Înțelegerea noțiunilor de bază ale managementului schemelor este crucială pentru construirea și menținerea unei baze de date PostgreSQL eficiente. În acest articol, vom analiza modul tradițional de gestionare a unei scheme Postgres și un mod mai nou și mai eficient de a face acest lucru vizual, fără a fi nevoie să scriem nicio linie de cod.
Ce este o schemă PostgreSQL?
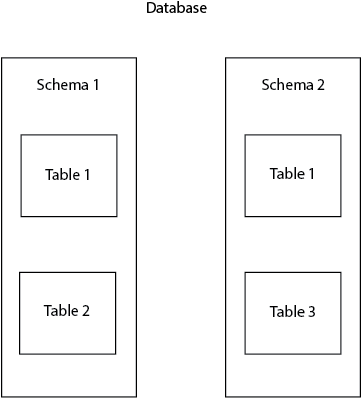
În primul rând, pentru a pune bazele articolului, haideți să clarificăm puțină terminologie. În Postgres, schema este denumită și spațiu de nume. Spațiul de nume poate fi asociat cu un nume de familie. Acesta este utilizat pentru a identifica și diferenția anumite obiecte din baza de date (tabele, vizualizări, coloane etc.). Nu este permisă crearea a două tabele cu același nume într-o singură schemă, dar se poate face acest lucru în două scheme diferite. De exemplu, putem avea două tabele, ambele cu numele table1, prezente în schemele public și postgres.
De ce se folosesc schemele?
Schemele sunt foarte utile pentru a organiza obiectele bazei de date în grupuri logice și pentru a evita coliziunea de nume. În afară de aceasta, schemele sunt adesea folosite pentru a permite diferiților utilizatori să lucreze cu baza de date fără să interfereze între ei. Un exemplu obișnuit este atunci când fiecare utilizator al bazei de date lucrează pe propria schemă, fără a interfera cu alți utilizatori și evitând conflictele.
Modul clasic de gestionare a schemelor PostgreSQL
Toate interogările de mai jos vor fi executate din interiorul shell-ului PostgreSQL.
Crearea unei scheme
Când creați o nouă bază de date în Postgres, schema implicită este publică. O nouă schemă poate fi creată prin executarea următoarei interogări:
CREATE SCHEMA schema_1;
Înainte de a-i adăuga câteva tabele, voi explica două concepte importante: nume calificate și nume necalificate.
-
Un nume calificat este reprezentat de numele schemei și de numele tabelei separate de un punct. Acesta va specifica schema în care dorim să creăm tabelul nostru:
.
xxxxxxxxxx
CREATE TABLE schema_name.table_name (...);
-
Un nume necalificat este format doar din numele tabelului. Acest lucru va crea tabelul în baza de date selectată, care este publică în mod implicit. Acest lucru poate fi modificat prin intermediul search_path, dar vom detalia acest lucru mai târziu. Un exemplu de denumire necalificată este:
.
xxxxxxxxxx
CREATE TABLE table_name (...);
Colonii tabelelor vor fi definiți în interiorul parantezelor din interogările de mai sus (…).
Pentru a crea un tabel nou în noua noastră schemă, vom executa:
.
xxxxxxxxxx
CREATE TABLE schema_1.persons (name text, age int);
Pentru a renunța la schemă, avem două posibilități. Dacă schema este goală (nu conține niciun tabel, vizualizare sau alte obiecte), putem executa:
.
xxxxxxxxxx
DROP SCHEMA schema_1;
În cazul în care schema conține obiecte de baze de date, vom introduce comanda în cascadă:
.
xxxxxxxxxx
DROP SCHEMA schema_1 CASCADE;
În PostgreSQL este de asemenea posibil să se creeze o schemă deținută de un alt utilizator cu:
xxxxxxxxxx
CREATE SCHEMA schema_name AUTHORIZATION username;
Cale de căutare
Când se execută o comandă cu un nume necalificat, Postgres urmează o cale de căutare pentru a determina ce scheme să utilizeze. În mod implicit, calea de căutare este setată la schema publică. Pentru a o vizualiza, executați:
.
xxxxxxxxxx
SHOW search_path;
Dacă nu s-a schimbat nimic în baza de date, această interogare ar trebui să aducă următorul rezultat:
xxxxxxxxxx
search_path
--------------
"$user",public
Calea_de_cercetare poate fi modificată astfel încât sistemul să aleagă automat o altă schemă dacă se utilizează un nume necalificat. Prima schemă din calea de căutare se numește schema curentă. De exemplu, voi seta schema_1 ca fiind schema curentă:
.
xxxxxxxxxx
SET search_path TO schema_1,public;
Următoarea interogare va utiliza un nume necalificat pentru a crea un tabel. Aceasta o va crea automat în schema_1:
.
xxxxxxxxxx
CREATE TABLE address (city text, street text, number int);
Calea nouă: Gestionați fără cod!
Există o modalitate mai simplă de a realiza toate sarcinile de gestionare a schemelor, fără a fi nevoie să scrieți nicio linie de cod. Folosind DbSchema puteți executa toate interogările de mai sus dintr-o interfață grafică intuitivă, cu doar câteva clicuri. Conectarea la baza de date va dura doar câteva secunde. De la început, puteți selecta pe ce schemă să lucrați.
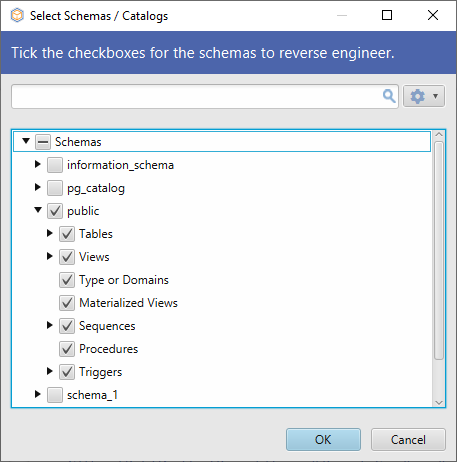
Schema sau schemele selectate vor fi analizate invers de DbSchema și afișate în layout.
Pentru a crea o nouă schemă, trebuie doar să faceți clic dreapta pe folderul schemei din meniul din stânga și să selectați Create Schema.
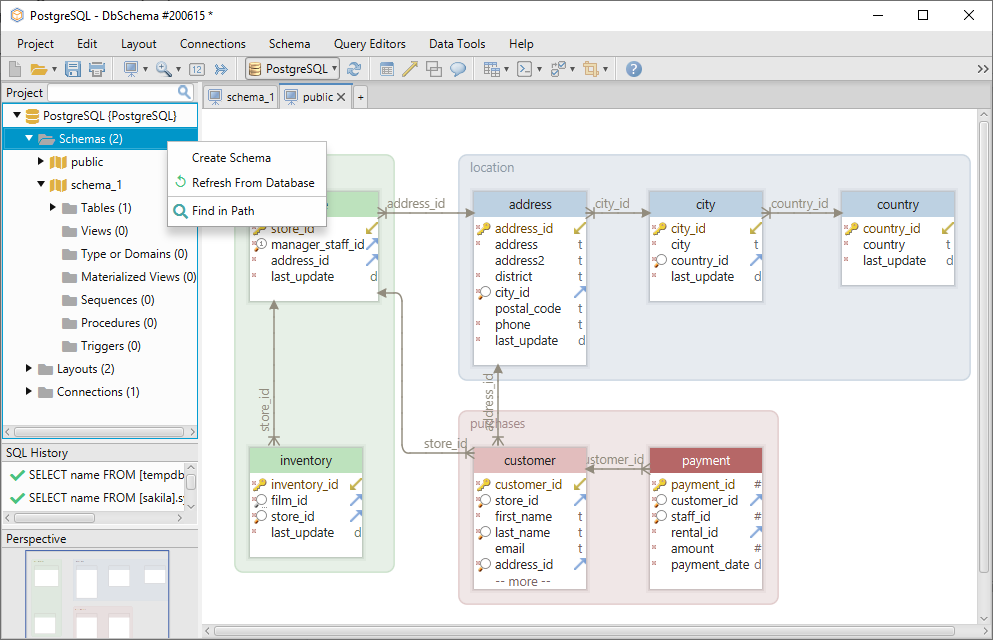
Pentru a crea o nouă tabelă în schemă, faceți clic dreapta pe layout și selectați Create Table.
Schema poate fi abandonată făcând clic dreapta pe numele său din meniul din stânga.
Pentru a adăuga o altă schemă din baza de date, alegeți Refresh From Database.
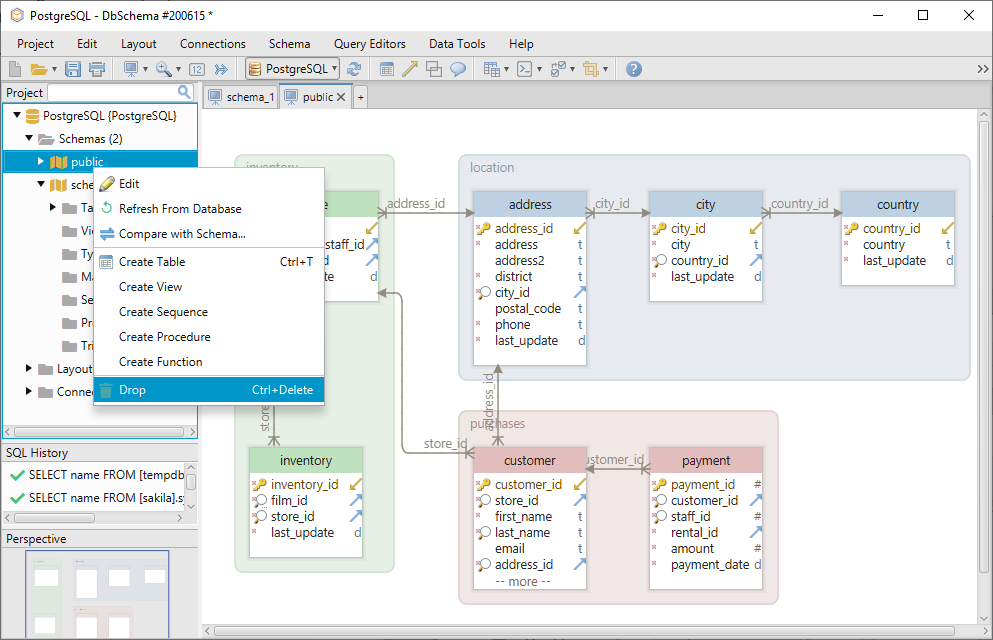
Utilizând DbSchema, nu va fi nevoie să folosiți sintaxa show_path, deoarece puteți crea tabelele chiar în layout. Un layout poate fi comparat cu o planșă de desen pe care puteți adăuga tabelele și le puteți edita. Fiecărui layout îi este asociată o schemă, astfel încât, dacă vă aflați pe layout-ul schema_1, tabelele vor fi create automat acolo.
Work Offline
DbSchema stochează o imagine locală a schemei într-un fișier de proiect local. Acest lucru înseamnă că fișierul de proiect poate fi deschis fără conectivitate cu baza de date (offline). În regim offline, puteți efectua toate acțiunile prezentate mai sus și multe altele, dar fără date. După reconectarea la baza de date, puteți compara fișierul de proiect cu baza de date și puteți alege ce acțiuni să păstrați sau să abandonați.
Același lucru se poate face între două versiuni diferite ale aceluiași fișier de proiect. De exemplu, dacă lucrați într-o echipă, se poate întâmpla să existe mai multe scheme (producție, testare, dezvoltare), fiecare cu propriul fișier de proiect. Dacă apare o modificare în dezvoltare și doriți să o implementați peste celelalte două scheme, puteți pur și simplu să comparați și să sincronizați cele două fișiere de proiect.
Concluzie
Înțelegerea conceptelor enumerate mai sus vă va ajuta să vă gestionați cu ușurință schemele PostgreSQL. Utilizarea unui designer vizual, cum ar fi DbSchema, vă va ușura și mai mult munca, permițându-vă să faceți totul vizual, fără a fi nevoie să scrieți o singură linie de cod.