
Înainte de a începe această călătorie de a încerca să învăț informatică, existau anumiți termeni și expresii care mă făceau să vreau să fug în direcția opusă.
Dar în loc să fug, mă prefăceam că le cunosc, dând din cap în conversații, pretinzând că știu la ce se referea cineva, deși adevărul era că nu aveam nicio idee și de fapt mă oprisem complet din ascultat atunci când auzeam That Super Scary Computer Science Term™. De-a lungul acestei serii, am reușit să acopăr o mulțime de teren și mulți dintre acești termeni au devenit, de fapt, mult mai puțin înfricoșători!
Există unul mare, totuși, pe care l-am evitat o vreme. Până acum, de câte ori auzisem acest termen, mă simțeam paralizat. A apărut în conversații ocazionale la întâlniri și, uneori, în discuții la conferințe. De fiecare dată, mă gândesc la mașini care se învârt și la computere care scuipă șiruri de coduri indescifrabile, cu excepția faptului că toți ceilalți din jurul meu le pot de fapt descifra, așa că de fapt doar eu sunt cel care nu știe ce se întâmplă (hopa, cum s-a întâmplat asta?!).
Poate că nu sunt singurul care s-a simțit așa. Dar, presupun că ar trebui să vă spun ce este de fapt acest termen, nu? Ei bine, pregătiți-vă, pentru că mă refer la mereu evazivul și aparent confuzul arbore abstract de sintaxă, sau AST pe scurt. După mulți ani în care am fost intimidat, sunt încântat să încetez în sfârșit să mă mai tem de acest termen și să înțeleg cu adevărat ce naiba este.
Este timpul să înfruntăm cu capul înainte rădăcina arborelui sintactic abstract – și să ne ridicăm nivelul jocului nostru de parsare!
Toată căutarea bună începe cu o fundație solidă, iar misiunea noastră de a demistifica această structură ar trebui să înceapă exact în același mod: cu o definiție, bineînțeles!
Un arbore de sintaxă abstractă (denumit de obicei doar AST) nu este de fapt nimic mai mult decât o versiune simplificată și condensată a unui arbore de parsare. În contextul proiectării compilatoarelor, termenul „AST” este utilizat în mod interschimbabil cu arborele de sintaxă.

Ne gândim adesea la arborii de sintaxă (și la modul în care sunt construiți) în comparație cu omologii lor arborele parse, cu care suntem deja destul de familiarizați. Știm că arborii parse sunt structuri de date arborescente care conțin structura gramaticală a codului nostru; cu alte cuvinte, conțin toate informațiile sintactice care apar într-o „propoziție” de cod și sunt derivate direct din gramatica limbajului de programare însuși.
Un arbore de sintaxă abstract, pe de altă parte, ignoră o cantitate semnificativă de informații sintactice pe care un arbore parse le-ar conține altfel.
În schimb, un AST conține doar informațiile legate de analiza textului sursă și omite orice alt conținut suplimentar care este utilizat în timpul analizei textului.
Această distincție începe să aibă mult mai mult sens dacă ne concentrăm asupra „abstractizării” unui AST.
Ne vom aminti că un arbore de analiză este o versiune ilustrată, picturală a structurii gramaticale a unei propoziții. Cu alte cuvinte, putem spune că un arbore parse reprezintă exact cum arată o expresie, o propoziție sau un text. Practic, este o traducere directă a textului în sine; luăm propoziția și transformăm fiecare bucățică din ea – de la punctuație la expresii și token-uri – într-o structură de date arborescentă. Acesta dezvăluie sintaxa concretă a unui text, motiv pentru care este denumit și arbore de sintaxă concretă sau CST. Folosim termenul concret pentru a descrie această structură deoarece este o copie gramaticală a codului nostru, jeton cu jeton, în format arbore.
Dar ce face ca ceva să fie concret față de abstract? Ei bine, un arbore sintactic abstract nu ne arată exact cum arată o expresie, așa cum o face un arbore de analiză.

În schimb, un arbore de sintaxă abstract ne arată părțile „importante” – lucrurile care ne interesează cu adevărat, care dau sens „propoziției” codului nostru în sine. Arborii de sintaxă ne arată bucățile semnificative ale unei expresii, sau sintaxa abstractizată a textului nostru sursă. Prin urmare, în comparație cu arborii de sintaxă concreți, aceste structuri sunt reprezentări abstracte ale codului nostru (și, în unele privințe, mai puțin exacte), care este exact modul în care și-au primit numele.
Acum că am înțeles distincția dintre aceste două structuri de date și modurile diferite în care acestea pot reprezenta codul nostru, merită să ne punem întrebarea: unde se potrivește un arbore de sintaxă abstract în compilator? În primul rând, să ne reamintim tot ceea ce știm despre procesul de compilare așa cum îl cunoaștem până acum.

Să spunem că avem un text sursă super scurt și dulce, care arată astfel: 5 + (1 x 12).
Ne vom aminti că primul lucru care se întâmplă în procesul de compilare este scanarea textului, o sarcină efectuată de scaner, care are ca rezultat fragmentarea textului în cele mai mici părți posibile, care se numesc lexeme. Această parte va fi agnostică față de limbă, iar noi ne vom trezi cu versiunea decupată a textului nostru sursă.
În continuare, chiar aceste lexeme sunt transmise lexorului/tokenizatorului, care transformă aceste mici reprezentări ale textului nostru sursă în token-uri, care vor fi specifice limbii noastre. Token-urile noastre vor arăta cam așa: . Efortul comun al scanerului și al tokenizatorului constituie analiza lexicală a compilației.
Apoi, odată ce intrarea noastră a fost tokenizată, tokenii rezultați sunt trecuți la parserul nostru, care ia textul sursă și construiește din el un arbore de analiză. Ilustrația de mai jos exemplifică modul în care arată codul nostru tokenizat, în format parse tree.
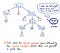
Lucrarea de transformare a tokenilor într-un parse tree se numește, de asemenea, parsare și este cunoscută sub numele de faza de analiză sintactică. Faza de analiză sintactică depinde în mod direct de faza de analiză lexicală; astfel, analiza lexicală trebuie să fie întotdeauna pe primul loc în procesul de compilare, deoarece parserul compilatorului nostru își poate face treaba numai după ce tokenizatorul își face treaba!
Ne putem gândi la părțile compilatorului ca la niște prieteni buni, care toți depind unii de alții pentru a se asigura că codul nostru este transformat corect dintr-un text sau fișier într-un arbore de analiză.
Dar să revenim la întrebarea noastră inițială: unde se încadrează arborele sintactic abstract în acest grup de prieteni? Ei bine, pentru a răspunde la această întrebare, ne ajută să înțelegem necesitatea unui AST în primul rând.
Condensarea unui arbore în altul
Bine, deci acum avem doi arbori pe care trebuie să îi ținem drepți în capul nostru. Aveam deja un arbore de analiză, și cum mai avem încă o structură de date de învățat! Și, aparent, această structură de date AST este doar un arbore de căutare simplificat. Deci, de ce avem nevoie de ea? Care este chiar rostul ei?
Bine, haideți să aruncăm o privire la arborele nostru de parse, da?
Știm deja că arborii de parse reprezintă programul nostru în părțile sale cele mai distincte; într-adevăr, acesta a fost motivul pentru care scanerul și tokenizatorul au sarcini atât de importante de a descompune expresia noastră în cele mai mici părți ale sale!
Ce înseamnă de fapt să reprezinți un program prin părțile sale cele mai distincte?
Se pare că, uneori, toate părțile distincte ale unui program nu ne sunt de fapt atât de utile tot timpul.
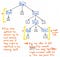
Să aruncăm o privire la ilustrația prezentată aici, care reprezintă expresia noastră originală, 5 + (1 x 12), în formatul arborelui parse tree. Dacă ne uităm atent la acest arbore cu un ochi critic, vom vedea că există câteva cazuri în care un nod are exact un singur copil, care sunt, de asemenea, denumite noduri cu un singur succesor, deoarece au un singur nod copil care derivă din ele (sau un singur „succesor”).
În cazul exemplului nostru de arbore de parsare, nodurile cu un singur succesor au un nod părinte de tipul sau Exp, care au un singur succesor de o anumită valoare, cum ar fi 5, 1 sau 12. Cu toate acestea, nodurile părinte Exp de aici nu ne adaugă de fapt nimic de valoare, nu-i așa? Putem vedea că ele conțin noduri copil de tip token/terminal, dar nu ne pasă cu adevărat de nodul părinte „expresie”; tot ceea ce dorim cu adevărat să știm este ce este expresia?
Nodul părinte nu ne oferă nicio informație suplimentară după ce am analizat arborele nostru. În schimb, ceea ce ne interesează cu adevărat este nodul unic copil și unic succesor. Într-adevăr, acesta este nodul care ne oferă informațiile importante, partea care este semnificativă pentru noi: numărul și valoarea în sine! Având în vedere faptul că aceste noduri părinte sunt oarecum inutile pentru noi, devine evident că acest arbore de analiză este un fel de verb.
Toate aceste noduri cu un singur succesor sunt destul de inutile pentru noi și nu ne ajută deloc. Așadar, să scăpăm de ele!
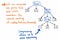
Dacă comprimăm nodurile cu un singur succesor din arborele nostru parse, vom avea în final o versiune mai comprimată a aceleiași structuri exacte. Dacă ne uităm la ilustrația de mai sus, vom vedea că menținem în continuare exact aceeași structurare ca înainte, iar nodurile/tokenurile/terminalele noastre apar în continuare în locul corect în cadrul arborelui. Dar, am reușit să îl micșorăm puțin.
Și putem tăia și mai multe din arborele nostru. De exemplu, dacă ne uităm la arborele nostru de analiză așa cum este el în acest moment, vom vedea că există o structură în oglindă în cadrul acestuia. Subexpresia (1 x 12) este imbricata în parantezele (), care sunt token-uri de sine stătătoare.
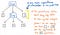
Cu toate acestea, aceste paranteze nu ne ajută cu adevărat odată ce avem arborele nostru la locul lui. Știm deja că 1 și 12 sunt argumente care vor fi transmise operației de înmulțire x, așa că parantezele nu ne spun prea multe în acest moment. De fapt, am putea comprima și mai mult arborele nostru de parsare și să scăpăm de aceste noduri de frunze superflue.
După ce comprimăm și simplificăm arborele nostru de parsare și scăpăm de „praful” sintactic străin, ne trezim cu o structură care arată vizibil diferit în acest punct. Această structură este, de fapt, noul și mult-așteptatul nostru prieten: arborele de sintaxă abstractă.

Imaginea de mai sus ilustrează exact aceeași expresie ca și arborele nostru de analiză: 5 + (1 x 12). Diferența constă în faptul că a abstractizat expresia de sintaxa concretă. Nu mai vedem parantezele () în acest arbore, deoarece acestea nu sunt necesare. În mod similar, nu mai vedem non-terminale precum Exp, deoarece ne-am dat deja seama ce este „expresia” și suntem capabili să scoatem valoarea care contează cu adevărat pentru noi – de exemplu, numărul 5.
Acesta este exact factorul care face diferența între un AST și un CST. Știm că un arbore sintactic abstract ignoră o cantitate semnificativă de informații sintactice pe care le conține un arbore de parsare și omite „conținutul suplimentar” care este utilizat în parsare. Dar acum putem vedea exact cum se întâmplă acest lucru!

Acum că am condensat un arbore de parsare al nostru, vom fi mult mai capabili să observăm mult mai bine unele dintre tiparele care disting un AST de un CST.
Există câteva moduri în care un arbore sintactic abstract se va deosebi vizual de un arbore de parsare:
- Un AST nu va conține niciodată detalii sintactice, cum ar fi virgule, paranteze și punct și virgulă (în funcție, bineînțeles, de limbă).
- Un AST va avea o versiune prăbușită a ceea ce altfel ar apărea ca noduri cu un singur succesor; nu va conține niciodată „lanțuri” de noduri cu un singur copil.
- În cele din urmă, orice token de operator (cum ar fi
+,-,xși/) va deveni noduri interne (părinte) în arbore, mai degrabă decât frunzele care se termină într-un arbore parse.
Vizual, un AST va părea întotdeauna mai compact decât un arbore parse, deoarece este, prin definiție, o versiune comprimată a unui arbore parse, cu mai puține detalii sintactice.
Atunci, ar fi logic că, dacă un AST este o versiune compactată a unui arbore parse, nu putem crea cu adevărat un arbore sintactic abstract decât dacă avem elementele necesare pentru a construi un arbore parse pentru început!
Acesta este, într-adevăr, modul în care arborele sintactic abstract se încadrează în procesul mai larg de compilare. Un AST are o legătură directă cu arborii de parsare despre care am învățat deja, în timp ce, în același timp, se bazează pe lexer pentru a-și face treaba înainte ca un AST să poată fi creat vreodată.

Arborele sintactic abstract este creat ca rezultat final al fazei de analiză sintactică. Analizatorul, care se află în față și în centrul atenției ca „personaj” principal în timpul analizei sintactice, poate sau nu poate genera întotdeauna un arbore de parsare, sau CST. În funcție de compilator și de modul în care a fost proiectat, parserul poate trece direct la construirea unui arbore de sintaxă, sau AST. Dar parserul va genera întotdeauna un AST ca ieșire, indiferent dacă va crea un arbore de parsare între timp sau câte treceri ar trebui să facă pentru a face acest lucru.
Anatomia unui AST
Acum că știm că arborele sintactic abstract este important (dar nu neapărat intimidant!), putem începe să îl disecăm puțin mai mult. Un aspect interesant despre modul în care este construit AST are legătură cu nodurile acestui arbore.
Imaginea de mai jos exemplifică anatomia unui singur nod în cadrul unui arbore de sintaxă abstractă.
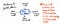
Observăm că acest nod este similar cu altele pe care le-am văzut înainte, în sensul că el conține niște date (un token și value al acestuia). Cu toate acestea, el conține, de asemenea, niște pointeri foarte specifici. Fiecare nod dintr-un AST conține referințe la următorul său nod frate, precum și la primul său nod copil.
De exemplu, expresia noastră simplă de 5 + (1 x 12) ar putea fi construită într-o ilustrație vizualizată a unui AST, precum cea de mai jos.

Ne putem imagina că citirea, parcurgerea sau „interpretarea” acestui AST ar putea începe de la nivelele inferioare ale arborelui, urcând în sus pentru a construi o valoare sau un return result până la sfârșit.
De asemenea, poate fi de ajutor să vedem o versiune codificată a ieșirii unui parser pentru a ne ajuta să ne completăm vizualizările. Putem să ne sprijinim pe diverse instrumente și să folosim analizoare preexistente pentru a vedea un exemplu rapid al modului în care ar putea arăta expresia noastră atunci când este rulată printr-un analizor. Mai jos este un exemplu al textului nostru sursă, 5 + (1 * 12), rulat prin Esprima, un parser ECMAScript, și arborele de sintaxă abstractă rezultat, urmat de o listă a token-urilor sale distincte.
În acest format, putem vedea cuibărirea arborelui dacă ne uităm la obiectele imbricate. Vom observa că valorile care conțin 1 și 12 sunt copiii left și, respectiv, right ai unei operații părinte, *. Vom vedea, de asemenea, că operația de înmulțire (*) constituie subarborele drept al întregii expresii în sine, motiv pentru care este imbricata în cadrul obiectului mai mare BinaryExpression, sub cheia "right". În mod similar, valoarea lui 5 este unicul "left" copil al obiectului mai mare BinaryExpression.

Cel mai intrigant aspect al arborelui de sintaxă abstractă este, totuși, faptul că, deși sunt atât de compacte și curate, ele nu sunt întotdeauna o structură de date ușor de încercat și de construit. De fapt, construirea unui AST poate fi destul de complexă, în funcție de limbajul cu care se confruntă parserul!
Majoritatea parser-elor vor construi de obicei fie un arbore de parsare (CST) și apoi îl vor converti într-un format AST, deoarece acest lucru poate fi uneori mai ușor – chiar dacă înseamnă mai mulți pași și, în general, mai multe treceri prin textul sursă. Construirea unui CST este de fapt destul de ușoară odată ce parserul cunoaște gramatica limbii pe care încearcă să o analizeze. Nu trebuie să facă o muncă complicată pentru a afla dacă un token este „semnificativ” sau nu; în schimb, doar ia exact ceea ce vede, în ordinea specifică în care îl vede, și scuipă totul într-un arbore.
Pe de altă parte, există unele parsere care vor încerca să facă toate acestea ca un proces într-o singură etapă, sărind direct la construirea unui arbore sintactic abstract.
Construirea directă a unui AST poate fi complicată, deoarece parserul trebuie nu numai să găsească token-urile și să le reprezinte corect, ci și să decidă care token-uri contează pentru noi și care nu.
În proiectarea compilatoarelor, AST-ul sfârșește prin a fi super important din mai multe motive. Da, poate fi complicat de construit (și probabil ușor de încurcat), dar, de asemenea, este ultimul și ultimul rezultat al fazelor de analiză lexicală și sintactică combinate! Fazele de analiză lexicală și sintactică sunt adesea denumite împreună faza de analiză sau front-end-ul compilatorului.

Ne putem gândi la arborele sintactic abstract ca la „proiectul final” al front-end-ului compilatorului. Este partea cea mai importantă, deoarece este ultimul lucru pe care front-end-ul trebuie să îl arate pentru sine. Termenul tehnic pentru aceasta se numește reprezentare intermediară a codului sau RI, deoarece devine structura de date care este folosită în cele din urmă de compilator pentru a reprezenta un text sursă.
Un arbore sintactic abstract este cea mai comună formă de RI, dar și, uneori, cea mai neînțeleasă. Dar acum că îl înțelegem un pic mai bine, putem începe să ne schimbăm percepția asupra acestei structuri înfricoșătoare! Să sperăm că acum ne intimidează un pic mai puțin.
Resurse
Există o mulțime de resurse despre AST-uri, într-o varietate de limbaje. Să știi de unde să începi poate fi dificil, mai ales dacă vrei să înveți mai mult. Mai jos sunt câteva resurse accesibile începătorilor, care intră în mult mai multe detalii, fără a fi prea mult prea stufoase. Asbtracting fericit!
- The AST vs. Parse Tree, profesor Charles N. Fischer
- Care este diferența dintre arborii de analiză și arborii de sintaxă abstractă?, StackOverflow
- Arbori de sintaxă abstracți vs. arbori de sintaxă concreți, Eli Bendersky
- Arbori de sintaxă abstracți, Profesor Stephen A. Edwards
- Arbori de sintaxă abstracți & Top-Down Parsing, Profesor Konstantinos (Kostis) Sagonas
- Analiza lexicală și sintactică a limbajelor de programare, Chris Northwood
- AST Explorer, Felix Kling
.