Přehled
- Naučte se interpretovat Bias a Variance v daném modelu.
- Jaký je rozdíl mezi Bias a Variance?
- Jak dosáhnout Bias a Variance Tradeoff pomocí pracovního postupu strojového učení
Úvod
Povíme si o počasí. Prší, jen když je trochu vlhko, a neprší, když je větrno, horko nebo mráz. Jak byste v tomto případě natrénovali predikční model a zajistili, aby při předpovědi počasí nedocházelo k chybám? Možná si řeknete, že existuje mnoho učebních algoritmů, ze kterých si můžete vybrat. V mnoha ohledech se liší, ale je zde zásadní rozdíl v tom, co očekáváme a co model předpovídá. To je koncept Bias and Variance Tradeoff.
Obvykle se Bias and Variance Tradeoff učí pomocí hutných matematických vzorců. V tomto článku jsem se však pokusil vysvětlit Bias a Variance co nejjednodušeji!
Soustředím se na to, abych vás provedl procesem pochopení zadání problému a zajistil, abyste vybrali nejlepší model, u kterého jsou chyby Bias a Variance minimální.
Pro tento účel jsem si vzal na pomoc populární datovou sadu Pima Indians Diabetes. Datová sada se skládá z diagnostických měření dospělých pacientek indiánského původu Pima. U této datové sady se zaměříme na proměnnou „Outcome“ – která udává, zda pacientka má či nemá cukrovku. Evidentně se jedná o problém binární klasifikace a my se do něj hned ponoříme a naučíme se, jak na to.
Pokud vás tato problematika a koncepty datové vědy zajímají a chcete se je naučit prakticky, podívejte se na náš kurz – Úvod do datové vědy
Obsah
- Vyhodnocení modelu strojového učení
- Zadání problému a primární kroky
- Co je to zkreslení?
- Co je to variance
- Kompromis mezi odchylkou a variací
Vyhodnocení modelu strojového učení
Primárním cílem modelu strojového učení je učit se z daných dat a vytvářet předpovědi na základě vzorce pozorovaného během procesu učení. Tím však náš úkol nekončí. Na základě toho, jaké výsledky generuje, musíme modely neustále vylepšovat. Výkon modelu také kvantifikujeme pomocí metrik, jako je přesnost, střední kvadratická chyba (MSE), skóre F1 atd. a snažíme se tyto metriky zlepšovat. To může být často složité, když musíme zachovat flexibilitu modelu, aniž bychom museli dělat kompromisy v jeho správnosti.
Model strojového učení s dohledem má za cíl trénovat se na vstupních proměnných(X) tak, aby předpovídané hodnoty(Y) byly co nejblíže skutečným hodnotám. Tento rozdíl mezi skutečnými a předpovídanými hodnotami představuje chybu a slouží k vyhodnocení modelu. Chyba jakéhokoli algoritmu strojového učení s dohledem se skládá ze tří částí:
- Bias error
- Variance error
- The noise
Když šum je neredukovatelná chyba, kterou nemůžeme odstranit, ostatní dvě tj.tj. Bias a Variance, jsou redukovatelné chyby, které se můžeme pokusit co nejvíce minimalizovat.
V následujících kapitolách se budeme zabývat chybou Bias, chybou Variance a kompromisem Bias-Variance, který nám pomůže při výběru nejlepšího modelu. A co je zajímavé, budeme se zabývat některými technikami, jak se s těmito chybami vypořádat na příkladu datové sady.
Zadání problému a primární kroky
Jak bylo vysvětleno dříve, vzali jsme datovou sadu Pima Indians Diabetes a vytvořili na ní klasifikační problém. Začněme měřením datové sady a sledujme, s jakými daty máme co do činění. Učiníme tak importem potřebných knihoven:
Nyní načteme data do datového rámce a budeme pozorovat některé řádky, abychom získali náhled na data.
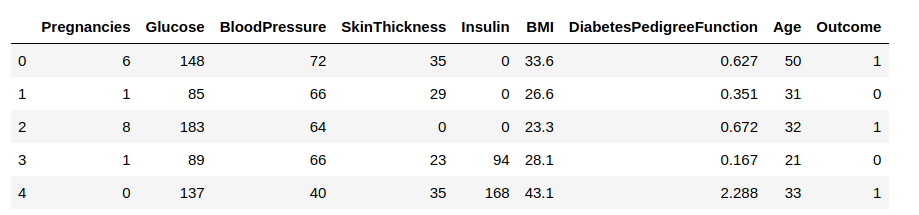
Potřebujeme předpovědět sloupec „Outcome“. Oddělíme jej a přiřadíme cílové proměnné ‚y‘. Zbytek datového rámce bude tvořit soubor vstupních proměnných X.
Nyní provedeme škálování predikčních proměnných a poté oddělíme trénovací a testovací data.
Jelikož jsou výsledky klasifikovány v binárním tvaru, použijeme nejjednodušší klasifikátor K-nejbližší soused(Knn), abychom klasifikovali, zda má pacient cukrovku, nebo ne.
Jak ale rozhodneme o hodnotě ‚k‘?
- Možná bychom měli použít k = 1, abychom získali velmi dobré výsledky na našich trénovacích datech? To by mohlo fungovat, ale nemůžeme zaručit, že model bude stejně dobře fungovat na našich testovacích datech, protože může být příliš specifický
- Co takhle použít vysokou hodnotu k, řekněme třeba k = 100, abychom mohli uvažovat velký počet nejbližších bodů a zohlednit i body vzdálené? Takový model však bude příliš obecný a nemůžeme si být jisti, zda správně zohlednil všechny možné přispívající prvky.
Vezměme několik možných hodnot k a fitujme model na trénovací data pro všechny tyto hodnoty. Pro všechny tyto hodnoty také vypočítáme tréninkové a testovací skóre.
Abychom z toho získali další poznatky, vykreslíme tréninková data(červeně) a testovací data(modře).
Pro výpočet skóre pro konkrétní hodnotu k,
![]()
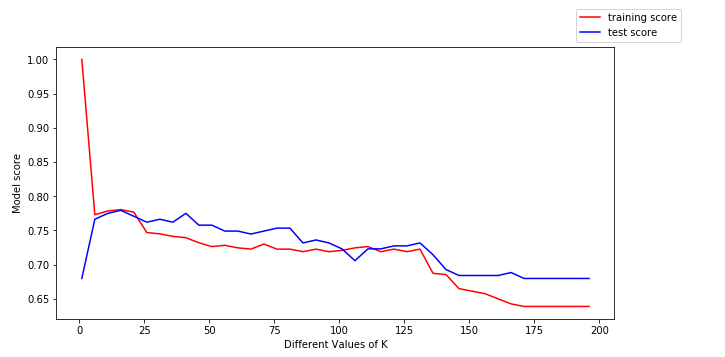
Z výše uvedeného grafu můžeme vyvodit následující závěry:
- Pro nízké hodnoty k je trénovací skóre vysoké, zatímco testovací skóre je nízké
- S rostoucí hodnotou k začíná testovací skóre růst a trénovací skóre klesat.
- Při určité hodnotě k jsou si však jak trénovací, tak testovací skóre blízké.
Tady přichází ke slovu zkreslení a rozptyl.
Co je to zkreslení?
Zjednodušeně řečeno, zkreslení je rozdíl mezi předpovídanou hodnotou a očekávanou hodnotou. Abychom to dále vysvětlili, model při tréninku na poskytnutých datech vychází z určitých předpokladů. Když se zavede na testovací/ověřovací data, nemusí být tyto předpoklady vždy správné.
V našem modelu, pokud použijeme velký počet nejbližších sousedů, může model zcela rozhodnout, že některé parametry nejsou vůbec důležité. Může se například domnívat, že o tom, zda má pacient cukrovku, rozhoduje pouze hladina glukózy a krevní tlak. Tento model by učinil velmi silné předpoklady o tom, že ostatní parametry nemají na výsledek vliv. Můžete si ho také představit jako model předpovídající jednoduchý vztah, když datové body jasně ukazují na složitější vztah:
Matematicky nechť jsou vstupní proměnné X a cílová proměnná Y. Vztah mezi nimi mapujeme pomocí funkce f.
Tedy,
Y = f(X) + e
Tady „e“ je chyba, která je normálně rozdělena. Cílem našeho modelu f'(x) je předpovídat hodnoty co nejblíže f(x). Zde je Bias modelu:
Bias = E
Jak jsem vysvětlil výše, pokud model provádí zobecnění, tj. pokud je chyba biasu vysoká, vzniká velmi zjednodušený model, který příliš nezohledňuje odchylky. Protože se špatně učí z trénovacích dat, nazývá se to Underfitting (nedostatečné přizpůsobení).
Co je to Variance?
Na rozdíl od biasu je Variance, když model bere v úvahu také kolísání v datech, tj. šum. Co se tedy stane, když má náš model vysoký rozptyl?
Model bude stále brát v úvahu rozptyl jako něco, z čeho se může učit. To znamená, že model se z trénovacích dat učí příliš mnoho, a to natolik, že když je konfrontován s novými (testovacími) daty, není schopen na jejich základě přesně předpovídat.
Maticky řečeno, chyba rozptylu v modelu je:
Variance-E^2
Protože v případě vysokého rozptylu se model z trénovacích dat učí příliš mnoho, nazývá se to overfitting.
V kontextu našich dat, pokud použijeme velmi málo nejbližších sousedů, je to jako říci, že pokud je počet těhotenství větší než 3, hladina glukózy větší než 78, diastolický tlak menší než 98, tloušťka kůže menší než 23 mm atd. pro každou funkci….. rozhodnout, že pacient má diabetes. Všichni ostatní pacienti, kteří nesplňují výše uvedená kritéria, nejsou diabetici. To sice může platit pro jednoho konkrétního pacienta v trénovací množině, ale co když jsou tyto parametry odlehlé nebo byly dokonce zaznamenány nesprávně? Je zřejmé, že takový model by se mohl ukázat jako velmi nákladný!“
Navíc by tento model měl vysokou chybu rozptylu, protože předpovědi, zda pacient je či není diabetik, se velmi liší podle druhu trénovacích dat, která mu poskytujeme. Takže i změna hladiny glukózy na 75 by vedla k tomu, že by model předpověděl, že pacient nemá cukrovku.
Pro zjednodušení, model předpovídá velmi složité vztahy mezi výsledkem a vstupními funkcemi, zatímco by stačila kvadratická rovnice. Takto by vypadal klasifikační model při vysoké chybě rozptylu/při nadměrném přizpůsobení:
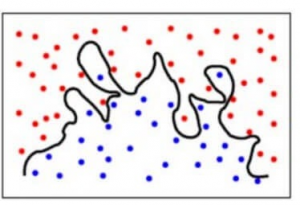
Abychom to shrnuli,
- Model s vysokou chybou bias nedostatečně vyhovuje datům a vytváří na nich velmi zjednodušené předpoklady
- Model s vysokou chybou variance příliš vyhovuje datům a příliš se z nich učí
- Dobrý model je takový, kde jsou chyby bias i variance vyvážené
Bias-Variance Tradeoff
Jak výše uvedené pojmy vztáhneme k našemu modelu Knn z dřívějška? Pojďme to zjistit!
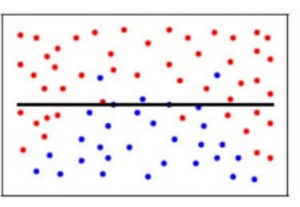
V našem modelu, řekněme pro, k = 1, bude uvažován bod, který je nejblíže danému datovému bodu. Zde může být předpověď pro tento konkrétní datový bod přesná, takže chyba zkreslení bude menší.
Rozptylová chyba však bude vysoká, protože se uvažuje pouze jeden nejbližší bod, a to bez ohledu na ostatní možné body. Jakému scénáři to podle vás odpovídá? Ano, uvažujete správně, to znamená, že náš model je nadměrně přizpůsobený.
Na druhou stranu pro vyšší hodnoty k se bude uvažovat mnohem více bodů bližších k danému datovému bodu. To by mělo za následek vyšší chybu zkreslení a nedostatečné přizpůsobení, protože se uvažuje mnoho bodů blíže k datovému bodu, a proto se nemůže naučit specifika z trénovací množiny. Můžeme však počítat s nižší chybou rozptylu pro testovací množinu, která má neznámé hodnoty.
Pro dosažení rovnováhy mezi chybou zkreslení a chybou rozptylu potřebujeme takovou hodnotu k, aby se model neučil ze šumu (overfit na datech) ani nevytvářel přehnané předpoklady o datech(underfit na datech). Pro zjednodušení by vyvážený model vypadal takto:
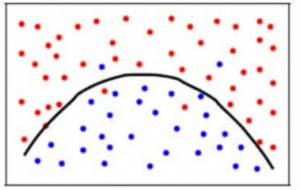
Přestože jsou některé body klasifikovány nesprávně, model obecně přesně odpovídá většině datových bodů. Rovnováha mezi chybou Bias a chybou Variance je kompromis Bias-Variance.
Následující diagram býčího oka vysvětluje kompromis lépe:
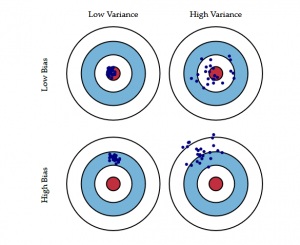
Střed, tj. býčí oko, je výsledek modelu, kterého chceme dosáhnout a který dokonale správně předpovídá všechny hodnoty. Jak se od býčího oka vzdalujeme, náš model začíná dělat stále více chybných předpovědí.
Model s nízkým zkreslením a vysokým rozptylem předpovídá body, které jsou obecně kolem středu, ale dost daleko od sebe. Model s vysokým zkreslením a nízkým rozptylem je docela daleko od středu, ale protože rozptyl je nízký, předpovídané body jsou blíže k sobě.
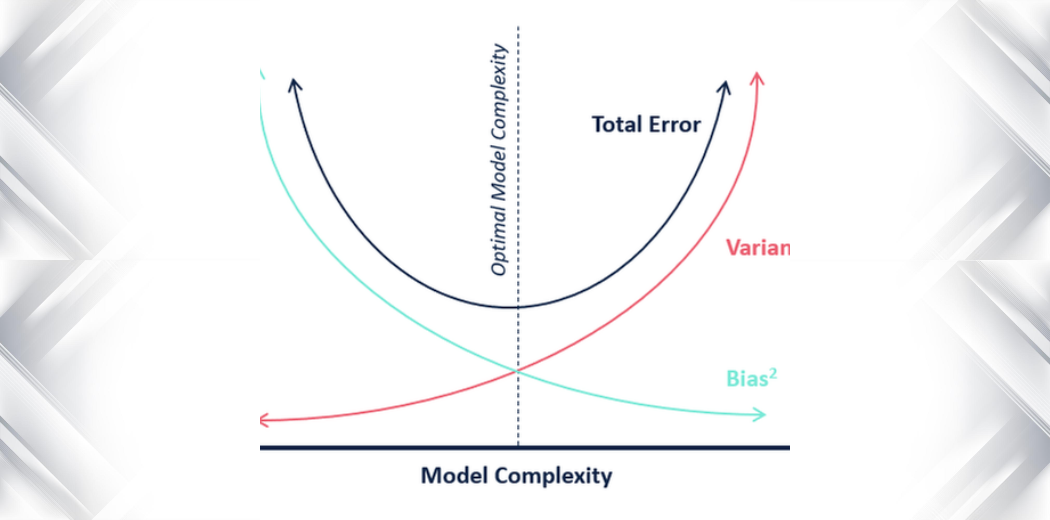
Pokud jde o složitost modelu, můžeme k rozhodnutí o optimální složitosti našeho modelu použít následující diagram.
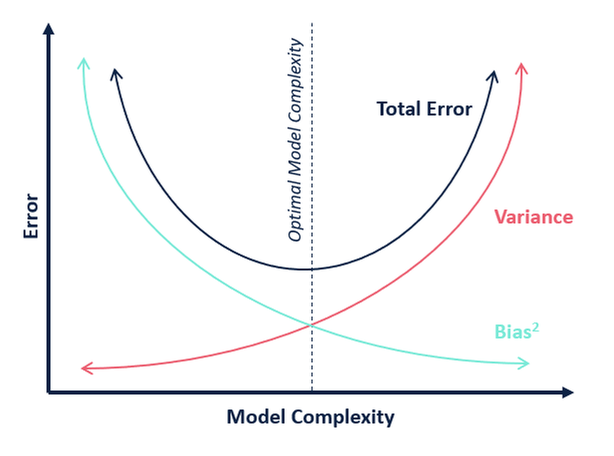
Takže, jaká je podle vás optimální hodnota k?
Z výše uvedeného vysvětlení můžeme dojít k závěru, že k, pro které
- je testovací skóre nejvyšší a
- jak testovací, tak trénovací skóre jsou si blízké
je optimální hodnota k. Takže i když děláme kompromisy s nižším trénovacím skóre, stále získáváme vysoké skóre pro naše testovací data, což je rozhodující – testovací data jsou přece jen neznámá data.
Udělejme si tabulku pro různé hodnoty k, abychom to dále dokázali:
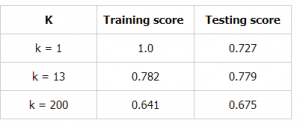
Závěr
Shrneme-li to, v tomto článku jsme se dozvěděli, že ideální model bude takový, kde chyba zkreslení i chyba rozptylu jsou nízké. Vždy bychom se však měli snažit o model, jehož skóre modelu pro trénovací data se co nejvíce blíží skóre modelu pro testovací data.
Tady jsme přišli na to, jak vybrat model, který není příliš složitý (vysoký rozptyl a nízký bias), což by vedlo k nadměrnému přizpůsobení, a ani příliš jednoduchý(vysoký bias a nízký rozptyl), což by vedlo k nedostatečnému přizpůsobení.
Bias a rozptyl hrají důležitou roli při rozhodování, který predikční model použít. Doufám, že tento článek tento koncept dobře vysvětlil.