GPI-forankrede proteiner er den mærkelige mand ude. I introduktionsundervisningen i cellebiologi lærte de os, at der var fem typer membranproteiner, der hedder som følger: Type I, Type II, Type III, Type IV og GPI-forankrede. Hvorfor har vi denne mærkelige klasse af proteiner, der er fæstnet til en sukker- og fedtkæde? Hvad kan de gøre? Kan vi få indsigt i mit protein af interesse – PrP – ved at lære mere om denne klasse af proteiner, som det er medlem af?
Sonia og jeg og vores holdkammerat Andrew og har læst en del om dette emne, og jeg skriver dette blogindlæg for at dele noget af det, vi har lært.
læsning
Vi startede med at læse et par anmeldelser . Disse dækkede for det meste selve GPI-ankerets struktur og biogenese, som man ved utroligt meget om.
Dette anker, hvis fulde navn er glycosylphosphatidylinositol, er ikke en monolit: det er en generel beskrivelse af et molekyle, hvis detaljer kan variere. Generelt har man fra ω-resten (den sidste posttranslationelt tilstedeværende) i proteinet ethanolamin, dernæst et fosfat, dernæst nogle sukkerarter og dernæst et fosfolipid. Den centrale sukkerrygsøjle er bevaret, men de sidekæder, der forgrener sig fra den, kan variere, og både fosholipidhovedgruppen og fedtsyrerne kan også variere. PrP’s GPI-anker blev karakteriseret i , men selv da er det ikke en monolit – man identificerede mindst seks forskellige strukturer, der adskiller sig i sukker-sidekædesammensætningen.
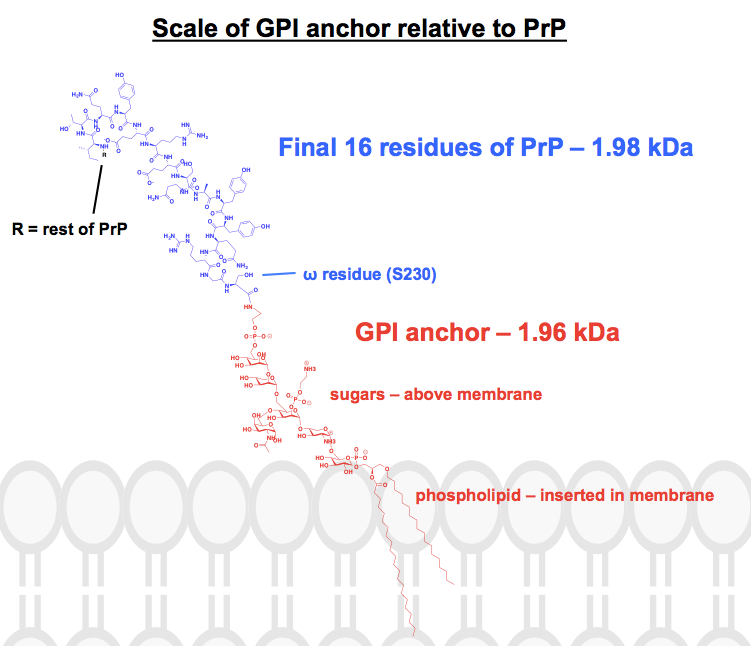
Alle kemiske strukturer, jeg har fundet af GPI-ankre, har i det mindste nogle dele forkortet eller opsummeret, og proteinet er som regel bare vist som et billede. Jeg ønskede at få en fornemmelse af, hvordan disse ankre rent faktisk ser ud kemisk set, i forbindelse med de tilknyttede proteiner, så jeg satte mig for at tegne en komplet struktur i ChemDraw. Med udgangspunkt i figur 1 af – det tætteste, jeg kunne finde på en komplet skeletstruktur – tilføjede jeg detaljerne i en af PrP’s GPI-ankre fra det øverste panel i figur 6. Molekylvægten blev 1.958 Da, så for kontekstens skyld tegnede jeg de sidste 16 rester af HuPrP23-230 ind, som vejer tilsvarende 1.979 Da. Dette svarer til ca. 8 % af PrP’s posttranslationelt modificerede sekvens. Jeg er ikke sikker på, at jeg fik alle bindinger rigtigt, men her er, hvad jeg kom frem til:
I mange tilfælde har et gen flere isoformer, hvor ét splejsningsprodukt giver anledning til et GPI-forankret protein, mens andre giver anledning til sekreterede eller transmembranformer. Eksempler herpå er NCAM1, som har tre større isoformer, hvoraf den ene er GPI-forankret og de to andre er transmembraner , og ACHE (der koder for acetylcholinesterase), hvis GPI-forankrede form tilsyneladende kun findes på røde blodlegemer (NCBI Genes). Den mest fascinerende historie her er den om musegenet Ly6a, som takket være en genetisk polymorfisme er GPI-forankret i nogle musestammer og ikke i andre. Kun i sin GPI-forankrede form fungerer det som receptor for den virale vektor AAV PHP.eB . (Denne vektor opnår en utrolig effektiv optagelse i hjernens neuroner til genterapi , men desværre er det kun et muse-gen – vi mennesker har ikke engang Ly6a).
Der vides meget om, hvordan GPI-ankre bliver syntetiseret og knyttet til proteiner , med >20 proteiner involveret i vejen, hvoraf de fleste begynder med præfikset “PIG” og er kodet af gener som PIGA, PIGK og så videre – se figur 2 for et diagram. Det meste af biosyntesen foregår med ankeret indsat i membranen i ER’et, men uden at være knyttet til noget protein. Faktisk foregår de første par trin på membranens cytosoliske blad, og først senere vender ankeret over på lumenalsiden (inde i ER). Det sidste trin er, når GPI-transamidase, et kompleks bestående af mindst fem proteiner, kløver GPI-signalet af proteinets C-terminus og fastgør GPI-ankeret til den såkaldte ω-rest i proteinet (den sidste rest i den posttranslationelt modificerede sekvens). Derefter sker der en yderligere modning af GPI-ankeret, efterhånden som proteinet vandrer ud af ER mod celleoverfladen.
Der findes en række små molekylære inhibitorer af GPI-biosyntesen i svampe, hvoraf nogle har man forsøgt at udvikle som svampemidler , men så vidt jeg kunne se, er den eneste kendte inhibitor af GPI-biosyntesen i pattedyrceller mannosamin, en mannoseanalog, der er kemisk uforenelig med inkorporering i GPI .
Jeg ledte og ledte efter et sekvenslogo for hvilket aminosyresekvensmotiv GPI-transamidase genkender, men fandt ingen. Tilsyneladende er sekvensmotivet ret løst , og tilsyneladende er GPI-signalerne ikke engang homologe , hvilket betyder, at de ikke udviklede sig fra en fælles forfædresekvens, men snarere udviklede sig konvergent, i det omfang der overhovedet er nogen konvergens. Den bedste beskrivelse jeg har kunnet finde er at (hvis man læser N-til-C-terminalt op til enden af proteinet) har man brug for 1) ca. 11 rester af en ustruktureret linker, 2) et par rester med små sidekæder, herunder en ω rest som kan være enten S, N, D, G, A eller C, 3) en spacer på 5-10 polære aminosyrer, og endelig 4) 15-20 hydrofobiske aminosyrer . PrP følger løst dette motiv. Ifølge de offentliggjorte strukturer slutter alfa-helix 3 ved rest Q223, hvilket efterlader den “ustrukturerede linker” som blot AYYYQR (noget kortere end de foreskrevne 11 rester). Den “lille sidekæde”-region ville være GS|SM (hvor røret angiver transamidase-skæringsstedet), den polære region ville være VLFSSPP og den hydrofobiske C-terminus som VILLISFLIFLIVG.
Nogle af proteinerne i GPI-biosyntesen og fastgørelsesvejen er meget vigtige, og der er beskrevet en række alvorlige sygdomme og syndromer med GPI-ankermangel, som skyldes bialleliske tab af funktion eller tilsyneladende hypomorfe missense-mutationer i gener som PIGO, PIGV, PIGW, PGAP2 og PGAP3 .
Sonia fandt en glimrende artikel fra et par år siden, hvor man foretog en mutagenesescreening i haploide menneskelige celler for at identificere gener, der er nødvendige for biogenese af to GPI-forankrede proteiner: PrP og CD59 . De brugte gentagen FACS-sortering af celler baseret på PrP og CD59 på celleoverfladen for at identificere celler med dramatisk reducerede overfladeniveauer af disse proteiner og foretog derefter sekventering for at se, hvilke genknockouts der var beriget i disse celler i forhold til den oprindelige population. Som man kunne forvente, dukkede de fleste PIG-gener op for begge proteiner (figur 4), men ikke alle hits overlappede hinanden, hvilket er lidt overraskende, især fordi PrP og CD59 i det mindste på RNA-niveau er to af de proteiner med de mest ensartede ekspressionsprofiler på tværs af væv (se varmekortet nederst i dette indlæg). En række enzymer, der er involveret i GPI-anker-sidekædemodifikation, blev kun fundet for CD59, hvilket tyder på, at CD59, men ikke PrP, har brug for disse komplekse sidekæder for at kunne modnes og nå celleoverfladen. I mellemtiden blev Sec62 og Sec63 kun fundet for PrP – det er proteiner, der på en eller anden måde er involveret i co-translationel translokation til ER, men tilsyneladende er de nødvendige for PrP, men ikke for CD59 eller CD55 eller CD109, to andre kontrolproteiner, som de undersøgte. Dette er et fascinerende nyt kapitel i svaret på mit spørgsmål, “er der noget særligt ved PrP’s ekspression?”, hvor jeg ledte efter noget unikt ved biogenesen af PrP, som potentielt kunne være målbart med et lille molekyle. Selvfølgelig, bare fordi disse proteiner ikke var vigtige for tre andre kontrolproteiner i betyder det ikke, at de ikke er vigtige – en undersøgelse fandt, at Sec62 var nødvendig for sekretion af mange små proteiner , og SEC62-genet er totalt udtømt for loss-of-function-varianter i den menneskelige befolkning, nok til at antyde haploinsufficiens. SEC63 synes mindre begrænset, selv om det blot kan betyde, at det virker recessivt.
Ingen af ovenstående besvarer spørgsmålet om, hvorfor GPI-forankrede proteiner findes. Min gamle cellebiologiundervisning udelod i øvrigt en detalje: Der findes faktisk en sjette klasse af membranproteiner, kaldet tail-ankored (TA)-proteiner , som blot har en hydrofob C-terminus, der stikker ind i membranen, men som ikke stikker ud på den anden side. Hvorfor kunne alle disse GPI-forankrede proteiner ikke bare være TA-proteiner? Hvorfor udviklede cellerne en så kompliceret vej til at syntetisere et sukker-fedt-anker i stedet, og hvorfor udviklede de det så tidligt i spillet – GPI-ankre er til stede overalt i eukaryoter, herunder i mange encellede patogener, der inficerer mennesker.
De fleste af anmeldelserne brugte ikke meget tid på dette spørgsmål, sandsynligvis fordi det er det sværeste at besvare. De GPI-forankrede proteiner selv, i det omfang deres oprindelige funktioner er kendt, har en enorm række funktioner – der er enzymer (såsom AChE), celleadhæsionsmolekyler (såsom NCAM1), proteiner, der regulerer komplement i immunsystemet (CD59), og så videre . Der er tilsyneladende mindst ét GPI-forankret protein, der er involveret i vedligeholdelse af myelin i perifere nerver . Men hvad præcist kan GPI-forankrede proteiner gøre, som andre proteiner ikke kan? En gennemgang nævner et par idéer, der er blevet foreslået. Den ene er, at GPI-forankrede proteiner er gode til forbigående dimerisering . Nogle undersøgelser har udforsket tanken om, at homodimerisering spiller en vis rolle i prionbiologien , selv om relevansen af de anvendte modelsystemer for in vivo-situationen endnu ikke er klar. En anden idé er, at fordi GPI-forankrede proteiner kan afstødes fra celleoverfladen, f.eks. af angiotensin-konverterende enzym (ACE) , kan deres lokalisering reguleres på en eller anden dynamisk måde. Også på dette område ved vi, at PrP kan afgives, tilsyneladende af enzymet ADAM10 , selv om en eventuel rolle i PrP’s oprindelige funktion endnu ikke er klarlagt. En tredje idé, og måske den, som jeg har hørt mest om, er, at GPI-forankrede proteiner selektivt samles i “lipid rafts” . Dette er måske den mest lokkende forklaring, fordi man kan forestille sig alle mulige afledte virkninger, hvor den øgede effektive lokale koncentration af disse proteiner giver mulighed for flere interaktioner osv. Men i en anmeldelse blev det påpeget, at et forbehold er, at lipidflåder stadig er mere en abstrakt idé end en konkret ting – selv om de funktionelt defineres af detergenternes uopløselighed, og de fleste mennesker beskriver dem som værende rige på sfingomyelin og kolesterol, er der ingen universelt accepteret definition af, hvad der er og ikke er en lipidflåde, og de empiriske beviser tyder på, at de kan være meget mindre og mere forbigående, end de fleste mennesker tror.
Med denne læsning i hånden gik jeg i gang med at skaffe en liste over disse proteiner og lave nogle analyser på dem for at se, om jeg kunne få en bedre fornemmelse af, hvordan de er.
analyser
Uniprot har en liste over 173 menneskelige GPI-forankrede proteiner. Disse kortlagt til 140 gen-symboler, som faldt til 135 efter at have kørt dette script for at opdatere til de i øjeblikket HGNC-godkendte protein-kodende gen-symboler. Den endelige liste med 135 gensymboler er her.
Uniprot tilbyder ikke nogen oplysninger om, hvordan deres annotationer blev genereret, selv om der må være en betydelig grad af manuel kuratering. Til sammenligning gravede Andrew også op en række pæne papirer, der brugte PI-PLD eller PI-PLC, to enzymer, der kløver GPI-ankre, til empirisk at isolere GPI-forankrede proteiner fra celler . Ved at kombinere listerne fra disse papirer og mappe dem til de nuværende gensymboler fremkom der 107 gener. Vi har stikprøvevis kontrolleret flere af disse tilfældigt. Blandt dem var velkendte GPI-forankrede proteiner såsom glypican-1 (GPC1) og neural celleadhæsionsmolekyle (NCAM1), som begge er rapporteret at have interaktioner med PrP . Men der var også flere gener til stede, for hvilke der ikke syntes at være nogen GPI-forankring kendt i litteraturen, f.eks. VDAC3, hvoraf nogle måske blot er meget rigelige proteiner eller falske positive af andre årsager. I mellemtiden er der indlysende kilder til falsk negative: gener, der simpelthen ikke blev udtrykt i den undersøgte cellelinje, eller som ikke var rigelige nok til at blive opfanget ved massespekulation, og PrP-paralogerne SPRN og PRND var ikke med på listerne. Samlet set var 51 gener i begge lister, en meget signifikant berigelse (OR = 217, P < 1 × 10-84), hvilket er med til at forsikre mig om, at Uniprots annotationer er i overensstemmelse med empiriske data. Men for yderligere analyser besluttede vi at gå med Uniprot-listen, da den synes mere følsom og specifik.
Armed denne liste ønskede jeg at se, hvordan GPI-forankrede proteiner stablede sig op. PrP er et enkelt exon, kort (208 aminosyrer i sin modne form), ikke-essentielt, bredt eksponeret protein. Er disse træk typiske eller atypiske for et GPI-forankret protein?
Det viser sig, at GPI-forankrede proteiner er over det hele, lige så variable på alle de dimensioner, jeg kiggede på, som alle andre sæt proteiner er.
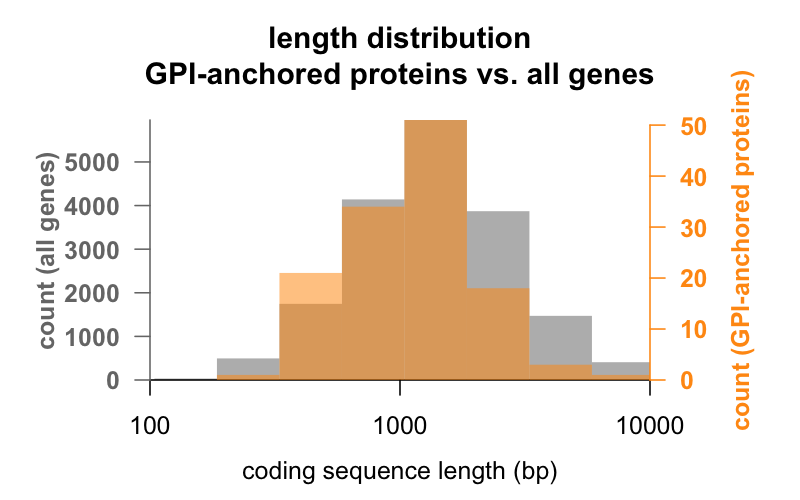
For det første, længden. Nedenfor ses overlejrede histogrammer af den kodningssekvenslængde i basepar for alle gener i forhold til gener, der koder for GPI-ankrede proteiner. Fordelingen af GPI-forankrede proteiner er kun lige akkurat forskudt til venstre. Det gennemsnitlige GPI-forankrede proteingen har en kodningssekvens på 1.301 bp, mens det gennemsnitlige gen har 1.729, men denne forskel i gennemsnit er lille i forhold til variationen inden for hver gruppe. PrP er med kun 762 bp kodningssekvens bestemt til den lille side, selv om det på ingen måde er en outlier i nogen af grupperne – CD52 er med kun 186 basepar sekvens og tilsyneladende kun 12 aminosyrer i sin modne form det mindste GPI-forankrede protein.
Hvad med antallet af exons? GPI-forankrede proteiner har i gennemsnit lidt færre exoner sammenlignet med alle gener (gennemsnit 7,8 vs. 10,1), hvilket stemmer overens med den lille forskel i længdefordelingen, der er nævnt ovenfor, men de fleste er multi-exoner. Også her er PrP på den lille side: Der er kun seks GPI-forankrede proteiner, der kun har 1 kodende exon, og tre af dem er PrP og dets to paraloger, Sho og Dpl. (De tre andre gener er GAS1, SPACA4 og det fabelagtigt navngivne OMG).
Næst kiggede jeg på loss-of-function constraint. Constraint er et mål for, hvor stærk naturlig selektion et gen er underlagt, baseret på hvor udtømt det er for f.eks. nonsense-, frameshift- og splejsestedsvariation i den generelle befolkning sammenlignet med forventningen baseret på mutationsrater. Denne måleenhed er ikke særlig fortolkelig for korte gener, både af statistiske grunde (antallet af forventede mutationer er lavt for korte gener, så det er svært at kvantificere udtynding) og af biologiske grunde (enkelt exon-gener er ikke udsat for nonsense-medieret henfald, så det er sværere at vide, om proteinafkortningsvarianter virkelig er “loss-of-function” eller ej). Men da de fleste GPI-forankrede proteiner ikke er så korte som PrP, syntes jeg, at det var værd at tage et kig på. Resultatet: GPI-forankrede proteiner er i gennemsnit bare en smule mindre begrænsede, hvilket betyder, at de har mere af deres forventede mængde tab af funktionsvariation end det gennemsnitlige gen. Det gennemsnitlige gen har 47 % af sin tab af funktionsvariation, mens GPI-forankrede proteiner har 56 %. Men som med alt andet her er der en stor spredning i begge lejre. For GPI-forankrede proteiner har man i den ene ende den absolut begrænsede ACHE (17 LoF’er forventet og ingen observeret) og i den anden ende adskillige gener, der tilsyneladende slet ikke er underlagt nogen selektion mod tab af funktion – CNTN6, CD109, TREH og MSLN er et par eksempler. PRNP falder i sidstnævnte lejr, når man udelukker rester ≥145, hvor protein-truncating varianter forårsager en gevinst af funktion .
Sidst undrede jeg mig over, hvor GPI-forankrede proteiner kommer til udtryk. PRNP er højest i hjernen, men udtrykkes overalt. Er det typisk? Jeg downloadede den fulde GTEx v7 “gene median tpm” oversigtsfil (Jan 15, 2016), hvor hver række er et gen og hver kolonne er et væv, og cellerne er RPKM’er – RNA-seq læsninger pr. kilobase af exon pr. million kortlagte læsninger. Det krævede en del finpudsning at arbejde med dette datasæt. Jeg har hørt, at nogle bioinformatikere anser <1 RPKM for at være “ikke udtrykt”, men udtryksmatricen er sparsom – de fleste gener er ikke stærkt udtrykt i de fleste væv – så støjen under 1 RPKM kan dominere, hvis du bare plotter de rå RPKM’er. I mellemtiden er genekspression noget, som man skal tænke på en logisk skala, da generne i et væv kan variere fra <1 RPKM til >10.000 RPKM, så hvis man betragter alt på en lineær skala, kan de få virkelig højt udtrykte gen/væv-kombinationer også dominere, hvilket får matrixen til at se endnu mere sparsom ud, end den er. Jeg tog derfor log10 af matricen og afkortede fordelingen ved , således at den lilla skala, jeg brugte, løber 1 – 10 – 100 – 1.000 – 10.000 RPKM. Derefter subsettede jeg til de Uniprot GPI-forankrede proteiner. For at visualisere dette lavede jeg for første gang i mit liv et heatmap. Jeg har ofte set disse i papirer, og de taler normalt ikke til mig, men her var mit mål bare at få en fornemmelse af udtryksmønstret, og efter at have leget lidt rundt, var dette det, der gav mig den største indsigt. Princippet i et heatmap er, at rækkerne og kolonnerne er grupperet, så lignende ting går sammen. Således er f.eks. alle kolonnerne med hjernevæv opstillet efter hinanden i et felt på x-aksen, og alle de meget hjerneudtrykte gener er opstillet efter hinanden i et felt på y-aksen, således at deres skæringspunkt danner et tæt lilla rektangel, der kan fortolkes som: “der findes en klynge af gener, der hovedsagelig er hjerneudtrykt”.
Interesserede læsere kan se den fulde PDF-fil med vektorkunst af varmekortet, men for at gøre det mere umiddelbart tilgængeligt er her en håndnoteret version, der kalder de interessante klynger frem:

Svaret er altså nej – de fleste GPI-forankrede proteiner har ikke det samme ekspressionsmønster som PRNP. PRNP er en af den håndfuld af de mere højt og bredt eksprimerede og optræder nær toppen af dette varmekort sammen med CD59, LY6E, GPC1 og BST2. De fleste GPI-forankrede proteiner har en lavere eller mere vævsbegrænset ekspression, med nogle næsten udelukkende udtrykt i hjernen og andre næsten udelukkende ikke udtrykt i hjernen, og andre mindre klynger, der hovedsagelig tilhører specifikke væv som f.eks. testiklerne, såsom PrP’s paralog PRND, hvis knockout forårsager mandlig sterilitet .
konklusioner
GPI-forankrede proteiner kan have stort set alle størrelser, udtrykkes i stort set alle væv og tilsyneladende have stort set alle funktioner, i det omfang deres funktioner er kendt. Mange GPI-forankrede proteiner har meget klare native funktioner, men disse funktioner er forskellige, og det er ikke klart, hvorfor de kræver GPI-forankring, især fordi mange af disse proteiner også findes i ikke-GPI-forankrede isoformer. I mellemtiden ved vi for andre GPI-forankrede proteiner, herunder PrP, kun lidt nok om den native funktion til at begynde med, så det er svært at spekulere i, hvorfor den native funktion kræver GPI-forankring. Ingen af de analyser, jeg foretog, eller de anmeldelser, jeg læste, var i stand til at opstille et forenende princip om, hvorfor denne forankringsmekanisme eksisterer, eller hvad der gør, at disse proteiner kræver den. Der er en række hypoteser om, hvorfor GPI-forankrede proteiner er unikke, herunder lipid rafts, homodimere og shedding. Alle disse hypoteser kan have en vis holdbarhed. Men i sidste ende virker det usandsynligt, at svaret er et eureka-øjeblik, men snarere, som så meget andet i biologien, en prosaisk blanding af forskellige ting.
R-kode og rå datafiler til analyserne i dette indlæg er her.