
Si quieres aprender más en Python, haz el curso gratuito Intro to Python for Data Science de DataCamp.
Todos habéis visto conjuntos de datos. A veces son pequeños, pero a menudo en ocasiones, son tremendamente grandes en tamaño. Se vuelve muy desafiante procesar los conjuntos de datos que son muy grandes, al menos lo suficientemente significativos como para causar un cuello de botella de procesamiento.
Entonces, ¿qué hace que estos conjuntos de datos sean tan grandes? Bueno, son las características. Cuanto mayor sea el número de características, más grandes serán los conjuntos de datos. Bueno, no siempre. Encontrarás conjuntos de datos en los que el número de características es muy grande, pero no contienen tantas instancias. Pero ese no es el punto de discusión aquí. Por lo tanto, es posible que se pregunte, con un ordenador básico en la mano, cómo procesar este tipo de conjuntos de datos sin irse por las ramas.
A menudo, en un conjunto de datos de alta dimensión, quedan algunas características totalmente irrelevantes, insignificantes y sin importancia. Se ha visto que la contribución de este tipo de características es a menudo menor hacia el modelado predictivo en comparación con las características críticas. También pueden tener una contribución nula. Estas características causan una serie de problemas que a su vez impide el proceso de modelado predictivo eficiente –
- Asignación de recursos innecesarios para estas características.
- Estas características actúan como un ruido para el que el modelo de aprendizaje de la máquina puede realizar terriblemente mal.
- El modelo de la máquina toma más tiempo para ser entrenado.
Entonces, ¿cuál es la solución aquí? La solución más económica es la selección de características.
La selección de características es el proceso de selección de las características más significativas de un conjunto de datos dado. En muchos de los casos, la selección de características puede mejorar el rendimiento de un modelo de aprendizaje automático también.
Suena interesante derecho?
Tienes una introducción informal a la selección de características y su importancia en el mundo de la ciencia de datos y aprendizaje automático. En este post vas a cubrir:
- Introducción a la selección de características y entender su importancia
- Diferencia entre selección de características y reducción de dimensionalidad
- Diferentes tipos de métodos de selección de características
- Implementación de diferentes métodos de selección de características con scikit-learn
Introducción a la selección de características
La selección de características también se conoce como Selección de variables o Selección de atributos.
Esencialmente, es el proceso de selección de las más importantes/relevantes. Características de un conjunto de datos.
Entender la importancia de la selección de características
La importancia de la selección de características se puede reconocer mejor cuando se trata de un conjunto de datos que contiene un gran número de características. Este tipo de conjunto de datos suele denominarse conjunto de datos de alta dimensionalidad. Ahora, con esta alta dimensionalidad, viene un montón de problemas tales como – esta alta dimensionalidad aumentará significativamente el tiempo de entrenamiento de su modelo de aprendizaje automático, puede hacer que su modelo sea muy complicado que a su vez puede conducir a Overfitting.
A menudo en un conjunto de características de alta dimensión, quedan varias características que son redundantes lo que significa que estas características no son más que extensiones de las otras características esenciales. Estas características redundantes no contribuyen eficazmente al entrenamiento del modelo. Así que, claramente, hay una necesidad de extraer las características más importantes y más relevantes para un conjunto de datos con el fin de obtener el rendimiento de modelado predictivo más eficaz.
«El objetivo de la selección de variables es triple: mejorar el rendimiento de predicción de los predictores, proporcionar predictores más rápidos y más rentables, y proporcionar una mejor comprensión del proceso subyacente que generó los datos.»
Una introducción a la selección de variables y características
Ahora vamos a entender la diferencia entre la reducción de la dimensionalidad y la selección de características.
A veces, la selección de características se confunde con la reducción de la dimensionalidad. Pero son diferentes. La selección de características es diferente de la reducción de la dimensionalidad. Ambos métodos tienden a reducir el número de atributos en el conjunto de datos, pero un método de reducción de la dimensionalidad lo hace creando nuevas combinaciones de atributos (a veces conocido como transformación de características), mientras que los métodos de selección de características incluyen y excluyen atributos presentes en los datos sin cambiarlos.
Algunos ejemplos de métodos de reducción de la dimensionalidad son el análisis de componentes principales, la descomposición del valor singular, el análisis discriminante lineal, etc.
Déjeme resumirle la importancia de la selección de características:
- Permite que el algoritmo de aprendizaje automático se entrene más rápidamente.
- Reduce la complejidad de un modelo y lo hace más fácil de interpretar.
- Mejora la precisión de un modelo si se elige el subconjunto adecuado.
- Reduce el sobreajuste.
En la siguiente sección, estudiará los diferentes tipos de métodos de selección de características generales – Métodos de filtro, Métodos de envoltura y Métodos incrustados.
Métodos de filtro
La siguiente imagen describe mejor los métodos de selección de características basados en el filtro:

Fuente de la imagen: Analytics Vidhya
El método del filtro se basa en la unicidad general de los datos a evaluar y escoger el subconjunto de características, sin incluir ningún algoritmo de minería. El método de filtro utiliza el criterio de evaluación exacta que incluye la distancia, la información, la dependencia y la consistencia. El método de filtrado utiliza los criterios principales de la técnica de clasificación y utiliza el método de ordenación por rango para la selección de variables. La razón por la que se utiliza el método de clasificación es la simplicidad, la producción de características excelentes y relevantes. El método de clasificación filtrará las características irrelevantes antes de que comience el proceso de clasificación.
Los métodos de filtrado se utilizan generalmente como un paso de preprocesamiento de datos. La selección de características es independiente de cualquier algoritmo de aprendizaje automático. Las características se clasifican sobre la base de puntuaciones estadísticas que tienden a determinar la correlación de las características con la variable de resultado. La correlación es un término muy contextual, y varía de un trabajo a otro. Puede consultar la siguiente tabla para definir los coeficientes de correlación para diferentes tipos de datos (en este caso continuos y categóricos).

Fuente de la imagen: Analytics Vidhya
Algunos ejemplos de algunos métodos de filtrado incluyen la prueba de Chi-cuadrado, la ganancia de información y las puntuaciones del coeficiente de correlación.
A continuación, verás los métodos Wrapper.
Métodos de envoltura
Al igual que los métodos de filtro, permítanme darles un mismo tipo de infográfico que les ayudará a entender mejor los métodos de envoltura:
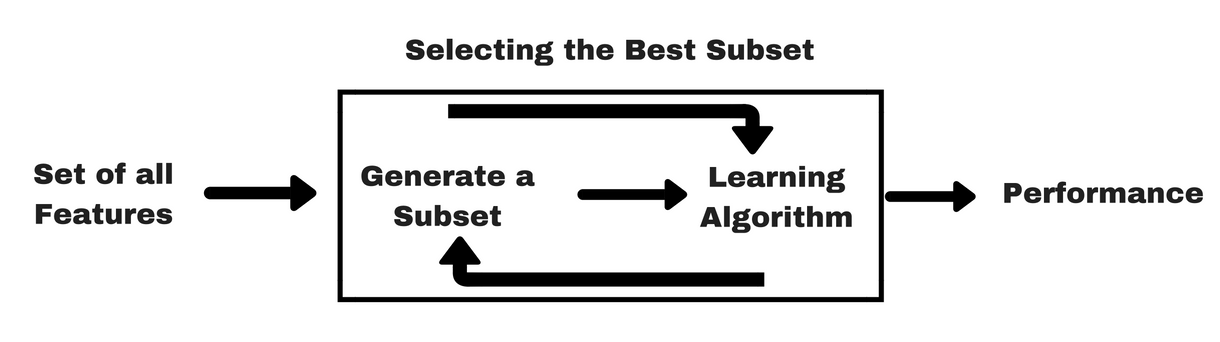
Fuente de la imagen: Analytics Vidhya
Como puedes ver en la imagen anterior, un método wrapper necesita un algoritmo de aprendizaje automático y utiliza su rendimiento como criterio de evaluación. Este método busca una característica que se adapte mejor al algoritmo de aprendizaje automático y tiene como objetivo mejorar el rendimiento de la minería. Para evaluar las características, la precisión predictiva utilizada para las tareas de clasificación y la bondad de la agrupación se evalúa utilizando la agrupación.
Algunos ejemplos típicos de métodos de envoltura son la selección de características hacia adelante, la eliminación de características hacia atrás, la eliminación de características recursivas, etc.
- Selección hacia adelante: El procedimiento comienza con un conjunto vacío de características . Se determina la mejor de las características originales y se añade al conjunto reducido. En cada iteración posterior, se añade al conjunto el mejor de los atributos originales restantes.
- Eliminación hacia atrás: El procedimiento comienza con el conjunto completo de atributos. En cada paso, elimina el peor atributo que queda en el conjunto.
- Combinación de selección hacia delante y eliminación hacia atrás: Los métodos de selección hacia delante y de eliminación hacia atrás pueden combinarse para que, en cada paso, el procedimiento seleccione el mejor atributo y elimine el peor de entre los atributos restantes.
- Eliminación recursiva de características: La eliminación recursiva de características realiza una búsqueda codiciosa para encontrar el subconjunto de características de mejor rendimiento. Crea modelos de forma iterativa y determina la característica de mejor o peor rendimiento en cada iteración. Construye los siguientes modelos con las características restantes hasta que se exploran todas las características. A continuación, clasifica las características en función de su orden de eliminación. En el peor de los casos, si un conjunto de datos contiene N características, RFE hará una búsqueda codiciosa de 2N combinaciones de características.
¡Bastante bien!
Ahora estudiemos los métodos integrados.
Los métodos integrados
Son iterativos en el sentido de que se ocupan de cada iteración del proceso de entrenamiento del modelo y extraen cuidadosamente aquellas características que más contribuyen al entrenamiento para una iteración particular. Los métodos de regularización son los métodos incrustados más utilizados que penalizan una característica dado un umbral de coeficiente.
Por eso los métodos de regularización también se llaman métodos de penalización que introducen restricciones adicionales en la optimización de un algoritmo de predicción (como un algoritmo de regresión) que sesgan el modelo hacia una menor complejidad (menos coeficientes).
Ejemplos de algoritmos de regularización son el LASSO, la Red Elástica, la Regresión Ridge, etc.
Diferencia entre métodos de filtro y métodos wrapper
Bueno, a veces puede resultar confuso diferenciar entre los métodos de filtro y los métodos wrapper en cuanto a sus funcionalidades. Veamos en qué se diferencian.
- Los métodos de filtrado no incorporan un modelo de aprendizaje automático para determinar si una característica es buena o mala mientras que los métodos de envoltura utilizan un modelo de aprendizaje automático y entrenan la característica para decidir si es esencial o no.
- Los métodos de filtrado son mucho más rápidos en comparación con los métodos de envoltura ya que no implican el entrenamiento de los modelos. Por otro lado, los métodos de envoltura son computacionalmente costosos, y en el caso de conjuntos de datos masivos, los métodos de envoltura no son el método de selección de características más eficaz a tener en cuenta.
- Los métodos de filtro pueden no encontrar el mejor subconjunto de características en situaciones en las que no hay suficientes datos para modelar la correlación estadística de las características, pero los métodos de envoltura siempre pueden proporcionar el mejor subconjunto de características debido a su naturaleza exhaustiva.
- Usar las características de los métodos de envoltura en su modelo final de aprendizaje automático puede llevar a un sobreajuste, ya que los métodos de envoltura ya entrenan los modelos de aprendizaje automático con las características y esto afecta al verdadero poder de aprendizaje. Pero las características de los métodos de filtrado no conducirán a un sobreajuste en la mayoría de los casos
Hasta ahora ha estudiado la importancia de la selección de características, entendiendo su diferencia con la reducción de la dimensionalidad. También has cubierto varios tipos de métodos de selección de características. Hasta ahora, todo bien.
Ahora, veamos algunas trampas en las que puedes caer mientras realizas la selección de características:
Consideración importante
Puede que ya hayas entendido el valor de la selección de características en un pipeline de machine learning y el tipo de servicios que proporciona si se integra. Pero es muy importante entender en qué punto exacto debe integrar la selección de características en su pipeline de machine learning.
En términos sencillos, debe incluir el paso de selección de características antes de alimentar los datos al modelo para su entrenamiento, especialmente cuando utiliza métodos de estimación de precisión como la validación cruzada. Esto asegura que la selección de características se realiza en el pliegue de datos justo antes de entrenar el modelo. Pero si realizas la selección de características primero para preparar tus datos, y luego realizas la selección del modelo y el entrenamiento en las características seleccionadas, entonces sería un error garrafal.
Si realizas la selección de características en todos los datos y luego la validación cruzada, entonces los datos de prueba en cada pliegue del procedimiento de validación cruzada también se utilizaron para elegir las características, y esto tiende a sesgar el rendimiento de tu modelo de aprendizaje automático.
¡Basta de teorías! Vamos a pasar directamente a la codificación.
Un caso de estudio en Python
Para este caso de estudio, se utilizará el conjunto de datos Pima Indians Diabetes. La descripción del conjunto de datos se puede encontrar aquí.
El conjunto de datos corresponde a tareas de clasificación en las que tienes que predecir si una persona tiene diabetes en base a 8 características.
Hay un total de 768 observaciones en el conjunto de datos. Su primera tarea es cargar el conjunto de datos para poder proceder. Pero antes de eso vamos a importar las dependencias necesarias, usted va a necesitar. Usted puede importar los otros a medida que avanza.
import pandas as pdimport numpy as npAhora que las dependencias se importan vamos a cargar el conjunto de datos de los indios Pima en un objeto Dataframe con la ayuda de la biblioteca Pandas.
data = pd.read_csv("diabetes.csv")El conjunto de datos se carga con éxito en los datos del objeto Dataframe. Ahora, vamos a echar un vistazo a los datos.
data.head()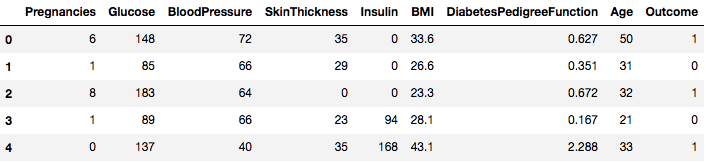
Así que usted puede ver 8 características diferentes etiquetados en los resultados de 1 y 0 donde 1 significa que la observación tiene diabetes, y 0 denota la observación no tiene diabetes. Se sabe que el conjunto de datos tiene valores perdidos. En concreto, hay observaciones que faltan para algunas columnas que están marcadas como un valor cero. Se puede deducir esto por la definición de esas columnas, y es poco práctico tener un valor cero no es válido para esas medidas, por ejemplo cero para el índice de masa corporal o la presión arterial es inválido.
Pero para este tutorial, utilizará directamente la versión preprocesada del conjunto de datos.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Ahora ha cargado los datos en un objeto DataFrame llamado dataframe.
Convirtamos el objeto DataFrame en una matriz NumPy para lograr un cálculo más rápido. Además, vamos a segregar los datos en variables separadas para que las características y las etiquetas estén separadas.
array = dataframe.valuesX = arrayY = array¡Maravilloso! Has preparado tus datos.
Primero, vas a implementar un test estadístico Chi-Cuadrado para características no negativas para seleccionar 4 de las mejores características del conjunto de datos. Ya has visto que la prueba de Chi-Cuadrado pertenece a la clase de métodos de filtrado. Si alguien tiene curiosidad por conocer las interioridades de Chi-Squared, este vídeo hace un excelente trabajo.
La librería scikit-learn proporciona la clase SelectKBest que se puede utilizar con un conjunto de diferentes pruebas estadísticas para seleccionar un número específico de características, en este caso, es Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Has importado las librerías para ejecutar los experimentos. Ahora, vamos a verlo en acción.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretación:
Puede ver las puntuaciones de cada atributo y los 4 atributos elegidos (los que tienen las puntuaciones más altas): plas, test, masa y edad. Estas puntuaciones le ayudarán a determinar las mejores características para entrenar su modelo.
P.S.: La primera fila indica los nombres de las características. Para el preprocesamiento del conjunto de datos, los nombres han sido codificados numéricamente.
A continuación, implementará la Eliminación Recursiva de Características que es un tipo de método de selección de características envolvente.
La Eliminación Recursiva de Características (o RFE) funciona eliminando recursivamente los atributos y construyendo un modelo en aquellos atributos que permanecen.
Utiliza la precisión del modelo para identificar qué atributos (y combinación de atributos) contribuyen más a la predicción del atributo objetivo.
Puede aprender más sobre la clase RFE en la documentación de scikit-learn.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionUtilizará RFE con el clasificador Logistic Regression para seleccionar las 3 mejores características. La elección del algoritmo no importa demasiado mientras sea hábil y consistente.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Puede ver que RFE eligió las 3 características principales como preg, mass y pedi.
Estas están marcadas como Verdaderas en la matriz de soporte y marcadas con una opción «1» en la matriz de clasificación. Esto, a su vez, indica la fuerza de estas características.
A continuación, utilizará la regresión Ridge que es básicamente una técnica de regularización y una técnica de selección de características incrustadas también.
Este artículo le da una excelente explicación sobre la regresión Ridge. Asegúrese de comprobarlo.
# First things firstfrom sklearn.linear_model import RidgeA continuación, utilizará la regresión Ridge para determinar el coeficiente R2.
También, consulte la documentación oficial de scikit-learn sobre la regresión Ridge.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Para entender mejor los resultados de la regresión Ridge, implementará una pequeña función de ayuda que le ayudará a imprimir los resultados de una mejor manera para que pueda interpretarlos fácilmente.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)A continuación, pasará los términos de coeficiente del modelo Ridge a esta pequeña función y verá lo que sucede.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Podrá ver todos los términos de coeficiente anexados con las variables de característica. Esto le ayudará de nuevo a elegir las características más esenciales. A continuación se presentan algunos puntos que debe tener en cuenta al aplicar la regresión Ridge:
- También se conoce como L2-Regularización.
- Para las características correlacionadas, significa que tienden a obtener coeficientes similares.
- Las características que tienen coeficientes negativos no contribuyen mucho. Pero en un escenario más complejo en el que se está tratando con muchas características, entonces esta puntuación definitivamente le ayudará en el proceso de toma de decisiones de selección de características final.
Bueno, eso concluye la sección de estudio de caso. Los métodos que implementó en la sección anterior le ayudarán a entender las características de un conjunto de datos en particular de una manera integral. Permítanme darles algunos puntos críticos sobre estas técnicas:
- La selección de características es esencialmente una parte del preprocesamiento de datos que se considera la parte que más tiempo consume de cualquier tubería de aprendizaje automático.
- Estas técnicas le ayudarán a acercarse de una manera más sistemática y amigable con el aprendizaje automático. Usted será capaz de interpretar las características con mayor precisión.
¡Resumen!
En este post, usted cubrió uno de los temas estadísticos más estudiados y bien investigados, es decir, la selección de características. También se familiarizó con sus diferentes variantes y las utilizó para ver qué características de un conjunto de datos son importantes.
Puede llevar este tutorial más allá fusionando una medida de correlación en el método de envoltura y ver cómo se desempeña. En el transcurso de la acción, puede terminar creando su propio mecanismo de selección de características. Así es como estableces la base de tu pequeña investigación. Los investigadores también están utilizando varios principios de soft computing para realizar la selección. Esto es en sí mismo todo un campo de estudio e investigación. Además, deberías probar los algoritmos de selección de características existentes en varios conjuntos de datos y sacar tus propias conclusiones.
¿Por qué se mantienen estos métodos tradicionales de selección de características?
Sí, esta pregunta es obvia. Porque hay arquitecturas de redes neuronales (por ejemplo las CNN) que son bastante capaces de extraer las características más significativas de los datos, pero eso también tiene una limitación. Utilizar una CNN para un conjunto de datos tabulares normales que no tienen propiedades específicas (las propiedades que tiene una imagen típica como las propiedades de transición, los bordes, las propiedades de posición, los contornos, etc.) no es la decisión más sabia. Además, cuando los datos y los recursos son limitados, entrenar una CNN con conjuntos de datos tabulares normales puede convertirse en un completo desperdicio. Así que, en situaciones como esa, los métodos que has estudiado serán definitivamente útiles.
Los siguientes son algunos recursos si quieres profundizar en este tema:
- Selección de características para el descubrimiento de conocimiento y la minería de datos
- Subespacio, estructura latente y selección de características: Taller de perspectivas estadísticas y de optimización
- Selección de características: Planteamiento del problema y usos
- Uso de algoritmos genéticos para la selección de características en Data Analytics
A continuación se muestran las referencias que se utilizaron para escribir este tutorial.
- Minería de Datos: Conceptos y Técnicas; Jiawei Han Micheline Kamber Jian Pei.
- Una introducción a la selección de características
- Artículo de Analytics Vidhya sobre la selección de características
- Modelos jerárquicos y mixtos – Curso de DataCamp
- Selección de características para el aprendizaje automático en Python
- Detección de valores atípicos en datos de flujo mediante métodos de aprendizaje automático y selección de características
- S. Visalakshi y V. Radha, «A literature review of feature selection techniques and applications: Revisión de la selección de características en la minería de datos», 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.