Der er mange store fordele ved at virtualisere din infrastruktur og køre virtuelle ressourcer til at betjene forretningskritiske arbejdsbelastninger. I tilfældet med VMware vSphere giver det mange bemærkelsesværdige funktioner og muligheder, der giver høj tilgængelighed i miljøet samt automatiseret planlægning af arbejdsbelastninger for at sikre den mest effektive brug af hardware og ressourcer i dit vSphere-miljø.
I dette indlæg vil vi tale om to af de centrale funktioner på cluster-niveau i vSphere i virksomheden – vSphere HA og DRS. Du har højst sandsynligt set begge disse to refereret sammen med kørsel af vSphere i virksomheden.
Hvad er vSphere HA og DRS? Hvad gør de?
Hvordan kan du drage fordel af at køre begge dele i dit vSphere-miljø?
Lad os tage et kig på en grundlæggende introduktion til HA og DRS i VMware vSphere og se, hvordan de kan sammenlignes, og hvilke fordele der er ved at bruge dem.
VMware vSphere Clusters
En af de indlysende fordele og bedste praksis, når man bruger VMware vSphere til at køre forretningskritiske arbejdsbelastninger, er at køre en vSphere Cluster.
Hvad er en vSphere Cluster?
En vSphere Cluster er en konfiguration af mere end én VMware ESXi-server, der er aggregeret sammen som en pulje af ressourcer, der bidrager til vSphere Cluster. Ressourcer som f.eks. CPU-compute, hukommelse og i tilfælde af softwaredefineret lagring som f.eks. vSAN, lagring, bidrager hver enkelt ESXi-vært.
Hvorfor er det vigtigt at køre dine forretningskritiske arbejdsbelastninger oven på en vSphere Cluster?
Når man tænker på de fordele, som det giver at køre en hypervisor, giver det mulighed for at køre mere end én server oven på et enkelt sæt fysisk hardware. Virtualisering af arbejdsbelastninger på denne måde giver mange effektivitetsfordele i størrelsesordener sammenlignet med at køre en enkelt server på et enkelt sæt fysisk hardware.
Dette kan imidlertid også blive akilleshælen for en virtualiseret løsning, da virkningen af en hardwarefejl kan påvirke mange flere forretningskritiske tjenester og applikationer. Du kan forestille dig, at hvis du kun har en enkelt VMware ESXi-vært, der kører mange VM’er, vil virkningen af at miste denne enkelte ESXi-vært være enorm.
Det er her, hvor det at køre flere VMware ESXi-værter i en vSphere Cluster virkelig skinner.
Du kan dog spørge dig selv, hvordan det blot at køre flere værter i en klynge forbedrer din højtilgængelighed? Hvordan “ved” en host i vSphere Cluster, om en anden host er gået ned? Er der en særlig mekanisme, der bruges til at tage sig af forvaltningen af høj tilgængelighed af arbejdsbelastninger, der kører på en vSphere Cluster? Ja, det er der. Lad os se.
Hvad er HA i VMware?
VMware indså behovet for at have en mekanisme til at kunne yde beskyttelse mod en fejlslagen ESXi-vært i vSphere Cluster. Med dette behov blev VMware High-Availability (HA) født.
VMware vSphere HA giver følgende fordele:
VMware vSphere HA er omkostningseffektiv og giver mulighed for automatiseret genstart af VM’er og vSphere-værter, når der registreres et servernedbrud eller en fejl i operativsystemet i vSphere-miljøet
Overvåger alle VMware vSphere-værter & VM’er i vSphere Cluster
Giver høj tilgængelighed til de fleste programmer, der kører i virtuelle maskiner, uanset operativsystem og programmer.
Det smukke ved VMwares vSphere HA-løsning, der er implementeret via VMware Cluster, er den enkelhed, hvormed den kan konfigureres. Med få klik gennem en guide-drevet grænseflade kan høj tilgængelighed konfigureres med få klik. Hvordan kan dette sammenlignes med traditionelle “clustering”-teknologier?
Sammenligning af Windows Server Failover Clustering
Windows Server Failover Clustering (WSFC) er blevet den clusteringteknologi, som de fleste tænker på, når de har clusteringteknologi i tankerne. Problemet set med WSFC er, at det kræver en masse specialiseret ekspertise at køre WSFC-tjenester korrekt, især når det drejer sig om opgraderinger, patching og generelle driftsopgaver.
Kontrasterer man vSphere HA med WSFC, er det operationelle overhead minimalt i forhold til WSFC. Der er lille chance for, at HA kan blive konfigureret forkert, da det enten er aktiveret på en klynge eller ej. Med WSFC er der mange overvejelser, der skal gøres, når WSFC konfigureres, for at undgå både konfigurations- og implementeringsfejl. Tænk på følgende:
- Failover clustering kræver applikationer, der understøtter clustering (SQL osv.)
- Failover clustering kræver, at quorum er konfigureret korrekt
- Understøttes ikke af mange ældre operativsystemer og applikationer
- Kræver kompleksitet af klyngenetværksnavne, ressourcer og netværk
Windows Server Failover Clustering annonceres til at give næsten nul nedetid på applikationsniveauet. Men når du tilføjer den ekspertise, der kræves for en velfungerende HA-løsning, sammen med den korrekte implementering af WSFC, kan risiciene begynde at opveje fordelene ved at bruge WSFC til høj tilgængelighed af applikationer og tjenester. Dette gælder især for de fleste organisationer, som måske ikke virkelig har brug for en “nul-nedbrudsløsning”. Derudover skal din applikation være designet til at drage fordel af WSFC og fungere korrekt med WSFC-teknologien.
Mens vSphere HA kræver en genstart af de virtuelle maskiner på en sund vært, når der sker en failover, kræver det ingen installation af yderligere software i de virtuelle gæstemaskiner, ingen komplekse konfigurationer af yderligere klyngeteknologier, og applikationer eller operativsystemer behøver ikke at være designet til at fungere med en bestemt klyngeteknologi.
Legacy-operativsystemer og -programmer har generelt begrænsede evner, når det gælder understøttede teknologier til at levere høj tilgængelighed. Så der kan bogstaveligt talt ikke være nogen native muligheder for at levere failover-funktionalitet i tilfælde af hardwarefejl.
Mekanismen for høj tilgængelighed vSphere HA fungerer og er enkel at implementere, konfigurere og administrere. Derudover er dette en teknologi, der er velafprøvet i tusindvis af VMware-kundemiljøer, så den har en stabil og lang historie med vellykkede implementeringer.
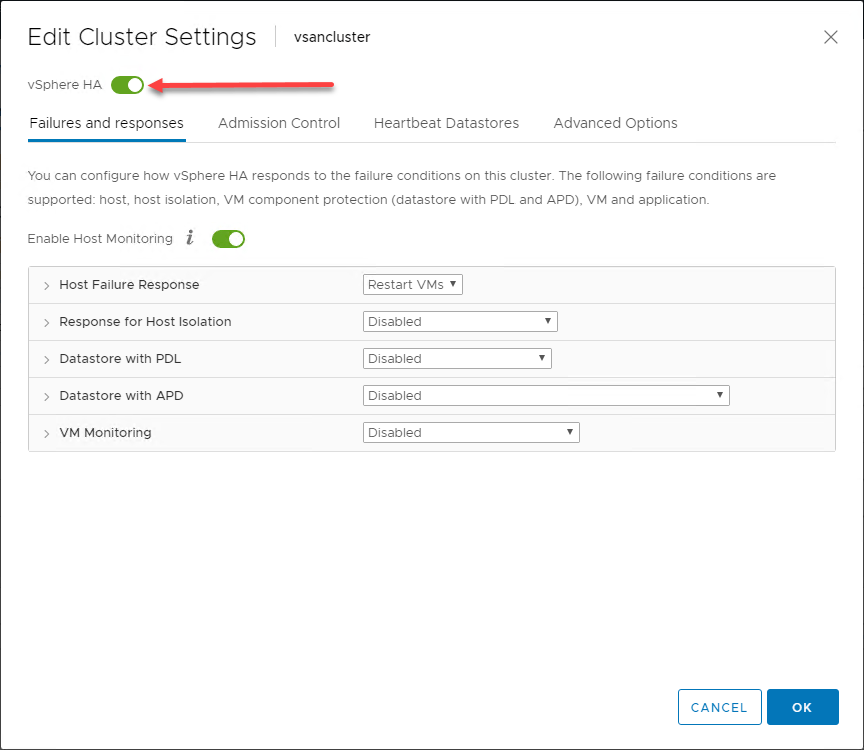
Generel oversigt over vSphere HA-adfærd
Ved hjælp af de fordele, der gives til ESXi-værterne i en vSphere Cluster, implementerer vSphere HA i sin mest grundlæggende form en overvågningsmekanisme mellem værterne i vSphere Cluster’en. Overvågningsmekanismen giver mulighed for at fastslå, om en vært i vSphere Cluster har fejlet.
I infografikken nedenfor har en vSphere Cluster med to knudepunkter oplevet en fejl på en af ESXi-værterne i vSphere Cluster’en. vSphere Cluster har vSphere HA aktiveret på klyngeniveau.
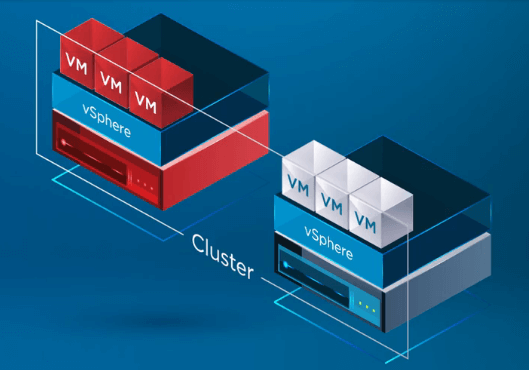
Når vSphere HA erkender, at en vært i vSphere Cluster er fejlslagen, flytter HA-processen registreringen af VM’er fra den fejlslagne vært over til en sund vært.
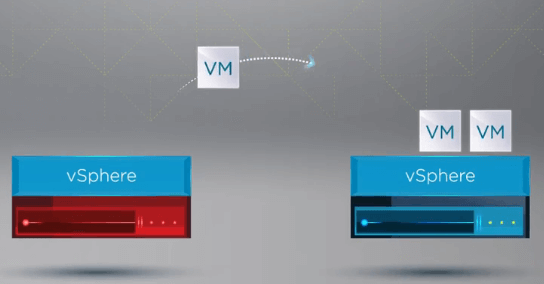
Når VM’erne er registreret på en sund vært, genstarter vSphere HA alle VM’er fra den fejlslagne vært på en sund ESXi-vært i klyngen, hvor VM’erne blev genregistreret. Den eneste nedetid, der opstår, er ved genstarten af de virtuelle maskiner på en sund vært i vSphere-klyngen.
VSphere HA Technical Overview
Forudsætninger for vSphere HA
Du undrer dig måske over, hvilke underliggende forudsætninger der kan være nødvendige for, at vSphere HA kan fungere. Skal du blot bruge en VMware Cluster for at aktivere HA? I modsætning til Windows Server Failover Clustering er der kun nogle få krav, der skal være på plads, for at HA kan fungere.
Krav:
- Mindst to ESXi-værter
- Mindst 4 GB hukommelse konfigureret på hver vært
- vCenter Server
- vSphere Standard-licens
- Delt lagring til VM’er
- Pingable gateway eller en anden pålidelig netværksknude
Hvis du bemærker, er der ingen quorum-komponent påkrævet, ingen kompleks netværksnavngivning involveret og ingen andre særlige klyngeressourcer, der skal være på plads.
Læs mere: Sådan konfigureres en vSphere High Availability Cluster
VMware vSphere HA Master vs. underordnede hosts
Når du aktiverer vSphere HA i en klynge, udpeges en bestemt host i vSphere Cluster som master for vSphere HA. De resterende ESXi-værter i vSphere Cluster er konfigureret som underordnede værter i vSphere HA-konfigurationen.
Hvilken rolle spiller den vSphere HA ESXi-vært, der er udpeget som master? vSphere HA-masterknuden:
- Overvåger tilstanden af de underordnede slaveværter – Hvis den underordnede vært fejler eller er utilgængelig, identificerer masterværten, hvilke VM’er der skal genstartes
- Overvåger strømtilstanden for alle VM’er, der er beskyttet. Hvis en VM fejler, sikrer master vSphere HA-knuden, at VM’en genstartes. vSphere HA-masteren bestemmer, hvor VM-genstarten finder sted (hvilken ESXi-vært).
- Holder styr på alle de klyngeværter og VM’er, der er beskyttet af vSphere HA
- Er udpeget som mediator mellem vSphere Cluster og vCenter Server. HA-masteren rapporterer klyngens tilstand til vCenter og leverer forvaltningsgrænsefladen til klyngen for vCenter Server
- Kan selv køre VM’er og overvåge status for VM’er
- Lagerer beskyttede VM’er i klyngens datastores
vSphere HA-underordnede værter:
- Kører virtuelle maskiner lokalt
- Overvåger køretidstilstandene for de virtuelle maskiner i vSphere Cluster
- Rapporterer statusopdateringer til vSphere HA-masteren
Masterhostvalg og masterfejl
Hvordan vælges vSphere HA-masterværten? Når vSphere HA er aktiveret for en klynge, deltager alle aktive værter (ingen vedligeholdelsestilstand osv.) i valget af masterværten. Hvis den valgte mastervært fejler, finder der et nyt valg sted, hvor en ny master HA-vært vælges til at udfylde denne rolle.
VMware vSphere HA Cluster Failure Types
I en vSphere HA-aktiveret klynge er der tre typer af fejl, der kan ske for at udløse en vSphere HA failover-hændelse. Disse værtsfejltyper er:
- Fejl – En fejl er intuitivt set det, du tror. En vært er holdt op med at fungere på en eller anden måde på grund af hardware eller andre problemer.
- Isolation – Isolationen af en vært sker som regel på grund af en netværkshændelse, der isolerer en bestemt vært fra de andre værter i vSphere HA-klyngen.
- Partitionering – En partitionshændelse er kendetegnet ved, at en underordnet vært mister netværksforbindelsen til masterværten i vSphere HA-klyngen.
Hjertestop, detektion af fejl og fejlhandlinger
Hvordan afgør masterknuden, om der er en fejl på en bestemt vært?
Der er flere forskellige mekanismer, som masterknuden bruger til at afgøre, om en vært har fejlet:
- Masterknuden udveksler netværkshjertebeats med de andre værter i klyngen hvert sekund.
- Når netværkshjertebeatet er mislykkedes, kontrollerer masterværten for kontrol af værtens levedygtighed.
- Kontrollen af værtens levedygtighed bestemmer, om den underordnede vært udveksler hjertebeats med en af datastorerne. Derefter sender den ICMP-pings til dens administrations-IP-adresser
- Hvis direkte kommunikation med HA-agenten på en underordnet vært fra hovedværten ikke er mulig, og ICMP-pings til administrationsadressen mislykkes, betragtes værten som mislykket, og VM’erne genstartes på en anden vært.
- Hvis det konstateres, at den underordnede vært udveksler hjerteslag med datastoren, antager hovedværten, at værten befinder sig i en netværkspartition eller er netværksisoleret. I dette tilfælde overvåger masterhost’en blot værten og VM’erne
- Netværksisolation er den begivenhed, hvor en underordnet vært kører, men ikke længere kan ses fra et HA-administrationsagentperspektiv på administrationsnetværket. Hvis en vært holder op med at se denne trafik, forsøger den at pinge klyngeisolationsadresserne. Hvis denne pingfejl mislykkes, erklærer værten, at den er isoleret fra netværket
- I dette tilfælde overvåger masterknuden de VM’er, der kører på den isolerede vært. Hvis VM’erne slukker på den isolerede vært, genstarter masterknuden VM’erne på en anden vært
Datastore Heartbeating
Som nævnt ovenfor er en af de målinger, der bruges til at bestemme fejldetektion, datastore heartbeating. Hvad er dette præcist? VMware vCenter vælger et foretrukket sæt af datastores til heartbeating. Derefter opretter vSphere HA en mappe ved roden af hver datastore, som bruges både til datastore heartbeating og til at holde styr på listen over beskyttede VM’er. Denne mappe hedder .vSphere-HA.
Der er en vigtig bemærkning, der skal huskes vedrørende vSAN-datastores. Et vSAN-datastore kan ikke bruges til datastore heartbeating. Hvis du kun har et vSAN-datastore til rådighed, kan der ikke bruges heartbeat-datastores.
- VM- og programovervågning
En anden ekstremt kraftfuld funktion i vSphere HA er muligheden for at overvåge individuelle virtuelle maskiner via VMware Tools og genstarte virtuelle maskiner, der ikke reagerer på VMware Tools-hardbeats. Programovervågning kan genstarte en VM, hvis hjerteslagene for et program, der kører, ikke modtages.
- VM-overvågning – Med VM-overvågning bruger VM-overvågningstjenesten VMware Tools til at fastslå, om hver enkelt VM kører ved at kontrollere både hjerteslag og disk I/O, der genereres af VMware Tools. Hvis disse kontroller mislykkes, fastslår VM Monitoring-tjenesten, at gæstestyresystemet højst sandsynligt er mislykkedes, og den virtuelle maskine genstartes. Den ekstra disk I/O-kontrol er med til at undgå unødvendige VM-nulstillinger, hvis VM’er eller programmer stadig fungerer korrekt.
Programovervågning – Programovervågningsfunktionen aktiveres ved at få det relevante SDK fra en tredjepartssoftwareleverandør, der gør det muligt at opsætte tilpassede hjerteslag for de programmer, der skal overvåges af vSphere HA-processen. Ligesom VM-overvågningsprocessen nulstilles VM’en, hvis der ikke længere modtages hjerteslag for applikationer, hvis der ikke længere modtages hjerteslag for applikationer.
Både disse overvågningsfunktioner kan konfigureres yderligere med overvågningsfølsomhed og også maksimale nulstillinger pr. VM for at undgå at nulstille VM’er gentagne gange på grund af softwarefejl eller falsk positive fejl.
VMware vSphere HA er en fantastisk måde at sikre, at din vSphere Cluster giver meget robust høj tilgængelighed for at beskytte mod generelle værtsfejl på ESXi-værter i din vSphere Cluster.
Hvad med at sikre effektiv udnyttelse af ressourcerne i din vSphere Cluster? Lad os tage et kig på den næste vSphere Cluster-tilstand for at sikre effektiv udnyttelse af dine vSphere Cluster-ressourcer og -kapacitet.
Hvad er DRS i VMware?
VMware Distributed Resource Scheduler (DRS) er en virkelig kraftfuld funktion, når du kører vSphere Clusters. Den giver planlægning og belastningsudligning på tværs af en vSphere Cluster. VMware DRS er den funktion, der findes i vSphere Clusters, og som sikrer, at virtuelle maskiner, der kører i dit vSphere-miljø, får de ressourcer, de har brug for, for at kunne køre effektivt og virkningsfuldt.
VM’er er generelt underlagt DRS tidligt i livet, da DRS fra deres første tænding i en DRS-aktiveret klynge placerer de virtuelle maskiner på den bedste vært, der er konfigureret til at levere de nødvendige ressourcer til den virtuelle maskine, så snart de er tændt. Desuden bestræber DRS sig på at holde vSphere-klynger afbalancerede ud fra et ressourceforbrugsperspektiv.
Selv om en vSphere Cluster er balanceret på et bestemt tidspunkt, kan VM’er blive flyttet rundt eller ændres på en sådan måde, at der kan snige sig en ubalance af klyngeressourcer tilbage i miljøet. Når klynger bliver ubalancerede, kan det være skadeligt for den samlede ydeevne for virtuelle maskiner, der kører i en vSphere Cluster.
Som standard kører DRS automatisk på en vSphere-klynge hvert femte minut for at bestemme balancen i en vSphere Cluster og se, om der skal foretages ændringer for at gøre en mere effektiv udnyttelse af ressourcerne.
VMware DRS-krav
For at drage fordel af VMware DRS er der flere krav, der skal være opfyldt for at sikre, at du kan drage fordel af Distributed Resource Scheduler-funktionaliteten. Disse omfatter:
- En klynge af ESXi-værter
- vCenter Server
- Enterprise Plus-licens
- vMotion er påkrævet for automatisk belastningsudligning
Læs mere: Sådan konfigureres en vSphere DRS Cluster
VMware DRS Actions
Når VMware DRS kører på en vSphere Cluster hvert femte minut, fastslås det, om der er nogen ubalancer, der findes i klyngen. Hvis det er tilfældet, udføres der en vMotion for at flytte udpegede VM’er fra en ESXi-vært til en anden.
Hvordan bestemmer DRS helt præcist, om virtuelle maskiner er bedre egnet på en ESXi-vært eller en anden?
DRS kører en særlig algoritme for at bestemme den rigtige ESXi-vært, der skal huse en bestemt VM. Når en VM tændes, tager denne algoritme hensyn til ressourcefordelingen på tværs af vSphere Cluster, efter at den sikrer, at der ikke er nogen overtrædelser af begrænsninger, hvis en bestemt VM placeres på en bestemt ESXi-vært.
Dertil kommer, at der tages hensyn til behovet for selve VM’en, så VM’en forhåbentlig aldrig vil blive udsultet for ressourcer, når den tændes. Hvad er inkluderet i VM-behovet? En VM’s efterspørgsel omfatter den mængde ressourcer, der er nødvendige for at køre.
- For CPU-behovet beregnes dette på baggrund af den mængde CPU, som VM’en i øjeblikket bruger
- For hukommelse beregnes behovet på baggrund af formlen: For hukommelse til VM-hukommelse: For hukommelse er efterspørgslen baseret på følgende formel: VM-hukommelsebehov = Funktion(Aktiv hukommelse brugt, Swapped, Shared) + 25 % (ledig forbrugt hukommelse). Dette viser, at DRS-hukommelsesbalancen hovedsageligt er baseret på en VM’s aktive hukommelsesforbrug, mens der tages hensyn til en lille mængde ledig forbrugt hukommelse som en stødpude for en eventuel stigning i arbejdsbyrden.
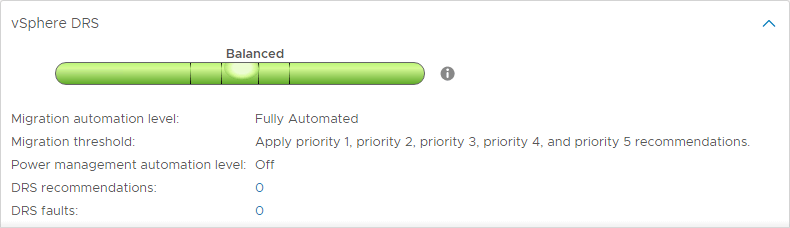
DRS automatiseringsniveauer
En af de interessante funktioner i DRS er DRS’s automatiseringsniveauer. Mens DRS fortsat scanner vSphere Cluster og giver anbefalinger hvert 5. minut, kan du bestemme, om DRS er i stand til at gennemføre sine anbefalinger automatisk eller kun foreslå ændringer, der bør foretages. DRS har tre DRS automatiseringsniveauer. Disse omfatter:
- Fuldt automatiseret – I den fuldt automatiserede tilgang anvender DRS både anbefalingerne for den indledende placering og belastningsbalancering automatisk
- Delvist automatiseret – Med delvis automatisering anvender DRS kun anbefalinger for den indledende placering af VM’er
- Manuel – I manuel tilstand, skal du anvende anbefalingerne for både første placering og anbefalinger til belastningsbalancering
DRS Migration Thresholds
DRS indeholder en anden meget nyttig indstilling til at styre mængden af ubalance, der vil blive tolereret, før DRS’s anbefalinger vil blive foretaget. Der er fem DRS-migreringstærskelværdier til at styre den mængde ubalance, der tolereres.
Der er et interval fra 1 (mest konservativ) til 5 (mest aggressiv).
Med mere aggressive indstillinger tolererer DRS mindre ubalance i en klynge. Jo mere konservativ, jo mere tolererer DRS ubalance.

VMware DRS VM/Host-regler
Der findes en yderst nyttig funktion, når du bruger VMware DRS til at styre placeringen af VM’er i dine vSphere DRS-aktiverede klynger. VM/Host-reglerne giver dig mulighed for at køre specifikke VM’er på specifikke ESXi-værter. Du kan på en måde tænke på dette som affinitetsregler.
Med VM/Host-reglerne kan du:
- Holde virtuelle maskiner sammen
- Separere virtuelle maskiner
- Binde virtuelle maskiner til bestemte værter
- Binde virtuelle maskiner til virtuelle maskiner
Nedenfor er vist et eksempel på oprettelse af en VM/Host-regel for virtuelle maskiner og ESXi-værter.
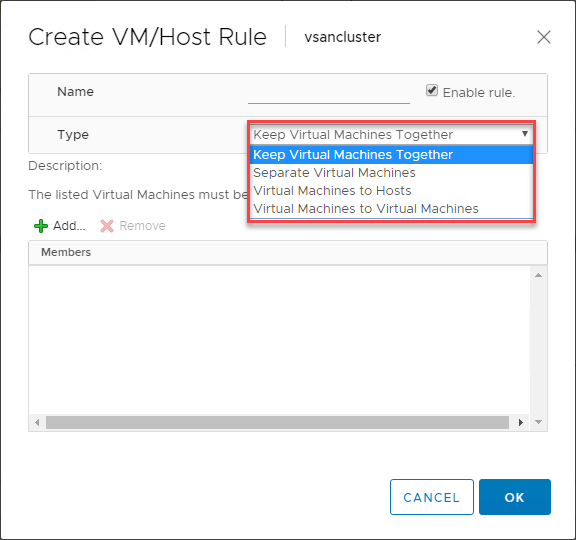
Hvilken type anvendelsestilfælde findes der for disse VM/Host-regler? En af de klassiske anvendelsestilfælde, der findes, er med domænecontrollere. Generelt set, hvis du kører alle dine domænecontrollere i et virtualiseret miljø som f.eks. en vSphere Cluster, vil du gerne sikre dig, at du har dine virtuelle domænecontroller-maskiner adskilt fra hinanden i klyngen. På denne måde har du, hvis en ESXi-vært går ned sammen med en af dine domænecontrollere, stadig en domænecontroller, der er underlagt en regel om separate virtuelle maskiner, som holder den væk fra den samme vært som en anden DC.
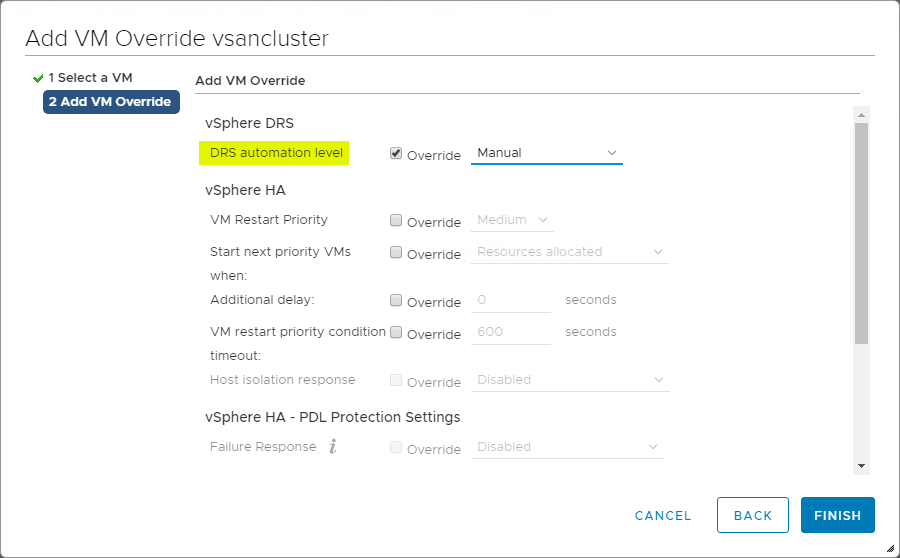
VM-overrides for DRS
VSphere Cluster giver stor granularitet for operationer, der påvirker individuelle VM’er i vSphere Cluster. Du kan oprette VM-overrides til at tilsidesætte globale indstillinger, der er indstillet på klyngeniveau for HA og DRS, for at definere mere specifikke indstillinger for hver enkelt VM.
CPU- og hukommelsesudnyttelsesoversigt
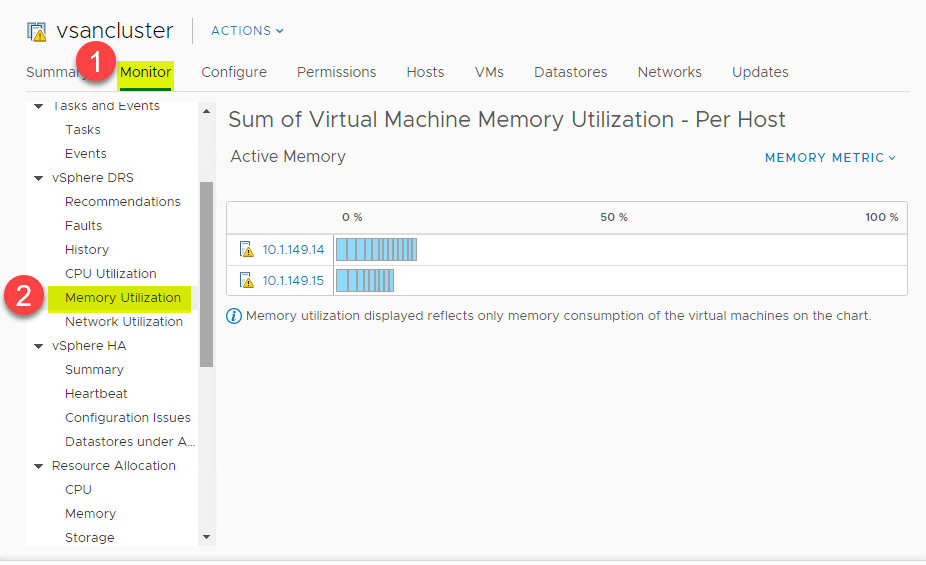
DRS giver et fantastisk overblik på højt niveau over CPU-udnyttelsesoversigten over CPU-ressourcerne for ESXi-værter i vSphere Cluster. Naviger til > Indstillinger > Overvågning > vSphere DRS > CPU-udnyttelse.
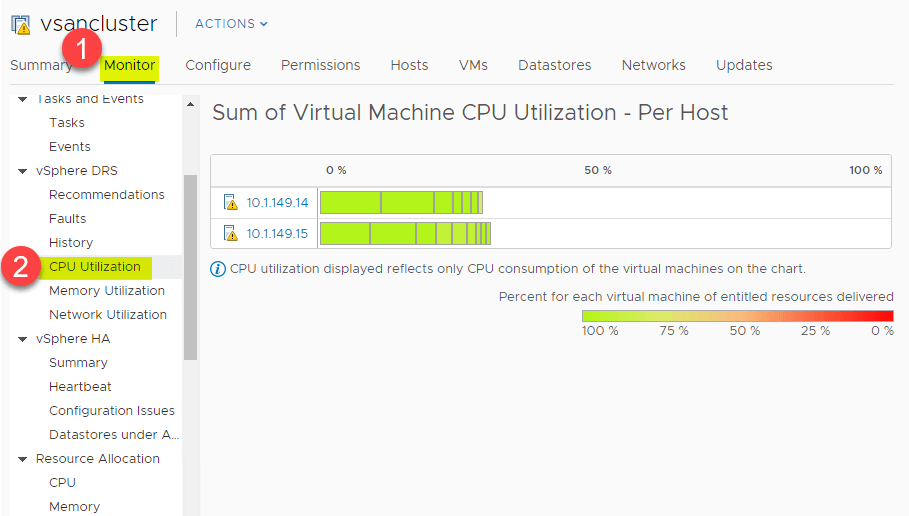
Det samme overblik på højt niveau kan også ses for hukommelsesforbruget. Naviger til > Indstillinger > Overvågning > vSphere DRS > Hukommelsesudnyttelse
Det bedste fra to verdener
Er VMware vSphere HA og VMware DRS konkurrerende teknologier?
Nej, det er de ikke. Faktisk anbefales det stærkt at bruge både vSphere HA og VMware DRS sammen for at kombinere automatisk failover med load balancing-funktioner og -funktioner. Dette resulterer i et meget mere modstandsdygtigt og afbalanceret vSphere-miljø.
Hvis der opstår fejl på en ESXi-vært, genstarter vSphere HA de virtuelle maskiner på de resterende sunde værter i en vSphere Cluster. Så den første prioritet er naturligvis tilgængeligheden af virtuelle maskinressourcer. VMware DRS vil derefter køre og bestemme, om der er nogen ubalance mellem de ESXi-værter, der kører arbejdsbelastningerne, og vil komme med anbefalinger til at løse eventuelle ubalancer i klyngen baseret på den konfigurerede migrationstærskel. Baseret på automatiseringsniveauet vil disse anbefalinger enten blive udført automatisk eller kun blive anbefalet, hvis de ikke er fuldt automatiserede.
Sluttanker om VMware vSphere HA og DRS
Det anbefales kraftigt at køre både VMware vSphere HA og DRS i en vSphere-klynge i produktion. Brug af begge teknologier hjælper med at gøre dine arbejdsbelastninger meget tilgængelige og sikrer, at de løbende har de nødvendige ressourcer baseret på VM’ens krav til CPU/hukommelse.
Forståelse af, hvordan begge mekanismer fungerer, hjælper dig som vSphere-administrator med at udnytte begge teknologier på den bedst mulige måde og i overensstemmelse med bedste praksis. Blandt de fordele, som begge teknologier giver, er det, at hver funktion er ekstremt nem at aktivere og konfigurere. Med et par enkle klik i egenskaberne for dine vSphere-klynger kan du hurtigt begynde at drage fordel af disse tilgængelige funktioner på klyngeniveau.
Følg vores Twitter- og Facebook-feeds for at få nye udgivelser, opdateringer, indsigtsfulde indlæg og meget mere.