Ultima actualizare la 18 august 2020
Datele pot avea valori lipsă, iar acest lucru poate cauza probleme pentru mulți algoritmi de învățare automată.
Ca atare, este o bună practică să identificați și să înlocuiți valorile lipsă pentru fiecare coloană din datele de intrare înainte de a vă modela sarcina de predicție. Acest lucru se numește imputare a datelor lipsă sau, pe scurt, imputare.
O abordare populară pentru imputarea datelor este de a calcula o valoare statistică pentru fiecare coloană (cum ar fi o medie) și de a înlocui toate valorile lipsă pentru acea coloană cu statistica respectivă. Este o abordare populară deoarece statistica este ușor de calculat folosind setul de date de instruire și deoarece deseori are ca rezultat o performanță bună.
În acest tutorial, veți descoperi cum să utilizați strategiile de imputare statistică pentru datele lipsă în învățarea automată.
După finalizarea acestui tutorial, veți ști:
- Valorile lipsă trebuie să fie marcate cu valori NaN și pot fi înlocuite cu măsuri statistice pentru a calcula coloana de valori.
- Cum se încarcă o valoare CSV cu valori lipsă și se marchează valorile lipsă cu valori NaN și se raportează numărul și procentul de valori lipsă pentru fiecare coloană.
- Cum se impută valorile lipsă cu ajutorul statisticilor ca metodă de pregătire a datelor la evaluarea modelelor și la ajustarea unui model final pentru a face predicții pe date noi.
Dă startul proiectului tău cu noua mea carte Data Preparation for Machine Learning, care include tutoriale pas cu pas și fișierele de cod sursă Python pentru toate exemplele.
Să începem.
- Actualizat Jun/2020: Schimbată coloana folosită pentru predicție în exemple.

Statistical Imputation for Missing Values in Machine Learning
Fotografie de Bernal Saborio, unele drepturi rezervate.
Tutorial Overview
Acest tutorial este împărțit în trei părți; acestea sunt:
- Imputarea statistică
- Set de date despre colici de cal
- Imputarea statistică cu SimpleImputer
- Transformarea datelor cu SimpleImputer
- SimpleImputer și evaluarea modelului
- Compararea diferitelor statistici imputate
- Transformarea SimpleImputer atunci când se face o predicție
.
Imputarea statistică
Un set de date poate avea valori lipsă.
Sunt rânduri de date în care una sau mai multe valori sau coloane din acel rând nu sunt prezente. Valorile pot lipsi complet sau pot fi marcate cu un caracter sau o valoare specială, cum ar fi un semn de întrebare „?”.
Aceste valori pot fi exprimate în mai multe moduri. Am văzut că ele apar ca nimic, un șir de caractere gol, șirul explicit NULL sau nedefinit sau N/A sau NaN și numărul 0, printre altele. Indiferent de modul în care apar în setul dvs. de date, știind la ce să vă așteptați și verificând pentru a vă asigura că datele corespund acestei așteptări, veți reduce problemele pe măsură ce începeți să utilizați datele.
– Pagina 10, Bad Data Handbook, 2012.
Valorile ar putea lipsi din mai multe motive, adesea specifice domeniului problemei, și ar putea include motive precum măsurători corupte sau indisponibilitatea datelor.
Pot apărea din mai multe motive, cum ar fi funcționarea defectuoasă a echipamentului de măsurare, modificări ale proiectului experimental în timpul colectării datelor și colaționarea mai multor seturi de date similare, dar nu identice.
– Pagina 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
Majoritatea algoritmilor de învățare automată necesită valori numerice de intrare și o valoare care să fie prezentă pentru fiecare rând și coloană dintr-un set de date. Ca atare, valorile lipsă pot cauza probleme pentru algoritmii de învățare automată.
Ca atare, este obișnuit să se identifice valorile lipsă într-un set de date și să le înlocuiască cu o valoare numerică. Acest lucru se numește imputare de date sau imputare de date lipsă.
O abordare simplă și populară a imputării de date implică utilizarea metodelor statistice pentru a estima o valoare pentru o coloană din acele valori care sunt prezente, apoi înlocuirea tuturor valorilor lipsă din coloană cu statistica calculată.
Este simplă pentru că statisticile sunt rapid de calculat și este populară pentru că se dovedește adesea foarte eficientă.
Statisticile comune calculate includ:
- Valoarea medie a coloanei.
- Valoarea mediană a coloanei.
- Valoarea modală a coloanei.
- O valoare constantă.
Acum că suntem familiarizați cu metodele statistice de imputare a valorilor lipsă, haideți să analizăm un set de date cu valori lipsă.
Vreți să începeți cu pregătirea datelor?
Faceți acum cursul meu rapid gratuit de 7 zile prin e-mail (cu cod de probă).
Click pentru a vă înscrie și pentru a obține, de asemenea, o versiune gratuită a cursului în format PDF Ebook.
Download Your FREE Mini-Course
Horse Colic Dataset
The horse colic dataset descrie caracteristicile medicale ale cailor cu colici și dacă au trăit sau au murit.
Există 300 de rânduri și 26 de variabile de intrare cu o variabilă de ieșire. Este o sarcină de predicție de clasificare binară care implică predicția 1 dacă calul a trăit și 2 dacă calul a murit.
Există multe câmpuri pe care le-am putea selecta pentru a prezice în acest set de date. În acest caz, vom prezice dacă problema a fost chirurgicală sau nu (indexul coloanei 23), ceea ce face ca aceasta să fie o problemă de clasificare binară.
Setul de date are numeroase valori lipsă pentru multe dintre coloane, unde fiecare valoare lipsă este marcată cu un caracter de semn de întrebare („?”).
Mai jos se oferă un exemplu de rânduri din setul de date cu valori lipsă marcate.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Puteți afla mai multe despre setul de date aici:
- Horse Colic Dataset
- Horse Colic Dataset Description
Nu este nevoie să descărcați setul de date, deoarece îl vom descărca automat în exemplele lucrate.
Marcarea valorilor lipsă cu o valoare NaN (not a number) într-un set de date încărcat folosind Python este o bună practică.
Puteți încărca setul de date folosind funcția Pandas read_csv() și specificați „na_values” pentru a încărca valori de „?’ ca fiind lipsă, marcate cu o valoare NaN.
|
1
2
3
4
|
…
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
|
După ce au fost încărcate, putem revizui datele încărcate pentru a confirma că „?” sunt marcate ca fiind NaN.
|
1
2
3
|
…
# rezumați primele câteva rânduri
print(dataframe.head())
|
Apoi putem enumera fiecare coloană și raporta numărul de rânduri cu valori lipsă pentru coloana respectivă.
|
1
2
3
4
5
6
7
|
…
# rezumați numărul de rânduri cu valori lipsă pentru fiecare coloană
for i in range(dataframe.shape):
# numără numărul de rânduri cu valori lipsă
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Lipsesc: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Corelând toate acestea, exemplul complet de încărcare și rezumare a setului de date este prezentat mai jos.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# summarize the horse colic dataset
from pandas import read_csv
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# rezumați primele câteva rânduri
print(dataframe.head())
# rezumați numărul de rânduri cu valori lipsă pentru fiecare coloană
for i in range(dataframe.shape):
# numărați numărul de rânduri cu valori lipsă
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Missing: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Executarea exemplului încarcă mai întâi setul de date și rezumă primele cinci rânduri.
Potem vedea că valorile lipsă care au fost marcate cu un caracter „?” au fost înlocuite cu valori NaN.
În continuare, putem vedea lista tuturor coloanelor din setul de date, precum și numărul și procentul de valori lipsă.
Vezi că unele coloane (de exemplu, indicii de coloană 1 și 2) nu au valori lipsă, iar alte coloane (de exemplu, indicii de coloană 15 și 21) au multe sau chiar o majoritate de valori lipsă.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Missing: 1 (0,3%)
> 1, Lipsesc: 0 (0,0%)
> 2, Lipsesc: 0 (0.0%)
> 3, Lipsesc: 60 (20.0%)
> 4, Lipsesc: 24 (8,0%)
> 5, Lipsesc: 58 (19,3%)
> 6, Lipsesc: 56 (18,7%)
> 7, Lipsesc: 69 (23,0%)
> 8, Lipsesc: 47 (15,7%)
> 9, Lipsesc: 32 (10,7%)
> 10, Lipsesc: 55 (18,3%)
> 11, Lipsesc: 44 (14,7%)
> 12, Lipsesc: 56 (18,7%)
> 13, Lipsesc: 104 (34,7%)
> 14, Lipsesc: 106 (35,3%)
> 15, Lipsesc: 247 (82,3%)
> 16, Lipsesc: 102 (34,0%)
> 17, Lipsesc: 118 (39,3%)
> 18, Lipsesc: 29 (9,7%)
> 19, Lipsesc: 33 (11,0%)
> 20, Lipsesc: 165 (55,0%)
> 21, Lipsesc: 198 (66,0%)
> 22, Lipsesc: 1 (0,3%)
> 23, Lipsesc: 0 (0,0%)
> 24, Lipsește:
> 24, Lipsește: 0 (0.0%)
> 25, Lipsesc: 0 (0.0%)
>: 0 (0.0%)
> 26, Lipsesc: 0 (0.0%)
> 27, Lipsesc: 0 (0.0%)
|
Acum că suntem familiarizați cu setul de date privind colicile cabaline care are valori lipsă, să vedem cum putem folosi imputarea statistică.
Imputarea statistică cu SimpleImputer
Librăria de învățare automată scikit-learn oferă clasa SimpleImputer care suportă imputarea statistică.
În această secțiune, vom explora modul de utilizare eficientă a clasei SimpleImputer.
Transformare de date SimpleImputer
SimpleImputer este o transformare de date care este mai întâi configurată pe baza tipului de statistică de calculat pentru fiecare coloană, de ex.ex. medie.
|
1
2
3
|
…
# define imputer
imputer = SimpleImputer(strategy=’mean’)
|
Apoi imputerul este ajustat pe un set de date pentru a calcula statistica pentru fiecare coloană.
|
1
2
3
|
…
# fit pe setul de date
imputer.fit(X)
|
Imputerul fit se aplică apoi unui set de date pentru a crea o copie a setului de date cu toate valorile lipsă pentru fiecare coloană înlocuite cu o valoare statistică.
|
1
2
3
|
…
# transformă setul de date
Xtrans = imputer.transform(X)
|
Potem demonstra utilizarea sa pe setul de date privind colicile cabaline și confirma că funcționează prin rezumarea numărului total de valori lipsă din setul de date înainte și după transformare.
Exemplul complet este prezentat mai jos.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# imputare statistică transformare pentru setul de date pentru colici de cal
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# load dataset
> url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
> data = dataframe.values
ix = ) if i != 23]
X, y = date, date
# print total lipsuri
print(‘Lipsește: %d’ % sum(isnan(X).flatten())))
# definește imputer
imputer = SimpleImputer(strategy=’mean’)
# ajustează pe setul de date
# imputer.fit(X)
# transformați setul de date
> Xtrans = imputer.transform(X)
# imprimați totalul lipsurilor
> print(‘Lipsește: %d’ % sum(isnan(Xtrans).flatten()))
|
Executarea exemplului încarcă mai întâi setul de date și raportează numărul total de valori lipsă din setul de date ca fiind 1.605.
Transformarea este configurată, ajustată și efectuată, iar noul set de date rezultat nu are valori lipsă, confirmând că a fost efectuată așa cum ne așteptam.
Care valoare lipsă a fost înlocuită cu valoarea medie a coloanei sale.
|
1
2
|
Missing: 1605
Lipsesc: 0
|
Evaluare simplă a calculatoarelor și a modelelor
Este o bună practică să se evalueze modelele de învățare automată pe un set de date folosind validarea încrucișată k-fold.
Pentru a aplica corect imputarea statistică a datelor lipsă și pentru a evita scurgerile de date, este necesar ca statisticile calculate pentru fiecare coloană să fie calculate numai pe setul de date de instruire, apoi să fie aplicate la seturile de instruire și de testare pentru fiecare pliu din setul de date.
Dacă folosim reeșantionarea pentru a selecta valorile parametrilor de reglare sau pentru a estima performanța, imputarea ar trebui încorporată în cadrul reeșantionării.
– Pagina 42, Applied Predictive Modeling, 2013.
Acest lucru poate fi realizat prin crearea unui pipeline de modelare în care prima etapă este imputarea statistică, apoi a doua etapă este modelul. Acest lucru se poate realiza utilizând clasa Pipeline.
De exemplu, Pipeline-ul de mai jos utilizează un SimpleImputer cu o strategie „medie”, urmată de un model Random Forest.
|
1
2
3
4
5
|
…
# define modeling pipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
Potem evalua media…set de date imputate și pipeline-ul de modelare a pădurii aleatoare pentru setul de date privind colicile cabaline cu validare încrucișată repetată de 10 ori.
Exemplul complet este prezentat mai jos.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
25
|
# evaluează imputația medie și aleatorie forest pentru setul de date cu colici de cal
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# define pipe de modelare
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# define model de evaluare
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluează modelul
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(‘Mean Accuracy: %.3f (%.3f)’ % (mean(scoruri), std(scoruri)))
|
Executarea exemplului aplică corect imputarea datelor la fiecare pliu al procedurii de validare încrucișată.
Nota: Rezultatele dumneavoastră pot varia având în vedere natura stocastică a algoritmului sau a procedurii de evaluare, sau diferențele de precizie numerică. Luați în considerare rularea exemplului de câteva ori și comparați rezultatul mediu.
Producția este evaluată utilizând trei repetări ale validării încrucișate de 10 ori și raportează precizia medie de clasificare pe setul de date ca fiind de aproximativ 86.3 la sută, ceea ce reprezintă un scor bun.
|
1
|
Precizia medie: 0,863 (0.054)
|
Compararea diferitelor statistici imputate
Cum știm că utilizarea unei strategii statistice „medii” este bună sau cea mai bună pentru acest set de date?
Răspunsul este că nu știm și că a fost aleasă în mod arbitrar.
Potem proiecta un experiment pentru a testa fiecare strategie statistică și a descoperi care funcționează cel mai bine pentru acest set de date, comparând strategiile medie, mediană, modă (cea mai frecventă) și constantă (0). Precizia medie a fiecărei abordări poate fi apoi comparată.
Exemplul complet este prezentat mai jos.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
32
|
# comparați strategii de imputare statistică pentru setul de date privind colicile cabaline
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
> X, y = data, data
# evaluează fiecare strategie pe setul de date
rezultate = list()
strategii =
for s in strategies:
# create the modeling pipeline
pipeline = Pipeline(steps=)
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# stochează rezultatele
rezultate.append(scoruri)
print(‘>%s %.3f (%.3f)’ % (s, mean(scoruri), std(scoruri)))
# reprezentarea grafică a performanțelor modelului pentru comparație
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
Executarea exemplului evaluează fiecare strategie de imputare statistică pe setul de date privind colicile cabalinelor utilizând validarea încrucișată repetată.
Nota: Rezultatele dumneavoastră pot varia având în vedere natura stocastică a algoritmului sau a procedurii de evaluare, sau diferențele de precizie numerică. Luați în considerare rularea exemplului de câteva ori și comparați rezultatul mediu.
Precizia medie a fiecărei strategii este raportată pe parcurs. Rezultatele sugerează că utilizarea unei valori constante, de exemplu 0, duce la cea mai bună performanță de aproximativ 88,1 %, ceea ce reprezintă un rezultat remarcabil.
|
1
2
3
4
|
>mediana 0.860 (0,054)
>mediana 0,862 (0.065)
>most_frequent 0.872 (0.052)
>constant 0.881 (0.047)
|
La sfârșitul rulării, se creează un grafic box and whisker pentru fiecare set de rezultate, care permite compararea distribuției rezultatelor.
Se poate observa clar că distribuția scorurilor de acuratețe pentru strategia constantă este mai bună decât pentru celelalte strategii.
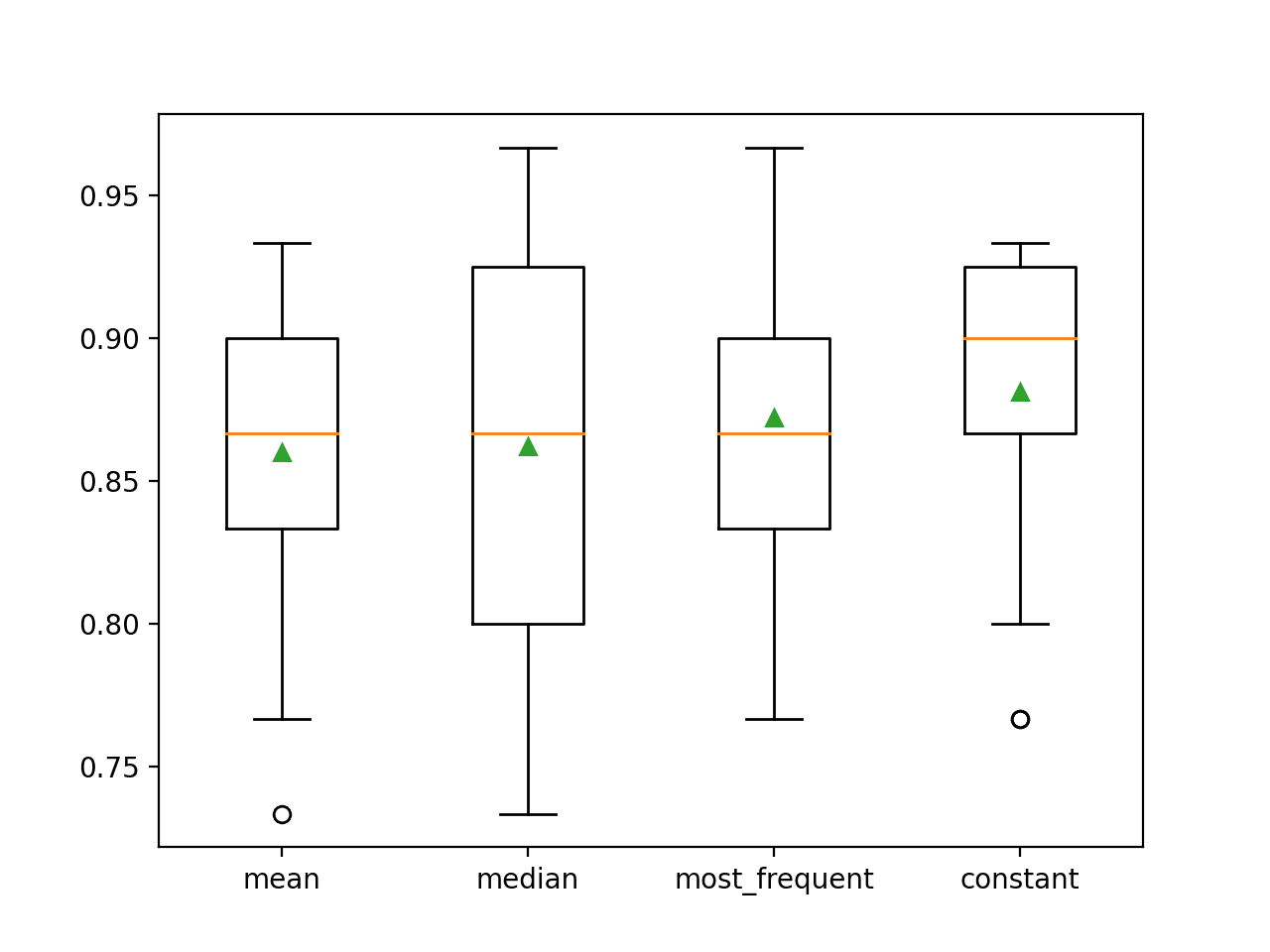
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
Am putea dori să creăm o conductă de modelare finală cu strategia de imputare constantă și algoritmul random forest, apoi să facem o predicție pentru noile date.
Acest lucru poate fi realizat prin definirea conductei și adaptarea acesteia pe toate datele disponibile, apoi apelarea funcției predict(), trecând noile date ca argument.
Important, rândul de date noi trebuie să marcheze orice valori lipsă folosind valoarea NaN.
|
1
2
3
|
…
# define new data
row =
|
Exemplul complet este prezentat mai jos.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
23
|
# imputare constantă strategie și predicție pentru setul de date cu colici de furtun
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
> X, y = date, date
# creați conducta de modelare
pipeline = Pipeline(steps=)
# ajustați modelul
pipeline.fit(X, y)
# definește noile date
> row =
# realizează o predicție
yhat = pipeline.predict()
# rezumă predicția
print(‘Predicted Class: %d’ % yhat)
|
Executarea exemplului se potrivește pipeline-ului de modelare pe toate datele disponibile.
Se definește un nou rând de date cu valorile lipsă marcate cu NaN și se face o predicție de clasificare.
|
1
|
Clasa prezisă: 2
|
Lecturi suplimentare
Această secțiune oferă mai multe resurse pe această temă, dacă doriți să o aprofundați.
Tutoriale conexe
- Rezultate pentru seturi de date standard de clasificare și regresie Machine Learning
- Cum să gestionați datele lipsă cu Python
Cărți
- Bad Data Handbook, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
APIs
- Imputation of missing values, scikit-learn Documentation.
- sklearn.impute.SimpleImputer API.
Dataset
- Horse Colic Dataset
- Horse Colic Dataset Description
Summary
În acest tutorial, ați descoperit cum să utilizați strategiile de imputare statistică pentru datele lipsă în învățarea automată.
În mod specific, ați învățat:
- Valorile lipsă trebuie să fie marcate cu valori NaN și pot fi înlocuite cu măsuri statistice pentru a calcula coloana de valori.
- Cum să încărcați o valoare CSV cu valori lipsă și să marcați valorile lipsă cu valori NaN și să raportați numărul și procentul de valori lipsă pentru fiecare coloană.
- Cum se impută valorile lipsă cu ajutorul statisticilor ca metodă de pregătire a datelor atunci când se evaluează modelele și când se ajustează un model final pentru a face predicții pe date noi.
Aveți întrebări?
Puneți întrebările dvs. în comentariile de mai jos și voi face tot posibilul să vă răspund.
Pregătiți-vă cu pregătirea modernă a datelor!

Pregătiți-vă datele de Machine Learning în câteva minute
…cu doar câteva linii de cod python
Descoperiți cum în noul meu Ebook:
Data Preparation for Machine Learning
Acesta oferă tutoriale de auto-studiu cu cod complet de lucru pe:
Feature Selection, RFE, Data Cleaning, Data Transforms, Data Scaling, Dimensionality Reduction, și multe altele….
Aduceți tehnici moderne de pregătire a datelor la
Proiectele dvs. de învățare automată
Vezi ce conține