Overblik
- Lær at fortolke Bias og Variance i en given model.
- Hvad er forskellen mellem Bias og Varians?
- Hvordan man opnår Bias og Variance Tradeoff ved hjælp af Machine Learning workflow
Indledning
Lad os tale om vejret. Det regner kun, hvis det er lidt fugtigt, og det regner ikke, hvis det blæser, er varmt eller fryser. Hvordan vil du i dette tilfælde træne en prædiktiv model og sikre, at der ikke er fejl i vejrudsigten? Du kan sige, at der er mange læringsalgoritmer at vælge imellem. De er forskellige på mange måder, men der er en stor forskel på, hvad vi forventer, og hvad modellen forudsiger. Det er begrebet Bias and Variance Tradeoff.
Usuelt undervises der i Bias and Variance Tradeoff gennem tætte matematiske formler. Men i denne artikel har jeg forsøgt at forklare Bias og Variance så enkelt som muligt!
Mit fokus vil være at spinne dig igennem processen med at forstå problemformuleringen og sikre, at du vælger den bedste model, hvor Bias- og Variance-fejlene er minimale.
Dertil har jeg taget det populære Pima Indians Diabetes-datasæt op. Datasættet består af diagnostiske målinger af voksne kvindelige patienter af indfødt indiansk Pima-arv. For dette datasæt vil vi fokusere på variablen “Outcome” – som angiver, om patienten har diabetes eller ej. Det er tydeligvis et binært klassifikationsproblem, og vi vil dykke direkte ned og lære, hvordan vi skal gribe det an.
Hvis du er interesseret i dette og data science koncepter og ønsker at lære praktisk henvises til vores kursus- Introduktion til Data Science
Indholdsfortegnelse
- Evaluering af en Machine Learning model
- Problemformulering og primære trin
- Hvad er bias?
- Hvad er Varians?
- Bias-Varians Tradeoff
Evaluering af din Machine Learning-model
Det primære formål med Machine Learning-modellen er at lære fra de givne data og generere forudsigelser baseret på det mønster, der observeres under læringsprocessen. Vores opgave slutter dog ikke her. Vi skal løbende foretage forbedringer af modellerne på baggrund af den type resultater, som den genererer. Vi kvantificerer også modellens ydeevne ved hjælp af målinger som nøjagtighed, gennemsnitlig kvadreret fejl (MSE), F1-score osv. og forsøger at forbedre disse målinger. Dette kan ofte blive vanskeligt, når vi skal bevare modellens fleksibilitet uden at gå på kompromis med dens korrekthed.
En overvåget maskinlæringsmodel har til formål at træne sig selv på inputvariablerne(X) på en sådan måde, at de forudsagte værdier(Y) er så tæt på de faktiske værdier som muligt. Denne forskel mellem de faktiske værdier og de forudsagte værdier er fejlen, og den bruges til at evaluere modellen. Fejlen for enhver overvåget Machine Learning-algoritme består af 3 dele:
- Biasfejl
- Variansfejl
- Støjen
Mens støjen er den ureducerbare fejl, som vi ikke kan eliminere, er de to andre i.Dvs. bias og varians er reducerbare fejl, som vi kan forsøge at minimere så meget som muligt.
I de følgende afsnit vil vi behandle bias-fejlen, varians-fejlen og afvejningen mellem bias og varians, som vil hjælpe os med at vælge den bedste model. Og det spændende er, at vi vil dække nogle teknikker til at håndtere disse fejl ved hjælp af et eksempeldatasæt.
Problemformulering og primære trin
Som forklaret tidligere har vi taget Pima Indians Diabetes-datasættet op og dannet et klassifikationsproblem på det. Lad os starte med at måle datasættet og observere, hvilken type data vi har med at gøre. Det gør vi ved at importere de nødvendige biblioteker:
Nu vil vi indlæse dataene i en dataramme og observere nogle rækker for at få indsigt i dataene.
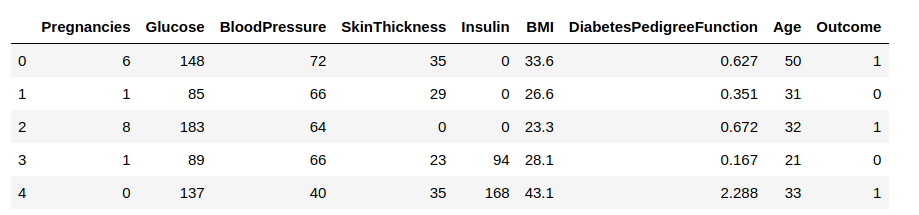
Vi skal forudsige kolonnen ‘Outcome’ (resultat). Lad os adskille den og tildele den til en målvariabel ‘y’. Resten af datarammen vil være sættet af inputvariabler X.
Lad os nu skalere forudsigelsesvariablerne og derefter adskille trænings- og testdataene.
Da resultaterne er klassificeret i binær form, vil vi bruge den enkleste K-nearest neighbor classifier(Knn) til at klassificere, om patienten har diabetes eller ej.
Men hvordan bestemmer vi værdien af ‘k’?
- Måske skal vi bruge k = 1, så vi får meget gode resultater på vores træningsdata? Det kan måske fungere, men vi kan ikke garantere, at modellen vil give lige så gode resultater på vores testdata, da den kan blive for specifik
- Hvad med at bruge en høj værdi af k, f.eks. k = 100, så vi kan tage hensyn til et stort antal nærmeste punkter for også at tage hensyn til de fjerneste punkter? Denne form for model vil imidlertid være for generisk, og vi kan ikke være sikre på, at den har taget hensyn til alle de mulige bidragende træk korrekt.
Lad os tage nogle få mulige værdier af k og tilpasse modellen på træningsdataene for alle disse værdier. Vi vil også beregne træningsresultatet og testresultatet for alle disse værdier.
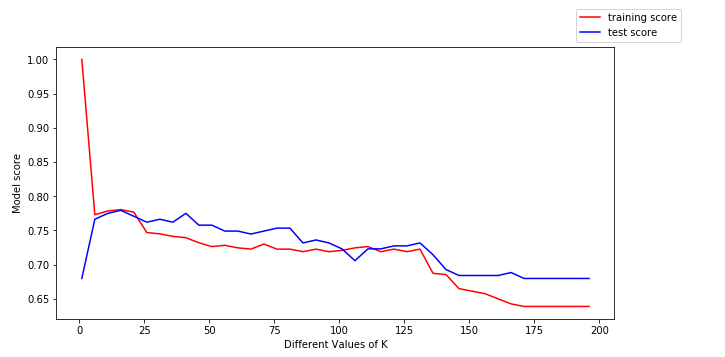
For at få mere indsigt i dette, lad os plotte træningsdataene(med rødt) og testdataene(med blåt).
For at beregne scorerne for en bestemt værdi af k,
![]()
Vi kan drage følgende konklusioner af ovenstående plot:
- For lave værdier af k er træningsscoren høj, mens testscoren er lav
- Da værdien af k stiger, begynder testscoren at stige, og træningsscoren begynder at falde
- Da værdien af k stiger, begynder testscoren at stige, og træningsscoren begynder at falde.
- Hvorimod ved en vis værdi af k er både træningsscoren og testscoren tæt på hinanden.
Det er her, bias og varians kommer ind i billedet.
Hvad er bias?
I de enkleste vendinger er bias forskellen mellem den forudsagte værdi og den forventede værdi. For at forklare det nærmere, foretager modellen visse antagelser, når den træner på de leverede data. Når den introduceres til test-/valideringsdataene, er disse antagelser måske ikke altid korrekte.
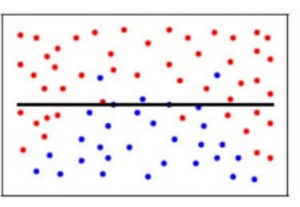
I vores model kan modellen, hvis vi bruger et stort antal nærmeste naboer, helt og holdent beslutte, at nogle parametre slet ikke er vigtige. Den kan f.eks. bare overveje, at Glusoce-niveauet og blodtrykket afgør, om patienten har diabetes. Denne model ville gøre meget stærke antagelser om, at de andre parametre ikke påvirker resultatet. Man kan også se det som en model, der forudsiger en simpel sammenhæng, når datapunkterne klart indikerer en mere kompleks sammenhæng:
Matematisk set, lad inputvariablerne være X og en målvariabel Y. Vi kortlægger forholdet mellem de to ved hjælp af en funktion f.
Derfor,
Y = f(X) + e
Her er “e” fejlen, der er normalfordelt. Målet med vores model f'(x) er at forudsige værdier, der ligger så tæt på f(x) som muligt. Her er modellens Bias:
Bias = E
Som jeg forklarede ovenfor, når modellen foretager generaliseringerne, dvs. når der er en høj biasfejl, resulterer det i en meget forenklet model, der ikke tager særlig godt hensyn til variationerne. Da den ikke lærer træningsdataene særlig godt, kaldes det for Underfitting.
Hvad er en Variance?
I modsætning til bias er Variance, når modellen også tager højde for udsving i dataene, dvs. støjen. Så hvad sker der, når vores model har en høj varians?
Modellen vil stadig betragte variansen som noget, den kan lære af. Det vil sige, at modellen lærer for meget af træningsdataene, så meget, at den, når den konfronteres med nye data (testdata), ikke er i stand til at forudsige nøjagtigt på grundlag af dem.
Matematisk set er variansfejlen i modellen:
Varians-E^2
Da modellen i tilfælde af høj varians lærer for meget af træningsdataene, kaldes det for overfitting.
I forbindelse med vores data, hvis vi bruger meget få nærmeste naboer, svarer det til at sige, at hvis antallet af graviditeter er mere end 3, glukoseniveauet er mere end 78, det diastoliske blodtryk er mindre end 98, hudtykkelsen er mindre end 23 mm osv. for hver funktion….. beslutte, at patienten har diabetes. Alle de andre patienter, der ikke opfylder ovenstående kriterier, er ikke diabetiske. Selv om dette måske er sandt for en bestemt patient i træningssættet, hvad så hvis disse parametre er outliers eller endda er registreret forkert? Det er klart, at en sådan model kan vise sig at være meget dyr!
Dertil kommer, at denne model vil have en høj variansfejl, fordi forudsigelserne af, om patienten er diabetiker eller ej, varierer meget med den type træningsdata, vi giver den. Så selv en ændring af glukoseniveauet til 75 ville resultere i, at modellen forudsiger, at patienten ikke har diabetes.
For at gøre det mere enkelt forudsiger modellen meget komplekse sammenhænge mellem resultatet og de indgående funktioner, når en kvadratisk ligning ville have været tilstrækkelig. Sådan ville en klassifikationsmodel se ud, når der er en høj variansfejl/når der er overfitting:
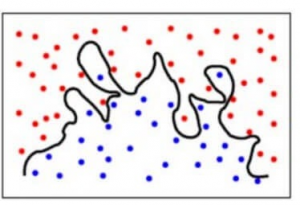
For at opsummere,
- En model med en høj bias-fejl underpasser dataene og gør meget forenklede antagelser om dem
- En model med en høj varians-fejl overpasser dataene og lærer for meget af dem
- En god model er, hvor både bias- og varians-fejl er afbalanceret
Bias-Varians Tradeoff
Hvordan relaterer vi ovenstående begreber til vores Knn-model fra tidligere? Lad os finde ud af det!
I vores model, for eksempel for, k = 1, vil det punkt, der ligger tættest på det pågældende datapunkt, blive taget i betragtning. Her vil forudsigelsen måske være nøjagtig for det pågældende datapunkt, så bias-fejlen vil være mindre.
Derimod vil variansfejlen være høj, da der kun tages hensyn til det ene nærmeste punkt, og dette tager ikke hensyn til de andre mulige punkter. Hvilket scenarie mener du, at dette svarer til? Ja, du tænker rigtigt, det betyder, at vores model er overfitting.
På den anden side vil der for højere værdier af k blive taget hensyn til mange flere punkter, der ligger tættere på det pågældende datapunkt. Dette ville resultere i en højere biasfejl og undertilpasning, da mange punkter tættere på datapunktet tages i betragtning, og den kan således ikke lære de specifikke detaljer fra træningssættet. Vi kan dog tage højde for en lavere variansfejl for testsættene, som har ukendte værdier.
For at opnå en balance mellem bias-fejl og varians-fejl skal vi have en sådan værdi for k, at modellen hverken lærer af støjen (overfit på data) eller laver vidtgående antagelser om dataene(underfit på data). For at gøre det mere enkelt vil en afbalanceret model se således ud:
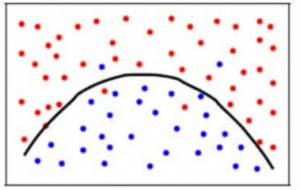
Og selv om nogle punkter klassificeres forkert, passer modellen generelt præcist til de fleste datapunkter. Balancen mellem Bias-fejlen og Varians-fejlen er Bias-Varians Tradeoff.
Det følgende bulls-eye-diagram forklarer tradeoff bedre:
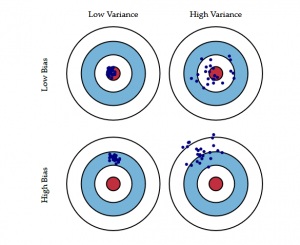
Centret dvs. bull’s eye er det modelresultat, som vi ønsker at opnå, og som perfekt forudsiger alle værdier korrekt. Efterhånden som vi bevæger os væk fra bull’s eye, begynder vores model at lave flere og flere forkerte forudsigelser.
En model med lav bias og høj varians forudsiger punkter, der generelt ligger omkring centrum, men ret langt væk fra hinanden. En model med høj bias og lav varians er ret langt væk fra bull’s eye, men da variansen er lav, er de forudsagte punkter tættere på hinanden.
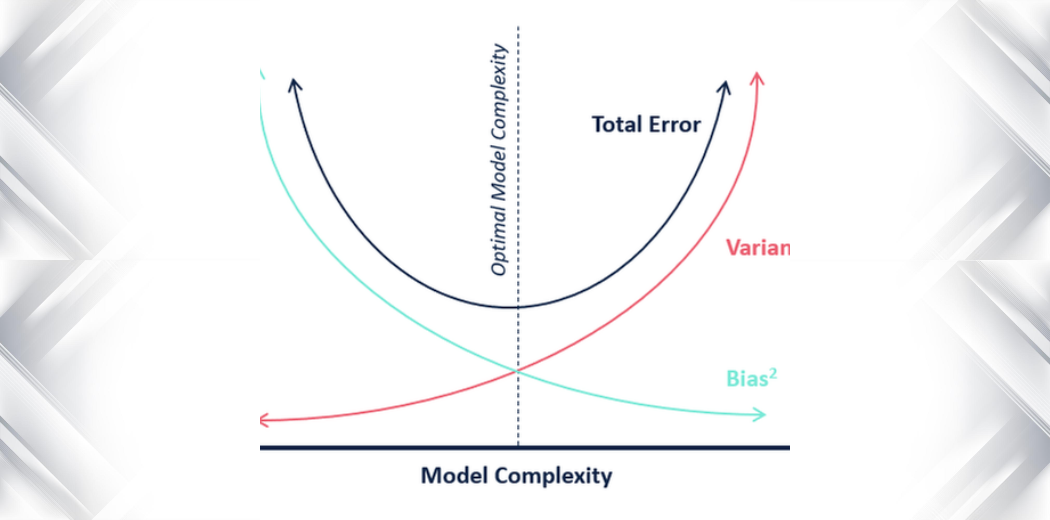
Med hensyn til modellens kompleksitet kan vi bruge følgende diagram til at beslutte os for den optimale kompleksitet af vores model.
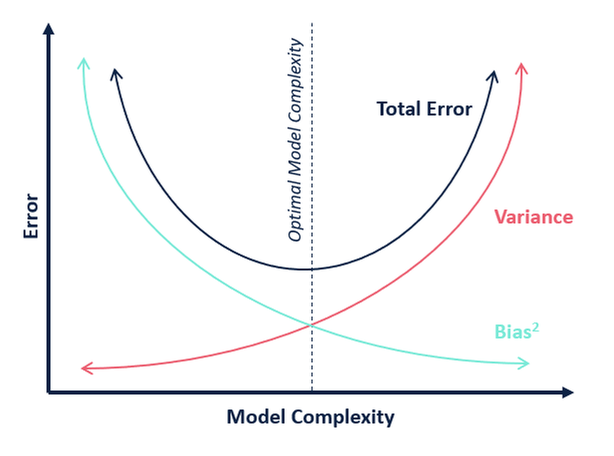
Så, hvad mener du er den optimale værdi for k?
Fra ovenstående forklaring kan vi konkludere, at det k, for hvilket
- det testresultat er det højeste, og
- både testresultatet og træningspointen ligger tæt på hinanden
er den optimale værdi for k. Så selv om vi går på kompromis med en lavere træningsscore, får vi stadig en høj score for vores testdata, hvilket er mere afgørende – testdataene er trods alt ukendte data.
Lad os lave en tabel for forskellige værdier af k for yderligere at bevise dette:
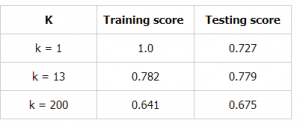
Slutning
For at opsummere har vi i denne artikel lært, at en ideel model vil være en model, hvor både bias-fejlen og variansfejlen er lav. Vi bør dog altid tilstræbe en model, hvor modellens score for træningsdataene ligger så tæt som muligt på modellens score for testdataene.
Der fandt vi ud af, hvordan vi kan vælge en model, der ikke er for kompleks (høj varians og lav bias), hvilket ville føre til overfitting, og heller ikke for simpel(høj bias og lav varians), hvilket ville føre til underfitting.
Bias og varians spiller en vigtig rolle, når vi skal afgøre, hvilken prædiktionsmodel vi skal bruge. Jeg håber, at denne artikel har forklaret begrebet godt.