Reinforcement Learning(RL) er et af de hotteste forskningsemner inden for moderne kunstig intelligens, og dets popularitet er kun stigende. Lad os se på 5 nyttige ting, man skal vide for at komme i gang med RL.
Reinforcement Learning(RL) er en type maskinlæringsteknik, der gør det muligt for en agent at lære i et interaktivt miljø ved forsøg og fejl ved hjælp af feedback fra sine egne handlinger og erfaringer.
Selv om både overvåget og forstærkende læring anvender kortlægning mellem input og output, bruger forstærkende læring i modsætning til overvåget læring, hvor den feedback, der gives til agenten, er korrekte sæt handlinger til udførelse af en opgave, belønninger og straffe som signaler for positiv og negativ adfærd.
I forhold til uovervåget læring er forstærkningslæring anderledes med hensyn til mål. Mens målet i uovervåget indlæring er at finde ligheder og forskelle mellem datapunkter, er målet i tilfælde af forstærkningsindlæring at finde en passende handlingsmodel, der maksimerer agentens samlede kumulative belønning. Figuren nedenfor illustrerer handlingsbelønningsfeedbacksløjfen i en generisk RL-model.

Hvordan formuleres et grundlæggende Reinforcement Learning-problem?
Nogle nøglebegreber, der beskriver de grundlæggende elementer i et RL-problem, er:
- Miljø – Fysisk verden, som agenten opererer i
- Tilstand – Agentens aktuelle situation
- Belønning – Feedback fra miljøet
- Politik – Metode til at kortlægge agentens tilstand til handlinger
- Værdi – Fremtidig belønning, som en agent ville modtage ved at foretage en handling i en bestemt tilstand
Et RL-problem kan bedst forklares ved hjælp af spil. Lad os tage spillet PacMan, hvor agentens (PacMan) mål er at spise maden i gitteret og samtidig undgå spøgelserne på sin vej. I dette tilfælde er gitterverdenen det interaktive miljø for agenten, hvor den handler. Agenten modtager en belønning for at spise maden og en straf, hvis den bliver dræbt af et spøgelse (taber spillet). Tilstandene er agentens placering i gitterverdenen, og den samlede kumulative belønning er, at agenten vinder spillet.

For at opbygge en optimal politik står agenten over for det dilemma at udforske nye tilstande og samtidig maksimere sin samlede belønning. Dette kaldes en afvejning mellem udforskning og udnyttelse. For at afbalancere begge dele kan den bedste overordnede strategi indebære kortsigtede ofre. Derfor bør agenten indsamle tilstrækkelige oplysninger til at træffe den bedste overordnede beslutning i fremtiden.
Markov Decision Processes (MDP’er) er matematiske rammer til at beskrive et miljø i RL, og næsten alle RL-problemer kan formuleres ved hjælp af MDP’er. En MDP består af et sæt af begrænsede miljøtilstande S, et sæt af mulige handlinger A(s) i hver tilstand, en belønningsfunktion R(s) med reel værdi og en overgangsmodel P(s’, s | a). I virkelige miljøer er det imidlertid mere sandsynligt, at der ikke er nogen forudgående viden om miljøets dynamik. Modelfrie RL-metoder er praktiske i sådanne tilfælde.
Q-learning er en almindeligt anvendt modelfri metode, som kan anvendes til at opbygge en selvspillende PacMan-agent. Den drejer sig om begrebet opdatering af Q-værdier, som angiver værdien af at udføre handling a i tilstand s. Følgende værdiopdateringsregel er kernen i Q-læringsalgoritmen.

Her er en videodemonstration af en PacMan-agent, der bruger Deep Reinforcement Learning.
Hvad er nogle af de mest anvendte forstærkningslæringsalgoritmer?
Q-learning og SARSA (State-Action-Reward-State-Action) er to almindeligt anvendte modelfrie RL-algoritmer. De adskiller sig fra hinanden med hensyn til deres udforskningsstrategier, mens deres udnyttelsesstrategier er ens. Mens Q-learning er en off-policy-metode, hvor agenten lærer værdien på grundlag af handling a*, der er afledt af en anden politik, er SARSA en on-policy-metode, hvor den lærer værdien på grundlag af sin aktuelle handling a, der er afledt af den aktuelle politik. Disse to metoder er enkle at gennemføre, men mangler generalitet, da de ikke har mulighed for at estimere værdier for usete tilstande.
Dette kan overvindes ved hjælp af mere avancerede algoritmer såsom Deep Q-Networks(DQNs), der anvender neurale netværk til at estimere Q-værdier. Men DQN’er kan kun håndtere diskrete, lavdimensionelle aktionsrum.
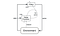
Deep Deterministic Policy Gradient(DDPG) er en modelfri, off-policy, aktør-kritisk algoritme, der tackler dette problem ved at lære politikker i højdimensionelle, kontinuerlige aktionsrum. Figuren nedenfor er en repræsentation af en aktør-kritisk arkitektur.
Hvad er de praktiske anvendelser af forstærket læring?
Da RL kræver mange data, er det derfor mest anvendeligt inden for områder, hvor simulerede data er let tilgængelige, f.eks. spil og robotteknologi.
- RL er ret udbredt i forbindelse med opbygning af AI til at spille computerspil. AlphaGo Zero er det første computerprogram, der har besejret en verdensmester i det gamle kinesiske spil Go. Andre omfatter ATARI-spil, backgammon ,osv
- I robotteknologi og industriel automatisering bruges RL til at sætte robotten i stand til at skabe et effektivt adaptivt kontrolsystem for sig selv, som lærer af sine egne erfaringer og sin egen adfærd. DeepMind’s arbejde med Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates er et godt eksempel på det samme. Se denne interessante demonstrationsvideo.
Andre anvendelser af RL omfatter abstrakte tekstresumeeringsmotorer, dialogagenter (tekst, tale), der kan lære af brugerinteraktioner og forbedres med tiden, læring af optimale behandlingspolitikker i sundhedssektoren og RL-baserede agenter til online aktiehandel.
Hvordan kan jeg komme i gang med Reinforcement Learning?
For at forstå de grundlæggende begreber i RL kan man henvise til følgende ressourcer.
- Reinforcement Learning-An Introduction, en bog af faderen til Reinforcement Learning- Richard Sutton og hans ph.d.-konsulent Andrew Barto. Et online udkast af bogen er tilgængeligt her.
- Undervisningsmateriale fra David Silver, herunder videoforelæsninger, er et godt introduktionskursus om RL.
- Her er en anden teknisk tutorial om RL af Pieter Abbeel og John Schulman (Open AI/ Berkeley AI Research Lab).
For at komme i gang med at bygge og teste RL-agenter kan følgende ressourcer være nyttige.
- Denne blog om, hvordan du træner en Neural Network ATARI Pong-agent med Policy Gradients fra rå pixels af Andrej Karpathy, vil hjælpe dig med at få din første Deep Reinforcement Learning-agent op og køre på kun 130 linjer Python-kode.
- DeepMind Lab er en open source 3D-spillignende platform skabt til agentbaseret AI-forskning med rige simulerede miljøer.
- Project Malmo er en anden AI-eksperimenteringsplatform til støtte for grundforskning inden for AI.
- OpenAI gym er et værktøjssæt til opbygning og sammenligning af algoritmer til forstærkende læring.