Indledning
Hvis du analyserer dine data ved hjælp af multipel regression og nogen af dine uafhængige variabler blev målt på en nominel eller ordinal skala, skal du vide, hvordan du opretter dummy-variabler og fortolker deres resultater. Dette skyldes, at nominelle og ordinale uafhængige variabler, mere bredt kendt som kategoriske uafhængige variabler, ikke kan indtastes direkte i en multipel regressionsanalyse. I stedet skal de omdannes til dummy-variabler. Undtagelsen er ordinale uafhængige variabler, der indgår i en multipel regressionsanalyse som kontinuerte uafhængige variabler, som ikke skal omdannes til dummy-variabler. Derfor viser vi i denne vejledning, hvordan du opretter dummy-variabler, når du har kategoriske uafhængige variabler.
Først opstiller vi det eksempel, vi bruger til at vise, hvordan du opretter dummy-variabler i SPSS Statistics, før vi forklarer, hvordan du konfigurerer dine data i vinduerne Variable View og Data View i SPSS Statistics, så du kan oprette dummy-variabler. Hvis du ikke er bekendt med brugen af dummy-variabler, anbefaler vi, at du derefter læser om nogle af de grundlæggende principper for dummy-variabler og dummy-kodning, herunder: (a) antallet af dummy-variabler, som du skal oprette i din analyse, og (b) hvordan du opretter dummy-variabler og dummy-kodning. I afsnittet Procedure, der følger, beskriver vi den enkle 3-trins procedure Create Dummy Variables i SPSS Statistics, som kan bruges til at oprette dummy-variabler. Endelig forklarer vi SPSS Statistics output efter at have kørt Create Dummy Variables-proceduren, herunder hvordan dine dummy-variabler nu vil blive opstillet i vinduerne Variable View og Data View i SPSS Statistics.
Note: Hvis du finder, at procedurerne i denne vejledning ikke dækker den type dummy-variabler, du ønsker at oprette, bedes du kontakte os. Vi kan muligvis tilføje en anden vejledning til webstedet for at hjælpe.
SPSS Statistics
Eksempel anvendt i denne vejledning
I denne vejledning vil vi bruge eksemplet med 10 triatleter, der blev bedt om at vælge deres yndlingssport blandt de tre sportsgrene, de udfører, når de laver triatlon: svømning, cykling og løb. Deres svar blev registreret i den nominelle uafhængige variabel, favourite_sport, som har tre kategorier: “svømning”, “cykling” og “løb”. Denne nominelle uafhængige variabel, favourite_sport, skulle indgå i en multipel regressionsanalyse, som også omfattede en række kontinuerlige uafhængige variabler. Da denne uafhængige variabel var kategorisk (dvs. nominelle variabler og ordinale variabler kan groft sagt klassificeres som kategoriske variabler), skulle der oprettes dummy-variabler, før den kunne indgå i den multiple regressionsanalyse.
Vigtigt: Bemærk, at favourite_sport er en nominel variabel, men du kan også oprette dummy-variabler for en ordinal variabel. Desuden er processen for oprettelse af dummy-variabler den samme, uanset om du har en ordinal- eller nominalvariabel, bortset fra en lille ændring, du skal foretage, når du opstiller dine data, hvilket forklares nedenfor.
Note 1: “Kategorierne” i en kategorisk uafhængig variabel kaldes også “grupper” eller “niveauer”, men udtrykket “niveauer” er normalt forbeholdt kategorier, der har en rækkefølge (f.eks. kunne den ordinale uafhængige variabel, “fitnessniveau”, have tre niveauer: “lav”, “moderat” og “høj”). Disse tre udtryk – “kategorier”, “grupper” og “niveauer” – kan dog anvendes i flæng. I denne vejledning vil vi henvise til dem som kategorier, men du kan henvise til dem som grupper eller niveauer, hvis du foretrækker det.
Note 2: Udtrykket “faktorer” bruges nogle gange i stedet for “kategoriske uafhængige variabler” (dvs. uafhængige variabler, der er “ordinale” eller “nominelle”). Disse to udtryk – “kategoriske uafhængige variabler” og “faktorer” – kan dog anvendes i flæng. I denne vejledning vil vi henvise til dem som kategoriske uafhængige variabler, og du vil også se SPSS Statistics henvise til dem som uafhængige variabler i stedet for faktorer i sin multiple regressionsprocedure. Du kan dog henvise til dem som faktorer, hvis du foretrækker det.
SPSS Statistics
Oprettelse af dine data i SPSS Statistics
Når du opretter dummy-variabler, starter du med en enkelt kategorisk uafhængig variabel (f.eks. favorit_sport). For at oprette denne kategoriske uafhængige variabel har SPSS Statistics en variabelvisning, hvor du definerer de typer af variabler, du analyserer, og en datavisning, hvor du indtaster dine data for denne variabel. I dette afsnit viser vi dig først, hvordan du opstiller en kategorisk uafhængig variabel i vinduet Variable View i SPSS Statistics, før vi viser dig, hvordan du indtaster dine data i vinduet Data View. Vi gør dette ved hjælp af vores kategoriske uafhængige variabel, favourite_sport, som har tre kategorier: “svømning”, “cykling” og “løb”.
Variabelvisning i SPSS Statistics
For en enkelt kategorisk uafhængig variabel (f.eks, favourite_sport), vil dit Variable View-vindue se ud som det nedenfor:
Note: Du kan få adgang til Variable View-vinduet i SPSS Statistics ved at klikke på fanen ![]() i nederste venstre hjørne af SPSS Statistics-softwaren.
i nederste venstre hjørne af SPSS Statistics-softwaren.
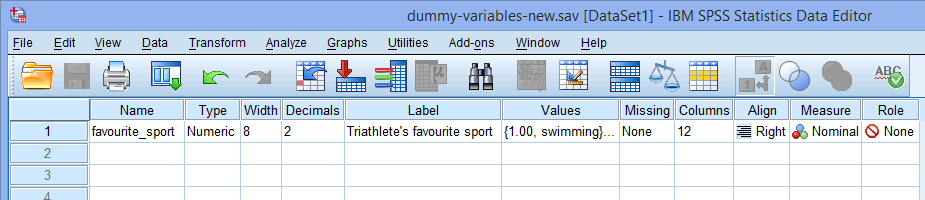
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Navnet på din kategoriske uafhængige variabel skal indtastes i cellen under ![]() -kolonnen (f.eks, “favourite_sport” i række
-kolonnen (f.eks, “favourite_sport” i række ![]() for at repræsentere vores kategoriske uafhængige variabel, favourite_sport. Der er visse “ulovlige” tegn, som ikke kan indtastes i cellen
for at repræsentere vores kategoriske uafhængige variabel, favourite_sport. Der er visse “ulovlige” tegn, som ikke kan indtastes i cellen ![]() . Hvis du derfor får en fejlmeddelelse, og du gerne vil have os til at tilføje en SPSS Statistics-vejledning, der forklarer, hvad disse ulovlige tegn er, bedes du kontakte os.
. Hvis du derfor får en fejlmeddelelse, og du gerne vil have os til at tilføje en SPSS Statistics-vejledning, der forklarer, hvad disse ulovlige tegn er, bedes du kontakte os.
Note: For din egen skyld kan du også angive en etiket for dine variabler i kolonnen ![]() . F.eks. var den etiket, vi indtastede for “favourite_sport” “Triathletes favourite sport”.
. F.eks. var den etiket, vi indtastede for “favourite_sport” “Triathletes favourite sport”.
Cellen under ![]() -kolonnen skal indeholde oplysninger om kategorierne for din kategoriske uafhængige variabel (f.eks. “swimming”, “cycling” og “running” for favorite_sport. For at indtaste disse oplysninger skal du klikke i cellen under kolonnen
-kolonnen skal indeholde oplysninger om kategorierne for din kategoriske uafhængige variabel (f.eks. “swimming”, “cycling” og “running” for favorite_sport. For at indtaste disse oplysninger skal du klikke i cellen under kolonnen ![]() for din uafhængige variabel. Knappen
for din uafhængige variabel. Knappen ![]() vises i cellen. Klik på denne knap, og dialogboksen Værdilabels vises. Du skal nu give hver kategori af din uafhængige variabel en “værdi”, som du indtaster i feltet Værdi: (f.eks. “1”), samt en “etiket”, som du indtaster i feltet Etiket: (f.eks. “svømning”). Ved at klikke på knappen
vises i cellen. Klik på denne knap, og dialogboksen Værdilabels vises. Du skal nu give hver kategori af din uafhængige variabel en “værdi”, som du indtaster i feltet Værdi: (f.eks. “1”), samt en “etiket”, som du indtaster i feltet Etiket: (f.eks. “svømning”). Ved at klikke på knappen ![]() vises kodningen i hovedfeltet (f.eks. “1.00=”svømning” for favorit_sport). Opsætningen for vores kategoriske uafhængige variabel er vist i dialogboksen Value Labels nedenfor:
vises kodningen i hovedfeltet (f.eks. “1.00=”svømning” for favorit_sport). Opsætningen for vores kategoriske uafhængige variabel er vist i dialogboksen Value Labels nedenfor:
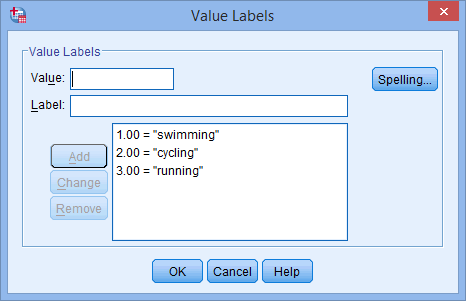
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Cellen under kolonnen ![]() bør vise
bør vise ![]() , hvis du har en nominel uafhængig variabel (f.eks, favorit_sport, som i vores eksempel) eller
, hvis du har en nominel uafhængig variabel (f.eks, favorit_sport, som i vores eksempel) eller ![]() , hvis du har en ordinal uafhængig variabel (forestil dig f.eks. en ordinalvariabel som “Body Mass Index” (BMI), BMI), som har fire niveauer: “Undervægt”, “sund/normal vægt”, “overvægt” og “fedme”). Endelig skal cellen under kolonnen
, hvis du har en ordinal uafhængig variabel (forestil dig f.eks. en ordinalvariabel som “Body Mass Index” (BMI), BMI), som har fire niveauer: “Undervægt”, “sund/normal vægt”, “overvægt” og “fedme”). Endelig skal cellen under kolonnen ![]() vise
vise ![]() .
.
Note: Vi foreslår at ændre cellen under kolonnen ![]() fra
fra ![]() til
til ![]() , men du behøver ikke at foretage denne ændring. Vi foreslår, at du gør det, fordi der er visse analyser i SPSS Statistics, hvor indstillingen
, men du behøver ikke at foretage denne ændring. Vi foreslår, at du gør det, fordi der er visse analyser i SPSS Statistics, hvor indstillingen ![]() resulterer i, at dine variabler automatisk bliver overført til visse felter i de dialogbokse, du bruger. Da du måske ikke ønsker at overføre disse variabler, foreslår vi, at du ændrer indstillingen
resulterer i, at dine variabler automatisk bliver overført til visse felter i de dialogbokse, du bruger. Da du måske ikke ønsker at overføre disse variabler, foreslår vi, at du ændrer indstillingen ![]() til
til ![]() , så dette ikke sker automatisk.
, så dette ikke sker automatisk.
Du har nu med succes indtastet alle de oplysninger, som SPSS Statistics har brug for at vide om din kategoriske uafhængige variabel, i vinduet Variabelvisning. I næste afsnit viser vi dig, hvordan du indtaster dine data i vinduet Datavisning.
Datavisningen i SPSS Statistics
Baseret på filopsætningen for din kategoriske uafhængige variabel i vinduet Variabelvisning ovenfor, ser vinduet Datavisning således ud:
Bemærk: Du kan få adgang til vinduet Datavisning i SPSS Statistics ved at klikke på fanen ![]() i nederste venstre hjørne af SPSS Statistics-softwaren.
i nederste venstre hjørne af SPSS Statistics-softwaren.
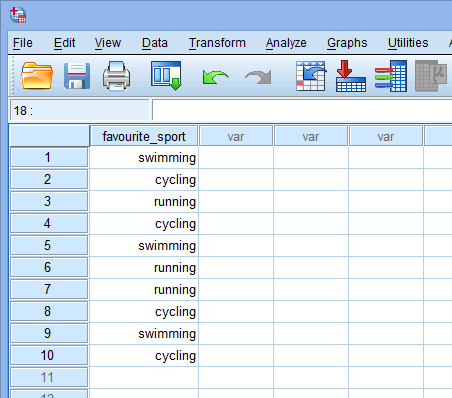
Udgivet med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Din kategoriske uafhængige variabel vil blive vist i den første kolonne, da det var den rækkefølge, vi indtastede variablen i vinduet Variabelvisning. I vores eksempel vises svarene fra de 10 triatleter under kolonnen ![]() . Nu skal du blot indtaste dine data i cellerne under denne første kolonne. Husk, at hver række repræsenterer et tilfælde (et tilfælde kan f.eks. være en enkelt deltager). I række
. Nu skal du blot indtaste dine data i cellerne under denne første kolonne. Husk, at hver række repræsenterer et tilfælde (et tilfælde kan f.eks. være en enkelt deltager). I række ![]() i vores eksempel repræsenterer det første tilfælde derfor en triatlet, hvis yndlingssport var “svømning”. Da disse celler i første omgang vil være tomme, skal du klikke ind i cellerne for at indtaste dine data. Du vil bemærke, at når du klikker ind i cellerne under kolonnen
i vores eksempel repræsenterer det første tilfælde derfor en triatlet, hvis yndlingssport var “svømning”. Da disse celler i første omgang vil være tomme, skal du klikke ind i cellerne for at indtaste dine data. Du vil bemærke, at når du klikker ind i cellerne under kolonnen ![]() , vil SPSS Statistics give dig en drop-down mulighed med dine kategorier allerede udfyldt.
, vil SPSS Statistics give dig en drop-down mulighed med dine kategorier allerede udfyldt.
Nu, hvor du har oprettet dine data i vinduerne Variable View og Data View i SPSS Statistics, anbefaler vi, at du læser næste afsnit: Forståelse af dummy-variabler og dummy-kodning, hvor vi forklarer de grundlæggende principper for dummy-variabler og dummy-kodning. Hvis du imidlertid allerede er bekendt med de grundlæggende principper for dummy-variabler og dummy-kodning, kan du springe dette afsnit over og gå direkte til afsnittet Procedure, hvor vi beskriver proceduren Create Dummy Variables i SPSS Statistics, som bruges til at oprette dummy-variabler.
SPSS Statistics
Forståelse af dummy-variabler og dummy-kodning
Som vi nævnte i indledningen, skal du vide, hvordan du opretter dummy-variabler og fortolker deres resultater, hvis du analyserer dine data ved hjælp af multipel regression, og nogen af dine uafhængige variabler blev målt på en nominel eller ordinær skala, hvis du analyserer dine data ved hjælp af multipel regression, og du skal vide, hvordan du opretter dummy-variabler og fortolker resultaterne. Dette skyldes, at kategoriske uafhængige variabler (dvs. nominelle og ordinale uafhængige variabler) ikke kan indtastes direkte i en multipel regression. I stedet skal de omdannes til dummy-variabler. Undtagelsen er ordinale uafhængige variabler, der indgår i en multipel regression som kontinuerte uafhængige variabler, som ikke skal konverteres til dummy-variabler. I afsnittene nedenfor forklarer vi det: (a) antallet af dummy-variabler, du skal oprette, og (b) hvordan du opretter dummy-variabler og dummy-kodning.
Antal dummy-variabler, du skal oprette
Antal dummy-variabler, du skal oprette, vil afhænge af, hvor mange kategorier din kategoriske uafhængige variabel har. Som hovedregel skal du oprette en dummy-variabel mindre end antallet af kategorier i din kategoriske uafhængige variabel. Hvis du f.eks. har en kategorisk uafhængig variabel med tre kategorier (f.eks. favorite_sport, med følgende tre kategorier: “svømning”, “cykling” og “løb”), opretter du to dummy-variabler og vælger en kategori som referencekategori (f.eks. bliver “svømning” og “cykling” dummy-variabler, og “løb” bliver referencekategorien). Vi forklarer mere om referencekategorier efter den følgende tabel, som indeholder nogle eksempler på kategoriske uafhængige variabler og antallet af dummy-variabler, der skal oprettes:
| Navn på den kategoriske uafhængige variabel | Type af variabel | Antal kategorier | Antal af dummy-variabler | ||||
|---|---|---|---|---|---|---|---|
| 1 | Køn | Nominalt | To (Mænd &Frakker) |
En=Mænd “Kvinder” er referencekategorien |
|||
| 2 | Højde | Ordinal | To (Under 180cm & 180cm og derover) |
One=Under 180cm “180cm og derover” er referencekategorien |
|||
| 3 | Ethnicitet | Nominalt | Tre (Afroamerikaner, Caucasian & Hispanic) |
To=Afroamerikaner & Caucasian “Hispanic” er referencekategorien |
|||
| 4 | Fysisk aktivitetsniveau | Ordinal | Tre (Lav, Moderat & Høj) |
To=Lav & Moderat “Høj” er referencekategorien |
|||
| 5 | Fag | Nominalt | Fire (Kirurgen, Læge, Sygeplejerske & Terapeut) |
Tre=Kirurg, Læge & Sygeplejerske “Terapeut” er referencekategorien |
|||
| 6 | Indflydelsesgrad | Ordinal | Fire (Helt enig, Enig, Uenig, Helt uenig) |
Tre=Stærk enig, Enig & Uenig “Helt uenig” er referencekategorien |
|||
| 7 | Fagområde | Nominalt | Fem (Business studies, Psykologi, biologiske videnskaber, ingeniørvidenskab & Jura) |
Fire=erhvervsstudier, psykologi, biologiske videnskaber & ingeniørvidenskab “Jura” er referencekategorien |
|||
| 8 | Alder | Ordinal | Fem (Under 18 år, 19-30, 31-40, 41-50, 51-60) |
Fire=Under 18, 19-30, 31-40 & 41-50 “51-60” er referencekategorien |
|||
| Tabel: Eksempler på kategoriske uafhængige variabler og deres respektive dummy-variabler | |||||||
Som det fremgår af ovenstående tabel, behøver du kun at oprette én dummy-variabel mindre end antallet af kategorier i din kategoriske uafhængige variabel. Det skyldes, at du kun behøver (og bør) overføre dette antal dummy-variabler til en multipel regression, når du har en kategorisk uafhængig variabel. Der er dog gode grunde til at oprette en dummy-variabel for hver kategori i den kategoriske uafhængige variabel: (a) det er mere fleksibelt, og (b) det giver mulighed for at foretage flere sammenligninger (se bemærkningen nedenfor). Med andre ord, hvis din kategoriske uafhængige variabel har tre kategorier, skal du oprette tre dummy-variabler, ikke blot to.
Glædeligvis opretter proceduren Create Dummy Variables i SPSS Statistics version 22 og nyere automatisk en dummy-variabel for hver kategori af din kategoriske uafhængige variabel. Dette er dog ikke tilfældet for proceduren Recode into Different Variables i SPSS Statistics version 21 eller tidligere. Derfor vil du under normale omstændigheder have oprettet følgende opsætning i SPSS Statistics, afhængigt af om du har version 21 eller tidligere eller version 22 og højere:
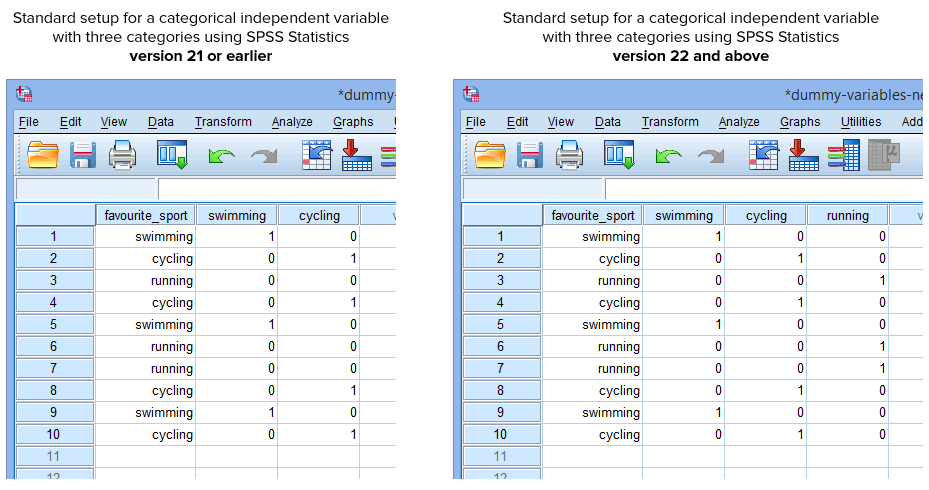
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Bemærk: Som nævnt ovenfor er det af to grunde fordelagtigt at oprette en dummy-variabel for hver kategori af den kategoriske uafhængige variabel: (a) det er mere fleksibelt, og (b) det gør det muligt at foretage flere sammenligninger. Vi berører kort disse fordele nedenfor:
Det er mere fleksibelt:
Når du har oprettet en dummy-variabel for hver kategori af din kategoriske uafhængige variabel, kan du derefter betragte enhver kategori som en referencekategori. I vores eksempel har vi betragtet kategorien “løb” som referencekategori, hvilket betyder, at vi ville have overført “svømning” og “cykling” til den multiple regressionsligning. Hvis vi imidlertid senere ændrede mening om vores valg af referencekategori, skulle vi køre dummy-variabelproceduren igen (medmindre du har SPSS Statistics version 22 eller nyere). Lad os f.eks. antage, at vi nu ønskede at betragte kategorien “cykling” som referencekategori. Vi kunne nu overføre dummy-variablerne “svømning” og “løb” til den multiple regressionsligning, fordi vi også har dummy-variablen “løb”.
Det giver mulighed for at foretage flere sammenligninger:
Koefficienten for en dummy-variabel repræsenterer forskellen mellem den kategori, som den pågældende dummy-variabel repræsenterer, og referencekategorien. Med “løb” som referencekategori repræsenterer koefficienten for dummy-variablen “svømning” f.eks. forskellen i den afhængige variabel mellem kategorierne “svømning” og “løb”. Ved anvendelse af denne metode vil ikke alle kombinationer af kategorier være mulige. Dette problem kan løses ved at anvende forskellige referencekategorier. Dette er muligt, hvis alle kategorier af den kategoriske variabel har en dummy-variabel.
Sådan oprettes dummy-variabler og dummy-kodning
Der er to trin for at få succes med at oprette dummy-variabler i en multipel regression: (1) opret dummy-variabler, der repræsenterer kategorierne for din kategoriske uafhængige variabel, og (2) indtast værdier i disse dummy-variabler – kendt som dummy-kodning – for at repræsentere kategorierne for den kategoriske uafhængige variabel. Vi forklarer denne proces nedenfor ved hjælp af det eksempel, vi opstillede ovenfor.
Forklaring: Dummy-variabler er simpelthen nye variabler, der fungerer som “pladsholdere” for et bestemt kodningsskema. De indeholder i sig selv ikke nogen data overhovedet. I stedet skal der tilføjes data/værdier til disse dummy-variabler, så de kan opfylde deres formål, nemlig at repræsentere kategorierne for din kategoriske uafhængige variabel. Der findes mange forskellige typer kodningsskemaer, som dikterer de værdier, der indtastes i dummy-variabler, men vi anvender et meget almindeligt kodningsskema, der kaldes dummy-kodning eller alternativt indikator-kodning (bemærk, at du ikke må blive forvirret, for dummy-variabler og dummy-kodning er ikke det samme). Dummy-kodning fungerer ved at bruge hver dummy-variabel til at identificere en specifik kategori af en kategorisk uafhængig variabel med undtagelse af en referencekategori, som vi forklarer nedenfor.
Lad os starte med at betragte vores eksempel på en kategorisk uafhængig variabel, favorit_sport, som har tre kategorier: “svømning”, “cykling” og “løb”. Da der er tre kategorier, skal der være to dummy-variable, der repræsenterer to af kategorierne, og en referencekategori, der repræsenterer den tredje kategori.
Bemærk: Husk fra diskussionen ovenfor, at en multipel regression kræver, at du overfører én dummy-variabel mindre end antallet af kategorier i din kategoriske uafhængige variabel (dvs. to i vores eksempel). Du kan dog oprette en dummy-variabel for hver kategori i den kategoriske uafhængige variabel af hensyn til større fleksibilitet og muligheden for at foretage flere sammenligninger. Ikke desto mindre fremhæver vi i nedenstående diskussion kun det, der er nødvendigt for en multipel regression; dvs. oprettelse af én dummyvariabel mindre end antallet af kategorier i din kategoriske uafhængige variabel, idet den kategori, der ikke er direkte repræsenteret, bliver “referencekategori”.
Lad f.eks. dummyvariabel nr. 1 repræsentere kategorien “svømning” og dummyvariabel nr. 2 repræsentere kategorien “cykling”. Der er således ingen dummy-variabel tilbage for kategorien “løb”. Denne “manglende” kategori er referencekategorien, og den er ikke nødvendig. Det er desuden helt op til Dem, hvilken kategori De ønsker at bruge som referencekategori. Vi kunne lige så godt have valgt kategorien “svømning” som referencekategori i stedet for kategorien “løb”. Den eneste grund til, at vi ikke gjorde det, er, at SPSS Statistics som standard bruger den sidste kategori, du har kodet i variabelvisningen for din kategoriske uafhængige variabel, som referencekategori (se bemærkningen nedenfor).
Bemærkning: Som forklaret i afsnittet Dataopsætning tidligere og som vist nedenfor i dialogboksen Værdilabels var den tredje og sidste kategori for vores kategoriske uafhængige variabel “løb” (dvs, 3=”running”).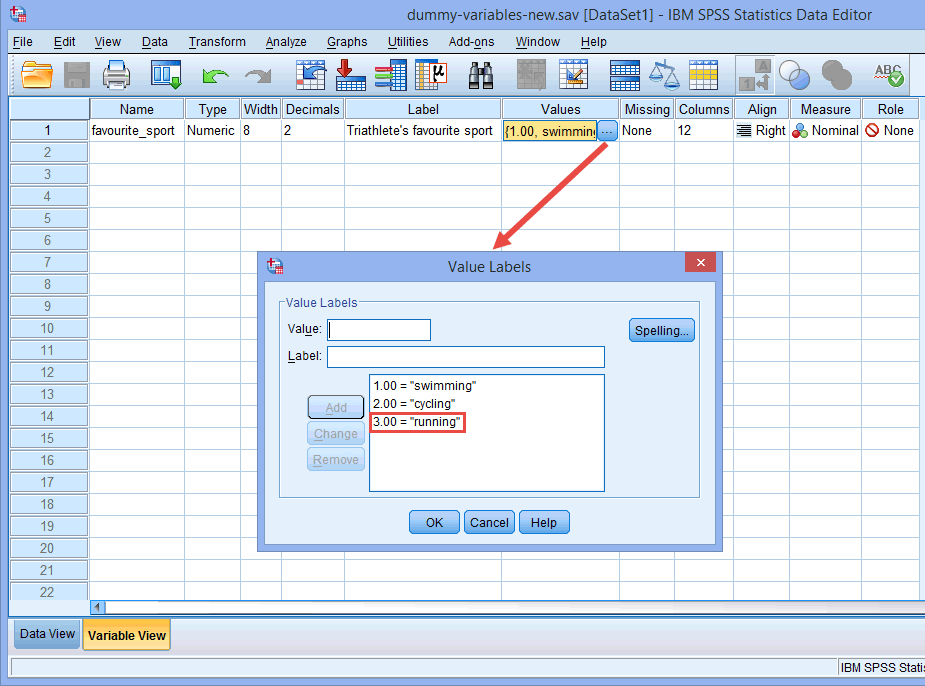
Der var ingen teoretisk eller statistisk grund til, at vi skulle gøre kategorien “running” til den tredje og sidste kategori, hvilket gjorde den til referencekategori i SPSS Statistics som standard. Vi gjorde det simpelthen på denne måde, fordi når triatleter deltager i en triatlon, svømmer de først, derefter foretager de en cykeltur, før de til sidst løber til målstregen. Derfor virkede det logisk at kode vores kategoriske uafhængige variabel på denne måde. Vi kunne dog have kodet den som 1=cykling, 2=løb og 3=svømning; det ville ikke have gjort nogen forskel bortset fra, at “svømning” som den tredje og sidste kategori ville være blevet vores referencekategori som standard i SPSS Statistics.
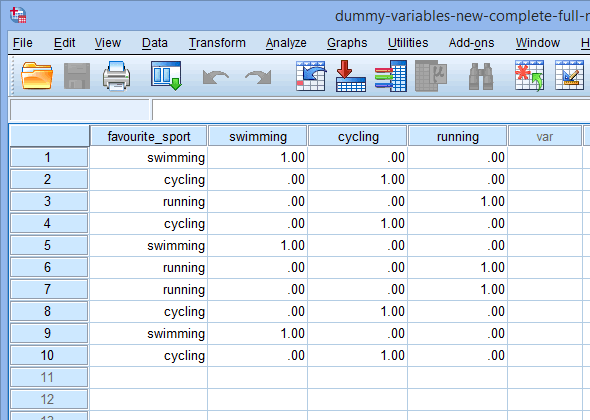
Når man opretter dummy-variabler, bør man give dem et meningsfuldt navn. Da hver af vores dummy-variabler repræsenterer en kategori af vores kategoriske uafhængige variabel, er det almindeligt at henvise til hver dummy-variabel ved navnet på den kategori, den repræsenterer. Derfor har vi kaldt dummyvariabel nr. 1 “svømning”, da den repræsenterer kategorien svømning. På samme måde har vi kaldt dummyvariabel nr. 2 for “cykling”, da den repræsenterer kategorien cykling. Ved at oprette disse to dummy-variabler får vi to nye kolonner i vores datasæt i SPSS Statistics, som vist nedenfor:
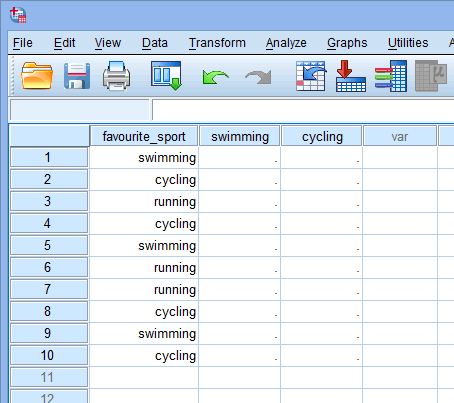
Udgivet med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Nu, hvor vi har oprettet to dummy-variabler og givet dem passende navne, skal vi indtaste værdier i disse variabler, så hver dummy-variabel virkelig repræsenterer sin kategori af den kategoriske uafhængige variabel. Med dummy-kodning er dette meget enkelt. Du indtaster et “1” for at repræsentere ethvert tilfælde (f.eks. en deltager i dit datasæt), der har kategorien, og du indtaster et “0” (nul), hvis de ikke har kategorien. Først betragtes dummy-variablen “svømning”, som vist nedenfor:
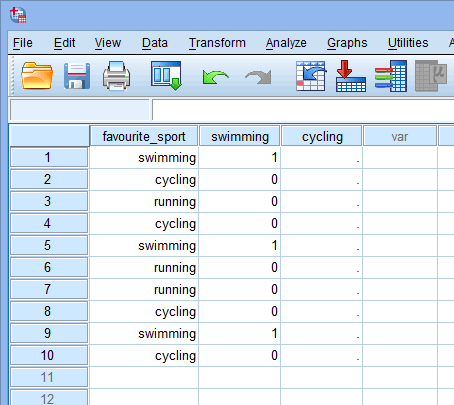
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Hvis en af triatleterne angav, at “svømning” var deres “yndlings”-sport, ville vi indtaste et “1” i cellen under kolonnen med dummy-variablen “svømning” (![]() ) for den triatlet, der angav, at svømning var deres “yndlings”-sport. Hvis en af triatleterne derimod angav, at “cykling” eller “løb” var deres “yndlingsidræt”, ville vi indtaste et “0” i cellen under kolonnen med dummy-variabel for svømning (
) for den triatlet, der angav, at svømning var deres “yndlings”-sport. Hvis en af triatleterne derimod angav, at “cykling” eller “løb” var deres “yndlingsidræt”, ville vi indtaste et “0” i cellen under kolonnen med dummy-variabel for svømning (![]() ) for den triatlet, der angav, at svømning “ikke” var deres yndlingssport (dvs. at enten “cykling” eller “løb” var den pågældende triatlets yndlingssport). Dette er fremhævet nedenfor for alle 10 triatleter:
) for den triatlet, der angav, at svømning “ikke” var deres yndlingssport (dvs. at enten “cykling” eller “løb” var den pågældende triatlets yndlingssport). Dette er fremhævet nedenfor for alle 10 triatleter:
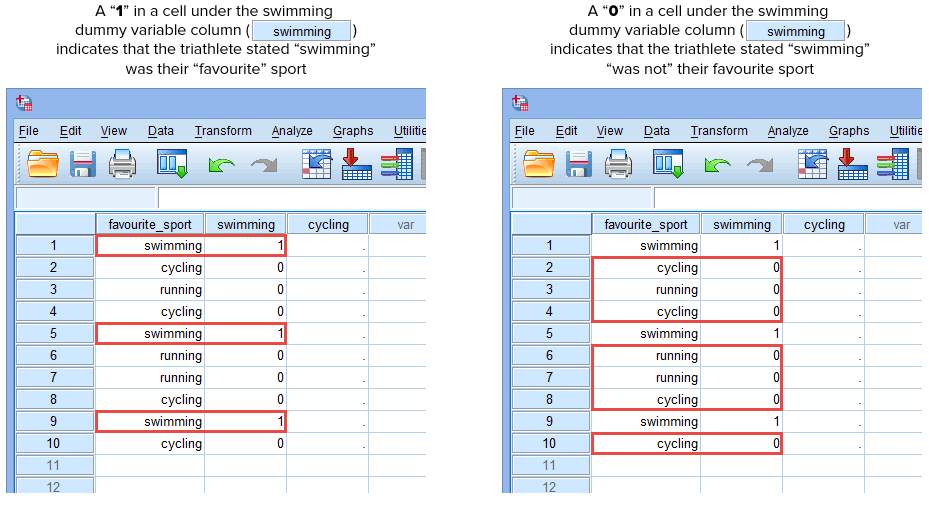
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Vi gentager denne proces for den anden dummy-variabel, “cykling”, som vist nedenfor:
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Hvis en af triatleterne angav, at “cykling” var deres “yndlings”-sport, ville vi indtaste et “1” i cellen under dummy-variabelkolonnen for cykling (![]() ) for den triatlet, der angav, at cykling var deres “yndlings”-sport. Hvis en af triatleterne derimod angav, at “svømning” eller “løb” var deres “yndlingsidræt”, ville vi indtaste et “0” i cellen under kolonnen med dummy-variabel for cykling (
) for den triatlet, der angav, at cykling var deres “yndlings”-sport. Hvis en af triatleterne derimod angav, at “svømning” eller “løb” var deres “yndlingsidræt”, ville vi indtaste et “0” i cellen under kolonnen med dummy-variabel for cykling (![]() ) for den triatlet, der angav, at cykling “ikke” var deres yndlingsidræt (dvs. at enten “svømning” eller “løb” var den pågældende triatlets yndlingssport). Dette er fremhævet nedenfor for alle 10 triatleter:
) for den triatlet, der angav, at cykling “ikke” var deres yndlingsidræt (dvs. at enten “svømning” eller “løb” var den pågældende triatlets yndlingssport). Dette er fremhævet nedenfor for alle 10 triatleter:
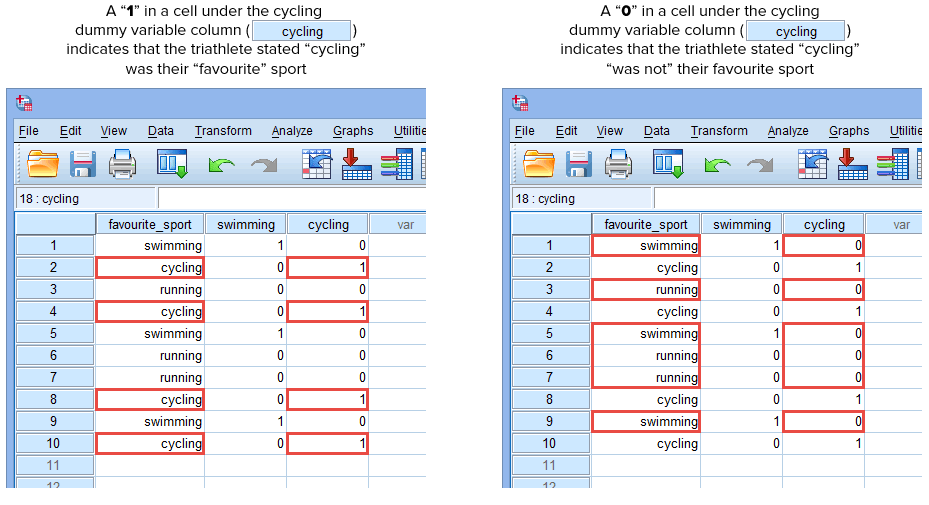
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Gennem at indtaste “1 “er og “0 “er i dine dummy-variabler på denne måde har du skabt et sæt dummy-variabler, som du kan indtaste i en multipel regressionsanalyse. I afsnittet Procedure, der følger, viser vi dig, hvordan du opretter disse dummy-variabler ved hjælp af proceduren Opret dummy-variabler.
SPSS Statistics
Procedure i SPSS Statistics til oprettelse af dummy-variabler
Der findes to procedurer i SPSS Statistics til oprettelse af dummy-variabler: proceduren Opret dummy-variabler og proceduren Omkodning til forskellige variabler. I denne vejledning viser vi dig, hvordan du bruger proceduren Create Dummy Variables (Opret dummyvariabler), som er en enkel procedure i 3 trin. Den er dog kun tilgængelig, hvis du har SPSS Statistics version 22 eller nyere, idet version 26 (og abonnementsversionen af SPSS Statistics) er den nyeste version af SPSS Statistics. Hvis du er usikker på, hvilken version af SPSS Statistics du bruger, kan du se vores vejledning: Identificering af din version af SPSS Statistics. Hvis du har SPSS Statistics version 21 eller tidligere eller er interesseret i at foretage flere sammenligninger, når du udfører din multiple regressionsanalyse, skal du se nedenstående note:
Note: Hvis du har SPSS Statistics version 21 eller tidligere, kan du ikke bruge proceduren Create Dummy Variables (Opret dummy-variabler). Derfor giver proceduren Recode into Different Variables dig i det mindste mulighed for at oprette dummy-variabler i SPSS Statistics. Selv om du også kan bruge proceduren Recode into Different Variables til at oprette dummy-variabler, hvis du har SPSS Statistics version 22 eller nyere, har vi i denne vejledning beskrevet proceduren Create Dummy Variables, fordi den er dedikeret til at oprette dummy-variabler og er meget nemmere og hurtigere at bruge. Den kræver f.eks. kun 3 trin for at oprette dummy-variabler for det eksempel, der er anvendt i denne vejledning, sammenlignet med 28 trin for det samme eksempel ved hjælp af proceduren Recode into Different Variables.
Så hvis du har SPSS Statistics version 21 eller tidligere, indeholder vores udvidede vejledning om Creating dummy variables i medlemsafsnittet om Laerd Statistics en side, der er dedikeret til at vise, hvordan du udfører denne 28-trins procedure Recode into Different Variables. Du kan få adgang til denne udvidede vejledning ved at abonnere på Laerd Statistics. Alternativt kan du blot bruge nedenstående procedure Opret dummy-variabler.
For at oprette dummy-variabler, når du har SPSS Statistics version 22 eller nyere, skal du følge nedenstående 3-trins procedure Opret dummy-variabler:
- Klik på Transform > Opret dummy-variabler i hovedmenuen, som vist nedenfor:

Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Du får vist dialogboksen Opret dummyvariabler, som vist nedenfor:
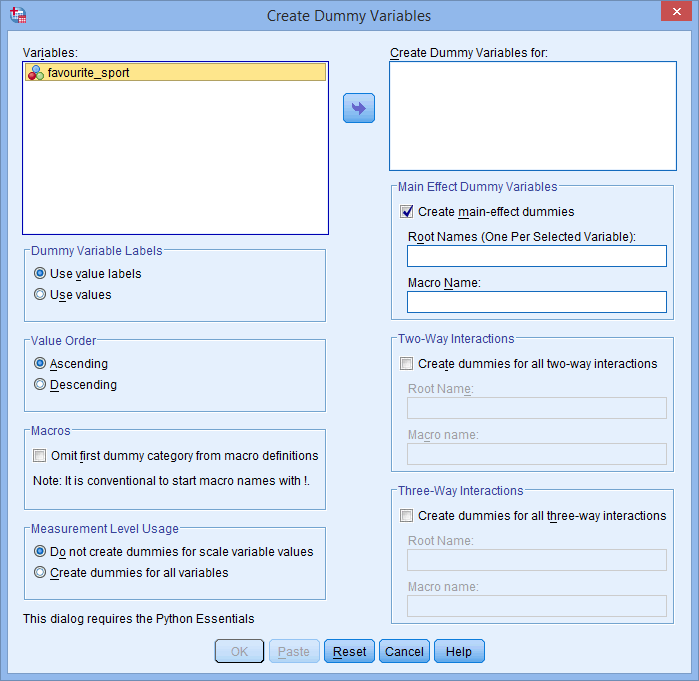
Udgivet med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
- Overfør den kategoriske uafhængige variabel, favourite_sport, til boksen Opret dummyvariabler for: ved at markere den (ved at klikke på den) og derefter klikke på knappen
 . Indtast også et “rodnavn”, der kan repræsentere alle de nye dummy-variabler, i feltet Root Names (One Per Selected Variable): i området -Main Effect Dummy Variables- (Dummy-variabler med hovedvirkning). Vi indtastede rodnavnet “fs” som en forkortelse for vores kategoriske uafhængige variabel, “favorite_sport”, som vist nedenfor:
. Indtast også et “rodnavn”, der kan repræsentere alle de nye dummy-variabler, i feltet Root Names (One Per Selected Variable): i området -Main Effect Dummy Variables- (Dummy-variabler med hovedvirkning). Vi indtastede rodnavnet “fs” som en forkortelse for vores kategoriske uafhængige variabel, “favorite_sport”, som vist nedenfor:
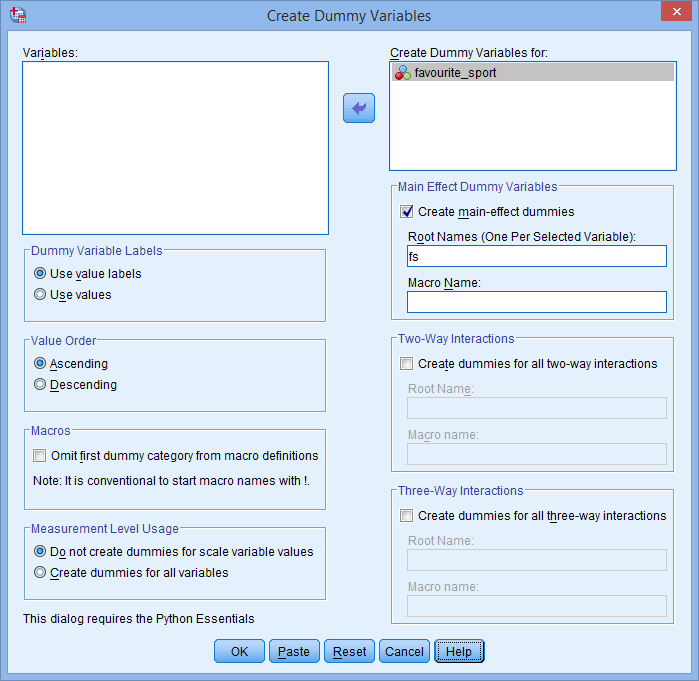
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Bemærk: SPSS Statistics tilføjer et fortløbende nummer (dvs. 1, 2, 3, 4 osv.) i slutningen af det rodnavn, du vælger til at repræsentere din kategoriske uafhængige variabel. Der oprettes et fortløbende nummer for hver af de dummy-variabler, du ønsker at oprette (hvis du f.eks. har to dummy-variabler, vil der blive tilføjet et 1 og 2 i slutningen af rodnavnet, men hvis du har seks dummy-variabler, vil der blive tilføjet et 1, 2, 3, 3, 4, 4, 5 og 6 i slutningen af rodnavnet). Dette er vist for vores eksempel i vinduet Variabelvisning nedenfor:
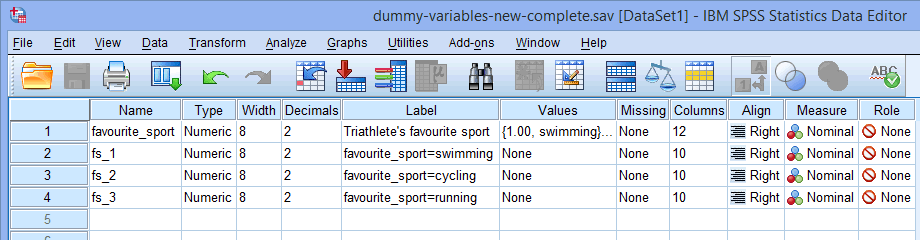
Da vores kategoriske uafhængige variabel, favorit_sport, havde tre kategorier (dvs. svømning, cykling og løb), opretter proceduren Opret dummyvariabler tre dummyvariabler (dvs. en for svømning, en for cykling og en for løb). Disse tre dummy-variabler er fremhævet i kolonnen ovenfor: “fs_1” (for svømning), “fs_2” (for cykling) og “fs_3” (for løb). Du kan omdøbe disse senere, så de giver mere mening. Vi fremhæver blot dette, så du ved, hvordan feltet Root Names (One Per Selected Variable): ovenfor fungerer.
ovenfor: “fs_1” (for svømning), “fs_2” (for cykling) og “fs_3” (for løb). Du kan omdøbe disse senere, så de giver mere mening. Vi fremhæver blot dette, så du ved, hvordan feltet Root Names (One Per Selected Variable): ovenfor fungerer.
Det rodenavn, du indtaster i feltet Root Names (One Per Selected Variable):, kan heller ikke være det samme som navnet på din kategoriske uafhængige variabel, som vist nedenfor (dvs, hvor vi har indtastet rodnavnet “favourite_sport” for at illustrere, hvad vi ikke kunne kalde vores rodnavn):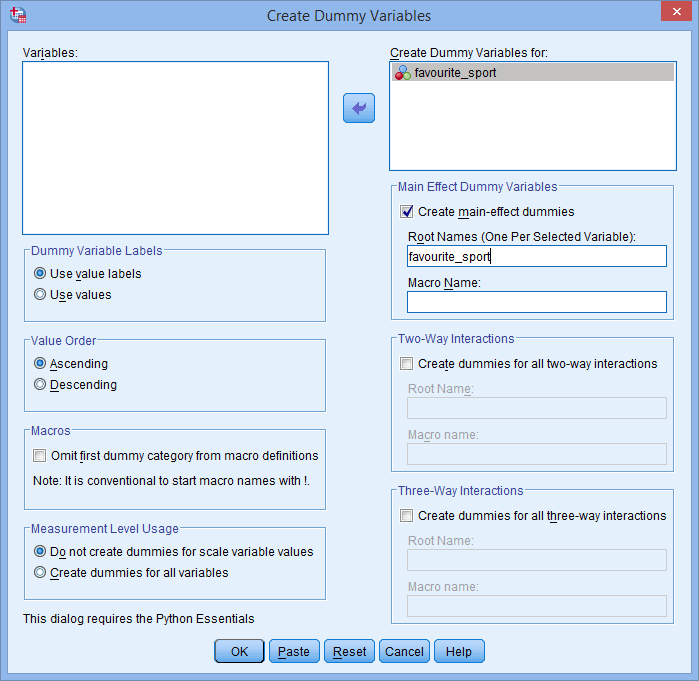
Hvis det rodnavn, du indtaster, er det samme som navnet på din kategoriske uafhængige variabel, som vist ovenfor, vil du, når du klikker på knappen , få følgende advarsel:
, få følgende advarsel:
- Klik på knappen .
Når du har udført ovenstående 3-trins procedure Opret dummyvariabel, har du oprettet dummyvariabler for din kategoriske uafhængige variabel. I næste afsnit fremhæves det output, der oprettes i Variable View og Data View i SPSS Statistics efter at have kørt denne Create Dummy Variables-procedure.
SPSS Statistics
Output og dataopsætning i SPSS Statistics efter oprettelse af dummy-variabler
Når du har oprettet dine dummy-variabler, producerer SPSS Statistics følgende Variable Creation table dens IBM SPSS Statistics Viewer:
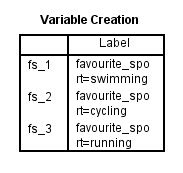
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Tabellen Variabeloprettelse bekræfter, at du har oprettet dummy-variabler. Der bør være lige så mange rækker, som der er nye dummy-variabler. Da vi har oprettet tre dummy-variabler, er der tre rækker i tabellen, “fs_1”, “fs_2” og “fs_3”, som afspejler det rodnavn og den fortløbende nummerering, der blev indtastet i trin 2 i proceduren Opret dummy-variabler i det foregående afsnit. For hver af disse dummy-variabler er der angivet en etiket i tabellen for at gøre det klart, hvilken kategori af den kategoriske uafhængige variabel hver dummy-variabel repræsenterer. F.eks. er etiketten “favourite_sport=swimming” angivet for “fs_1”, hvilket angiver, at “fs_1” er dummy-variablen for kategorien “svømning” af den kategoriske uafhængige variabel, favourite_sport.
Næst skal du gå til vinduet Variable View i SPSS Statistics ved at klikke på fanen ![]() . De tre dummy-variabler vil være blevet tilføjet, som vist nedenfor (dvs. dummy-variablerne “fs_1”, “fs_2” og “fs_3” i kolonnen
. De tre dummy-variabler vil være blevet tilføjet, som vist nedenfor (dvs. dummy-variablerne “fs_1”, “fs_2” og “fs_3” i kolonnen ![]() ):
):
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Bemærk: Du kan ændre navnene på dummy-variablerne i kolonnen ![]() for at gøre det mere tydeligt, hvad de er. Vi har f.eks. ændret “fs_1” til “svømning”, “fs_2” til “cykling” og “fs_3” til “løb”, som vist nedenfor:
for at gøre det mere tydeligt, hvad de er. Vi har f.eks. ændret “fs_1” til “svømning”, “fs_2” til “cykling” og “fs_3” til “løb”, som vist nedenfor:
Til sidst skal du gå til vinduet Datavisning i SPSS Statistics ved at klikke på fanen ![]() . Dummy-kodningen vises under hver af de dummy-variabler, der er blevet oprettet. I rækkerne under kolonnen “fs_1” er kategorien “svømning” f.eks. kodet som “1,00”, mens kategorierne “cykling” og “løb” er kodet som “,00”, som vist nedenfor. Hvis du er usikker på, hvorfor disse dummy-variabler er dummy-kodet på denne måde, kan du se afsnittet: Forståelse af dummy-variabler og dummy-kodning.
. Dummy-kodningen vises under hver af de dummy-variabler, der er blevet oprettet. I rækkerne under kolonnen “fs_1” er kategorien “svømning” f.eks. kodet som “1,00”, mens kategorierne “cykling” og “løb” er kodet som “,00”, som vist nedenfor. Hvis du er usikker på, hvorfor disse dummy-variabler er dummy-kodet på denne måde, kan du se afsnittet: Forståelse af dummy-variabler og dummy-kodning.
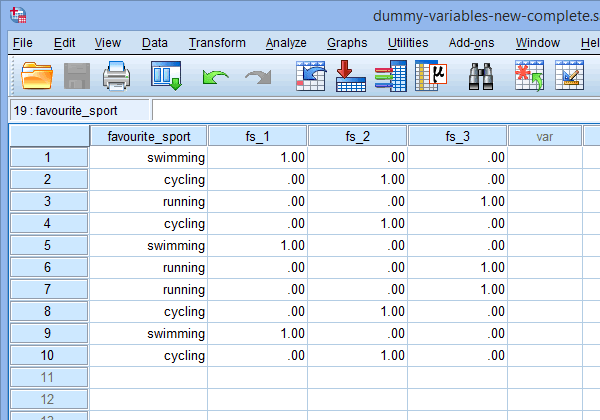
Publiceret med skriftlig tilladelse fra SPSS Statistics, IBM Corporation.
Note 1: På grund af standardindstillingerne i SPSS Statistics vil dine dummy-variabler blive kodet som henholdsvis “1.00” eller “.00” i stedet for “1” eller “0”. De er identiske. Du vil dog ofte se dummy-kodning skrevet i form af 1’er og 0’er i stedet for at inkludere decimaler.
Note 2: Hvis du har ændret navnene på dummy-variablerne i kolonnen ![]() i vinduet Variabelvisning ovenfor, vil disse også være blevet ændret i kolonnerne i vinduet Datavisning, som vist nedenfor (f.eks. hedder kolonneoverskriften
i vinduet Variabelvisning ovenfor, vil disse også være blevet ændret i kolonnerne i vinduet Datavisning, som vist nedenfor (f.eks. hedder kolonneoverskriften ![]() nu
nu ![]() ):
):