Overview
- Învățați să interpretați Bias și Variance într-un model dat.
- Care este diferența dintre Bias și Varianță?
- Cum să obțineți Bias și Varianță Tradeoff folosind fluxul de lucru Machine Learning
Introducere
Lasă-ne să vorbim despre vreme. Plouă doar dacă este puțin umed și nu plouă dacă bate vântul, este cald sau înghețat. În acest caz, cum ați putea antrena un model predictiv și să vă asigurați că nu există erori în prognozarea vremii? Ați putea spune că există mulți algoritmi de învățare din care puteți alege. Aceștia sunt distincți în multe privințe, dar există o diferență majoră în ceea ce ne așteptăm și ceea ce prezice modelul. Acesta este conceptul de Bias and Variance Tradeoff.
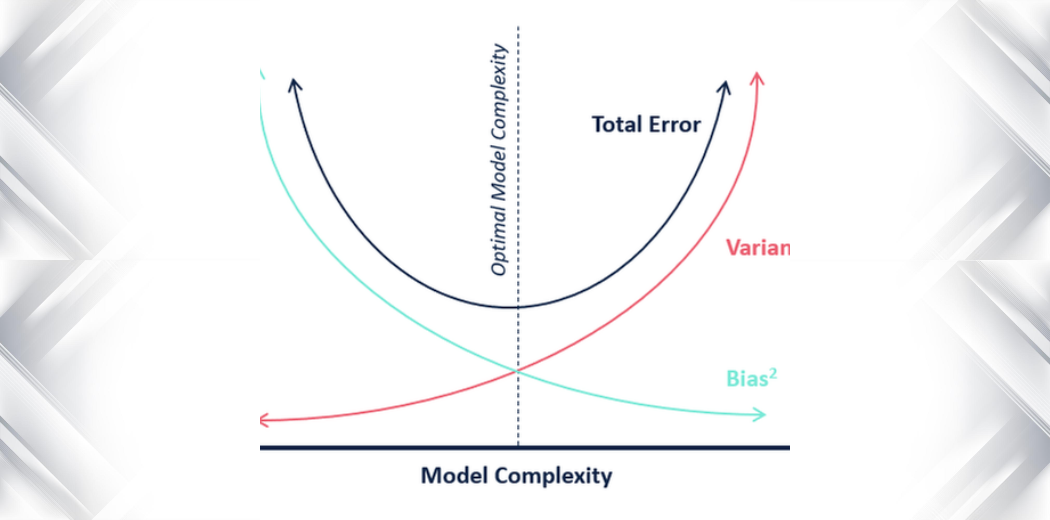
De obicei, Bias and Variance Tradeoff este predat prin formule matematice dense. Dar, în acest articol, am încercat să explic Bias și Varianța cât mai simplu posibil!
Accentul meu va fi acela de a vă învârti prin procesul de înțelegere a enunțului problemei și de a mă asigura că alegeți cel mai bun model în care erorile de Bias și Varianță sunt minime.
Pentru aceasta, am preluat popularul set de date Pima Indians Diabetes. Setul de date constă în măsurători de diagnosticare ale pacienților adulți de sex feminin din patrimoniul indienilor nativi Pima. Pentru acest set de date, ne vom concentra pe variabila „Outcome” – care indică dacă pacientul are sau nu diabet. Evident, aceasta este o problemă de clasificare binară și ne vom arunca cu capul înainte și vom învăța cum să o abordăm.
Dacă sunteți interesat de acest lucru și de conceptele de știință a datelor și doriți să învățați practic, consultați cursul nostru- Introducere în știința datelor
Tabel de conținut
- Evaluarea unui model de învățare automată
- Declararea problemei și pașii principali
- Ce este biasul?
- Ce este varianța?
- Bias-Variance Tradeoff
Evaluarea modelului de învățare automată
Obiectivul principal al modelului de învățare automată este de a învăța din datele date și de a genera predicții pe baza modelului observat în timpul procesului de învățare. Cu toate acestea, sarcina noastră nu se încheie aici. Trebuie să aducem continuu îmbunătățiri modelelor, pe baza tipului de rezultate pe care le generează. De asemenea, cuantificăm performanța modelului utilizând parametri precum Precizia, Eroarea medie pătratică (MSE), scorul F1 etc. și încercăm să îmbunătățim acești parametri. Acest lucru poate deveni adesea dificil atunci când trebuie să menținem flexibilitatea modelului fără a compromite corectitudinea acestuia.
Un model de învățare automată supravegheată urmărește să se antreneze pe variabilele de intrare (X) în așa fel încât valorile prezise (Y) să fie cât mai apropiate de valorile reale. Această diferență între valorile reale și valorile prezise reprezintă eroarea și este utilizată pentru a evalua modelul. Eroarea pentru orice algoritm supravegheat de învățare automată cuprinde 3 părți:
- Eroare de bias
- Eroare de variație
- Zgomotul
În timp ce zgomotul este eroarea ireductibilă pe care nu o putem elimina, celelalte două i.adică Bias și Varianța sunt erori reductibile pe care putem încerca să le minimizăm cât mai mult posibil.
În secțiunile următoare, vom aborda eroarea de Bias, eroarea de Varianță și compromisul Bias-Varianță, care ne vor ajuta la selectarea celui mai bun model. Și ceea ce este interesant este faptul că vom acoperi câteva tehnici de tratare a acestor erori prin utilizarea unui set de date de exemplu.
Enunțarea problemei și etapele principale
După cum am explicat mai devreme, am preluat setul de date Pima Indians Diabetes și am format o problemă de clasificare pe acesta. Să începem prin a evalua setul de date și să observăm tipul de date cu care avem de-a face. Vom face acest lucru prin importarea bibliotecilor necesare:
Acum, vom încărca datele într-un cadru de date și vom observa câteva rânduri pentru a obține informații despre date.
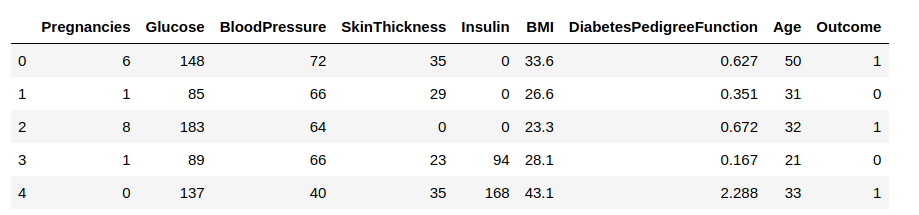
Trebuie să prezicem coloana ‘Outcome’. Să o separăm și să o atribuim unei variabile țintă ‘y’. Restul cadrului de date va fi setul de variabile de intrare X.
Acum să dimensionăm variabilele de predicție și apoi să separăm datele de instruire și cele de testare.
Din moment ce rezultatele sunt clasificate într-o formă binară, vom folosi cel mai simplu clasificator K-nearest neighbor(Knn) pentru a clasifica dacă pacientul are sau nu diabet.
Cum decidem însă valoarea lui ‘k’?
- Poate ar trebui să folosim k = 1 astfel încât să obținem rezultate foarte bune pe datele noastre de antrenament? Acest lucru ar putea funcționa, dar nu putem garanta că modelul va funcționa la fel de bine pe datele noastre de testare, deoarece poate deveni prea specific
- Ce-ar fi să folosim o valoare mare a lui k, de exemplu k = 100, astfel încât să putem lua în considerare un număr mare de puncte apropiate pentru a ține cont și de punctele îndepărtate? Cu toate acestea, acest tip de model va fi prea generic și nu putem fi siguri că a luat în considerare corect toate caracteristicile contributive posibile.
Să luăm câteva valori posibile ale lui k și să ajustăm modelul pe datele de instruire pentru toate aceste valori. Vom calcula, de asemenea, scorul de instruire și scorul de testare pentru toate aceste valori.
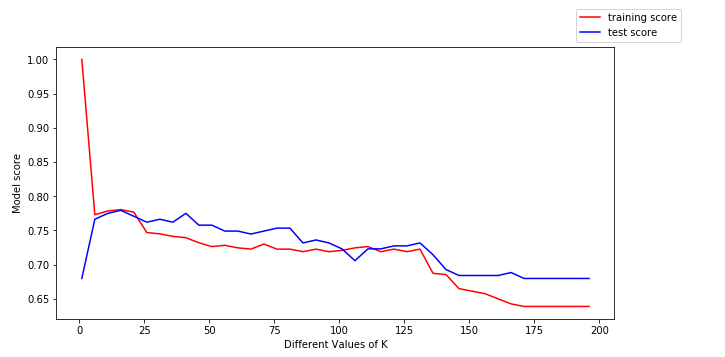
Pentru a obține mai multe informații de aici, haideți să reprezentăm grafic datele de instruire (în roșu) și datele de testare (în albastru).
Pentru a calcula scorurile pentru o anumită valoare a lui k,
![]()
Potem trage următoarele concluzii din graficul de mai sus:
- Pentru valori mici ale lui k, scorul de instruire este mare, în timp ce scorul de testare este mic
- Pe măsură ce valoarea lui k crește, scorul de testare începe să crească, iar scorul de instruire începe să scadă.
- Cu toate acestea, la o anumită valoare a lui k, atât scorul de instruire, cât și scorul de testare sunt apropiate unul de celălalt.
Acesta este momentul în care intră în scenă Bias și Varianța.
Ce este Bias?
În termenii cei mai simpli, Bias este diferența dintre valoarea prezisă și valoarea așteptată. Pentru a explica mai departe, modelul face anumite presupuneri atunci când se antrenează pe datele furnizate. Atunci când este introdus pe datele de testare/validare, aceste ipoteze pot să nu fie întotdeauna corecte.
În modelul nostru, dacă folosim un număr mare de vecini apropiați, modelul poate decide în totalitate că unii parametri nu sunt deloc importanți. De exemplu, acesta poate considera doar că nivelul de glucoză și tensiunea arterială decid dacă pacientul are diabet. Acest model ar face ipoteze foarte puternice cu privire la ceilalți parametri care nu afectează rezultatul. De asemenea, vă puteți gândi la el ca la un model care prezice o relație simplă atunci când punctele de date indică în mod clar o relație mai complexă:
Matematic, fie ca variabilele de intrare să fie X și o variabilă țintă Y. Mapăm relația dintre cele două folosind o funcție f.
Deci,
Y = f(X) + e
Aici „e” este eroarea care este distribuită normal. Scopul modelului nostru f'(x) este de a prezice valori cât mai apropiate de f(x). Aici, Biasul modelului este:
Bias = E
După cum am explicat mai sus, atunci când modelul face generalizări, adică atunci când există o eroare de bias mare, rezultă un model foarte simplist care nu ia în considerare foarte bine variațiile. Din moment ce nu învață foarte bine datele de instruire, se numește Underfitting.
Ce este o Varianță?
Contrareferitor la bias, Varianța este atunci când modelul ia în considerare și fluctuațiile din date, adică zgomotul. Deci, ce se întâmplă atunci când modelul nostru are o varianță mare?
Modelul va considera în continuare varianța ca fiind ceva din care să învețe. Adică, modelul învață prea mult din datele de instruire, atât de mult încât, atunci când este confruntat cu date noi (de testare), este incapabil să prezică cu precizie pe baza acestora.
Matematic, eroarea de varianță în model este:
Varianța-E^2
Deoarece în cazul unei varianțe mari, modelul învață prea mult din datele de instruire, se numește supraadaptare.
În contextul datelor noastre, dacă folosim foarte puțini vecini apropiați, este ca și cum am spune că dacă numărul de sarcini este mai mare de 3, nivelul de glucoză este mai mare de 78, TA diastolică este mai mică de 98, grosimea pielii este mai mică de 23 mm și așa mai departe pentru fiecare caracteristică….. decide că pacientul are diabet. Toți ceilalți pacienți care nu îndeplinesc criteriile de mai sus nu sunt diabetici. Deși acest lucru poate fi adevărat pentru un anumit pacient din setul de formare, ce se întâmplă dacă acești parametri sunt aberanți sau chiar au fost înregistrați incorect? În mod clar, un astfel de model s-ar putea dovedi a fi foarte costisitor!
În plus, acest model ar avea o eroare de varianță mare, deoarece predicțiile cu privire la faptul că pacientul este diabetic sau nu variază foarte mult în funcție de tipul de date de instruire pe care i le furnizăm. Astfel, chiar și schimbarea nivelului de glucoză la 75 ar face ca modelul să prezică faptul că pacientul nu are diabet.
Pentru a simplifica, modelul prezice relații foarte complexe între rezultat și caracteristicile de intrare atunci când ar fi fost suficientă o ecuație pătratică. Așa ar arăta un model de clasificare atunci când există o eroare de varianță mare/ când există o supraadaptare:
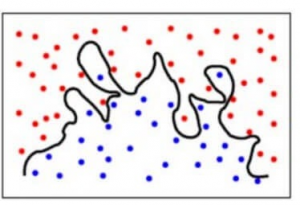
Pentru a rezuma,
- Un model cu o eroare de părtinire mare este subadaptat la date și face presupuneri foarte simpliste asupra acestora
- Un model cu o eroare de varianță mare este supraadaptat la date și învață prea mult din ele
- Un model bun este acela în care atât eroarea de părtinire cât și cea de varianță sunt echilibrate
Bias-Variance Tradeoff
Cum raportăm conceptele de mai sus la modelul nostru Knn de mai devreme? Să aflăm!
În modelul nostru, să spunem, pentru, k = 1, se va lua în considerare punctul cel mai apropiat de punctul de date în cauză. Aici, predicția ar putea fi precisă pentru acel anumit punct de date, astfel încât eroarea de părtinire va fi mai mică.
Cu toate acestea, eroarea de varianță va fi mare, deoarece este luat în considerare doar punctul cel mai apropiat și acest lucru nu ia în considerare celelalte puncte posibile. La ce scenariu credeți că corespunde acest lucru? Da, gândiți corect, acest lucru înseamnă că modelul nostru este supraadaptat.
Pe de altă parte, pentru valori mai mari ale lui k, vor fi luate în considerare mult mai multe puncte mai apropiate de punctul de date în cauză. Acest lucru ar duce la o eroare de polarizare mai mare și la o subadaptare, deoarece sunt luate în considerare multe puncte mai apropiate de punctul de date și, astfel, nu poate învăța specificul din setul de instruire. Cu toate acestea, putem lua în considerare o eroare de varianță mai mică pentru setul de testare care are valori necunoscute.
Pentru a obține un echilibru între eroarea de părtinire și eroarea de varianță, avem nevoie de o valoare a lui k astfel încât modelul să nu învețe din zgomot (supraadaptare la date) și nici să nu facă presupuneri radicale cu privire la date (subadaptare la date). Pentru a simplifica, un model echilibrat ar arăta astfel:
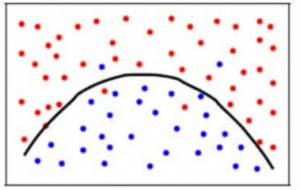
Chiar dacă unele puncte sunt clasificate incorect, modelul se potrivește, în general, cu exactitate majorității punctelor de date. Echilibrul dintre eroarea Bias și eroarea de varianță este compromisul Bias-Varianță.
Diagrama de tip ochi de taur de mai jos explică mai bine compromisul:
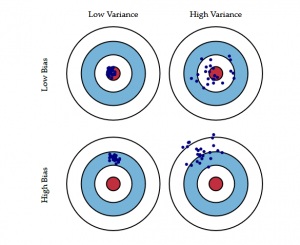
Centrul, adică ochiul de taur, este rezultatul modelului pe care dorim să îl obținem și care prezice perfect și corect toate valorile. Pe măsură ce ne îndepărtăm de ochiul de taur, modelul nostru începe să facă din ce în ce mai multe predicții greșite.
Un model cu bias scăzut și varianță ridicată prezice puncte care se află în jurul centrului în general, dar destul de departe unele de altele. Un model cu bias mare și varianță mică este destul de departe de ochiul de taur, dar deoarece varianța este mică, punctele prezise sunt mai apropiate unele de altele.
În ceea ce privește complexitatea modelului, putem folosi următoarea diagramă pentru a decide asupra complexității optime a modelului nostru.
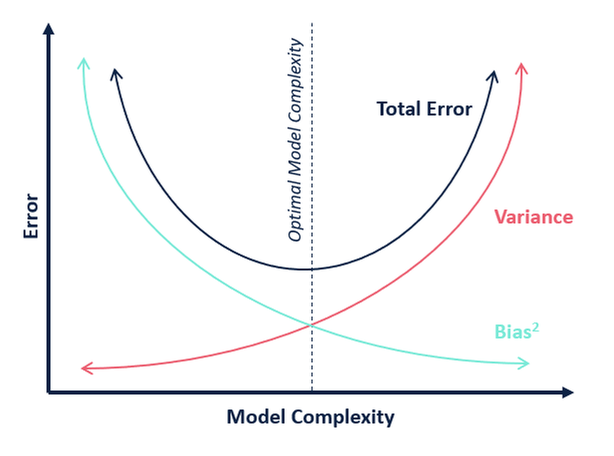
Atunci, care credeți că este valoarea optimă pentru k?
Din explicația de mai sus, putem concluziona că k pentru care
- punctajul de testare este cel mai mare și
- atât punctajul de testare cât și cel de instruire sunt apropiate unul de celălalt
este valoarea optimă a lui k. Deci, chiar dacă facem un compromis cu un scor de instruire mai mic, tot obținem un scor ridicat pentru datele de testare, ceea ce este mai important – datele de testare sunt, la urma urmei, date necunoscute.
Să facem un tabel pentru diferite valori ale lui k pentru a dovedi în continuare acest lucru:
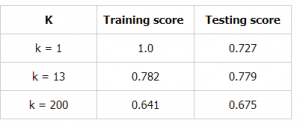
Concluzie
Pentru a rezuma, în acest articol, am învățat că un model ideal ar fi unul în care atât eroarea de polarizare, cât și eroarea de varianță sunt scăzute. Cu toate acestea, ar trebui să urmărim întotdeauna un model în care scorul modelului pentru datele de instruire să fie cât mai aproape posibil de scorul modelului pentru datele de testare.
Aici am aflat cum să alegem un model care să nu fie prea complex (varianță mare și eroare de părtinire mică), ceea ce ar duce la o supraadaptare și nici prea simplu (eroare de părtinire mare și varianță mică), ceea ce ar duce la o subadaptare.
Biasul și varianța joacă un rol important în a decide ce model predictiv să folosim. Sper că acest articol a explicat bine conceptul.
.