Overview
- Aprende a interpretar el Bias y la Varianza en un modelo dado.
- ¿Cuál es la diferencia entre Sesgo y Varianza?
- Cómo lograr el equilibrio entre Sesgo y Varianza utilizando el flujo de trabajo de Aprendizaje Automático
Introducción
Hablemos del tiempo. Sólo llueve si hay un poco de humedad y no llueve si hace viento, calor o frío. En este caso, ¿cómo entrenarías un modelo predictivo y te asegurarías de que no hay errores en la predicción del tiempo? Se puede decir que hay muchos algoritmos de aprendizaje entre los que elegir. Son distintos en muchos aspectos, pero hay una gran diferencia en lo que esperamos y lo que el modelo predice. Ese es el concepto de Bias and Variance Tradeoff.
Por lo general, el Bias and Variance Tradeoff se enseña a través de densas fórmulas matemáticas. Pero en este artículo, he intentado explicar el sesgo y la varianza de la forma más sencilla posible.
Me centraré en hacerle girar a través del proceso de comprensión del planteamiento del problema y asegurarme de que elige el mejor modelo en el que los errores de sesgo y varianza son mínimos.
Para ello, he tomado el popular conjunto de datos de la diabetes de los indios Pima. El conjunto de datos consiste en mediciones de diagnóstico de pacientes mujeres adultas de la herencia indígena Pima. Para este conjunto de datos, vamos a centrarnos en la variable «Outcome», que indica si el paciente tiene diabetes o no. Evidentemente, se trata de un problema de clasificación binaria y vamos a sumergirnos de lleno en él para aprender cómo llevarlo a cabo.
Si te interesa esto y los conceptos de ciencia de datos y quieres aprender de forma práctica consulta nuestro curso- Introducción a la ciencia de datos
Tabla de contenidos
- Evaluación de un modelo de aprendizaje automático
- Enunciado del problema y pasos principales
- ¿Qué es el sesgo?
- ¿Qué es la varianza?
- Compensación entre sesgo y varianza
Evaluación del modelo de aprendizaje automático
El objetivo principal del modelo de aprendizaje automático es aprender de los datos dados y generar predicciones basadas en el patrón observado durante el proceso de aprendizaje. Sin embargo, nuestra tarea no termina ahí. Tenemos que introducir continuamente mejoras en los modelos, basándonos en el tipo de resultados que genera. También cuantificamos el rendimiento del modelo utilizando métricas como la precisión, el error cuadrático medio (MSE), la puntuación F1, etc., e intentamos mejorar estas métricas. Esto a menudo puede ser complicado cuando tenemos que mantener la flexibilidad del modelo sin comprometer su corrección.
Un modelo de aprendizaje automático supervisado tiene como objetivo entrenarse en las variables de entrada (X) de tal manera que los valores predichos (Y) sean lo más cercanos a los valores reales. Esta diferencia entre los valores reales y los valores predichos es el error y se utiliza para evaluar el modelo. El error de cualquier algoritmo de aprendizaje automático supervisado se compone de 3 partes:
- Error de sesgo
- Error de varianza
- El ruido
Mientras que el ruido es el error irreducible que no podemos eliminar, los otros dos, es decir, el sesgo y la varianza, se pueden utilizar.En las siguientes secciones, cubriremos el error de sesgo, el error de varianza y el equilibrio entre sesgo y varianza, que nos ayudarán a seleccionar el mejor modelo. Y lo que es emocionante es que vamos a cubrir algunas técnicas para hacer frente a estos errores mediante el uso de un conjunto de datos de ejemplo.
Enunciado del problema y pasos primarios
Como se explicó anteriormente, hemos tomado el conjunto de datos de la diabetes de los indios Pima y formamos un problema de clasificación en él. Empecemos por calibrar el conjunto de datos y observar el tipo de datos con el que estamos tratando. Para ello, importaremos las bibliotecas necesarias:
Ahora, cargaremos los datos en un marco de datos y observaremos algunas filas para obtener información sobre los datos.
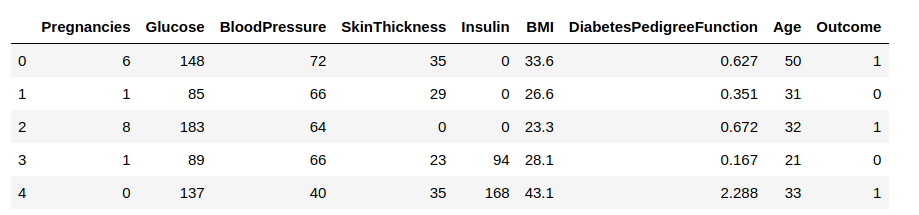
Necesitamos predecir la columna ‘Outcome’. Separémosla y asignémosla a una variable objetivo ‘y’. El resto del marco de datos será el conjunto de variables de entrada X.
Ahora escalemos las variables predictoras y luego separemos los datos de entrenamiento y los de prueba.
Dado que los resultados se clasifican de forma binaria, utilizaremos el clasificador más sencillo K-próximo (Knn) para clasificar si el paciente tiene diabetes o no.
Sin embargo, ¿cómo decidimos el valor de ‘k’?
- ¿Tal vez deberíamos utilizar k = 1 para obtener muy buenos resultados en nuestros datos de entrenamiento? Eso podría funcionar, pero no podemos garantizar que el modelo funcione igual de bien en nuestros datos de prueba, ya que puede volverse demasiado específico
- ¿Qué tal si usamos un valor alto de k, digamos como k = 100 para que podamos considerar un gran número de puntos más cercanos para tener en cuenta también los puntos distantes? Sin embargo, este tipo de modelo será demasiado genérico y no podremos estar seguros de que ha considerado correctamente todas las posibles características que contribuyen a él.
Tomemos unos cuantos valores posibles de k y ajustemos el modelo a los datos de entrenamiento para todos esos valores. También calcularemos la puntuación de entrenamiento y la puntuación de prueba para todos esos valores.
Para obtener más información de esto, representemos los datos de entrenamiento (en rojo) y los datos de prueba (en azul).
Para calcular las puntuaciones para un valor concreto de k,
![]()
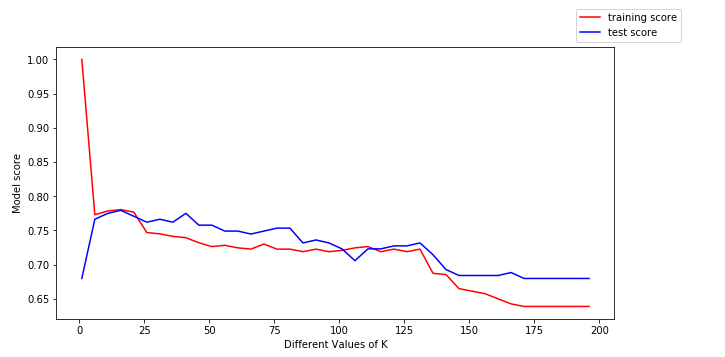
Podemos sacar las siguientes conclusiones del gráfico anterior:
- Para valores bajos de k, la puntuación de entrenamiento es alta, mientras que la puntuación de prueba es baja
- A medida que aumenta el valor de k, la puntuación de prueba empieza a aumentar y la de entrenamiento a disminuir.
- Sin embargo, en algún valor de k, tanto la puntuación de entrenamiento como la de prueba se acercan la una a la otra.
Aquí es donde entran en escena el Sesgo y la Varianza.
¿Qué es el Sesgo?
En los términos más simples, el Sesgo es la diferencia entre el Valor Predicho y el Valor Esperado. Para explicarlo mejor, el modelo hace ciertas suposiciones cuando se entrena con los datos proporcionados. Cuando se introduce en los datos de prueba/validación, estas suposiciones pueden no ser siempre correctas.
En nuestro modelo, si utilizamos un gran número de vecinos más cercanos, el modelo puede decidir totalmente que algunos parámetros no son importantes en absoluto. Por ejemplo, puede considerar sólo que el nivel de Glusoce y la Presión Arterial deciden si el paciente tiene diabetes. Este modelo haría suposiciones muy fuertes sobre los otros parámetros que no afectan al resultado. También puede pensar en él como un modelo que predice una relación simple cuando los puntos de datos indican claramente una relación más compleja:
Matemáticamente, dejemos que las variables de entrada sean X y una variable objetivo Y. Trazamos la relación entre las dos utilizando una función f.
Por lo tanto,
Y = f(X) + e
Aquí ‘e’ es el error que se distribuye normalmente. El objetivo de nuestro modelo f'(x) es predecir valores tan cercanos a f(x) como sea posible. Aquí, el Bias del modelo es:
Bias = E
Como he explicado anteriormente, cuando el modelo hace las generalizaciones es decir, cuando hay un error de sesgo alto, resulta en un modelo muy simplista que no considera las variaciones muy bien. Como no aprende muy bien los datos de entrenamiento, se llama Underfitting.
¿Qué es una Varianza?
Al contrario que el sesgo, la Varianza es cuando el modelo tiene en cuenta las fluctuaciones de los datos es decir, el ruido también. Entonces, ¿qué ocurre cuando nuestro modelo tiene una varianza alta?
El modelo seguirá considerando la varianza como algo de lo que aprender. Es decir, el modelo aprende demasiado de los datos de entrenamiento, hasta el punto de que cuando se enfrenta a nuevos datos (de prueba), es incapaz de predecir con exactitud basándose en ellos.
Matemáticamente, el error de varianza en el modelo es:
Varianza-E^2
Dado que en el caso de una varianza alta, el modelo aprende demasiado de los datos de entrenamiento, se llama sobreajuste.
En el contexto de nuestros datos, si utilizamos muy pocos vecinos más cercanos, es como decir que si el número de embarazos es superior a 3, el nivel de glucosa es superior a 78, la PA diastólica es inferior a 98, el grosor de la piel es inferior a 23 mm y así sucesivamente para cada característica….. decidir que el paciente tiene diabetes. Todos los demás pacientes que no cumplen los criterios anteriores no son diabéticos. Aunque esto puede ser cierto para un paciente concreto del conjunto de entrenamiento, ¿qué ocurre si estos parámetros son los valores atípicos o incluso se registraron incorrectamente? Evidentemente, este modelo podría resultar muy costoso.
Además, este modelo tendría un alto error de varianza porque las predicciones de que el paciente es diabético o no varían mucho con el tipo de datos de entrenamiento que le estamos proporcionando. Así, incluso cambiando el nivel de glucosa a 75, el modelo predeciría que el paciente no tiene diabetes.
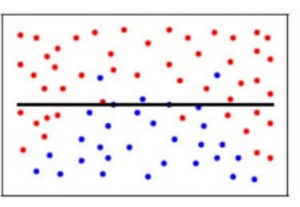
Para simplificar, el modelo predice relaciones muy complejas entre el resultado y las características de entrada, cuando habría bastado con una ecuación cuadrática. Así es como se vería un modelo de clasificación cuando hay un error de varianza alto/cuando hay sobreajuste:
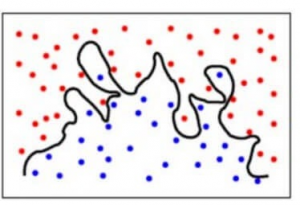
En resumen,
- Un modelo con un alto error de sesgo no se ajusta a los datos y hace suposiciones muy simplistas sobre ellos
- Un modelo con un alto error de varianza se ajusta en exceso a los datos y aprende demasiado de ellos
- Un buen modelo es aquel en el que tanto el error de sesgo como el de varianza están equilibrados
Compensación entre sesgo y varianza
¿Cómo relacionamos los conceptos anteriores con nuestro modelo Knn de antes? Averigüémoslo
En nuestro modelo, digamos, para, k = 1, se considerará el punto más cercano al punto de datos en cuestión. Aquí, la predicción podría ser precisa para ese punto de datos en particular, por lo que el error de sesgo será menor.
Sin embargo, el error de varianza será alto ya que sólo se considera el punto más cercano y esto no tiene en cuenta los otros puntos posibles. ¿A qué escenario crees que corresponde esto? Sí, estás pensando bien, esto significa que nuestro modelo está sobreajustado.
Por otro lado, para valores más altos de k, se considerarán muchos más puntos más cercanos al punto de datos en cuestión. Esto daría lugar a un mayor error de sesgo y a un infraajuste, ya que se consideran muchos puntos más cercanos al punto de datos y, por lo tanto, no puede aprender los aspectos específicos del conjunto de entrenamiento. Sin embargo, podemos tener en cuenta un error de varianza más bajo para el conjunto de pruebas que tiene valores desconocidos.
Para lograr un equilibrio entre el error de sesgo y el error de varianza, necesitamos un valor de k tal que el modelo no aprenda del ruido (sobreajuste de los datos) ni haga suposiciones radicales sobre los datos (infraajuste de los datos). Para simplificar, un modelo equilibrado sería así:
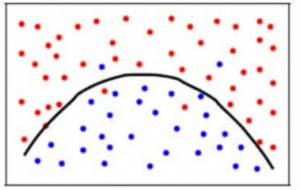
Aunque algunos puntos se clasifican incorrectamente, el modelo generalmente se ajusta a la mayoría de los puntos de datos con precisión. El equilibrio entre el error de sesgo y el error de varianza es la compensación entre sesgo y varianza.
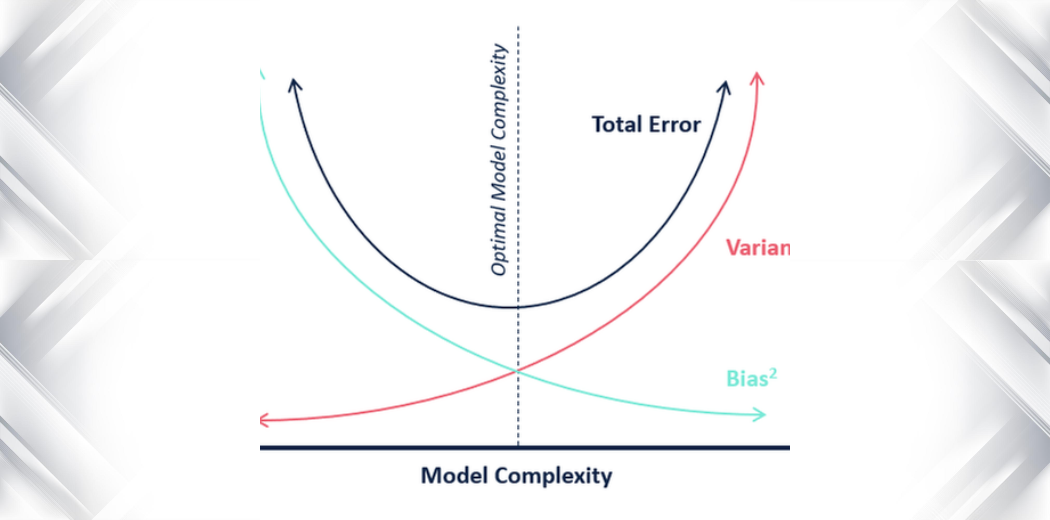
El siguiente diagrama de ojo de buey explica mejor la compensación:
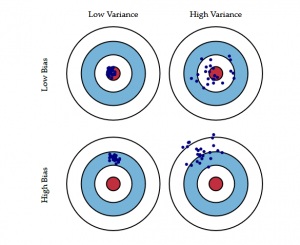
El centro, es decir, el ojo de buey, es el resultado del modelo que queremos conseguir y que predice perfectamente todos los valores de forma correcta. A medida que nos alejamos del ojo de buey, nuestro modelo empieza a hacer predicciones cada vez más erróneas.
Un modelo con bajo sesgo y alta varianza predice puntos que están alrededor del centro generalmente, pero bastante alejados entre sí. Un modelo con alto sesgo y baja varianza está bastante lejos de la diana, pero como la varianza es baja, los puntos predichos están más cerca unos de otros.
En términos de complejidad del modelo, podemos utilizar el siguiente diagrama para decidir la complejidad óptima de nuestro modelo.
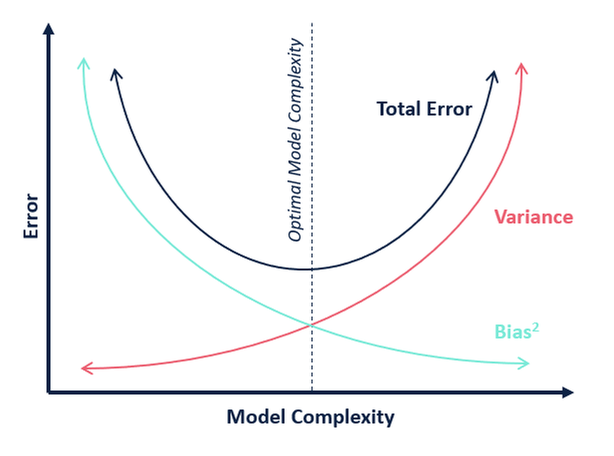
Entonces, ¿cuál crees que es el valor óptimo de k?
De la explicación anterior, podemos concluir que el k para el que
- la puntuación de las pruebas es la más alta, y
- tanto la puntuación de las pruebas como la de los entrenamientos están cerca entre sí
es el valor óptimo de k. Por lo tanto, a pesar de que estamos comprometiéndonos con una puntuación de entrenamiento más baja, seguimos obteniendo una puntuación alta para nuestros datos de prueba, lo que es más crucial – los datos de prueba son, después de todo, datos desconocidos.
Hagamos una tabla para diferentes valores de k para demostrar aún más esto:
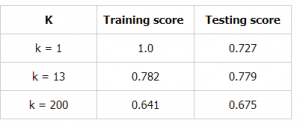
Conclusión
Para resumir, en este artículo, hemos aprendido que un modelo ideal sería aquel en el que tanto el error de sesgo como el error de varianza son bajos. Sin embargo, siempre debemos aspirar a un modelo en el que la puntuación del modelo para los datos de entrenamiento sea lo más cercana posible a la puntuación del modelo para los datos de prueba.
Ahí descubrimos cómo elegir un modelo que no sea demasiado complejo (alta varianza y bajo sesgo), lo que llevaría a un sobreajuste, y tampoco demasiado simple (alto sesgo y baja varianza), lo que llevaría a un infraajuste.
El sesgo y la varianza juegan un papel importante a la hora de decidir qué modelo predictivo utilizar. Espero que este artículo haya explicado bien el concepto.