Hay muchas grandes ventajas que ofrece la virtualización de su infraestructura y la ejecución de recursos virtuales para servir a las cargas de trabajo críticas para el negocio. En el caso de VMware vSphere, ofrece muchas características y capacidades notables que proporcionan alta disponibilidad en el entorno, así como la programación automatizada de la carga de trabajo para garantizar el uso más eficiente del hardware y los recursos en su entorno vSphere.
En este post, hablaremos de dos de las principales características a nivel de clúster de vSphere en la empresa: vSphere HA y DRS. Es muy probable que haya visto ambas referencias junto con la ejecución de vSphere en la empresa.
¿Qué es vSphere HA y DRS? ¿Qué hacen?
¿Cómo se beneficia al ejecutar ambos en su entorno vSphere?
Veamos una introducción básica a HA y DRS en VMware vSphere y veamos cómo se comparan y los beneficios de su uso.
VMware vSphere Clusters
Una de las ventajas obvias y las mejores prácticas cuando se utiliza VMware vSphere para ejecutar cargas de trabajo críticas para el negocio es ejecutar un vSphere Cluster.
¿Qué es un vSphere Cluster?
Un vSphere Cluster es una configuración de más de un servidor VMware ESXi agregado como un conjunto de recursos aportados al vSphere Cluster. Los recursos como el cálculo de la CPU, la memoria y, en el caso del almacenamiento definido por software como vSAN, el almacenamiento, son aportados por cada host ESXi.
¿Por qué es importante ejecutar las cargas de trabajo críticas para la empresa sobre un clúster de vSphere?
Cuando se piensa en las ventajas que proporciona la ejecución de un hipervisor, permite que más de un servidor se ejecute sobre un único conjunto de hardware físico. Virtualizar las cargas de trabajo de esta manera proporciona muchos beneficios de eficiencia en órdenes de magnitud en comparación con la ejecución de un solo servidor en un único conjunto de hardware físico.
Sin embargo, esto también puede convertirse en el talón de Aquiles de una solución virtualizada, ya que el impacto de un fallo de hardware puede afectar a muchos más servicios y aplicaciones críticos para el negocio. Puedes imaginar que si sólo tienes un único host VMware ESXi ejecutando muchas VMs, el impacto de perder ese único host ESXi sería inmenso.
Aquí es donde la ejecución de múltiples hosts VMware ESXi en un vSphere Cluster realmente brilla.
Sin embargo, usted puede preguntarse, ¿cómo el simple hecho de ejecutar múltiples hosts en un clúster mejora su alta disponibilidad? ¿Cómo un host en el vSphere Cluster «sabe» si otro host ha fallado? ¿Existe un mecanismo especial que se encarga de gestionar la alta disponibilidad de las cargas de trabajo que se ejecutan en un vSphere Cluster? Sí, lo hay. Veamos.
¿Qué es la HA en VMware?
VMware se dio cuenta de la necesidad de tener un mecanismo para poder proporcionar protección contra un host ESXi fallido en el vSphere Cluster. Con esta necesidad, nació VMware High-Availability (HA).
VMware vSphere HA ofrece las siguientes ventajas:
VMware vSphere HA es rentable y permite reiniciar de forma automatizada las VM y los hosts de vSphere cuando se produce una interrupción del servidor o se detecta un fallo del sistema operativo en el entorno de vSphere
Monitorea todos los hosts de VMware vSphere &VM en el clúster de vSphere
Ofrece alta disponibilidad a la mayoría de las aplicaciones que se ejecutan en las máquinas virtuales, independientemente del sistema operativo y las aplicaciones.
La belleza de la solución vSphere HA de VMware que se implementa a través del VMware Cluster es la simplicidad con la que se puede configurar. Con unos pocos clics a través de una interfaz guiada por un asistente, se puede configurar la alta disponibilidad. ¿Cómo se compara esto con las tecnologías tradicionales de «clustering»?
Comparación de Windows Server Failover Clustering
Windows Server Failover Clustering (WSFC) se ha convertido en la tecnología de clustering en la que la mayoría piensa cuando tiene en mente la tecnología de clustering. El problema que se observa con WSFC es que requiere muchos conocimientos especializados para ejecutar los servicios de WSFC correctamente, especialmente cuando se trata de actualizaciones, parches y tareas operativas generales.
Contrastando vSphere HA con WSFC, la sobrecarga operativa es mínima en comparación con WSFC. Hay pocas posibilidades de que la HA se configure de forma incorrecta, ya que se habilita o no en un clúster. Con WSFC, hay muchas consideraciones que deben hacerse al configurar WSFC para evitar errores de configuración e implementación. Piense en lo siguiente:
- La agrupación en clústeres de conmutación por error requiere aplicaciones que admitan la agrupación en clústeres (SQL, etc)
- La agrupación en clústeres de conmutación por error requiere que el quórum esté configurado correctamente
- No es compatible con muchos sistemas operativos y aplicaciones heredados
- Requiere la complejidad de los nombres de red del clúster, los recursos y las redes
La agrupación en clústeres de conmutación por error de Windows Server se anuncia para proporcionar un tiempo de inactividad casi nulo a nivel de aplicación. Sin embargo, cuando se añaden los conocimientos necesarios para una solución de HA que funcione correctamente, junto con la implementación adecuada de WSFC, los riesgos pueden empezar a superar los beneficios del uso de WSFC para la alta disponibilidad de aplicaciones y servicios. Esto es especialmente cierto cuando para la mayoría de las organizaciones que pueden no necesitar realmente una solución de «tiempo de inactividad cero». Además, su aplicación tiene que estar diseñada para aprovechar WSFC y trabajar correctamente con la tecnología WSFC.
Aunque vSphere HA requiere un reinicio de las máquinas virtuales en un host sano cuando se produce una conmutación por error, no requiere la instalación de software adicional dentro de las máquinas virtuales invitadas, ni configuraciones complejas de tecnologías de clustering adicionales, y las aplicaciones o los SO no tienen que estar diseñados para trabajar con una tecnología de clustering particular.
Los sistemas operativos y las aplicaciones de legado generalmente tienen capacidades limitadas cuando se trata de tecnologías soportadas para proporcionar alta disponibilidad. Por lo tanto, es posible que literalmente no haya opciones nativas para proporcionar la funcionalidad de conmutación por error en el caso de fallos de hardware.
El mecanismo de alta disponibilidad de vSphere HA funciona y es sencillo de implementar, configurar y gestionar. Además, se trata de una tecnología bien probada en miles de entornos de clientes de VMware, por lo que cuenta con un historial estable y largo de implementaciones exitosas.
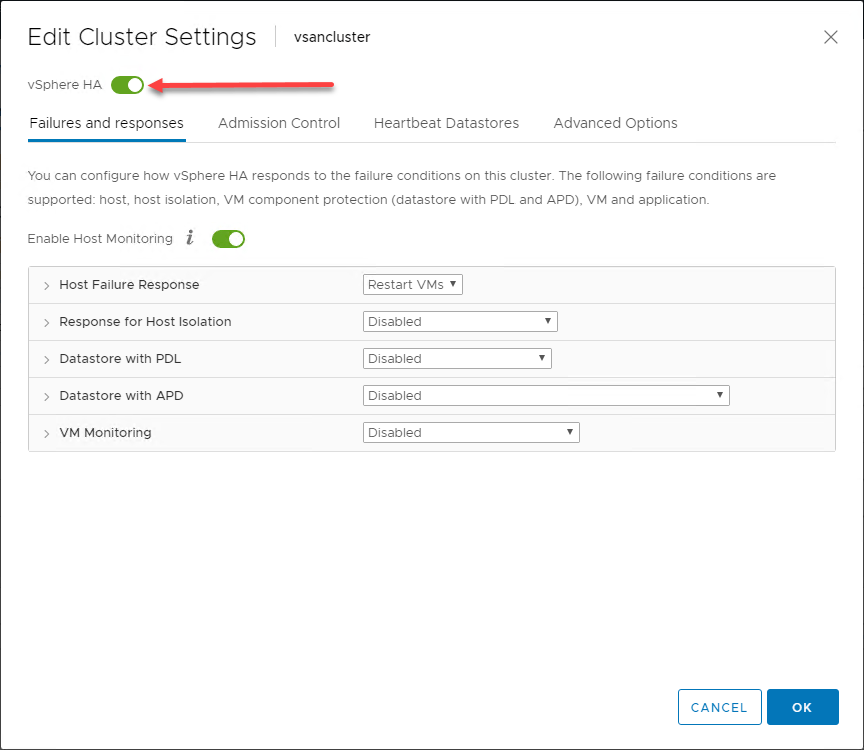
Resumen general del comportamiento de vSphere HA
Aprovechando las ventajas que ofrecen los hosts ESXi en un vSphere Cluster, en su forma más básica, vSphere HA implementa un mecanismo de monitorización entre los hosts del vSphere Cluster. El mecanismo de monitorización proporciona una forma de determinar si algún host del vSphere Cluster ha fallado.
En la infografía siguiente, un vSphere Cluster de dos nodos ha experimentado un fallo en uno de los hosts ESXi del vSphere Cluster. El vSphere Cluster tiene vSphere HA habilitado a nivel de cluster.
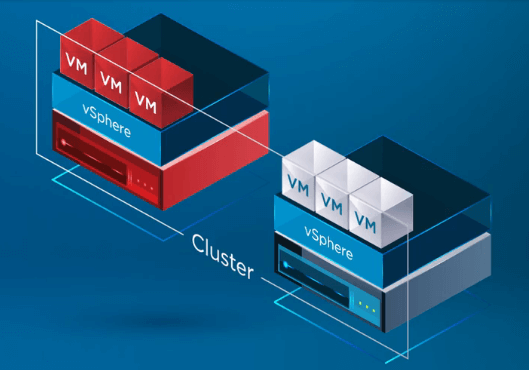
Después de que vSphere HA reconoce que un host del vSphere Cluster ha fallado, el proceso de HA mueve el registro de las VMs del host que ha fallado a un host sano.
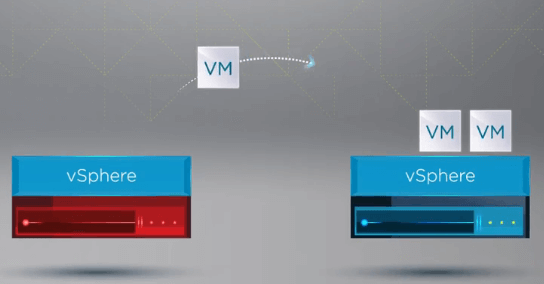
Después de registrar las máquinas virtuales en un host sano, vSphere HA reinicia todas las máquinas virtuales del host que ha fallado en un host ESXi sano del cluster en el que se han vuelto a registrar las máquinas virtuales. El único tiempo de inactividad en el que se incurre es con el reinicio de las VM en un host sano del clúster de vSphere.
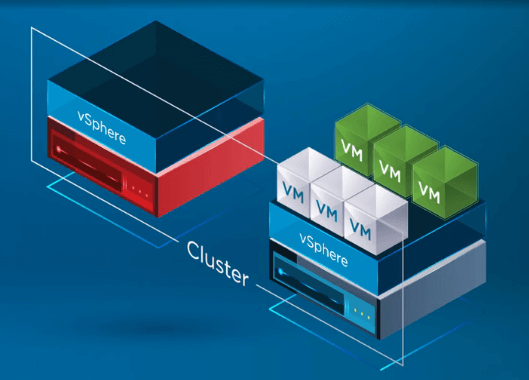
Resumen técnico de vSphere HA
Requisitos previos para vSphere HA
Tal vez se pregunte qué requisitos previos subyacentes pueden ser necesarios para que vSphere HA funcione. ¿Simplemente se necesita un clúster de VMware para activar la HA? A diferencia de Windows Server Failover Clustering, sólo hay unos pocos requisitos que deben estar en su lugar para que HA funcione.
Requisitos:
- Al menos dos hosts ESXi
- Al menos 4 GB de memoria configurados en cada host
- vCenter Server
- Licencia estándar de vSphere
- Almacenamiento compartido para las VMs
- Gateway pingable u otro nodo de red fiable
Si se observa, no se requiere un componente de quórum, no hay nomenclatura de red compleja involucrada, y no hay otros recursos de clúster especiales que necesitan estar en su lugar.
Lea más: Cómo configurar un clúster de alta disponibilidad de vSphere
VMware vSphere HA Master vs Subordinate Hosts
Cuando se habilita vSphere HA en un clúster, se designa un host concreto del clúster de vSphere como maestro de vSphere HA. Los restantes hosts ESXi en el vSphere Cluster se configuran como subordinados en la configuración de vSphere HA.
¿Qué papel desempeña el host ESXi de vSphere HA designado como maestro? El nodo maestro de vSphere HA:
- Monitorea el estado de los hosts subordinados esclavos – Si el host subordinado falla o es inalcanzable, el host maestro identifica qué VMs necesitan ser reiniciadas
- Monitorea el estado de energía de todas las VMs que están protegidas. Si una VM falla, el nodo maestro de vSphere HA se asegura de que la VM se reinicie. El maestro de vSphere HA decide dónde tiene lugar el reinicio de la VM (qué host ESXi).
- Mantiene un registro de todos los hosts del clúster y las VM que están protegidas por vSphere HA
- Se designa como mediador entre el vSphere Cluster y vCenter Server. El maestro de HA informa del estado del clúster a vCenter y proporciona la interfaz de gestión del clúster para vCenter Server
- Puede ejecutar las VM por sí mismo y supervisar el estado de las VM
- Almacena las VM protegidas en los almacenes de datos del clúster
Hosts subordinados de vSphere HA:
- Ejecuta máquinas virtuales localmente
- Supervisa los estados de ejecución de las VM en el clúster de vSphere
- Informa de las actualizaciones de estado al maestro de vSphere HA
Elección del host maestro y fallo del maestro
¿Cómo se selecciona el host maestro de vSphere HA? Cuando se habilita vSphere HA para un clúster, todos los hosts activos (sin modo de mantenimiento, etc.) participan en la elección del host maestro. Si el host maestro elegido falla, se lleva a cabo una nueva elección en la que se elige un nuevo host maestro de HA para cumplir ese papel.
Tipos de fallo de clúster de vSphere HA de VMware
En un clúster habilitado para vSphere HA, hay tres tipos de fallos que pueden ocurrir para desencadenar un evento de conmutación por error de vSphere HA. Esos tipos de fallos de host son:
- Fallo – Un fallo es intuitivamente lo que usted piensa. Un host ha dejado de funcionar de alguna forma o manera debido a problemas de hardware o de otro tipo.
- Aislamiento – El aislamiento de un host generalmente ocurre debido a un evento de red que aísla un host en particular de los otros hosts en el clúster de vSphere HA.
- Partición – Un evento de partición se caracteriza por un host subordinado que pierde la conectividad de red con el host maestro del clúster de vSphere HA.
Corazón, detección de fallas y acciones de falla
¿Cómo determina el nodo maestro si hay una falla de un host en particular?
Hay varios mecanismos diferentes que el nodo maestro utiliza para determinar si un host ha fallado:
- El nodo maestro intercambia heartbeats de red con los otros hosts en el cluster cada segundo.
- Después de que el heartbeat de red ha fallado, el host maestro comprueba la comprobación de vida del host.
- La comprobación de vida del host determina si el host subordinado está intercambiando heartbeats con uno de los datastores. A continuación, envía pings ICMP a sus direcciones IP de gestión
- Si la comunicación directa con el agente de HA de un host subordinado desde el host maestro no es posible y los pings ICMP a la dirección de gestión fallan, el host se considera fallido y las máquinas virtuales se reinician en un host diferente.
- Si se descubre que el host subordinado está intercambiando heartbeats con el datastore, el host maestro asume que el host está en una partición de red o está aislado de la red. En este caso, el maestro simplemente monitoriza el host y las VMs
- El aislamiento de red es el evento en el que un host subordinado está funcionando, pero ya no puede ser visto desde la perspectiva de un agente de gestión de HA en la red de gestión. Si un host deja de ver este tráfico, intenta hacer un ping a las direcciones de aislamiento del clúster. Si este ping falla, el host declara que está aislado de la red
- En este caso, el nodo maestro supervisa las máquinas virtuales que se están ejecutando en el host aislado. Si las VMs se apagan en el host aislado, el nodo maestro reinicia las VMs en otro host
Datastore Heartbeating
Como se mencionó anteriormente, una de las métricas utilizadas para determinar la detección de fallos es el datastore heartbeating. ¿Qué es esto exactamente? VMware vCenter selecciona un conjunto preferido de datastores para el heartbeating. A continuación, vSphere HA crea un directorio en la raíz de cada almacén de datos que se utiliza tanto para el heartbeating del almacén de datos como para mantener la lista de máquinas virtuales protegidas. Este directorio se denomina .vSphere-HA.
Hay una nota importante a recordar con respecto a los datastores vSAN. Un datastore vSAN no se puede utilizar para el latido del datastore. Si sólo tiene un datastore vSAN disponible, no puede haber datastores heartbeat utilizados.
- Monitorización de VM y aplicaciones
Otra característica extremadamente potente de vSphere HA es la capacidad de monitorizar máquinas virtuales individuales a través de VMware Tools y reiniciar cualquier máquina virtual que no responda a los latidos de VMware Tools. La monitorización de aplicaciones puede reiniciar una VM si no se reciben los latidos de una aplicación que se está ejecutando.
- Monitorización de VM – Con la monitorización de VM, el servicio de monitorización de VM utiliza VMware Tools para determinar si cada VM se está ejecutando mediante la comprobación de los latidos del corazón y la E/S del disco generada por VMware Tools. En caso de que estas comprobaciones fallen, el servicio VM Monitoring determina que lo más probable es que el sistema operativo invitado haya fallado y la VM se reinicie. La comprobación adicional de E/S de disco ayuda a evitar cualquier reinicio innecesario de la VM si las VM o las aplicaciones siguen funcionando correctamente.
Monitoreo de aplicaciones: la función de monitoreo de aplicaciones se habilita obteniendo el SDK apropiado de un proveedor de software de terceros que permite configurar latidos personalizados para que las aplicaciones sean monitoreadas por el proceso de vSphere HA. Al igual que el proceso de monitorización de la VM, si los latidos de la aplicación dejan de recibirse, la VM se reinicia.
Ambas funciones de monitorización pueden configurarse aún más con la sensibilidad de la monitorización y también con los reinicios máximos por VM para ayudar a evitar el reinicio de VMs repetidamente por errores de software o falsos positivos.
VMware vSphere HA es una gran manera de asegurar que su vSphere Cluster proporciona una alta disponibilidad muy resistente para proteger contra los fallos generales de los hosts ESXi en su vSphere Cluster.
¿Qué hay de asegurar el uso eficiente de los recursos en su vSphere Cluster? Echemos un vistazo a la siguiente provisión de vSphere Cluster para ayudar a garantizar el uso eficiente de los recursos y la capacidad de su vSphere Cluster.
¿Qué es DRS en VMware?
VMware Distributed Resource Scheduler (DRS) es una característica realmente potente cuando se ejecutan vSphere Clusters. Proporciona la programación y el equilibrio de carga a través de un vSphere Cluster. VMware DRS es la función que se encuentra en vSphere Clusters y que garantiza que las máquinas virtuales que se ejecutan dentro de su entorno vSphere reciban los recursos que necesitan para ejecutarse de forma eficaz y eficiente.
Las máquinas virtuales generalmente están sujetas a DRS desde el principio, ya que desde su primer encendido en un clúster habilitado para DRS, éste coloca las máquinas virtuales en el mejor host configurado para proporcionar los recursos necesarios a la máquina virtual tan pronto como se enciende. Además, DRS se esfuerza por mantener los clústeres de vSphere equilibrados desde una perspectiva de uso de recursos.
Aunque un vSphere Cluster esté equilibrado en un momento determinado, las VMs pueden moverse o cambiar de tal manera que un desequilibrio de los recursos del cluster puede volver a aparecer en el entorno. Cuando los clusters se desequilibran, puede ser perjudicial para el rendimiento general de las máquinas virtuales que se ejecutan en un vSphere Cluster.
Por defecto, DRS se ejecuta automáticamente en un clúster de vSphere cada cinco minutos para determinar el equilibrio de un Clúster de vSphere y ver si es necesario realizar algún cambio para hacer un uso más eficaz de los recursos.
Requisitos de VMware DRS
Para aprovechar VMware DRS, hay varios requisitos que deben cumplirse para asegurar el aprovechamiento de la funcionalidad del Programador de Recursos Distribuidos. Estos incluyen:
- Un cluster de hosts ESXi
- vCenter Server
- Licencia Enterprise Plus
- vMotion es necesario para el balanceo de carga automático
Leer más: Cómo configurar un clúster de vSphere DRS
Acciones de VMware DRS
Cuando VMware DRS se ejecuta en un clúster de vSphere cada cinco minutos, determina si existen desequilibrios en el clúster. Si es así, se realizará un vMotion para mover las VMs designadas de un host ESXi a otro.
¿Cómo determina exactamente DRS si las máquinas virtuales son más adecuadas en un host ESXi o en otro?
DRS ejecuta un algoritmo especial para determinar el host ESXi adecuado que debe albergar una VM concreta. Cuando se enciende una VM, este algoritmo tiene en cuenta la distribución de recursos en todo el clúster de vSphere después de asegurarse de que no se produzcan violaciones de las restricciones si se coloca una VM concreta en un host ESXi determinado.
Además, se tiene en cuenta la demanda de la propia VM, por lo que es de esperar que la VM nunca se quede sin recursos cuando se encienda. ¿Qué se incluye en la demanda de la VM? La demanda de una VM incluye la cantidad de recursos necesarios para funcionar.
- Para la demanda de CPU, se calcula en base a la cantidad de CPU que la VM está consumiendo actualmente
- Para la memoria, la demanda se calcula en base a la fórmula: Demanda de memoria de la VM = Función(Memoria activa utilizada, Intercambiada, Compartida) + 25% (memoria consumida en reposo). Esto muestra que el equilibrio de la memoria DRS se basa principalmente en el uso de la memoria activa de una VM, mientras que considera una pequeña cantidad de su memoria consumida ociosa como un colchón para cualquier aumento de la carga de trabajo.
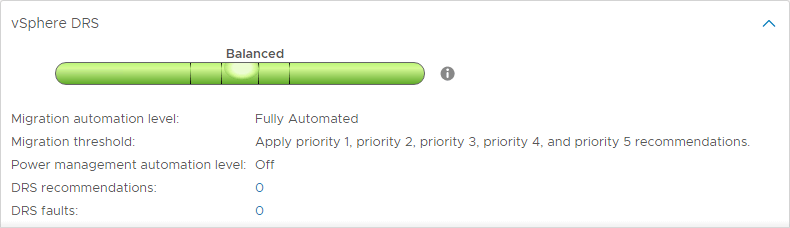
Niveles de automatización de DRS
Una de las características interesantes de DRS son los niveles de automatización de DRS. Mientras que DRS sigue escaneando el clúster de vSphere y proporcionando recomendaciones cada 5 minutos, usted puede determinar si DRS es capaz de promulgar sus recomendaciones de forma automática o sólo sugerir los cambios que se deben hacer. DRS tiene tres niveles de automatización de DRS. Estos incluyen:
- Totalmente automatizado – En el enfoque totalmente automatizado, DRS aplica tanto la colocación inicial como las recomendaciones de equilibrio de carga de forma automática
- Parcialmente automatizado – Con la automatización parcial, DRS aplica las recomendaciones sólo para la colocación inicial de las VM
- Manual – En el modo manual, debe aplicar las recomendaciones tanto para la colocación inicial como para las recomendaciones de equilibrio de carga
Umbrales de migración de DRS
DRS incluye otro ajuste muy útil para controlar la cantidad de desequilibrio que se tolerará antes de que se hagan las recomendaciones de DRS. Hay cinco umbrales de migración DRS para controlar la cantidad de desequilibrio tolerado.
El rango es de 1 (más conservador) a 5 (más agresivo).
Con ajustes más agresivos, DRS tolera menos desequilibrio en un cluster. Cuanto más conservador, más DRS tolera el desequilibrio.

Reglas de VM/Host de VMware DRS
Hay una característica extremadamente útil que se encuentra cuando se utiliza VMware DRS para controlar la colocación de las VM en sus clusters habilitados para vSphere DRS. Las reglas VM/Host le permiten ejecutar VMs específicas en un host ESXi específico. Puede pensar en esto como reglas de afinidad en cierto modo.
Las reglas VM/Host le permiten:
- Mantener máquinas virtuales juntas
- Separar máquinas virtuales
- Atar máquinas virtuales a hosts específicos
- Atar máquinas virtuales a máquinas virtuales
A continuación se muestra un ejemplo de creación de una regla VM/Host para máquinas virtuales y hosts ESXi.
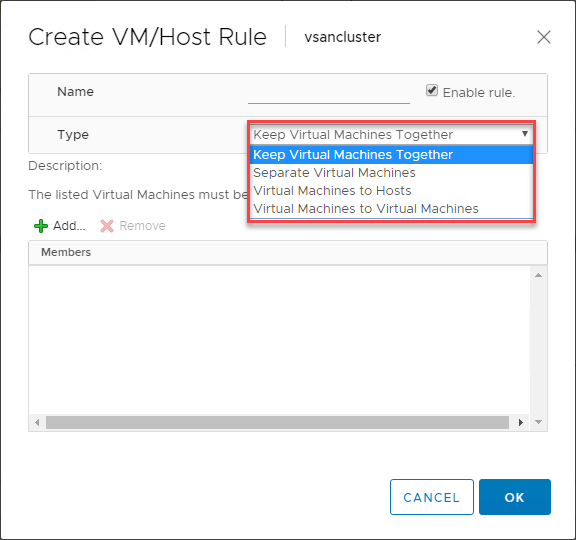
¿Qué tipo de caso de uso existe para estas reglas VM/Host? Uno de los casos de uso clásicos que existen es con los controladores de dominio. En general, si está ejecutando todos sus controladores de dominio en un entorno virtualizado como un Clúster vSphere, querrá asegurarse de tener las máquinas virtuales de los controladores de dominio separadas unas de otras dentro del clúster. De esta manera, si tiene un host ESXi que se cae junto con uno de sus controladores de dominio, todavía tiene un controlador de dominio que está sujeto a una regla de Máquinas Virtuales Separadas que lo mantiene fuera del mismo host que otro DC.
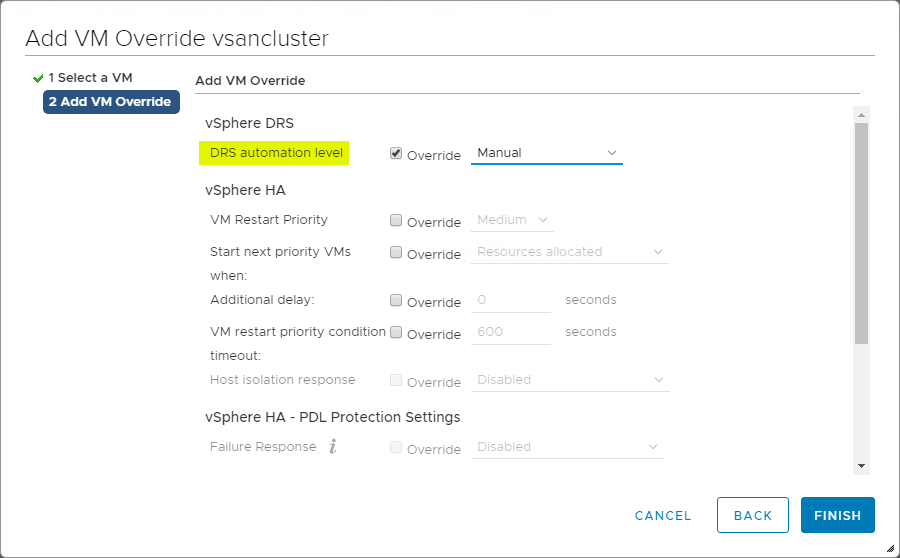
VM Overrides para DRS
El vSphere Cluster proporciona una granularidad para las operaciones que afectan a las máquinas virtuales individuales dentro del vSphere Cluster. Puede crear VM Overrides para anular las configuraciones globales establecidas a nivel de clúster para HA y DRS para definir configuraciones más específicas para cada VM individual.
Resumen de utilización de CPU y memoria
DRS proporciona una gran vista de alto nivel del resumen de utilización de CPU de los recursos de CPU de los hosts ESXi en el vSphere Cluster. Navegue a > Ajustes > Monitor > vSphere DRS > Utilización de la CPU.
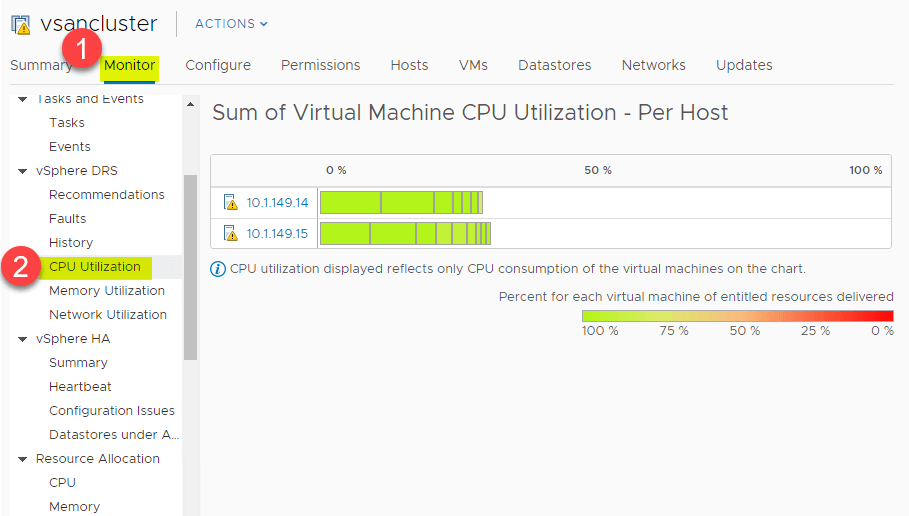
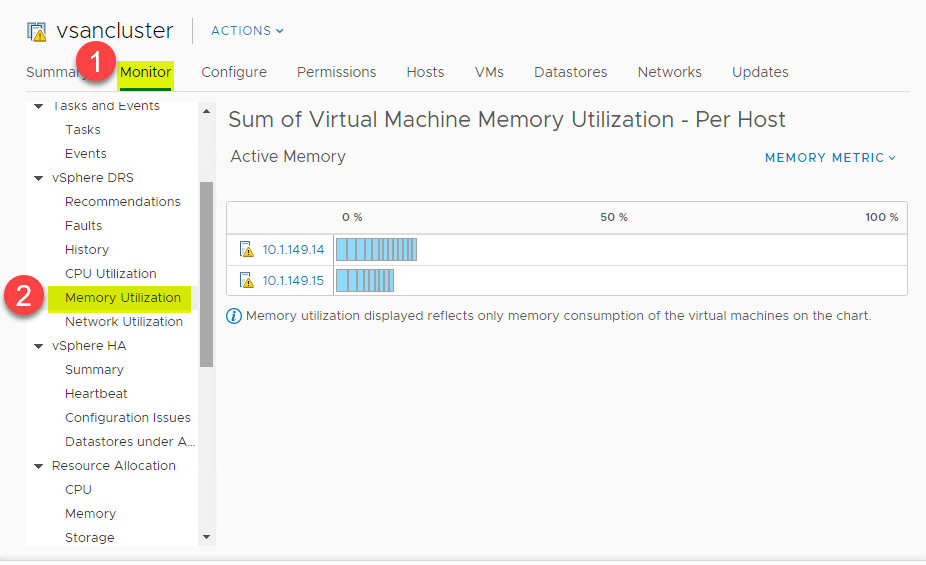
La misma visión general de alto nivel se puede ver para el consumo de memoria también. Navegue a > Configuración > Monitor > vSphere DRS > Utilización de la memoria
Lo mejor de ambos mundos
¿Es VMware vSphere HA y VMware DRS tecnologías que compiten?
No, no lo son. De hecho, es muy recomendable utilizar tanto vSphere HA como VMware DRS juntos para combinar la conmutación por error automática con las características y la funcionalidad de equilibrio de carga. Esto da como resultado un entorno vSphere mucho más resistente y más equilibrado.
Si se produce un fallo en un host ESXi, vSphere HA reiniciará las máquinas virtuales en los restantes hosts sanos de un vSphere Cluster. Así, la primera prioridad, por supuesto, es la disponibilidad de los recursos de las máquinas virtuales. A continuación, VMware DRS se ejecutará y determinará si existe algún desequilibrio entre los hosts ESXi que ejecutan las cargas de trabajo y hará recomendaciones para resolver cualquier desequilibrio en el clúster basándose en el umbral de migración configurado. En función del nivel de automatización, estas recomendaciones se ejecutarán automáticamente o sólo se recomendarán si no están totalmente automatizadas.
Pensamientos finales sobre VMware vSphere HA y DRS
Se recomienda encarecidamente ejecutar tanto VMware vSphere HA como DRS en un clúster vSphere de producción. El uso de ambas tecnologías ayuda a que sus cargas de trabajo estén altamente disponibles y asegura que tengan continuamente los recursos necesarios en función de las demandas de CPU/memoria de la VM.
Entender cómo funcionan ambos mecanismos le ayuda como administrador de vSphere a aprovechar ambas tecnologías de la mejor manera posible y de acuerdo con las mejores prácticas. Entre los beneficios que ambas tecnologías aportan, cada característica es extremadamente fácil de habilitar y configurar. Con unos simples clics en las propiedades de sus vSphere Clusters, puede empezar a beneficiarse rápidamente de estas características disponibles a nivel de cluster.
Siga nuestros feeds de Twitter y Facebook para obtener nuevos lanzamientos, actualizaciones, publicaciones perspicaces y mucho más.