El Aprendizaje por Refuerzo(RL) es uno de los temas de investigación más candentes en el campo de la Inteligencia Artificial moderna y su popularidad no hace más que crecer. Veamos 5 cosas útiles que hay que saber para empezar con el RL.
El Aprendizaje por Refuerzo(RL) es un tipo de técnica de aprendizaje automático que permite a un agente aprender en un entorno interactivo por ensayo y error utilizando la retroalimentación de sus propias acciones y experiencias.
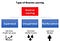
Aunque tanto el aprendizaje supervisado como el de refuerzo utilizan el mapeo entre la entrada y la salida, a diferencia del aprendizaje supervisado en el que la retroalimentación proporcionada al agente es un conjunto correcto de acciones para realizar una tarea, el aprendizaje de refuerzo utiliza recompensas y castigos como señales para el comportamiento positivo y negativo.
En comparación con el aprendizaje no supervisado, el aprendizaje por refuerzo es diferente en términos de objetivos. Mientras que el objetivo en el aprendizaje no supervisado es encontrar similitudes y diferencias entre puntos de datos, en el caso del aprendizaje por refuerzo el objetivo es encontrar un modelo de acción adecuado que maximice la recompensa total acumulada del agente. La figura siguiente ilustra el bucle de retroalimentación acción-recompensa de un modelo genérico de RL.

¿Cómo formular un problema básico de Aprendizaje por Refuerzo?
Algunos términos clave que describen los elementos básicos de un problema de RL son:
- Entorno – Mundo físico en el que opera el agente
- Estado – Situación actual del agente
- Recompensa – Retroalimentación del entorno
- Política – Método para asignar el estado del agente a las acciones
- Valor – Recompensa futura que recibiría un agente al realizar una acción en un estado concreto
Un problema de RL se puede explicar mejor a través de juegos. Tomemos el juego de PacMan en el que el objetivo del agente (PacMan) es comer la comida en la cuadrícula mientras evita los fantasmas en su camino. En este caso, el mundo de la cuadrícula es el entorno interactivo en el que actúa el agente. El agente recibe una recompensa por comer comida y un castigo si es asesinado por el fantasma (pierde el juego). Los estados son la ubicación del agente en el mundo cuadriculado y la recompensa total acumulada es que el agente gane el juego.

Para construir una política óptima, el agente se enfrenta al dilema de explorar nuevos estados y maximizar su recompensa total al mismo tiempo. Esto se denomina equilibrio entre exploración y explotación. Para equilibrar ambos, la mejor estrategia global puede implicar sacrificios a corto plazo. Por lo tanto, el agente debe recoger suficiente información para tomar la mejor decisión global en el futuro.
Los Procesos de Decisión de Markov (MDP) son marcos matemáticos para describir un entorno en la RL y casi todos los problemas de RL pueden ser formulados utilizando MDP. Un MDP consiste en un conjunto de estados finitos del entorno S, un conjunto de acciones posibles A(s) en cada estado, una función de recompensa de valor real R(s) y un modelo de transición P(s’, s | a). Sin embargo, es más probable que los entornos del mundo real carezcan de cualquier conocimiento previo de la dinámica del entorno. Los métodos de RL sin modelo resultan útiles en estos casos.
El aprendizaje Q es un enfoque sin modelo comúnmente utilizado que puede usarse para construir un agente PacMan autojugable. Gira en torno a la noción de actualización de los valores Q que denota el valor de realizar la acción a en el estado s. La siguiente regla de actualización de valores es el núcleo del algoritmo de aprendizaje Q.

Aquí hay un vídeo de demostración de un agente de PacMan que utiliza el aprendizaje por refuerzo profundo.
¿Cuáles son algunos de los algoritmos de Aprendizaje por Refuerzo más utilizados?
El aprendizaje Q y SARSA (Estado-Acción-Recompensa-Estado-Acción) son dos algoritmos de RL sin modelo comúnmente utilizados. Se diferencian en cuanto a sus estrategias de exploración mientras que sus estrategias de explotación son similares. Mientras que el aprendizaje Q es un método fuera de política en el que el agente aprende el valor basado en la acción a* derivada de la otra política, SARSA es un método dentro de política en el que aprende el valor basado en su acción actual a derivada de su política actual. Estos dos métodos son sencillos de implementar pero carecen de generalidad ya que no tienen la capacidad de estimar valores para estados no vistos.
Esto puede ser superado por algoritmos más avanzados como Deep Q-Networks(DQNs) que utilizan Redes Neuronales para estimar valores Q. Pero las DQNs sólo pueden manejar espacios de acción discretos y de baja dimensión.
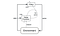
Dep Deterministic Policy Gradient(DDPG) es un algoritmo libre de modelos, fuera de la política, actor-crítico que aborda este problema mediante el aprendizaje de políticas en espacios de acción continuos y de alta dimensión. La figura siguiente es una representación de la arquitectura actor-crítica.
¿Cuáles son las aplicaciones prácticas del aprendizaje por refuerzo?
Dado que el RL requiere una gran cantidad de datos, es más aplicable en dominios donde los datos simulados están fácilmente disponibles como el juego, la robótica.
- El RL se utiliza bastante en la construcción de IA para jugar a juegos de ordenador. AlphaGo Zero es el primer programa informático que derrotó a un campeón mundial en el antiguo juego chino del Go. Otros incluyen juegos de ATARI, Backgammon ,etc
- En robótica y automatización industrial, la RL se utiliza para que el robot pueda crear un sistema de control adaptativo eficiente para sí mismo que aprenda de su propia experiencia y comportamiento. El trabajo de DeepMind en Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates es un buen ejemplo de ello. Vea este interesante vídeo de demostración.
Otras aplicaciones de RL incluyen motores de resumen de texto abstracto, agentes de diálogo (texto, voz) que pueden aprender de las interacciones del usuario y mejorar con el tiempo, el aprendizaje de políticas de tratamiento óptimas en la asistencia sanitaria y agentes basados en RL para el comercio de acciones en línea.
¿Cómo puedo iniciarme en el aprendizaje por refuerzo?
Para entender los conceptos básicos de la RL, se pueden consultar los siguientes recursos.
- Reinforcement Learning-An Introduction, un libro del padre del aprendizaje por refuerzo -Richard Sutton- y su asesor doctoral Andrew Barto. Un borrador en línea del libro está disponible aquí.
- El material didáctico de David Silver, que incluye conferencias en vídeo, es un gran curso de introducción a la RL.
- Aquí hay otro tutorial técnico sobre RL por Pieter Abbeel y John Schulman (Open AI/ Berkeley AI Research Lab).
Para empezar a construir y probar agentes de RL, los siguientes recursos pueden ser útiles.
- Este blog sobre cómo entrenar un agente ATARI Pong de red neuronal con gradientes de política a partir de píxeles crudos por Andrej Karpathy le ayudará a obtener su primer agente de aprendizaje de refuerzo profundo en sólo 130 líneas de código Python.
- DeepMind Lab es una plataforma de código abierto similar a un juego en 3D creada para la investigación de la IA basada en agentes con ricos entornos simulados.
- Project Malmo es otra plataforma de experimentación de la IA para apoyar la investigación fundamental en la IA.
- OpenAI gym es un conjunto de herramientas para construir y comparar algoritmos de aprendizaje por refuerzo.