Af: Derek Colley | Opdateret: 2014-01-29 | Kommentarer (5) | Relateret: Flere >Funktioner – System
Problem
Du ønsker at hente en tilfældig prøve fra et SQL Server forespørgselsresultatsæt. Måske leder du efter en repræsentativ stikprøve af data fra en stor kundedatabase; måske leder du efter nogle gennemsnit eller en idé om, hvilken type data du har. SELECT TOP N er ikke altid ideelt, da data outliers ofte forekommer i starten og slutningen af datasæt, især når de er ordnet alfabetisk eller efter en skalarværdi. Ligeledes har du måske brugt TABLESAMPLE, men det har begrænsninger, især med små eller skæve datasæt. Måske har din chef bedt dig om et tilfældigt udvalg af 100 kundenavne og -lokationer, eller du deltager i en revision og har brug for at udtage et tilfældigt udvalg af data til analyse. Hvordan ville du udføre denne opgave? Se dette tip for at få mere at vide.
Løsning
Dette tip viser dig, hvordan du kan bruge TABLESAMPLE i T-SQL til at hente pseudo-tilfældige datastikprøver, og gennemgår de interne aspekter af TABLESAMPLE, og hvor det ikke er hensigtsmæssigt. Det vil også vise dig en alternativ metode – en matematisk metode ved hjælp af NEWID() kombineret med CHECKSUM og en bitvis operatør, som Microsoft har nævnt i artiklen TABLESAMPLE TechNet. Vi vil tale lidt om statistisk stikprøveudtagning generelt (forskellene mellem tilfældig, systematisk og stratificeret) med eksempler, og vi vil tage et kig på, hvordan SQL-statistikker udtages som et eksempel, og de muligheder vi kan bruge til at tilsidesætte denne stikprøveudtagning. Efter at have læst dettetip, bør du have en forståelse for fordelene ved sampling frem for at bruge metoder som TOP N og vide, hvordan du kan anvende mindst én metode til at opnå dette i SQL Server.
Setup
I dette tip vil jeg bruge et datasæt, der indeholder en identitets INT-kolonne (for at etablere graden af tilfældighed ved udvælgelse af rækker) og andre kolonner fyldt med pseudo-tilfældig data af forskellige datatyper, for at (vagt) simulere rigtige data i en tabel. Du kan bruge nedenstående T-SQL-kode til at opsætte dette. Det burde kun tage et par minutter at køre og er testet på SQL Server 2012 Developer Edition.
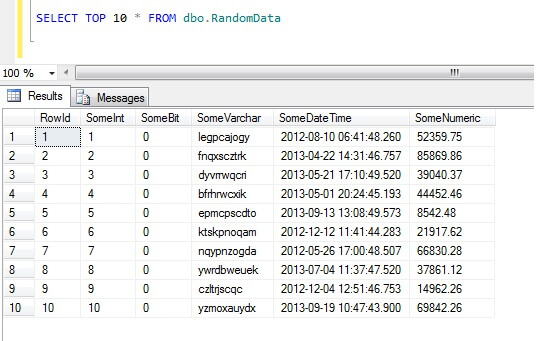
Vælgelse af de 10 øverste rækker af data giver dette resultat (bare for at give dig en idé om dataenes form).Som en sidebemærkning er dette et generelt stykke kode, som jeg har lavet til at generere random-ishdata, når jeg havde brug for det – du er velkommen til at tage det og øge/pille det til dit hjertes indhold!
Sådan skal du ikke prøve data i SQL Server
Nu har vi vores dataeksempler, lad os tænke på de værste måder at få en prøve på. I AdventureWorks-databasen findes der en tabel, der hedder Person.Address. Lad os tage en prøve ved at tage de 10 bedste resultater, uden nogen bestemt rækkefølge:
SELECT TOP 10 * FROM Person.Address
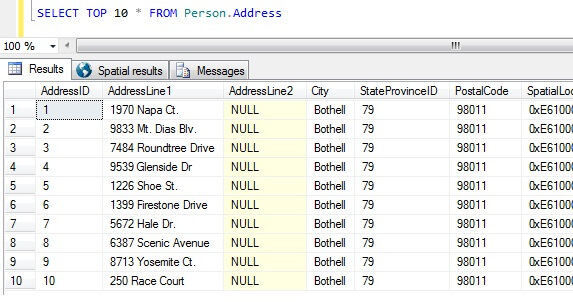
Går vi alene ud fra denne prøve, kan vi se, at alle de returnerede personer bor i Bothell, og deler postnummer 98011. Dette skyldes, at resultaterne ikke blev angivet til at blive returneret i nogen bestemt rækkefølge, men blev faktisk returneret i rækkefølge efter AddressID-kolonnen. Bemærk, at dette IKKE er en garanteret adfærd for især heap-data – se dette citat fra BOL:
“Normalt lagres data i første omgang i den rækkefølge, som er de rækker, der er indsat i tabellen, men Database Engine kan flytte data rundt i heap’en for at lagre rækkerne effektivt; derfor kan datarækkefølgen ikke forudsiges. For at garantere rækkefølgen af de rækker, der returneres fra en heap, skal du bruge ORDER BY-klausulen.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Hvis man tager dette resultatsæt, kan en person, der ikke er informeret om tabellens karakter, konkludere, at alle deres kunder bor i Bothell.
Typer af dataudtagninger i SQL Server
Overstående er klart forkert, så vi har brug for en bedre måde at udtage prøver på. Hvad med at tage en prøve med jævne mellemrum i hele tabellen?
Dette skulle returnere 47 rækker:
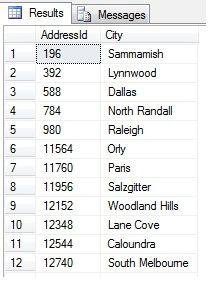
Så langt, så godt. Vi har taget en række med regelmæssige intervaller i hele vores datasæt og returneret et statistisk tværsnit – eller har vi? Ikke nødvendigvis. Glem ikke, at rækkefølgen ikke er garanteret. Vi kan drage en eller to konklusioner om disse data. Lad os aggregere dem for at illustrere det. Kør ovenstående kodestump igen, men ændr den sidste SELECT-blok som følger:
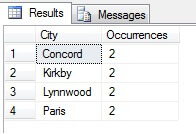
Du kan se i mit eksempel, at jeg ud fra et samlet antal på mere end 19.000 rækker i tabellen Person.Address har udtaget ca. 1/4 % af rækkerne, og derfor kan jeg konkludere, at (i mit eksempel) Concord, Kirkby, Lynnwood og Paris har flest indbyggere og desuden er lige befolkede. Er det korrekt? Sludder, selvfølgelig:
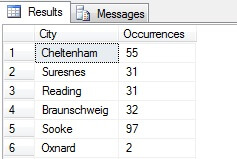
Som du kan se, var ingen af mine fire faktisk blandt de fire bedste steder at bo, som vurderet ud fra denne tabel. Ikke alene var stikprøvedataene for små, men jeg aggregerede denne lille stikprøve og forsøgte at drage en konklusion ud fra den. Det betyder, at mit resultatsæt er statistisk insignifikant – at bevise statistisk signifikans er en af de største bevisbyrder ved præsentation af statistiske oversigter (eller burde være det) og en stor nedtur for mange populære infografikker og markedsføringsstyrede datagrammer.
Så, stikprøveudtagning på denne måde (kaldet systematisk stikprøveudtagning) er effektiv, men kun for en statistisk signifikant population. Der er faktorer som periodicitet og proportioner, der kan ødelægge en stikprøve – lad os se proportioner i praksis ved at tage en stikprøve på 10 byer fra tabellen Person.Address ved hjælp af følgende kode, som henter en særskilt liste af byer fra tabellen Person.Address og derefter udvælger 10 byer fra denne liste ved hjælp af systematisk stikprøveudtagning:
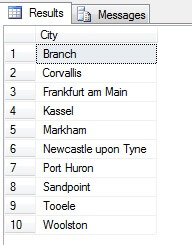
Looking like a good sample, right? Lad os nu sammenligne det med en stikprøve af IKKE-distinkte byer, der er opført i stigende rækkefølge, dvs. hver niende by, hvor n er det samlede antal rækker divideret med 10. Dette mål tager hensyn til stikprøvepopulationen:
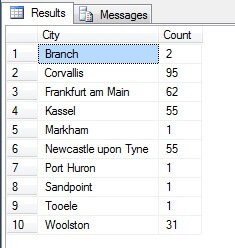
De data, der returneres, er helt anderledes – ikke på grund af tilfældigheder, men ved præsentation af en repræsentativ stikprøve. Bemærk, at denne liste, hvor jeg har medtaget tællingerne for hver by i kildetabellen for at skitsere, hvor meget befolkningen spiller en rolle i dataudvælgelsen, omfatter de fire mest befolkede byer i stikprøven, hvilket (hvis man betragter en ordnet ikke-distinktiv liste) er den mest retfærdige repræsentation. Det er ikke nødvendigvis den bedste repræsentation til dine behov, så vær forsigtig, når du vælger din statistiske stikprøvemetode.
Andre stikprøvemetoder
Klyngestikprøveudtagning – her opdeles den population, der skal udtages som stikprøve, i klynger eller delmængder, hvorefter hver af disse delmængder tilfældigt bestemmes til at indgå eller ikke indgå i output-resultatsættet. Hvis de er inkluderet, returneres alle medlemmer af den pågældende delmængde i resultatmængden. Se TABLESAMPLE nedenfor for et eksempel på dette.
Disproportional stikprøveudtagning – dette er ligesom stratificeret stikprøveudtagning, hvor medlemmer af undergrupper udvælges for at repræsentere hele gruppen, men i stedet for at være proportionelle kan der være forskellige antal medlemmer fra hver gruppe, der udvælges for at udligne repræsentationen fra hver gruppe. Dvs. i betragtning af byerne i Person.Address i eksemplet fra afsnittet ovenfor var det første resultatsæt uforholdsmæssigt, da det ikke tog hensyn til befolkningstallet, men det andet resultatsæt var forholdsmæssigt, da det repræsenterede antallet af byposter i tabellen Person.Address. Denne type prøveudtagning er faktisk nyttig, hvis en bestemt kategori er underrepræsenteret i datasættet, og andelen ikke er vigtig (f.eks. 100 tilfældige kunder fra 100 tilfældige byer stratificeret efter by – byerne i delmængden ville have brug for normalisering – uproportionel prøveudtagning kan bruges).
SQL Server Random Data with TABLESAMPLE
SQL Server leveres hjælpsomt med en metode til prøveudtagning af data. Lad os se den i aktion. Brug følgende kode til at returnere ca. 100 rækker (hvis den returnerer 0 rækker, skal du køre igen – jeg forklarer det om lidt) af data fra dbo.RandomData, som vi definerede tidligere.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
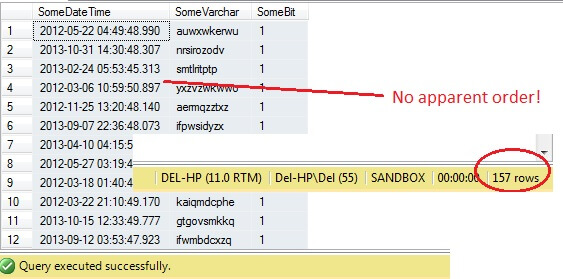
Så langt, så godt, ikke? Vent lige lidt – vi kan ikke se kolonnen Id. Lad os inkludere dette og køre igen:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
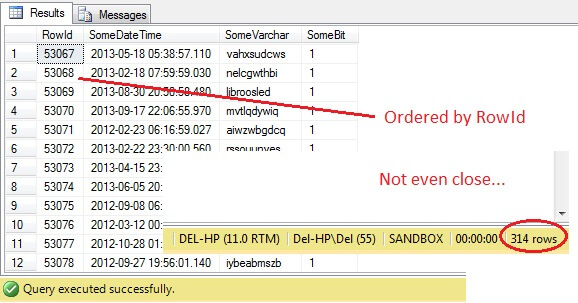
Åh nej – TABLESAMPLE har valgt et udsnit af data, men det er ikke tilfældigt – RowId viser et klart afgrænset udsnit med en minimums- og en maksimumsværdi. Desuden har den heller ikke returneret præcis 100 rækker. Hvad sker der?
TABLESAMPLE bruger den implicitte SYSTEM-modifikator. Dette modifikator, der er aktiveret som standard og er en ANSI-SQL-specifikation, dvs. ikke valgfri, vil tage hver 8 KB side, som tabellen ligger på, og beslutte, om alle rækker på den side, der er i den pågældende tabel, skal medtages i den producerede prøve, baseret på den procentdel eller N ROWS, der er angivet. Derfor bør en tabel, der er placeret på mange sider, dvs. har mange datarækker, give en mere tilfældig prøve, da der vil være flere sider i prøven. Det mislykkes i et eksempel som vores, hvor dataene er skalariske og små og kun befinder sig på få sider – hvis et antal sider ikke klarer skæringen, kan det i høj grad skævvride outputprøven. Dette er TABLESAMPLE’s ulempe – den fungerer ikke godt for “små” data, og den tager ikke hensyn til fordelingen af dataene på siderne. Så arrangementet af data på siderne er i sidste ende ansvarlig for den stikprøve, der returneres af denne metode.
Lyder dette bekendt? Det er i bund og grund klyngestikprøveudtagning, hvor alle medlemmer (rækker) i de valgte grupper (klynger) er repræsenteret i resultatmængden.
Lad os teste det på en stor tabel for at understrege pointen om omvendt ikke-skalerbarhed. Lad os først identificere den største tabel i AdventureWorks-databasen. Vi bruger en standardrapport til dette – ved hjælp af SSMS skal du højreklikke på AdventureWorks2012-databasen, gå til Rapporter -> Standardrapporter -> Diskforbrug efter de største tabeller. Bestil efter Data(KB) ved at klikke på kolonneoverskriften (du skal måske gøre dette to gange for at opnå faldende rækkefølge). Du vil se nedenstående rapport.
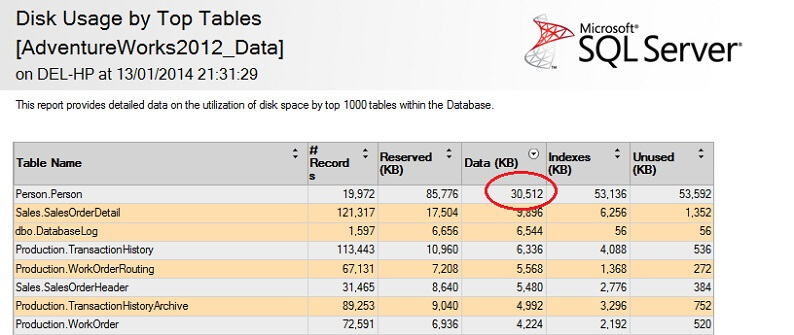
Jeg har indcirklet det interessante tal – personen. Person-tabellen bruger 30,5 MB data og er den største tabel (efter data, ikke efter antal poster). Så lad os prøve at tage en prøve fra denne tabel i stedet:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
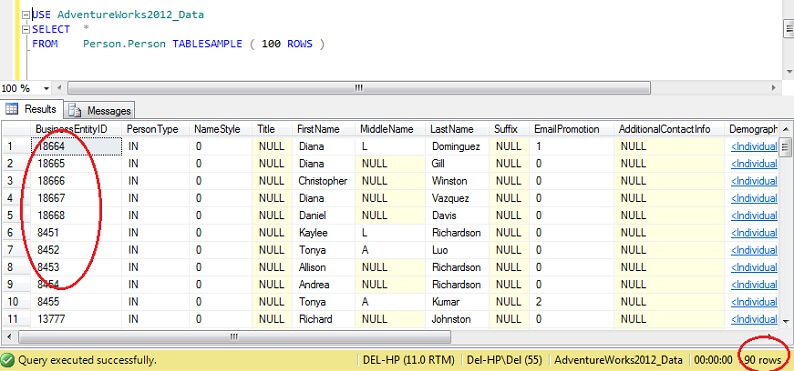
Du kan se, at vi er meget tættere på 100 rækker, men det afgørende er, at der ikke ser ud til at være meget clustering på primærnøglen (selv om der er noget, da der er mere end 1 række pr. side).
Som følge heraf er TABLESAMPLE god til store data, og bliver katastrofalt dårligere jo mindre datasættet er. Det er ikke godt for os, når vi udtager prøver fra stratificerede data eller klyngedata, hvor vi tager mange prøver fra små grupper eller delmængder af data og derefter aggregerer disse. Lad os så se på en alternativ metode.
Random SQL Server Data with ORDER BY NEWID()
Her er et citat fra BOL om at få en virkelig tilfældig prøve:
“Hvis du virkelig ønsker en tilfældig prøve af individuelle rækker, skal du ændre din forespørgsel til at filtrere rækker tilfældigt ud, i stedet for at bruge TABLESAMPLE. Følgende forespørgsel bruger f.eks. NEWID-funktionen til at returnere ca. én procent af rækkerne i tabellen Sales.SalesOrderDetail:
Hvordan virker det? Lad os dele WHERE-klausulen ud og forklare den.
Funktionen CHECKSUM beregner en kontrolsum over elementerne i listen. Det kan diskuteres, om SalesOrderID overhovedet er påkrævet, da NEWID() er en funktion, der returnerer et nyt tilfældigt GUID, så multiplikation af et tilfældigt tal med en konstant bør under alle omstændigheder resultere i et tilfældigt tal, og det ser faktisk ud til, at det ikke gør nogen forskel at udelukke SalesOrderID. Hvis du er en ivrig statistiker og kan begrunde medtagelsen af dette, bedes du bruge kommentarfeltet nedenfor og fortælle mig, hvorfor jeg tager fejl!
Funktionen CHECKSUM returnerer en VARBINARY. Ved at udføre en bitvis AND-operation med 0x7fffffffffff, som svarer til (11111111111…) i binær form, fås en decimalværdi, som reelt er en repræsentation af en tilfældig streng af 0’er og 1’er. Ved at dividere med koefficienten 0x7fffffffffff normaliseres dette decimaltal effektivt til et tal mellem 0 og 1. For derefter at afgøre, om hver række fortjener at indgå i det endelige resultatsæt, anvendes en tærskelværdi på 1/x (i dette tilfælde 0,01), hvor x er den procentdel af dataene, der skal hentes som en prøve.
Vær opmærksom på, at denne metode er en form for tilfældig prøveudtagning snarere end systematisk prøveudtagning, så du vil sandsynligvis få data fra alle dele af dine kildedata, men nøglen her er, at du *måske ikke*. Naturen af tilfældig stikprøveudtagning betyder, at enhver enkelt prøve, du indsamler, kan være skævvredet i retning af et segment af dine data, så for at drage fordel af regression til middelværdien (tendens til et tilfældigt resultat, i dette tilfælde) skal du sikre dig, at du tager flere prøver og vælger fra en delmængde af disse, hvis dine resultater ser skæve ud. Alternativt kan du tage stikprøver fra delmængder af dine data og derefter aggregere disse – dette er en anden type stikprøveudtagning, kaldet stratificeret stikprøveudtagning.
Hvordan bliver SQL Server-statistikker udtaget som stikprøver?
I SQL Server sker automatisk opdatering af kolonne- eller brugerdefinerede statistikker, når en fastsat tærskelværdi af tabelrækker ændres for en given tabel. For 2012 er denne tærskelværdi beregnet til SQRT(1000 * TR), hvor TR er antallet af tabelrækker i tabellen. Før 2005 blev det automatiske opdateringsstatistikjob udløst for hver (500 rækker + 20 % ændring) af tabelrækker. Når den automatiske opdateringsproces starter, vil prøveudtagningen *reducere antallet af rækker, der udtages, jo større tabellen bliver*, med andre ord er der et forhold, der ligner omvendt proportionalitet mellem tabelprøvetagningsprocenten og tabellens størrelse, men følger en proprietær algoritme.
Interessant nok synes dette at være det modsatte af indstillingen TABLESAMPLE (N PERCENT), hvor de udtagne rækker er i normal proportionalitet med antallet af rækker i tabellen. Vi kan deaktivere automatisk statistik (vær forsigtig med at gøre dette) og opdatere statistikken manuelt – dette opnås ved at bruge NORECOMPUTE på UPDATE STATISTICS statementet. Med UPDATE STATISTICS kan vi tilsidesætte nogle af indstillingerne – vi kan f.eks. vælge at prøve N rækker eller N procent (svarende til TABLESAMPLE), udføre en FULLSCAN eller blot RESAMPLE ved hjælp af den sidst kendte sats.
Næste skridt
For yderligere læsning, Joseph Sack er en Microsoft MVP kendt for sit arbejde med statistisk analyse af SQL Server – se nedenfor for nogle links til hans arbejde, sammen med nogle referencer til arbejde, der er brugt til denne artikel og til nogle relaterede tips fra MSSQLTips.com. Tak for læsning!
Sidst opdateret: 2014-01-29


Om forfatteren
 Derek Colley er en britisk baseret DBA og BI-udvikler med mere end ti års erfaring i at arbejde med SQL Server, Oracle og MySQL.
Derek Colley er en britisk baseret DBA og BI-udvikler med mere end ti års erfaring i at arbejde med SQL Server, Oracle og MySQL.Se alle mine tips
- Mere tips til databaseudviklere…