De: Derek Colley | Actualizat: 2014-01-29 | Comentarii (5) | Related: Mai multe > Funcții > – Sistem
Problemă
Cercetați să obțineți un eșantion aleatoriu dintr-un set de rezultate ale unei interogări SQL Server. Poate că sunteți în căutarea unui eșantion reprezentativ de date dintr-o bază de date mare de clienți; poate că sunteți în căutarea unor medii sau a unei idei despre tipul de date pe care le dețineți. SELECT TOP N nu este întotdeauna ideal, deoarece valorile aberante ale datelor apar adesea la începutul și la sfârșitul seturilor de date, în special atunci când sunt ordonate alfabetic sau după o anumită valoare scalară. De asemenea, este posibil să fi utilizat TABLESAMPLE, dar acesta are limitări, în special în cazul seturilor de date mici sau înclinate. Poate că șeful dvs. v-a cerut o selecție aleatorie a 100 de nume de clienți și locații; sau participați la un audit și trebuie să preluați un eșantion aleatoriu de date pentru analiză. Cum ați putea îndeplini această sarcină? Consultați acest sfat pentru a afla mai multe.
Soluție
Acest sfat vă va arăta cum să utilizați TABLESAMPLE în T-SQL pentru a prelua eșantioane de date pseudoaleatoare și va vorbi despre elementele interne ale TABLESAMPLE și despre situațiile în care nu este adecvat. De asemenea, vă va arăta o metodă alternativă – o metodă matematică care utilizează NEWID() cuplat cu CHECKSUM și un operator bitwise, notată de Microsoft în articolul TABLESAMPLE TechNet. Vom vorbi puțin despre eșantionarea statistică în general (diferențele dintre eșantionarea aleatorie, sistematică și stratificată) cu ajutorul unor exemple și vom analiza modul în care sunt eșantionate statisticile SQL, ca un exemplu, și opțiunile pe care le putem folosi pentru a suprascrie această eșantionare. După ce ați citit acest sfat, ar trebui să aveți o apreciere a beneficiilor eșantionării față de utilizarea unor metode precum TOP N și să știți cum să aplicați cel puțin o metodă pentru a realiza acest lucru în SQL Server.
Setup
Pentru acest sfat, voi utiliza un set de date care conține o coloană INT de identitate (pentru a stabili gradul de aleatorism la selectarea rândurilor) și alte coloane umplute cu date pseudoaleatoare de diferite tipuri de date, pentru a simula (vag) datele reale dintr-un tabel. Puteți utiliza codul T-SQL de mai jos pentru a configura acest lucru. Ar trebui să dureze doar câteva minute pentru a fi rulat și este testat pe SQL Server 2012 Developer Edition.
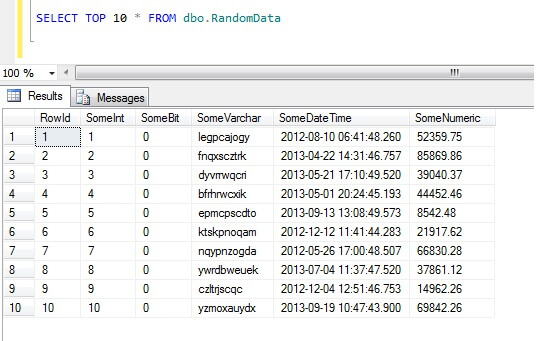
Selectarea primelor 10 rânduri de date produce acest rezultat (doar pentru a vă face o idee despre forma datelor).Ca o paranteză, aceasta este o bucată de cod general pe care am creat-o pentru a genera date aleatoare aleatoare ori de câte ori am avut nevoie – simțiți-vă liberi să o luați și să o măriți/pilotați după bunul plac!
Cum să nu eșantionați date în SQL Server
Acum avem eșantioanele noastre de date, haideți să ne gândim la cele mai proaste moduri de a obține un eșantion. În baza de date AdventureWorks, există un tabel numit Person.Address. Să eșantionăm luând primele 10 rezultate, fără o anumită ordine:
SELECT TOP 10 * FROM Person.Address
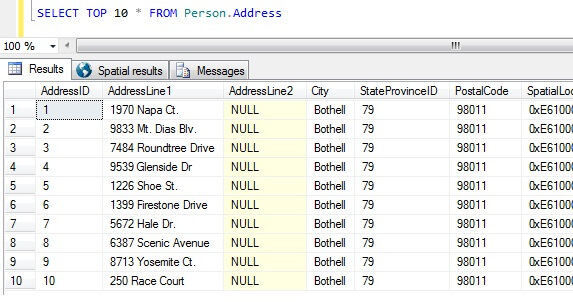
După acest eșantion singur, putem vedea că toate persoanele returnate locuiesc în Bothell și au în comun codul poștal 98011. Acest lucru se datorează faptului că rezultatele au fost specificate să nu fie returnate într-o anumită ordine, dar au fost de fapt returnate în ordinea coloanei AddressID. Rețineți că acesta NU este un comportament garantat pentru datele din heap în special – a se vedea acest citat din BOL:
„De obicei, datele sunt stocate inițial în ordinea în care sunt introduse rândurile în tabel, dar motorul bazei de date poate muta datele în heap pentru a stoca rândurile în mod eficient; astfel, ordinea datelor nu poate fi prezisă. Pentru a garanta ordinea rândurilor returnate dintr-un heap, trebuie să folosiți clauza ORDER BY.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Prelucrând acest set de rezultate, o persoană neinformată despre natura tabelului ar putea concluziona că toți clienții lor locuiesc în Bothell.
Tipuri de eșantionare a datelor în SQL Server
Cele de mai sus sunt în mod clar false, așa că avem nevoie de o modalitate mai bună de eșantionare. Ce-ar fi să luăm un eșantion la intervale regulate în tot tabelul?
Aceasta ar trebui să returneze 47 de rânduri:
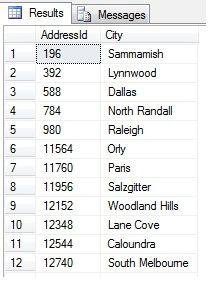
Până aici, totul este bine. Am luat un rând la intervale regulate în tot setul nostru de date și am returnat o secțiune transversală statistică – sau nu? Nu neapărat. Nu uitați, ordinea nu este garantată. Am putea face una sau două concluzii despre aceste date. Haideți să le agregăm pentru a le ilustra. Reexecutați fragmentul de cod de mai sus, dar modificați blocul SELECT final astfel:
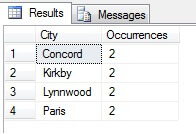
Puteți vedea în exemplul meu că, dintr-un număr total de peste 19 000 de rânduri din tabelul Person.Address, am eșantionat aproximativ 1/4% din rânduri și, prin urmare, pot concluziona că (în exemplul meu), Concord, Kirkby, Lynnwood și Paris au cel mai mare număr de rezidenți și, în plus, sunt la fel de populate. Este corect? Absurd, desigur:
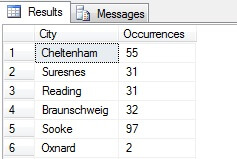
După cum puteți vedea, niciunul dintre cele patru locuințe ale mele nu se afla, de fapt, în primele patru locuri de locuit, așa cum este judecat de acest tabel. Nu numai că eșantionul de date a fost prea mic, dar am agregat acest eșantion minuscul și am încercat să trag o concluzie din el. Acest lucru înseamnă că setul meu de rezultate este nesemnificativ din punct de vedere statistic -în mod ciudat, dovedirea semnificației statistice este una dintre sarcinile majore ale dovezilor atunci când se prezintă rezumate statistice (sau ar trebui să fie) și o cădere majoră a multor infografice populare și datagrame conduse de marketing.
Deci, eșantionarea în acest mod (numită eșantionare sistematică) este eficientă, dar numai pentru o populație semnificativă din punct de vedere statistic. Există factori, cum ar fi periodicitatea și proporția, care pot strica un eșantion – să vedem proporția în acțiune prin prelevarea unui eșantion de 10 orașe din tabelul Person.Address, folosind următorul cod, care obține o listă distinctă de orașe din tabelul Person.Address, apoi selectează 10 orașe din acea listă folosind eșantionarea sistematică:
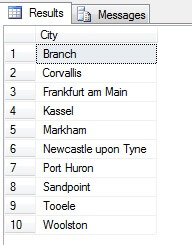
Pare a fi un eșantion bun, nu? Acum haideți să îl comparăm cu un eșantion de orașe NON-distincte listate în ordine crescătoare, adică fiecare al n-lea oraș, unde n este numărul total de rânduri împărțit la 10. Această măsură ține cont de populația eșantionului:
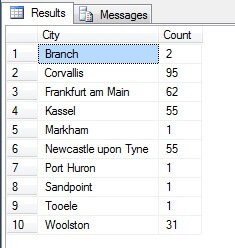
Datele returnate sunt complet diferite – nu din întâmplare, ci prin prezentarea unui eșantion reprezentativ. Rețineți că această listă, pe care am inclus numărătoarea fiecărui oraș din tabelul sursă pentru a evidenția cât de mult joacă populația în selecția datelor, include primele patru orașe cele mai populate din eșantion, ceea ce (dacă luați în considerare o listă ordonată nedistinctă) este cea mai corectă reprezentare. Nu este neapărat cea mai bună reprezentare pentru nevoile dumneavoastră, așa că fiți atenți atunci când alegeți metoda de eșantionare statistică.
Alte metode de eșantionare
Eșantionare pe clustere – aceasta este situația în care populația care urmează să fie eșantionată este împărțită în clustere, sau subansamble, apoi fiecare dintre aceste subansamble este determinată în mod aleatoriu pentru a fi inclusă sau nu în setul de rezultate de ieșire. În cazul în care este inclus, fiecare membru al subansamblului respectiv este returnat în setul de rezultate. A se vedea TABLESAMPLE de mai jos pentru un exemplu în acest sens.
Eșantionare disproporțională – este ca și eșantionarea stratificată, în care membrii grupurilor de subansambluri sunt selectați pentru a reprezenta întregul grup, dar în loc să fie proporțională, pot exista numere diferite de membri din fiecare grup selectați pentru a egaliza reprezentarea din fiecare grup. De exemplu, având în vedere orașele din Person.Address din exemplul din secțiunea de mai sus, primul set de rezultate a fost disproporționat, deoarece nu a luat în considerare populația, dar al doilea set de rezultate a fost proporțional, deoarece a reprezentat numărul de intrări de orașe din tabelul Person.Address. Acest tip de eșantionare este, de fapt, util dacă o anumită categorie este subreprezentată în setul de date, iar proporția nu este importantă (de exemplu, 100 de clienți aleatori din 100 de orașe aleatorii stratificate în funcție de oraș – orașele din subansamblu ar avea nevoie de normalizare – s-ar putea folosi eșantionarea disproporționată).
SQL Server Random Data with TABLESAMPLE
SQL Server vine în mod util cu o metodă de eșantionare a datelor. Să o vedem în acțiune. Folosiți următorul cod pentru a returna aproximativ 100 de rânduri (dacă returnează 0 rânduri, rulați din nou – voi explica imediat) de date din dbo.RandomData pe care am definit-o mai devreme.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
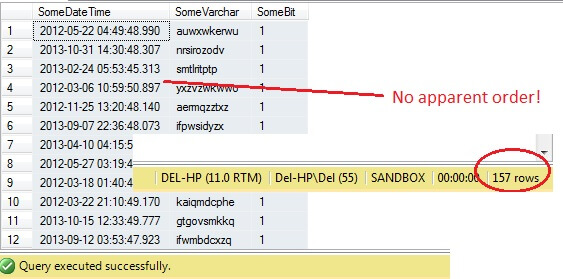
Până aici, totul este bine, nu? Stați puțin – nu putem vedea coloana Id. Să includem asta și să reluăm execuția:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
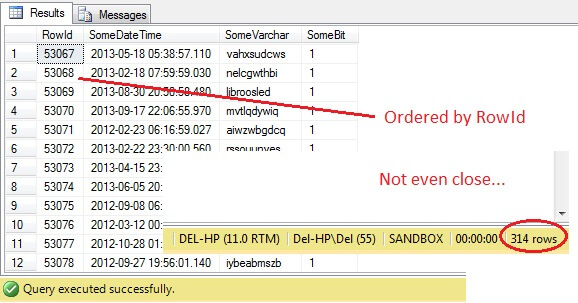
Oh, Doamne – TABLESAMPLE a selectat o felie de date, dar nu este aleatorie – RowId arată o felie clar delimitată, cu o valoare minimă și una maximă. Mai mult, nici nu a returnat exact 100 de rânduri. Ce se întâmplă?
TABLESAMPLE folosește modificatorul implicit SYSTEM. Acest modificator, activat în mod implicit și o specificație ANSI-SQL, adică nu este opțional, va lua fiecare pagină de 8KB pe care se află tabela și va decide dacă va include sau nu toate rândurile de pe acea pagină care se află în acea tabelă în eșantionul produs, în funcție de procentul sau de N Rânduri transmise. Prin urmare, un tabel care se află pe mai multe pagini, adică are rânduri mari de date, ar trebui să returneze un eșantion mai aleatoriu, deoarece vor fi mai multe pagini în eșantion. Nu reușește în cazul unui exemplu ca al nostru, în care datele sunt scalare și mici și rezidă pe doar câteva pagini – dacă un număr oarecare de pagini nu reușesc să facă parte din eșantion, acest lucru poate distorsiona semnificativ eșantionul de ieșire. Acesta este dezavantajul TABLESAMPLE – nu funcționează bine pentru date „mici” și nu ia în considerare distribuția datelor pe pagini. Așadar, aranjamentul datelor pe pagini este în cele din urmă responsabil pentru eșantionul returnat de această metodă.
Îți sună cunoscut? Este, în esență, o eșantionare cluster, în care toți membrii (rândurile) din grupurile (clusterele) selectate sunt reprezentate în setul de rezultate.
Să o testăm pe un tabel mare pentru a sublinia punctul de nescalabilitate inversă. Să identificăm mai întâi cel mai mare tabel din baza de date AdventureWorks. Vom folosi un raport standard pentru acest lucru – folosind SSMS, faceți clic dreapta pe baza de date AdventureWorks2012, mergeți la Reports -> Standard Reports -> Disk Usage by Top Tables. Ordonați după date (KB) făcând clic pe antetul coloanei (este posibil să doriți să faceți acest lucru de două ori pentru o ordine descrescătoare). Veți vedea raportul de mai jos.
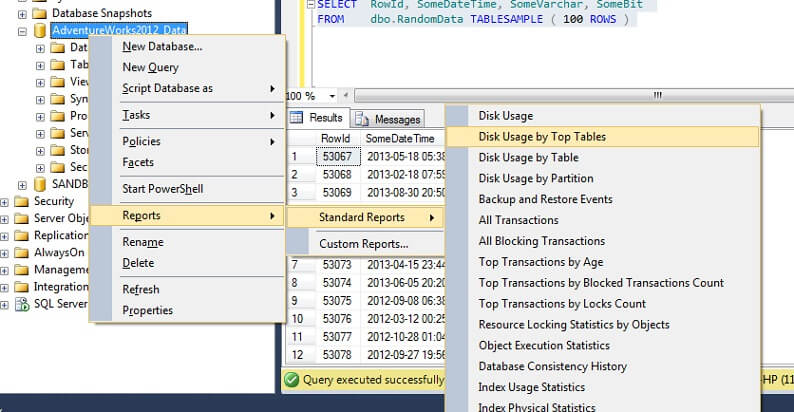
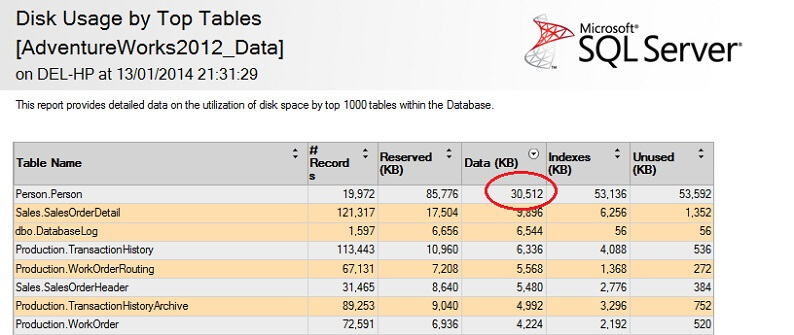
Am încercuit cifra interesantă – Persoana. Tabelul Person consumă 30,5 MB de date și este cel mai mare tabel (după date, nu după numărul de înregistrări). Așadar, să încercăm în schimb să luăm o mostră din acest tabel:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
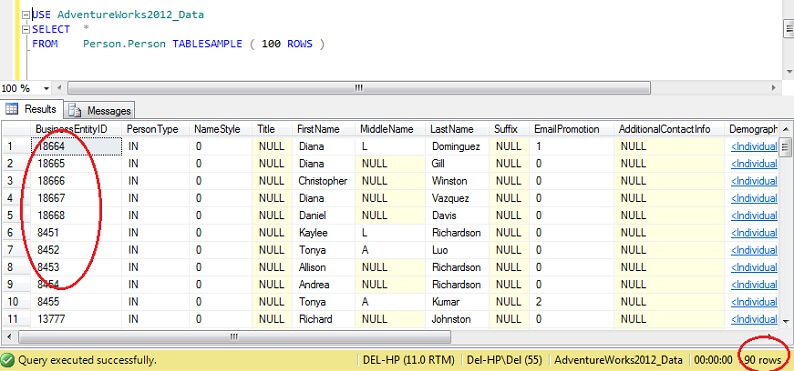
Vezi că suntem mult mai aproape de 100 de rânduri, dar, în mod crucial, nu pare să existe prea multă grupare pe cheia primară (deși există ceva, deoarece există mai mult de 1 rând pe pagină).
În consecință, TABLESAMPLE este bun pentru date mari și devine catastrofal de rău cu cât setul de date este mai mic. Acest lucru nu este bun pentru noi atunci când eșantionăm din date stratificate sau din date grupate, unde luăm multe eșantioane din grupuri mici sau subseturi de date, apoi le agregăm. Să ne uităm la o metodă alternativă, atunci.
Date aleatorii SQL Server cu ORDER BY NEWID()
Iată un citat din BOL despre obținerea unui eșantion cu adevărat aleatoriu:
„Dacă doriți cu adevărat un eșantion aleatoriu de rânduri individuale, modificați interogarea pentru a filtra rândurile în mod aleatoriu, în loc să folosiți TABLESAMPLE. De exemplu, următoarea interogare utilizează funcția NEWID pentru a returna aproximativ un procent din rândurile din tabelul Sales.SalesOrderDetail:
Cum funcționează acest lucru? Să despărțim clauza WHERE și să o explicăm.
Funcția CHECKSUM calculează o sumă de control asupra elementelor din listă. Este discutabil dacă SalesOrderID este chiar necesar, deoarece NEWID() este o funcție care returnează un nou GUID aleatoriu, astfel încât înmulțirea unei cifre aleatoare cu o constantă ar trebui să rezulte în orice caz o cifră aleatoare.Într-adevăr, excluderea SalesOrderID nu pare să facă nicio diferență. Dacă sunteți un statistician pasionat și puteți justifica includerea acesteia, vă rog să folosiți secțiunea de comentarii de mai jos și să-mi spuneți de ce mă înșel!
Funcția CHECKSUM returnează un VARBINARY. Efectuând o operație de tip „bitwise AND” cu 0x7fffffff, care este echivalentul lui (11111111111…) în binar, se obține o valoare zecimală care este, de fapt, o reprezentare a unui șir aleatoriu de 0s și 1s. Împărțind cu coeficientul 0x7fffffff normalizează efectiv această cifră zecimală la o cifră între 0 și 1. Apoi, pentru a decide dacă fiecare rând merită să fie inclus în setul final de rezultate, se folosește un prag de 1/x (în acest caz, 0,01), unde x este procentul de date care trebuie recuperat ca eșantion.
Atenție la faptul că această metodă este o formă de eșantionare aleatorie mai degrabă decât de eșantionare sistematică, astfel încât este probabil să obțineți date din toate părțile datelor sursă, dar cheia aici este că *poate să nu*. Natura eșantionării aleatorii înseamnă că orice eșantion pe care îl colectați poate fi înclinat către un segment al datelor dvs., astfel încât, pentru a beneficia de regresia la medie (tendința către un rezultat aleatoriu, în acest caz), asigurați-vă că luați mai multe eșantioane și că selectați dintr-un subset al acestora, dacă rezultatele dvs. par înclinate. Alternativ, luați eșantioane din subseturi ale datelor dumneavoastră, apoi agregați-le – acesta este un alt tip de eșantionare, numit eșantionare stratificată.
Cum se eșantionează statisticile SQL Server?
În SQL Server, actualizarea automată a statisticilor de coloană sau definite de utilizator are loc ori de câte ori se modifică un prag stabilit de rânduri de tabel pentru un anumit tabel. Pentru 2012, acest prag este calculat la SQRT(1000 * TR), unde TR este numărul de rânduri de tabel din tabel. Înainte de 2005, sarcina de actualizare automată a statisticilor se declanșează la fiecare (500 de rânduri + 20% schimbare) de rânduri din tabel. Odată ce procesul de actualizare automată începe, eșantionarea va *reduce numărul de rânduri eșantionate cu cât tabelul devine mai mare*, cu alte cuvinte, există o relație similară cu proporția inversă între procentul de eșantionare a tabelului și dimensiunea tabelului, dar care urmează un algoritm proprietar.
În mod interesant, acest lucru pare să fie opusul opțiunii TABLESAMPLE (N PERCENT), unde rândurile eșantionate sunt în proporție normală cu numărul de rânduri din tabel. Putem dezactiva statisticile automate (aveți grijă când faceți acest lucru) și să actualizăm statisticile manual – acest lucru se realizează prin utilizarea NORECOMPUTE pe instrucțiunea UPDATE STATISTICS. Cu UPDATE STATISTICS putem suprascrie unele dintre opțiuni – de exemplu, putem alege să eșantionăm N rânduri sau N procente (similar cu TABLESAMPLEAMPLE), să efectuăm un FULLSCAN sau pur și simplu RESAMPLE folosind ultima rată cunoscută.
Pași următori
Pentru lecturi suplimentare, Joseph Sack este un MVP Microsoft cunoscut pentru activitatea sa în domeniul analizei statistice a SQL Server – vă rugăm să consultați mai jos câteva link-uri către activitatea sa, împreună cu câteva referințe la lucrările utilizate pentru acest articol și la câteva sfaturi conexe de pe MSSQLTips.com. Vă mulțumim pentru lectură!
Ultima actualizare: 2014-01-29


Despre autor
 Derek Colley este un DBA și dezvoltator BI cu sediul în Marea Britanie, cu mai mult de un deceniu de experiență de lucru cu SQL Server, Oracle și MySQL.
Derek Colley este un DBA și dezvoltator BI cu sediul în Marea Britanie, cu mai mult de un deceniu de experiență de lucru cu SQL Server, Oracle și MySQL.Vezi toate sfaturile mele
- Mai multe sfaturi pentru dezvoltatorii de baze de date…