Există multe avantaje mari care sunt oferite de virtualizarea infrastructurii dvs. și de rularea resurselor virtuale pentru a deservi sarcinile de lucru critice pentru afaceri. În cazul VMware vSphere, acesta oferă multe caracteristici și capabilități notabile care asigură o disponibilitate ridicată în mediu, precum și programarea automată a sarcinilor de lucru pentru a asigura cea mai eficientă utilizare a hardware-ului și a resurselor în mediul vSphere.
În această postare, vom vorbi despre două dintre caracteristicile de bază la nivel de cluster ale vSphere în cadrul întreprinderii – vSphere HA și DRS. Cel mai probabil le-ați văzut pe ambele menționate împreună cu rularea vSphere în întreprindere.
Ce sunt vSphere HA și DRS? Ce fac acestea?
Cum beneficiați de rularea ambelor în mediul dumneavoastră vSphere?
Să aruncăm o privire la o introducere de bază în HA și DRS în VMware vSphere și să vedem cum se compară și care sunt beneficiile utilizării lor.
Clustere VMware vSphere
Unul dintre avantajele evidente și cele mai bune practici atunci când se utilizează VMware vSphere pentru a rula sarcini de lucru critice pentru afaceri este de a rula un Cluster vSphere.
Ce este un vSphere Cluster?
Un vSphere Cluster este o configurație formată din mai multe servere VMware ESXi agregate împreună ca un grup de resurse care contribuie la vSphere Cluster. Resursele, cum ar fi computerele CPU, memoria și, în cazul stocării definite prin software, cum ar fi vSAN, stocarea, sunt contribuite de fiecare gazdă ESXi.
De ce este importantă rularea încărcăturilor de lucru critice pentru afacerea dvs. pe un cluster vSphere Cluster?
Când vă gândiți la avantajele oferite de rularea unui hipervizor, acesta permite rularea mai multor servere pe un singur set de hardware fizic. Virtualizarea încărcăturilor de lucru în acest mod oferă multe beneficii de eficiență în ordine de mărime în comparație cu rularea unui singur server pe un singur set de hardware fizic.
Cu toate acestea, acest lucru poate deveni, de asemenea, călcâiul lui Ahile al unei soluții virtualizate, deoarece impactul unei defecțiuni hardware poate afecta mult mai multe servicii și aplicații critice pentru afaceri. Vă puteți imagina că, dacă aveți o singură gazdă VMware ESXi care rulează multe VM-uri, impactul pierderii acelei singure gazde ESXi ar fi imens.
Acesta este momentul în care rularea mai multor gazde VMware ESXi într-un vSphere Cluster strălucește cu adevărat.
Totuși, vă puteți întreba, cum poate simpla rulare a mai multor gazde într-un cluster să vă îmbunătățească disponibilitatea ridicată? Cum „știe” o gazdă din vSphere Cluster dacă o altă gazdă a eșuat? Există un mecanism special care este utilizat pentru a se ocupa de gestionarea disponibilității ridicate a sarcinilor de lucru care rulează pe un vSphere Cluster? Da, există. Să vedem.
Ce este HA în VMware?
VMware și-a dat seama de necesitatea de a avea un mecanism pentru a putea oferi protecție împotriva unei gazde ESXi eșuate în vSphere Cluster. Având în vedere această nevoie, s-a născut VMware High-Availability (HA).
VMware vSphere HA oferă următoarele beneficii:
VMware vSphere HA este rentabil și permite reporniri automate ale mașinilor virtuale și ale gazdelor vSphere atunci când există o întrerupere a serverului sau o defecțiune a sistemului de operare detectată în mediul vSphere
Monitorizează toate gazdele VMware vSphere & VM din clusterul vSphere
Furnizează o disponibilitate ridicată pentru majoritatea aplicațiilor care rulează în mașinile virtuale, indiferent de sistemul de operare și de aplicații.
Frumusețea soluției VMware vSphere HA care este implementată prin intermediul VMware Cluster este simplitatea cu care poate fi configurată. Cu câteva clicuri printr-o interfață bazată pe un asistent, poate fi configurată o disponibilitate ridicată. Cum se compară acest lucru cu tehnologiile tradiționale de „clustering”?
Comparație între Windows Server Failover Clustering
Windows Server Failover Clustering (WSFC) a devenit tehnologia de clustering la care se gândesc cei mai mulți atunci când au în minte o tehnologie de clustering. Problema văzută cu WSFC este că necesită multă expertiză specializată pentru a rula corect serviciile WSFC, în special atunci când vine vorba de actualizări, aplicare de patch-uri și sarcini operaționale generale.
Contrastând vSphere HA cu WSFC, cheltuielile operaționale sunt minime în comparație cu WSFC. Există puține șanse ca HA să fie configurat incorect, deoarece acesta este activat sau nu pe un cluster. Cu WSFC, există multe considerente care trebuie luate în considerare la configurarea WSFC pentru a evita atât greșelile de configurare, cât și cele de implementare. Gândiți-vă la următoarele:
- Failover clustering necesită aplicații care suportă clustering (SQL, etc)
- Failover clustering necesită ca quorum-ul să fie configurat corect
- Nu este suportat de multe sisteme de operare și aplicații moștenite
- Exigă o complexitate a numelor de rețea de cluster, a resurselor și a rețelelor
Windows Server Failover Clustering este promovat pentru a oferi un timp de nefuncționare aproape zero la nivel de aplicație. Cu toate acestea, atunci când adăugați expertiza necesară pentru o soluție HA care să funcționeze corect, împreună cu implementarea corectă a WSFC, riscurile pot începe să depășească beneficiile utilizării WSFC pentru o disponibilitate ridicată a aplicațiilor și serviciilor. Acest lucru este valabil mai ales atunci când pentru majoritatea organizațiilor care s-ar putea să nu aibă cu adevărat nevoie de o soluție cu „timp de nefuncționare zero”. În plus, aplicația dvs. trebuie să fie proiectată pentru a profita de WSFC și pentru a funcționa în mod corespunzător cu tehnologia WSFC.
În timp ce vSphere HA necesită o repornire a mașinilor virtuale pe o gazdă sănătoasă atunci când are loc un failover, nu necesită instalarea de software suplimentar în interiorul mașinilor virtuale invitate, nu necesită configurații complexe ale unor tehnologii de clusterizare suplimentare, iar aplicațiile sau sistemele de operare nu trebuie să fie proiectate pentru a funcționa cu o anumită tehnologie de clusterizare.
Sistemele de operare și aplicațiile vechi au, în general, capacități limitate în ceea ce privește tehnologiile suportate pentru a asigura o disponibilitate ridicată. Astfel, este posibil să nu existe literalmente nicio opțiune nativă pentru a oferi funcționalitate de failover în cazul unor defecțiuni hardware.
Mecanismul de înaltă disponibilitate vSphere HA funcționează și este simplu de implementat, configurat și gestionat. În plus, aceasta este o tehnologie care este bine testată în mii de medii ale clienților VMware, deci are un istoric stabil și lung de implementări de succes.
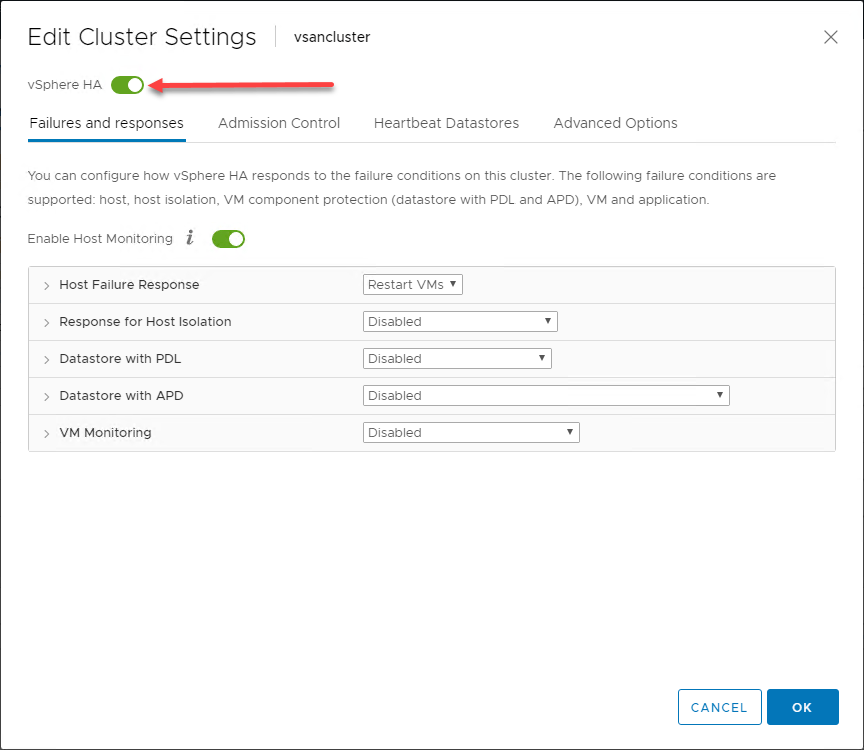
General Overview of vSphere HA Behavior
Utilizând avantajele oferite gazdelor ESXi dintr-un vSphere Cluster, în forma sa cea mai elementară, vSphere HA implementează un mecanism de monitorizare între gazdele din vSphere Cluster. Mecanismul de monitorizare oferă o modalitate de a determina dacă una dintre gazdele din vSphere Cluster a eșuat.
În infograficul de mai jos, un vSphere Cluster cu două noduri a suferit o defecțiune a uneia dintre gazdele ESXi din vSphere Cluster. Clusterul vSphere Cluster are activat vSphere HA la nivel de cluster.
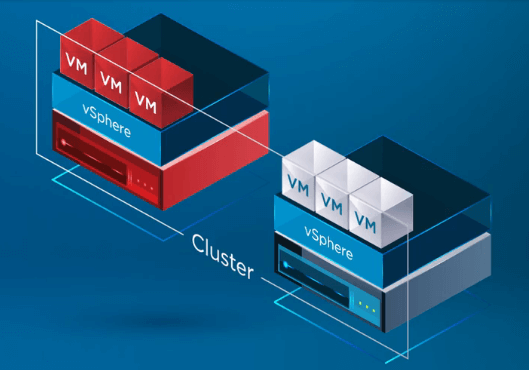
După ce vSphere HA recunoaște că o gazdă din vSphere Cluster a avut o defecțiune, procesul HA mută înregistrarea VM-urilor de pe gazda avariată pe o gazdă sănătoasă.
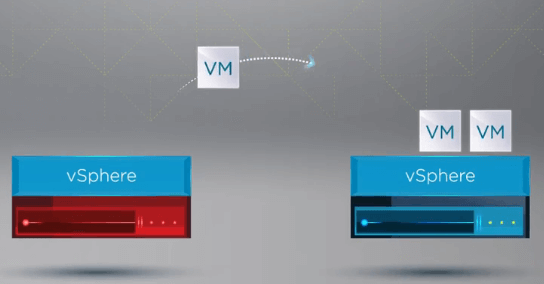
După ce VM-urile sunt înregistrate pe o gazdă sănătoasă, vSphere HA repornește toate VM-urile de pe gazda eșuată pe o gazdă ESXi sănătoasă din clusterul în care au fost reînregistrate VM-urile. Singurul timp de nefuncționare înregistrat este cel de repornire a VM-urilor pe o gazdă sănătoasă din clusterul vSphere.
VSphere HA Technical Overview
Precondiții pentru vSphere HA
S-ar putea să vă întrebați ce condiții prealabile de bază pot fi necesare pentru ca vSphere HA să funcționeze. Să aveți nevoie pur și simplu de un VMware Cluster pentru a activa HA? Spre deosebire de Windows Server Failover Clustering, există doar câteva cerințe care trebuie să fie îndeplinite pentru ca HA să funcționeze.
Cerințe:
- Acel puțin două gazde ESXi
- Acel puțin 4 GB de memorie configurată pe fiecare gazdă
- vCenter Server
- Licență vSphere Standard
- Stocare partajată pentru VM-uri
- Pingable gateway sau un alt nod de rețea fiabil
Dacă observați, nu este necesară nicio componentă de cvorum, nu este implicată nicio denumire complexă a rețelei și nicio altă resursă specială a clusterului care trebuie să fie în funcțiune.
Citește mai mult: Cum se configurează un cluster vSphere High Availability
VMware vSphere HA Master vs Subordinate Hosts
Când activați vSphere HA pe un cluster, o anumită gazdă din clusterul vSphere este desemnată ca master al vSphere HA. Celelalte gazde ESXi din vSphere Cluster sunt configurate ca subordonate în configurația vSphere HA.
Ce rol joacă gazda ESXi vSphere HA care este desemnată ca maestru? Nodul maestru vSphere HA:
- Monitorizează starea gazdelor subordonate slave – Dacă gazda subordonată eșuează sau este inaccesibilă, gazda maestru identifică ce mașini virtuale trebuie repornite
- Monitorizează starea de alimentare a tuturor mașinilor virtuale care sunt protejate. În cazul în care o VM eșuează, nodul vSphere HA principal se asigură că VM este repornită. Maestrul vSphere HA decide unde are loc repornirea VM (care gazdă ESXi).
- Măsoară toate gazdele clusterului și VM-urile care sunt protejate de vSphere HA
- Este desemnat ca mediator între vSphere Cluster și vCenter Server. Maestrul HA raportează starea de sănătate a clusterului către vCenter și oferă interfața de gestionare a clusterului pentru vCenter Server
- Pute să ruleze el însuși VM-uri și să monitorizeze starea VM-urilor
- Stochează VM-urile protejate în stocurile de date ale clusterului
vSphere HA Subordinate Hosts:
- Execută mașinile virtuale la nivel local
- Monitorizează stările de execuție ale mașinilor virtuale din clusterul vSphere
- Raportează actualizări de stare către vSphere HA master
Elegerea gazdei master și eșecul master
Cum este selectată gazda master vSphere HA? Atunci când vSphere HA este activat pentru un cluster, toate gazdele active (fără mod de întreținere etc.) participă la alegerea gazdei master. Dacă gazda master aleasă eșuează, are loc o nouă alegere în care o nouă gazdă master HA este aleasă pentru a îndeplini acest rol.
VMware vSphere HA Cluster Failure Types
Într-un cluster vSphere HA activat, există trei tipuri de defecțiuni care pot avea loc pentru a declanșa un eveniment de failover vSphere HA. Aceste tipuri de eșecuri ale gazdelor sunt:
- Eșec – Un eșec este intuitiv ceea ce credeți. O gazdă a încetat să mai funcționeze sub o formă sau alta din cauza unor probleme hardware sau de altă natură.
- Izolare – Izolarea unei gazde se întâmplă, în general, din cauza unui eveniment de rețea care izolează o anumită gazdă de celelalte gazde din clusterul vSphere HA.
- Partition – Un eveniment de partiție se caracterizează prin faptul că o gazdă subordonată pierde conectivitatea de rețea cu gazda principală a clusterului vSphere HA.
Heartbeating, Failure Detection, and Failure Actions
Cum determină nodul principal dacă există o defecțiune a unei anumite gazde?
Există mai multe mecanisme diferite pe care nodul principal le utilizează pentru a determina dacă o gazdă a eșuat:
- Nodul principal face schimb de bătăi de inimă în rețea cu celelalte gazde din cluster la fiecare secundă.
- După ce bătăile de inimă în rețea au eșuat, gazda principală verifică dacă gazda principală face schimb de bătăi de inimă cu unul dintre stocurile de date. Apoi trimite ping-uri ICMP la adresele IP de management ale acesteia
- Dacă nu este posibilă comunicarea directă cu agentul HA al unei gazde subordonate de la gazda principală și dacă ping-urile ICMP la adresa de management eșuează, gazda este considerată ca fiind eșuată, iar VM-urile sunt repornite pe o altă gazdă.
- Dacă se constată că gazda subordonată face schimb de bătăi de inimă cu depozitul de date, gazda principală presupune că gazda se află într-o partiție de rețea sau este izolată de rețea. În acest caz, magistrala monitorizează pur și simplu gazda și VM-urile
- Isolarea rețelei este evenimentul în care o gazdă subordonată rulează, dar nu mai poate fi văzută din perspectiva unui agent de gestionare HA din rețeaua de gestionare. Dacă o gazdă încetează să mai vadă acest trafic, aceasta încearcă să facă ping la adresele de izolare a clusterului. Dacă acest ping eșuează, gazda declară că este izolată de rețea
- În acest caz, nodul principal monitorizează VM-urile care rulează pe gazda izolată. Dacă VM-urile se opresc pe gazda izolată, nodul principal repornește VM-urile pe o altă gazdă
Datastore Heartbeating
După cum am menționat mai sus, una dintre metricile utilizate pentru a determina detectarea defecțiunilor este datastore heartbeating. Ce este aceasta mai exact? VMware vCenter selectează un set preferat de datastore-uri pentru heartbeating. Apoi, vSphere HA creează un director la rădăcina fiecărui datastore care este utilizat atât pentru datastore heartbeating, cât și pentru a ține la curent cu lista de VM protejate. Acest director se numește .vSphere-HA.
Există o notă importantă de reținut în ceea ce privește datastore-urile vSAN. Un datastore vSAN nu poate fi utilizat pentru datastore heartbeating. Dacă aveți doar un datastore vSAN disponibil, nu pot fi utilizate datastore-uri heartbeat.
- VM and Application Monitoring
O altă caracteristică extrem de puternică a vSphere HA este capacitatea de a monitoriza mașinile virtuale individuale prin VMware Tools și de a reporni orice mașină virtuală care nu răspunde la bătăile inimii VMware Tools. Application Monitoring poate reporni o mașină virtuală în cazul în care nu se primesc bătăile inimii pentru o aplicație care rulează.
- VM Monitoring – Cu VM Monitoring, serviciul VM Monitoring utilizează VMware Tools pentru a determina dacă fiecare mașină virtuală rulează prin verificarea atât a bătăilor inimii, cât și a I/O pe disc generate de VMware Tools. În cazul în care aceste verificări eșuează, serviciul VM Monitoring determină cel mai probabil că sistemul de operare invitat a eșuat și VM este repornit. Verificarea suplimentară a I/O a discului ajută la evitarea oricăror reporniri inutile ale mașinilor virtuale dacă mașinile virtuale sau aplicațiile încă funcționează corect.
Application Monitoring – Funcția de monitorizare a aplicațiilor este activată prin obținerea SDK-ului corespunzător de la un furnizor de software terț care permite configurarea unor bătăi de inimă personalizate pentru aplicațiile care urmează să fie monitorizate de procesul vSphere HA. La fel ca în cazul procesului de monitorizare a mașinilor virtuale, dacă nu se mai primesc bătăi de inimă pentru aplicații, mașina virtuală este resetată.
Ambele funcții de monitorizare pot fi configurate în continuare cu sensibilitatea monitorizării și, de asemenea, cu resetarea maximă per VM pentru a ajuta la evitarea resetării repetate a VM-urilor pentru erori software sau fals pozitive.
VMware vSphere HA este o modalitate excelentă de a vă asigura că vSphere Clusterul dvs. oferă o disponibilitate ridicată foarte rezistentă pentru a vă proteja împotriva defecțiunilor generale ale gazdelor ESXi din vSphere Cluster.
Cum rămâne cu asigurarea utilizării eficiente a resurselor în vSphere Clusterul dvs. Să aruncăm o privire asupra următoarei prevederi vSphere Cluster pentru a vă ajuta să asigurați utilizarea eficientă a resurselor și capacității vSphere Clusterului dvs. vSphere.
Ce este DRS în VMware?
VMware Distributed Resource Scheduler (DRS) este o caracteristică foarte puternică atunci când se execută vSphere Clusters. Aceasta asigură programarea și echilibrarea încărcăturii în cadrul unui vSphere Cluster. VMware DRS este caracteristica care se găsește în vSphere Clusters și care asigură faptul că mașinilor virtuale care rulează în cadrul mediului vSphere le sunt furnizate resursele de care au nevoie pentru a funcționa eficient și eficace.
MV-urile sunt, în general, supuse DRS încă de la începutul vieții, deoarece de la prima lor pornire într-un cluster activat pentru DRS, DRS plasează VM-urile pe cea mai bună gazdă configurată pentru a furniza resursele necesare pentru VM imediat ce sunt pornite. În plus, DRS se străduiește să mențină clusterele vSphere echilibrate din punctul de vedere al utilizării resurselor.
Chiar dacă un cluster vSphere Cluster este echilibrat la un anumit moment dat, VM-urile pot fi mutate sau se pot schimba în așa fel încât un dezechilibru al resurselor clusterului se poate strecura din nou în mediu. Atunci când clusterele devin dezechilibrate, acest lucru poate fi în detrimentul performanței generale a mașinilor virtuale care rulează într-un vSphere Cluster.
În mod implicit, DRS rulează automat pe un cluster vSphere la fiecare cinci minute pentru a determina echilibrul unui cluster vSphere și pentru a vedea dacă trebuie făcute modificări pentru a utiliza mai eficient resursele.
Requisite VMware DRS
Pentru a profita de VMware DRS, există mai multe cerințe care trebuie îndeplinite pentru a asigura valorificarea funcționalității Distributed Resource Scheduler. Acestea includ:
- Un cluster de gazde ESXi
- vCenter Server
- Licență Enterprise Plus
- vMotion este necesară pentru echilibrarea automată a sarcinii
Citește mai mult: Cum se configurează un cluster vSphere DRS
Acțiuni VMware DRS
Când VMware DRS rulează pe un cluster vSphere la fiecare cinci minute, acesta determină dacă există dezechilibre care există în cluster. În caz afirmativ, se va efectua un vMotion pentru a muta VM-urile desemnate de la o gazdă ESXi la alta.
Cum anume determină DRS dacă mașinile virtuale sunt mai potrivite pe o gazdă ESXi sau alta?
DRS rulează un algoritm special pentru a determina gazda ESXi potrivită care ar trebui să găzduiască o anumită VM. Atunci când o mașină virtuală este pornită, acest algoritm ia în considerare distribuția resurselor în vSphere Cluster după ce se asigură că nu există încălcări ale constrângerilor dacă o anumită mașină virtuală este plasată pe o anumită gazdă ESXi.
În plus, se ia în considerare cererea mașinii virtuale în sine, astfel încât se speră că aceasta nu va fi niciodată lipsită de resurse atunci când este pornită. Ce este inclus în cererea VM? Cererea unei VM include cantitatea de resurse necesare pentru a funcționa.
- Pentru cererea de CPU, aceasta este calculată pe baza cantității de CPU pe care VM-ul o consumă în prezent
- Pentru memorie, cererea este calculată pe baza formulei: VM memory demand = Function(Active memory used, Swapped, Shared) + 25% (idle consumed memory). Acest lucru arată că echilibrul de memorie DRS se bazează în principal pe utilizarea memoriei active a unui VM, luând în considerare în același timp o cantitate mică de memorie consumată în inactivitate ca o rezervă pentru orice creștere a volumului de lucru.
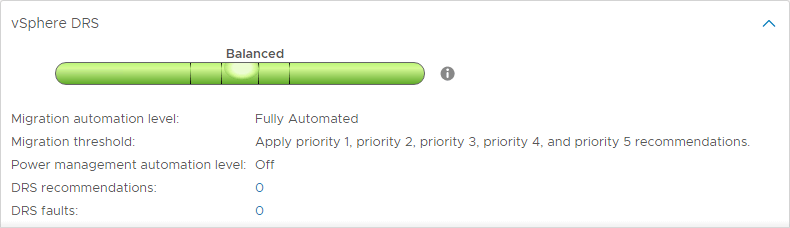
Niveluri de automatizare DRS
Una dintre caracteristicile interesante ale DRS este reprezentată de nivelurile de automatizare DRS. În timp ce DRS continuă să scaneze vSphere Cluster și să furnizeze recomandări la fiecare 5 minute, puteți determina dacă DRS este sau nu capabil să pună în aplicare recomandările sale în mod automat sau doar să sugereze modificări care ar trebui efectuate. DRS are trei niveluri de automatizare DRS. Acestea includ:
- Complet automatizat – În abordarea complet automatizată, DRS aplică automat atât recomandările de plasare inițială, cât și cele de echilibrare a încărcăturii
- Parțial automatizat – Cu automatizarea parțială, DRS aplică recomandările doar pentru plasarea inițială a VM-urilor
- Manual – În modul manual, trebuie să aplicați recomandările atât pentru plasarea inițială, cât și pentru recomandările de echilibrare a încărcăturii
DRS Migration Thresholds
DRS include o altă setare foarte utilă pentru a controla cantitatea de dezechilibru care va fi tolerată înainte de a se face recomandările DRS. Există cinci praguri de migrare DRS pentru a controla cantitatea de dezechilibru tolerată.
Scala este de la 1 (cel mai conservator) la 5 (cel mai agresiv).
Cu setări mai agresive, DRS tolerează mai puțin dezechilibru într-un cluster. Cu cât este mai conservator, cu atât DRS tolerează mai mult dezechilibrul.

Reguli VM/Host VMware DRS
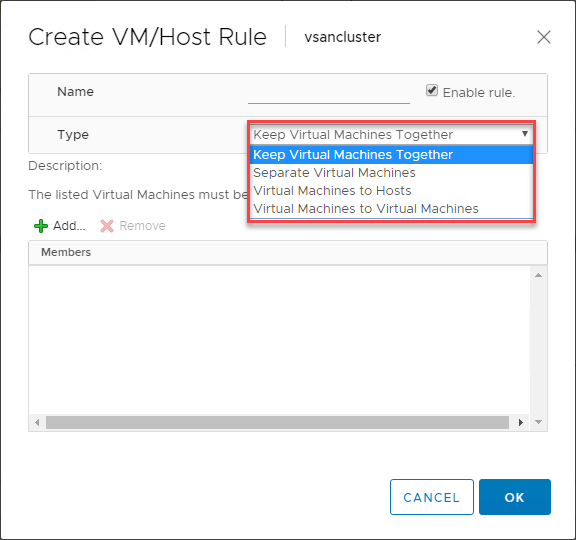
Există o caracteristică extrem de utilă care se găsește atunci când se utilizează VMware DRS pentru a controla plasarea mașinilor virtuale în clusterele compatibile cu vSphere DRS. Regulile VM/Host Rules vă permit să rulați anumite VM-uri pe anumite gazde ESXi. Vă puteți gândi la aceasta ca la niște reguli de afinitate, într-un fel.
Regulile VM/Host vă permit să:
- Măinile virtuale sunt ținute împreună
- Separarea mașinilor virtuale
- Alegarea mașinilor virtuale la anumite gazde
- Alegarea mașinilor virtuale la mașini virtuale
Mai jos este prezentat un exemplu de creare a unei reguli VM/Host pentru mașini virtuale și gazde ESXi.
Ce tip de caz de utilizare există pentru aceste reguli VM/Host? Unul dintre cazurile de utilizare clasice care există este cu controlorii de domeniu. În general, dacă rulați toate controlorii de domeniu într-un mediu virtualizat, cum ar fi un vSphere Cluster, doriți să vă asigurați că aveți mașinile virtuale ale controlorilor de domeniu separate unele de altele în cadrul clusterului. În acest fel, dacă aveți o gazdă ESXi care cade împreună cu unul dintre controlorii de domeniu, aveți în continuare un controler de domeniu care face obiectul unei reguli Separate Virtual Machines (Mașini virtuale separate) care îl ține în afara aceleiași gazde ca și un alt DC.
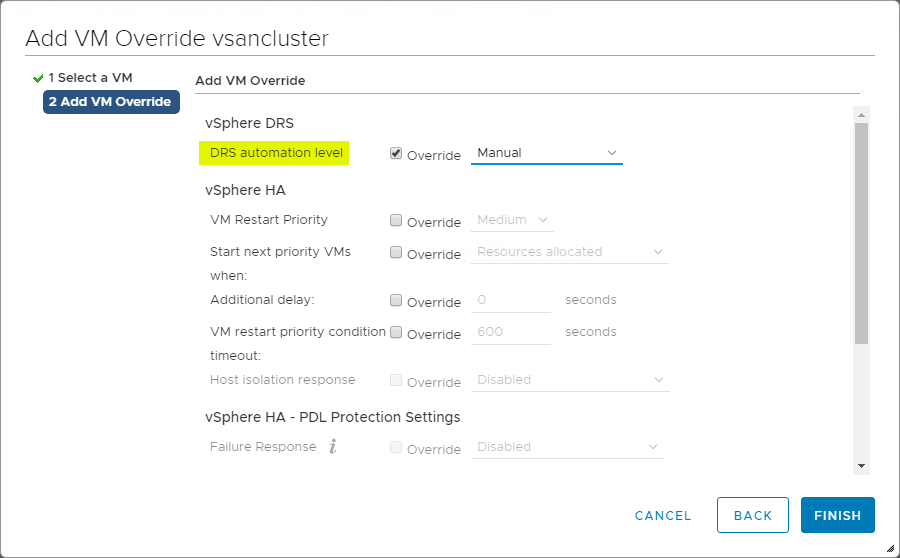
VM Overrides for DRS
Clusterul vSphere oferă o granularitate mare pentru operațiunile care afectează mașinile virtuale individuale din cadrul clusterului vSphere. Puteți crea VM Overrides pentru a suprascrie setările globale stabilite la nivel de cluster pentru HA și DRS pentru a defini setări mai specifice pentru fiecare VM individuală.
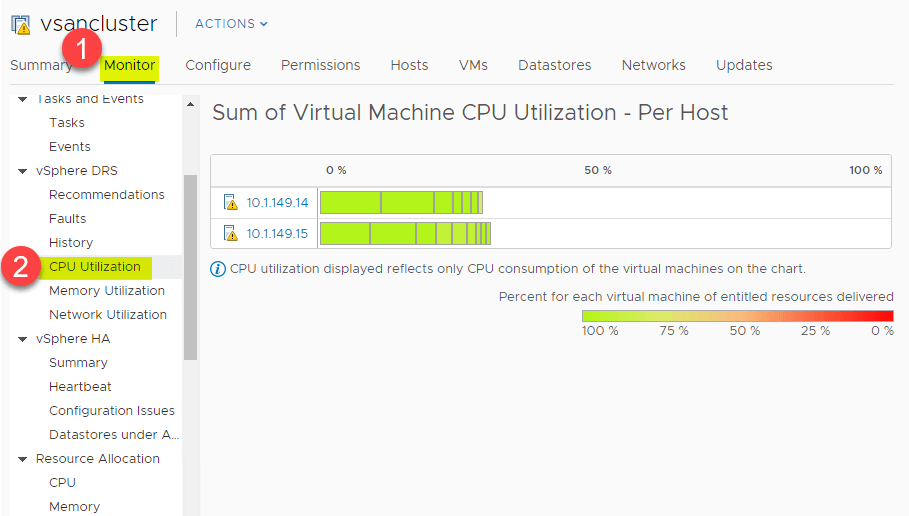
CPU and Memory Utilization Summary
DRS oferă o mare vizualizare la nivel înalt a rezumatului utilizării CPU a resurselor CPU ale gazdelor ESXi din cadrul clusterului vSphere Cluster. Navigați la > Settings > Monitor > vSphere DRS > CPU Utilization.
Aceeași privire de ansamblu la nivel înalt poate fi vizualizată și pentru consumul de memorie. Navigați la > Settings > Monitor > vSphere DRS > Memory Utilization
Cel mai bun din ambele lumi
Este VMware vSphere HA și VMware DRS tehnologii concurente?
Nu, ele nu sunt. De fapt, este foarte recomandat să folosiți atât vSphere HA, cât și VMware DRS împreună pentru a combina failoverul automat cu caracteristicile și funcționalitățile de echilibrare a încărcăturii. Astfel, se obține un mediu vSphere mult mai rezistent și mai echilibrat.
Dacă are loc o defecțiune a unei gazde ESXi, vSphere HA va reporni VM-urile pe gazdele sănătoase rămase într-un vSphere Cluster. Așadar, prima prioritate, desigur, este disponibilitatea resurselor mașinilor virtuale. VMware DRS va rula apoi și va determina dacă există vreun dezechilibru între gazdele ESXi care rulează sarcinile de lucru și va face recomandări pentru a rezolva orice dezechilibru din cluster pe baza pragului de migrare configurat. În funcție de nivelul de automatizare, aceste recomandări vor fi fie puse în aplicare în mod automat, fie doar recomandate dacă nu sunt complet automatizate.
Gânduri finale despre VMware vSphere HA și DRS
Executarea atât a VMware vSphere HA, cât și a DRS sunt foarte recomandate într-un cluster vSphere de producție. Utilizarea ambelor tehnologii ajută la asigurarea unei disponibilități ridicate a volumelor de lucru și asigură că acestea dispun în permanență de resursele necesare în funcție de cererile de CPU/memorie ale mașinilor virtuale.
Înțelegerea modului în care funcționează ambele mecanisme vă ajută, în calitate de administrator vSphere, să valorificați ambele tehnologii în cel mai bun mod posibil și în conformitate cu cele mai bune practici. Printre beneficiile pe care le aduc ambele tehnologii, fiecare funcție este extrem de ușor de activat și configurat. Cu câteva clicuri simple în proprietățile clusterelor dumneavoastră vSphere, puteți începe rapid să beneficiați de aceste caracteristici disponibile la nivel de cluster.
Să urmăriți fluxurile noastre Twitter și Facebook pentru noi versiuni, actualizări, postări pătrunzătoare și multe altele.
.