Introducere
Dacă vă analizați datele folosind regresia multiplă și oricare dintre variabilele independente au fost măsurate pe o scară nominală sau ordinală, trebuie să știți cum să creați variabile fictive și să interpretați rezultatele acestora. Acest lucru se datorează faptului că variabilele independente nominale și ordinale, cunoscute mai larg ca variabile independente categoriale, nu pot fi introduse direct într-o analiză de regresie multiplă. În schimb, acestea trebuie să fie convertite în variabile fictive. Excepție fac variabilele independente ordinale care sunt introduse într-o regresie multiplă ca variabile independente continue, care nu trebuie să fie convertite în variabile fictive. Prin urmare, în acest ghid vă arătăm cum să creați variabile fictive atunci când aveți variabile independente categorice.
În primul rând, prezentăm exemplul pe care îl folosim pentru a arăta cum să creăm variabile fictive în SPSS Statistics, înainte de a explica cum să vă configurați datele în ferestrele Variable View și Data View din SPSS Statistics astfel încât să puteți crea variabile fictive. Dacă nu sunteți familiarizat cu utilizarea variabilelor fictive, vă recomandăm să citiți apoi câteva dintre principiile de bază ale variabilelor fictive și ale codării fictive, inclusiv: (a) numărul de variabile fictive pe care trebuie să le creați în analiza dumneavoastră; și (b) modul de creare a variabilelor fictive și a codării fictive. În secțiunea Procedură care urmează, prezentăm procedura simplă, în 3 pași, Create Dummy Variables (Crearea de variabile fictive) din SPSS Statistics, care poate fi utilizată pentru a crea variabile fictive. În cele din urmă, explicăm ieșirea din SPSS Statistics după rularea procedurii Create Dummy Variables, inclusiv modul în care variabilele dvs. fictive vor fi acum configurate în ferestrele Variable View și Data View din SPSS Statistics.
Nota: Dacă considerați că procedurile din acest ghid nu acoperă tipul de variabile fictive pe care doriți să le creați, vă rugăm să ne contactați. Este posibil să putem adăuga un alt ghid pe site pentru a vă ajuta.
SPSS Statistics
Exemplu folosit în acest ghid
În acest ghid vom folosi exemplul a 10 triatloniști cărora li s-a cerut să își aleagă sportul preferat dintre cele trei sporturi pe care le practică atunci când fac un triatlon: înot, ciclism și alergare. Răspunsurile lor au fost înregistrate în variabila nominală independentă, sport_preferat, care are trei categorii: „înot”, „ciclism” și „alergare”. Această variabilă independentă nominală, sport_preferat, urma să fie inclusă într-o analiză de regresie multiplă care avea, de asemenea, o serie de variabile independente continue. Deoarece această variabilă independentă era categorică (adică variabilele nominale și variabilele ordinale pot fi clasificate, în linii mari, ca variabile categorice), a trebuit să se creeze variabile fictive înainte ca aceasta să poată fi introdusă în analiza de regresie multiplă.
Important: Observați că sportul_preferat este o variabilă nominală, dar puteți crea, de asemenea, variabile fictive pentru o variabilă ordinală. Mai mult, procesul de creare a variabilelor fictive este același indiferent dacă aveți o variabilă ordinală sau nominală, cu excepția unei mici modificări pe care trebuie să o faceți la configurarea datelor, care este explicată mai jos.
Nota 1: „Categoriile” unei variabile independente categoriale sunt, de asemenea, denumite „grupuri” sau „niveluri”, dar termenul „niveluri” este, de obicei, rezervat pentru categoriile care au o ordine (de exemplu, variabila independentă ordinală, „nivel de fitness”, ar putea avea trei niveluri: „scăzut”, „moderat” și „ridicat”). Cu toate acestea, acești trei termeni – „categorii”, „grupuri” și „niveluri” – pot fi utilizați în mod interschimbabil. În acest ghid, ne vom referi la ele ca fiind categorii, dar, dacă preferați, vă puteți referi la ele ca grupuri sau niveluri.
Nota 2: Termenul „factori” este uneori folosit în loc de „variabile independente categoriale” (adică variabile independente care sunt „ordinale” sau „nominale”). Cu toate acestea, acești doi termeni – „variabile independente categorice” și „factori” – pot fi utilizați în mod interschimbabil. În acest ghid, ne vom referi la ele ca variabile independente categorice și veți vedea, de asemenea, că SPSS Statistics se referă la ele ca variabile independente și nu ca factori în procedura sa de regresie multiplă. Cu toate acestea, vă puteți referi la ele ca factori, dacă preferați.
SPSS Statistics
Setting your data in SPSS Statistics
Când creați variabilele fictive, veți începe cu o singură variabilă independentă categorială (de exemplu, favourite_sport). Pentru a configura această variabilă independentă categorială, SPSS Statistics are o Vizualizare variabilă în care definiți tipurile de variabile pe care le analizați și o Vizualizare date în care introduceți datele pentru această variabilă. În această secțiune, vă arătăm mai întâi cum să configurați o variabilă independentă categorială în fereastra Variable View a SPSS Statistics, înainte de a vă arăta cum să introduceți datele în fereastra Data View. Facem acest lucru folosind variabila noastră independentă categorială, favourite_sport, care are trei categorii: „înot”, „ciclism” și „alergare”.
The Variable View in SPSS Statistics
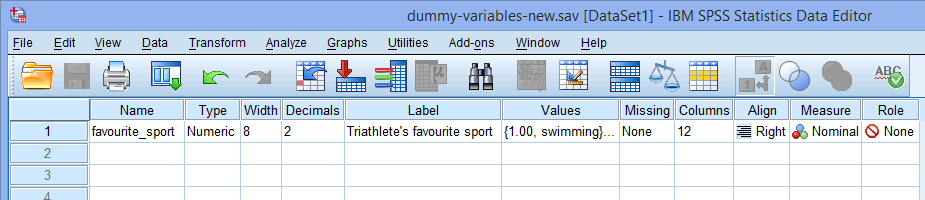
Pentru o singură variabilă independentă categorică (de ex, sport_preferat), fereastra de vizualizare a variabilelor va arăta ca cea de mai jos:
Nota: Puteți accesa fereastra de vizualizare a variabilelor în SPSS Statistics făcând clic pe fila ![]() din colțul din stânga jos al software-ului SPSS Statistics.
din colțul din stânga jos al software-ului SPSS Statistics.
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Numele variabilei independente categorice trebuie introdus în celula de sub coloana ![]() (de ex, „favorit_sport” în rândul
(de ex, „favorit_sport” în rândul ![]() pentru a reprezenta variabila noastră independentă categorială, favorit_sport. Există anumite caractere „ilegale” care nu pot fi introduse în celula
pentru a reprezenta variabila noastră independentă categorială, favorit_sport. Există anumite caractere „ilegale” care nu pot fi introduse în celula ![]() . Prin urmare, dacă primiți un mesaj de eroare și doriți să adăugăm un ghid SPSS Statistics pentru a explica ce sunt aceste caractere ilegale, vă rugăm să ne contactați.
. Prin urmare, dacă primiți un mesaj de eroare și doriți să adăugăm un ghid SPSS Statistics pentru a explica ce sunt aceste caractere ilegale, vă rugăm să ne contactați.
Nota: Pentru propria dvs. claritate, puteți, de asemenea, să furnizați o etichetă pentru variabilele dvs. în coloana ![]() . De exemplu, eticheta pe care am introdus-o pentru „sport_preferat” a fost „Sportul preferat al triatlonistului”.
. De exemplu, eticheta pe care am introdus-o pentru „sport_preferat” a fost „Sportul preferat al triatlonistului”.
Celula de sub coloana ![]() trebuie să conțină informații despre categoriile variabilei dvs. independente categoriale (de exemplu, „înot”, „ciclism” și „alergare” pentru sport_preferat. Pentru a introduce aceste informații, faceți clic în celula de sub coloana
trebuie să conțină informații despre categoriile variabilei dvs. independente categoriale (de exemplu, „înot”, „ciclism” și „alergare” pentru sport_preferat. Pentru a introduce aceste informații, faceți clic în celula de sub coloana ![]() pentru variabila dvs. independentă. Butonul
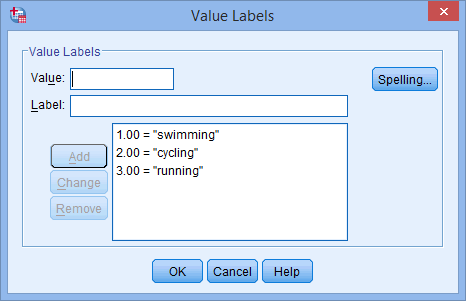
pentru variabila dvs. independentă. Butonul ![]() va apărea în celulă. Faceți clic pe acest buton și va apărea caseta de dialog Value Labels (Etichete valoare). Acum trebuie să atribuiți fiecărei categorii a variabilei dumneavoastră independente o „valoare”, pe care o introduceți în caseta Value: (de exemplu, „1”), precum și o „etichetă”, pe care o introduceți în caseta Label: (de exemplu, „swimming”). Făcând clic pe butonul
va apărea în celulă. Faceți clic pe acest buton și va apărea caseta de dialog Value Labels (Etichete valoare). Acum trebuie să atribuiți fiecărei categorii a variabilei dumneavoastră independente o „valoare”, pe care o introduceți în caseta Value: (de exemplu, „1”), precum și o „etichetă”, pe care o introduceți în caseta Label: (de exemplu, „swimming”). Făcând clic pe butonul ![]() , codificarea va apărea în caseta principală (de exemplu, „1.00=”înot” pentru favourite_sport). Configurația pentru variabila noastră independentă categorială este prezentată în caseta de dialog Value Labels de mai jos:
, codificarea va apărea în caseta principală (de exemplu, „1.00=”înot” pentru favourite_sport). Configurația pentru variabila noastră independentă categorială este prezentată în caseta de dialog Value Labels de mai jos:
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Celula de sub coloana ![]() ar trebui să arate
ar trebui să arate ![]() dacă aveți o variabilă independentă nominală (de ex, sport_preferat, ca în exemplul nostru) sau
dacă aveți o variabilă independentă nominală (de ex, sport_preferat, ca în exemplul nostru) sau ![]() dacă aveți o variabilă independentă ordinală (de exemplu, imaginați-vă o variabilă ordinală cum ar fi „Indicele de masă corporală” (IMC), BMI), care are patru niveluri: „Subponderal”, „Sănătos/ponderalitate normală”, „Supraponderal” și „Obez”). În cele din urmă, celula de sub coloana
dacă aveți o variabilă independentă ordinală (de exemplu, imaginați-vă o variabilă ordinală cum ar fi „Indicele de masă corporală” (IMC), BMI), care are patru niveluri: „Subponderal”, „Sănătos/ponderalitate normală”, „Supraponderal” și „Obez”). În cele din urmă, celula de sub coloana ![]() ar trebui să afișeze
ar trebui să afișeze ![]() .
.
Nota: Vă sugerăm să schimbați celula de sub coloana ![]() de la
de la ![]() la
la ![]() , dar nu este necesar să faceți această modificare. Vă sugerăm să o faceți deoarece există anumite analize în SPSS Statistics în care setarea
, dar nu este necesar să faceți această modificare. Vă sugerăm să o faceți deoarece există anumite analize în SPSS Statistics în care setarea ![]() are ca rezultat faptul că variabilele dvs. sunt transferate automat în anumite câmpuri din casetele de dialog pe care le utilizați. Deoarece este posibil să nu doriți să transferați aceste variabile, vă sugerăm să schimbați setarea
are ca rezultat faptul că variabilele dvs. sunt transferate automat în anumite câmpuri din casetele de dialog pe care le utilizați. Deoarece este posibil să nu doriți să transferați aceste variabile, vă sugerăm să schimbați setarea ![]() în
în ![]() pentru ca acest lucru să nu se întâmple în mod automat.
pentru ca acest lucru să nu se întâmple în mod automat.
Acum ați introdus cu succes toate informațiile pe care SPSS Statistics trebuie să le cunoască despre variabila dvs. independentă categorială în fereastra Variable View. În secțiunea următoare, vă arătăm cum să introduceți datele dvs. în fereastra Data View.
The Data View in SPSS Statistics
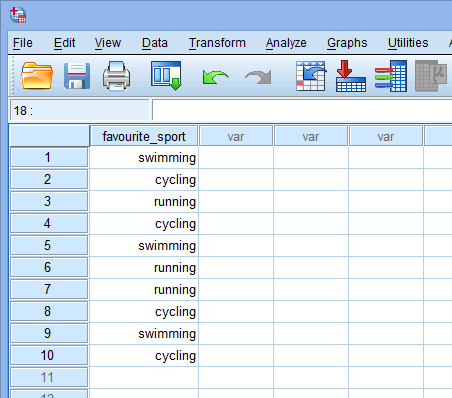
Pe baza configurației fișierului pentru variabila dvs. independentă categorială din fereastra Variable View de mai sus, fereastra Data View arată după cum urmează:
Nota: Puteți accesa fereastra Data View în SPSS Statistics făcând clic pe fila ![]() din colțul din stânga jos al software-ului SPSS Statistics.
din colțul din stânga jos al software-ului SPSS Statistics.
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Variabila dvs. independentă categorială va fi afișată în prima coloană, deoarece aceasta a fost ordinea în care am introdus variabila în fereastra Variable View. În exemplul nostru, răspunsurile celor 10 triatloniști sunt prezentate în coloana ![]() . Acum, trebuie pur și simplu să introduceți datele dvs. în celulele de sub această primă coloană. Rețineți că fiecare rând reprezintă un caz (de exemplu, un caz ar putea fi un singur participant). Prin urmare, în rândul
. Acum, trebuie pur și simplu să introduceți datele dvs. în celulele de sub această primă coloană. Rețineți că fiecare rând reprezintă un caz (de exemplu, un caz ar putea fi un singur participant). Prin urmare, în rândul ![]() din exemplul nostru, primul caz a reprezentat un triatlonist al cărui sport preferat era „înotul”. Deoarece aceste celule vor fi inițial goale, trebuie să faceți clic în celule pentru a introduce datele. Veți observa că atunci când faceți clic în celulele de sub coloana
din exemplul nostru, primul caz a reprezentat un triatlonist al cărui sport preferat era „înotul”. Deoarece aceste celule vor fi inițial goale, trebuie să faceți clic în celule pentru a introduce datele. Veți observa că atunci când faceți clic în celulele de sub coloana ![]() , SPSS Statistics vă va oferi o opțiune derulantă cu categoriile dvs. deja populate.
, SPSS Statistics vă va oferi o opțiune derulantă cu categoriile dvs. deja populate.
Acum că ați configurat datele dvs. în ferestrele Variable View și Data View din SPSS Statistics, vă recomandăm să citiți secțiunea următoare: Înțelegerea variabilelor fictive și a codării fictive, în care explicăm principiile de bază ale variabilelor fictive și ale codării fictive. Cu toate acestea, dacă sunteți deja familiarizat cu principiile de bază ale variabilelor fictive și ale codificării fictive, puteți sări peste această secțiune și puteți trece direct la secțiunea Procedură, în care prezentăm procedura Create Dummy Variables (Crearea de variabile fictive) din SPSS Statistics care este utilizată pentru a crea variabile fictive.
SPSS Statistics
Înțelegerea variabilelor fictive și a codificării fictive
După cum am menționat în Introducere, dacă vă analizați datele utilizând regresia multiplă și oricare dintre variabilele independente au fost măsurate pe o scară nominală sau ordinală, trebuie să știți cum să creați variabile fictive și să interpretați rezultatele acestora. Acest lucru se datorează faptului că variabilele independente categorice (și anume, variabilele independente nominale și ordinale) nu pot fi introduse direct într-o regresie multiplă. În schimb, acestea trebuie să fie convertite în variabile fictive. Excepție fac variabilele independente ordinale care sunt introduse într-o regresie multiplă ca variabile independente continue, care nu trebuie să fie convertite în variabile fictive. În secțiunile de mai jos, vom explica: (a) numărul de variabile fictive pe care trebuie să le creați; și (b) cum să creați variabile fictive și codificarea fictivă.
Numărul de variabile fictive pe care trebuie să le creați
Numărul de variabile fictive pe care trebuie să le creați va depinde de câte categorii are variabila dvs. independentă categorială. Ca regulă generală, veți crea cu o variabilă fictivă mai puțin decât numărul de categorii din variabila dvs. independentă categorială. De exemplu, dacă aveți o variabilă independentă categorială cu trei categorii (de exemplu, favourite_sport, cu următoarele trei categorii: „înot”, „ciclism” și „alergare”), veți crea două variabile fictive și veți selecta o categorie care să acționeze ca o categorie de referință (de exemplu, „înot” și „ciclism” devin variabile fictive, iar „alergare” devine categoria de referință). Explicăm mai multe despre categoriile de referință după tabelul următor, care oferă câteva exemple de variabile independente categoriale și numărul de variabile fictive care trebuie create:
| Numele variabilei independente categorice | Tipul de variabilă | Numărul de categorii | Numărul de variabile fictive | ||||
|---|---|---|---|---|---|---|---|
| 1 | Gender | Nominal | Doi (Bărbați & Femei) |
Unu=Bărbați „Femei” este categoria de referință |
|||
| 2 | Height | Ordinal | Two (Under 180cm & 180cm and above) |
One=Under 180cm „180cm și peste” este categoria de referință |
|||
| 3 | Etnicitate | Nominal | Trei (Afro-american, caucaziană & hispanică) |
Doi=afroamerican & caucazian „Hispanic” este categoria de referință |
|||
| 4 | Nivelul activității fizice | Ordinal | Trei (Scăzut, Moderat & Ridicat) |
Doi=Bătrân & Moderat „Ridicat” este categoria de referință |
|||
| 5 | Profesie | Nominal | Patru (Chirurg, Doctor, Asistent medical & Terapeut) |
Trei=Surgent, Doctor & Asistent medical „Terapeut” este categoria de referință |
|||
| 6 | Nivel de acord | Ordinal | Patru (Foarte de acord, De acord, Dezacord, Total dezacord) |
Trei=Totalmente de acord, De acord & Dezacord „Total dezacord” este categoria de referință |
|||
| 7 | Domeniul de studiu | Nominal | Cinci (Studii de afaceri, Psihologie, Științe biologice, Inginerie & Drept) |
Patru=Studii economice, Psihologie, Științe biologice & Inginerie „Drept” este categoria de referință |
|||
| 8 | Vârsta | Ordinal | Cinci (Sub 18 ani, 19-30, 31-40, 41-50, 51-60) |
Patru=Sub 18 ani, 19-30, 31-40 & 41-50 „51-60” este categoria de referință |
|||
| Tabel: Exemple de variabile independente categoriale și variabilele lor fictive respective | |||||||
După cum se arată în tabelul de mai sus, trebuie să creați o singură variabilă fictivă mai puțin decât numărul de categorii din variabila dvs. independentă categorială. Acest lucru se datorează faptului că trebuie (și ar trebui) să transferați acest număr de variabile fictive într-o regresie multiplă doar atunci când aveți o variabilă independentă categorială. Cu toate acestea, există motive întemeiate pentru a crea o variabilă fictivă pentru fiecare categorie a variabilei independente categoriale: (a) este mai flexibil și (b) permite efectuarea de comparații multiple (a se vedea nota de mai jos). Cu alte cuvinte, dacă variabila dvs. independentă categorială are trei categorii, ar trebui să creați trei variabile fictive, nu doar două.
Din fericire, procedura Create Dummy Variables (Crearea de variabile fictive) din SPSS Statistics versiunea 22 și versiunile ulterioare creează automat o variabilă fictivă pentru fiecare categorie a variabilei dvs. independente categoriale. Cu toate acestea, acest lucru nu este valabil pentru procedura Recode into Different Variables din SPSS Statistics versiunea 21 sau o versiune anterioară. Prin urmare, în circumstanțe normale, veți fi creat următoarea configurație în SPSS Statistics, în funcție de faptul că aveți versiunea 21 sau anterioară sau versiunea 22 și mai sus:
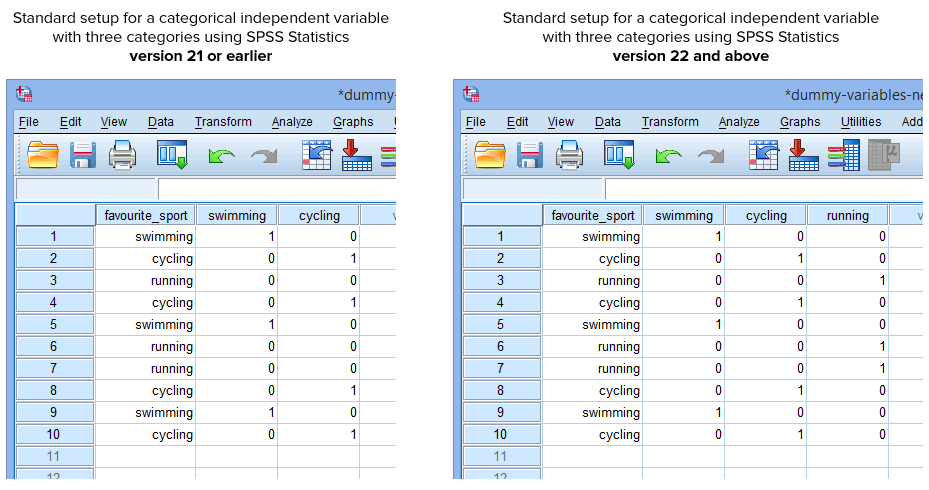
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Nota: După cum s-a menționat mai sus, crearea unei variabile fictive pentru fiecare categorie a variabilei independente categorice este benefică din două motive: (a) este mai flexibilă și (b) permite efectuarea de comparații multiple. Ne referim pe scurt la aceste beneficii în cele ce urmează:
Este mai flexibil:
După ce ați creat o variabilă fictivă pentru fiecare categorie a variabilei independente categoriale, puteți apoi să considerați orice categorie ca fiind o categorie de referință. În exemplul nostru, am considerat categoria „alergare” ca fiind categoria de referință, ceea ce înseamnă că am fi transferat „înotul” și „ciclismul” în ecuația de regresie multiplă. Cu toate acestea, dacă ulterior ne-am răzgândit cu privire la alegerea categoriei de referință, ar trebui să rulăm din nou procedura de variabilă fictivă (cu excepția cazului în care aveți SPSS Statistics versiunea 22 sau o versiune superioară). De exemplu, să presupunem că acum dorim să considerăm categoria „ciclism” ca fiind categoria de referință. Am putea acum să transferăm variabilele fictive „înot” și „alergare” în ecuația de regresie multiplă, deoarece avem și variabila fictivă „alergare”.
Acesta permite efectuarea de comparații multiple:
Ceficientul unei variabile fictive reprezintă diferența dintre categoria pe care o reprezintă acea variabilă fictivă și categoria de referință. De exemplu, cu „alergare” ca și categorie de referință, coeficientul variabilei fictive „înot” reprezintă diferența în variabila dependentă între categoriile „înot” și „alergare”. Folosind această metodă, nu toate combinațiile de categorii vor fi posibile. Această problemă poate fi rezolvată prin utilizarea unor categorii de referință diferite. Acest lucru este posibil dacă toate categoriile variabilei categoriale au o variabilă fictivă.
Cum se creează variabilele fictive și codificarea fictivă
Există doi pași pentru a configura cu succes variabilele fictive într-o regresie multiplă: (1) creați variabile fictive care reprezintă categoriile variabilei dvs. independente categorice; și (2) introduceți valori în aceste variabile fictive – cunoscute sub numele de codare fictivă – pentru a reprezenta categoriile variabilei independente categorice. Explicăm acest proces mai jos, folosind exemplul pe care l-am prezentat mai sus.
Explicație: Variabilele fictive sunt pur și simplu variabile noi, care acționează ca „înlocuitori” pentru o anumită schemă de codificare. Ele nu conțin niciun fel de date, în sine. În schimb, trebuie adăugate date/valori la aceste variabile fictive pentru ca acestea să își poată îndeplini scopul de a reprezenta categoriile variabilei dumneavoastră independente categoriale. Există multe tipuri diferite de scheme de codificare care vor dicta valorile care sunt introduse în variabilele fictive, dar noi folosim o schemă de codificare foarte comună numită codificare fictivă sau, alternativ, codificare indicatoare (N.B., nu vă confundați, deoarece variabilele fictive și codificarea fictivă nu sunt același lucru). Codificarea dummy funcționează prin utilizarea fiecărei variabile dummy pentru a identifica o categorie specifică a unei variabile independente categoriale, cu excepția unei categorii de referință, pe care o explicăm mai jos.
Să începem prin a lua în considerare exemplul nostru de variabilă independentă categorială, sport_preferat, care are trei categorii: „înot”, „ciclism” și „alergare”. Deoarece există trei categorii, trebuie să existe două variabile fictive care să reprezinte două dintre categorii și o categorie de referință care să reprezinte cea de-a treia categorie.
Rețineți: Amintiți-vă din discuția de mai sus că o regresie multiplă necesită să transferați cu o variabilă fictivă mai puțin decât numărul de categorii din variabila dvs. independentă categorială (adică, două în exemplul nostru). Cu toate acestea, puteți crea o variabilă fictivă pentru fiecare categorie a variabilei independente categorice în scopul unei mai mari flexibilități și al capacității de a face comparații multiple. Cu toate acestea, în discuția de mai jos subliniem doar ceea ce este necesar pentru o regresie multiplă; și anume, crearea unei variabile fictive mai puțin decât numărul de categorii din variabila dvs. independentă categorială, categoria care nu este reprezentată direct devenind „categoria de referință”.
De exemplu, fie ca variabila fictivă nr. 1 să reprezinte categoria „înot” și variabila fictivă nr. 2 să reprezinte categoria „ciclism”. Astfel, nu rămâne nicio variabilă fictivă pentru categoria „alergare”. Această categorie „lipsă” este categoria de referință și nu este necesară. În plus, este decizia dumneavoastră ce categorie doriți să folosiți ca și categorie de referință. Am fi putut la fel de bine să alegem categoria „înot” ca și categorie de referință în locul categoriei „alergare”. Singurul motiv pentru care nu am făcut-o este că, în mod implicit, SPSS Statistics utilizează ultima categorie pe care ați codificat-o în Variable View pentru variabila dvs. independentă categorială ca și categorie de referință (a se vedea nota de mai jos).
Nota: După cum s-a explicat în secțiunea Data Setup (Configurarea datelor) de mai devreme și după cum se arată mai jos în caseta de dialog Value Labels (Etichete valoare), a treia și ultima categorie a variabilei noastre independente categoriale a fost „alergare” (de ex, 3=”alergare”).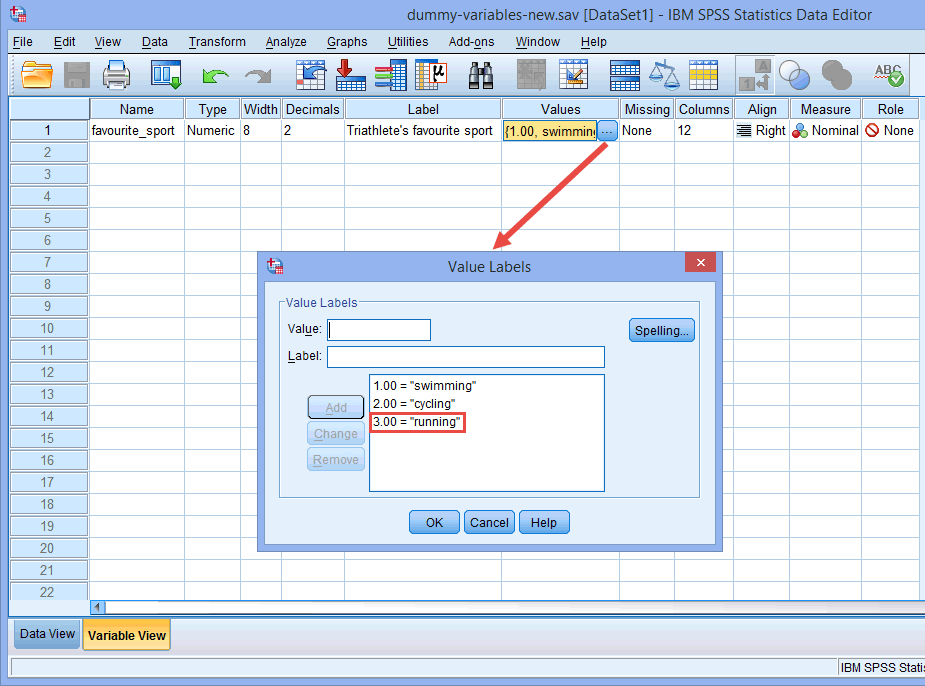
Nu a existat niciun motiv teoretic sau statistic pentru ca noi să facem din categoria „alergare” a treia și ultima categorie, ceea ce a făcut ca aceasta să fie categoria de referință în SPSS Statistics în mod implicit. Pur și simplu am procedat astfel deoarece, atunci când triatloniștii participă la un triatlon, ei fac mai întâi înotul, apoi întreprind un ciclu, înainte de a alerga în cele din urmă până la linia de sosire. Prin urmare, a părut logic să codificăm variabila noastră independentă categorială în acest mod. Cu toate acestea, am fi putut să o codificăm ca 1=ciclism, 2=cursă și 3=înot; nu ar fi făcut nicio diferență, cu excepția faptului că, în calitate de a treia și ultima categorie, „înotul” ar fi devenit implicit categoria noastră de referință în SPSS Statistics.
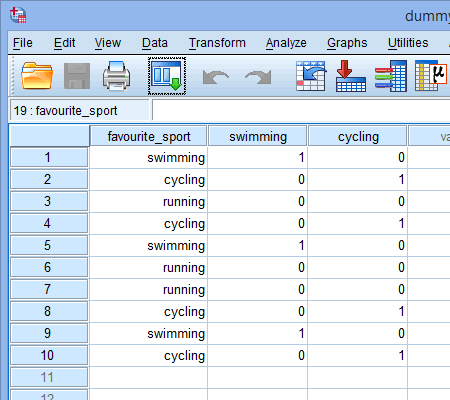
Când creați variabile fictive, ar trebui să le dați un nume semnificativ. Deoarece fiecare dintre variabilele noastre fictive reprezintă o categorie a variabilei noastre independente categorice, se obișnuiește să ne referim la fiecare variabilă fictivă prin numele categoriei pe care o reprezintă. Prin urmare, am numit variabila fictivă nr. 1 „înot”, deoarece reprezintă categoria înot. În mod similar, am numit variabila fictivă nr. 2 „ciclism”, deoarece reprezintă categoria ciclism. Prin crearea acestor două variabile fictive, vom avea două noi coloane în setul nostru de date din SPSS Statistics, așa cum se arată mai jos:
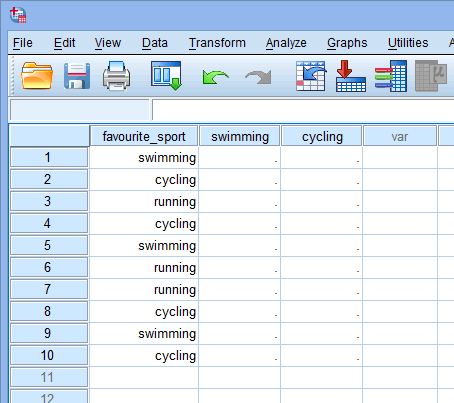
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Acum că am creat două variabile fictive și le-am dat nume corespunzătoare, trebuie să introducem valori în aceste variabile, astfel încât fiecare variabilă fictivă să reprezinte cu adevărat categoria sa din variabila independentă categorială. Cu ajutorul codului dummy, acest lucru este foarte simplu. Introduceți un „1” pentru a reprezenta orice caz (de exemplu, un participant din setul dvs. de date) care are categoria respectivă și introduceți un „0” (zero) dacă nu are categoria respectivă. Mai întâi, luați în considerare variabila fictivă „înot”, așa cum se arată mai jos:
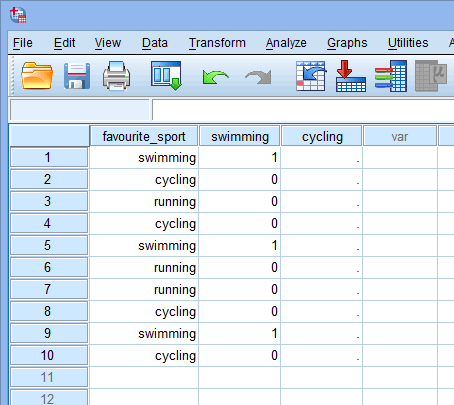
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Dacă unul dintre triatloniști a declarat că „înotul” este sportul său „preferat”, vom introduce un „1” în celula de sub coloana variabilei fictive „înot” (![]() ) pentru acel triatlonist care a declarat că înotul este sportul său „preferat”. Alternativ, în cazul în care unul dintre triatloniști a declarat că „ciclismul” sau „alergarea” este sportul său „preferat”, vom introduce un „0” în celula de sub coloana variabilei fictive de înot (
) pentru acel triatlonist care a declarat că înotul este sportul său „preferat”. Alternativ, în cazul în care unul dintre triatloniști a declarat că „ciclismul” sau „alergarea” este sportul său „preferat”, vom introduce un „0” în celula de sub coloana variabilei fictive de înot (![]() ) pentru acel triatlonist care a declarat că înotul „nu” este sportul său preferat (adică, aceasta înseamnă că fie „ciclismul”, fie „alergarea” este sportul preferat al acelui triatlonist). Acest lucru este evidențiat mai jos pentru toți cei 10 triatloni:
) pentru acel triatlonist care a declarat că înotul „nu” este sportul său preferat (adică, aceasta înseamnă că fie „ciclismul”, fie „alergarea” este sportul preferat al acelui triatlonist). Acest lucru este evidențiat mai jos pentru toți cei 10 triatloni:
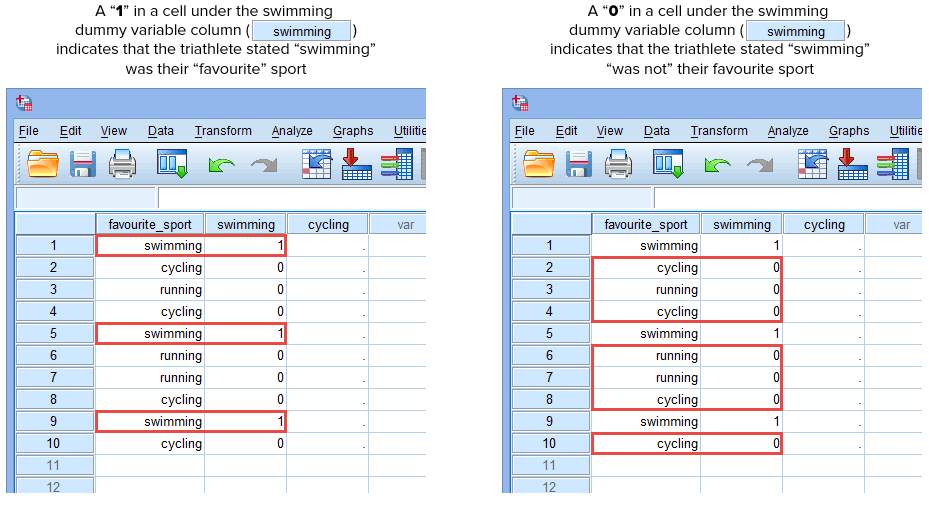
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Repetăm acest proces pentru cealaltă variabilă fictivă, „ciclism”, așa cum se arată mai jos:
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Dacă unul dintre triatloniști a declarat că „ciclismul” este sportul său „preferat”, vom introduce un „1” în celula de sub coloana variabilei fictive ciclism (![]() ) pentru acel triatlonist care a declarat că ciclismul este sportul său „preferat”. Alternativ, în cazul în care unul dintre triatloniști a declarat că „înotul” sau „alergarea” este sportul său „preferat”, vom introduce un „0” în celula de sub coloana variabilei fictive ciclism (
) pentru acel triatlonist care a declarat că ciclismul este sportul său „preferat”. Alternativ, în cazul în care unul dintre triatloniști a declarat că „înotul” sau „alergarea” este sportul său „preferat”, vom introduce un „0” în celula de sub coloana variabilei fictive ciclism (![]() ) pentru acel triatlonist care a declarat că ciclismul „nu” este sportul său preferat (adică, aceasta înseamnă că fie „înotul”, fie „alergarea” este sportul preferat al acelui triatlonist). Acest lucru este evidențiat mai jos pentru toți cei 10 triatloni:
) pentru acel triatlonist care a declarat că ciclismul „nu” este sportul său preferat (adică, aceasta înseamnă că fie „înotul”, fie „alergarea” este sportul preferat al acelui triatlonist). Acest lucru este evidențiat mai jos pentru toți cei 10 triatloni:
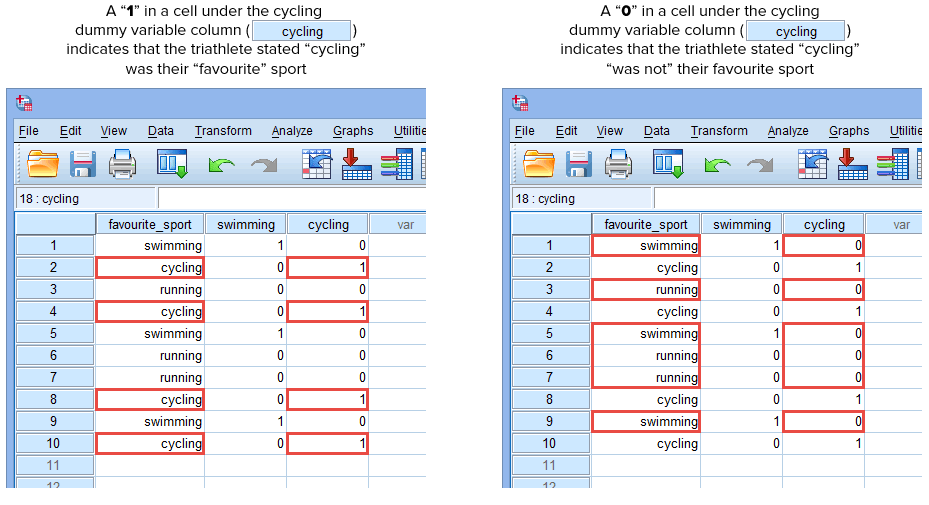
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Întroducând „1”-uri și „0”-uri în variabilele dvs. fictive în acest mod, veți fi creat un set de variabile fictive pe care le puteți introduce într-o analiză de regresie multiplă. În secțiunea Procedure (Procedură) care urmează, vă arătăm cum să creați aceste variabile fictive folosind procedura Create Dummy Variables (Creare variabile fictive).
SPSS Statistics
Procedură în SPSS Statistics pentru a crea variabile fictive
Există două proceduri în SPSS Statistics pentru a crea variabile fictive: procedura Create Dummy Variables (Creare variabile fictive) și procedura Recode into Different Variables (Recodificare în variabile diferite). În acest ghid, vă arătăm cum să utilizați procedura Create Dummy Variables, care este o procedură simplă în 3 pași. Cu toate acestea, aceasta este disponibilă numai dacă aveți SPSS Statistics versiunea 22 sau o versiune ulterioară, versiunea 26 (și versiunea de abonament a SPSS Statistics) fiind cea mai recentă versiune a SPSS Statistics. Dacă nu sunteți sigur de versiunea de SPSS Statistics pe care o utilizați, consultați ghidul nostru: Identificarea versiunii dvs. de SPSS Statistics. Dacă aveți SPSS Statistics versiunea 21 sau o versiune anterioară sau sunteți interesat să faceți comparații multiple atunci când efectuați analiza de regresie multiplă, vă rugăm să consultați Nota de mai jos:
Nota: Dacă aveți SPSS Statistics versiunea 21 sau o versiune anterioară, nu puteți utiliza procedura Create Dummy Variables. Prin urmare, procedura Recodificare în variabile diferite vă permite cel puțin să creați variabile fictive în SPSS Statistics. Deși puteți utiliza, de asemenea, procedura Recode into Different Variables pentru a crea variabile fictive dacă aveți SPSS Statistics versiunea 22 sau o versiune ulterioară, am prezentat procedura Create Dummy Variables în acest ghid deoarece este dedicată creării de variabile fictive și este mult mai ușor și mai rapid de utilizat. De exemplu, este nevoie de doar 3 pași pentru a crea variabile fictive pentru exemplul utilizat în acest ghid, comparativ cu 28 de pași pentru același exemplu utilizând procedura Recode into Different Variables.
De aceea, dacă aveți SPSS Statistics versiunea 21 sau o versiune anterioară, ghidul nostru îmbunătățit privind Crearea variabilelor fictive din secțiunea membrilor de la Laerd Statistics include o pagină dedicată pentru a arăta cum se realizează această procedură Recode into Different Variables în 28 de pași. Puteți accesa acest ghid îmbunătățit abonându-vă la Laerd Statistics. Alternativ, puteți utiliza pur și simplu procedura Create Dummy Variables de mai jos.
Pentru a crea variabile fictive atunci când aveți SPSS Statistics versiunea 22 sau o versiune ulterioară, urmați procedura în 3 pași Create Dummy Variables de mai jos:
- Click Transform > Create Dummy Variables din meniul principal, așa cum se arată mai jos:

Publicată cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Vă va fi prezentată caseta de dialog Create Dummy Variables for:, așa cum se arată mai jos:
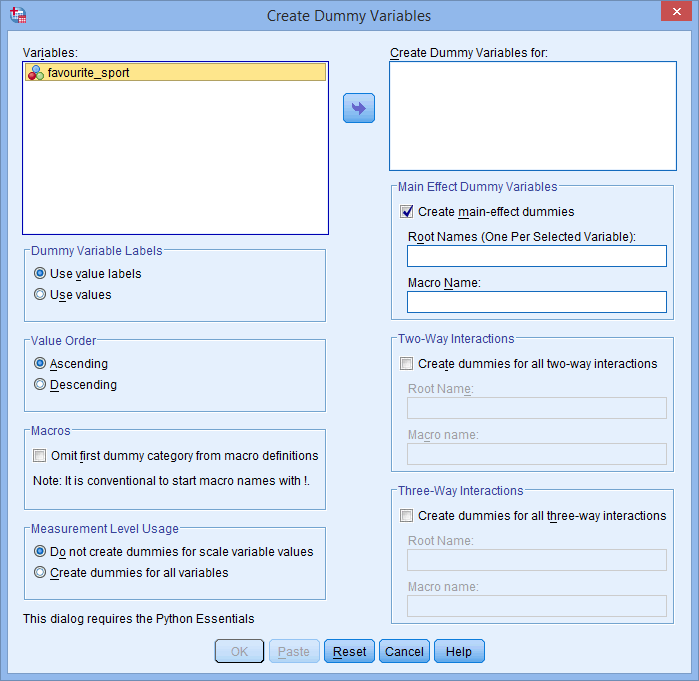
Published with written permission from SPSS Statistics, IBM Corporation.
- Transferați variabila independentă categorică, favourite_sport, în caseta Create Dummy Variables for: selectând-o (făcând clic pe ea) și apoi făcând clic pe butonul
 . De asemenea, introduceți un nume „rădăcină” care poate reprezenta toate noile variabile fictive în caseta Root Names (One Per Selected Variable): (Nume rădăcină (unul pentru fiecare variabilă selectată): din zona -Main Effect Dummy Variables- (Variabile fictive cu efect principal). Noi am introdus numele rădăcină „fs” ca o abreviere pentru variabila noastră independentă categorială, „favourite_sport”, așa cum se arată mai jos:
. De asemenea, introduceți un nume „rădăcină” care poate reprezenta toate noile variabile fictive în caseta Root Names (One Per Selected Variable): (Nume rădăcină (unul pentru fiecare variabilă selectată): din zona -Main Effect Dummy Variables- (Variabile fictive cu efect principal). Noi am introdus numele rădăcină „fs” ca o abreviere pentru variabila noastră independentă categorială, „favourite_sport”, așa cum se arată mai jos:
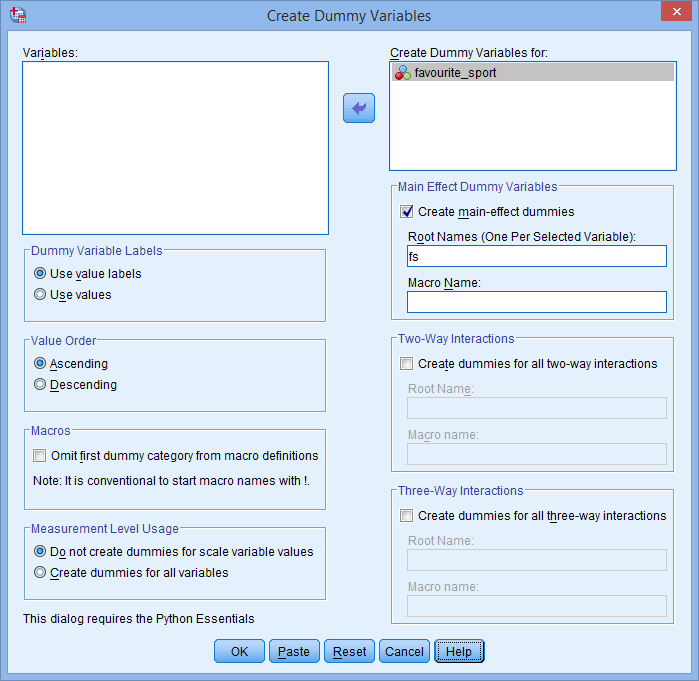
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Nota: SPSS Statistics va adăuga un număr secvențial (de exemplu, 1, 2, 3, 4, etc.) la sfârșitul numelui rădăcină pe care îl alegeți pentru a reprezenta variabila dvs. independentă categorială. Se va crea un număr secvențial pentru fiecare dintre variabilele fictive pe care doriți să le creați (de exemplu, dacă aveți două variabile fictive, se va adăuga un 1 și un 2 la capătul numelui rădăcină, dar dacă aveți șase variabile fictive, se va adăuga un 1, 2, 3, 4, 5 și 6 la capătul numelui rădăcină). Acest lucru este prezentat pentru exemplul nostru în fereastra Variable View de mai jos:
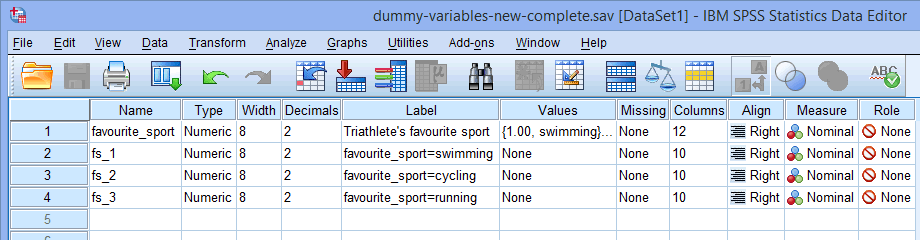
Din moment ce variabila noastră independentă categorială, sport_preferat, avea trei categorii (adică înot, ciclism și alergare), procedura Create Dummy Variables creează trei variabile fictive (adică una pentru înot, una pentru ciclism și una pentru alergare). Aceste trei variabile fictive sunt evidențiate în coloana de mai sus: „fs_1” (pentru înot), „fs_2” (pentru ciclism) și „fs_3” (pentru alergare). Le puteți redenumi ulterior astfel încât să aibă mai mult sens. Evidențiem acest lucru doar pentru ca să știți cum funcționează caseta Root Names (One Per Selected Variable): de mai sus.
de mai sus: „fs_1” (pentru înot), „fs_2” (pentru ciclism) și „fs_3” (pentru alergare). Le puteți redenumi ulterior astfel încât să aibă mai mult sens. Evidențiem acest lucru doar pentru ca să știți cum funcționează caseta Root Names (One Per Selected Variable): de mai sus.
De asemenea, numele rădăcinii pe care îl introduceți în caseta Root Names (One Per Selected Variable): nu poate fi același cu numele variabilei dvs. independente categorice, așa cum se arată mai jos (de ex, unde am introdus numele rădăcină, „favorit_sport”, pentru a ilustra ceea ce nu am putut numi numele nostru rădăcină):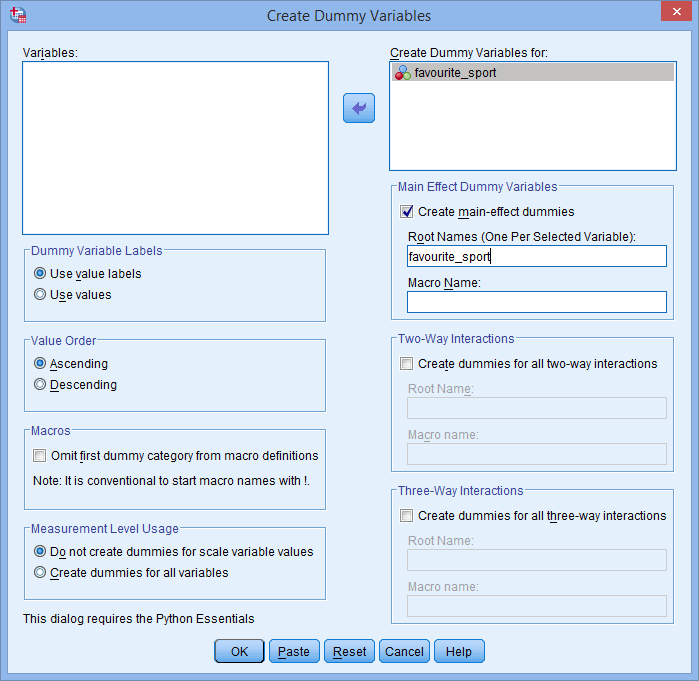
Dacă numele rădăcină pe care îl introduceți este același cu numele variabilei dvs. independente categoriale, așa cum se arată mai sus, atunci când faceți clic pe butonul , veți primi următorul avertisment:
, veți primi următorul avertisment:
- Click pe butonul .
După efectuarea procedurii Create Dummy Variable (Creare variabilă fictivă) în 3 pași de mai sus, veți fi creat variabile fictive pentru variabila dvs. independentă categorială. În secțiunea următoare, evidențiați ieșirea care este creată în Variable View și Data View din SPSS Statistics după executarea acestei proceduri Create Dummy Variables.
SPSS Statistics
Output and data setup in SPSS Statistics after creating dummy variables
După ce ați creat variabilele Dummy, SPSS Statistics produce următorul tabel Variable Creation its IBM SPSS Statistics Viewer:
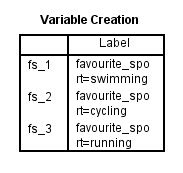
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Tabelul de creare a variabilelor confirmă faptul că ați creat cu succes variabilele fictive. Ar trebui să existe atâtea rânduri câte variabile fictive noi există. Deoarece am creat trei variabile fictive, există trei rânduri în tabel, „fs_1”, „fs_2” și „fs_3”, care reflectă numele rădăcinii și numerotarea secvențială introduse în Pasul 2 al procedurii Create Dummy Variables (Crearea variabilelor fictive) din secțiunea anterioară. Pentru fiecare dintre aceste variabile fictive, se furnizează o etichetă în tabel pentru a clarifica ce categorie a variabilei independente categoriale reprezintă fiecare variabilă fictivă. De exemplu, pentru „fs_1” este furnizată eticheta „favourite_sport=înot”, indicând că „fs_1” este variabila fictivă pentru categoria „înot” a variabilei independente categoriale, favourite_sport.
În continuare, accesați fereastra Variable View (Vizualizare variabile) din SPSS Statistics, făcând clic pe fila ![]() . Cele trei variabile fictive vor fi fost adăugate, așa cum se arată mai jos (adică variabilele fictive, „fs_1”, „fs_2” și „fs_3”, în coloana
. Cele trei variabile fictive vor fi fost adăugate, așa cum se arată mai jos (adică variabilele fictive, „fs_1”, „fs_2” și „fs_3”, în coloana ![]() ):
):
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Nota: Puteți schimba numele variabilelor fictive din coloana ![]() pentru a face mai clar ce sunt acestea. De exemplu, am schimbat „fs_1” în „înot”, „fs_2” în „ciclism” și „fs_3” în „alergare”, așa cum se arată mai jos:
pentru a face mai clar ce sunt acestea. De exemplu, am schimbat „fs_1” în „înot”, „fs_2” în „ciclism” și „fs_3” în „alergare”, așa cum se arată mai jos:
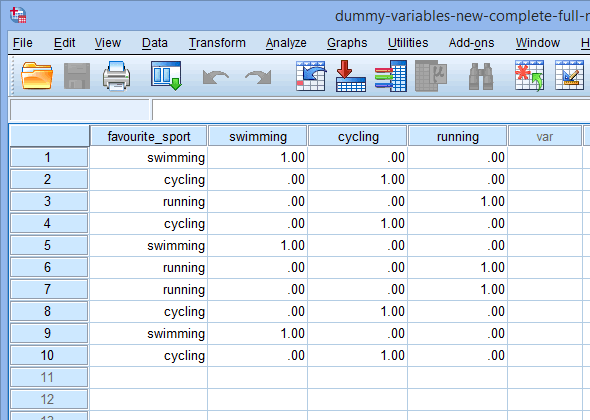
În cele din urmă, mergeți la fereastra Data View a SPSS Statistics făcând clic pe fila ![]() . Codificarea fictivă este afișată sub fiecare dintre variabilele fictive care au fost create. De exemplu, în rândurile de sub coloana „fs_1”, categoria „înot” este codificată ca „1,00”, în timp ce categoriile „ciclism” și „alergare” sunt codificate ca „.00”, așa cum se arată mai jos. Dacă nu sunteți sigur de ce aceste variabile fictive sunt codificate în acest mod, consultați secțiunea: Înțelegerea variabilelor fictive și a codificării fictive.
. Codificarea fictivă este afișată sub fiecare dintre variabilele fictive care au fost create. De exemplu, în rândurile de sub coloana „fs_1”, categoria „înot” este codificată ca „1,00”, în timp ce categoriile „ciclism” și „alergare” sunt codificate ca „.00”, așa cum se arată mai jos. Dacă nu sunteți sigur de ce aceste variabile fictive sunt codificate în acest mod, consultați secțiunea: Înțelegerea variabilelor fictive și a codificării fictive.
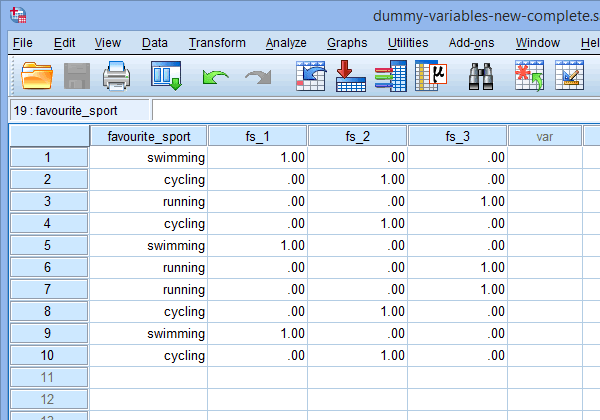
Publicat cu permisiunea scrisă a SPSS Statistics, IBM Corporation.
Nota 1: Datorită setărilor implicite ale SPSS Statistics, variabilele dvs. fictive vor fi codificate „1.00” sau „.00” în loc de „1” sau „0”, respectiv „1”. Acestea sunt identice. Cu toate acestea, veți vedea adesea codificarea variabilelor fictive scrisă în termeni de 1 și 0, mai degrabă decât incluzând zecimale.
Nota 2: Dacă ați schimbat numele variabilelor fictive în coloana ![]() din fereastra Variable View (Vizualizare variabile) de mai sus, acestea vor fi fost modificate și în coloanele din fereastra Data View (Vizualizare date), așa cum se arată mai jos (de exemplu, titlul coloanei
din fereastra Variable View (Vizualizare variabile) de mai sus, acestea vor fi fost modificate și în coloanele din fereastra Data View (Vizualizare date), așa cum se arată mai jos (de exemplu, titlul coloanei ![]() este acum intitulat
este acum intitulat ![]() ):
):