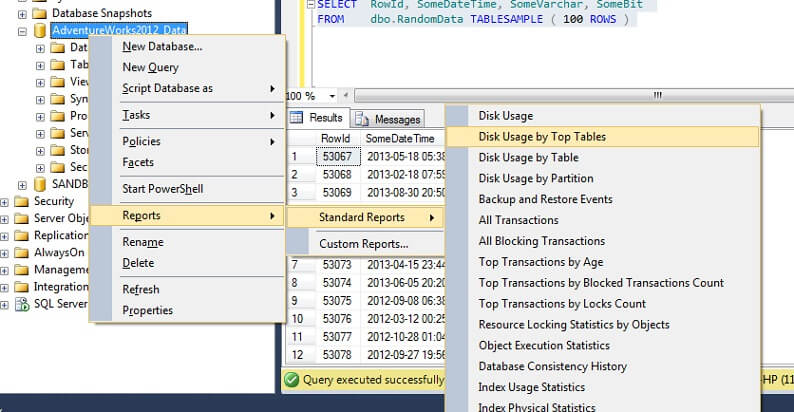
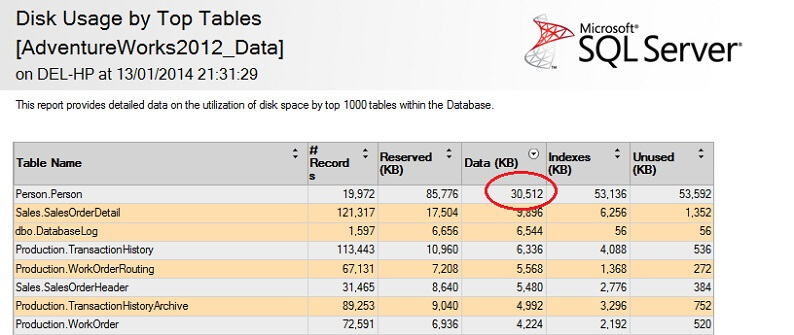
He rodeado la cifra interesante: la tabla Person. Persona consume 30,5MB de datos y es la tabla más grande (por datos, no por número de registros). Así que intentemos tomar una muestra de esta tabla en su lugar:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
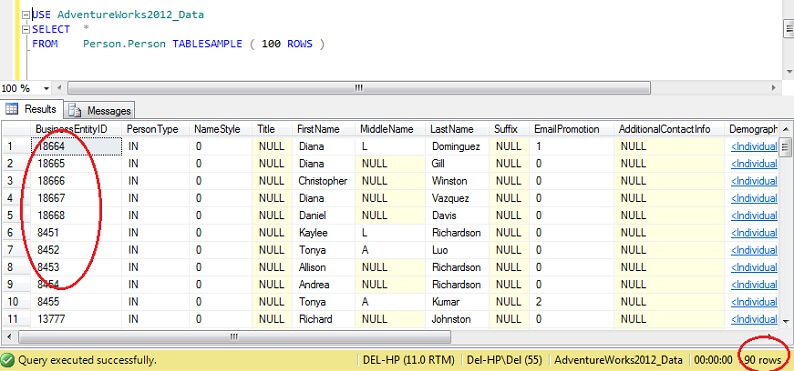
Puedes ver que estamos mucho más cerca de las 100 filas, pero lo más importante es que no parece haber mucha agrupación en la clave primaria (aunque hay algo, ya que hay más de 1 fila por página).
En consecuencia, TABLESAMPLE es bueno para los datos grandes, y empeora catastróficamente cuanto más pequeño es el conjunto de datos. Esto no es bueno para nosotros cuando el muestreo de los datos estratificados o datos agrupados, donde estamos tomando muchas muestras de pequeños grupos o subconjuntos de datos y luego agregarlos. Veamos entonces un método alternativo.
Datos aleatorios de SQL Server con ORDER BY NEWID()
Aquí hay una cita de BOL sobre cómo obtener una muestra verdaderamente aleatoria:
«Si realmente quiere una muestra aleatoria de filas individuales, modifique su consulta para filtrar las filas aleatoriamente, en lugar de utilizar TABLESAMPLE. Por ejemplo, la siguiente consulta utiliza la función NEWID para devolver aproximadamente el uno por ciento de las filas de la tabla Sales.SalesOrderDetail:
¿Cómo funciona esto? Vamos a dividir la cláusula WHERE y explicarla.
La función CHECKSUM está calculando una suma de comprobación sobre los elementos de la lista. Es discutible si el SalesOrderID es necesario, ya que NEWID() es una función que devuelve un nuevo GUID aleatorio, por lo que multiplicar una cifra aleatoria por una constante debería dar como resultado una cifra aleatoria en cualquier caso. Si usted es un experto en estadística y puede justificar la inclusión de esto, por favor, utilice la sección de comentarios a continuación y hágame saber por qué estoy equivocado!
La función CHECKSUM devuelve un VARBINARIO. Realizando una operación AND a nivel de bits con 0x7fffffff, que es el equivalente a (111111111…) en binario, se obtiene un valor decimal que es efectivamente una representación de una cadena aleatoria de 0s y 1s. Dividiendo por el coeficiente 0x7fffffff se normaliza efectivamente esta cifra decimal a una cifra entre 0 y 1. Luego, para decidir si cada fila merece ser incluida en el conjunto de resultados final, se utiliza un umbral de 1/x (en este caso, 0,01) donde x es el porcentaje de los datos a recuperar como muestra.
Tenga en cuenta que este método es una forma de muestreo aleatorio en lugar de muestreo sistemático, por lo que es probable que obtenga datos de todas las partes de sus datos de origen, pero la clave aquí es que *puede que no*. La naturaleza del muestreo aleatorio significa que cualquier muestra que recoja puede estar sesgada hacia un segmento de sus datos, así que para beneficiarse de la regresión a la media (tendencia hacia un resultado aleatorio, en este caso) asegúrese de tomar múltiples muestras y seleccionar de un subconjunto de ellas, si sus resultados parecen sesgados. Alternativamente, tome muestras de subconjuntos de sus datos, y luego agréguelos – este es otro tipo de muestreo, llamado muestreo estratificado.
¿Cómo se muestrean las estadísticas de SQL Server?
En SQL Server, la actualización automática de las estadísticas de columna o definidas por el usuario tiene lugar cada vez que se cambia un umbral establecido de filas de la tabla para una tabla determinada. En 2012, este umbral se calcula en SQRT(1000 * TR), donde TR es el número de filas de la tabla. Antes de 2005, el trabajo estadístico de actualización automática se disparará por cada (500 filas + 20% de cambio) de filas de la tabla. Una vez que se inicia el proceso de actualización automática, el muestreo *reducirá el número de filas muestreadas cuanto más grande sea la tabla*, en otras palabras, hay una relación que es similar a la proporción inversa entre el porcentaje de muestreo de la tabla y el tamaño de la tabla, pero sigue un algoritmo propio.
Interesantemente, esto parece ser lo contrario de la opción TABLESAMPLE (N PERCENT), donde las filas muestreadas está en proporción normal al número de filas en la tabla. Podemos deshabilitar las estadísticas automáticas (tenga cuidado al hacerlo) y actualizar las estadísticas manualmente – esto se logra usando NORECOMPUTE en la sentencia UPDATE STATISTICS. Con UPDATE STATISTICS podemos anular algunas de las opciones – por ejemplo, podemos elegir muestrear N filas, o N por ciento (similar a TABLESAMPLE), realizar un FULLSCAN, o simplemente RESAMPLE usando la última tasa conocida.
Siguientes pasos
Para más lecturas, Joseph Sack es un MVP de Microsoft conocido por su trabajo en el análisis estadístico de SQL Server – por favor, vea a continuación algunos enlaces a su trabajo, junto con algunas referencias al trabajo utilizado para este artículo y a algunos consejos relacionados de MSSQLTips.com. Gracias por leer!
Última actualización: 2014-01-29


Acerca del autor
 Derek Colley es un DBA y desarrollador de BI residente en el Reino Unido con más de una década de experiencia trabajando con SQL Server, Oracle y MySQL.
Derek Colley es un DBA y desarrollador de BI residente en el Reino Unido con más de una década de experiencia trabajando con SQL Server, Oracle y MySQL.Ver todos mis consejos
- Más consejos para desarrolladores de bases de datos…