
Hvis du vil lære mere om Python, kan du tage DataCamps gratis kursus Intro til Python for Data Science.
I har alle set datasæt. Nogle gange er de små, men ofte til tider er de enormt store i størrelse. Det bliver meget udfordrende at behandle de datasæt, der er meget store, i hvert fald betydelige nok til at forårsage en flaskehals i behandlingen.
Så, hvad gør disse datasæt så store? Tja, det er funktioner. Jo mere antallet af funktioner er, jo større bliver datasættene. Nå, men ikke altid. Du vil finde datasæt, hvor antallet af features er meget stort, men de indeholder ikke så mange instanser. Men det er ikke det, der skal diskuteres her. Så man kan med en almindelig computer i hånden undre sig over, hvordan man kan behandle denne type datasæt uden at slå på trådene.
Ofte er der i et højdimensionelt datasæt stadig nogle helt irrelevante, ubetydelige og uvæsentlige features tilbage. Det har vist sig, at disse typer funktioner ofte har et mindre bidrag til den prædiktive modellering end de kritiske funktioner. De kan også have et bidrag på nul. Disse funktioner forårsager en række problemer, som igen forhindrer processen med effektiv prædiktiv modellering –
- Unødvendig ressourceallokering til disse funktioner.
- Disse funktioner fungerer som støj, som maskinlæringsmodellen kan præstere forfærdelig dårligt for.
- Maskinmodellen tager mere tid at blive trænet.
Så, hvad er løsningen her? Den mest økonomiske løsning er Feature Selection.
Feature Selection er processen med at udvælge de mest betydningsfulde funktioner fra et givet datasæt. I mange af tilfældene kan Feature Selection også forbedre ydeevnen af en maskinlæringsmodel.
Det lyder interessant, ikke sandt?
Du fik en uformel introduktion til Feature Selection og dens betydning i en verden af datalogi og maskinlæring. I dette indlæg vil du dække:
- Indledning til feature selection og forståelse af dens betydning
- Forskellen mellem feature selection og dimensionalitetsreduktion
- Forskellige typer af feature selection-metoder
- Implementering af forskellige feature selection-metoder med scikit-learn
Indledning til feature selection
Feature selection er også kendt som Variable selection eller Attribute selection.
Essentielt set er det en proces, hvor man udvælger de vigtigste/relevante. Funktioner i et datasæt.
Forstå betydningen af funktionsudvælgelse
Vigtigheden af funktionsudvælgelse kan bedst erkendes, når man har at gøre med et datasæt, der indeholder et stort antal funktioner. Denne type datasæt betegnes ofte som et højdimensionelt datasæt. Nu, med denne høje dimensionalitet, kommer en masse problemer såsom – denne høje dimensionalitet vil øge træningstiden for din maskinlæringsmodel betydeligt, det kan gøre din model meget kompliceret, hvilket igen kan føre til Overfitting.
Ofte i et højdimensionelt featuresæt forbliver der flere features, som er redundante, hvilket betyder, at disse features ikke er andet end udvidelser af de andre væsentlige features. Disse overflødige funktioner bidrager heller ikke effektivt til modeltræningen. Så det er klart, at der er behov for at udtrække de vigtigste og mest relevante funktioner for et datasæt for at få den mest effektive prædiktive modelleringspræstation.
“Målet med variabelvalg er tredobbelt: at forbedre prædiktorernes prædiktionspræstation, at give hurtigere og mere omkostningseffektive prædiktorer og at give en bedre forståelse af den underliggende proces, der har genereret dataene.”
-An Introduction to Variable and Feature Selection
Nu skal vi forstå forskellen mellem dimensionalitetsreduktion og feature selection.
Sommetider forveksles feature selection med dimensionalitetsreduktion. Men de er forskellige. Featurevalg er forskelligt fra dimensionalitetsreduktion. Begge metoder har en tendens til at reducere antallet af attributter i datasættet, men en dimensionalitetsreduktionsmetode gør det ved at skabe nye kombinationer af attributter (undertiden kendt som feature transformation), mens feature selection metoder inkluderer og ekskluderer attributter, der er til stede i dataene, uden at ændre dem.
Nogle eksempler på dimensionalitetsreduktionsmetoder er Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis osv.
Lad mig opsummere betydningen af feature selection for dig:
- Det gør det muligt for maskinindlæringsalgoritmen at træne hurtigere.
- Det reducerer kompleksiteten af en model og gør den lettere at fortolke.
- Det forbedrer nøjagtigheden af en model, hvis den rigtige delmængde er valgt.
- Det reducerer Overfitting.
I det næste afsnit vil du studere de forskellige typer generelle metoder til udvælgelse af funktioner – Filtermetoder, Wrapper-metoder og Embedded-metoder.
Filtermetoder
Det følgende billede beskriver bedst filterbaserede metoder til udvælgelse af funktioner:

Billedkilde: Filtreringsmetoden er afhængig af den generelle entydighed af de data, der skal evalueres, og vælger en delmængde af funktioner, der ikke omfatter nogen miningalgoritme. Filtermetoden anvender det nøjagtige vurderingskriterium, som omfatter afstand, information, afhængighed og konsistens. Filtermetoden anvender de vigtigste kriterier for rangordningsteknik og anvender rangordningsmetoden til udvælgelse af variabler. Grunden til at anvende rangordningsmetoden er enkelhed, og den giver fremragende og relevante funktioner. Rangordningsmetoden vil filtrere irrelevante funktioner fra, før klassifikationsprocessen starter.
Filtermetoder anvendes generelt som et datapræprocesseringstrin. Udvælgelsen af funktioner er uafhængig af enhver maskinlæringsalgoritme. Funktioner giver rang på grundlag af statistiske scorer, som har tendens til at bestemme funktionernes korrelation med udfaldsvariablen. Korrelation er et meget kontekstafhængigt begreb, og det varierer fra arbejde til arbejde. Du kan henvise til følgende tabel for at definere korrelationskoefficienter for forskellige typer data (i dette tilfælde kontinuerlige og kategoriske).

Billedkilde: Analytics Vidhya
Nogle eksempler på nogle filtermetoder omfatter Chi-kvadrat-test, informationsgevinst og scoringer af korrelationskoefficienter.
Næst vil du se Wrapper-metoder.
Wrapper-metoder
Legeledes som filtermetoder vil jeg give dig en lignende infografik, som vil hjælpe dig med at forstå wrapper-metoder bedre:
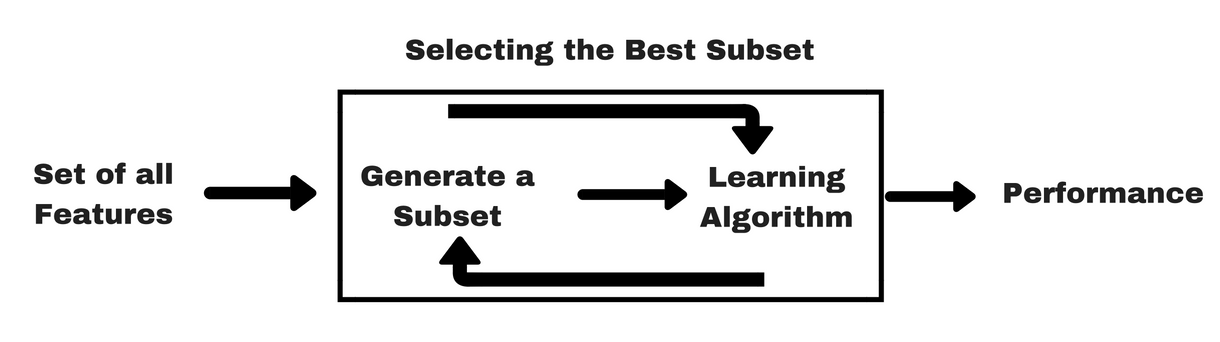
Billedkilde: Som du kan se i ovenstående billede, har en wrapper-metode brug for én maskinlæringsalgoritme og bruger dens ydeevne som evalueringskriterium. Denne metode søger efter en funktion, der er bedst egnet til den maskinlæringsalgoritme, og har til formål at forbedre minedriftsydelsen. For at evaluere funktionerne anvendes den prædiktive nøjagtighed til klassifikationsopgaver, og klyngens godhed evalueres ved hjælp af clustering.
Nogle typiske eksempler på wrapper-metoder er forward feature selection, backward feature elimination, rekursiv feature elimination osv.
- Forward Selection: Proceduren starter med et tomt sæt af træk . Det bedste af de oprindelige træk bestemmes og tilføjes til det reducerede sæt. Ved hver efterfølgende iteration tilføjes den bedste af de resterende oprindelige egenskaber til sættet.
- Bagudrettet eliminering: Proceduren starter med det fulde sæt af attributter. Ved hvert trin fjernes den dårligste attribut, der er tilbage i sættet.
- Kombination af fremadrettet udvælgelse og bagudrettet eliminering: Metoderne trinvis fremadrettet udvælgelse og bagudrettet eliminering kan kombineres, således at proceduren på hvert trin udvælger den bedste attribut og fjerner den dårligste af de tilbageværende attributter.
- Rekursiv eliminering af egenskaber: Ved rekursiv eliminering af egenskaber foretages en greedy-søgning for at finde den bedst fungerende delmængde af egenskaber. Den opretter modeller gentagne gange og bestemmer den bedste eller den dårligste egenskab ved hver iteration. Den konstruerer de efterfølgende modeller med de resterende funktioner, indtil alle funktioner er udforsket. Derefter rangeres funktionerne efter den rækkefølge, i hvilken de er blevet fjernet. I værste fald, hvis et datasæt indeholder N antal funktioner, vil RFE foretage en grådig søgning efter 2N kombinationer af funktioner.
Godt nok!
Nu skal vi studere indlejrede metoder.
Indlejrede metoder
Indlejrede metoder er iterative i den forstand, at de tager sig af hver iteration af modeltræningsprocessen og omhyggeligt udtrækker de funktioner, der bidrager mest til træningen for en bestemt iteration. Regulariseringsmetoder er de mest almindeligt anvendte indlejrede metoder, som straffer en funktion givet en koefficienttærskel.
Det er grunden til, at regulariseringsmetoder også kaldes penaliseringsmetoder, der indfører yderligere begrænsninger i optimeringen af en forudsigelsesalgoritme (f.eks. en regressionsalgoritme), som skævvrider modellen i retning af lavere kompleksitet (færre koefficienter).
Eksempler på reguleringsalgoritmer er LASSO, Elastic Net, Ridge Regression osv.
Difference mellem filter- og wrappermetoder
Jamen, det kan til tider være forvirrende at skelne mellem filtermetoder og wrappermetoder med hensyn til deres funktionaliteter. Lad os tage et kig på, hvilke punkter de adskiller sig fra hinanden.
- Filtermetoder inkorporerer ikke en maskinlæringsmodel for at afgøre, om en funktion er god eller dårlig, mens wrapper-metoder bruger en maskinlæringsmodel og træner den funktionen for at afgøre, om den er væsentlig eller ej.
- Filtermetoder er meget hurtigere sammenlignet med wrapper-metoder, da de ikke involverer træning af modellerne. På den anden side er wrappermetoder beregningskrævende, og i tilfælde af massive datasæt er wrappermetoder ikke den mest effektive metode til udvælgelse af funktioner at overveje.
- Filtermetoder kan muligvis ikke finde den bedste delmængde af funktioner i situationer, hvor der ikke er nok data til at modellere den statistiske korrelation af funktionerne, men wrappermetoder kan altid give den bedste delmængde af funktioner på grund af deres udtømmende karakter.
- Anvendelse af funktioner fra wrapper-metoder i din endelige maskinlæringsmodel kan føre til overpasning, da wrapper-metoder allerede træner maskinlæringsmodeller med funktionerne, og det påvirker den sande læringskraft. Men funktioner fra filtermetoder vil ikke føre til overtilpasning i de fleste tilfælde
Så langt har du studeret betydningen af funktionsudvælgelse og forstået forskellen mellem den og dimensionalitetsreduktion. Du har også dækket forskellige typer af metoder til udvælgelse af funktioner. Så langt, så godt!
Lad os nu se nogle fælder, som du kan komme i, mens du udfører funktionsudvælgelse:
Vigtig overvejelse
Du har måske allerede forstået værdien af funktionsudvælgelse i en pipeline til maskinlæring og den slags tjenester, som den giver, hvis den er integreret. Men det er meget vigtigt at forstå, præcis hvor du bør integrere funktionsudvælgelse i din pipeline til maskinlæring.
Simpelt sagt bør du inkludere funktionsudvælgelsestrinet, før du indfører dataene til modellen til træning, især når du bruger metoder til estimering af nøjagtighed som f.eks. krydsvalidering. Dette sikrer, at funktionsudvælgelse udføres på datafoldet lige før modellen trænes. Men hvis du først udfører funktionsudvælgelse for at forberede dine data og derefter udfører modeludvælgelse og træning på de udvalgte funktioner, så ville det være en fejltagelse.
Hvis du udfører funktionsudvælgelse på alle data og derefter krydsvaliderer, så blev testdataene i hver fold i krydsvalideringsproceduren også brugt til at vælge funktionerne, og dette har en tendens til at skævvride din maskinlæringsmodels ydeevne.
Genstand med teorier! Lad os komme direkte til noget kodning nu.
En casestudie i Python
I denne casestudie skal du bruge Pima Indians Diabetes-datasættet. Beskrivelsen af datasættet kan findes her.
Datasættet svarer til klassifikationsopgaver, hvor du skal forudsige, om en person har diabetes på baggrund af 8 funktioner.
Der er i alt 768 observationer i datasættet. Din første opgave er at indlæse datasættet, så du kan gå videre. Men før det, lad os importere de nødvendige afhængigheder, du får brug for. Du kan importere de andre undervejs.
import pandas as pdimport numpy as npNu, hvor afhængighederne er importeret, lad os indlæse Pima Indians-datasættet i et Dataframe-objekt ved hjælp af Pandas-biblioteket.
data = pd.read_csv("diabetes.csv")Datasættet er succesfuldt indlæst i Dataframe-objektet data. Lad os nu tage et kig på dataene.
data.head()
Så du kan se 8 forskellige funktioner mærket i resultaterne 1 og 0, hvor 1 står for, at observationen har diabetes, og 0 betegner, at observationen ikke har diabetes. Datasættet er kendt for at have manglende værdier. Specifikt er der manglende observationer for nogle kolonner, der er markeret som en nulværdi. Man kan udlede dette af definitionen af disse kolonner, og det er upraktisk at have en nulværdi er ugyldig for disse foranstaltninger, f.eks, nul for kropsmasseindeks eller blodtryk er ugyldigt.
Men i denne vejledning vil du direkte bruge den forbehandlede version af datasættet.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Du har indlæst dataene i et DataFrame-objekt kaldet dataframe nu.
Lad os konvertere DataFrame-objektet til et NumPy-array for at opnå hurtigere beregning. Lad os også adskille dataene i separate variabler, så funktionerne og etiketterne er adskilt.
array = dataframe.valuesX = arrayY = arrayVelsket! Du har forberedt dine data.
Først skal du implementere en statistisk Chi-Squared-test for ikke-negative funktioner for at udvælge 4 af de bedste funktioner fra datasættet. Du har allerede set, at Chi-Squared-testen hører til klassen af filtermetoder. Hvis nogen er nysgerrige efter at kende de interne aspekter af Chi-Squared, gør denne video et fremragende stykke arbejde.
Scikit-learn-biblioteket leverer SelectKBest-klassen, der kan bruges med en række forskellige statistiske test til at vælge et bestemt antal funktioner, i dette tilfælde er det Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Du importerede bibliotekerne for at køre eksperimenterne. Lad os nu se det i aktion.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features)# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretation:
Du kan se scoren for hver attribut og de 4 valgte attributter (dem med den højeste score): plas, test, masse og alder. Disse scorer vil hjælpe dig yderligere med at bestemme de bedste egenskaber til træning af din model.
P.S.: Den første række angiver navnene på egenskaberne. Med henblik på forbehandling af datasættet er navnene blevet numerisk kodet.
Dernæst skal du implementere Recursive Feature Elimination, som er en type wrapper-featureudvælgelsesmetode.
Den rekursive Feature Elimination (eller RFE) fungerer ved rekursivt at fjerne attributter og opbygge en model på de attributter, der er tilbage.
Den bruger modellens nøjagtighed til at identificere, hvilke attributter (og kombinationer af attributter) der bidrager mest til at forudsige målattributten.
Du kan få mere at vide om RFE-klassen i scikit-learn-dokumentationen.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionDu vil bruge RFE med Logistic Regression-klassifikatoren til at vælge de 3 bedste funktioner. Valget af algoritme betyder ikke så meget, så længe den er dygtig og konsistent.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Du kan se, at RFE valgte de 3 bedste funktioner som preg, mass og pedi.
Disse er markeret True i support arrayet og markeret med et valg “1” i ranking arrayet. Dette angiver igen styrken af disse funktioner.
Næste gang vil du bruge Ridge-regression, som grundlæggende er en reguleringsteknik og en indlejret funktionsudvælgelsesteknik også.
Denne artikel giver dig en fremragende forklaring på Ridge-regression. Sørg for at tjekke den ud.
# First things firstfrom sklearn.linear_model import RidgeNæst vil du bruge Ridge-regression til at bestemme koefficienten R2.
Tjek også scikit-learns officielle dokumentation om Ridge-regression.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)For bedre at forstå resultaterne af Ridge-regression vil du implementere en lille hjælpefunktion, som vil hjælpe dig med at udskrive resultaterne i en bedre, så du nemt kan fortolke dem.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Næst vil du videregive Ridge-modellens koefficienttermer til denne lille funktion og se, hvad der sker.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Du kan se alle koefficienttermerne, der er vedhæftet med feature-variablerne. Det vil igen hjælpe dig med at vælge de mest væsentlige funktioner. Nedenfor er nogle punkter, som du bør huske på, mens du anvender Ridge-regression:
- Det er også kendt som L2-regularisering.
- For korrelerede funktioner betyder det, at de har en tendens til at få ens koefficienter.
- Funktioner med negative koefficienter bidrager ikke så meget. Men i et mere komplekst scenarie, hvor du har med mange funktioner at gøre, vil denne score helt sikkert hjælpe dig i den endelige beslutningsproces for valg af funktioner.
Det afslutter casestudieafsnittet. De metoder, som du implementerede i ovenstående afsnit, vil hjælpe dig til at forstå funktionerne i et bestemt datasæt på en omfattende måde. Lad mig give dig nogle kritiske punkter om disse teknikker:
- Udvælgelse af karakteristika er i det væsentlige en del af forbehandlingen af data, som anses for at være den mest tidskrævende del af enhver pipeline til maskinlæring.
- Disse teknikker vil hjælpe dig med at gribe det an på en mere systematisk måde og på en maskinlæringsvenlig måde. Du vil være i stand til at fortolke funktionerne mere præcist.
Wrap up!
I dette indlæg har du dækket et af de mest velundersøgte og velforskede statistiske emner, nemlig valg af funktioner. Du blev også fortrolig med dens forskellige varianter og brugte dem til at se, hvilke funktioner i et datasæt der er vigtige.
Du kan gå videre med denne tutorial ved at flette et korrelationsmål ind i wrapper-metoden og se, hvordan den klarer sig. I løbet af handlingen ender du måske med at skabe din egen mekanisme til udvælgelse af funktioner. På den måde skaber du grundlaget for din lille forskning. Forskere bruger også forskellige soft computing-principper for at udføre udvælgelsen. Dette er i sig selv et helt undersøgelses- og forskningsområde. Du bør også afprøve de eksisterende algoritmer til udvælgelse af funktioner på forskellige datasæt og drage dine egne konklusioner.
Hvorfor gælder disse traditionelle metoder til udvælgelse af funktioner stadig?
Ja, dette spørgsmål er indlysende. Fordi der findes neurale netarkitekturer (f.eks. CNN’er), som er ganske velegnede til at udtrække de mest betydningsfulde træk fra data, men det har også en begrænsning. Det er ikke den klogeste beslutning at bruge et CNN til et almindeligt tabulært datasæt, som ikke har specifikke egenskaber (de egenskaber, som et typisk billede har, f.eks. overgangsegenskaber, kanter, positionsegenskaber, konturer osv. Når man har begrænsede data og begrænsede ressourcer, kan det desuden være helt spildt at træne en CNN på almindelige tabeldatasæt. Så i sådanne situationer vil de metoder, som du har studeret, helt sikkert være nyttige.
Følgende er nogle ressourcer, hvis du gerne vil grave mere i dette emne:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection: Statistical and Optimization Perspectives Workshop
- Feature Selection: Statistical and Optimization Perspectives Workshop
- Feature Selection: Problemstilling og anvendelser
- Anvendelse af genetiske algoritmer til udvælgelse af funktioner i dataanalyse
Nedenfor er de referencer, der blev brugt til at skrive denne vejledning.
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- En introduktion til feature selection
- Analytics Vidhya-artikel om feature selection
- Hierarchical and Mixed Model – DataCamp-kursus
- Feature Selection For Machine Learning in Python
- Outlier Detection in Stream Data by MachineLearning and Feature Selection Methods
- S. Visalakshi og V. Radha, “A literature review of feature selection techniques and applications”: Review of feature selection in data mining,” 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.