Proteinele ancorate de GPI sunt un om ciudat. La cursul introductiv de biologie celulară, ne-au învățat că există cinci tipuri de proteine de membrană, denumite după cum urmează: Tipul I, Tipul II, Tipul III, Tipul IV și cele ancorate în GPI. De ce avem această clasă ciudată de proteine fuzionate cu un lanț de zahăr și grăsimi? Care este rolul lor? Putem obține informații despre proteina care mă interesează – PrP – învățând mai multe despre această clasă de proteine din care face parte?
Sonia și cu mine și cu colegul nostru de echipă Andrew și am citit ceva pe această temă și scriu această postare pe blog pentru a împărtăși o parte din ceea ce am învățat.
lectură
Am început prin a citi câteva recenzii . Acestea au acoperit în mare parte structura și biogeneza ancorei GPI în sine, despre care se știe o mulțime de lucruri.
Această ancoră, al cărei nume complet este glicozilfosfatidilinositol, nu este un monolit: este o descriere generală a unei molecule ale cărei detalii pot varia. În general, pornind de la reziduul ω (ultimul reziduu post-translațional prezent) al proteinei, aveți etanolamină, apoi un fosfat, apoi niște zaharuri, apoi un fosfolipid. Coloana vertebrală de bază a zahărului este conservată, dar lanțurile laterale care se ramifică din aceasta pot varia, iar grupul de căpătâi al fosfolipidului și acizii grași pot, de asemenea, să varieze. Ancora GPI a PrP a fost caracterizată în , dar chiar și atunci nu este un monolit – au identificat cel puțin șase structuri diferite care diferă în ceea ce privește compoziția lanțurilor laterale de zahăr.
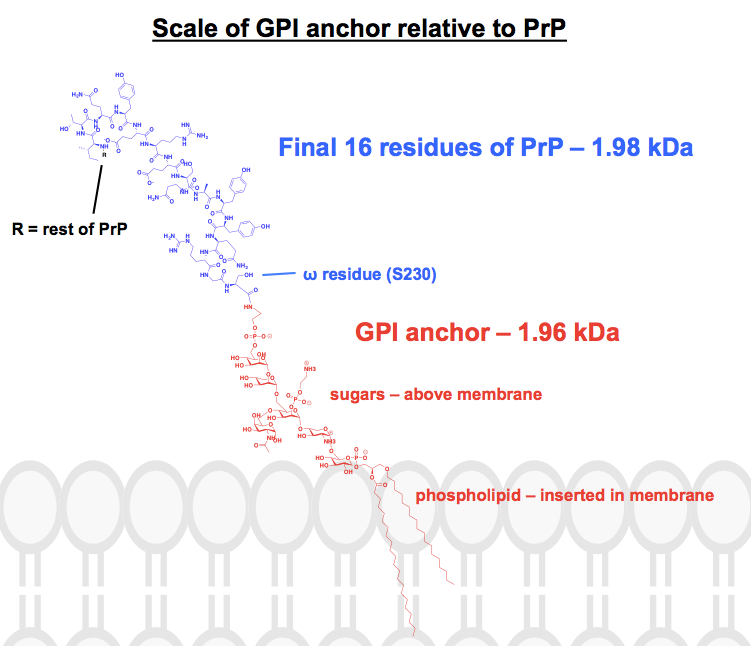
Toată structura chimică pe care am găsit-o a ancorelor GPI are cel puțin unele părți abreviate sau rezumate, iar proteina este de obicei prezentată doar ca o imagine. Am vrut să-mi fac o idee despre cum arată de fapt aceste ancore din punct de vedere chimic, în contextul proteinelor la care sunt atașate, așa că mi-am propus să desenez efectiv o structură completă în ChemDraw. Pornind de la figura 1 din – cel mai apropiat lucru de o structură scheletică completă pe care l-am putut găsi – am adăugat detaliile uneia dintre ancorele GPI ale PrP din panoul superior al figurii 6. Greutatea moleculară a ajuns la 1.958 Da, așa că, pentru context, am desenat ultimele 16 reziduuri din HuPrP23-230, care cântăresc în mod comparabil, la 1.979 Da. Aceasta reprezintă aproximativ 8% din secvența modificată post-translațional a PrP. Nu sunt sigur că am nimerit corect fiecare legătură, dar iată ce mi-a ieșit:
În multe cazuri, o genă are mai multe izoforme, cu un produs de splicing care dă naștere unei proteine ancorate în GPI, în timp ce altele dau naștere la forme secretate sau transmembranare. Exemplele includ NCAM1, care are trei izoforme majore, dintre care una este ancorată în GPI și celelalte două sunt transmembranare , și ACHE (care codifică acetilcolinesteraza), a cărei formă ancorată în GPI se pare că se găsește doar pe globulele roșii (NCBI Genes). Cea mai fascinantă poveste în acest caz este cea a genei de șoarece Ly6a care, datorită unui polimorfism genetic, este ancorată în GPI în unele tulpini de șoareci și nu în altele. Numai în forma sa ancorată în GPI, aceasta acționează ca receptor pentru vectorul viral AAV PHP.eB . (Acest vector realizează o absorbție uimitor de eficientă în neuronii creierului pentru terapia genică , dar, din păcate, este o genă de șoarece – noi, oamenii, nici măcar nu avem Ly6a).
Se cunosc multe despre modul în care ancorele GPI sunt sintetizate și atașate la proteine , cu >20 de proteine implicate în această cale, dintre care cele mai multe încep cu prefixul „PIG” și sunt codificate de gene precum PIGA, PIGK și așa mai departe – a se vedea figura 2 pentru o diagramă. Cea mai mare parte a biosintezei are loc cu ancora inserată în membrana din ER, dar nu este atașată la nicio proteină. De fapt, primii câțiva pași au loc pe frunza citosolică a membranei și abia mai târziu ancora se întoarce pe partea lumenală (în interiorul ER). Etapa finală are loc atunci când GPI transamidaza, un complex alcătuit din cel puțin cinci proteine, desprinde semnalul GPI de la terminația C a proteinei și atașează ancora GPI la așa-numitul reziduu ω al proteinei (ultimul reziduu din secvența modificată post-translațional). Apoi are loc o maturare suplimentară a ancorei GPI pe măsură ce proteina migrează din ER spre suprafața celulară.
Există o serie de inhibitori cu molecule mici ai biosintezei GPI în ciuperci, dintre care unii au încercat să fie dezvoltați ca medicamente antifungice , dar, din câte am aflat, singurul inhibitor cunoscut al biosintezei GPI în celulele mamiferelor este mannosamina, un analog al mannozei care este incompatibil din punct de vedere chimic cu încorporarea în GPI .
Am căutat și am căutat un logo de secvență despre ce motiv de secvență de aminoacizi recunoaște transamidaza GPI, dar nu am găsit niciunul. Se pare că motivul de secvență este destul de liber , și se pare că semnalele GPI nu sunt nici măcar omoloage , ceea ce înseamnă că nu au evoluat de la o secvență ancestrală comună, ci mai degrabă au evoluat în mod convergent, în măsura în care există chiar și o convergență. Cea mai bună descriere pe care am reușit să o găsesc este că (citind de la N la C-terminal până la capătul proteinei) aveți nevoie de 1) aproximativ 11 reziduuri de un linker nestructurat, 2) câteva reziduuri cu lanțuri laterale mici, inclusiv un reziduu ω care poate fi fie S, N, D, G, A sau C, 3) un distanțier de 5-10 aminoacizi polari și, în final, 4) 15-20 de aminoacizi hidrofobi . PrP urmează în mod vag acest motiv. Conform structurilor publicate , alfa helixul 3 se termină la reziduul Q223, ceea ce lasă „liantul nestructurat” ca fiind doar AYYQR (ceva mai scurt decât cele 11 reziduuri prescrise). Regiunea „lanțului lateral mic” ar fi GS|SM (cu o țeavă indicând locul de tăiere al transamidazei), regiunea polară ar fi VLFSSPP, iar terminația C hidrofobă ar fi VILLISFLIFLIVG.
Câteva dintre proteinele din calea de biosinteză și atașare a GPI sunt foarte importante și au fost descrise o serie de boli și sindroame severe de deficiență a ancorei GPI, datorate unor mutații bialelice de pierdere a funcției sau mutații missense aparent hipomorfe în gene precum PIGO, PIGV, PIGW, PGAP2 și PGAP3 .
Sonia a găsit o lucrare excelentă de acum câțiva ani în care au făcut un screening prin mutageneză în celule umane haploide pentru a identifica genele necesare pentru biogeneza a două proteine ancorate în GPI: PrP și CD59 . Aceștia au folosit sortarea repetată FACS a celulelor pe baza PrP și CD59 de la suprafața celulară pentru a identifica celulele cu niveluri de suprafață dramatic reduse ale acestor proteine, iar apoi au efectuat secvențierea pentru a vedea ce gene knock-out au fost îmbogățite în aceste celule față de populația mamă. După cum v-ați aștepta, majoritatea genelor PIG au apărut pentru ambele proteine (Figura 4), dar nu toate rezultatele s-au suprapus, ceea ce este puțin surprinzător, mai ales că, cel puțin la nivel de ARN, PrP și CD59 sunt două dintre proteinele cu cele mai asemănătoare profiluri de expresie între țesuturi (a se vedea harta termică din partea de jos a acestei postări). O serie de enzime implicate în modificarea lanțurilor laterale de ancorare GPI au apărut doar pentru CD59, sugerând că CD59, dar nu și PrP, are nevoie de aceste lanțuri laterale complexe pentru a se maturiza și a ajunge la suprafața celulară. Între timp, Sec62 și Sec63 au apărut doar pentru PrP – acestea sunt proteine implicate cumva în translocarea translațională în ER, dar se pare că sunt necesare pentru PrP, dar nu și pentru CD59, CD55 sau CD109, alte două proteine de control analizate. Acesta este un nou capitol fascinant în răspunsul la întrebarea mea, „este ceva special în ceea ce privește expresia PrP?”, în care căutam ceva unic în ceea ce privește biogeneza PrP care ar putea fi potențial țintit cu o moleculă mică. Bineînțeles, doar pentru că aceste proteine nu au fost importante pentru alte trei proteine de control în nu înseamnă că nu sunt importante – un studiu a constatat că Sec62 era necesară pentru secreția multor proteine mici , iar gena SEC62 este total sărăcită de variante cu pierdere de funcție în populația umană, suficient pentru a sugera haploinsuficiență. SEC63 pare mai puțin constrânsă, deși asta ar putea însemna doar că acționează în mod recesiv.
Nimeni dintre cei de mai sus nu răspunde la întrebarea de ce există proteinele ancorate în GPI. Vechiul meu curs de biologie celulară a omis un detaliu, apropo: există de fapt o a șasea clasă de proteine membranare, numite proteine ancorate la coadă (TA) , care au doar o extremitate C hidrofobă care se lipește în membrană, dar nu iese în afară pe partea cealaltă. De ce nu ar putea toate aceste proteine ancorate în GPI să fie doar proteine TA? De ce au evoluat celulele o cale atât de complicată pentru a sintetiza în schimb o ancoră de zahăr-grăsime și de ce au evoluat-o atât de devreme în joc – ancorele GPI sunt prezente în toate eucariotele, inclusiv în mulți agenți patogeni unicelulare care infectează oamenii.
Majoritatea recenziilor nu au petrecut mult timp cu această întrebare, probabil pentru că este cel mai greu de răspuns. Proteinele ancorate de GPI în sine, în măsura în care funcțiile lor native sunt cunoscute, au o gamă imensă de funcții – există enzime (cum ar fi AChE), molecule de adeziune celulară (cum ar fi NCAM1), proteine care reglează complementul în sistemul imunitar (CD59) și așa mai departe . Se pare că există cel puțin o proteină ancorată în GPI implicată în menținerea mielinei în nervii periferici . Dar ce anume pot face proteinele ancorate de GPI pe care alte proteine nu le pot face? O recenzie citează câteva idei care au fost propuse. Una dintre ele este că proteinele ancorate de GPI sunt bune la dimerizarea tranzitorie . Unele studii au explorat ideea că homodimerizarea joacă un anumit rol în biologia prionilor , deși relevanța sistemelor model utilizate acolo pentru situația in vivo nu este încă clară. O altă idee este că, deoarece proteinele ancorate în GPI pot fi eliminate de la suprafața celulară, de exemplu de către enzima de conversie a angiotensinei (ACE) , localizarea lor poate fi reglată într-un mod dinamic. Și în acest caz, știm că PrP poate fi eliminată, aparent de către enzima ADAM10 , deși nu este încă clar dacă are vreun rol în funcția nativă a PrP. O a treia idee, și poate cea despre care am auzit vorbindu-se cel mai mult, este aceea că proteinele ancorate în GPI se adună selectiv în „rafturi lipidice” . Aceasta este poate cea mai tentantă explicație, deoarece vă puteți imagina tot felul de efecte în lanț, în care concentrația locală efectivă crescută a acestor proteine permite mai multe interacțiuni, și așa mai departe. Dar o recenzie a subliniat faptul că un avertisment este că plutele lipidice sunt încă mai mult o idee abstractă decât un lucru concret – în timp ce acestea sunt definite din punct de vedere funcțional prin insolubilitatea detergentului și majoritatea oamenilor le descriu ca fiind bogate în sfingomielină și colesterol, nu există o definiție universal acceptată a ceea ce este și nu este o plută lipidică, iar dovezile empirice sugerează că acestea pot fi mult mai mici și mai tranzitorii decât cred majoritatea oamenilor.
Cu această lectură în mână, am pornit să obțin o listă a acestor proteine și să fac câteva analize asupra lor pentru a vedea dacă aș putea avea o idee mai bună despre cum sunt.
analize
Uniprot are o listă de 173 de proteine umane ancorate în GPI. Acestea au fost cartografiate la 140 de simboluri genice, care au scăzut la 135 după ce am rulat acest script pentru a actualiza la simbolurile genice de codificare a proteinelor aprobate în prezent de HGNC. Lista finală de 135 de simboluri genetice este aici.
Uniprot nu oferă nicio informație despre modul în care au fost generate adnotările lor, deși trebuie să existe un grad semnificativ de curatorie manuală. Pentru comparație, Andrew a dezgropat, de asemenea, o serie de lucrări îngrijite care au folosit PI-PLD sau PI-PLC, două enzime care clivează ancorele GPI, pentru a izola în mod empiric proteinele ancorate în GPI din celule . Combinarea listelor din aceste lucrări și cartografierea cu simbolurile actuale ale genelor a dat 107 gene. Am verificat la fața locului câteva dintre acestea la întâmplare. Printre acestea se numărau proteine binecunoscute ancorate în GPI, cum ar fi glypican-1 (GPC1) și molecula de adeziune a celulelor neuronale (NCAM1), despre care s-a raportat că au interacțiuni cu PrP . Dar, de asemenea, au fost prezente mai multe gene pentru care nu părea să se cunoască în literatura de specialitate nicio ancorare GPI, cum ar fi VDAC3, unele dintre acestea putând fi pur și simplu proteine foarte abundente sau false pozitive din alte motive. Între timp, există surse evidente de falsuri negative: gene care pur și simplu nu au fost exprimate în linia celulară studiată sau care nu au fost suficient de abundente pentru a fi detectate prin spectrometrie de masă, iar paralogii PrP SPRN și PRND nu se aflau pe liste. În total, 51 de gene se aflau în ambele liste, o îmbogățire foarte semnificativă (OR = 217, P < 1 × 10-84), ceea ce mă ajută să mă asigur că adnotările Uniprot sunt în concordanță cu datele empirice. Dar pentru analizele ulterioare am decis să mergem cu lista Uniprot, deoarece pare mai sensibilă și mai specifică.
Înarmați cu această listă, am vrut să văd cum se situează proteinele ancorate în GPI. PrP este o proteină cu un singur exon, scurtă (208 aminoacizi în forma sa matură), neesențială, neesențială și exprimată pe scară largă. Sunt aceste caracteristici tipice sau atipice pentru o proteină ancorată de GPI?
Se pare că proteinele ancorate de GPI sunt peste tot pe hartă, la fel de variabile pe fiecare dimensiune pe care am analizat-o ca orice alt set de proteine.
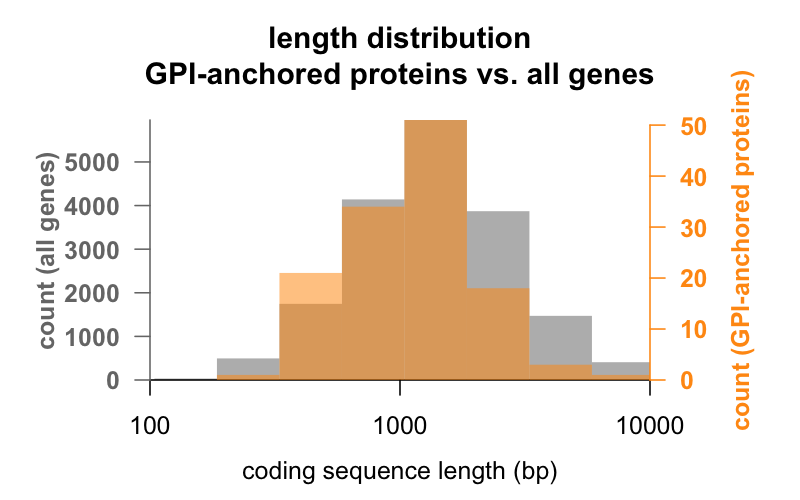
În primul rând, lungimea. Mai jos sunt suprapuse histogramele suprapuse ale lungimii secvenței codificatoare în perechi de baze pentru toate genele, față de genele care codifică proteine ancorate în GPI. Distribuția celor ancorate de GPI este abia deplasată spre stânga. Gena medie a proteinei ancorate de GPI are 1 301 pb de secvență codificatoare, în timp ce gena medie are 1 729, dar această diferență de medii este mică în comparație cu variația din cadrul fiecărui grup. PrP, cu doar 762 pb de secvență codificatoare, este cu siguranță pe partea mică, deși nu este în niciun caz o valoare aberantă în niciunul dintre grupuri – CD52, cu doar 186 de perechi de baze de secvență și aparent doar 12 aminoacizi în forma sa matură , este cea mai mică proteină ancorată de GPI.
Cum rămâne cu numărul de exoni? Proteinele ancorate de GPI au în medie ceva mai puțini exoni, comparativ cu toate genele (media 7,8 vs. 10,1), în concordanță cu diferența ușoară de distribuție a lungimii observată mai sus, dar majoritatea sunt multi-exoni. Și în acest caz, PrP se află pe partea mică: există doar șase proteine ancorate în GPI care au doar un exon codificator, iar trei dintre acestea sunt PrP și cei doi paralogi ai săi, Sho și Dpl. (Celelalte trei gene sunt GAS1, SPACA4 și fabuloasa OMG).
În continuare am analizat constrângerea de pierdere a funcției. Constrângerea este o măsură a cât de puternică este selecția naturală la care este supusă o genă, bazată pe cât de sărăcită este pentru, să zicem, nonsens, frameshift și variația situsului de îmbinare în populația generală, în comparație cu așteptările bazate pe ratele de mutație. Această măsură nu este foarte ușor de interpretat în cazul genelor scurte, atât din motive statistice (numărul de mutații preconizate este scăzut în cazul genelor scurte, astfel încât este greu de cuantificat epuizarea), cât și din motive biologice (genele cu un singur exon nu sunt supuse descompunerii mediate de nonsens, astfel încât este mai greu de știut dacă variantele de trunchiere a proteinelor sunt într-adevăr „pierderi de funcție” sau nu). Dar, deoarece majoritatea proteinelor ancorate în GPI nu sunt la fel de scurte ca PrP, am considerat că merită să arunc o privire. Rezultatul: în medie, proteinele ancorate în GPI sunt doar puțin mai puțin constrânse, ceea ce înseamnă că au o cantitate mai mare din cantitatea așteptată de variație de pierdere a funcției, decât o genă medie. Gena medie are 47% din variația sa de pierdere a funcției, iar proteinele ancorate în GPI au 56%. Dar, ca în cazul tuturor lucrurilor de aici, există o distribuție largă în ambele tabere. În ceea ce privește proteinele ancorate în GPI, la un capăt se află ACHE (17 LoF așteptate și niciuna observată) și, la celălalt capăt, mai multe gene care par să nu fie supuse deloc selecției împotriva pierderii de funcție – CNTN6, CD109, TREH și MSLN sunt câteva exemple. PRNP se încadrează în această din urmă tabără, odată ce excludem reziduurile ≥145, unde variantele de trunchiere a proteinei determină un câștig de funcție .
În cele din urmă, m-am întrebat unde sunt exprimate proteinele ancorate în GPI. PRNP este cea mai ridicată în creier, dar este exprimată peste tot. Este acest lucru tipic? Am descărcat fișierul complet de rezumat GTEx v7 „gene median tpm” (15 ianuarie 2016), în care fiecare rând este o genă și fiecare coloană este un țesut, iar celulele sunt RPKM-uri – citiri RNA-seq pe kilobază de exon pe milion de citiri cartografiate. Lucrul cu acest set de date a necesitat câteva ajustări. Am auzit că unii bioinformaticieni consideră că <1 RPKM este „neexprimat”, dar matricea de expresie este rarefiată – majoritatea genelor nu sunt foarte exprimate în majoritatea țesuturilor – astfel încât zgomotul sub 1 RPKM poate domina dacă se trasează doar RPKM-urile brute. Între timp, expresia genelor este ceva la care trebuie să vă gândiți pe o scară logaritmică, deoarece genele dintr-un țesut pot varia de la <1 RPKM la >10.000 RPKM, astfel încât, dacă considerați totul pe o scară liniară, atunci cele câteva combinații de gene/țesut cu adevărat foarte bine exprimate pot, de asemenea, să domine, făcând ca matricea să pară și mai rarefiată decât este. Prin urmare, am luat log10 al matricei și am trunchiat distribuția la , astfel, scara purpurie pe care am folosit-o merge 1 – 10 – 100 – 1.000 – 10.000 RPKM. Apoi, am subsettat la proteinele ancorate în GPI din Uniprot. Pentru a vizualiza acest lucru, am făcut o hartă termică pentru prima dată în viața mea. Am văzut de multe ori acestea în lucrări și, de obicei, nu mă interesează, dar aici scopul meu era doar să am o idee despre modelul de expresie și, după ce m-am jucat puțin, aceasta a fost cea care mi-a oferit cele mai multe informații. Principiul unei hărți termice este acela că rândurile și coloanele sunt grupate astfel încât lucrurile similare să meargă împreună. Astfel, de exemplu, toate coloanele de țesut cerebral sunt aliniate consecutiv într-o zonă pe axa x, iar toate genele puternic exprimate în creier sunt aliniate consecutiv într-o zonă pe axa y, astfel încât intersecția lor să formeze un dreptunghi violet dens care poate fi interpretat ca fiind „există un grup de gene care sunt în mare parte exprimate în creier”.
Cititorii interesați pot vizualiza PDF-ul de artă vectorială la scară completă a hărții termice, dar pentru a o face mai imediat accesibilă, iată o versiune notată de mână, care indică grupurile de interes:

Răspunsul, deci, este nu – majoritatea proteinelor ancorate în GPI nu au același model de expresie ca PRNP. PRNP este una dintre cele câteva dintre cele mai puternic și mai larg exprimate, figurând aproape de partea superioară a acestei hărți termice, alături de CD59, LY6E, GPC1 și BST2. Majoritatea proteinelor ancorate în GPI au o expresie mai mică sau mai restrânsă la nivel tisular, unele fiind exprimate aproape exclusiv în creier și altele aproape exclusiv neexprimate în creier, iar alte grupuri mai mici aparținând în principal unor țesuturi specifice, cum ar fi testiculele, cum ar fi PRND, paralogul lui PrP, al cărui knock-out provoacă sterilitate masculină .
concluzii
Proteinele ancorate de GPI pot avea aproape orice dimensiune, pot fi exprimate în aproape orice țesut și, aparent, au aproape orice funcție, în măsura în care funcțiile lor sunt cunoscute. Multe proteine ancorate în GPI au funcții native foarte clare, dar aceste funcții sunt diverse și nu este clar de ce necesită ancorarea în GPI, mai ales că multe dintre aceste proteine există și în izoforme care nu sunt ancorate în GPI. Între timp, pentru alte proteine ancorate în GPI, inclusiv PrP, știm destul de puțin despre funcția nativă pentru început, astfel încât este dificil să speculăm măcar de ce funcția nativă necesită ancorarea în GPI. Niciuna dintre analizele pe care le-am făcut sau din recenziile pe care le-am citit nu a reușit să desprindă un principiu unificator cu privire la motivul pentru care există acest mecanism de ancorare sau ce face ca aceste proteine să aibă nevoie de el. Există o serie de ipoteze privind motivul pentru care proteinele ancorate de GPI sunt unice, inclusiv rafturile lipidice, homodimerii și vărsarea. Toate aceste ipoteze ar putea fi valabile. Dar, la sfârșitul zilei, răspunsul pare puțin probabil să fie un moment eureka, ci mai degrabă, la fel ca o mare parte din biologie, un amestec prozaic de lucruri diferite.
Codul R și fișierele de date brute pentru analizele din acest post sunt aici.
.