
Dacă doriți să învățați mai mult în Python, urmați cursul gratuit Intro to Python for Data Science de la DataCamp.
Toți ați văzut seturi de date. Uneori sunt mici, dar de multe ori, uneori, sunt de dimensiuni extraordinar de mari. Devine foarte dificil să procesați seturile de date care sunt foarte mari, cel puțin suficient de semnificative pentru a provoca un blocaj de procesare.
Atunci, ce face ca aceste seturi de date să fie atât de mari? Ei bine, este vorba de caracteristici. Cu cât numărul de caracteristici este mai mare, cu atât seturile de date vor fi mai mari. Ei bine, nu întotdeauna. Veți găsi seturi de date în care numărul de caracteristici este foarte mare, dar care nu conțin atât de multe instanțe. Dar nu acesta este punctul de discuție aici. Așadar, s-ar putea să vă întrebați, cu un calculator de bază în mână, cum să procesați acest tip de seturi de date fără să bateți câmpii.
De multe ori, într-un set de date cu dimensiuni mari, rămân câteva caracteristici complet irelevante, nesemnificative și neimportante. S-a observat că contribuția acestor tipuri de caracteristici este adesea mai mică la modelarea predictivă în comparație cu caracteristicile critice. Este posibil ca acestea să aibă, de asemenea, o contribuție zero. Aceste caracteristici cauzează o serie de probleme care, la rândul lor, împiedică procesul de modelare predictivă eficientă –
- Alocarea inutilă de resurse pentru aceste caracteristici.
- Aceste caracteristici acționează ca un zgomot pentru care modelul de învățare automată poate avea performanțe teribil de slabe.
- Modelul automat are nevoie de mai mult timp pentru a fi antrenat.
Deci, care este soluția aici? Cea mai economică soluție este selecția caracteristicilor.
Selecția caracteristicilor este procesul de selectare a celor mai semnificative caracteristici dintr-un set de date dat. În multe dintre cazuri, Feature Selection poate îmbunătăți, de asemenea, performanța unui model de învățare automată.
Sună interesant, nu-i așa?
Aveți o introducere informală în Feature Selection și importanța sa în lumea științei datelor și a învățării automate. În acest post veți acoperi:
- Introducere în selecția caracteristicilor și înțelegerea importanței sale
- Diferența dintre selecția caracteristicilor și reducerea dimensionalității
- Diferite tipuri de metode de selecție a caracteristicilor
- Implementarea diferitelor metode de selecție a caracteristicilor cu scikit-learn
Introducere la selecția caracteristicilor
Selecția caracteristicilor este cunoscută și sub numele de selecție de variabile sau selecție de atribute.
În esență, este procesul de selectare a celor mai importante/relevante. Caracteristici ale unui set de date.
Înțelegerea importanței selecției caracteristicilor
Importanța selecției caracteristicilor poate fi recunoscută cel mai bine atunci când aveți de-a face cu un set de date care conține un număr mare de caracteristici. Acest tip de set de date este adesea denumit un set de date cu dimensiuni mari. Acum, odată cu această dimensionalitate ridicată, apar o mulțime de probleme, cum ar fi – această dimensionalitate ridicată va crește semnificativ timpul de instruire a modelului dvs. de învățare automată, vă poate face modelul foarte complicat, ceea ce, la rândul său, poate duce la supraadaptare.
De multe ori, într-un set de caracteristici cu dimensiuni ridicate, rămân mai multe caracteristici care sunt redundante, ceea ce înseamnă că aceste caracteristici nu sunt altceva decât extensii ale altor caracteristici esențiale. Aceste caracteristici redundante nu contribuie în mod eficient nici la formarea modelului. Deci, în mod clar, este necesar să se extragă cele mai importante și cele mai relevante caracteristici pentru un set de date pentru a obține cele mai eficiente performanțe de modelare predictivă.
„Obiectivul selecției variabilelor este triplu: îmbunătățirea performanței de predicție a predictorilor, furnizarea de predictori mai rapizi și mai eficienți din punct de vedere al costurilor și o mai bună înțelegere a procesului de bază care a generat datele.”
-An Introduction to Variable and Feature Selection
Acum să înțelegem diferența dintre reducerea dimensionalității și selecția caracteristicilor.
Uneori, selecția caracteristicilor este confundată cu reducerea dimensionalității. Dar ele sunt diferite. Selecția caracteristicilor este diferită de reducerea dimensionalității. Ambele metode tind să reducă numărul de atribute din setul de date, dar o metodă de reducere a dimensionalității face acest lucru prin crearea de noi combinații de atribute (cunoscută uneori sub numele de transformare a caracteristicilor), în timp ce metodele de selecție a caracteristicilor includ și exclud atributele prezente în date fără a le modifica.
Câteva exemple de metode de reducere a dimensionalității sunt Analiza componentelor principale, Descompunerea valorii singulare, Analiza discriminantă liniară etc.
Lasă-mă să vă rezum importanța selecției caracteristicilor:
- Acesta permite algoritmului de învățare automată să se antreneze mai repede.
- Reduce complexitatea unui model și îl face mai ușor de interpretat.
- Îmbunătățește acuratețea unui model dacă se alege subsetul potrivit.
- Reduce supraadaptarea.
În secțiunea următoare, veți studia diferitele tipuri de metode generale de selectare a caracteristicilor – metode de filtrare, metode Wrapper și metode Embedded.
Metode de filtrare
Următoarea imagine descrie cel mai bine metodele de selectare a caracteristicilor bazate pe filtre:

Sursa imaginii: Analytics Vidhya
Metoda filtrului se bazează pe unicitatea generală a datelor care urmează să fie evaluate și să aleagă un subset de caracteristici, fără a include niciun algoritm de minerit. Metoda de filtrare utilizează criteriul de evaluare exactă care include distanța, informația, dependența și consistența. Metoda de filtrare utilizează criteriile principale ale tehnicii de clasificare și folosește metoda de ordonare a rangurilor pentru selectarea variabilelor. Motivul pentru utilizarea metodei de clasificare este simplitatea, produce caracteristici excelente și relevante. Metoda de clasificare va filtra caracteristicile irelevante înainte de începerea procesului de clasificare.
Metodele de filtrare sunt utilizate în general ca etapă de preprocesare a datelor. Selectarea caracteristicilor este independentă de orice algoritm de învățare automată. Caracteristicile acordă un rang pe baza unor scoruri statistice care tind să determine corelația caracteristicilor cu variabila de rezultat. Corelația este un termen puternic contextual și variază de la o lucrare la alta. Puteți consulta tabelul de mai jos pentru a defini coeficienții de corelație pentru diferite tipuri de date (în acest caz, continue și categorice).

Sursa imaginii: Analytics Vidhya
Câteva exemple de metode de filtrare includ testul Chi pătrat, câștigul de informație și scorurile coeficienților de corelație.
În continuare, veți vedea metodele Wrapper.
Metode de înfășurare
Ca și metodele de filtrare, permiteți-mi să vă dau un același tip de infografic care vă va ajuta să înțelegeți mai bine metodele de înfășurare:
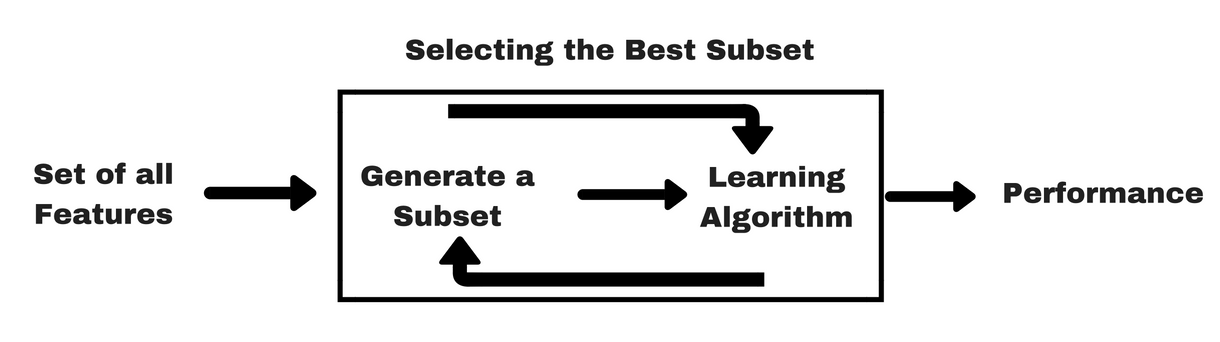
Sursa imaginii: Analytics Vidhya
După cum puteți vedea în imaginea de mai sus, o metodă wrapper are nevoie de un algoritm de învățare automată și folosește performanța acestuia ca și criteriu de evaluare. Această metodă caută o caracteristică care se potrivește cel mai bine algoritmului de învățare automată și urmărește să îmbunătățească performanța de extragere. Pentru a evalua caracteristicile, acuratețea predictivă utilizată pentru sarcinile de clasificare și bonitatea clusterului este evaluată cu ajutorul clusterelor.
Câteva exemple tipice de metode de înfășurare sunt selecția înainte a caracteristicilor, eliminarea inversă a caracteristicilor, eliminarea recursivă a caracteristicilor etc.
- Forward Selection: Procedura începe cu un set gol de caracteristici . Cea mai bună dintre caracteristicile originale este determinată și adăugată la setul redus. La fiecare iterație ulterioară, cea mai bună dintre atributele originale rămase se adaugă la set.
- Eliminare inversă: Procedura începe cu setul complet de atribute. La fiecare pas, se elimină cel mai prost atribut rămas în set.
- Combinație de selecție înainte și eliminare înapoi: Metodele de selecție înainte pas cu pas și de eliminare înapoi pot fi combinate astfel încât, la fiecare pas, procedura să selecteze cel mai bun atribut și să-l elimine pe cel mai rău dintre atributele rămase.
- Eliminare recurentă a caracteristicilor: Eliminarea recurentă a caracteristicilor efectuează o căutare lacomă pentru a găsi cel mai performant subset de caracteristici. Aceasta creează modele în mod iterativ și determină cea mai bună sau cea mai puțin performantă caracteristică la fiecare iterație. Construiește modelele următoare cu caracteristicile rămase până când toate caracteristicile sunt explorate. Apoi, clasifică caracteristicile în funcție de ordinea eliminării lor. În cel mai rău caz, dacă un set de date conține un număr N de caracteristici, RFE va face o căutare lacomă pentru 2N combinații de caracteristici.
Destul de bine!
Acum să studiem metodele încorporate.
Metode încorporate
Metodele încorporate sunt iterative în sensul că se ocupă de fiecare iterație a procesului de formare a modelului și extrag cu atenție acele caracteristici care contribuie cel mai mult la formarea pentru o anumită iterație. Metodele de regularizare sunt cele mai frecvent utilizate metode încorporate care penalizează o caracteristică dată de un prag de coeficient.
De aceea, metodele de regularizare se mai numesc și metode de penalizare care introduc constrângeri suplimentare în optimizarea unui algoritm de predicție (cum ar fi un algoritm de regresie) care înclină modelul spre o complexitate mai mică (mai puțini coeficienți).
Exemple de algoritmi de regularizare sunt LASSO, Elastic Net, Ridge Regression, etc.
Diferența dintre metodele de filtrare și metodele de înfășurare
Ei bine, ar putea deveni confuz uneori să se facă diferența între metodele de filtrare și metodele de înfășurare în ceea ce privește funcționalitățile lor. Să aruncăm o privire asupra punctelor în care acestea diferă una de cealaltă.
- Metodele de filtrare nu încorporează un model de învățare automată pentru a determina dacă o caracteristică este bună sau rea, în timp ce metodele de învățare automată utilizează un model de învățare automată și antrenează caracteristica pentru a decide dacă aceasta este esențială sau nu.
- Metodele de filtrare sunt mult mai rapide în comparație cu metodele de învățare automată, deoarece nu implică antrenarea modelelor. Pe de altă parte, metodele wrapper sunt costisitoare din punct de vedere computațional, iar în cazul seturilor de date masive, metodele wrapper nu sunt cea mai eficientă metodă de selecție a caracteristicilor care trebuie luată în considerare.
- Metodele de filtrare pot eșua în găsirea celui mai bun subset de caracteristici în situațiile în care nu există suficiente date pentru a modela corelația statistică a caracteristicilor, dar metodele wrapper pot oferi întotdeauna cel mai bun subset de caracteristici datorită naturii lor exhaustive.
- Utilizarea caracteristicilor din metodele wrapper în modelul final de învățare automată poate duce la supraadaptare, deoarece metodele wrapper antrenează deja modele de învățare automată cu caracteristicile și afectează adevărata putere de învățare. Dar caracteristicile din metodele de filtrare nu vor duce la supraadaptare în majoritatea cazurilor
Până acum ați studiat importanța selecției caracteristicilor și ați înțeles diferența dintre aceasta și reducerea dimensionalității. De asemenea, ați abordat diferite tipuri de metode de selecție a caracteristicilor. Până aici, totul este bine!
Acum, să vedem câteva capcane în care puteți intra în timp ce efectuați selecția caracteristicilor:
Considerare importantă
Este posibil să fi înțeles deja valoarea selecției caracteristicilor într-o conductă de învățare automată și tipul de servicii pe care le oferă dacă este integrată. Dar este foarte important să înțelegeți exact unde anume ar trebui să integrați selecția caracteristicilor în conducta dvs. de învățare automată.
Simplu vorbind, ar trebui să includeți etapa de selecție a caracteristicilor înainte de a introduce datele în model pentru instruire, în special atunci când utilizați metode de estimare a preciziei, cum ar fi validarea încrucișată. Acest lucru asigură faptul că selecția caracteristicilor este efectuată pe pliul de date chiar înainte ca modelul să fie antrenat. Dar dacă efectuați mai întâi selecția caracteristicilor pentru a pregăti datele, apoi efectuați selecția modelului și instruirea pe caracteristicile selectate, atunci ar fi o gafă.
Dacă efectuați selecția caracteristicilor pe toate datele și apoi faceți validarea încrucișată, atunci datele de test din fiecare pliu al procedurii de validare încrucișată au fost, de asemenea, utilizate pentru a alege caracteristicile, iar acest lucru tinde să influențeze performanța modelului dvs. de învățare automată.
Suficient de teorii! Să trecem direct la codare acum.
Un studiu de caz în Python
Pentru acest studiu de caz, veți folosi setul de date Pima Indians Diabetes. Descrierea setului de date poate fi găsită aici.
Setul de date corespunde unor sarcini de clasificare în care trebuie să preziceți dacă o persoană are diabet pe baza a 8 caracteristici.
Există un total de 768 de observații în setul de date. Prima dvs. sarcină este să încărcați setul de date astfel încât să puteți continua. Dar înainte de asta să importăm dependențele necesare, de care veți avea nevoie. Pe celelalte le puteți importa pe parcurs.
import pandas as pdimport numpy as npAcum că dependențele sunt importate, haideți să încărcăm setul de date Pima Indians într-un obiect Dataframe cu ajutorul bibliotecii Pandas.
data = pd.read_csv("diabetes.csv")Setul de date este încărcat cu succes în datele obiectului Dataframe. Acum, să aruncăm o privire asupra datelor.
data.head()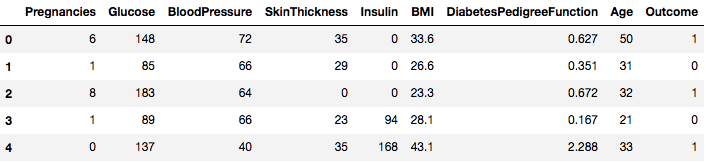
Acum puteți vedea 8 caracteristici diferite etichetate în rezultatele 1 și 0, unde 1 înseamnă că observația are diabet, iar 0 denotă că observația nu are diabet. Se știe că setul de date are valori lipsă. Mai exact, există observații lipsă pentru unele coloane care sunt marcate ca fiind o valoare zero. Puteți deduce acest lucru din definiția acelor coloane și nu este practic ca o valoare zero să nu fie valabilă pentru acele măsuri, de exemplu, zero pentru indicele de masă corporală sau tensiunea arterială este invalidă.
Dar pentru acest tutorial, veți folosi direct versiunea preprocesată a setului de date.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Acum ați încărcat datele într-un obiect DataFrame numit dataframe.
Să convertim obiectul DataFrame într-un array NumPy pentru a obține un calcul mai rapid. De asemenea, să segregăm datele în variabile separate, astfel încât caracteristicile și etichetele să fie separate.
array = dataframe.valuesX = arrayY = arrayMinunat! Ați pregătit datele.
În primul rând, veți implementa un test statistic Chi-Squared pentru caracteristici non-negative pentru a selecta 4 dintre cele mai bune caracteristici din setul de date. Ați văzut deja că testul Chi-Squared aparține clasei de metode de filtrare. Dacă cineva este curios să cunoască elementele interne ale Chi-Squared, acest videoclip face o treabă excelentă.
Biblioteca scikit-learn oferă clasa SelectKBest care poate fi utilizată cu o suită de teste statistice diferite pentru a selecta un anumit număr de caracteristici, în acest caz, este Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Ați importat bibliotecile pentru a rula experimentele. Acum, haideți să le vedem în acțiune.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretare:
Puteți vedea scorurile pentru fiecare atribut și cele 4 atribute alese (cele cu cele mai mari scoruri): plas, test, masă și vârstă. Aceste scoruri vă vor ajuta în continuare să determinați cele mai bune caracteristici pentru antrenarea modelului dumneavoastră.
P.S.: Primul rând denotă numele caracteristicilor. Pentru preprocesarea setului de date, numele au fost codificate numeric.
În continuare, veți implementa Recursive Feature Elimination, care este un tip de metodă de selecție a caracteristicilor de tip wrapper.
Recursive Feature Elimination (sau RFE) funcționează prin eliminarea recursivă a atributelor și construirea unui model pe baza acelor atribute care rămân.
Se utilizează acuratețea modelului pentru a identifica ce atribute (și combinații de atribute) contribuie cel mai mult la prezicerea atributului țintă.
Puteți afla mai multe despre clasa RFE în documentația scikit-learn.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionVă veți utiliza RFE cu clasificatorul Logistic Regression pentru a selecta primele 3 caracteristici. Alegerea algoritmului nu contează prea mult, atâta timp cât este abil și consecvent.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Vezi că RFE a ales primele 3 caracteristici ca fiind preg, mass și pedi.
Acestea sunt marcate ca fiind Adevărate în matricea de suport și marcate cu alegerea „1” în matricea de clasificare. Acest lucru, la rândul său, indică puterea acestor caracteristici.
În continuare, veți folosi regresia Ridge, care este practic o tehnică de regularizare și, de asemenea, o tehnică de selecție a caracteristicilor încorporate.
Acest articol vă oferă o explicație excelentă privind regresia Ridge. Asigurați-vă că îl consultați.
# First things firstfrom sklearn.linear_model import RidgeÎn continuare, veți utiliza regresia Ridge pentru a determina coeficientul R2.
De asemenea, consultați documentația oficială a scikit-learn privind regresia Ridge.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Pentru a înțelege mai bine rezultatele regresiei Ridge, veți implementa o mică funcție de ajutor care vă va ajuta să imprimați rezultatele într-un mod mai bun, astfel încât să le puteți interpreta cu ușurință.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)În continuare, veți trece termenii de coeficient ai modelului Ridge către această mică funcție și veți vedea ce se întâmplă.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Puteți observa toți termenii de coeficient anexați cu variabilele caracteristice. Aceasta vă va ajuta din nou să alegeți cele mai esențiale caracteristici. Mai jos sunt câteva puncte pe care ar trebui să le aveți în vedere în timp ce aplicați regresia Ridge:
- Este, de asemenea, cunoscută sub numele de L2-Regularizare.
- Pentru caracteristicile corelate, înseamnă că acestea tind să obțină coeficienți similari.
- Caracteristicile care au coeficienți negativi nu contribuie atât de mult. Dar într-un scenariu mai complex în care aveți de-a face cu o mulțime de caracteristici, atunci acest scor vă va ajuta cu siguranță în procesul decizional final de selecție a caracteristicilor.
Bine, cu aceasta se încheie secțiunea de studiu de caz. Metodele pe care le-ați implementat în secțiunea de mai sus vă vor ajuta să înțelegeți caracteristicile unui anumit set de date într-un mod cuprinzător. Permiteți-mi să vă prezint câteva puncte critice cu privire la aceste tehnici:
- Selecția caracteristicilor este, în esență, o parte a preprocesării datelor, care este considerată a fi partea care consumă cel mai mult timp în orice proces de învățare automată.
- Aceste tehnici vă vor ajuta să o abordați într-un mod mai sistematic și mai prietenos cu învățarea automată. Veți putea interpreta caracteristicile cu mai multă acuratețe.
Încheiem!
În această postare, ați acoperit unul dintre cele mai bine studiate și mai bine cercetate subiecte statistice, și anume, selecția caracteristicilor. De asemenea, v-ați familiarizat cu diferitele sale variante și le-ați folosit pentru a vedea ce caracteristici dintr-un set de date sunt importante.
Puteți duce acest tutorial mai departe prin îmbinarea unei măsuri de corelație în metoda wrapper și să vedeți cum se comportă. În cursul acțiunii, ați putea ajunge să vă creați propriul mecanism de selecție a caracteristicilor. În acest fel stabiliți fundamentul pentru mica dumneavoastră cercetare. Cercetătorii folosesc, de asemenea, diverse principii de soft computing pentru a efectua selecția. Acesta este în sine un întreg domeniu de studiu și de cercetare. De asemenea, ar trebui să încercați algoritmii existenți de selecție a caracteristicilor pe diferite seturi de date și să trageți propriile concluzii.
De ce aceste metode tradiționale de selecție a caracteristicilor sunt încă valabile?
Da, această întrebare este evidentă. Pentru că există arhitecturi de rețele neuronale (de exemplu, CNN) care sunt destul de capabile să extragă cele mai semnificative caracteristici din date, dar și acestea au o limitare. Utilizarea unui CNN pentru un set de date tabulare obișnuite care nu au proprietăți specifice (proprietățile pe care le deține o imagine tipică, cum ar fi proprietățile de tranziție, marginile, proprietățile de poziție, contururile etc.) nu este cea mai înțeleaptă decizie de luat. În plus, atunci când dispuneți de date și resurse limitate, antrenarea unui CNN pe seturi de date tabulare obișnuite s-ar putea transforma într-o pierdere totală. Așadar, în astfel de situații, metodele pe care le-ați studiat vă vor fi cu siguranță utile.
Cele de mai jos sunt câteva resurse dacă doriți să aprofundați acest subiect:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection: Statistical and Optimization Perspectives Workshop
- Feature Selection: Problem statement and Uses
- Utilizarea algoritmilor genetici pentru selecția caracteristicilor în analiza datelor
Mai jos sunt referințele care au fost folosite pentru a scrie acest tutorial.
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- O introducere în selectarea caracteristicilor
- Analytics Vidhya article on feature selection
- Hierarchical and Mixed Model – DataCamp course
- Feature Selection For Machine Learning in Python
- Outlier Detection in Stream Data by MachineLearning and Feature Selection Methods
- S. Visalakshi și V. Radha, „A literature review of feature selection techniques and applications: Review of feature selection in data mining”, 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.
.