Sidst opdateret den 18. august 2020
Datasæt kan have manglende værdier, og dette kan skabe problemer for mange maskinlæringsalgoritmer.
Det er derfor god praksis at identificere og erstatte manglende værdier for hver kolonne i dine inputdata, før du modellerer din forudsigelsesopgave. Dette kaldes imputering af manglende data, eller kort sagt imputering.
En populær tilgang til dataimputering er at beregne en statistisk værdi for hver kolonne (f.eks. et gennemsnit) og erstatte alle manglende værdier for den pågældende kolonne med den statistiske værdi. Det er en populær tilgang, fordi statistikken er nem at beregne ved hjælp af træningsdatasættet, og fordi den ofte resulterer i god ydeevne.
I denne tutorial vil du opdage, hvordan du kan bruge statistiske imputeringsstrategier for manglende data i maskinlæring.
Når du har gennemført denne tutorial, vil du vide:
- Manglende værdier skal markeres med NaN-værdier og kan erstattes med statistiske mål for at beregne kolonnen af værdier.
- Hvordan du indlæser en CSV-værdi med manglende værdier og markerer de manglende værdier med NaN-værdier og rapporterer antallet og procentdelen af manglende værdier for hver kolonne.
- Hvordan du imputerer manglende værdier med statistik som en datapræparationsmetode ved evaluering af modeller og ved tilpasning af en endelig model til at foretage forudsigelser på nye data.
Kick-start dit projekt med min nye bog Data Preparation for Machine Learning, herunder trinvise vejledninger og Python-kildekodefilerne til alle eksempler.
Lad os komme i gang.
- Opdateret jun/2020: Ændret den kolonne, der anvendes til forudsigelse i eksemplerne.

Statistisk imputering for manglende værdier i maskinlæring
Foto af Bernal Saborio, nogle rettigheder forbeholdes.
Tutorialoversigt
Denne tutorial er opdelt i tre dele; de er:
- Statistisk imputation
- Horse Colic Dataset
- Statistisk imputation med SimpleImputer
- SimpleImputer Data Transform
- SimpleImputer and Model Evaluation
- Sammenligning af forskellige imputerede statistikker
- SimpleImputer Transform når der foretages en forudsigelse
Statistisk imputering
Et datasæt kan have manglende værdier.
Dette er rækker af data, hvor en eller flere værdier eller kolonner i den pågældende række ikke er til stede. Værdierne kan mangle helt, eller de kan være markeret med et særligt tegn eller en særlig værdi, f.eks. et spørgsmålstegn “?”.
Disse værdier kan udtrykkes på mange måder. Jeg har set dem vise sig som ingenting overhovedet , en tom streng , den eksplicitte streng NULL eller udefineret eller N/A eller NaN og tallet 0, blandt andet. Uanset hvordan de optræder i dit datasæt, vil det at vide, hvad man kan forvente, og kontrollere, at dataene svarer til denne forventning, reducere problemerne, når du begynder at bruge dataene.
– Side 10, Bad Data Handbook, 2012.
Værdier kan mangle af mange årsager, der ofte er specifikke for problemdomænet, og kan omfatte årsager som korrupte målinger eller manglende tilgængelighed af data.
De kan opstå af en række årsager, f.eks. dårligt fungerende måleudstyr, ændringer i forsøgsdesignet under dataindsamlingen og samling af flere lignende, men ikke identiske datasæt.
– Side 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
De fleste maskinlæringsalgoritmer kræver numeriske inputværdier, og der skal være en værdi til stede for hver række og kolonne i et datasæt. Som sådan kan manglende værdier skabe problemer for maskinlæringsalgoritmer.
Som sådan er det almindeligt at identificere manglende værdier i et datasæt og erstatte dem med en numerisk værdi. Dette kaldes dataimputering eller imputering af manglende data.
En simpel og populær tilgang til dataimputering indebærer anvendelse af statistiske metoder til at estimere en værdi for en kolonne ud fra de værdier, der er til stede, og derefter erstatte alle manglende værdier i kolonnen med den beregnede statistik.
Det er enkelt, fordi statistikken er hurtig at beregne, og det er populært, fordi det ofte viser sig at være meget effektivt.
Fælles statistikker, der beregnes, omfatter:
- Kolonnens middelværdi.
- Kolonnens medianværdi.
- Kolonnens modeværdi.
- En konstant værdi.
Nu da vi er bekendt med statistiske metoder til imputering af manglende værdier, skal vi se på et datasæt med manglende værdier.
Vil du komme i gang med datapræparation?
Tag mit gratis 7-dages e-mail crashkursus nu (med prøvekode).
Klik for at tilmelde dig og få også en gratis PDF Ebook-version af kurset.
Download dit GRATIS minikursus
Datasæt om hestekolik
Datasættet om hestekolik beskriver medicinske karakteristika for heste med kolik, og om de levede eller døde.
Der er 300 rækker og 26 inputvariable med én outputvariabel. Det er en binær klassifikationsforudsigelsesopgave, der indebærer at forudsige 1, hvis hesten levede, og 2, hvis hesten døde.
Der er mange felter, vi kunne vælge at forudsige i dette datasæt. I dette tilfælde vil vi forudsige, om problemet var kirurgisk eller ej (kolonneindeks 23), hvilket gør det til en binær klassifikationsopgave.
Datasættet har mange manglende værdier for mange af kolonnerne, hvor hver manglende værdi er markeret med et spørgsmålstegn (“?”).
Nedenfor er der et eksempel på rækker fra datasættet med markerede manglende værdier.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Du kan få mere at vide om datasættet her:
- Horse Colic Dataset
- Horse Colic Dataset Description
Det er ikke nødvendigt at downloade datasættetet, da vi downloader det automatisk i de gennemarbejdede eksempler.
Markering af manglende værdier med en NaN-værdi (ikke et tal) i et indlæst datasæt ved hjælp af Python er en bedste praksis.
Vi kan indlæse datasættet ved hjælp af Pandas-funktionen read_csv() og angive “na_values” for at indlæse værdier af ‘?’ som manglende, markeret med en NaN-værdi.
|
1
2
3
3
4
|
…
# indlæs datasæt
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
|
Når de er indlæst, kan vi gennemgå de indlæste data for at bekræfte, at “?” værdier er markeret som NaN.
|
1
2
3
|
…
# sammenfatning af de første par rækker
print(dataframe.head())
|
Vi kan derefter opregne hver enkelt kolonne og rapportere antallet af rækker med manglende værdier for kolonnen.
|
1
2
3
4
5
6
7
|
…
# sammenfatning af antallet af rækker med manglende værdier for hver kolonne
for i in range(dataframe.shape):
# tæl antallet af rækker med manglende værdier
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Mangler: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Det komplette eksempel på indlæsning og sammenfatning af datasættet er anført nedenfor.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# opsummering af datasættet om hestekolik
from pandas import read_csv
# indlæs datasæt
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# opsummering af de første par rækker
print(dataframe.head())
# sammenfatning af antallet af rækker med manglende værdier for hver kolonne
for i in range(dataframe.shape):
# tæl antallet af rækker med manglende værdier
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Mangler: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Kør eksemplet først indlæser datasættet og opsummerer de første fem rækker.
Vi kan se, at de manglende værdier, der var markeret med et “?”-tegn, er blevet erstattet med NaN-værdier.
Dernæst kan vi se listen over alle kolonner i datasættet og antallet og procentdelen af manglende værdier.
Vi kan se, at nogle kolonner (f.eks. kolonneindeks 1 og 2) ikke har nogen manglende værdier, mens andre kolonner (f.eks. kolonneindeks 15 og 21) har mange eller endog et flertal af manglende værdier.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Mangler: 1 (0,3 %)
> 1, Mangler: 1 (0,3 %)
> 1, Mangler: 0 (0,0%)
> 2, Mangler: 0 (0,0%)
> 2, Mangler: 0 (0,0%)
> 3, Mangler: 0 (0,0%)
> 3, Mangler: 60 (20,0%)
> 4, Mangler: 0,0 (20,0%)
> 4, Mangler: (8,0%)
> 5, Mangler: 24 (8,0%)
> 5, Mangler: 58 (19,3%)
> 6, Mangler: 58 (19,3%)
> 6, Mangler: 56 (18,7%)
> 7, Mangler: 56 (18,7%)
> 7, Mangler: 69 (23,0%)
> 8, Mangler: 69 (23,0%)
> 8, Mangler: (15,7%)
> 9, Mangler: 47 (15,7%)
> 9, Mangler: (10,7%)
> 10, Mangler: 32 (10,7%)
> 10, Mangler: 55 (18,3%)
> 11, Mangler: (14,7%)
> 12, Mangler: 44 (14,7%)
> 12, Mangler: (18,7%)
> 13, Mangler: 56 (18,7%)
> 13, Mangler: (34,7%)
> 14, Mangler: 104 (34,7%)
> 14, Mangler: (35,3%)
> 15, Mangler: 106 (35,3%)
> 15, Mangler: 247 (82,3%)
> 16, Mangler: 102 (34,0%)
> 17, Mangler: (39,3%)
> 18, Mangler: 118 (39,3%)
> 18, Mangler: (9,7%)
> 19, Mangler: 29 (9,7%)
> 19, Mangler: (11,0%)
> 20, Mangler: 33 (11,0%)
> 20, Mangler: 165 (55,0%)
> 21, Manglende: (66,0%)
> 22, Mangler: 198 (66,0%)
> 22, Mangler: 1 (0,3%)
> 23, Mangler: 1 (0,3%)
> 23, Mangler: 0 (0,0%)
> 24, Mangler: 0 (0,0%)
> 24, Mangler: 0 (0,0%)
> 25, Mangler: 0 (0,0%)
> 25, Mangler: 0 (0.0%)
> 26, Mangler: 0 (0.0%)
> 26, Mangler: 0 (0.0%)
> 27, Mangler: 0 (0.0%)
> 27, Mangler: 0 (0,0%)
|
Nu da vi er bekendt med datasættet for hestekolik, der har manglende værdier, skal vi se på, hvordan vi kan bruge statistisk imputering.
Statistisk imputering med SimpleImputer
Scikit-learn-biblioteket til maskinindlæring indeholder klassen SimpleImputer, der understøtter statistisk imputering.
I dette afsnit vil vi undersøge, hvordan vi effektivt kan bruge SimpleImputer-klassen.
SimpleImputer-datatatransformation
SimpleImputer er en datatransformation, der først konfigureres baseret på den type statistik, der skal beregnes for hver kolonne, f.eks.f.eks. middelværdi.
|
1
2
3
|
…
# define imputer
imputer = SimpleImputer(strategy=’mean’)
|
Dernæst tilpasses imputeren på et datasæt for at beregne statistikken for hver kolonne.
|
1
2
3
|
…
# fit på datasættet
imputer.fit(X)
|
Den fit imputer anvendes derefter på et datasæt for at skabe en kopi af datasættet med alle manglende værdier for hver kolonne erstattet med en statistisk værdi.
|
1
2
3
|
…
# transformere datasættet
Xtrans = imputer.transform(X)
|
Vi kan demonstrere brugen heraf på datasættet om hestekolik og bekræfte, at det virker ved at opsummere det samlede antal manglende værdier i datasættet før og efter transformationen.
Det komplette eksempel er anført nedenfor.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# statistisk imputering transform for hestekolik-datasættet
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# indlæs datasæt
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# opdeling i input- og output-elementer
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# print total mangler
print(‘Mangler: %d’ % sum(isnan(X).flatten()))
# definér imputer
imputer = SimpleImputer(strategy=’mean’)
# fit på datasættet
imputer.fit(X)
# transformér datasættet
Xtrans = imputer.transform(X)
# udskriv total missing
print(‘Missing: %d’ % sum(isnan(Xtrans).flatten())))
|
Kør eksemplet først indlæser datasættet og rapporterer det samlede antal manglende værdier i datasættet som 1.605.
Transformationen er konfigureret, tilpasset og udført, og det resulterende nye datasæt har ingen manglende værdier, hvilket bekræfter, at den blev udført som forventet.
Hver manglende værdi blev erstattet med middelværdien for dens kolonne.
|
1
2
|
Mangler: 1605
Mangler: 1605
Mangler: 0
|
SimpleImputer and Model Evaluation
Det er en god praksis at evaluere maskinlæringsmodeller på et datasæt ved hjælp af k-fold cross-validation.
For at anvende statistisk imputation af manglende data korrekt og undgå datalækage kræves det, at de statistikker, der beregnes for hver kolonne, kun beregnes på træningsdatasættet og derefter anvendes på trænings- og testsættene for hver fold i datasættet.
Hvis vi bruger resampling til at vælge tuningparameterværdier eller til at estimere ydeevne, bør imputationen inkorporeres i resamplingen.
– Side 42, Applied Predictive Modeling, 2013.
Dette kan opnås ved at skabe en modelleringspipeline, hvor det første trin er den statistiske imputation, hvorefter det andet trin er modellen. Dette kan opnås ved hjælp af Pipeline-klassen.
For eksempel bruger pipelinen nedenfor en SimpleImputer med en ‘mean’-strategi efterfulgt af en random forest-model.
|
1
2
3
4
5
|
…
# definere modelleringspipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
Vi kan evaluere den gennemsnitlige-imputerede datasæt og random forest-modelleringspipeline for hestekolik-datasættet med gentagen 10-fold krydsvalidering.
Det komplette eksempel er anført nedenfor.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
25
|
# evaluere middelimputering og tilfældig forest for hestekolikdatasættet
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# indlæsning af datasæt
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# opdeling i input- og output-elementer
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# definér modelleringspipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# definér modelvurdering
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluere model
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(‘Mean Accuracy: %.3f (%.3f)’ % (mean(scores), std(scores))))
|
Afviklingen af eksemplet anvender korrekt dataimputering til hver fold af krydsvalideringsproceduren.
Anmærkning: Dine resultater kan variere på grund af algoritmens eller evalueringsprocedurens stokastiske karakter eller forskelle i numerisk præcision. Overvej at køre eksemplet et par gange og sammenlign det gennemsnitlige resultat.
Pipelinen er evalueret ved hjælp af tre gentagelser af 10-fold krydsvalidering og rapporterer den gennemsnitlige klassifikationsnøjagtighed på datasættet som ca. 86.3 procent, hvilket er en god score.
|
1
|
Median Accuracy: 0,863 (0.054)
|
Sammenligning af forskellige imputerede statistikker
Hvordan ved vi, at det er godt eller bedst at bruge en “gennemsnitlig” statistisk strategi for dette datasæt?
Svaret er, at det ved vi ikke, og at den blev valgt vilkårligt.
Vi kan udforme et eksperiment for at afprøve hver statistisk strategi og finde ud af, hvad der fungerer bedst for dette datasæt, ved at sammenligne strategierne middelværdi, median, mode (hyppigst forekommende) og konstant (0). Den gennemsnitlige nøjagtighed for hver strategi kan derefter sammenlignes.
Det komplette eksempel er anført nedenfor.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
32
|
# sammenligne statistiske imputeringsstrategier for datasættet for hestekolik
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# indlæs datasæt
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# opdelt i input- og output-elementer
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# evaluere hver strategi på datasættet
results = list()
strategies =
for s in strategies:
# opretter modelleringspipeline
pipeline = Pipeline(steps=)
# evaluerer modellen
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# gemme resultater
results.append(scores)
print(‘>%s %.3f (%.3f)’ % (s, mean(scores), std(scores)))
# plot modellens ydeevne til sammenligning
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
Afprøvning af eksemplet evaluerer hver statistisk imputeringsstrategi på datasættet for hestekolik ved hjælp af gentagen krydsvalidering.
Bemærk: Dine resultater kan variere på grund af algoritmens eller evalueringsprocedurens stokastiske karakter eller forskelle i den numeriske præcision. Overvej at køre eksemplet et par gange og sammenlign det gennemsnitlige resultat.
Den gennemsnitlige nøjagtighed for hver strategi er rapporteret undervejs. Resultaterne tyder på, at brugen af en konstant værdi, f.eks. 0, resulterer i den bedste præstation på ca. 88,1 procent, hvilket er et fremragende resultat.
|
1
2
3
4
|
>Middelværdi 0.860 (0.054)
>median 0.862 (0.065)
>mest_frekvent 0.872 (0.052)
>konstant 0.881 (0.047)
|
I slutningen af kørslen oprettes der et boks- og whiskerplot for hvert sæt resultater, så det er muligt at sammenligne fordelingen af resultaterne.
Vi kan tydeligt se, at fordelingen af nøjagtighedsscorerne for den konstante strategi er bedre end de andre strategier.
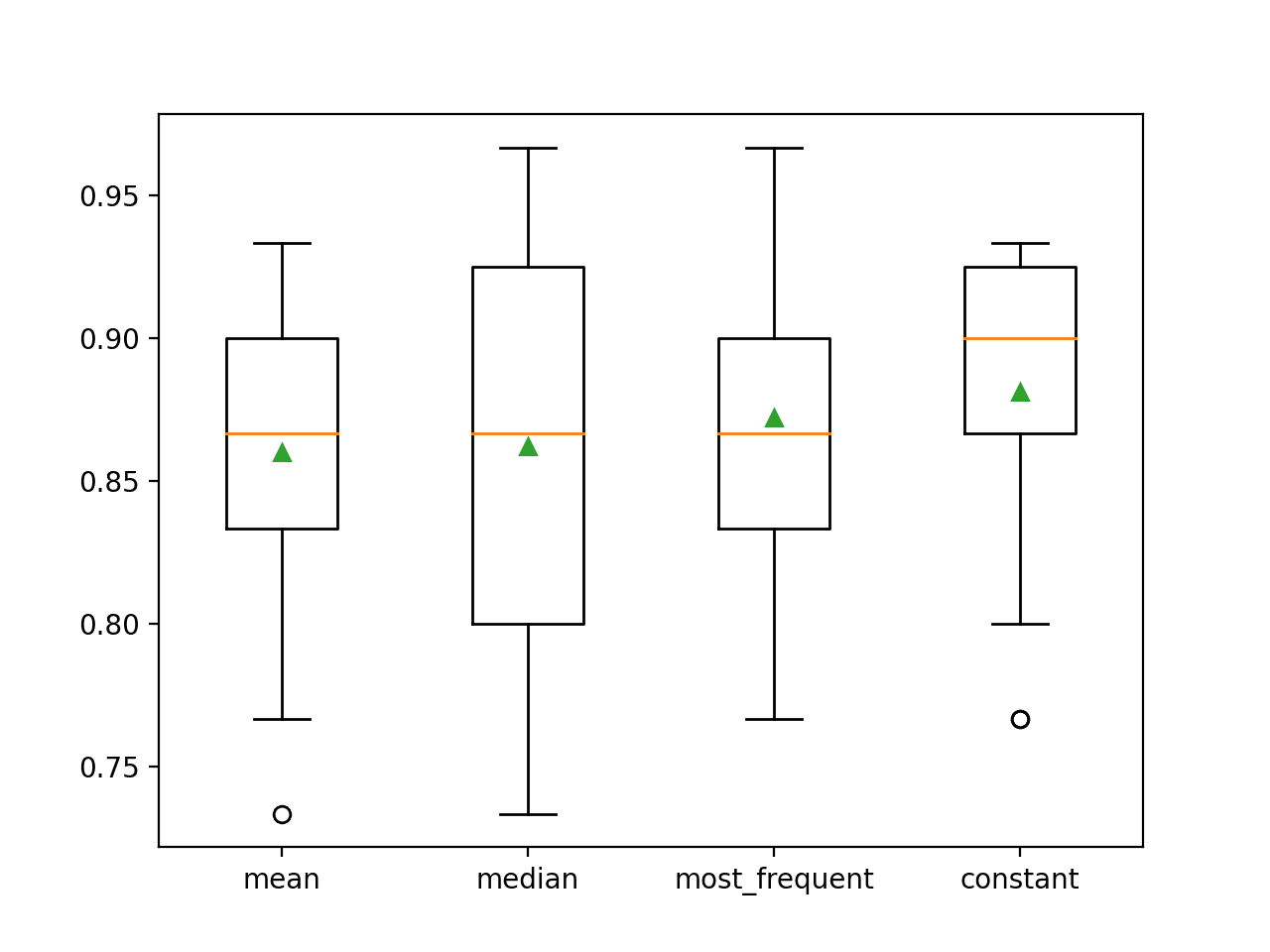
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
Vi ønsker måske at oprette en endelig modelleringspipeline med den konstante imputationsstrategi og random forest-algoritmen og derefter foretage en forudsigelse for nye data.
Dette kan opnås ved at definere pipelinen og tilpasse den på alle tilgængelige data og derefter kalde funktionen predict() og indsætte nye data som et argument.
Vigtigt er det, at rækken med nye data skal markere eventuelle manglende værdier ved hjælp af NaN-værdien.
|
1
2
3
|
…
# define new data
row =
|
Det komplette eksempel er anført nedenfor.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
23
|
# konstant imputering strategi og forudsigelse for datasættet for slangekolik
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# opdelt i input- og output-elementer
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# opretter modelleringspipeline
pipeline = Pipeline(steps=)
# tilpasser modellen
# pipeline.fit(X, y)
# definér nye data
row =
# lav en forudsigelse
yhat = pipeline.predict()
# opsummerer forudsigelse
print(‘Predicted Class: %d’ % yhat)
|
Afvikling af eksemplet passer til modelleringspipelinen på alle tilgængelige data.
En ny datarække defineres med manglende værdier markeret med NaN’er, og der foretages en klassifikationsforudsigelse.
|
1
|
Forudsigelse af klasse: 2
|
Videre læsning
Dette afsnit indeholder flere ressourcer om emnet, hvis du ønsker at gå i dybden.
Relaterede vejledninger
- Resultater for Standard Classification and Regression Machine Learning Datasets
- How to Handle Missing Data with Python
Bøger
- Bad Data Handbook, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
API’er
- Imputering af manglende værdier, scikit-learn Documentation.
- sklearn.impute.SimpleImputer API.
Dataset
- Horse Colic Dataset
- Horse Colic Dataset Description
Summary
I denne vejledning opdagede du, hvordan du kan bruge statistiske imputeringsstrategier til manglende data i maskinlæring.
Specifikt lærte du:
- Manglende værdier skal markeres med NaN-værdier og kan erstattes med statistiske mål for at beregne kolonnen af værdier.
- Hvordan du indlæser en CSV-værdi med manglende værdier og markerer de manglende værdier med NaN-værdier og rapporterer antallet og procentdelen af manglende værdier for hver kolonne.
- Sådan imputerer du manglende værdier med statistik som en datapræparationsmetode ved evaluering af modeller og ved tilpasning af en endelig model til at foretage forudsigelser på nye data.
Har du spørgsmål?
Sæt dine spørgsmål i kommentarerne nedenfor, og jeg vil gøre mit bedste for at svare.
Få styr på moderne datapræparation!

Forbered dine data til maskinlæring på få minutter
…med blot et par linjer python-kode
Opdag hvordan i min nye E-bog:
Dataforberedelse til maskinlæring
Den indeholder selvstuderende tutorials med fuld arbejdskode om:
Feature Selection, RFE, datarengøring, datatransformationer, skalering, dimensionalitetsreduktion og meget mere…
Bring moderne dataforberedelsesteknikker til
dine maskinlæringsprojekter
Se, hvad der er i