Datakryptering i hvile er et must for enhver moderne internetvirksomhed. Mange virksomheder krypterer dog ikke deres diske, fordi de frygter den potentielle ydelsesforringelse som følge af krypteringsoverhead.
Kryptering af data i hvile er afgørende for Cloudflare med mere end 200 datacentre i hele verden. I dette indlæg vil vi undersøge ydelsen af disk-kryptering på Linux og forklare, hvordan vi har gjort det mindst to gange hurtigere for os selv og vores kunder!
Kryptering af data i hvile
Når det kommer til kryptering af data i hvile, er der flere måder, hvorpå det kan implementeres på et moderne operativsystem (OS). De tilgængelige teknikker er tæt koblet til en typisk OS-lagringsstack. En forenklet version af lagringsstacken og krypteringsløsninger kan ses på nedenstående diagram:
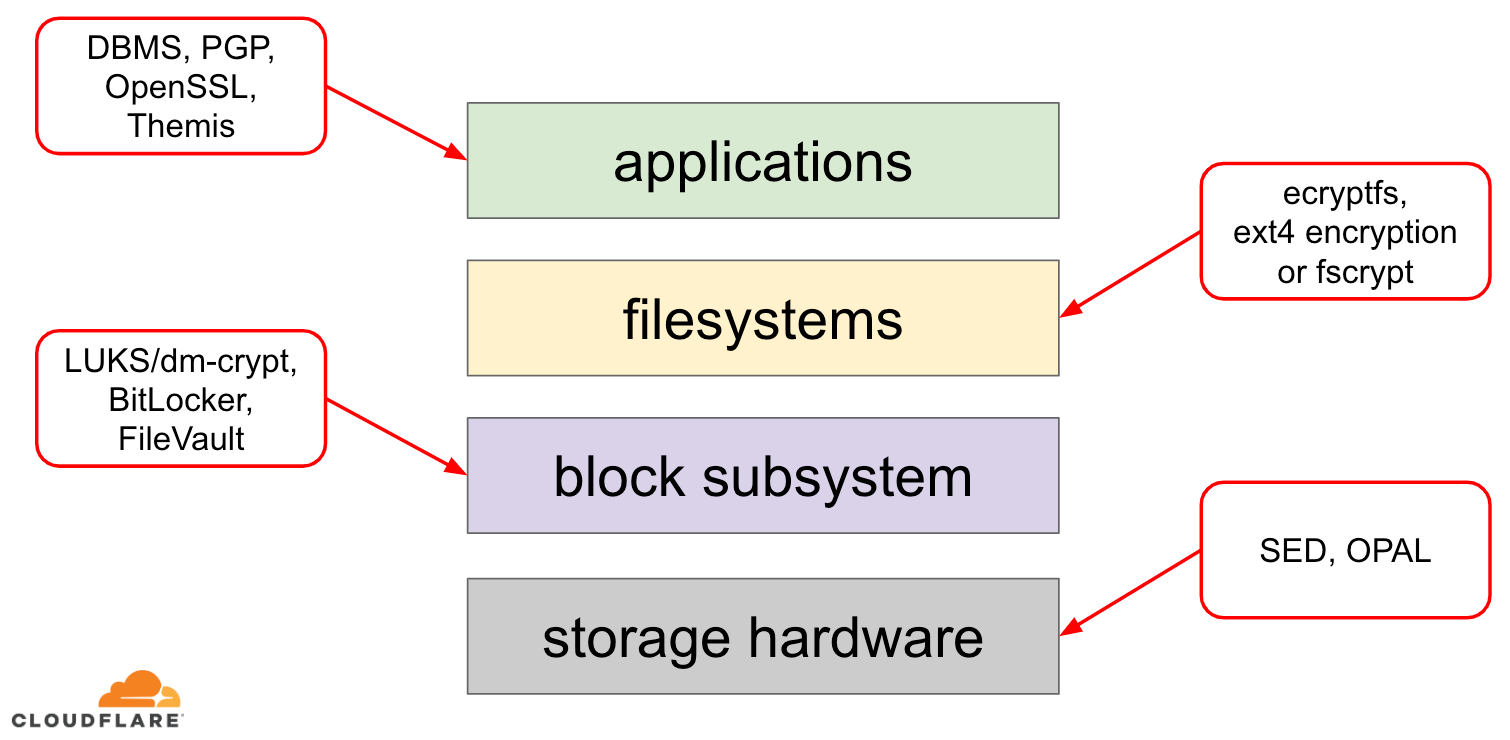
Overst i stakken findes programmer, som læser og skriver data i filer (eller streams). Filsystemet i operativsystemets kerne holder styr på, hvilke blokke på den underliggende blokanordning der hører til hvilke filer, og oversætter disse fillæsninger og -skrivninger til bloklæsninger og -skrivninger, men hardwarespecifikationerne for den underliggende lagerenhed er abstraheret væk fra filsystemet. Endelig videregiver blokundersystemet faktisk bloklæsninger og -skrivninger til den underliggende hardware ved hjælp af passende enhedsdrivere.
Begrebet lagringsstakken svarer faktisk til den velkendte OSI-model for netværk, hvor hvert lag har en mere overordnet opfattelse af oplysningerne, og gennemførelsesdetaljerne for de lavere lag er abstraheret fra de øverste lag. Og i lighed med OSI-modellen kan man anvende kryptering på forskellige lag (tænk på TLS vs. IPsec eller en VPN).
For data i hvile kan vi anvende kryptering enten på bloklagene (enten i hardware eller i software) eller på filniveau (enten direkte i programmer eller i filsystemet).
Blok- vs. filkryptering
Generelt set gælder det, at jo højere i stakken vi anvender kryptering, jo mere fleksibilitet har vi. Med kryptering på applikationsniveau kan applikationsvedligeholderne anvende en hvilken som helst krypteringskode, de ønsker, på de særlige data, de har brug for. Ulempen ved denne fremgangsmåde er, at de faktisk selv skal implementere den, og kryptering er generelt ikke særlig udviklervenlig: man skal kende en specifik kryptografisk algoritme til bunds, generere nøgler, nonces, IV’er osv. Desuden udnytter kryptering på applikationsniveau ikke caching på OS-niveau og især ikke Linux-sidecache: hver gang applikationen skal bruge dataene, skal den enten dekryptere dem igen, hvilket spilder CPU-cyklusser, eller implementere sin egen dekrypterede “cache”, hvilket øger kompleksiteten i koden.
Kryptering på filsystemniveau gør datakryptering gennemsigtig for applikationer, fordi filsystemet selv krypterer dataene, før det sender dem videre til blokundersystemet, så filer krypteres, uanset om applikationen har krypto-understøttelse eller ej. Desuden kan filsystemer konfigureres til kun at kryptere en bestemt mappe eller til at have forskellige nøgler til forskellige filer. Denne fleksibilitet har dog den pris, at konfigurationen er mere kompleks. Kryptering af filsystemer anses også for at være mindre sikker end blok-enhedskryptering, da kun indholdet af filerne er krypteret. Filer har også tilknyttede metadata, som f.eks. filstørrelse, antal filer, mappetræets layout osv., som stadig er synlige for en potentiel modstander.
Kryptering nede i bloklaget (ofte benævnt disk-kryptering eller fuld disk-kryptering) gør også datakryptering gennemsigtig for programmer og endda hele filsystemer. I modsætning til kryptering på filsystemniveau krypterer den alle data på disken, herunder filmetadata og selv ledig plads. Den er dog mindre fleksibel – man kan kun kryptere hele disken med en enkelt nøgle, så der er ingen konfiguration pr. mappe, pr. fil eller pr. bruger. Fra kryptoperspektivet kan ikke alle kryptografiske algoritmer anvendes, da bloklaget ikke længere har et overblik på højt niveau over dataene, så det er nødt til at behandle hver enkelt blok uafhængigt af hinanden. De fleste almindelige algoritmer kræver en eller anden form for block chaining for at være sikre, så de kan ikke anvendes til disk-kryptering. I stedet blev der udviklet særlige tilstande kun til dette specifikke anvendelsestilfælde.
Så hvilket lag skal man vælge? Som altid afhænger det af … Kryptering på applikations- og filsystemniveau er normalt det foretrukne valg for klientsystemer på grund af fleksibiliteten. F.eks. kan hver bruger på et skrivebord med flere brugere ønske at kryptere deres hjemmemappe med en nøgle, som de ejer, og lade nogle delte mapper forblive ukrypterede. På serversystemer, der forvaltes af SaaS/PaaS/IaaS-virksomheder (herunder Cloudflare), er det foretrukne valg derimod enkelhed og sikkerhed i konfigurationen – med fuld disk-kryptering aktiveret krypteres alle data fra alle programmer automatisk uden undtagelser eller tilsidesættelser. Vi mener, at alle data skal beskyttes uden at sortere dem i “vigtige” vs. “ikke vigtige” spande, så den selektive fleksibilitet, som de øverste lag giver, er ikke nødvendig.
Hardware vs. software disk kryptering
Når man krypterer data i bloklaget, er det muligt at gøre det direkte i lagerhardwaren, hvis hardwaren understøtter det. Hvis man gør det, giver det normalt en bedre læse-/skriveydelse og bruger færre ressourcer fra værten. Da det meste hardware-firmware imidlertid er proprietær, får det ikke så meget opmærksomhed og gennemgang fra sikkerhedssamfundet. Tidligere har dette ført til fejl i nogle implementeringer af hardwaredisk-kryptering, som har gjort hele sikkerhedsmodellen ubrugelig. Microsoft er f.eks. siden da begyndt at foretrække softwarebaseret disk-kryptering.
Vi ønskede ikke at udsætte vores data og vores kunders data for risikoen ved at bruge potentielt usikre løsninger, og vi tror stærkt på open source. Derfor er vi kun afhængige af softwaredisk kryptering i Linux-kernen, som er åben og er blevet revideret af mange sikkerhedseksperter over hele verden.
Linux disk krypteringspræstation
Vi har ikke kun til formål at spare båndbreddeomkostninger for vores kunder, men også at levere indhold til internetbrugere så hurtigt som muligt.
På et tidspunkt bemærkede vi, at vores diske ikke var så hurtige, som vi gerne ville have dem til at være. Nogle profileringer samt en hurtig A/B-test pegede på Linux-disk-kryptering. Da det ikke er en holdbar løsning ikke at kryptere data (selv om det skal være en offentlig internetcache), besluttede vi at se nærmere på Linux disk-krypteringsydelse.
Device mapper og dm-crypt
Linux implementerer gennemsigtig disk-kryptering via et dm-crypt-modul, og dm-crypt selv er en del af device mapper kernel framework. Kort fortalt gør device mapper det muligt at for-/efterbehandle IO-forespørgsler, mens de bevæger sig mellem filsystemet og den underliggende blokanordning.
dm-crypt krypterer især “skrive”-IO-forespørgsler, før de sendes længere ned i stakken til den faktiske blokanordning, og dekrypterer “læse”-IO-forespørgsler, før de sendes op til filsystemdriveren. Enkelt og let! Eller er det?
Benchmarking opsætning
For the record, tallene i dette indlæg blev opnået ved at køre specificerede kommandoer på en inaktiv Cloudflare G9-server uden for produktion. Opsætningen bør dog nemt kunne reproduceres på enhver moderne x86-bærbar computer.
Generelt set er det svært at benchmarke noget omkring en storage stack på grund af den støj, der indføres af selve storage hardwaren. Ikke alle diske er lige gode, så i dette indlæg vil vi bruge de hurtigste diske, der er tilgængelige derude – det vil sige ingen diske.
I stedet har Linux en mulighed for at emulere en disk direkte i RAM. Da RAM er meget hurtigere end noget vedvarende lager, bør det indføre lidt skævhed i vores resultater.
Følgende kommando opretter en 4 GB ramdisk:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Nu kan vi oprette en dm-crypt-instans oven på den og dermed aktivere kryptering for disken. Først skal vi generere diskens krypteringsnøgle, “formatere” disken og angive en adgangskode for at låse den nyligt genererede nøgle op.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:De, der er bekendt med LUKS/dm-crypt, har måske bemærket, at vi har brugt en LUKS-detacheret header her. Normalt gemmer LUKS den password-krypterede disk-krypteringsnøgle på den samme disk som dataene, men da vi ønsker at sammenligne læse/skrive-ydelsen mellem krypterede og ukrypterede enheder, kan vi ved et uheld overskrive den krypterede nøgle under vores benchmarking senere. Ved at opbevare den krypterede nøgle i en separat fil undgår vi dette problem i forbindelse med dette indlæg.
Nu kan vi faktisk “låse” den krypterede enhed op til vores testning:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0På dette tidspunkt kan vi nu sammenligne ydelsen for krypteret vs. ukrypteret ramdisk: Hvis vi læser/skriver data til /dev/ram0, vil de blive gemt i klartekst. På samme måde, hvis vi læser/skriver data til /dev/mapper/encrypted-ram0, vil de blive dekrypteret/krypteret undervejs af dm-crypt og gemt i ciphertext.
Det er værd at bemærke, at vi ikke opretter noget filsystem oven på vores blok-enheder for at undgå at forvrænge resultaterne med et filsystem-overhead.
Måling af gennemløb
Når det kommer til lagringstest/benchmarking, er Flexible I/O tester den sædvanlige go-to løsning. Lad os simulere simpel sekventiel læsning/skrivning belastning med 4K blokstørrelse på ramdisketten uden kryptering:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Overstående kommando vil køre i lang tid, så vi stopper den bare efter et stykke tid. Som vi kan se af statistikken, er vi i stand til at læse og skrive nogenlunde med samme gennemløb omkring 1126 MB/s. Lad os gentage testen med den krypterede ramdisk:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, det er et fald! Vi får kun ~147 MB/s nu, hvilket er mere end 7 gange langsommere! Og det er på en helt tomgangsmaskine!
Måske er krypto bare langsom
Den første ting vi overvejede er at sikre, at vi bruger den hurtigste krypto. cryptsetup giver os mulighed for at benchmarke alle de tilgængelige krypto-implementeringer på systemet for at vælge den bedste:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/ADet ser ud til, at aes-xts med en 256-bit datakrypteringsnøgle er den hurtigste her. Men hvilken bruger vi egentlig til vores krypterede ramdisk?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Vi bruger faktisk aes-xts med en 256-bit datakrypteringsnøgle (tæl alle nuller bekvemt maskeret af dmsetup-værktøjet – hvis du vil se de faktiske bytes, skal du tilføje --showkeys-indstillingen til ovenstående kommando). Tallene summer dog ikke op: cryptsetup benchmark fortæller os ovenfor, at vi ikke skal stole på resultaterne, da “Tests are approximate using memory only (no storage IO)”, men det er præcis sådan, vi har sat vores eksperiment op ved hjælp af ramdisketten. I et noget værre tilfælde (hvis vi antager, at vi læser alle data og derefter krypterer/afkrypterer dem sekventielt uden parallelitet) ved at lave back-of-the-envelope-beregning burde vi få omkring (1126 * 1823) / (1126 + 1823) =~696 MB/s, hvilket stadig er ret langt fra det faktiske 147 * 2 = 294 MB/s (i alt for læsninger og skrivninger).
dm-crypt performance flags
Ved læsning af cryptsetup man-siden bemærkede vi, at den har to indstillinger med præfikset --perf-, som sandsynligvis er relateret til performance tuning. Den første er --perf-same_cpu_crypt med en ret kryptisk beskrivelse:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Så vi aktiverer indstillingen
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Bemærk: ifølge den seneste man-side er der også en cryptsetup refresh-kommando, som kan bruges til at aktivere disse indstillinger live uden at skulle “lukke” og “genåbne” den krypterede enhed. Vores cryptsetup understøttede det dog ikke endnu.
Kontroller om indstillingen virkelig er blevet aktiveret:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptJa, vi kan nu se same_cpu_crypt i output, hvilket er det vi ønskede. Lad os køre benchmarken igen:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, nu er den ~136 MB/s, hvilket er lidt værre end før, så det er ikke godt. Hvad med den anden mulighed --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Måske er vi i “en eller anden situation” her, så lad os prøve det:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusOg nu benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, hvilket er en smule bedre, men stadig ikke godt …
Spørg fællesskabet
Vi var desperate og besluttede at søge støtte på internettet og sendte vores resultater til dm-crypt-mailinglisten, men svaret vi fik var ikke særlig opmuntrende:
Hvis tallene forstyrrer dig, så skyldes det manglende forståelse fra din side. Du er sandsynligvis ikke klar over, at kryptering er en tung operation…
Vi besluttede at lave en videnskabelig undersøgelse af dette emne ved at skrive “is encryption expensive” i Google Search, og et af de øverste resultater, som faktisk indeholder meningsfulde målinger, er… vores eget indlæg om omkostninger ved kryptering, men i forbindelse med TLS! Det er fascinerende læsning i sig selv, men essensen er: moderne krypto på moderne hardware er meget billig, selv på Cloudflare-skala (der laver millioner af krypterede HTTP-forespørgsler pr. sekund). Faktisk er det så billigt, at Cloudflare var den første udbyder, der tilbød gratis SSL/TLS til alle.
Digging into the source code
Når vi forsøgte at bruge de brugerdefinerede dm-crypt-optioner beskrevet ovenfor, var vi nysgerrige på, hvorfor de overhovedet eksisterer, og hvad denne “offloading” går ud på. Oprindeligt forventede vi, at dm-crypt skulle være en simpel “proxy”, som blot krypterer/afkrypterer data, mens de strømmer gennem stakken. Det viser sig, at dm-crypt gør mere end blot at kryptere hukommelsesbuffere, og et (forenklet) IO-traverse path-diagram er præsenteret nedenfor:

Når filsystemet udsender en skriveanmodning, behandler dm-crypt den ikke med det samme – i stedet lægger den den i en workqueue ved navn “kcryptd”. Kort fortalt planlægger en kernel workqueue blot noget arbejde (kryptering i dette tilfælde) til at blive udført på et senere tidspunkt, når det er mere bekvemt. Når “tiden” er inde, sender dm-crypt anmodningen til Linux Crypto API for den faktiske kryptering. Moderne Linux Crypto API er dog også asynkront, så afhængigt af hvilken særlig implementering dit system vil bruge, vil den højst sandsynligt ikke blive behandlet med det samme, men sættes i kø igen til “senere tidspunkt”. Når Linux Crypto API endelig vil foretage krypteringen, kan dm-crypt forsøge at sortere verserende skriveanmodninger ved at placere hver enkelt anmodning i et rød-sort træ. Derefter tager en separat kernetråd igen på “et senere tidspunkt” faktisk alle IO-anmodninger i træet og sender dem ned i stakken.
Nu til læseanmodninger: Denne gang skal vi først hente de krypterede data fra hardwaren, men dm-crypt spørger ikke bare driveren om dataene, men sætter anmodningen i kø i en anden workqueue ved navn “kcryptd_io”. På et senere tidspunkt, når vi rent faktisk har de krypterede data, planlægger vi dem til dekryptering ved hjælp af den nu velkendte “kcryptd”-workqueue. “kcryptd” sender anmodningen til Linux Crypto API, som også kan dekryptere dataene asynkront.
For at være fair skal det siges, at anmodningen ikke altid gennemløber alle disse køer, men den vigtige del her er, at skriveanmodninger kan sættes i kø op til 4 gange i dm-crypt og læseanmodninger op til 3 gange. På dette tidspunkt spekulerede vi på, om alle disse ekstra køer kan forårsage problemer med ydeevnen. Der er f.eks. en fin præsentation fra Google om forholdet mellem kø og ventetid i halen. En af de vigtigste ting at tage med fra præsentationen er:
En betydelig del af tail latency skyldes køeffekter
Så, hvorfor er alle disse køer der, og kan vi fjerne dem?
Git-arkæologi
Ingen skriver mere kompleks kode bare for sjov, især ikke til OS-kernen. Så alle disse køer må være blevet sat der af en grund. Heldigvis forvaltes Linux-kernens kildekode af git, så vi kan forsøge at spore ændringerne og beslutningerne omkring dem.
Arbejdskøen “kcryptd” har været i kildekoden siden begyndelsen af den tilgængelige historie med følgende kommentar:
Nødvendigt, fordi det ville være meget uklogt at foretage dekryptering i en interrupt-kontekst, så bios, der vender tilbage fra læseanmodninger, bliver sat i kø her.
Så det var kun til læsning, men selv da – hvorfor er vi interesseret i, om det er interruptkontekst eller ej, hvis Linux Crypto API sandsynligvis alligevel vil bruge en dedikeret tråd/kø til kryptering? Tja, tilbage i 2005 var Crypto API ikke asynkront, så det gav perfekt mening.
I 2006 dm-crypt begyndte dm-crypt at bruge “kcryptd” workqueue ikke kun til kryptering, men til at indsende IO-forespørgsler:
Denne patch er designet til at hjælpe dm-crypt med at overholde de nye begrænsninger, der er pålagt af følgende patch i -mm: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Det ser ud til, at målet her ikke var at tilføje mere samtidighed, men snarere at reducere kernens stack-brug, hvilket igen giver mening, da kernen har en fælles stack på tværs af al kode, så det er en ret begrænset ressource. Det er dog værd at bemærke, at Linux-kernens stak er blevet udvidet i 2014 til x86-platforme, så dette er måske ikke længere et problem.
En første version af “kcryptd_io” workqueue blev tilføjet i 2007 med henblik på at undgå:
Sult forårsaget af mange anmodninger, der venter på hukommelsesallokering…
Anmodningsbehandlingen var flaskehals på en enkelt workqueue her, så løsningen var at tilføje endnu en workqueue. Det giver mening.
Vi er bestemt ikke de første, der oplever ydelsesforringelse på grund af omfattende kø: I 2011 blev der indført en ændring for betinget at vende noget af køen for læseanmodninger tilbage:
Hvis der er nok hukommelse, kan koden direkte indsende bio i stedet for at sætte denne operation i kø i en separat tråd.
Dengang var Linux-kernens commit-meddelelser desværre ikke så mundrette som i dag, så der er ingen data om ydeevne til rådighed.
I 2015 begyndte dm-crypt at sortere skrivninger i en separat “dmcrypt_write”-tråd, før de sendes ned i stakken:
På en maskine med flere processorer afsluttes krypteringsanmodninger i en anden rækkefølge end den, de blev indsendt i. Følgelig ville skriveanmodninger blive indsendt i en anden rækkefølge, og det kunne medføre alvorlig ydelsesforringelse.
Det giver mening, da sekventiel diskadgang plejede at være meget hurtigere end den tilfældige, og dm-crypt brød det mønster. Men det gælder mest for spinning diske, som stadig var dominerende i 2015. Det er måske ikke så vigtigt med moderne hurtige SSD’er (herunder NVME SSD’er).
En anden del af commit-meddelelsen er værd at nævne:
…især gør det IO schedulere som CFQ i stand til at sortere mere effektivt…
Det nævner ydelsesfordelene for CFQ IO scheduler, men Linux schedulere er blevet forbedret siden da i en sådan grad, at CFQ scheduler er blevet fjernet fra kernen i 2018.
Det samme patchsæt erstatter sorteringslisten med et rød-sort træ:
I teorien burde sorteringen udføres af den underliggende disk scheduler, men i praksis accepterer og sorterer disk scheduleren kun et endeligt antal anmodninger. For at tillade sortering af alle anmodninger skal dm-crypt implementere sin egen sortering.
Det overhead, der er forbundet med rbtree-baseret sortering, anses for ubetydeligt, så det bruges ikke betinget.
Alt det giver mening, men det ville være rart at have nogle bagvedliggende data.
Interessant nok ser vi i samme patchsæt indførelsen af vores velkendte “submit_from_crypt_cpus”-indstilling:
Der er nogle situationer, hvor aflastning af skrive-bios fra krypteringstrådene til en enkelt tråd forringer ydelsen betydeligt
Overordnet set kan vi se, at alle ændringer var fornuftige og nødvendige, men tingene har dog ændret sig siden da:
- hardware blev hurtigere og smartere
- Linux ressourceallokering blev revideret
- koblede Linux-undersystemer blev rearkitekteret
Og mange af de ovenstående designvalg kan muligvis ikke anvendes på moderne Linux.
Den “oprydning”
Baseret på ovenstående forskning besluttede vi at forsøge at fjerne alle de ekstra køer og den asynkrone adfærd og vende tilbage dm-crypt til dens oprindelige formål: blot kryptere/afkryptere IO-forespørgsler, mens de passerer igennem. Men af hensyn til stabiliteten og yderligere benchmarking endte vi med ikke at fjerne den egentlige kode, men i stedet tilføje endnu en dm-crypt-option, som omgår alle køer/threads, hvis den er aktiveret. Flaget giver os mulighed for at skifte mellem den nuværende og den nye adfærd ved kørselstid under fuld produktionsbelastning, så vi nemt kan vende tilbage til vores ændringer, hvis vi skulle se bivirkninger. Den resulterende patch kan findes på Cloudflare GitHub Linux-repositoriet på Cloudflare.
Synkron Linux Crypto API
Fra diagrammet ovenfor kan vi huske, at ikke al køering er implementeret i dm-crypt. Moderne Linux Crypto API kan også være asynkron, og af hensyn til dette eksperiment ønsker vi også at fjerne køer der. Men hvad betyder “kan være”? OS’et kan indeholde forskellige implementeringer af den samme algoritme (f.eks. hardware-accelererede AES-NI på x86-platforme og generiske C-kode-AES-implementeringer). Som standard vælger systemet den “bedste” baseret på den konfigurerede algoritmeprioritet. dm-crypt gør det muligt at tilsidesætte denne adfærd og anmode om en bestemt cipher-implementering ved hjælp af præfikset capi:. Der er dog et problem. Lad os faktisk kontrollere de tilgængelige AES-XTS-implementeringer (det er vores disk-krypteringscipher, husker du det?) på vores system:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64Vi ønsker eksplicit at vælge en synkron cipher fra ovenstående liste for at undgå køeffekter i tråde, men de eneste to understøttede er xts(ecb(aes-generic)) (den generiske C-implementering) og __xts-aes-aesni (den x86-hardware-accelererede implementering). Vi vil helt klart have sidstnævnte, da den er meget hurtigere (vi sigter efter ydeevne her), men den er mistænkeligt nok markeret som intern (se internal: yes). Hvis vi tjekker kildekoden:
Mærk en cipher som en serviceimplementering, der kun kan bruges af en anden cipher og aldrig af en normal bruger af kernens krypto-API
Så denne cipher er kun beregnet til at blive brugt af anden wrapper-kode i krypto-API’en og ikke uden for den. I praksis betyder det, at den, der kalder Crypto API’et, udtrykkeligt skal angive dette flag, når der anmodes om en bestemt cipherimplementering, men dm-crypt gør det ikke, fordi det efter designet ikke er en del af Linux Crypto API’et, men snarere en “ekstern” bruger. Vi patcher allerede dm-crypt-modulet, så vi kan lige så godt bare tilføje det relevante flag. Der er dog et andet problem med især AES-NI: x86 FPU. “Floating point” siger du? Hvorfor har vi brug for floating point-matematik for at lave symmetrisk kryptering, som kun burde handle om bitforskydninger og XOR-operationer? Vi har ikke brug for matematikken, men AES-NI-instruktionerne bruger nogle af CPU-registrene, som er dedikeret til FPU’en. Desværre bevarer Linux-kernen ikke altid disse registre i interruptkontekst af ydelsesmæssige årsager (det er dyrt at gemme/gendanne FPU’en). Men dm-crypt kan udføre kode i interruptkontekst, så vi risikerer at korrumpere nogle andre procesdata, og vi går tilbage til “det ville være meget uklogt at foretage dekryptering i en interruptkontekst”-erklæring i den oprindelige kode.
Vores løsning til at løse ovenstående var at oprette et andet noget “smart” Crypto API-modul. Dette modul er synkront og ruller ikke sin egen krypto, men er blot en “router” af krypteringsanmodninger:
- Hvis vi kan bruge FPU’en (og dermed AES-NI) i den aktuelle eksekveringskontekst, videresender vi blot krypteringsanmodningen til den hurtigere, “interne”
__xts-aes-aesniimplementering (og vi kan bruge den her, fordi vi nu er en del af Crypto API’et) - I modsat fald videresender vi bare krypteringsanmodningen til den langsommere, generiske, C-baserede
xts(ecb(aes-generic))implementering
Anvendelse af det hele
Lad os gennemgå processen for at bruge det hele sammen. Det første skridt er at hente patchesne og genkompilere kernen (eller blot kompilere dm-crypt og vores xtsproxy-moduler).
Næst skal vi genstarte vores IO-arbejdsbelastning i en separat terminal, så vi kan sikre os, at vi kan omkonfigurere kernen ved kørselstid under belastning:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...I hovedterminalen skal du sikre dig, at vores nye Crypto API-modul er indlæst og tilgængeligt:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Omkonfigurer den krypterede disk til at bruge vores nyligt indlæste modul og aktiver vores patched dm-crypt flag (vi er nødt til at bruge lavt niveau dmsetup værktøj, da cryptsetup tydeligvis ikke er opmærksom på vores ændringer):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Vi har lige “indlæst” den nye konfiguration, men for at den kan træde i kraft, skal vi suspendere/genoptage den krypterede enhed:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0Og observer nu resultatet. Vi kan gå tilbage til den anden terminal, der kører fio-jobbet, og se på output, men for at gøre tingene pænere, er her et øjebliksbillede af det observerede læse/skrive-gennemløb i Grafana:
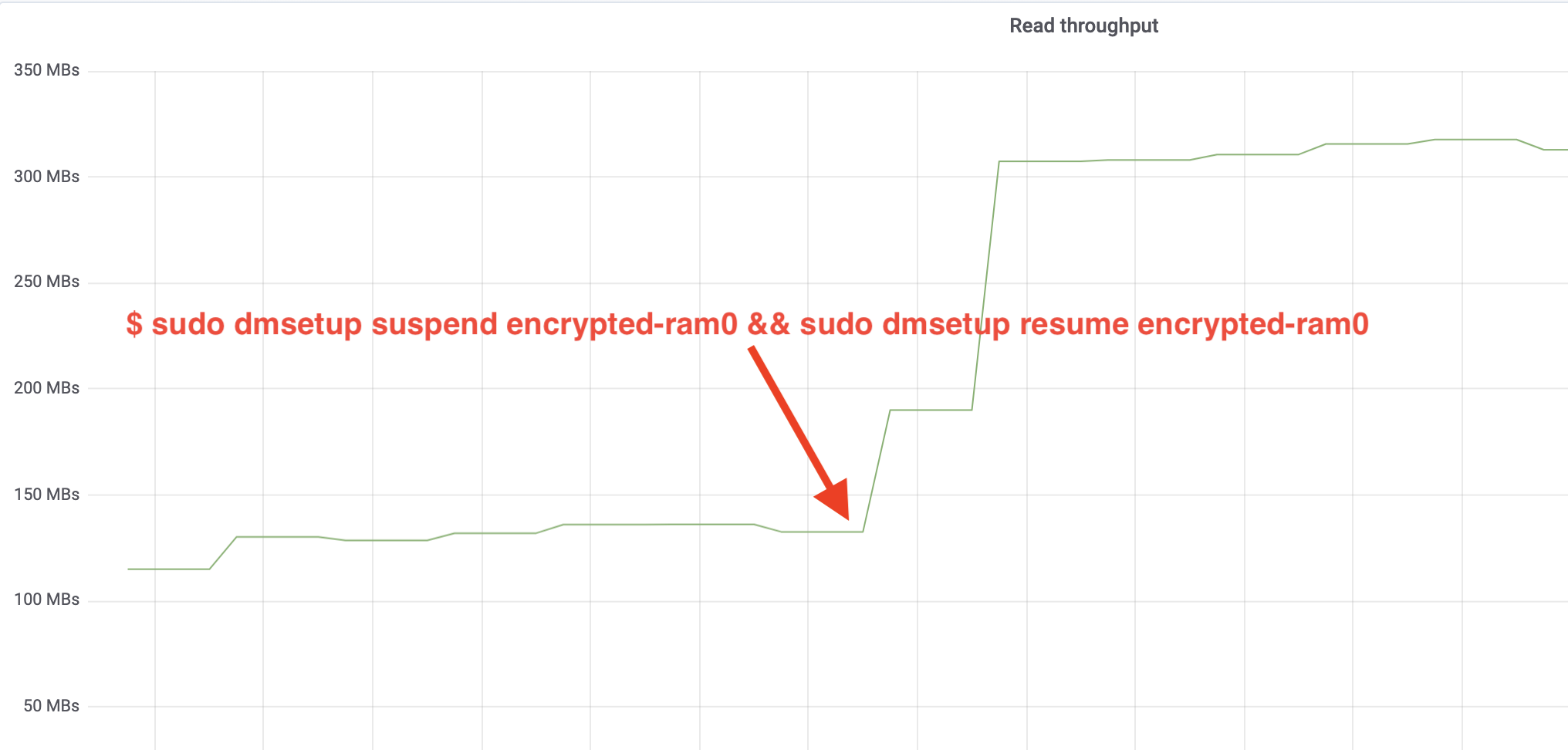
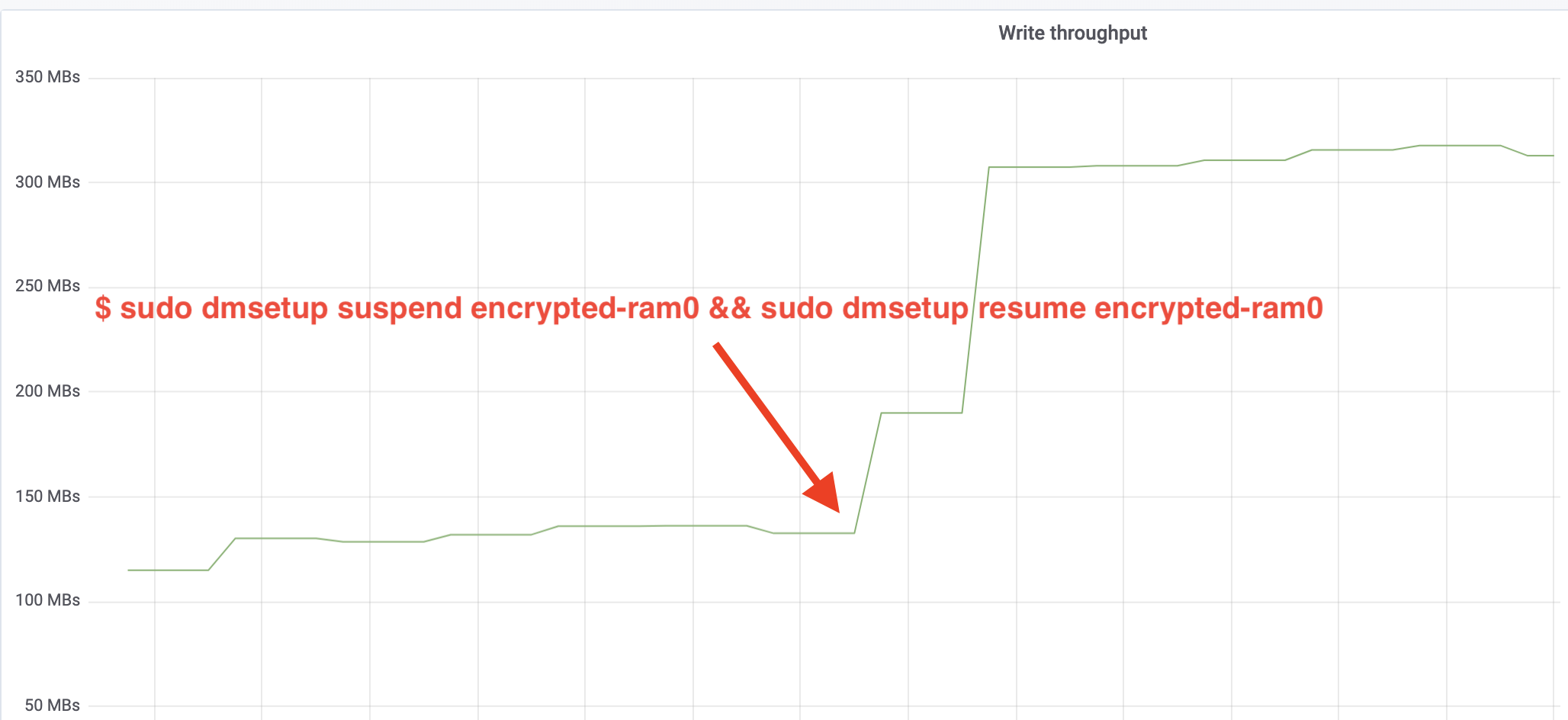
Wow, vi har mere end fordoblet gennemløbet! Med det samlede gennemløb på ~640 MB/s er vi nu meget tættere på det forventede ~696 MB/s fra ovenfor. Hvad med IO-latenstiden? (await-statistikken fra iostat-rapporteringsværktøjet):
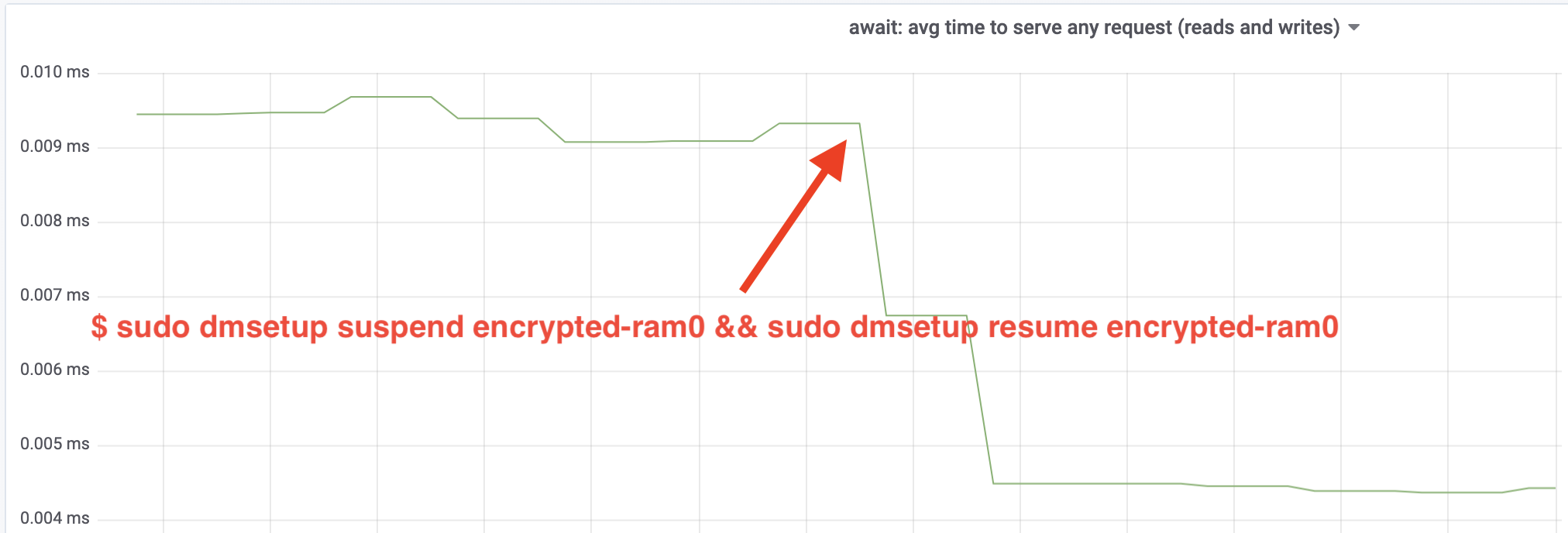
Latency er også blevet halveret!
Til produktion
Så langt har vi brugt en syntetisk opsætning, hvor nogle dele af den fulde produktionsstack mangler, som f.eks. filsystemer, rigtig hardware og vigtigst af alt, produktionsarbejdsmængde. For at sikre, at vi ikke optimerer imaginære ting, er her et øjebliksbillede af den produktionseffekt, som disse ændringer medfører for caching-delen af vores stak:

Denne graf repræsenterer en trevejssammenligning af de værst tænkelige svartider (99. percentil) for et cachetræf i en af vores servere. Den grønne linje er fra en server med ukrypterede diske, som vi vil bruge som baseline. Den røde linje er fra en server med krypterede diske med standardimplementeringen af Linux-disk-kryptering, og den blå linje er fra en server med krypterede diske og vores optimeringer aktiveret. Som vi kan se, har standardimplementeringen af Linux-disk-kryptering en betydelig indvirkning på vores cache-latenstid i de værst tænkelige scenarier, hvorimod den patchede implementering ikke kan adskilles fra slet ikke at bruge kryptering. Med andre ord har den forbedrede krypteringsimplementering slet ikke nogen indvirkning på vores cachesvarhastighed, så vi får den stort set gratis! Det er en gevinst!
Vi er kun lige begyndt
Dette indlæg viser, hvordan en arkitekturgennemgang kan fordoble et systems ydeevne. Desuden bekræftede vi igen, at moderne kryptografi ikke er dyrt, og at der normalt ikke er nogen undskyldning for ikke at beskytte dine data.
Vi vil indsende dette arbejde til optagelse i kernehovedkildetræet, men højst sandsynligt ikke i sin nuværende form. Selv om resultaterne ser opmuntrende ud, må vi huske på, at Linux er et meget bærbart styresystem: det kører på kraftige servere såvel som på små IoT-enheder med begrænsede ressourcer og på mange andre CPU-arkitekturer også. Den nuværende version af patches optimerer blot disk-kryptering til en bestemt arbejdsbyrde på en bestemt arkitektur, men Linux har brug for en løsning, der kører problemfrit overalt.
Det sagt, hvis du mener, at dit tilfælde ligner det, og du ønsker at drage fordel af ydelsesforbedringerne nu, kan du hente patches og forhåbentlig give feedback. Runtime-flaget gør det nemt at skifte funktionaliteten i farten, og der kan udføres en simpel A/B-test for at se, om det gavner et bestemt tilfælde eller en bestemt opsætning. Disse patches har kørt på tværs af vores brede netværk af mere end 200 datacentre på fem generationer af hardware, så de kan med rimelighed anses for at være stabile. Nyd både ydeevne og sikkerhed fra Cloudflare for alle!

Opdatering (11. oktober 2020)
Den vigtigste patch fra denne blog (i en let opdateret form) er blevet indføjet i mainline Linux-kernen og er tilgængelig siden version 5.9 og frem. Hovedforskellen er, at mainline-versionen eksponerer to flag i stedet for ét, som giver mulighed for at omgå dm-crypt-arbejdskøer for læsninger og skrivninger uafhængigt af hinanden. For nærmere oplysninger, se den officielle dm-crypt-dokumentation.