Molekulová hmotnost je jedním z nejdůležitějších aspektů vlastností polymerů. Všechny molekuly mají samozřejmě své vlastní molekulové hmotnosti. Mohlo by se zdát zřejmé, že molekulová hmotnost je základní vlastností každé molekulové sloučeniny. U polymerů nabývá molekulová hmotnost dalšího významu. To proto, že polymer je velká molekula složená z opakujících se jednotek, ale kolik opakujících se jednotek? Třicet? Tisíc? Milion? Kterákoli z těchto možností by mohla být stále považována za zástupce stejného materiálu, ale jejich molekulové hmotnosti by se velmi lišily, a tím i jejich vlastnosti.
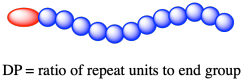
Tato variabilita zavádí některé jedinečné aspekty molekulové hmotnosti polymerů. Protože polymery jsou sestaveny z menších molekul, závisí délka (a tedy i molekulová hmotnost) polymerního řetězce na počtu monomerů, které byly do polymeru zakomponovány. Počet zřetězených monomerů v průměrném polymerním řetězci v materiálu se nazývá stupeň polymerace (DP).

Všimněte si toho klíčového bodu: je to pouze průměr. V každém daném materiálu budou některé řetězce, do kterých bylo přidáno více monomerů, a některé řetězce, do kterých bylo přidáno méně monomerů. Proč je mezi nimi takový rozdíl? Za prvé, růst polymerů je dynamický proces. Vyžaduje, aby se monomery spojovaly a reagovaly. Co když jeden monomer začne reagovat a vytvoří rostoucí řetězec dříve, než začnou reagovat ostatní? Díky svému náskoku bude tento řetězec delší než ostatní. Co když se s jedním z rostoucích řetězců něco pokazí a on už nebude moci přidávat nové monomery? Tento řetězec zažil předčasnou smrt a nikdy nebude růst tak dlouhý jako ostatní.
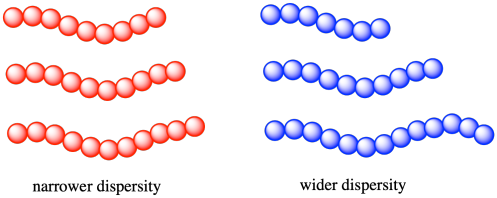
V důsledku toho, když mluvíme o molekulové hmotnosti polymeru, hovoříme vždy o průměrné hodnotě. Některé řetězce v materiálu budou delší (a těžší) a některé řetězce v materiálu budou kratší (a lehčí). Stejně jako u každé skupiny měření je užitečné vědět, jak široce jsou jednotlivé hodnoty ve skutečnosti rozloženy. V polymerní chemii se šířka rozložení molekulových hmotností popisuje pomocí disperzity (Ð, ve starších textech nazývané také polydisperzita nebo index polydisperzity, PDI). Disperzita vzorku polymeru se často pohybuje mezi 1 a 2 (i když může být i vyšší než 2). Čím více se blíží hodnotě 1, tím je distribuce užší. To znamená, že disperzita 1,0 by znamenala, že všechny řetězce ve vzorku jsou přesně stejně dlouhé a mají stejnou molekulovou hmotnost.
Původní myšlenka disperzity byla založena na alternativních metodách měření molekulové hmotnosti (nebo délky řetězce) vzorku polymeru. Jedna sada metod poskytla něco, co se nazývá průměrná početní molekulová hmotnost (symbol Mn). Tyto metody v podstatě vzaly hmotnost vzorku, spočítaly molekuly ve vzorku, a proto zjistily průměrnou hmotnost každé molekuly v tomto vzorku. Klasickým příkladem tohoto přístupu je experiment s koligativními vlastnostmi, například s teplotou tuhnutí. Víte, že nečistoty v kapalině mají tendenci narušovat mezimolekulární interakce a snižovat bod tuhnutí kapaliny. Možná také víte, že množství, o které se teplota tuhnutí sníží, závisí na počtu molekul nebo iontů, které se rozpustí. Pokud tedy zvážíte vzorek polymeru, rozpustíte ho v rozpouštědle a změříte bod tuhnutí, mohli byste zjistit počet rozpuštěných molekul a následně dojít k Mn.
To v praxi není tak snadné; poklesy bodu tuhnutí jsou velmi malé. Už se příliš často nepoužívají. Velmi častým příkladem druhu měření, které se dnes hojně používá ke stanovení Mn, je analýza koncových skupin. Při analýze koncových skupin používáme měření 1H NMR ke stanovení poměru určitého protonu v opakovacích jednotkách k určitému protonu v koncové skupině. Nezapomeňte, že koncová skupina může být něco jako iniciátor, který se přidává pouze na první monomer, aby se rozběhla polymerace. Na konci polymerace se stále nachází na konci polymerního řetězce, takže se jedná o koncovou skupinu. V jednom řetězci je pouze jedna, zatímco v polymeru je spousta monomerů zřetězených, takže poměr těchto zřetězených monomerů a koncové skupiny nám říká, jak je řetězec dlouhý.
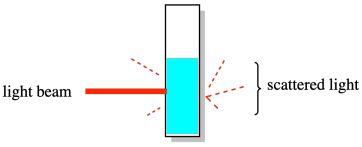
Druhá sada metod, na nichž byla disperzita založena, poskytla něco, co se nazývá hmotnostní průměr molekulové hmotnosti (symbol Mw). Klasickým příkladem byl experiment s rozptylem světla. Při tomto pokusu byl roztok polymeru vystaven paprsku světla a výsledné rozptýlené světlo – vycházející ze vzorku v různých směrech – bylo analyzováno za účelem určení velikosti polymerních řetězců v roztoku. Výsledky byly silněji ovlivněny většími molekulami v roztoku. V důsledku toho bylo toto měření molekulové hmotnosti vždy vyšší než měření založené na počítání každé jednotlivé molekuly.
Výsledný poměr, Ð = Mw / Mn, se stal známým jako index polydisperzity nebo nověji disperzita. Protože Mw byla vždy silněji ovlivněna delšími řetězci, byla o něco větší než Mn, a proto byla disperzita vždy větší než 1,0.
V současné době se molekulová hmotnost i disperzita nejčastěji měří pomocí gelové permeační chromatografie (GPC), která je synonymem pro velikostně vylučovací chromatografii (SEC). Tato metoda je technikou vysokoúčinné kapalinové chromatografie (HPLC). Rozpouštědlo obsahující vzorek polymeru se čerpá přes specializovanou chromatografickou kolonu schopnou oddělit molekuly na základě jejich velikostních rozdílů. Jakmile vzorek vystoupí z kolony, je detekován a zaznamenán. Nejčastěji přítomnost vzorku v rozpouštědle vystupujícím z kolony způsobuje mírnou změnu indexu lomu. Graf závislosti indexu lomu na čase představuje záznam množství vzorku vystupujícího z kolony v daném čase. Protože kolona odděluje molekuly na základě velikosti, osa času nepřímo odpovídá délce řetězce molekulové hmotnosti.
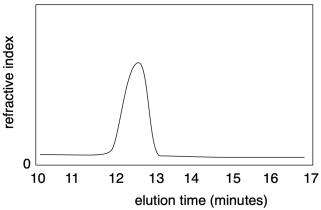
Jak může kolona oddělovat molekuly na základě velikosti? Kolona je naplněna porézním materiálem, obvykle nerozpustnými polymerními kuličkami. Velikost pórů se liší. Tyto póry a rozhodující pro separaci, protože molekuly protékající kolonou mohou v pórech dehtovat. Menší molekuly se mohou zdržet v kterémkoli z pórů materiálu, zatímco větší molekuly se zdrží pouze v největších pórech. Delší eluční čas proto odpovídá nižší molekulové hmotnosti.

Pokud byste do GPC vstříkli sérii různých polymerů, z nichž každý má jiné rozložení molekulových hmotností, pozorovali byste, že každý z nich eluuje v jinou dobu. Navíc každý pík může být širší nebo užší, v závislosti na disperzitě daného vzorku.
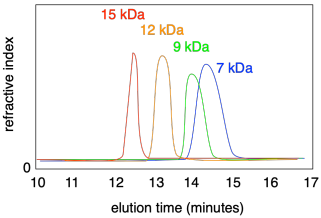
Čím širší je pík v GPC, tím širší je rozložení molekulových hmotností; čím užší jsou píky, tím rovnoměrnější jsou řetězce. Obvykle softwarový balík analyzuje křivku, aby určil disperzitu.

Všimněte si, že osa x na stopě GPC je nejčastěji označena jako „eluční čas“ a obvykle probíhá zleva doprava. Často je však osa x označena jako „molekulová pravá“, protože to je ve skutečnosti veličina, která nás zajímá. Ve skutečnosti je někdy osa obrácená, takže píky s vyšší molekulovou hmotností se zobrazují vpravo, protože takový pohled může být přirozenější. Musíte se pozorně podívat na data, abyste viděli, jak jsou zobrazena.
Spoléhání se na GPC při měření molekulových hmotností má určité problémy. Hlavní potíž spočívá v tom, že polymery v roztoku mají tendenci se stáčet do kuliček a tyto kuličky budou obsahovat větší či menší množství rozpouštědla v závislosti na tom, jak silně na sebe polymer a rozpouštědlo vzájemně působí. Pokud polymer silněji interaguje s rozpouštědlem, vtáhne do svých závitů mnohem více molekul rozpouštědla. Cívka se musí zvětšit, aby se do ní tyto vnitřní molekuly rozpouštědla vešly. Pokud s rozpouštědlem silně neinteraguje, většinou se jen přilepí k sobě a blokuje molekuly rozpouštědla ven. Mezi tím existuje široká škála chování.
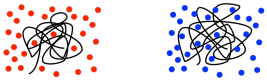
V důsledku toho mohou různé polymery v různých rozpouštědlech bobtnat v různé míře. To je důležité, protože GPC ve skutečnosti používá velikost závitu polymeru jako index jeho molekulové hmotnosti, takže porovnávání GPC stop dvou různých druhů polymerů je třeba provádět opatrně.
Problém CP1.1.
V každém z následujících případů uveďte, který polymer má vyšší molekulovou hmotnost a který má užší disperzitu
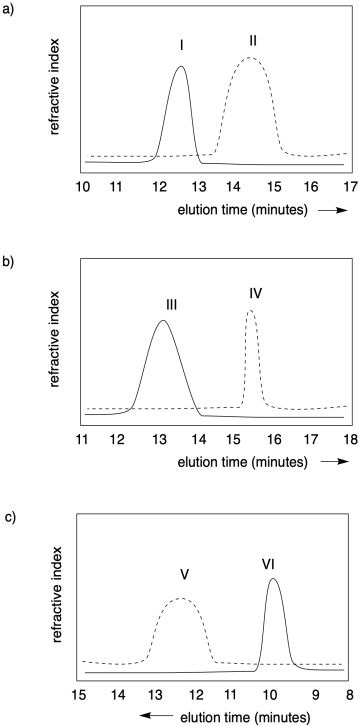
Problém CP1.2.
Vypočítejte molekulovou hmotnost následujících vzorků.
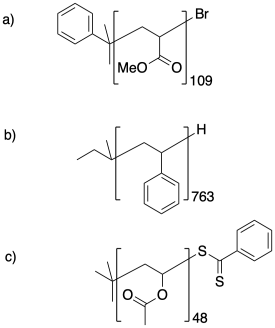
Problém CP1.3.
Pomocí analýzy koncových skupin NMR určete stupně polymerace u následujících vzorků.
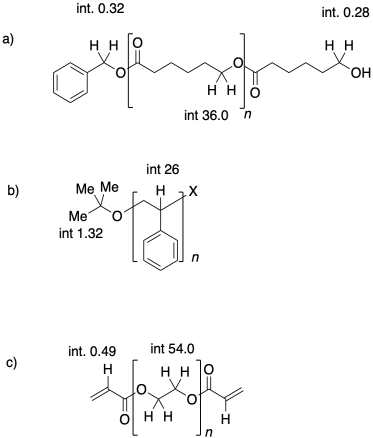
.