
Hvor jeg begyndte på denne rejse, hvor jeg forsøgte at lære datalogi, var der visse udtryk og sætninger, der fik mig til at løbe den anden vej.
Men i stedet for at løbe, foregav jeg at kende til det, nikkede med i samtaler og lod som om jeg vidste, hvad nogen henviste til, selv om sandheden var, at jeg ingen anelse havde og faktisk var holdt helt op med at lytte, da jeg hørte That Super Scary Computer Science Term™. I løbet af denne serie er det lykkedes mig at dække en masse område, og mange af disse termer er faktisk blevet meget mindre skræmmende!
Der er dog en stor en, som jeg har undgået i et stykke tid. Indtil nu har jeg, hver gang jeg havde hørt dette udtryk, følt mig lammet. Det er kommet op i afslappet samtale på meet ups og nogle gange i konferencesamtaler. Hver eneste gang tænker jeg på maskiner, der snurrer, og computere, der spytter kodestrenge ud, som er uopfattelige, bortset fra at alle andre omkring mig faktisk kan tyde dem, så det er faktisk kun mig, der ikke ved, hvad der foregår (ups, hvordan er det sket?!).
Måske er jeg ikke den eneste, der har følt det på den måde. Men jeg burde vel fortælle, hvad dette udtryk egentlig er, ikke? Nå, men gør dig klar, for jeg henviser til det evigt flygtige og tilsyneladende forvirrende abstrakte syntaksetræ, eller AST forkortet. Efter mange års intimiderethed glæder jeg mig til endelig at holde op med at være bange for dette begreb og virkelig forstå, hvad i alverden det er.
Det er på tide at se roden til det abstrakte syntaksetræ direkte i øjnene – og sætte vores parsingspil på et højere niveau!
Alle gode søgen starter med et solidt fundament, og vores mission om at afmystificere denne struktur bør begynde på nøjagtig samme måde: med en definition, naturligvis!
Et abstrakt syntaksetræ (normalt bare omtalt som et AST) er i virkeligheden ikke andet end en forenklet, kondenseret version af et parse tree. I forbindelse med compiler-design bruges udtrykket “AST” i flæng med syntaksetræ.

Vi tænker ofte på syntaksetræer (og hvordan de er konstrueret) i sammenligning med deres parse tree-modstykker, som vi allerede er ret bekendt med. Vi ved, at parse-træer er træ-datastrukturer, der indeholder den grammatiske struktur af vores kode; med andre ord indeholder de alle de syntaktiske oplysninger, der forekommer i en kode-“sætning”, og som er afledt direkte af grammatikken i selve programmeringssproget.
Et abstrakt syntaksetræ ignorerer derimod en betydelig mængde af de syntaktiske oplysninger, som et parse-træ ellers ville indeholde.
Derimod indeholder et AST kun de oplysninger, der vedrører analysen af kildeteksten, og springer alt andet ekstra indhold over, som bruges under parsningen af teksten.
Denne skelnen begynder at give meget mere mening, hvis vi fokuserer på “abstraktheden” i et AST.
Vi skal huske, at et parsetræ er en illustreret, billedlig version af den grammatiske struktur i en sætning. Med andre ord kan vi sige, at et parse tree repræsenterer præcis, hvordan et udtryk, en sætning eller en tekst ser ud. Det er dybest set en direkte oversættelse af selve teksten; vi tager sætningen og omdanner hver eneste lille del af den – fra tegnsætning til udtryk og tokens – til en trædatastruktur. Det afslører den konkrete syntaks i en tekst, hvilket er grunden til, at det også kaldes et konkret syntaksetræ, eller CST. Vi bruger udtrykket konkret til at beskrive denne struktur, fordi det er en grammatisk kopi af vores kode, token for token, i træformat.
Men hvad gør noget konkret i forhold til abstrakt? Jo, et abstrakt syntaksetræ viser os ikke præcis, hvordan et udtryk ser ud, på samme måde som et parse-træ gør.

Snarere viser et abstrakt syntaksetræ os de “vigtige” dele – de ting, som vi virkelig interesserer os for, og som giver mening til selve vores kode-“sætning”. Syntaksetræer viser os de vigtige dele af et udtryk eller den abstrakte syntaks i vores kildetekst. Derfor er disse strukturer i sammenligning med konkrete syntaksetræer abstrakte repræsentationer af vores kode (og på nogle måder mindre nøjagtige), hvilket er præcis, hvordan de har fået deres navn.
Nu da vi forstår forskellen mellem disse to datastrukturer og de forskellige måder, de kan repræsentere vores kode på, er det værd at stille spørgsmålet: Hvor passer et abstrakt syntaksetræ ind i compileren? Lad os først minde os selv om alt det, vi ved om kompileringsprocessen, som vi kender den indtil videre.

Lad os sige, at vi har en superkort og sød kildetekst, som ser således ud: 5 + (1 x 12).
Vi husker, at det første, der sker i kompileringsprocessen, er scanningen af teksten, et arbejde, der udføres af scanneren, hvilket resulterer i, at teksten bliver opdelt i sine mindste mulige dele, som kaldes lexemer. Denne del vil være sprognostisk, og vi ender med en strippet version af vores kildetekst.
Dernæst sendes netop disse lexemer videre til lexer/tokenizer, som forvandler disse små repræsentationer af vores kildetekst til tokens, som vil være specifikke for vores sprog. Vores tokens vil se nogenlunde sådan her ud: . Den fælles indsats af scanneren og tokenizer udgør den leksikalske analyse af kompileringen.
Når vores input er blevet tokeniseret, sendes de resulterende tokens videre til vores parser, som derefter tager kildeteksten og opbygger et parse-træ ud fra den. Illustrationen nedenfor eksemplificerer, hvordan vores tokeniserede kode ser ud i parsetræformat.
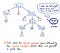
Arbejdet med at omdanne tokens til et parsetræ kaldes også parsing, og er kendt som syntaksanalysefasen. Syntaksanalysefasen er direkte afhængig af den leksikalske analysefase; derfor skal den leksikalske analyse altid komme først i kompileringsprocessen, fordi vores compilers parser først kan gøre sit arbejde, når tokenizer’en har gjort sit arbejde!
Vi kan tænke på compilerens dele som gode venner, der alle er afhængige af hinanden for at sikre, at vores kode bliver korrekt transformeret fra en tekst eller fil til et parsetræ.
Men tilbage til vores oprindelige spørgsmål: Hvor passer det abstrakte syntaksetræ ind i denne vennegruppe? Tja, for at kunne besvare det spørgsmål hjælper det at forstå behovet for et AST i første omgang.
Kondensering af et træ til et andet
Okay, så nu har vi to træer at holde styr på i vores hoveder. Vi havde allerede et parse tree, og hvordan er der endnu en datastruktur at lære! Og tilsyneladende er denne AST-datastruktur bare et forenklet parse-træ. Så hvorfor har vi brug for det? Hvad er overhovedet meningen med det?
Nå, men lad os tage et kig på vores parsetræ, skal vi?
Vi ved allerede, at parsetræer repræsenterer vores program i dets mest adskilte dele; det var faktisk derfor, at scanneren og tokenizeren har så vigtige opgaver med at nedbryde vores udtryk i dets mindste dele!
Hvad betyder det egentlig at repræsentere et program ved dets mest adskilte dele?
Som det viser sig, er alle de forskellige dele af et program nogle gange faktisk ikke så nyttige for os hele tiden.
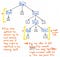
Lad os tage et kig på den viste illustration her, som repræsenterer vores oprindelige udtryk, 5 + (1 x 12), i parse tree tree-format. Hvis vi kigger nærmere på dette træ med et kritisk øje, vil vi se, at der er nogle få tilfælde, hvor en knude har præcis ét barn, som også kaldes single-successor-noder, da de kun har én barnknude, der stammer fra dem (eller én “successor”).
I tilfældet med vores parse-træeksempel har single-successor-noderne en overordnet node på en Expression eller Exp, som har en enkelt efterfølger af en eller anden værdi, f.eks. 5, 1 eller 12. Men Exp-forældreknuderne her tilføjer faktisk ikke noget af værdi for os, gør de? Vi kan se, at de indeholder token/terminal-underknuder, men vi er egentlig ligeglade med forælderknuden “expression”; det eneste, vi virkelig ønsker at vide, er, hvad udtrykket er?
Forælderknuden giver os slet ingen yderligere oplysninger, når vi har analyseret vores træ. I stedet er det, vi virkelig er optaget af, den enkelte barn- og efterfølgerknude. Det er nemlig den knude, der giver os de vigtige oplysninger, den del, der er betydningsfuld for os: selve tallet og værdien! I betragtning af at disse overordnede knuder er en slags unødvendige for os, bliver det tydeligt, at dette parse tree er en slags verbose.
Alle disse single-successor-noder er temmelig overflødige for os, og hjælper os slet ikke. Så lad os skille os af med dem!
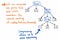
Hvis vi komprimerer single-successor-knuderne i vores parsetræ, ender vi med en mere komprimeret version af den samme nøjagtige struktur. Hvis vi ser på illustrationen ovenfor, kan vi se, at vi stadig bevarer nøjagtig den samme indlejring som før, og vores noder/tokens/terminaler vises stadig på det korrekte sted i træet. Men det er lykkedes os at slanke det en smule.
Og vi kan også trimme noget mere af vores træ. Hvis vi f.eks. kigger på vores parse-træ, som det ser ud i øjeblikket, vil vi se, at der er en spejlstruktur i det. Underudtrykket af (1 x 12) er indlejret i parenteser (), som er tokens i sig selv.
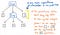
Disse parenteser hjælper os dog ikke rigtig, når vi først har fået vores træ på plads. Vi ved allerede, at 1 og 12 er argumenter, der vil blive videregivet til x-multiplikationsoperationen x, så parenteserne fortæller os ikke så meget på dette tidspunkt. Faktisk kunne vi komprimere vores parse-træ endnu mere og slippe af med disse overflødige bladknuder.
Når vi komprimerer og forenkler vores parse-træ og slipper af med det overflødige syntaktiske “støv”, ender vi med en struktur, der ser synligt anderledes ud på dette punkt. Denne struktur er faktisk vores nye og længe ventede ven: det abstrakte syntaksetræ.

Billedet ovenfor illustrerer nøjagtigt det samme udtryk som vores parse-træ: 5 + (1 x 12). Forskellen er, at det har abstraheret udtrykket væk fra den konkrete syntaks. Vi ser ikke flere af parenteserne () i dette træ, fordi de ikke er nødvendige. På samme måde ser vi ikke ikke-terminaler som Exp, da vi allerede har regnet ud, hvad “udtrykket” er, og vi er i stand til at trække den værdi ud, der virkelig betyder noget for os – f.eks. tallet 5.
Dette er netop det, der adskiller et AST fra et CST. Vi ved, at et abstrakt syntaksetræ ignorerer en betydelig mængde af den syntaktiske information, som et parse tree indeholder, og springer “ekstra indhold” over, som bruges ved parsing. Men nu kan vi se præcis, hvordan det sker!

Nu da vi har kondenseret vores eget parsetræ, bliver vi meget bedre til at opfange nogle af de mønstre, der adskiller en AST fra en CST.
Der er nogle få måder, hvorpå et abstrakt syntaksetræ vil adskille sig visuelt fra et parse tree:
- En AST vil aldrig indeholde syntaktiske detaljer, såsom kommaer, parenteser og semikolon (afhængigt af sproget, naturligvis).
- En AST vil have en sammenklappet version af det, der ellers ville fremstå som enkelt-successor-knuder; den vil aldrig indeholde “kæder” af knuder med et enkelt barn.
- Endeligt vil alle operatørtokens (såsom
+,-,xog/) blive interne (forælder)knuder i træet, snarere end de blade, der ender i et parsetræ.
Visuelt vil en AST altid fremstå mere kompakt end et parsetræ, da den pr. definition er en komprimeret version af et parsetræ, med færre syntaktiske detaljer.
Det ville derfor være logisk, at hvis en AST er en komprimeret version af et parsetræ, kan vi kun virkelig skabe et abstrakt syntaksetræ, hvis vi har tingene til at bygge et parsetræ til at begynde med!
Det er faktisk sådan, at det abstrakte syntaksetræ passer ind i den større kompileringsproces. Et AST har en direkte forbindelse til de parse-træer, som vi allerede har lært om, samtidig med at det er afhængig af, at lexeren gør sit arbejde, før et AST overhovedet kan oprettes.

Det abstrakte syntaksetræ oprettes som det endelige resultat af syntaksanalysefasen. Parseren, der står forrest som den vigtigste “karakter” under syntaksanalysen, genererer måske eller måske ikke altid et parse tree, eller CST. Afhængigt af selve compileren, og hvordan den er designet, kan parseren gå direkte videre til at konstruere et syntaksetræ, eller AST. Men parseren vil altid generere en AST som sit output, uanset om den skaber et parse tree i mellemtiden, eller hvor mange gennemløb den måtte være nødt til at tage for at gøre det.
Anatomi af en AST
Nu da vi ved, at det abstrakte syntaksetræ er vigtigt (men ikke nødvendigvis skræmmende!), kan vi begynde at dissekere det en lille smule mere. Et interessant aspekt ved, hvordan AST’en er opbygget, har at gøre med knuderne i dette træ.
Billedet nedenfor illustrerer anatomien af en enkelt knude i et abstrakt syntaksetræ.
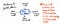
Vi vil bemærke, at denne node ligner andre, som vi har set før, idet den indeholder nogle data (en token og dens value). Den indeholder dog også nogle meget specifikke pointere. Hver knude i en AST indeholder henvisninger til dens næste søskendeknude samt dens første barnknude.
For eksempel kunne vores simple udtryk 5 + (1 x 12) konstrueres til en visualiseret illustration af en AST, som den nedenfor.

Vi kan forestille os, at læsning, traversering eller “fortolkning” af denne AST kan starte fra de nederste niveauer i træet og arbejde sig tilbage opad for at opbygge en værdi eller et return result til sidst.
Det kan også være en hjælp at se en kodet version af output fra en parser for at supplere vores visualiseringer. Vi kan læne os op ad forskellige værktøjer og bruge allerede eksisterende parsere for at se et hurtigt eksempel på, hvordan vores udtryk kan se ud, når det køres gennem en parser. Nedenfor er et eksempel på vores kildetekst, 5 + (1 * 12), kørt gennem Esprima, en ECMAScript-parser, og det resulterende abstrakte syntaksetræ, efterfulgt af en liste over dets forskellige tokens.
I dette format kan vi se indlejringen i træet, hvis vi ser på de indlejrede objekter. Vi vil bemærke, at værdierne, der indeholder 1 og 12, er henholdsvis left og right børn af en overordnet operation, *. Vi vil også se, at multiplikationsoperationen (*) udgør den højre undertræ til hele selve udtrykket, hvilket er grunden til, at den er indlejret i det større BinaryExpression-objekt under nøglen "right". På samme måde er værdien af 5 det enkelte "left" barn af det større BinaryExpression objekt.

Det mest fascinerende aspekt ved abstrakte syntaksetræer er dog det faktum, at selvom de er så kompakte og rene, er de ikke altid en nem datastruktur at forsøge at konstruere. Faktisk kan det være ret kompliceret at opbygge et AST, afhængigt af det sprog, som parseren har med at gøre!
De fleste parsere vil normalt enten konstruere et parse tree (CST) og derefter konvertere det til et AST-format, fordi det nogle gange kan være nemmere – selv om det betyder flere trin og generelt flere gennemgange af kildeteksten. Det er faktisk ret nemt at opbygge et CST, når først parseren kender grammatikken for det sprog, som den forsøger at parse. Den behøver ikke at gøre noget kompliceret arbejde for at finde ud af, om et token er “signifikant” eller ej. I stedet tager den bare præcis det, den ser, i den specifikke rækkefølge, den ser det, og spytter det hele ud i et træ.
På den anden side er der nogle parsere, der vil forsøge at gøre alt dette som en proces i et enkelt trin og hoppe direkte til at konstruere et abstrakt syntaksetræ.
Det kan være vanskeligt at opbygge et AST direkte, da parseren ikke blot skal finde tokens og repræsentere dem korrekt, men også beslutte, hvilke tokens der er vigtige for os, og hvilke der ikke er det.
I compiler-designet ender AST’et med at være supervigtigt af mere end én grund. Ja, den kan være vanskelig at konstruere (og sandsynligvis let at ødelægge), men den er også det sidste og endelige resultat af de lexikalske og syntaksmæssige analysefaser tilsammen! Den leksikalske og syntaksanalysen fase kaldes ofte i fællesskab for analysefasen, eller compilerens front-end.

Vi kan tænke på det abstrakte syntaks træ som det “endelige projekt” i compilerens front-end. Det er den vigtigste del, fordi det er den sidste ting, som frontend’en skal vise sig selv. Den tekniske betegnelse for dette kaldes den mellemliggende koderepræsentation eller IR, fordi det bliver den datastruktur, der i sidste ende bruges af compileren til at repræsentere en kildetekst.
Et abstrakt syntaksetræ er den mest almindelige form for IR, men også, nogle gange den mest misforståede. Men nu, hvor vi forstår den lidt bedre, kan vi begynde at ændre vores opfattelse af denne skræmmende struktur! Forhåbentlig er den nu lidt mindre skræmmende for os.
Ressourcer
Der findes en hel masse ressourcer derude om AST’er, i en lang række sprog. Det kan være svært at vide, hvor man skal starte, især hvis man ønsker at lære mere. Nedenfor er der et par begyndervenlige ressourcer, der dykker ned i en hel del flere detaljer uden at være alt for overvældende. Happy asbtracting!
- The AST vs the Parse Tree, Professor Charles N. Fischer
- Hvad er forskellen mellem parse trees og abstract syntax trees?, StackOverflow
- Abstract vs. Concrete Syntax Trees, Eli Bendersky
- Abstract Syntax Trees, Professor Stephen A. Edwards
- Abstract Syntax Trees & Top-Down Parsing, Professor Konstantinos (Kostis) Sagonas
- Lexical and Syntax Analysis of Programming Languages, Chris Northwood
- AST Explorer, Felix Kling